分析XSSstrike源码
#用于学习web安全自动化工具#
我能收获什么?
1.XSS漏洞检测机制
- 学习如何构造和发送XSS payload
- 如何识别响应中的回显,WAF,过滤规则等
- 如何使用词典,编码策略,上下文探测等绕过过滤器
2.Python安全工具开发技巧
- 使用requests,urllib等模块构造请求
- 多线程异步扫描
- 数据结构组织方式
- 命令行界面交互的设计思路
3.源码工程结构与模块划分
- 如何将工具拆分为功能模块
- 如何设计配置文件,命令参数,插件式架构
4.反WAF与XSS绕过技巧
- 内置的绕过payload和算法
- DOM与反射型XSS的区分探测方式
学习步骤
- 快速了解工具的功能和使用方式(阅读README文档,运行XSSstrike,观察常见命令行参数,输出内容,执行流程)
- 通过项目结构,理解各个模块的职责(梳理模块用途,建立模块依赖关系图)
- 选择一个典型流程深入分析
- 学习其中用到的关键技术
项目概述
理解XSSstrike运作原理,学习其中的技术
| 模块 | 功能说明 | 是否有独立文件/目录 |
|---|---|---|
| 智能 Payload 生成器 | 根据上下文动态构造有效 Payload,而非使用固定词典 | core/payloads.py |
| HTML/JS 解析器 | 手工编写的解析器,能理解上下文 | core/parsers/ 下可能包含 |
| Fuzzing 引擎 | 自动注入参数 + 分析响应 + 变异构造 | core/fuzzer.py |
| 爬虫引擎 | 多线程爬虫(基于 Photon) | core/crawler.py |
| 参数发现工具 | 自动挖掘 URL 参数(可能集成 Arjun) | core/parameter.py |
| WAF 探测与绕过 | 检测是否被 WAF 拦截并尝试绕过 | core/waf.py |
| DOM XSS 扫描 | 分析 JavaScript 中触发的 XSS(可能用到 headless 浏览器) | core/dom_scanner.py |
| 盲 XSS 支持 | 支持回显不可见的注入测试 | 可能集成 external webhook |
| Payload 编码器 | 支持 URL、Unicode、HTML 编码等 | utils/encoder.py |
| 配置模块 | 支持高度定制,可能有配置文件或命令参数 | config.py 或 core/config.py |
学习流程
一.运行XSSstrike+跟踪主入口
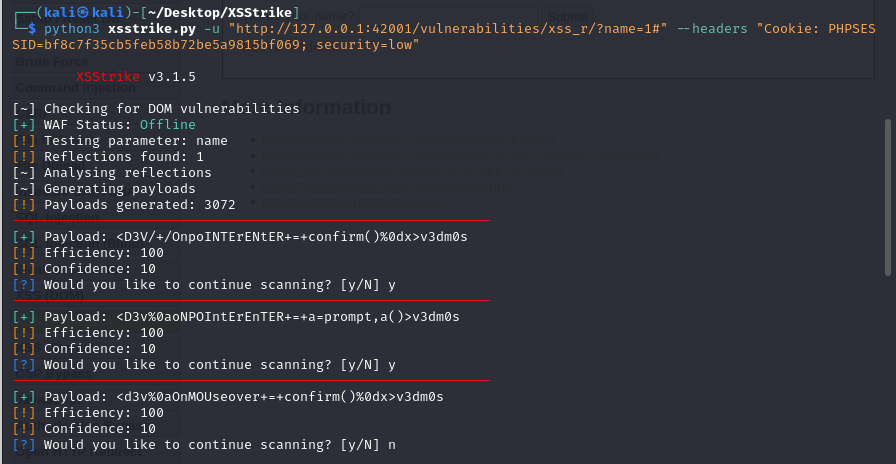
进行调试:我使用的是vscode,launch.json是其中的调试配置文件,用于告诉vscode要调试哪个程序(program),使用什么语言(python),传入哪些命令参数(args),是否使用终端,是否附加已有进程等等
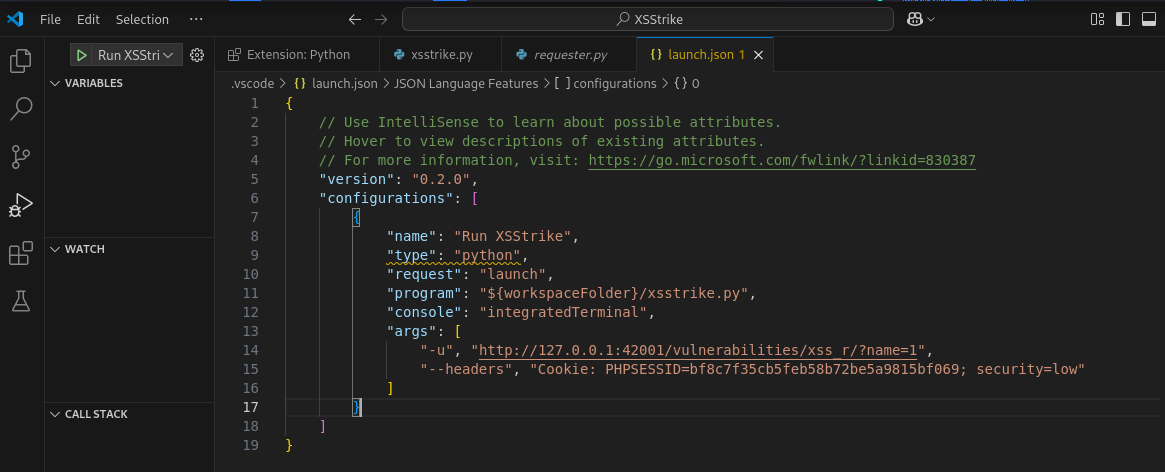
添加断点,进行调试,观察运行过程
二.分析主程序入口(xsstrike.py)
功能概述:这是主程序入口,所有的功能模块都是从这里开始被调用
内容:
1.基础引入和环境检测
2.参数解析:argparse
| 参数 | 作用说明 |
|---|---|
-u, --url | 设置目标 URL |
--data | 设置 POST 数据 |
--headers | 添加请求头(如 Cookie) |
--fuzzer | 进入单次 fuzz 模式 |
--crawl | 启用递归爬虫 |
-f, --file | 从文件读取 payload |
--blind | 插入盲 XSS payload |
--json | POST 数据为 JSON 格式 |
--skip | 扫描过程中不再询问是否继续 |
--timeout 等 | 设置线程数、延迟、代理等配置项 |
3.配置与全局变量初始化:将命令行参数作为全局配置传入globalVariables,方便各模块共享使用,处理headers和初始化关键模块
if type(args.add_headers) == bool:headers = extractHeaders(prompt()) # 手动输入
