MCP Python技术实践
目录
1. 引言篇
1.1 什么是MCP(Model Context Protocol)
1.2 MCP的核心设计理念
1.3 MCP的技术背景
1.3 学习目标与内容概览
2. 基础理论篇
2.1 MCP协议架构详解
2.2 MCP消息格式与通信机制
2.3 MCP核心概念深入
3. 环境搭建篇
3.1 开发环境准备
3.2 安装MCP SDK
3.3 项目结构建议
4. 入门实践篇
4.1 创建第一个MCP Server
基础Server实现
注册资源和工具
启动和测试
4.2 实现基础Resource
文件资源管理
数据库资源访问
API资源代理
4.3 开发自定义Tool
工具接口设计
参数验证处理
错误处理机制
4.4 客户端连接测试
MCP Client配置
5 MCP面试知识点总结与答案
5.1. 基础概念类问题
Q1: 什么是MCP?它解决了什么问题?
Q2: MCP的核心架构组件有哪些?
Q3: MCP与传统API有什么区别?
5.2. 技术实现类问题
Q4: 如何创建一个基础的MCP Server?
Q5: MCP Server支持哪些传输协议?
Q6: 如何实现Resource的动态发现?
Q7: 如何处理MCP中的错误和异常?
5.3. 高级特性类问题
Q8: 如何实现MCP Server的安全性?
Q9: 如何优化MCP Server的性能?
Q10: 如何实现Tool的链式调用?
5.4. 实际应用类问题
Q11: MCP适用于哪些场景?
Q12: 如何调试MCP Server?
Q13: MCP Server如何处理大文件?
5.5. 设计模式类问题
Q14: MCP中常用的设计模式有哪些?
Q15: 如何测试MCP Server?
5.6. 面试高频问题
Q16: MCP与函数调用(Function Calling)的区别?
Q17: 生产环境部署MCP Server需要注意什么?
Q18: MCP的未来发展趋势?
5.7. 实战经验类问题
Q19: 遇到MCP连接问题如何排查?
Q20: 如何设计一个高可用的MCP服务?
1. 引言篇
1.1 什么是MCP(Model Context Protocol)
如果你经常与AI应用打交道,你可能会遇到这样的困扰:想让AI助手访问你的本地文件、连接数据库、或者调用某个API,但每次都需要复杂的配置和集成工作。而且,不同的AI应用有不同的集成方式,维护起来十分麻烦。
Model Context Protocol(MCP)就是为了解决这个问题而诞生的。简单来说,MCP是一个标准化的协议,它就像是AI应用和外部数据源之间的"通用接口"。想象一下,如果所有的电子设备都需要不同的充电接口,那该多么麻烦。MCP就相当于给AI应用提供了一个统一的"USB-C接口",让它们能够轻松连接各种外部资源。
MCP的核心思想是建立一套标准化的通信规范,让AI模型能够安全、高效地访问外部数据和工具。这个协议定义了AI应用如何发现可用的资源,如何请求数据,以及如何调用外部工具。最重要的是,它是模型无关的,这意味着不管你使用的是ChatGPT、Claude还是其他AI模型,都可以通过这个协议来扩展能力。
在AI应用的生态系统中,MCP扮演着关键的桥梁角色。它位于AI模型和外部世界之间,提供了一个安全、标准化的连接层。这样,开发者就不需要为每个AI应用单独开发集成方案,而是可以创建一次MCP服务器,然后被多个AI应用复用。
1.2 MCP的核心设计理念
-
模型无关性
无论使用Claude、GPT-4还是开源模型,同一套MCP服务可跨平台复用。例如,一个文件系统MCP Server可同时服务于多个AI应用。 -
能力动态协商
采用"能力声明"机制,服务器启动时主动上报支持的功能(如文件读写/SQL查询),客户端无需预定义接口。这解决了传统集成方案中"接口冻结"的问题。 -
安全沙箱机制
通过Roots概念限定资源访问范围
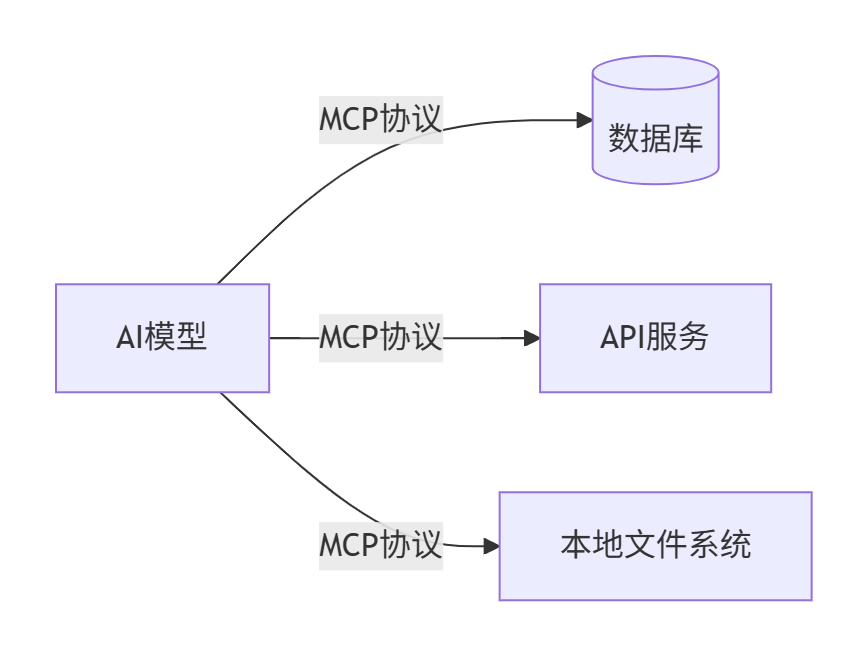
1.3 MCP的技术背景
统AI集成的三大困境
| 问题类型 | 典型案例 | MCP解决方案 |
|---|---|---|
| 碎片化接口 | 为每个AI工具开发独立插件 | 标准化JSON-RPC 2.0协议 |
| 安全风险 | 临时脚本处理敏感数据 | 基于OAuth2的细粒度授权 |
| 扩展成本 | 新增数据源需重构应用 | 热加载新Server无需重启 |
在MCP出现之前,AI应用与外部系统的集成是一个充满挑战的领域。每当我们想要让AI助手访问新的数据源或工具时,都需要进行大量的定制化开发工作。
首先是集成复杂性的问题。传统的方式下,每个AI应用都有自己的集成规范和接口要求。比如,你可能需要为ChatGPT编写一套插件,为Claude编写另一套集成代码,为其他AI应用再编写不同的方案。这不仅开发成本高昂,维护起来也是噩梦。随着AI应用的增多,这种"点对点"的集成方式变得越来越不可持续。
安全性也是一个重大挑战。在没有统一标准的情况下,每个集成方案都需要自己处理身份认证、权限控制和数据传输安全等问题。这不仅增加了开发复杂度,也增加了安全风险。缺乏统一的安全框架意味着每个开发者都需要重新发明轮子,很容易出现安全漏洞。
可扩展性限制同样明显。当你想要添加新的数据源或工具时,往往需要修改现有的AI应用代码,这种紧耦合的设计使得系统扩展变得困难。而且,不同的AI应用可能无法共享同样的扩展能力,导致重复开发和资源浪费。
MCP的出现正是为了解决这些痛点。它提供了一个标准化的协议框架,定义了AI应用与外部系统通信的统一方式。通过这个协议,开发者只需要实现一次MCP服务器,就能被所有支持MCP的AI应用使用。这大大降低了开发和维护成本,同时提高了系统的可扩展性。
MCP基于JSON-RPC 2.0协议构建,这是一个成熟、稳定的远程过程调用标准。它支持多种传输方式,包括标准输入输出(适合本地应用)、WebSocket(适合实时通信)和Server-Sent Events(适合远程服务)。这种灵活的设计使得MCP能够适应各种不同的部署场景。
与其他现有协议相比,MCP的优势在于它专门为AI应用场景设计。虽然REST API、GraphQL和gRPC都是优秀的通信协议,但它们并没有针对AI模型的特殊需求进行优化。MCP原生支持AI应用常见的操作模式,比如资源发现、工具调用、提示模板管理等,这使得它更适合构建AI驱动的应用。
1.3 学习目标与内容概览
通过这篇博客的学习,你将掌握使用Python开发MCP应用的完整技能。我们的目标不仅仅是学会使用MCP的API,更重要的是理解MCP的设计理念,掌握AI应用集成的最佳实践。
2. 基础理论篇
2.1 MCP协议架构详解
要深入理解MCP,我们首先需要了解它的整体架构。MCP采用了经典的客户端-服务器架构,但在这个架构中,角色的定义可能与你想象的有所不同。
在MCP的世界里,AI应用(比如Claude Desktop、ChatGPT等)充当客户端的角色,而提供数据和工具的程序则是服务器。这种设计很有意思:通常我们认为AI应用是"服务提供者",但在MCP的架构中,它们实际上是"服务消费者"。真正的服务提供者是那些暴露资源和工具的MCP服务器。
MCP的分层架构设计得很优雅。最底层是传输层,负责处理客户端和服务器之间的实际通信。MCP支持三种主要的传输方式:标准输入输出(stdio)适合本地运行的服务器,WebSocket适合需要双向实时通信的场景,而Server-Sent Events(SSE)则适合远程托管的服务器。这种多传输方式的设计使得MCP能够适应各种不同的部署环境。
在传输层之上是协议层,这里使用的是JSON-RPC 2.0标准。选择JSON-RPC并不是偶然的,它是一个成熟、简单、易于实现的远程过程调用协议。JSON-RPC的请求-响应模式非常适合MCP的交互需求,而它的错误处理机制也为MCP提供了良好的异常处理基础。
协议层再往上就是能力层,这是MCP的核心创新所在。能力层定义了四种主要的能力类型:Resources(资源)用于提供数据访问,Tools(工具)用于执行操作,Prompts(提示)用于提供模板化的指令,Sampling(采样)则允许服务器请求AI模型生成内容。这种能力分类非常直观,覆盖了AI应用与外部系统交互的主要场景。
最顶层是应用层,这里运行着实际的MCP客户端和服务器程序。客户端通常是AI应用或者集成了AI功能的软件,而服务器则是各种数据提供者和工具提供者。
MCP的数据流向遵循清晰的模式。首先是初始化阶段,客户端向服务器发送初始化请求,服务器响应并告知自己支持的能力。然后是能力发现阶段,客户端可以查询服务器提供的具体资源、工具和提示。最后是实际使用阶段,客户端根据需要读取资源、调用工具或获取提示模板。
这种架构设计的好处在于职责分离清晰。服务器专注于提供数据和工具,客户端专注于AI逻辑和用户交互。中间的协议层确保了通信的标准化和可靠性。这种设计使得系统既灵活又稳定,既易于扩展又易于维护。
2.2 MCP消息格式与通信机制
