并查集(上)
1 并查集所包含的方法
int find(a); bool issameset(a,b); void union(a,b);
方法一:int find(a);这个表示是否可以找到这里集合的代表元素
方法二: bool issameset(a,b);这个是表示两个元素是否在一个集合
方法三:void union(a,b);这个表示把两个集合联合在一起
他们均摊的时间复杂度为O(1)
int find(a);
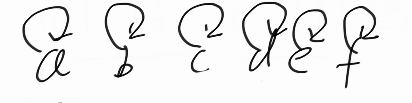
这个方法只需要寻找这个代表于元素是否为同一个,就代表这个两个元素在同一个集合里面,初始化就是把每一个元素进行自环
bool issameset(a,b);

这个方法表示为我们利用find方法找到这个最顶端的元素是否一样,一样就是在同一个集合里面
void union(a,b);

这个方法表示为,我们合并b和d这两个集合,然后直接把这个b挂到d这个代表元素u的下面
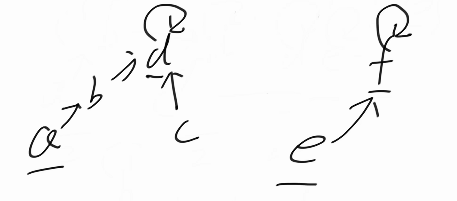
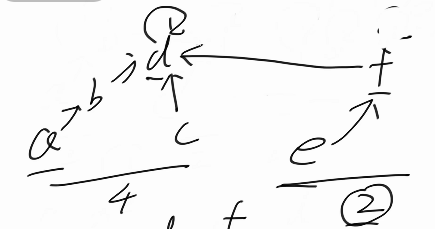
这里有一个优化,小的头去挂大的头把f挂到d的下面
2 样例展示方法

下面的数组下标表示每一个元素
0 1合并
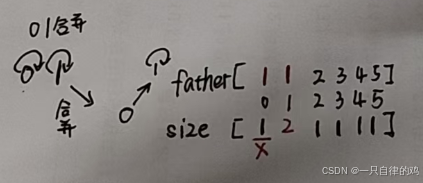
首先0的头部变成1了,但是1的头还是1,但是这个0的大小没有改变是因为这个已经没用了,用叉叉表示了,因为此时0不是头了,不再是代表数组
2 3合并
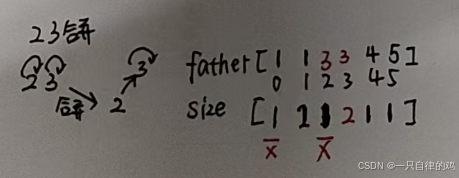
我们不难看到这个就是改变了头,这个3的头变成3了
4 5合并
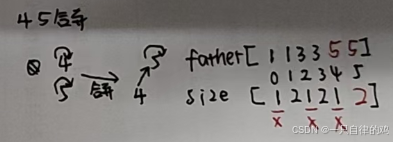
跟上述一样的
2 4合并
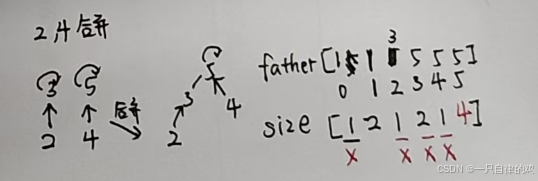
我们不难看出这个就是把这个对应不是代表值的,直接标记为垃圾值
改变对应的头和大小就好了
1 5合并

最后我们就可以得出这个了
扁平优化

当我们访问a的时候,再返回这个值的时候,所路过的点就直接指向X,这样就是扁平化,这样在下一次再次访问的时候,就可以直接以O(1)的时间复杂度来进行访问了

3 代码实现
#include<iostream>
using namespace std;
const int Max = 1000;
int father[Max];
int binsize[Max];
int binstack[Max];int find(int i) {//收集节点int size = 0;while (i != father[i]) {binstack[size++] = i;i = father[i];}//扁平化while (size > 0) {father[binstack[--size]] = i;}return i;
}bool issameset(int a, int b) {return find(a) == find(b);
}void binunion(int x) {//fx 代表大小 fy 代表大小int fx = find(x);int fy = find(x);if (binsize[fx] >= binsize[fy]) {binsize[fx] += binsize[fy];father[fy] = fx;}else {binsize[fy] += binsize[fx];father[fx] = fy;}
}int main() {}
1 int find(a);
这个就是寻找每一个元素在这个集合的代表元素,返回father数组里面的元素
2 bool issameset(a,b);
这个就是判断两个元素是否在同一个集合里面
3 void union(a,b);
这个就是把带有两个元素的集合进行合并,然后就是改变father数组里面的数字还有就是改变对应的大小,然后另外一个被合并的的size数组里面的数字进行改变
#include<iostream>
using namespace std;
int n;
const int MAX = 100;
int father[MAX];void build() {for (int i = 0; i <= n;i++) {father[i] = i;}
}int find(int i) {if (i != father[i]) {father[i] = find(father[i]);}return father[i];
}bool issameset(int x, int y) {return find(x) == find(y);
}void binunion(int x, int y) {father[find(x)] = find(y);
}int main() {}这个相比上面的那个代码没有大挂小的写法,栈是利用递归的方式进行书写的
int find(int i) {if (i != father[i]) {father[i] = find(father[i]);}return father[i];
}
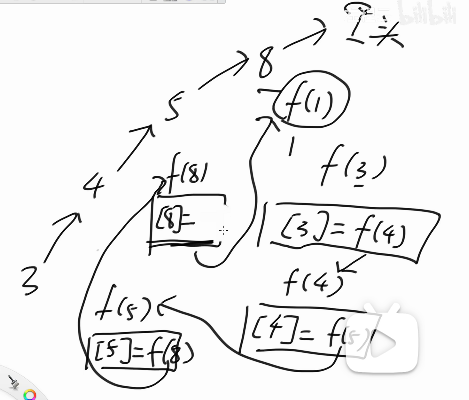
这个表示利用递归表示栈的过程,然后就是把那个小挂大的给删除了,不利用这个,一般都是扁平化的时候直接就是直接把后面放到第一个