elif type(args.add_headers) == str:headers = extractHeaders(args.add_headers) # 解析命令行输入
from core.config import blindPayload
from core.encoders import base64
from core.photon import photon
from core.prompt import prompt
from core.utils import extractHeaders, reader, converter
#这些是 XSStrike 自研的模块,用于数据处理、payload 编码、用户输入交互、爬虫等。4.程序执行主逻辑(主控制流)
1)单次fuzz模式
if fuzz:singleFuzz(target, paramData, encoding, headers, delay, timeout)
2)非递归扫描模式
elif not recursive and not args_seeds:if args_file:bruteforcer(target, paramData, payloadList, encoding, headers, delay, timeout)else:scan(target, paramData, encoding, headers, delay, timeout, skipDOM, skip)
解释:scan()是常规XSS扫描的主函数,bruteforcer是自定义的payload扫描
3)爬虫+全站扫描模式
else:if target:seedList.append(target)for target in seedList:logger.run('Crawling the target')scheme = urlparse(target).schemelogger.debug('Target scheme: {}'.format(scheme))host = urlparse(target).netlocmain_url = scheme + '://' + hostcrawlingResult = photon(target, headers, level,threadCount, delay, timeout, skipDOM)forms = crawlingResult[0]domURLs = list(crawlingResult[1])difference = abs(len(domURLs) - len(forms))if len(domURLs) > len(forms):for i in range(difference):forms.append(0)elif len(forms) > len(domURLs):for i in range(difference):domURLs.append(0)threadpool = concurrent.futures.ThreadPoolExecutor(max_workers=threadCount)futures = (threadpool.submit(crawl, scheme, host, main_url, form,blindXSS, blindPayload, headers, delay, timeout, encoding) for form, domURL in zip(forms, domURLs))for i, _ in enumerate(concurrent.futures.as_completed(futures)):if i + 1 == len(forms) or (i + 1) % threadCount == 0:logger.info('Progress: %i/%i\r' % (i + 1, len(forms)))logger.no_format('')
解释:基于Phonton进行自动爬虫,并结合HTML/JS解析器对表单/链接发起扫描和fuzz
总模块结构图:
xsstrike.py
├── argparse 命令行处理
├── 核心配置加载 core/config
├── 日志模块初始化 core/log
├── 请求头处理 extractHeaders/prompt
├── 调用模式模块:
│ ├── modes/scan.py
│ ├── modes/singleFuzz.py