MCP的消息格式完全基于JSON-RPC 2.0规范,这是一个非常简洁和强大的远程过程调用协议。如果你之前没有接触过JSON-RPC,不用担心,它的核心概念很容易理解。
JSON-RPC的基本思想是通过JSON格式的消息来调用远程函数。每个请求消息都包含几个关键字段:jsonrpc字段标识协议版本(固定为"2.0"),method字段指定要调用的方法名,params字段包含方法参数,id字段是请求的唯一标识符,用于匹配请求和响应。
响应消息的结构同样简单。成功的响应包含result字段,失败的响应包含error字段。error字段本身是一个对象,包含错误代码、错误消息和可选的详细信息。这种设计使得错误处理变得统一和可预测。
MCP在JSON-RPC的基础上定义了一套标准的方法名和参数结构。这些方法可以分为几个类别:初始化相关的方法用于建立连接和协商能力,能力发现方法用于查询可用的资源、工具和提示,实际操作方法用于读取资源、调用工具等。
特别值得注意的是,MCP还支持通知消息,这是JSON-RPC 2.0的一个特性。通知消息没有id字段,也不期望响应。这种单向消息非常适合实现事件通知,比如资源变更通知、工具执行进度通知等。
MCP的通信机制设计得很人性化。它支持同步和异步两种模式。同步模式下,客户端发送请求后等待响应,这是最基本的交互方式。异步模式下,客户端可以发送多个请求而不必等待前一个请求的响应,这提高了通信效率。
对于长时间运行的操作,MCP提供了进度通知机制。服务器可以在执行工具的过程中发送进度更新,让客户端了解操作的当前状态。这种设计改善了用户体验,特别是在处理大数据或复杂计算时。
错误处理是MCP通信机制的另一个亮点。它不仅继承了JSON-RPC的标准错误代码,还定义了MCP特有的错误类型。比如,当请求的资源不存在时,会返回特定的错误代码和消息。这种标准化的错误处理使得客户端能够提供更好的错误提示和恢复机制。
2.3 MCP核心概念深入
MCP的四个核心概念——Resources、Tools、Prompts和Sampling——构成了协议的能力基础。理解这些概念对于有效使用MCP至关重要。
Resources(资源)是MCP中最基础的概念。它代表了服务器能够提供的各种数据源。这些数据可能是静态的文件,也可能是动态的数据库查询结果,或者是实时的API响应。资源的设计理念类似于REST API中的GET端点,它们是只读的,客户端可以请求读取但不能直接修改。
每个资源都有一个URI来唯一标识它,还有名称、描述和MIME类型等元数据。这种设计使得资源发现和使用变得标准化。客户端可以通过列出所有资源来了解服务器的能力,然后根据URI读取具体的资源内容。
资源的一个重要特性是它们可以是动态的。这意味着同一个URI的资源内容可能会随时间变化。为了处理这种情况,MCP提供了资源订阅机制。客户端可以订阅特定资源的变更通知,当资源内容发生变化时,服务器会主动通知客户端。
Tools(工具)代表了服务器提供的可执行功能。与资源不同,工具是主动的,它们可以执行操作、修改状态、或者与外部系统交互。工具的概念类似于函数调用,客户端提供参数,服务器执行操作并返回结果。
每个工具都有详细的接口描述,包括输入参数的类型和约束、输出格式的说明等。这种自描述的特性使得AI模型能够理解如何使用这些工具。MCP使用JSON Schema来描述工具接口,这是一个成熟的标准,提供了丰富的类型描述能力。
工具的执行可能是耗时的,特别是当它们需要访问网络资源或处理大量数据时。为了改善用户体验,MCP支持工具执行的进度通知。服务器可以在执行过程中发送进度更新,让客户端了解操作的当前状态。
Prompts(提示)是MCP中一个很有创意的概念。它们是预定义的文本模板,用于帮助AI模型生成标准化的提示。这个概念的价值在于它将提示工程的最佳实践封装到了协议层面。
提示模板可以包含参数,这使得它们能够适应不同的使用场景。客户端可以获取提示模板,填入具体的参数值,然后生成最终的提示文本。这种方式既保证了提示的质量,又提供了必要的灵活性。
Sampling(采样)是MCP中最特殊的概念,它允许服务器向客户端请求AI模型生成内容。这种"反向调用"的设计很独特,它使得MCP服务器能够利用客户端的AI能力来完成自己的任务。
采样请求包含了完整的对话上下文和生成参数。服务器可以构造一个对话场景,然后请求客户端的AI模型生成响应。这种机制为服务器提供了强大的AI能力,而不必自己部署AI模型。
这四个核心概念相互补充,共同构成了MCP的能力体系。资源提供数据访问,工具提供操作能力,提示提供模板化的指令,采样提供AI生成能力。这种设计覆盖了AI应用与外部系统交互的主要需求,同时保持了协议的简洁性和一致性。
3. 环境搭建篇
3.1 开发环境准备
对于MCP Python开发,推荐使用PyCharm和conda的组合。这个组合提供了优秀的开发体验和包管理能力,特别适合Python项目开发。
首先确保你安装了Anaconda或Miniconda。如果还没有安装,建议使用Miniconda,它更轻量但功能完整。MCP开发需要Python 3.9或更高版本,这在现代Python环境中应该不是问题。
创建专用的conda环境是个好习惯,这样可以避免包冲突,也便于项目管理:
# 创建MCP开发环境
conda create -n mcp-dev python=3.10
# 激活环境
conda activate mcp-dev在PyCharm中,你需要将项目解释器设置为这个conda环境。在项目设置中找到Python解释器配置,选择Conda Environment,然后指向你刚创建的mcp-dev环境。这样PyCharm就能正确识别和管理项目依赖。
3.2 安装MCP SDK
激活conda环境后,安装MCP Python SDK:
pip install mcp这会安装MCP的核心库和必要的依赖。MCP Python SDK提供了创建服务器和客户端的全部功能,包括消息处理、传输层抽象等。
为了验证安装是否成功,可以运行一个简单的测试:
import mcp
from mcp.server import Server# 创建一个测试服务器
server = Server("test-server")
print(f"MCP SDK安装成功,版本:{mcp.__version__}")3.3 项目结构建议
对于MCP项目,我们建议采用清晰的目录结构:
mcp-project/
├── src/
│ ├── server.py # MCP服务器主文件
│ ├── resources/ # 资源处理模块
│ ├── tools/ # 工具实现模块
│ └── config.py # 配置管理
├── tests/ # 测试文件
├── requirements.txt # 依赖清单
└── README.md # 项目说明在PyCharm中,你可以将src目录标记为Sources Root,这样IDE就能正确处理模块导入和代码导航。
这个简化的环境搭建过程已经足够开始MCP开发了。PyCharm的强大功能会在开发过程中帮助你处理代码补全、调试、版本控制等任务,而conda环境确保了依赖管理的清晰和可重现性。
4. 入门实践篇
4.1 创建第一个MCP Server
基础Server实现
让我们从创建一个简单的MCP Server开始:
import asyncio
import logging
from typing import Any, Sequence
from mcp.server import Server
from mcp.server.models import InitializationOptions
from mcp.server.stdio import stdio_server
from mcp.types import (Resource,Tool,TextContent,ImageContent,EmbeddedResource
)# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)class MyFirstMCPServer:def __init__(self):self.server = Server("my-first-mcp-server")self.data_store = {} # 简单的内存数据存储async def initialize(self):"""服务器初始化"""logger.info("初始化MCP Server...")async def start(self):"""启动服务器"""# 注册资源和工具await self.register_resources()await self.register_tools()# 启动stdio服务器async with stdio_server() as (read_stream, write_stream):await self.server.run(read_stream,write_stream,InitializationOptions(server_name="my-first-mcp-server",server_version="1.0.0",capabilities=self.server.get_capabilities()))注册资源和工具
