生成式AI模型学习笔记
文章目录
- 生成式AI模型
- 1. 定义
- 2. 生成式模型与判别式模型
- 3. 深度生成式模型的类型
- 3.1 能量模型
- 3.2 变分自编码
- 3.2.1 变分自编码器(Variational Autoencoder, VAE)简介
- 3.2.2 代码示例(以 PyTorch 为例)
- 3.3 生成对抗网络
- 3.4 流模型
- 3.4.1 流模型简介
- 3.4.2 NICE:开创性流模型
- 3.4.3 流模型与 VAE、GAN 的区别
- 3.5 自回归模型
- 3.5.1 自回归模型简介
- 3.5.2 与 GAN 的对比
- 3.5.3 优缺点
- 3.6 扩散模型
- 3.6.1 扩散模型简介
- 3.6.2 模型优缺点
- 优点
- 缺点
- 3.6.3 主要应用领域
- 3.7 一致性模型
- 3.7.1 一致性模型简介
- 3.7.2 主要特点
- 3.7.3 推理速度与训练成本
- 4. 总结
生成式AI模型
深度生成式模型有多种类型,可用于生成不同类型的媒体内容,包括图像、视频、文本和音频。除了这些媒体类型外,模型还可以用于生成特定领域的数据,比如有机分子和蛋白质结构。
1. 定义
生成式模型是一类能够根据输入数据学习其分布,并能够生成与原始数据相似新样本的模型。在机器学习和人工智能领域,生成式模型不仅可以对数据进行建模,还能用于数据生成、增强、补全等任务。常见的生成式模型包括生成对抗网络(GAN)、变分自编码器(VAE)和扩散模型等。
2. 生成式模型与判别式模型
生成式模型试图学习数据的联合概率分布 P ( x , y ) P(x, y) P(x,y),不仅能够判断输入属于哪个类别,还能生成与训练数据相似的新样本。它们可以用于数据生成、缺失值填补等任务。
判别式模型则关注于学习条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x),直接建模输入与输出之间的映射关系,主要用于分类或回归等判别任务,无法生成新样本。
| 特点 | 生成式模型 | 判别式模型 |
|---|---|---|
| 学习目标 | 联合概率分布 P ( x , y ) P(x, y) P(x,y) | 条件概率分布 $P(y |
| 主要任务 | 数据生成、建模 | 分类、回归 |
| 能否生成数据 | 可以生成新样本 | 不能生成新样本 |
| 代表模型 | GAN、VAE、朴素贝叶斯等 | 逻辑回归、SVM、决策树等 |
| 复杂性 | 通常更复杂 | 相对简单 |
| 训练难度 | 较高 | 较低 |
3. 深度生成式模型的类型
谈及深度生成式模型或深度生成式AI时,我们常宽泛地将此定义扩展到所有能生成逼真数据(通常是文本、图像、视频和声音)的模型上。
3.1 能量模型
能量模型(Energy-Based Model, EBM)是一类通过定义能量函数 E ( x ) E(x) E(x) 或 E ( x , y ) E(x, y) E(x,y) 来对数据建模的生成式模型。能量函数用于衡量某个样本(或样本-标签对)的“合理性”或“可能性”,能量越低表示样本越可能来自真实数据分布。
能量模型的目标是学习一个能量函数,使得真实数据样本具有较低的能量,而非真实样本具有较高的能量。通过对能量函数的优化,模型能够区分真实数据与噪声数据,并可用于生成新样本、异常检测等任务。常见的能量模型包括玻尔兹曼机(Boltzmann Machine)、深度玻尔兹曼机(Deep Boltzmann machine, DBM)、受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)等。
下图是一个四层玻尔兹曼机,有三层隐藏节点:
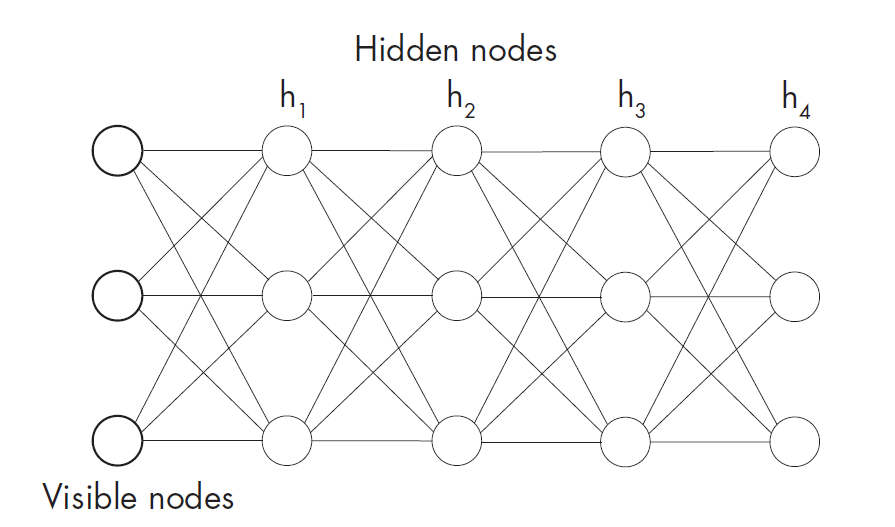
DBM 作为早期的深度生成式模型之一,在历史上扮演过重要角色,但如今在数据生成方面已经不那么流行。它的训练成本较高且较为复杂,与下文即将介绍的一些更新的模型相比,其表单能力相对较弱,容易导致生成样本的质量较低。
3.2 变分自编码
3.2.1 变分自编码器(Variational Autoencoder, VAE)简介
变分自编码器是一种基于概率图模型的生成式模型,通过引入潜在变量 z z z,对数据分布进行建模。VAE 由编码器(Encoder)和解码器(Decoder)两部分组成:编码器将输入数据 x x x 映射到潜在空间 z z z 的分布,解码器则从 z z z 生成新的数据样本 x ′ x' x′。
VAE 的核心思想是最大化观测数据的似然概率,同时通过变分推断近似后验分布。其损失函数通常包括重构误差和 KL 散度两部分。
3.2.2 代码示例(以 PyTorch 为例)
import torch