│ ├── modes/bruteforcer.py
│ └── core/photon.py + crawl.py (爬虫+分析)
└── payload/参数/headers/encoder 等辅助模块调用
三.modes/scan.py
功能概述:这个函数是XSStrike的核心扫描逻辑,其主要职责是对目标URL参数进行反射检查,判断是否存在XSS,分析过滤器绕过策略,并生成有效payload进行验证
内容:
1.URL构造和初始请求
GET, POST = (False, True) if paramData else (True, False)
解释:如果指定了 paramData(POST 数据),则使用 POST,否则默认 GET。
if not target.startswith('http'):try:response = requester('https://' + target, {},headers, GET, delay, timeout)target = 'https://' + targetexcept:target = 'http://' + target解释:自动补全协议头(如 example.com → https://example.com)
2.DOM XSS检测
if not skipDOM:logger.run('Checking for DOM vulnerabilities')highlighted = dom(response)if highlighted:logger.good('Potentially vulnerable objects found')logger.red_line(level='good')for line in highlighted:logger.no_format(line, level='good')logger.red_line(level='good')解释:使用core/dom.py模块进行静态DOM XSS检查,如果HTML中出现可能被动态执行的eval()或innerHTML拼接位置,会被标记
3.参数提取和WAF检测
params = getParams(target, paramData, GET)解释:从URL或POST data中提取参数
WAF = wafDetector(url, {list(params.keys())[0]: xsschecker}, headers, GET, delay, timeout)解释:使用core/wafDetector.py模块,向目标发送特征性payload并分析相应内容,检测是否存在WAF检测
4.反射检测+payload构造主循环
对每一个参数逐一进行 fuzz 和检测:
for paramName in params.keys():paramsCopy = copy.deepcopy(params)...
1)参数注入和反射检测
if encoding:paramsCopy[paramName] = encoding(xsschecker)else:paramsCopy[paramName] = xsscheckerresponse = requester(url, paramsCopy, headers, GET, delay, timeout)occurences = htmlParser(response, encoding)解释:注入payload,并分析响应中是否出现该值,htmlParser() 返回值如 {<位置>: <标签上下文>}。
2)分析过滤器
efficiencies = filterChecker(url, paramsCopy, headers, GET, delay, occurences, timeout, encoding)解释:使用多个轻量payload模拟不同类型的XSS注入,检测哪些被过滤,返回每种payload的注入效率指标。
3)生成绕过payload
vectors = generator(occurences, response.text)
解释:根据参数反射位置生成上下文对应的payload列表,含逃逸策略和双引号,尖括号编码等变体。
5.Payload验证循环
for confidence, vects in vectors.items():for vect in vects:...efficiencies = checker(...)
