DAY 36 超大力王爱学Python
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。
- 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。
- 探索性作业(随意完成):尝试进入nn.Module中,查看他的方法
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt# 设置随机种子,保证结果可复现
torch.manual_seed(42)
np.random.seed(42)# 数据加载与预处理
def load_and_preprocess_data():# 加载数据try:data = pd.read_csv('D:\代码\项目一信贷风险预测\data.csv')except:# 如果路径错误,使用模拟数据演示print("无法加载数据,使用模拟数据...")data = pd.DataFrame({'Home Ownership': np.random.choice(['Rent', 'Own Home', 'Home Mortgage'], 1000),'Annual Income': np.random.normal(50000, 20000, 1000),'Years in current job': np.random.choice(['1 year', '2 years', '3 years', '4 years', '5 years', '10+ years'], 1000),'Tax Liens': np.random.randint(0, 3, 1000),'Number of Open Accounts': np.random.randint(1, 20, 1000),'Years of Credit History': np.random.normal(10, 5, 1000),'Maximum Open Credit': np.random.normal(50000, 30000, 1000),'Number of Credit Problems': np.random.randint(0, 5, 1000),'Months since last delinquent': np.random.normal(20, 15, 1000),'Bankruptcies': np.random.randint(0, 3, 1000),'Purpose': np.random.choice(['debt consolidation', 'home improvements', 'buy a car', 'medical bills', 'small business'], 1000),'Term': np.random.choice(['Short Term', 'Long Term'], 1000),'Current Loan Amount': np.random.normal(20000, 15000, 1000),'Current Credit Balance': np.random.normal(15000, 10000, 1000),'Monthly Debt': np.random.normal(2000, 1000, 1000),'Credit Score': np.random.normal(700, 100, 1000),'Credit Default': np.random.binomial(1, 0.3, 1000)})# 处理缺失值data['Annual Income'] = data['Annual Income'].fillna(data['Annual Income'].mean())data['Years in current job'] = data['Years in current job'].fillna(data['Years in current job'].mode()[0])data['Months since last delinquent'] = data['Months since last delinquent'].fillna(data['Months since last delinquent'].mean())data['Bankruptcies'] = data['Bankruptcies'].fillna(data['Bankruptcies'].mean())data['Credit Score'] = data['Credit Score'].fillna(data['Credit Score'].mean())# 对类别变量进行编码label_encoders = {}categorical_columns = ['Home Ownership', 'Years in current job', 'Purpose', 'Term']for col in categorical_columns:le = LabelEncoder()data[col] = le.fit_transform(data[col])label_encoders[col] = lereturn data# 数据加载与预处理
data = load_and_preprocess_data()# 划分特征和目标变量
X = data.drop(['Id', 'Credit Default'], axis=1).values if 'Id' in data.columns else data.drop(['Credit Default'], axis=1).values
y = data['Credit Default'].values# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为 PyTorch 张量
X_train = torch.FloatTensor(X_train)
y_train = torch.FloatTensor(y_train).unsqueeze(1)
X_test = torch.FloatTensor(X_test)
y_test = torch.FloatTensor(y_test).unsqueeze(1)# 定义神经网络模型
class CreditNet(nn.Module):def __init__(self, input_size=16):super(CreditNet, self).__init__()self.fc1 = nn.Linear(input_size, 64)self.relu = nn.ReLU()self.fc2 = nn.Linear(64, 32)self.dropout = nn.Dropout(0.2) # 添加Dropout防止过拟合self.fc3 = nn.Linear(32, 16)self.fc4 = nn.Linear(16, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)out = self.relu(out)out = self.dropout(out) # 应用Dropoutout = self.fc3(out)out = self.relu(out)out = self.fc4(out)out = self.sigmoid(out)return out# 实例化模型、定义损失函数和优化器
model = CreditNet(input_size=X_train.shape[1])
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 100
train_losses = []print("开始训练模型...")
for epoch in tqdm(range(num_epochs), desc="训练进度"):optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()train_losses.append(loss.item())# 每10个epoch打印一次损失if (epoch + 1) % 10 == 0:tqdm.write(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 可视化训练损失
plt.figure(figsize=(10, 6))
plt.plot(range(1, num_epochs + 1), train_losses)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.show()# 在测试集上评估模型
model.eval()
with torch.no_grad():outputs = model(X_test)predicted_probs = outputs.numpy().flatten()predicted = (predicted_probs > 0.5).astype(int)y_test_np = y_test.numpy().flatten()# 计算准确率accuracy = np.mean(predicted == y_test_np)print(f'\nAccuracy: {accuracy * 100:.2f}%')# 计算AUCtry:auc = roc_auc_score(y_test_np, predicted_probs)print(f'AUC: {auc:.4f}')except:print("无法计算AUC(可能只有一类样本)")# 混淆矩阵cm = confusion_matrix(y_test_np, predicted)print("\nConfusion Matrix:")print(cm)# 分类报告print("\nClassification Report:")print(classification_report(y_test_np, predicted, target_names=['非违约', '违约']))
开始训练模型...