from torch import nnclass VAE(nn.Module):def __init__(self, input_dim, hidden_dim, latent_dim):super(VAE, self).__init__()# 编码器self.encoder = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU())self.fc_mu = nn.Linear(hidden_dim, latent_dim)self.fc_logvar = nn.Linear(hidden_dim, latent_dim)# 解码器self.decoder = nn.Sequential(nn.Linear(latent_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, input_dim),nn.Sigmoid())def encode(self, x):h = self.encoder(x)return self.fc_mu(h), self.fc_logvar(h)def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):return self.decoder(z)def forward(self, x):mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvar
该代码实现了一个简单的 VAE,包括编码、重参数化和解码过程。实际训练时,损失函数通常为重构误差与 KL 散度之和。
3.3 生成对抗网络
生成对抗网络(Generative Adversarial Network, GAN)简介:
生成对抗网络(GAN)是一类通过对抗过程进行训练的生成式模型,由 Ian Goodfellow 等人在 2014 年提出。GAN 由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是生成尽可能以假乱真的数据样本,而判别器的目标是区分输入是真实数据还是生成器生成的假数据。两者在训练过程中相互博弈,最终生成器能够生成与真实数据分布非常接近的新样本。
组成结构:
- 生成器(G): 接收随机噪声向量,输出伪造的数据样本。
- 判别器(D): 接收真实样本或生成样本,输出其为真实的概率。
训练目标是使生成器生成的数据能够“骗过”判别器,而判别器则努力分辨真假。整个过程可用极小极大博弈(minimax game)来描述。
优点:
- 能生成高质量、逼真的样本(如图像、音频等)。
- 不需要显式建模数据的概率分布。
- 在图像生成、风格迁移、超分辨率等领域表现突出。
缺点:
- 训练过程不稳定,容易出现模式崩溃(mode collapse)等问题。
- 需要精心设计网络结构和训练策略。
- 难以衡量生成样本的多样性和质量。
GAN 及其变体已成为生成式模型领域的重要研究方向,推动了深度生成模型的发展。
3.4 流模型
3.4.1 流模型简介
流模型(Flow-based Model)是一类通过可逆变换将简单分布(如高斯分布)映射到复杂数据分布的生成式模型。其核心思想是构建一系列可逆的变换函数,使得每一步变换都可以精确计算其雅可比行列式,从而能够直接对数据的似然概率进行精确建模和高效采样。
流模型的训练目标是最大化观测数据的对数似然(log-likelihood),与 VAE 类似,但流模型能够直接、精确地计算似然值,无需近似推断。
3.4.2 NICE:开创性流模型
NICE(Non-linear Independent Components Estimation,非线性独立分量估计)是流模型领域的开创性工作之一,由 Dinh 等人在 2014 年提出。NICE 采用一系列可逆的仿射变换,将数据从复杂分布映射到简单分布(如标准正态分布),并且每一步变换都保证可逆和雅可比行列式易于计算。NICE 的提出为后续更复杂的流模型(如 RealNVP、Glow)奠定了基础。
3.4.3 流模型与 VAE、GAN 的区别
- 生成方式不同:流模型通过可逆变换直接从噪声生成数据,且生成过程是确定性的;VAE 通过采样潜变量再解码生成数据,GAN 则通过生成器网络生成数据。
- 似然计算:流模型可以精确计算数据的对数似然,VAE 只能近似计算,GAN 通常无法直接计算似然。
- 训练目标:流模型和 VAE 都以最大化似然为目标,GAN 采用对抗训练目标。
- 样本质量与多样性:GAN 通常生成样本质量较高但训练不稳定,流模型生成样本质量略逊但训练稳定且易于解释。
流模型因其可逆性和精确似然计算的特性,在密度估计、可解释性和无损压缩等任务中具有独特优势。
3.5 自回归模型
3.5.1 自回归模型简介