1)判断有效性
bestEfficiency = max(efficiencies)
解释:如果payload达到效率100或>=95且以\开头,则认为是高危
2)是否继续扫描
if not skip:choice = input('...Continue?').lower()if choice != 'y':quit()
模块间调用逻辑图:
scan.py
├── requester() → 发起请求
├── dom() → DOM XSS 静态检测
├── getParams() → 参数提取
├── wafDetector() → 检测是否有 WAF
├── htmlParser() → 判断反射点(xsschecker 是否出现在响应中)
├── filterChecker() → 判断输入被过滤的规则
├── generator() → 根据反射点生成合适上下文 payload
└── checker() → 逐个 payload 验证其注入效率
四.modes/singleFuzz.py
功能概述:这是XSStrike中一个用于快速fuzz单个参数的简化扫描模块,适用于手动分析或快速检测用途。相比主扫描逻辑scan.py,它不执行DOM分析,paylaod构造或效率计算,仅将一个标准payload插入目标参数并fuzz相应内容
(注释:什么是fuzzing?fuzzing指的是自动的或半自动的向程序输入大量随机,异常或畸形的数据,以观察程序是否会出现异常行为,比如崩溃,处理失败或产生漏洞等。)
内容:
1.函数定义
def singleFuzz(target, paramData, encoding, headers, delay, timeout):
| 参数名 | 含义 |
|---|---|
target | 目标 URL |
paramData | POST 数据(若为 None 则默认 GET 请求) |
encoding | 可选,对 payload 进行编码 |
headers | 自定义请求头 |
delay | 每个请求之间的延迟(防止 WAF) |
timeout | 请求超时时间 |
2.请求方法和URL预处理
GET, POST = (False, True) if paramData else (True, False)# If the user hasn't supplied the root url with http(s), we will handle itif not target.startswith('http'):try:response = requester('https://' + target, {},headers, GET, delay, timeout)target = 'https://' + targetexcept:target = 'http://' + target3.日志输出和参数准备
host = urlparse(target).netloc
url = getUrl(target, GET)
params = getParams(target, paramData, GET)
解释:解析出主机名,最终构造的URL和参数键值对,使用core/utils.py中的工具函数
4.WAF检测
WAF = wafDetector(url, {list(params.keys())[0]: xsschecker}, headers, GET, delay, timeout)
5.Fuzz主题逻辑
for paramName in params.keys():logger.info('Fuzzing parameter: %s' % paramName)paramsCopy = copy.deepcopy(params)paramsCopy[paramName] = xsscheckerfuzzer(url, paramsCopy, headers, GET, delay, timeout, WAF, encoding)
解释:逐个参数插入标准payload,调用core/fuzzer.py中的fuzzer()进行fuzz
与scan.py的区别:
| 功能 | scan.py | singlefuzz.py |
|---|---|---|
| DOM 检测 | ✅ | ❌ |
| Payload 构造 | ✅ | ❌ |
| 自动反射分析 | ✅ | ❌ |
| 多参数扫描 | ✅ | ✅ |
| 标准 payload fuzz | ✅ | ✅(核心功能) |
| 用途 | 自动扫描 + 精度分析 | 快速测试某个目标是否有反射型 XSS |
五.modes/bruteforcer.py
功能概述:实现了一个基于payload列表的暴力测试器,用于向指定参数逐个注入Payload,并检测是否存在响应中,从而判断是否反射
内容:
1.主函数
def bruteforcer(target, paramData, payloadList, encoding, headers, delay, timeout):
-
target:目标 URL。 -
paramData:POST 参数,如果为空则默认使用 GET。 -
payloadList:需要测试的 Payload 字符串列表。 -
encoding:是否使用编码函数处理 Payload(如 HTML 实体编码等)。 -
headers:请求头字典。 -
delay:请求间隔延迟。 -
timeout:请求超时时间。
2.请求方法和URL预处理
GET, POST = (False, True) if paramData else (True, False)host = urlparse(target).netloc # Extracts host out of the urllogger.debug('Parsed host to bruteforce: {}'.format(host))url = getUrl(target, GET)logger.debug('Parsed url to bruteforce: {}'.format(url))params = getParams(target, paramData, GET)logger.debug_json('Bruteforcer params:', params)if not params:logger.error('No parameters to test.')quit()3.外层循环:遍历参数名,内层循环:遍历payload列表
for paramName in params.keys():progress = 1paramsCopy = copy.deepcopy(params)for payload in payloadList:logger.run('Bruteforcing %s[%s%s%s]%s: %i/%i\r' %(green, end, paramName, green, end, progress, len(payloadList)))if encoding:payload = encoding(unquote(payload))paramsCopy[paramName] = payloadresponse = requester(url, paramsCopy, headers,GET, delay, timeout).textif encoding:payload = encoding(payload)if payload in response:logger.info('%s %s' % (good, payload))progress += 1(持续更新 2025.5.31)
六.modes/craw.py
功能概述:
七.core/dom.py
功能概述:
八.core/fuzzer.py
功能概述:
九.core/generator.py
功能概述:
十.core/photon.py
功能概述:
十一.core/utils.py
功能概述:
十二.core/wafDetector.py
功能概述: