机器学习知识图谱——K-means++聚类算法
目录
一、图解K-means++ 聚类算法知识图谱
二、K-means 是什么?
三、K-means++ 是什么?
四、K-means++ 算法流程
第一步:选择初始质心(核心改进)
第二步:执行 K-means 正式流程
五、算法图示
六、优点 vs 缺点
七、常用场景
八、Python 代码示例 (使用 sklearn)
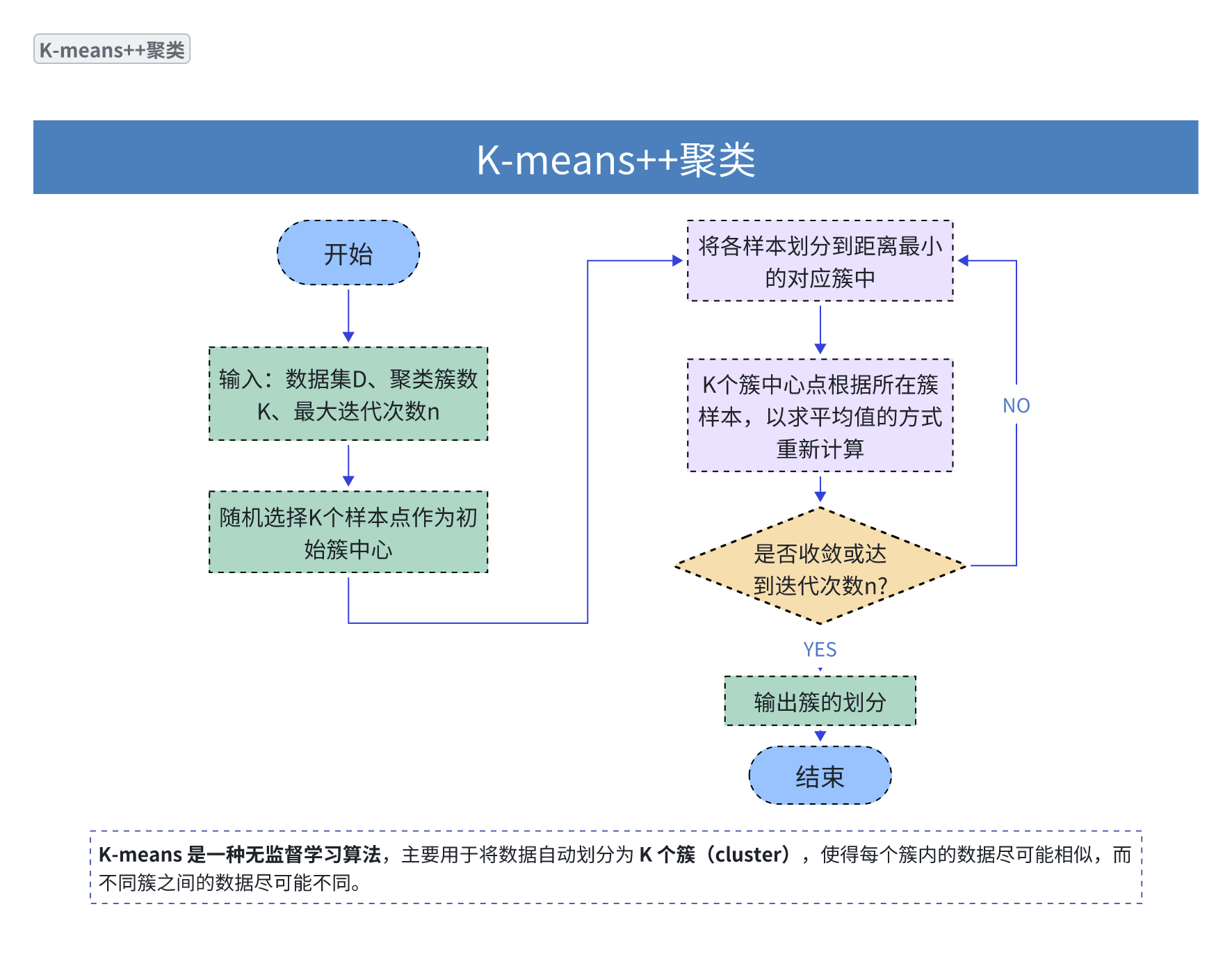
一、图解K-means++ 聚类算法知识图谱
这张图片展示的是 K-means++ 聚类算法的流程图。K-means++ 是 K-means 算法的一种改进,主要改进了初始质心(簇中心)的选择方式,以避免陷入局部最优解。
下面是流程图的详细解释:
1.开始(Start): 算法的起始点。
2.输入(Input):
-
数据集 D: 待聚类的数据。
-
聚类簇数 K: 希望将数据分成多少个簇。
-
最大迭代次数 n: 算法允许运行的最大迭代次数,用于防止无限循环。
3.随机选择 K 个样本点作为初始簇中心(Initialization of Centroids):
-
这是 K-means++ 相对于标准 K-means 的关键改进点。它不是完全随机选择初始质心,而是采用一种更智能的策略,使得初始质心之间尽可能地分散,从而提高了算法收敛到更好聚类结果的可能性。
4.将各样本划分到距离最小的对应簇中(Assignment Step):
-
对于数据集中的每个样本点,计算它到所有 K 个簇中心的距离。
-
将该样本点分配到距离最近的簇中心所代表的簇中。
5.K 个簇中心根据所在簇样本,以求平均值的方式重新计算(Update Step):
-
一旦所有样本都被分配到簇中,重新计算每个簇的中心。
-
新的簇中心是该簇中所有样本点的平均值(或重心)。
6.是否收敛或达到迭代次数 n? (Convergence Check):
-
检查算法是否达到终止条件:
-
收敛(Convergence): 簇中心在本次迭代中不再发生显著变化(即,簇中心的位置基本稳定)。
-
达到最大迭代次数 n: 算法已经运行了预设的最大迭代次数。
-
-
如果满足其中一个条件,则算法停止;否则,返回步骤4继续迭代。
7.输出簇的划分(Output):
-
当算法终止时,输出数据样本最终被划分到各个簇的结果。
7.结束(End): 算法的终止点。
总结来说,K-means++ 聚类算法通过改进初始簇中心的选择,然后迭代地执行样本分配和簇中心更新,直到收敛或达到最大迭代次数,从而完成数据的聚类。