【Spring】RAG 知识库基础
1. RAG 基础概念
1.1 什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将检索技术与人工智能生成技术相结合的混合架构,用于解决大模型时效性限制与幻觉问题
你可以这样理解:RAG 技术就像给 AI 配了一本“小抄”,能够让 AI 在生成内容(考试)的时候,参考“小抄”中的知识库内容再结合自己理解给出更为精准、切合实际需求的回复。
从 技术 的角度来理解,AI 大模型在输入用户提示词之前,会先查询知识库获取相关知识,然后将这些知识作为上下文提供给大语言模型,引导生成更实际、更具时效性、更准确的回答结果,通常引入 RAG 技术后,AI就能:
- 生成更准确、精准的回答
- 在特定的时机推荐自定义的课程、服务等内容
- 生成最新、最具时效性的内容
1.2 RAG 工作流程
RAG 工作流程主要包含以下四个步骤,下面就让我们来分步学习:
- 文档收集与切割
- 向量转换与存储
- 文档过滤与检索
- 查询增强和关联
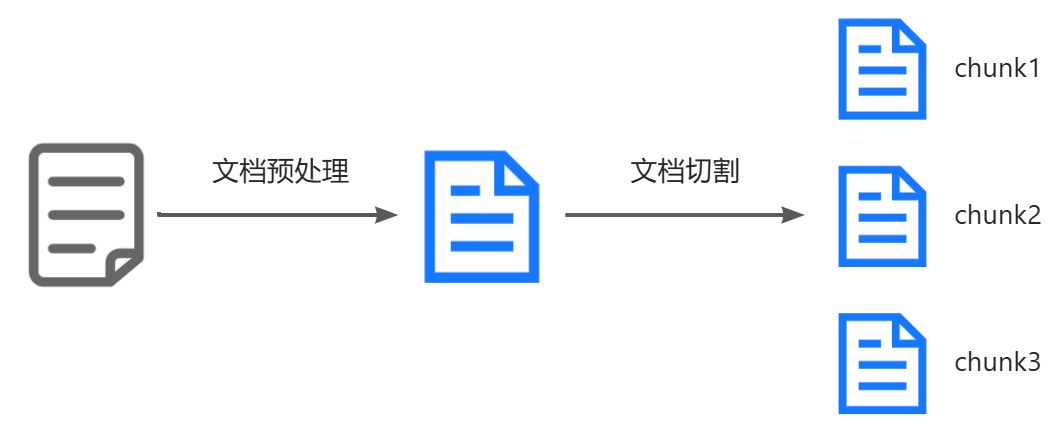
1.2.1 文档收集与切割
文档收集与切割又分为以下子步骤:
- 文档收集:从各种来源(网页、PDF、数据库)当中收集各种形式的文档
- 文档预处理:进行文档的清洗和标准化(比如对于文本大模型去除图片等无法识别项)
- 文档切割:将长文档按照一定规则切割成若干子文档(chunks)
- 按照固定大小切割(比如512MB)
- 按照语义边界切割(比如文章、段落等)
- 按照递归分割策略等算法进行切割
1.2.2 向量转换与存储
向量转换与存储又分为以下子步骤:
- 向量转换:使用 Embedding 模型将高维文本块转换成低维的向量表示,从而表示文本间的语义特征
- 向量存储:将文本域对应的向量表示存储到向量数据库中,以便支持快速高效的相似性查询

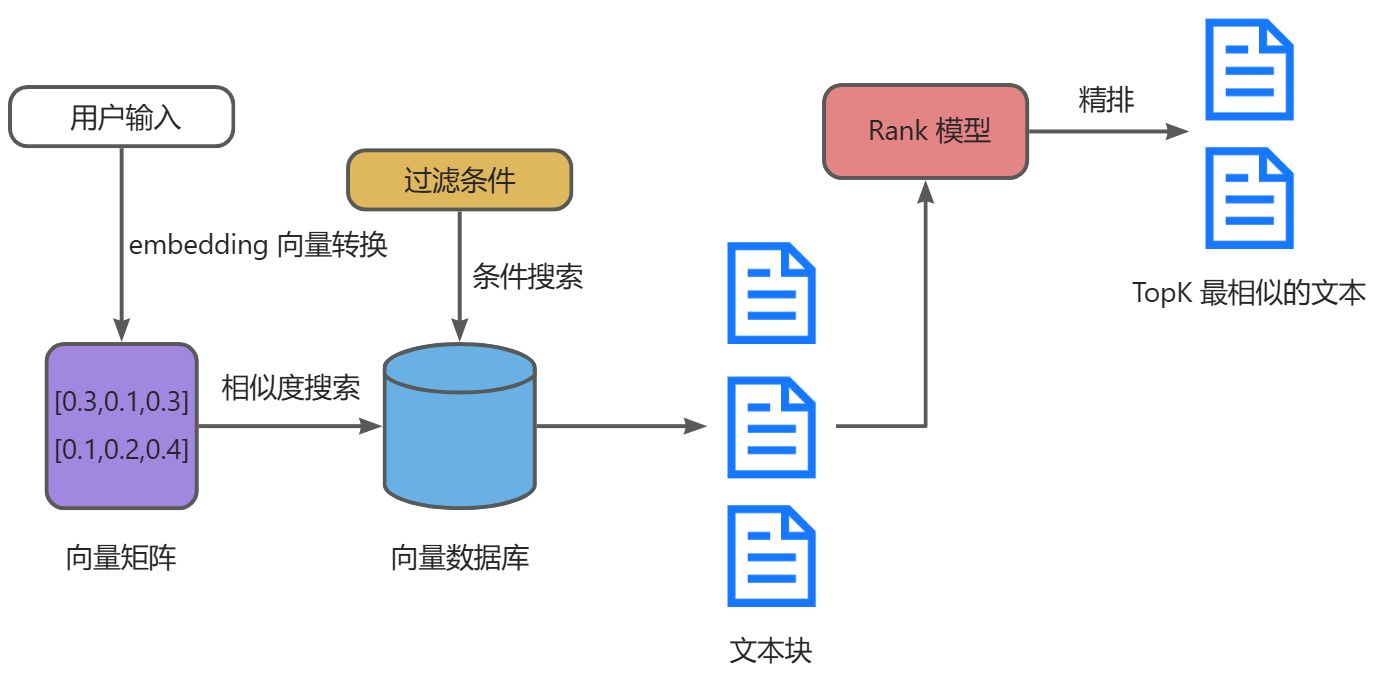
1.2.3 文档过滤与检索
文档过滤与检索又分为以下子步骤:
- 查询转换处理:将用户输入使用相同的 Embedding 模型转换为向量表示
- 文档过滤机制:根据相关元数据、关键词或者自定义规则进行文档过滤筛选
- 相似度搜索:使用一些相似度算法(余弦相似度、欧氏距离)在向量数据库中查找最相似的文档块