自回归模型(Autoregressive Model)是一类通过将数据的每个元素建模为前面元素的条件概率来生成数据的生成式模型。其核心思想是将高维数据的联合分布分解为一系列有序的条件分布。例如,对于序列 x = ( x 1 , x 2 , . . . , x n ) x = (x_1, x_2, ..., x_n) x=(x1,x2,...,xn),自回归模型将其联合概率分布分解为:
P ( x ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) ⋯ P ( x n ∣ x 1 , . . . , x n − 1 ) P(x) = P(x_1)P(x_2|x_1)P(x_3|x_1, x_2)\cdots P(x_n|x_1, ..., x_{n-1}) P(x)=P(x1)P(x2∣x1)P(x3∣x1,x2)⋯P(xn∣x1,...,xn−1)
常见的自回归模型包括:PixelRNN、PixelCNN(用于图像生成)、WaveNet(用于音频生成)、Transformer(用于文本生成)等。
3.5.2 与 GAN 的对比
- 生成方式:自回归模型按顺序逐步生成每个元素,每一步依赖于前面已生成的内容;GAN 则通过生成器一次性生成完整样本。
- 训练目标:自回归模型直接最大化数据的似然概率(log-likelihood);GAN 采用对抗训练目标,不直接优化似然。
- 采样速度:自回归模型生成速度较慢(需逐步生成),GAN 生成速度快(可并行)。
- 样本质量:GAN 通常能生成更高质量的样本,但训练不稳定;自回归模型训练稳定,生成样本多样性好,但可能缺乏全局一致性。
3.5.3 优缺点
优点:
- 训练过程稳定,易于收敛,训练难度低。
- 能精确计算数据的似然概率,便于模型评估。
- 生成样本多样性好,适用于序列建模(如文本、音频)。
缺点:
- 生成速度慢,难以并行化(尤其是长序列或高维数据)。
- 可能难以捕捉全局结构,生成的样本有时缺乏整体一致性。
自回归模型因其稳定性和可解释性,在自然语言处理、音频建模等领域应用广泛。
3.6 扩散模型
3.6.1 扩散模型简介
扩散模型(Diffusion Model)是一类基于概率扩散过程的生成式模型。其核心思想是将数据逐步添加噪声,直到变为纯噪声,然后训练一个神经网络学会逐步去噪,逆向还原出原始数据。训练过程中,模型学习如何从噪声中一步步恢复出真实样本。常见的扩散模型包括 DDPM(Denoising Diffusion Probabilistic Model)等。
3.6.2 模型优缺点
优点
- 能生成高质量、高分辨率的样本,尤其在图像生成领域表现突出。
- 训练过程稳定,不易出现模式崩溃(mode collapse)等问题。
- 理论基础扎实,易于解释和分析。
缺点
- 采样速度较慢,需要多步迭代去噪才能生成样本。
- 对计算资源要求较高,训练和推理成本大。
3.6.3 主要应用领域
- 图像生成与编辑(如文本到图像生成、图像修复、超分辨率等)
- 音频生成(如语音合成、音乐生成)
- 分子结构生成、医学影像等科学领域
扩散模型已成为当前生成式模型研究和应用的热点,推动了生成式 AI 在多个领域的进步。
3.7 一致性模型
3.7.1 一致性模型简介
一致性模型(Consistency Model, CM)是一类新兴的生成式模型,旨在结合扩散模型的高生成质量与更快的采样速度。其核心思想是通过一致性正则化训练神经网络,使模型在不同噪声水平下生成的样本保持一致,从而实现一步或少步采样即可生成高质量样本。
3.7.2 主要特点
- 高效采样:一致性模型能够在极少的采样步数(甚至一步)内生成高质量样本,大幅提升推理速度。
- 高生成质量:在图像等任务上,生成样本的质量接近甚至优于传统扩散模型。
- 训练方式灵活:可与扩散模型等已有生成模型结合,作为蒸馏或加速模块使用。
3.7.3 推理速度与训练成本
- 推理速度:一致性模型的推理速度远快于传统扩散模型,通常只需一步或少数几步采样,适合对实时性要求高的应用场景。
- 训练成本:训练成本与扩散模型相当,甚至略高,因为需要在不同噪声水平下进行一致性约束,以图像生成为例,需要包含大量成对的含噪声图像与清晰图像的数据集。但训练过程稳定,易于收敛。
一致性模型为生成式 AI 带来了高效推理与高质量生成的平衡,成为当前生成模型领域的重要研究方向之一。
4. 总结
本文系统梳理了主流深度生成式模型的类型及其特点,包括能量模型、变分自编码器(VAE)、生成对抗网络(GAN)、流模型、自回归模型、扩散模型和一致性模型。各类模型在生成方式、训练目标、样本质量、采样速度等方面各有优劣。能量模型和 VAE 以概率建模为核心,GAN 通过对抗训练生成高质量样本,流模型强调可逆性和精确似然计算,自回归模型适合序列建模,扩散模型和一致性模型则在高质量生成和高效采样之间取得平衡。生成式模型已广泛应用于图像、文本、音频等领域,并持续推动 AI 技术进步。