async def register_resources(self):"""注册资源"""@self.server.list_resources()async def handle_list_resources() -> list[Resource]:"""列出所有可用资源"""return [Resource(uri="file://config.json",name="配置文件",description="应用程序配置文件",mimeType="application/json"),Resource(uri="memory://data-store",name="内存数据存储",description="临时数据存储",mimeType="application/json")]@self.server.read_resource()async def handle_read_resource(uri: str) -> str:"""读取指定资源"""if uri == "file://config.json":return '{"app_name": "MCP Demo", "version": "1.0.0"}'elif uri == "memory://data-store":return str(self.data_store)else:raise ValueError(f"未知资源: {uri}")async def register_tools(self):"""注册工具"""@self.server.list_tools()async def handle_list_tools() -> list[Tool]:"""列出所有可用工具"""return [Tool(name="store_data",description="在内存中存储数据",inputSchema={"type": "object","properties": {"key": {"type": "string","description": "数据键名"},"value": {"type": "string", "description": "数据值"}},"required": ["key", "value"]}),Tool(name="get_data",description="从内存中获取数据",inputSchema={"type": "object","properties": {"key": {"type": "string","description": "要获取的数据键名"}},"required": ["key"]})]@self.server.call_tool()async def handle_call_tool(name: str, arguments: dict[str, Any]) -> list[TextContent]:"""处理工具调用"""if name == "store_data":key = arguments.get("key")value = arguments.get("value")self.data_store[key] = valuereturn [TextContent(type="text",text=f"数据已存储: {key} = {value}")]elif name == "get_data":key = arguments.get("key")value = self.data_store.get(key, "未找到")return [TextContent(type="text", text=f"{key}: {value}")]else:raise ValueError(f"未知工具: {name}")启动和测试
async def main():"""主函数"""server = MyFirstMCPServer()await server.initialize()await server.start()if __name__ == "__main__":asyncio.run(main())4.2 实现基础Resource
文件资源管理
import os
import json
import asyncio
from pathlib import Path
from typing import Dict, List, Optionalclass FileResourceManager:def __init__(self, base_path: str = "./resources"):self.base_path = Path(base_path)self.base_path.mkdir(exist_ok=True)async def list_files(self) -> List[Resource]:"""列出所有文件资源"""resources = []for file_path in self.base_path.rglob("*"):if file_path.is_file():relative_path = file_path.relative_to(self.base_path)mime_type = self._get_mime_type(file_path.suffix)resources.append(Resource(uri=f"file://{relative_path}",name=file_path.name,description=f"文件: {relative_path}",mimeType=mime_type))return resourcesasync def read_file(self, uri: str) -> str:"""读取文件内容"""# 从URI中提取文件路径file_path = uri.replace("file://", "")full_path = self.base_path / file_pathif not full_path.exists():raise FileNotFoundError(f"文件不存在: {file_path}")# 安全检查:确保文件在允许的目录内if not str(full_path.resolve()).startswith(str(self.base_path.resolve())):raise PermissionError("访问被拒绝")with open(full_path, 'r', encoding='utf-8') as f:return f.read()async def write_file(self, uri: str, content: str) -> bool:"""写入文件内容"""file_path = uri.replace("file://", "")full_path = self.base_path / file_path# 创建目录full_path.parent.mkdir(parents=True, exist_ok=True)with open(full_path, 'w', encoding='utf-8') as f:f.write(content)return Truedef _get_mime_type(self, suffix: str) -> str:"""根据文件扩展名获取MIME类型"""mime_types = {'.json': 'application/json','.txt': 'text/plain','.md': 'text/markdown','.html': 'text/html','.css': 'text/css','.js': 'application/javascript','.py': 'text/x-python','.xml': 'application/xml','.csv': 'text/csv'}return mime_types.get(suffix.lower(), 'application/octet-stream')数据库资源访问
import sqlite3
import asyncio
import aiosqlite