- 上下文组装:将最终检索到的多个文档块组装成连贯的上下文
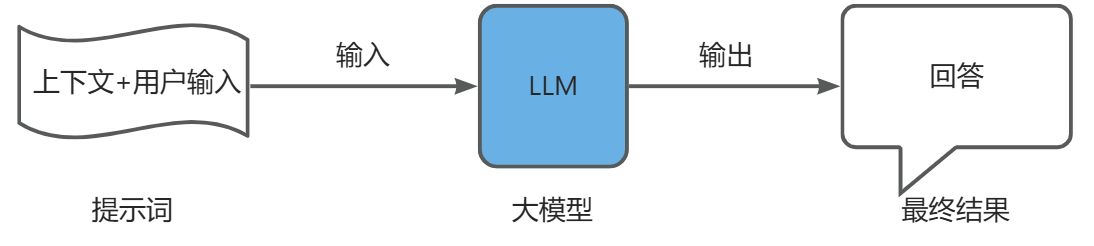
1.2.4 查询增强与关联
查询增强与关联又分为以下子步骤:
- 提示词组装:将得到的 TopK 相似文档作为上下文与用户输入拼接
- 上下文融合:大模型生成回答
- 源引用:在回答中添加信息来源引用
- 后处理:格式化或者其他处理优化最终输出
1.3 RAG 相关技术
前面我们介绍了 RAG 相关的核心步骤,但是内部涉及到一些专业术语在此处进一步展开叙述:
1.3.1 Embedding
Embedding:是指将高维的离散数据(文字、图片等)转换为低维的向量表示的过程,Embedding 嵌入过程必须保证向量能够表示文本间的语义特征,使得后续被计算机识别处理
Embedding 模型:指的是执行 Embedding 过程的机器学习模型,不同 embedding 模型的向量表示、维度也不同,一般来说维度越高表达越精确,同时占据的存储空间也会越多
1.3.2 向量数据库
向量数据库是专门用来存储以及检索向量的数据库系统,内置高效的索引查询算法以支持相似度搜索、K 近邻查询
💡 注意:并不是说只有向量数据库才能存储向量数据,传统型关系数据库也可以存储向量,只是无法支持高效的检索而已
AI 的流行带火了一些向量数据库,比如 Milnus、Pinecone。此外一些传统数据库也可以通过安装插件的方式来实现向量存储与检索,比如 PGVector、Redis Stack 的RediSearch 等,下面是向量数据库的分类图:

1.3.3 召回
召回:是信息检索过程的第一步,需要在大规模候选集合中选出可能的候选子集,强调 广度和速度,对于精确度要求不高
举个例子,当我们在百度当中搜索:“程序员米饭好好吃的github链接是什么?”,召回阶段就会在数亿个网站中匹配关键词为“程序员”、“米饭”、“github”的网站返回
1.3.4 精排和 Rank 模型
精排:是搜索/推荐系统的最后一步,会通过一些精确度较高、更复杂的计算算法,对候选集进行评分排序等操作,而 rank 模型就是执行将召回阶段得到的候选集进行精排过程的模型
💡 注意:现在 Rank 模型通常基于深度学习模型,比如 BERT 等,会综合用户历史行为,查询与候选项的关联度,即考虑多种特征评估相关性
1.3.5 混合检索策略
混合检索策略:是综合多种检索策略以提高检索效果,比如综合关键词检索、语义检索等
比如在大模型开发平台 Dify 中,就为用户提供了“基于全文关键词检索+基于向量检索”的混合检索策略,用户还可以设置不同检索策略之间的权重
2. RAG 实战:本地知识库
接下来就让我们实战 RAG 开发流程来实现一个《简历辅导知识问答》功能,Spring AI 开发框架提供了对 RAG 的全套支持,我们可以参考 Spring AI 和 Spring AI Alibaba 的官方文档进行学习:
📖 参考文档:
SpringAI:https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
SpringAI Alibaba:https://java2ai.com/docs/1.0.0-M6.1/tutorials/rag/?spm=4347728f.1073474f.0.0.493479829IRKIB
由于这是我们的第一个 RAG 程序,因此我们可以将上述步骤进行简化如下:
- 文档准备
- 文档读取
- 向量转换与存储
- 查询增强
2.1 文档准备
我们可以借助 AI 的力量来生成相关文档,参考提示词如下:
帮我生成 3 篇 Markdown 文章,主题是【后端开发简历辅导问答】,3 篇文章的问题分别针对在校生、应届生、社招的状态,内容形式为 1 问 1 答,每个问题标题使用 4 级标题,每篇内容需要有至少 5 个问题,要求每个问题中推荐一个相关的博客,博客链接都是 https://blog.csdn.net/weixin_62533201
相关文档可以在如下仓库链接中找到:
仓库链接:https://gitee.com/ricejson/rice_ai_agent

2.2 文档读取
现在我们需要将准备好的文档进行读取,然后保存到向量数据库,这个过程也被称为 ETL(抽取、转换、加载),Spring AI 提供了对 ETL 的全套支持。Spring AI 当中 ETL 具备以下三个核心组件:
- DocumentReader:用于读取文档,获得文档列表
- DocumentTransfer:转换文档,获得处理后的文档列表
- DocumentWriter:存储文档列表(保存到向量数据库或者其他地方)

1)步骤一:引入依赖
