qwen3解读
1. 模型架构
重点:
- 思维模式和非思维模式这两种不同的操作模式集成到一个模型中。这样可以让用户在这些模式间切换,而不是在不同模型间切换。
- 多阶段的后培训方法:增强推理和非推理模式。将基础模型和人的偏好结合。

预训练阶段:
- 通用知识学习:通过大规模数据训练模型理解语言结构、常识和通用知识,为后续阶段奠定基础。
- 推理能力强化:引入知识密集型数据(如专业领域文本、高质量合成数据),强化模型对复杂推理任务的适应性。
- 长上下文扩展:通过特定优化技术(动态位置编码 (YARN)、高效注意力机制 (DCA、稀疏注意力))提升模型对长序列的处理效率,并结合人工清洗与合成数据进一步强化能力。
位置编码调整:动态扩展与长度外推
技术原理 :传统位置编码(如绝对位置编码)在预训练时固定上下文长度,难以直接扩展到更长序列。Qwen3 采用 动态位置编码调整技术 (如 YARN),允许模型在推理时动态扩展上下文长度。
实现方式 :
在训练阶段,通过 长度外推 (Length Extrapolation)技术,使模型能够适应远超训练数据长度的上下文(例如从 32,768 token 推理时扩展至 128K token)。
使用 相对位置编码 或 旋转位置编码 (RoPE)等策略,增强模型对长序列位置信息的敏感性 。
注意力机制改进:降低计算复杂度
长序列处理的核心挑战是注意力机制的计算复杂度呈平方级增长(O(n²)),Qwen3 通过以下技术优化:
双块注意力(Dual Chunk Attention, DCA) :
将长序列划分为多个固定长度的“块”(Chunk),在块内计算局部注意力,块间则通过稀疏或跨块注意力减少计算量。 例如,对 32,768 token 的长上下文,模型可能先分块处理局部信息,再通过全局注意力聚合关键信息 。
稀疏注意力(Sparse Attention) :
通过稀疏化注意力矩阵(如仅关注关键位置或固定跨度的位置),大幅降低内存占用和计算成本 。
结合自适应带宽注意力 (Adaptive Bandwidth Attention, ABF),动态调整注意力覆盖的上下文范围,避免冗余计算 。
后训练阶段:
目标:

后训练流程:
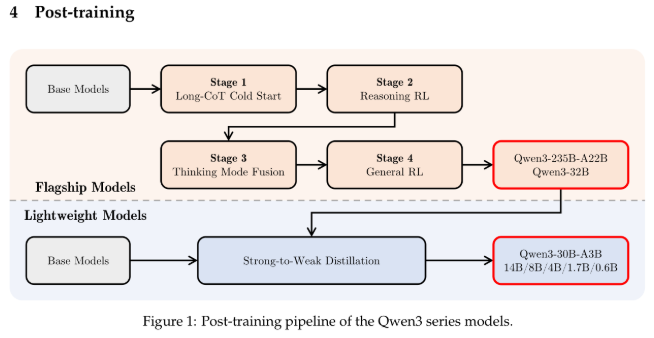
- 长思维链冷启动:构建高质量推理骨架。
使用 QwQ-32B (Qwen3的子模型)生成高质量的长思维链示例(Chain-of-Thought, CoT),覆盖数学、代码、逻辑推理等场景 。
结合人工清洗数据 (Qwen-72B标注的高质量推理样本),过滤错误推理路径。 - 推理强化学习:优化多步骤任务的连贯性。
基于 强化学习 (Reinforcement Learning, RL)框架,利用奖励模型(Reward Model)对生成的推理路径进行评估和反馈 。采用 GRPO 更新模型参数。
参考解读文章:Qwen3模型架构、训练方法梳理
重点强化数学、代码等领域的推理能力,确保多步骤任务的连贯性 - 思维模式融合:统一深度与快速模式。
混合训练 :在训练数据中混合长思维链(深度模式)和直接响应(快速模式)样本 。
用户控制机制 :通过指令(如 /think 或 /no think)动态切换模式 。 - 通用强化学习:对齐人类偏好并提升效率。
监督微调 (SFT):使用人工标注的指令-响应数据,训练模型遵循用户指令 。
人类反馈强化学习 (RLHF):通过大规模偏好数据优化生成结果,减少冗余输出 。
2. 训练数据量
数据总量比Qwen2.5翻了一倍,支持的语言种类更是增加了两倍多。

3. 性能表现
Qwen3 通过参数精简、架构创新和高效训练 ,实现了“小参数,高性能”的目标。其 MoE 模型 Qwen3-30B-A3B 的激活参数量仅为竞品的 10%,但性能更优;而 Dense 模型 Qwen3-1.7B 的参数量仅为 DeepSeek-R1 的 1/3,性能却与之相当 。
这种高效性使其在端侧部署、多语言任务及长文本处理中具有显著优势。