训练进度: 39%|███▉ | 39/100 [00:00<00:00, 382.36it/s]
Epoch [10/100], Loss: 0.6428
Epoch [20/100], Loss: 0.6112
Epoch [30/100], Loss: 0.5762
Epoch [40/100], Loss: 0.5473
Epoch [50/100], Loss: 0.5242
Epoch [60/100], Loss: 0.5083
训练进度: 39%|███▉ | 39/100 [00:00<00:00, 382.36it/s]
Epoch [70/100], Loss: 0.4941
训练进度: 100%|██████████| 100/100 [00:00<00:00, 320.51it/s]
Epoch [80/100], Loss: 0.4845
Epoch [90/100], Loss: 0.4759
Epoch [100/100], Loss: 0.4705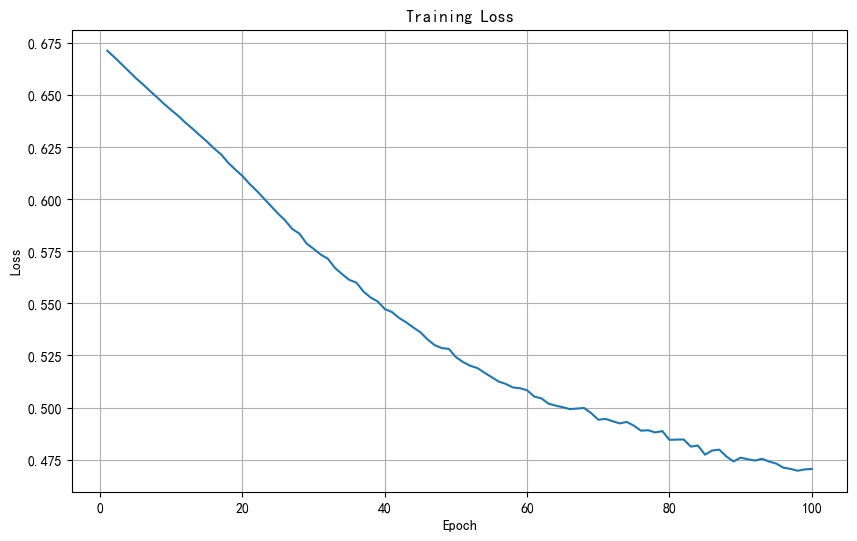
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import roc_auc_score, classification_report
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt# 设置中文字体为黑体(SimHei)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
# 设置随机种子,保证结果可复现
torch.manual_seed(42)
np.random.seed(42)# 加载和预处理数据
def load_and_preprocess_data():try:data = pd.read_csv('D:\代码\项目一信贷风险预测\data.csv')except:print("无法加载数据,使用模拟数据...")data = pd.DataFrame({'Home Ownership': np.random.choice(['Rent', 'Own Home', 'Home Mortgage'], 1000),'Annual Income': np.random.normal(50000, 20000, 1000),'Years in current job': np.random.choice(['1 year', '2 years', '3 years', '4 years', '5 years', '10+ years'], 1000),'Tax Liens': np.random.randint(0, 3, 1000),'Number of Open Accounts': np.random.randint(1, 20, 1000),'Years of Credit History': np.random.normal(10, 5, 1000),'Maximum Open Credit': np.random.normal(50000, 30000, 1000),'Number of Credit Problems': np.random.randint(0, 5, 1000),'Months since last delinquent': np.random.normal(20, 15, 1000),'Bankruptcies': np.random.randint(0, 3, 1000),'Purpose': np.random.choice(['debt consolidation', 'home improvements', 'buy a car', 'medical bills', 'small business'], 1000),'Term': np.random.choice(['Short Term', 'Long Term'], 1000),'Current Loan Amount': np.random.normal(20000, 15000, 1000),'Current Credit Balance': np.random.normal(15000, 10000, 1000),'Monthly Debt': np.random.normal(2000, 1000, 1000),'Credit Score': np.random.normal(700, 100, 1000),'Credit Default': np.random.binomial(1, 0.3, 1000)})# 处理缺失值data['Annual Income'] = data['Annual Income'].fillna(data['Annual Income'].mean())data['Years in current job'] = data['Years in current job'].fillna(data['Years in current job'].mode()[0])data['Months since last delinquent'] = data['Months since last delinquent'].fillna(data['Months since last delinquent'].mean())data['Bankruptcies'] = data['Bankruptcies'].fillna(data['Bankruptcies'].mean())data['Credit Score'] = data['Credit Score'].fillna(data['Credit Score'].mean())# 对类别变量进行编码label_encoders = {}categorical_columns = ['Home Ownership', 'Years in current job', 'Purpose', 'Term']for col in categorical_columns:le = LabelEncoder()data[col] = le.fit_transform(data[col])label_encoders[col] = lereturn datadata = load_and_preprocess_data()# 划分特征和目标变量
X = data.drop(['Id', 'Credit Default'], axis=1).values if 'Id' in data.columns else data.drop(['Credit Default'], axis=1).values
y = data['Credit Default'].values# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 转换为PyTorch张量
X_train = torch.FloatTensor(X_train)
y_train = torch.FloatTensor(y_train).unsqueeze(1)
X_test = torch.FloatTensor(X_test)
y_test = torch.FloatTensor(y_test).unsqueeze(1)# 定义不同配置的模型
class ModelConfig1(nn.Module):"""浅网络 + ReLU"""def __init__(self, input_size=16):super().__init__()self.layers = nn.Sequential(nn.Linear(input_size, 32),nn.ReLU(),nn.Linear(32, 1),nn.Sigmoid())def forward(self, x):return self.layers(x)class ModelConfig2(nn.Module):"""深网络 + ReLU"""def __init__(self, input_size=16):super().__init__()self.layers = nn.Sequential(nn.Linear(input_size, 64),nn.ReLU(),nn.Linear(64, 32),nn.ReLU(),nn.Linear(32, 16),nn.ReLU(),nn.Linear(16, 1),nn.Sigmoid())def forward(self, x):return self.layers(x)class ModelConfig3(nn.Module):"""深网络 + ReLU + Dropout"""def __init__(self, input_size=16):super().__init__()self.layers = nn.Sequential(nn.Linear(input_size, 64),nn.ReLU(),nn.Dropout(0.3),nn.Linear(64, 32),nn.ReLU(),nn.Dropout(0.3),nn.Linear(32, 16),nn.ReLU(),nn.Linear(16, 1),nn.Sigmoid())def forward(self, x):return self.layers(x)class ModelConfig4(nn.Module):"""深网络 + LeakyReLU + BatchNorm"""def __init__(self, input_size=16):super().__init__()self.layers = nn.Sequential(nn.Linear(input_size, 64),nn.BatchNorm1d(64),nn.LeakyReLU(0.1),nn.Linear(64, 32),nn.BatchNorm1d(32),nn.LeakyReLU(0.1),nn.Linear(32, 16),nn.BatchNorm1d(16),nn.LeakyReLU(0.1),nn.Linear(16, 1),nn.Sigmoid())def forward(self, x):return self.layers(x)# 训练和评估函数
def train_and_evaluate(model_class, optimizer_class, lr=0.001, epochs=50):model = model_class(input_size=X_train.shape[1])criterion = nn.BCELoss()optimizer = optimizer_class(model.parameters(), lr=lr)train_losses = []test_aucs = []for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()train_losses.append(loss.item())# 每5个epoch评估一次if (epoch + 1) % 5 == 0:model.eval()with torch.no_grad():test_outputs = model(X_test)try:auc = roc_auc_score(y_test.numpy(), test_outputs.numpy())test_aucs.append(auc)except:test_aucs.append(0)# 最终评估model.eval()with torch.no_grad():test_outputs = model(X_test)test_preds = (test_outputs > 0.5).float()accuracy = (test_preds == y_test).sum().item() / y_test.size(0)try:final_auc = roc_auc_score(y_test.numpy(), test_outputs.numpy())except:final_auc = 0return {'train_losses': train_losses,'test_aucs': test_aucs,'accuracy': accuracy,'auc': final_auc,'model': model}# 超参数配置
configs = [{'model_class': ModelConfig1, 'optimizer': optim.Adam, 'lr': 0.001, 'name': '浅网络+Adam'},{'model_class': ModelConfig2, 'optimizer': optim.Adam, 'lr': 0.001, 'name': '深网络+Adam'},{'model_class': ModelConfig3, 'optimizer': optim.Adam, 'lr': 0.001, 'name': '深网络+Dropout+Adam'},{'model_class': ModelConfig4, 'optimizer': optim.Adam, 'lr': 0.001, 'name': '深网络+BN+LeakyReLU+Adam'},{'model_class': ModelConfig4, 'optimizer': optim.SGD, 'lr': 0.01, 'name': '深网络+BN+LeakyReLU+SGD'},
]# 运行所有配置
results = {}
for config in configs:print(f"\n训练配置: {config['name']}")result = train_and_evaluate(config['model_class'], config['optimizer'], config['lr'],epochs=50)results[config['name']] = resultprint(f"最终准确率: {result['accuracy']*100:.2f}% | AUC: {result['auc']:.4f}")# 可视化训练损失
plt.figure(figsize=(12, 6))
for name, result in results.items():plt.plot(result['train_losses'], label=name)
plt.title('不同配置的训练损失对比')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.show()# 可视化测试AUC
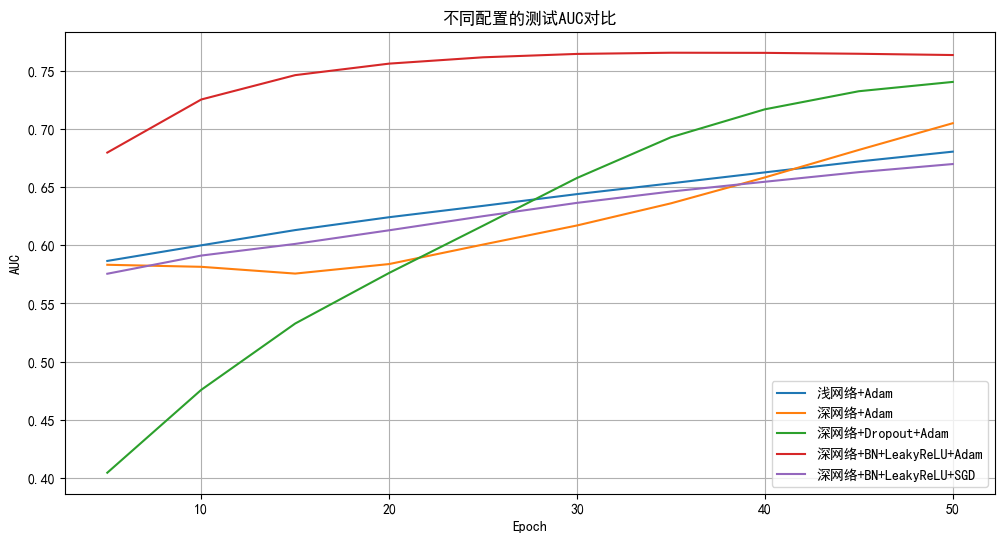
plt.figure(figsize=(12, 6))
x_ticks = [i for i in range(5, 51, 5)]
for name, result in results.items():plt.plot(x_ticks, result['test_aucs'], label=name)
plt.title('不同配置的测试AUC对比')
plt.xlabel('Epoch')
plt.ylabel('AUC')
plt.legend()
plt.grid(True)
plt.show()# 对比最终结果
print("\n最终结果对比:")
for name, result in results.items():print(f"{name}: 准确率={result['accuracy']*100:.2f}%, AUC={result['auc']:.4f}")最终结果对比:
浅网络+Adam: 准确率=72.33%, AUC=0.6804
深网络+Adam: 准确率=74.73%, AUC=0.7048
深网络+Dropout+Adam: 准确率=70.60%, AUC=0.7402
深网络+BN+LeakyReLU+Adam: 准确率=76.53%, AUC=0.7633
深网络+BN+LeakyReLU+SGD: 准确率=71.53%, AUC=0.6697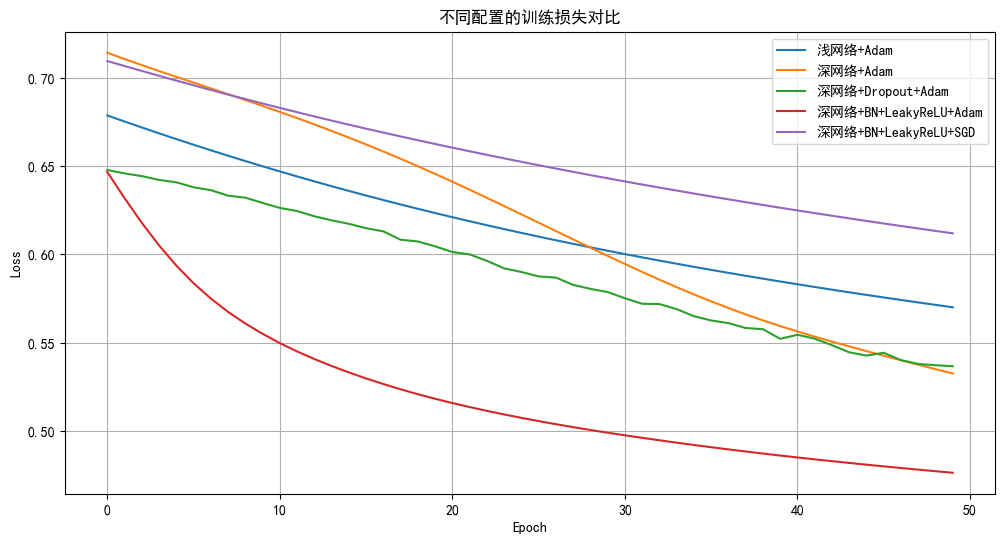
@浙大疏锦行