首先我们需要加载相关依赖用于读取 Markdown 格式的内容:
<!-- 读取markdown依赖 -->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId><version>1.0.0-M6</version>
</dependency>
2)步骤二:编写文档加载器类 MyMarkdownReader
/*** 自定义Markdown阅读器* @author ricejson*/
@Component
public class MyMarkdownReader {private static final Logger logger = LoggerFactory.getLogger(MyMarkdownReader.class);private final ResourcePatternResolver resolver;public MyMarkdownReader(ResourcePatternResolver resolver) {this.resolver = resolver;}public List<Document> loadMarkdowns(){List<Document> documents = new ArrayList<>();try {Resource[] resources = this.resolver.getResources("classpath:document/*.md");for (Resource resource : resources) {// 准备DocumentReaderConfigString filename = resource.getFilename();MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true).withIncludeCodeBlock(false).withIncludeBlockquote(true).withAdditionalMetadata("filename", filename).build();// 创建DocumentReaderMarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);documents.addAll(reader.get());}} catch (IOException e) {logger.error("markdown 文档加载失败!");}return documents;}
}
在上述代码中,我们可以通过MarkdownDocumentReaderConfig来额外指定读取文档的细节,比如是否包含代码块、引用块,此外还可以添加额外的元数据信息:比如此处我们就添加了文件名作为元数据信息
2.3 向量转换与存储
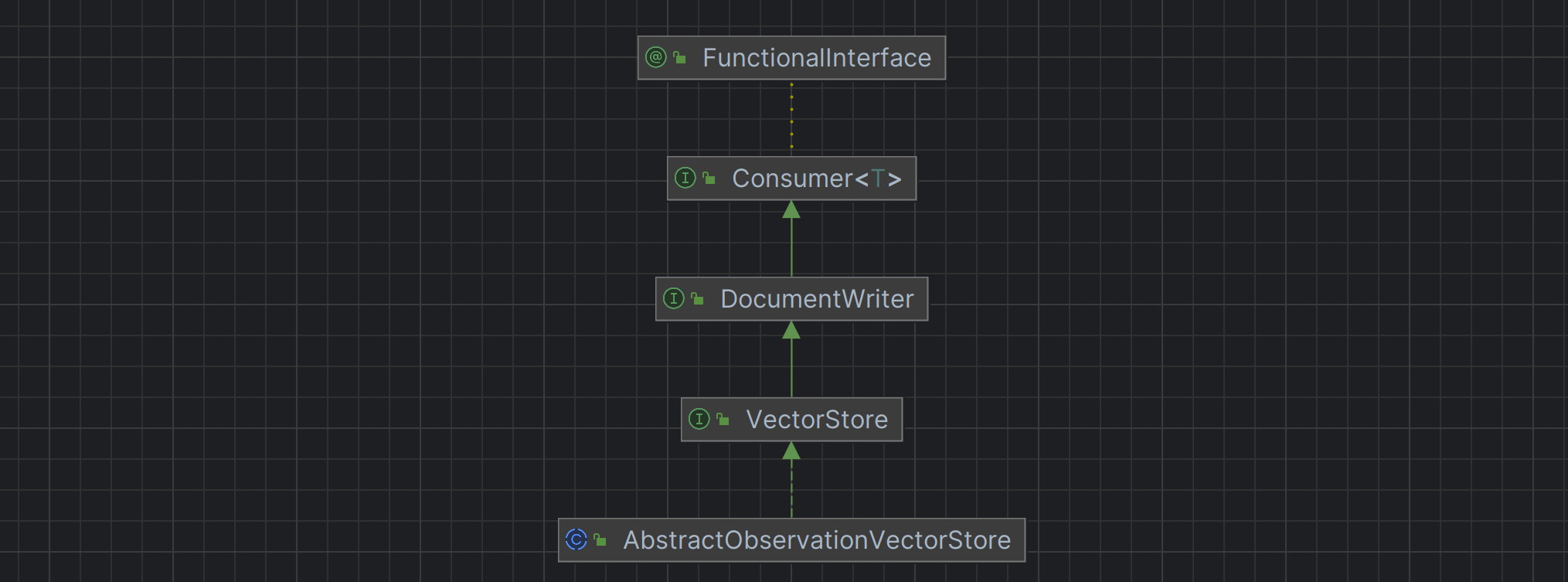
为了简化流程,此处我们使用内置的 Spring AI 提供的基于内存实现的向量数据库 SimpleVectorStore 来保存文档,从如下结构图我们可以看出 SimpleVectorStore 实现了 VectorStore 接口,而 VectorStore 接口又组合了 DocumentWriter 接口 ,因此具有文档写入能力
下面我们就来编写一个 ResumeAppVectoreStoreConfig 配置类用于向量的转换与存储
/*** 简历辅导应用向量存储配置类* @author ricejson*/
@Configuration
public class ResumeAppVectorStoreConfig {@Resourceprivate MyMarkdownReader reader;@Beanpublic VectorStore resumeAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {// 创建SimpleVectorStoreSimpleVectorStore vectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();// 加载文档List<Document> documents = reader.loadMarkdowns();vectorStore.add(documents);return vectorStore;}
}
2.4 查询增强
SpringAI 提供了开箱即用的 Advisor 特性来提供 RAG 功能,主要是 QuestionAnswerAdvisor 问答拦截器和 RetrievalAugmentationAdvisor 检索增强拦截器,前者简单易用,后者灵活强大。
查询增强的原理非常简单,即在将用户输入发送给大模型之前通过 Advisor 机制从向量数据库当中获取知识库数据,并将响应作为上下文信息提供给大模型,我们可以查看 QuestionAnswerAdvisor 相关源码:
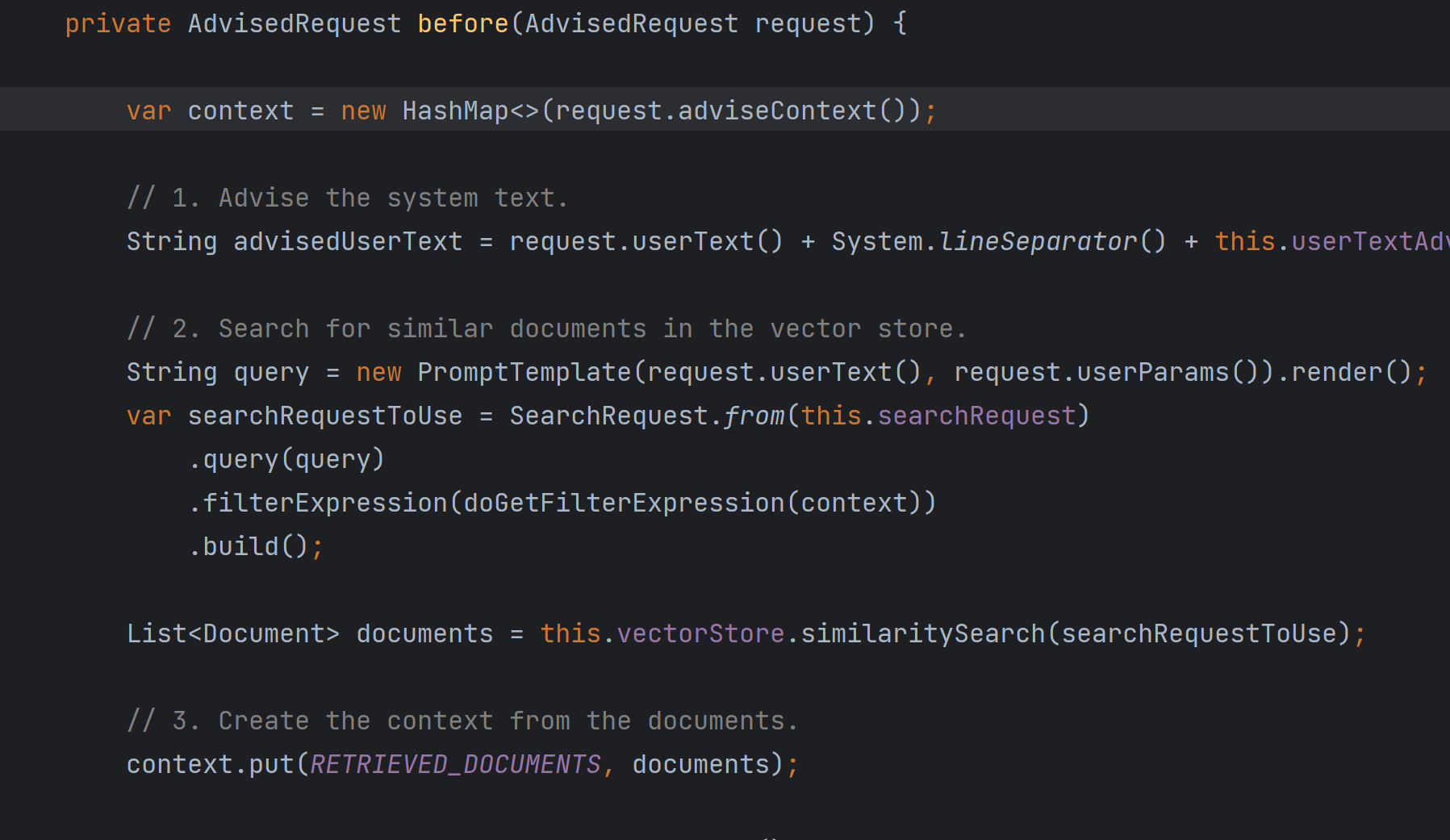
1)步骤一:引入依赖
<!-- RAG Advisor 依赖 -->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-advisors-vector-store</artifactId><version>1.0.0-M7</version>
</dependency>
2)步骤二:引入 advisor
@jakarta.annotation.Resourceprivate VectorStore resumeAppVectorStore;public String doChatWithRag(String userPrompt, String chatId) {return chatClient.prompt().user(userPrompt).advisors((spec) -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))// 开启日志拦截器.advisors(new MyLoggerAdvisor())// 开启知识问答RAG拦截器.advisors(new QuestionAnswerAdvisor(resumeAppVectorStore)).call().content();}
3)步骤三:执行测试
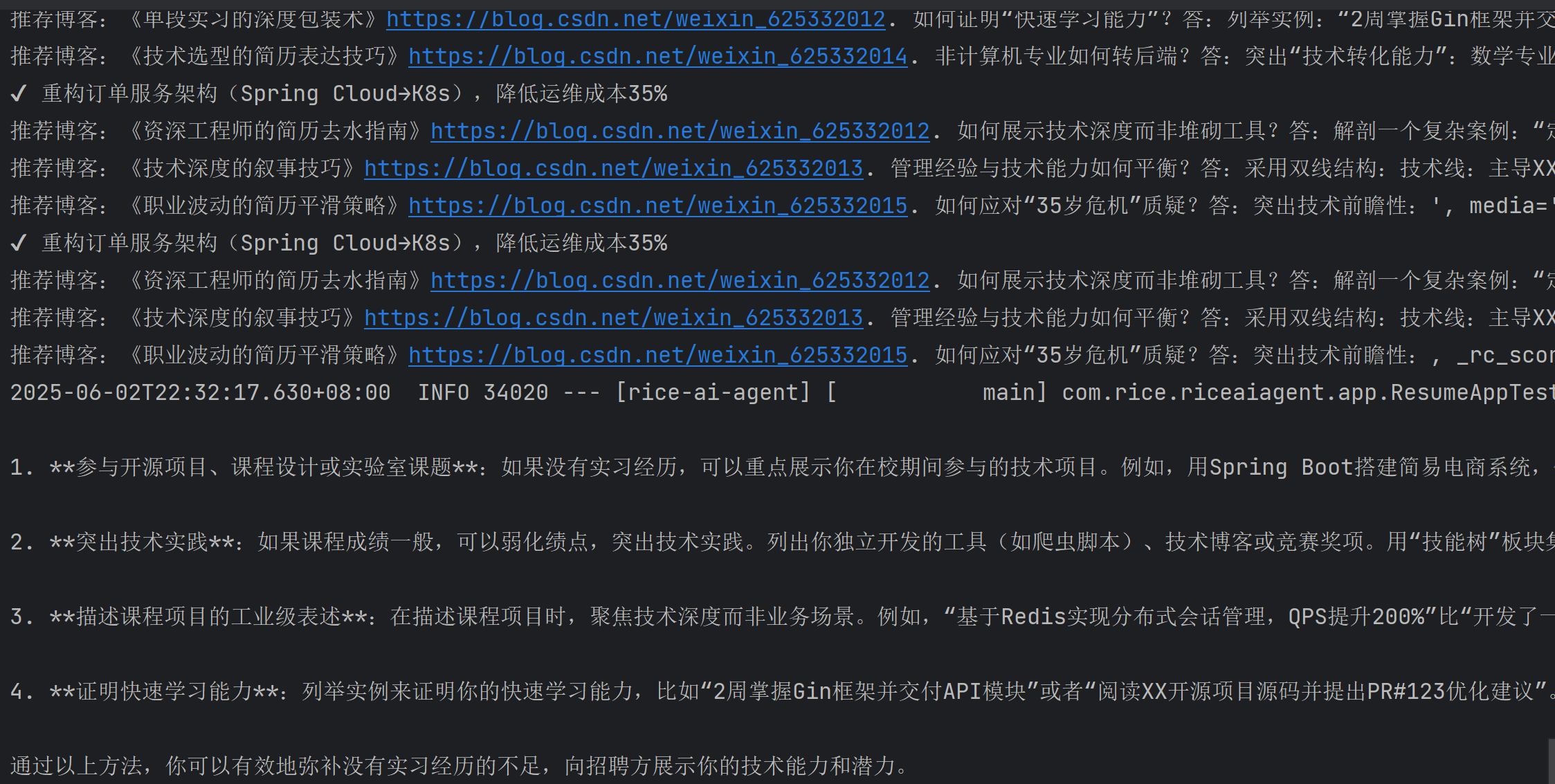
@Test
public void testDoChatWithRag() {String chatId = UUID.randomUUID().toString();String content = resumeApp.doChatWithRag("我是一名应届生,想应聘Java后端开发工程师,但是没有实习经历怎么办?", chatId);Assertions.assertNotNull(content);logger.info("content: {}", content);
}
运行结果如下图所示(证明知识库已经生效了):

3. RAG 实战:云知识库
在上一小节中,文档读取、文档加载、向量存储都是通过本地编程的方式实现的,实际上还有另一种方式:就是直接使用线上的云知识库来简化 RAG 的开发,但缺点就是涉及数据隐私以及额外费用问题
大部分 AI 应用开发平台都提供了云知识库的服务,这里我们还是使用百炼大模型平台,因为 Spring AI Alibaba 可以轻松与它进行集成
3.1 准备云知识库
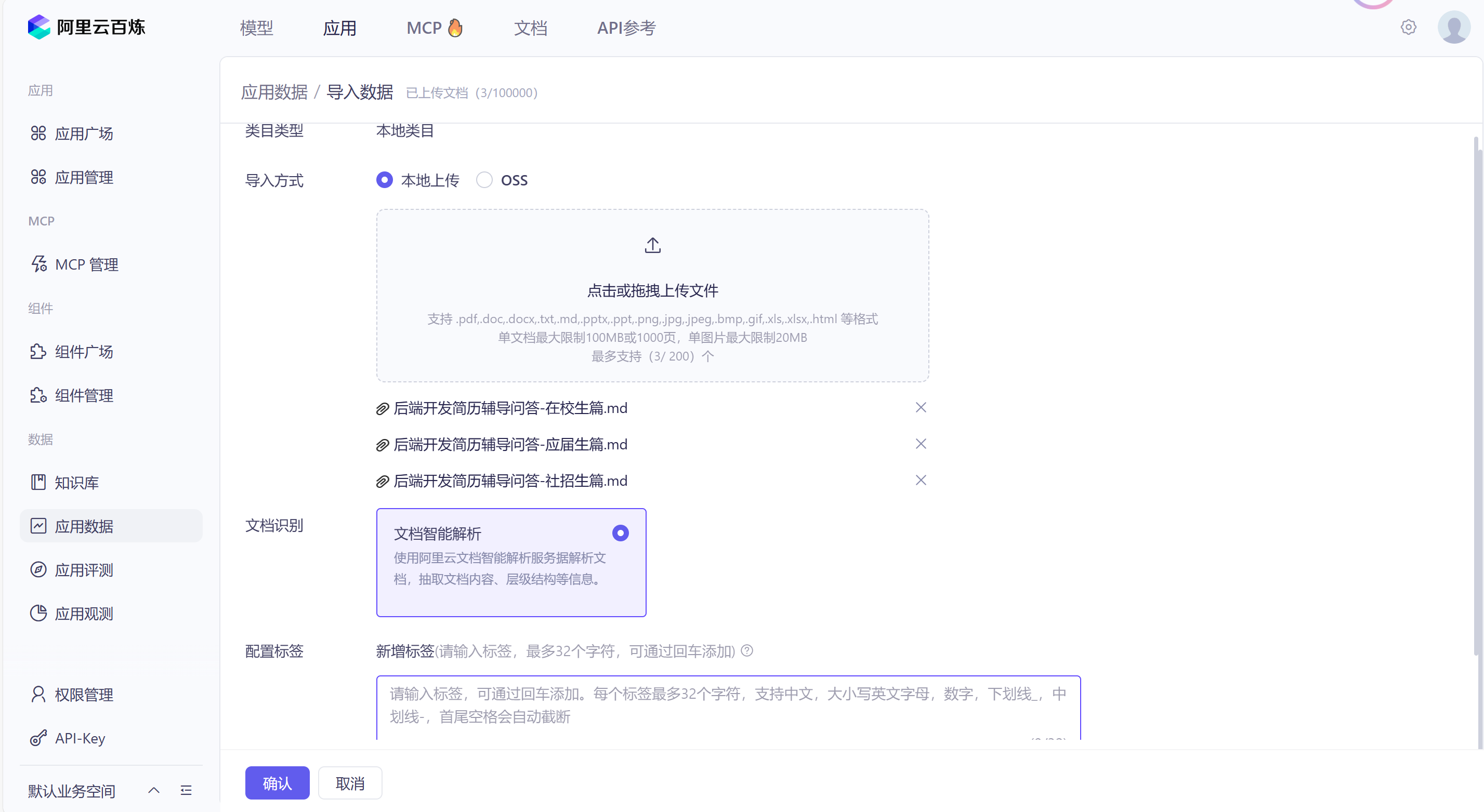
1)步骤一:准备数据
在应用数据模块平台可以将原始文档上传到平台并由平台帮忙解析内容:
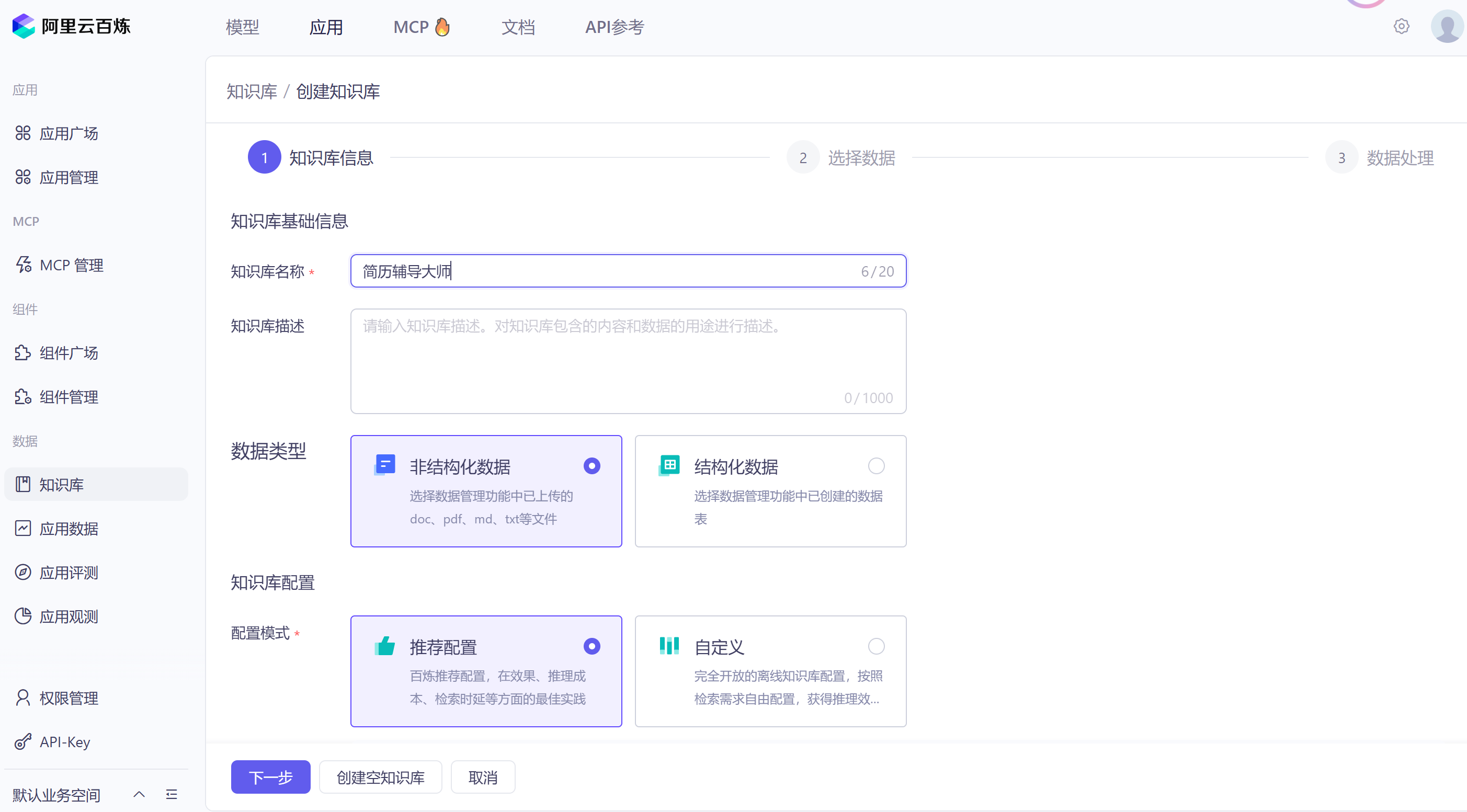
2)步骤二:创建知识库
在阿里百炼平台中,选择创建知识库应用,并使用默认配置即可
3)步骤三:导入数据到知识库中
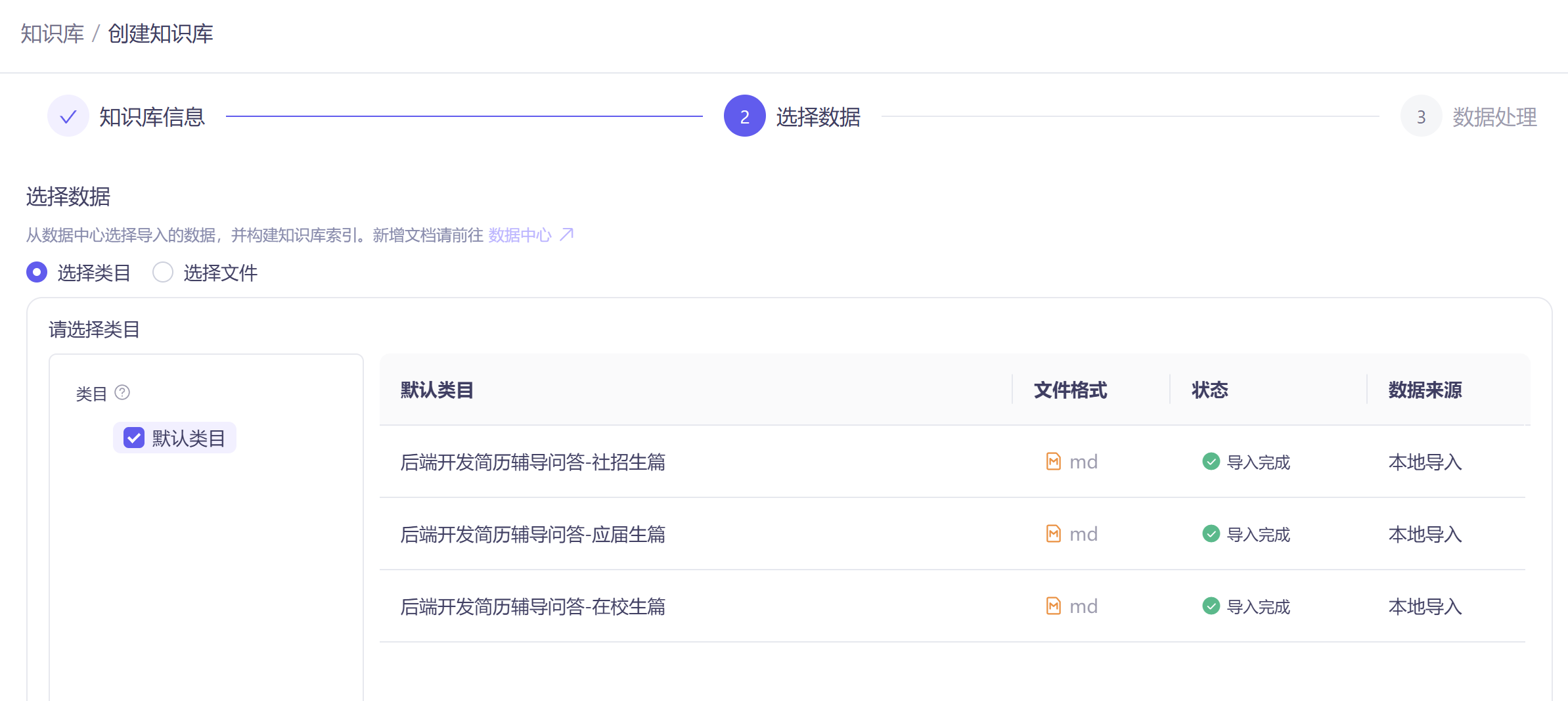
导入数据时,可以设置数据预处理规则,比如文档切割方式
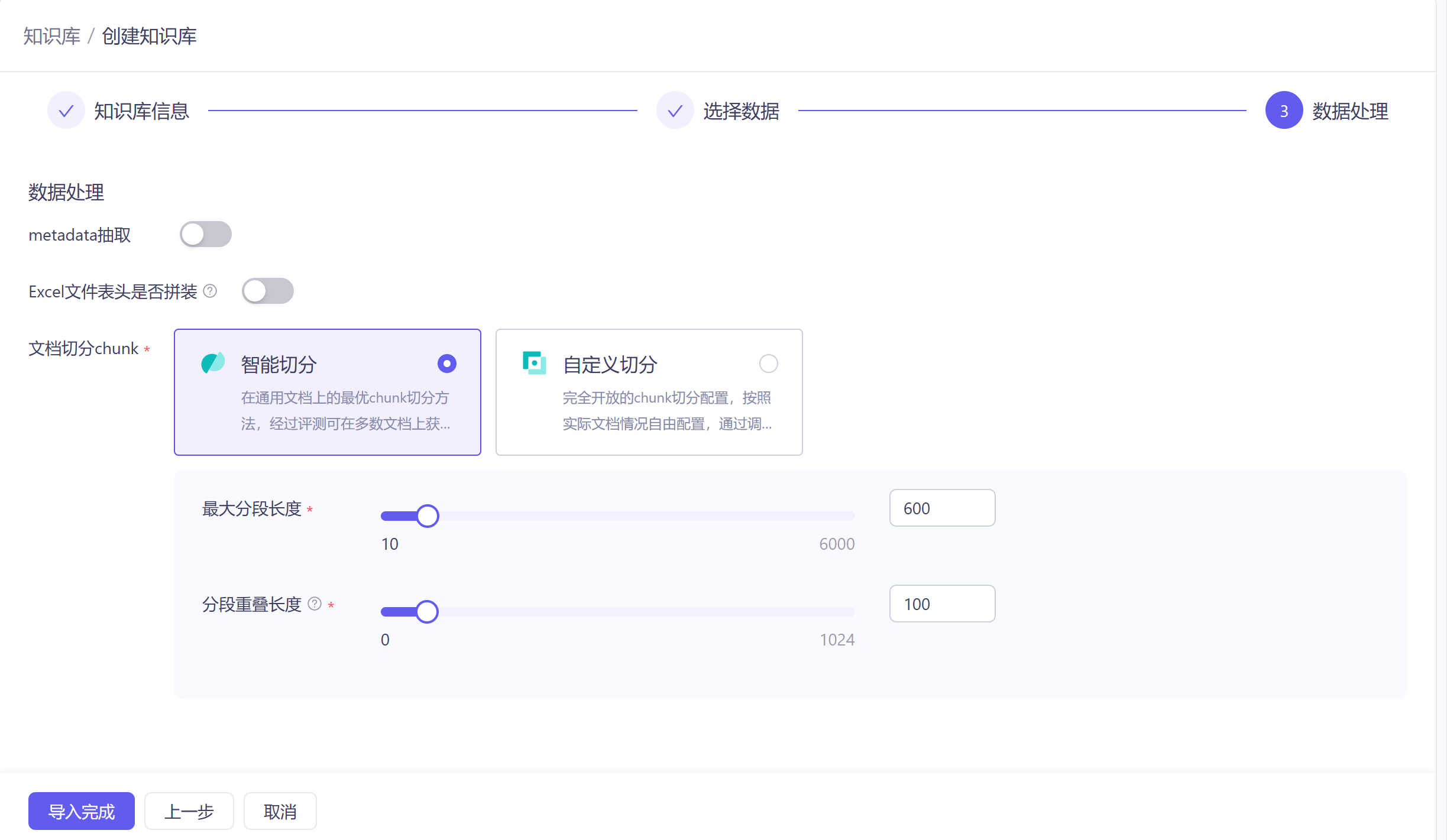
创建完毕后就可以进入知识库查看文档以及切片(如果分割不合理,可以手动编辑调整)
3.2 RAG 开发
接下来我们就可以通过程序的方式对接远程的云知识库了,我们可以参考 SpringAI Alibaba 的官方文档来学习:
SpringAI Alibaba 根据 Spring AI 当中的 DocumentRetrieval 特性自定义了一套检索规则,会自动从远程云知识库中调用灵积大模型 API 进行检索,而不再基于内存检索,下面就来实战一下:
1)步骤一:自定义 RetrievalAugmentationAdvisor
/*** 简历辅导大师云知识库配置类* @author ricejosn*/
@Configuration
public class ResumeAppRagCloudConfig {@Value("${spring.ai.dashscope.api-key}")private String dashScopeApiKey;@Beanpublic Advisor resumeAppCloudAdvisor() {// 创建APIDashScopeApi