from typing import Any, Dict, Listclass DatabaseResourceManager:def __init__(self, db_path: str = "resources.db"):self.db_path = db_pathasync def initialize(self):"""初始化数据库"""async with aiosqlite.connect(self.db_path) as db:await db.execute("""CREATE TABLE IF NOT EXISTS resources (id INTEGER PRIMARY KEY AUTOINCREMENT,name TEXT UNIQUE NOT NULL,type TEXT NOT NULL,data TEXT NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)""")await db.commit()async def list_resources(self) -> List[Resource]:"""列出数据库中的所有资源"""async with aiosqlite.connect(self.db_path) as db:cursor = await db.execute("SELECT id, name, type FROM resources ORDER BY name")rows = await cursor.fetchall()resources = []for row in rows:resources.append(Resource(uri=f"db://resource/{row[0]}",name=row[1],description=f"数据库资源: {row[1]} (类型: {row[2]})",mimeType="application/json"))return resourcesasync def read_resource(self, resource_id: int) -> Dict[str, Any]:"""读取数据库资源"""async with aiosqlite.connect(self.db_path) as db:cursor = await db.execute("SELECT name, type, data, created_at, updated_at FROM resources WHERE id = ?",(resource_id,))row = await cursor.fetchone()if not row:raise ValueError(f"资源不存在: {resource_id}")return {"id": resource_id,"name": row[0],"type": row[1], "data": json.loads(row[2]),"created_at": row[3],"updated_at": row[4]}async def create_resource(self, name: str, resource_type: str, data: Any) -> int:"""创建新资源"""async with aiosqlite.connect(self.db_path) as db:cursor = await db.execute("""INSERT INTO resources (name, type, data) VALUES (?, ?, ?)""",(name, resource_type, json.dumps(data)))await db.commit()return cursor.lastrowidasync def update_resource(self, resource_id: int, data: Any) -> bool:"""更新资源"""async with aiosqlite.connect(self.db_path) as db:await db.execute("""UPDATE resources SET data = ?, updated_at = CURRENT_TIMESTAMP WHERE id = ?""",(json.dumps(data), resource_id))await db.commit()return TrueAPI资源代理
import aiohttp
import asyncio
from typing import Dict, Any, Optional
from urllib.parse import urljoin, urlparseclass APIResourceProxy:def __init__(self, base_url: str, headers: Optional[Dict[str, str]] = None):self.base_url = base_url.rstrip('/')self.default_headers = headers or {}self.session = Noneasync def initialize(self):"""初始化HTTP会话"""connector = aiohttp.TCPConnector(limit=100, limit_per_host=30)timeout = aiohttp.ClientTimeout(total=30)self.session = aiohttp.ClientSession(connector=connector, timeout=timeout,headers=self.default_headers)async def close(self):"""关闭HTTP会话"""if self.session:await self.session.close()async def list_endpoints(self) -> List[Resource]:"""列出API端点资源"""# 这里可以通过API发现机制或配置文件定义端点endpoints = [{"path": "/users", "name": "用户列表", "method": "GET"},{"path": "/posts", "name": "文章列表", "method": "GET"},{"path": "/comments", "name": "评论列表", "method": "GET"}]resources = []for endpoint in endpoints:resources.append(Resource(uri=f"api://{endpoint['path']}",name=endpoint['name'],description=f"API端点: {endpoint['method']} {endpoint['path']}",mimeType="application/json"))return resourcesasync def call_api(self, path: str, method: str = "GET", params: Optional[Dict] = None, data: Optional[Dict] = None) -> Dict[str, Any]:"""调用API端点"""if not self.session:await self.initialize()url = urljoin(self.base_url + '/', path.lstrip('/'))try:async with self.session.request(method=method.upper(),url=url,params=params,json=data) as response:response.raise_for_status()if response.content_type == 'application/json':return await response.json()else:text = await response.text()return {"data": text, "content_type": response.content_type}except aiohttp.ClientError as e:raise ConnectionError(f"API调用失败: {str(e)}")except Exception as e:raise RuntimeError(f"未知错误: {str(e)}")async def get_resource(self, uri: str) -> str:"""获取API资源数据"""path = uri.replace("api://", "")result = await self.call_api(path)return json.dumps(result, ensure_ascii=False, indent=2)4.3 开发自定义Tool
工具接口设计
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional
import asyncio
import jsonclass BaseTool(ABC):"""工具基类"""def __init__(self, name: str, description: str):self.name = nameself.description = description@abstractmethoddef get_schema(self) -> Dict[str, Any]:"""获取工具参数模式"""pass@abstractmethodasync def execute(self, arguments: Dict[str, Any]) -> List[TextContent]:"""执行工具"""passdef validate_arguments(self, arguments: Dict[str, Any]) -> bool:"""验证参数"""schema = self.get_schema()required_fields = schema.get("required", [])# 检查必需字段for field in required_fields:if field not in arguments:raise ValueError(f"缺少必需参数: {field}")return Trueclass CalculatorTool(BaseTool):"""计算器工具"""def __init__(self):super().__init__(name="calculator",description="执行基本数学计算")def get_schema(self) -> Dict[str, Any]:return {"type": "object","properties": {"expression": {"type": "string","description": "要计算的数学表达式,如 '2 + 3 * 4'"}},"required": ["expression"]}async def execute(self, arguments: Dict[str, Any]) -> List[TextContent]:self.validate_arguments(arguments)expression = arguments["expression"]try:# 安全的数学表达式求值allowed_chars = set('0123456789+-*/().^% ')if not all(c in allowed_chars for c in expression):raise ValueError("表达式包含非法字符")# 替换^为**进行幂运算expression = expression.replace('^', '**')result = eval(expression)return [TextContent(type="text",text=f"计算结果: {expression} = {result}")]except Exception as e:return [TextContent(type="text", text=f"计算错误: {str(e)}")]class TextProcessorTool(BaseTool):"""文本处理工具"""def __init__(self):super().__init__(name="text_processor",description="处理文本:统计、转换、格式化等")def get_schema(self) -> Dict[str, Any]:return {"type": "object","properties": {"text": {"type": "string","description": "要处理的文本"},"operation": {"type": "string", "enum": ["count_words", "count_chars", "uppercase", "lowercase", "reverse"],"description": "要执行的操作"}},"required": ["text", "operation"]}async def execute(self, arguments: Dict[str, Any]) -> List[TextContent]:self.validate_arguments(arguments)text = arguments["text"]operation = arguments["operation"]if operation == "count_words":count = len(text.split())result = f"单词数量: {count}"elif operation == "count_chars":count = len(text)result = f"字符数量: {count}"elif operation == "uppercase":result = f"转换为大写: {text.upper()}"elif operation == "lowercase":result = f"转换为小写: {text.lower()}"elif operation == "reverse":result = f"反转文本: {text[::-1]}"else:result = f"未知操作: {operation}"return [TextContent(type="text", text=result)]参数验证处理
import jsonschema
from typing import Any, Dict, List, Unionclass ParameterValidator:"""参数验证器"""@staticmethoddef validate_schema(arguments: Dict[str, Any], schema: Dict[str, Any]) -> List[str]:"""使用JSON Schema验证参数"""errors = []try:jsonschema.validate(arguments, schema)except jsonschema.ValidationError as e:errors.append(f"参数验证失败: {e.message}")except jsonschema.SchemaError as e:errors.append(f"Schema错误: {e.message}")return errors@staticmethoddef validate_required_fields(arguments: Dict[str, Any], required: List[str]) -> List[str]:"""验证必需字段"""errors = []for field in required:if field not in arguments:errors.append(f"缺少必需参数: {field}")elif arguments[field] is None:errors.append(f"参数不能为空: {field}")return errors@staticmethoddef validate_type(value: Any, expected_type: Union[type, List[type]], field_name: str) -> List[str]:"""验证参数类型"""errors = []if isinstance(expected_type, list):if not any(isinstance(value, t) for t in expected_type):type_names = [t.__name__ for t in expected_type]errors.append(f"参数 {field_name} 类型错误,期望: {'/'.join(type_names)}")else:if not isinstance(value, expected_type):errors.append(f"参数 {field_name} 类型错误,期望: {expected_type.__name__}")return errors@staticmethod def validate_range(value: Union[int, float], min_val: Optional[Union[int, float]] = None,max_val: Optional[Union[int, float]] = None, field_name: str = "") -> List[str]:"""验证数值范围"""errors = []if min_val is not None and value < min_val:errors.append(f"参数 {field_name} 小于最小值 {min_val}")if max_val is not None and value > max_val:errors.append(f"参数 {field_name} 大于最大值 {max_val}")return errorsclass EnhancedTool(BaseTool):"""增强型工具基类,包含完整的参数验证"""async def execute(self, arguments: Dict[str, Any]) -> List[TextContent]:# 执行参数验证validation_errors = self.full_validate(arguments)if validation_errors:return [TextContent(type="text",text=f"参数验证失败:\n" + "\n".join(validation_errors))]# 执行具体工具逻辑return await self.execute_validated(arguments)def full_validate(self, arguments: Dict[str, Any]) -> List[str]:"""完整参数验证"""errors = []# JSON Schema验证schema_errors = ParameterValidator.validate_schema(arguments, self.get_schema())errors.extend(schema_errors)# 自定义验证custom_errors = self.custom_validate(arguments)errors.extend(custom_errors)return errorsdef custom_validate(self, arguments: Dict[str, Any]) -> List[str]:"""自定义验证逻辑,子类可重写"""return []@abstractmethodasync def execute_validated(self, arguments: Dict[str, Any]) -> List[TextContent]:"""执行已验证的工具逻辑"""pass错误处理机制
import traceback
import logging
from enum import Enum
from typing import Any, Dict, List, Optionalclass ErrorLevel(Enum):"""错误级别"""INFO = "info"WARNING = "warning" ERROR = "error"CRITICAL = "critical"class ToolError(Exception):"""工具执行错误"""def __init__(self, message: str, error_code: str = "TOOL_ERROR", level: ErrorLevel = ErrorLevel.ERROR, details: Optional[Dict] = None):super().__init__(message)self.message = messageself.error_code = error_codeself.level = levelself.details = details or {}class ErrorHandler:"""错误处理器"""def __init__(self, logger: Optional[logging.Logger] = None):self.logger = logger or logging.getLogger(__name__)def handle_error(self, error: Exception, context: Optional[Dict] = None) -> List[TextContent]:"""处理错误并返回用户友好的消息"""context = context or {}if isinstance(error, ToolError):return self._handle_tool_error(error, context)elif isinstance(error, ValueError):return self._handle_validation_error(error, context)elif isinstance(error, ConnectionError):return self._handle_connection_error(error, context)else:return self._handle_generic_error(error, context)def _handle_tool_error(self, error: ToolError, context: Dict) -> List[TextContent]:"""处理工具特定错误"""self.logger.error(f"工具错误 [{error.error_code}]: {error.message}", extra=context)message = f"❌ 工具执行失败\n错误: {error.message}"if error.details:message += f"\n详情: {json.dumps(error.details, ensure_ascii=False, indent=2)}"return [TextContent(type="text", text=message)]def _handle_validation_error(self, error: ValueError, context: Dict) -> List[TextContent]:"""处理参数验证错误"""self.logger.warning(f"参数验证错误: {str(error)}", extra=context)return [TextContent(type="text",text=f"⚠️ 参数错误\n{str(error)}\n请检查输入参数是否正确。")]def _handle_connection_error(self, error: ConnectionError, context: Dict) -> List[TextContent]:"""处理连接错误"""self.logger.error(f"连接错误: {str(error)}", extra=context)return [TextContent(type="text", text=f"🔌 连接失败\n无法连接到外部服务,请稍后重试。\n错误详情: {str(error)}")]def _handle_generic_error(self, error: Exception, context: Dict) -> List[TextContent]:"""处理通用错误"""error_trace = traceback.format_exc()self.logger.error(f"未知错误: {str(error)}\n{error_trace}", extra=context)# 在生产环境中,不应暴露详细的错误堆栈message = "❗ 系统错误\n执行过程中发生了意外错误,请联系管理员。"# 开发环境可以显示详细错误if context.get("debug_mode", False):message += f"\n详细错误:\n{str(error)}"return [TextContent(type="text", text=message)]class RobustTool(EnhancedTool):"""具有健壮错误处理的工具基类"""def __init__(self, name: str, description: str):super().__init__(name, description)self.error_handler = ErrorHandler()async def execute(self, arguments: Dict[str, Any]) -> List[TextContent]:"""执行工具,包含完整的错误处理"""try:return await super().execute(arguments)except Exception as e:context = {"tool_name": self.name,"arguments": arguments}return self.error_handler.handle_error(e, context)async def execute_with_retry(self, arguments: Dict[str, Any], max_retries: int = 3, retry_delay: float = 1.0) -> List[TextContent]:"""带重试机制的工具执行"""last_error = Nonefor attempt in range(max_retries + 1):try:return await self.execute(arguments)except Exception as e:last_error = eif attempt < max_retries:await asyncio.sleep(retry_delay * (2 ** attempt)) # 指数退避continuebreak# 所有重试都失败了context = {"tool_name": self.name,"arguments": arguments,"max_retries": max_retries,"final_attempt": True}return self.error_handler.handle_error(last_error, context)4.4 客户端连接测试
MCP Client配置
import asyncio
import json
from typing import Any, Dict, List, Optional
from mcp import ClientSession
from mcp.client.stdio import stdio_clientclass MCPTestClient:"""MCP测试客户端"""def __init__(self, server_command: List[str]):self.server_command = server_commandself.session: Optional[ClientSession] = Noneasync def connect(self):"""连接到MCP服务器"""try:# 启动stdio客户端self.session = await stdio_client(self.server_command)# 初始化连接await self.session.initialize()print("✅ 成功连接到MCP服务器")except Exception as e:print(f"❌ 连接失败: {str(e)}")raiseasync def disconnect(self):"""断开连接"""if self.session:await self.session.close()print("🔌 已断开连接")async def test_resources(self):"""测试资源功能"""print("\n=== 测试资源功能 ===")try:# 列出资源resources = await self.session.list_resources()print(f"📁 找到 {len(resources)} 个资源:")for resource in resources:print(f" - {resource.name}: {resource.uri}")# 尝试读取资源try:content = await self.session.read_resource(resource.uri)print(f" 内容预览: {content[:100]}...")except Exception as e:print(f" 读取失败: {str(e)}")except Exception as e:print(f"❌ 资源测试失败: {str(e)}")async def test_tools(self):"""测试工具功能"""print("\n=== 测试工具功能 ===")try:# 列出工具tools = await self.session.list_tools()print(f"🔧 找到 {len(tools)} 个工具:")for tool in tools:print(f" - {tool.name}: {tool.description}")# 测试具体工具if tools:await self._test_specific_tools(tools)except Exception as e:
5 MCP面试知识点总结与答案
5.1. 基础概念类问题
Q1: 什么是MCP?它解决了什么问题?
答案要点:
- MCP(Model Context Protocol)是由Anthropic开发的开源协议,为LLMs和AI代理提供了连接外部数据源和工具的标准化方式
- 解决的核心问题:
- AI模型与外部系统集成的标准化问题
- 消除不同工具和数据源的接入复杂性
- 提供统一的接口规范,类似于"AI的USB协议"
- 让AI能够安全、高效地访问本地文件、数据库、API等资源
Q2: MCP的核心架构组件有哪些?
答案要点:
- MCP Client: AI应用或大语言模型,消费MCP服务
- MCP Server: 轻量级程序,通过标准化的模型上下文协议暴露特定功能
- Resources: 数据源(文件、数据库、API等)
- Tools: 可执行的功能模块
- Prompts: 预定义的提示模板
Q3: MCP与传统API有什么区别?
答案要点:
- 标准化程度: MCP提供统一的协议规范,API各自独立
- 上下文感知: MCP专为AI上下文设计,更好地理解和处理AI需求
- 资源管理: MCP提供Resources概念,统一管理各类数据源
- 工具抽象: MCP的Tools提供更高层次的功能抽象
- 连接方式: 支持stdio、HTTP、WebSocket等多种传输方式
5.2. 技术实现类问题
Q4: 如何创建一个基础的MCP Server?
代码示例:
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Resource, Tool, TextContentclass BasicMCPServer:def __init__(self):self.server = Server("my-mcp-server")async def setup(self):# 注册资源列表处理器@self.server.list_resources()async def handle_list_resources():return [Resource(uri="file://config.json",name="配置文件",description="应用配置",mimeType="application/json")]# 注册工具列表处理器@self.server.list_tools()async def handle_list_tools():return [Tool(name="echo",description="回显输入文本",inputSchema={"type": "object","properties": {"text": {"type": "string"}},"required": ["text"]})]
Q5: MCP Server支持哪些传输协议?
答案要点:
- stdio: 标准输入输出,适合本地集成
- HTTP: RESTful API形式,适合网络服务
- WebSocket: 实时双向通信
- SSE (Server-Sent Events): 服务器主动推送
Q6: 如何实现Resource的动态发现?
代码示例:
class DynamicResourceManager:def __init__(self, watch_directories: List[str]):self.watch_dirs = watch_directoriesself.cached_resources = {}async def discover_resources(self) -> List[Resource]:resources = []for directory in self.watch_dirs:async for file_path in self._scan_directory(directory):resource = Resource(uri=f"file://{file_path}",name=file_path.name,description=f"动态发现: {file_path}",mimeType=self._detect_mime_type(file_path))resources.append(resource)return resources
Q7: 如何处理MCP中的错误和异常?
答案要点:
class ErrorHandler:async def handle_tool_call(self, name: str, args: dict):try:return await self._execute_tool(name, args)except ValidationError as e:return [TextContent(type="text",text=f"参数验证失败: {str(e)}")]except ConnectionError as e:return [TextContent(type="text", text=f"连接错误: {str(e)}")]except Exception as e:logger.error(f"未知错误: {str(e)}")return [TextContent(type="text",text="系统错误,请稍后重试")]
5.3. 高级特性类问题
Q8: 如何实现MCP Server的安全性?
答案要点:
- 身份验证: 实现token-based或证书认证
- 权限控制: 基于角色的访问控制(RBAC)
- 输入验证: JSON Schema验证所有输入参数
- 路径遍历防护: 严格检查文件访问路径
- 速率限制: 防止API滥用
- 数据加密: 敏感数据传输加密
class SecurityManager:def validate_file_access(self, file_path: str, base_path: str) -> bool:resolved_path = Path(file_path).resolve()base_resolved = Path(base_path).resolve()return str(resolved_path).startswith(str(base_resolved))def authenticate_request(self, token: str) -> bool:return self.token_validator.validate(token)
Q9: 如何优化MCP Server的性能?
答案要点:
- 连接池管理: 复用数据库和HTTP连接
- 异步处理: 使用asyncio处理并发请求
- 缓存策略: 缓存频繁访问的Resources
- 流式响应: 对大数据实现流式传输
- 资源预加载: 预先加载常用资源
class PerformanceOptimizer:def __init__(self):self.resource_cache = TTLCache(maxsize=1000, ttl=300)self.connection_pool = aiohttp.ClientSession()async def get_cached_resource(self, uri: str):if uri in self.resource_cache:return self.resource_cache[uri]data = await self._fetch_resource(uri)self.resource_cache[uri] = datareturn data
Q10: 如何实现Tool的链式调用?
代码示例:
class ToolChain:def __init__(self):self.tools = {}self.execution_graph = {}async def execute_chain(self, chain_definition: List[dict]) -> Any:results = {}for step in chain_definition:tool_name = step['tool']args = step['args']# 支持从前一步结果中获取参数resolved_args = self._resolve_args(args, results)result = await self.tools[tool_name].execute(resolved_args)results[step['id']] = resultreturn results
5.4. 实际应用类问题
Q11: MCP适用于哪些场景?
答案要点:
- 开发工具集成: IDE插件、代码分析工具
- 企业知识管理: 文档搜索、知识库访问
- 数据分析: 数据库查询、报表生成
- 工作流自动化: 任务调度、流程管理
- 多模态应用: 文件处理、图像分析
- API网关: 统一外部服务访问
Q12: 如何调试MCP Server?
答案要点:
import logging
from mcp.server.stdio import stdio_server# 配置详细日志
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)class DebuggableMCPServer:async def debug_mode_start(self):# 启用详细日志self.server.debug = True# 添加请求/响应日志@self.server.middlewareasync def log_requests(request, handler):logger.debug(f"收到请求: {request}")response = await handler(request)logger.debug(f"返回响应: {response}")return response
Q13: MCP Server如何处理大文件?
答案要点:
class LargeFileHandler:async def stream_large_file(self, file_path: str):chunk_size = 8192async with aiofiles.open(file_path, 'rb') as f:while chunk := await f.read(chunk_size):yield chunkasync def handle_large_resource(self, uri: str):if self._is_large_file(uri):return StreamingResponse(self.stream_large_file(uri),media_type='application/octet-stream')else:return await self._read_normal_file(uri)
5.5. 设计模式类问题
Q14: MCP中常用的设计模式有哪些?
答案要点:
- 工厂模式: 创建不同类型的Resources和Tools
- 适配器模式: 适配不同的外部API
- 策略模式: 不同的认证策略、缓存策略
- 观察者模式: 资源变更通知
- 装饰器模式: 中间件、权限检查
# 工厂模式示例
class ResourceFactory:@staticmethoddef create_resource(resource_type: str, config: dict) -> BaseResource:if resource_type == "file":return FileResource(config['path'])elif resource_type == "database":return DatabaseResource(config['connection_string'])elif resource_type == "api":return APIResource(config['endpoint'])else:raise ValueError(f"未知资源类型: {resource_type}")
Q15: 如何测试MCP Server?
答案要点:
import pytest
from mcp.client.stdio import stdio_clientclass TestMCPServer:@pytest.fixtureasync def client(self):server_command = ["python", "my_server.py"]session = await stdio_client(server_command)await session.initialize()yield sessionawait session.close()async def test_list_resources(self, client):resources = await client.list_resources()assert len(resources) > 0assert resources[0].name is not Noneasync def test_tool_execution(self, client):result = await client.call_tool("echo", {"text": "hello"})assert "hello" in result[0].text
5.6. 面试高频问题
Q16: MCP与函数调用(Function Calling)的区别?
答案要点:
- 协议层面: MCP是完整的协议规范,Function Calling是功能特性
- 标准化: MCP提供统一标准,Function Calling各家实现不同
- 资源管理: MCP有Resources概念,Function Calling只有函数
- 生态系统: MCP构建完整生态,Function Calling相对独立
Q17: 生产环境部署MCP Server需要注意什么?
答案要点:
- 监控告警: 性能指标、错误率监控
- 日志管理: 结构化日志、日志轮转
- 容器化: Docker部署,环境隔离
- 负载均衡: 多实例部署,流量分发
- 安全加固: 网络安全、访问控制
- 备份恢复: 数据备份、灾难恢复计划
Q18: MCP的未来发展趋势?
答案要点:
- 生态扩展: 更多工具和服务支持MCP
- 性能优化: 更高效的传输协议和序列化
- 安全增强: 更完善的安全机制
- 标准统一: 成为AI工具集成的行业标准
- 多模态支持: 更好的多模态数据处理能力
5.7. 实战经验类问题
Q19: 遇到MCP连接问题如何排查?
排查步骤:
- 检查进程状态: MCP Server是否正常运行
- 查看日志: stdio、网络连接日志
- 测试连通性: 使用简单客户端测试
- 验证协议: 检查消息格式是否正确
- 权限检查: 文件访问、网络权限
Q20: 如何设计一个高可用的MCP服务?
设计要点:
- 多实例部署: 避免单点故障
- 健康检查: 实现health check接口
- 故障转移: 自动切换到备用实例
- 数据同步: 多实例间数据一致性
- 监控报警: 实时监控服务状态