LLM优化技术——Paged Attention
在Transformer decoding的过程中,需要存储过去tokens的所有Keys和Values,以完成self attention的计算,称之为KV cache。
(1)KV cache的大小
可以计算存储KV cache所需的内存大小:
batch * layers * kv-heads * n_emd * length * 2(K & V) * bytes
对于Llama-2-70B(MHA),KV cache需要的内存大小为:
batch * 80 * 64 * 128 * N * 2 * 2(FP16) = 2.5 MB * BS * N

(2)KV cache中存在内存浪费
-
内部碎片化 (Internal Fragmentation): 由于输出长度未知而过度分配内存。
-
预留 (Reservation): 当前步骤未使用,但未来步骤需要的内存。
-
外部碎片化 (External Fragmentation): 由于不同请求序列长度不同导致的内存空隙。
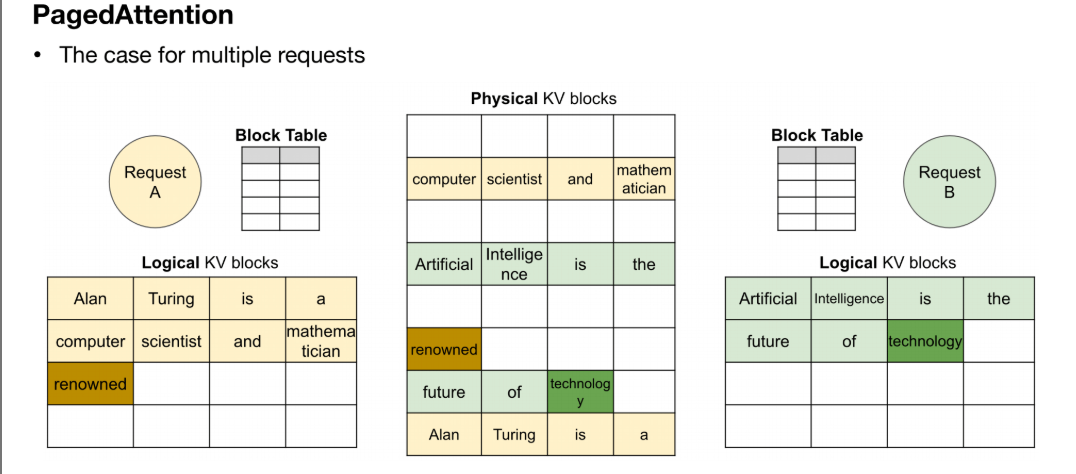
(3)Paged Attention
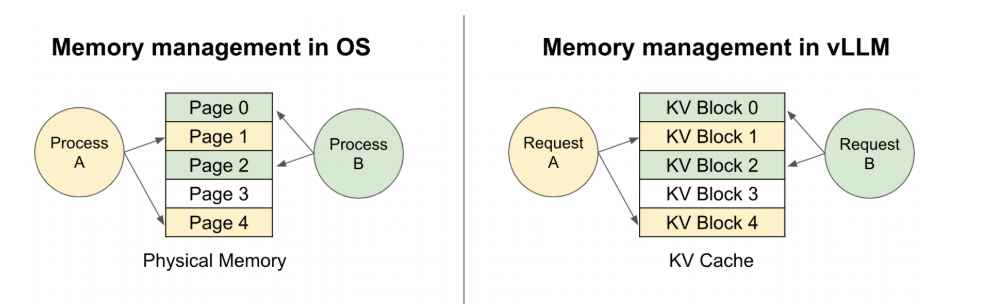
在不连续的内存空间中存储连续的keys和values