dashScopeApi = new DashScopeApi(dashScopeApiKey);// 自定义文档检索器final String KNOWLEDGE_NAME = "简历辅导大师";DashScopeDocumentRetriever documentRetriever = new DashScopeDocumentRetriever(dashScopeApi, DashScopeDocumentRetrieverOptions.builder()// 指定知识库名称.withIndexName(KNOWLEDGE_NAME).build());// 创建Advisorreturn new DocumentRetrievalAdvisor(documentRetriever);}
}
2)步骤二:引入 Advisor
@jakarta.annotation.Resource
private Advisor resumeAppCloudAdvisor;public String doChatWithCloudRag(String userPrompt, String chatId) {return chatClient.prompt().user(userPrompt).advisors((spec) -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))// 开启日志拦截器.advisors(new MyLoggerAdvisor())// 开启云知识问答RAG拦截器.advisors(resumeAppCloudAdvisor).call().content();
}
3)步骤三:执行测试
@Test
public void testDoChatWithCloudRag() {String chatId = UUID.randomUUID().toString();String content = resumeApp.doChatWithCloudRag("我是一名应届生,想应聘Java后端开发工程师,但是没有实习经历怎么办?", chatId);Assertions.assertNotNull(content);logger.info("content: {}", content);
}
程序运行效果如下图所示: