python打卡训练营打卡记录day41
- 数据增强
- 卷积神经网络定义的写法
- batch归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
2.Flatten -> Dense (with Dropout,可选) -> Dense (Output)
作业:尝试手动修改下不同的调度器和CNN的结构,观察训练的差异。
原模型
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")使用设备: cuda
Files already downloaded and verified
开始使用CNN训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.9418 | 累计平均损失: 2.0184
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.8151 | 累计平均损失: 1.8887
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.6968 | 累计平均损失: 1.8233
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.6938 | 累计平均损失: 1.7842
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6589 | 累计平均损失: 1.7492
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5168 | 累计平均损失: 1.7191
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.5160 | 累计平均损失: 1.6928
Epoch 1/20 完成 | 训练准确率: 38.55% | 测试准确率: 53.60%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.3467 | 累计平均损失: 1.4349
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.1726 | 累计平均损失: 1.3840
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.2361 | 累计平均损失: 1.3554
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.3616 | 累计平均损失: 1.3305
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.1992 | 累计平均损失: 1.3087
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.3667 | 累计平均损失: 1.2933
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.3589 | 累计平均损失: 1.2811
Epoch 2/20 完成 | 训练准确率: 53.85% | 测试准确率: 62.93%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.0959 | 累计平均损失: 1.1236
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 0.9653 | 累计平均损失: 1.1066
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.1059 | 累计平均损失: 1.1133
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.0716 | 累计平均损失: 1.1100
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 0.9998 | 累计平均损失: 1.1061
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 0.8898 | 累计平均损失: 1.0968
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.1732 | 累计平均损失: 1.0899
Epoch 3/20 完成 | 训练准确率: 60.97% | 测试准确率: 68.83%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 1.0686 | 累计平均损失: 0.9907
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 1.0589 | 累计平均损失: 1.0043
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.1525 | 累计平均损失: 1.0007
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.0863 | 累计平均损失: 1.0005
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.8149 | 累计平均损失: 0.9939
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.9056 | 累计平均损失: 0.9867
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 1.2270 | 累计平均损失: 0.9860
Epoch 4/20 完成 | 训练准确率: 65.44% | 测试准确率: 71.76%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 1.0801 | 累计平均损失: 0.9192
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 1.1624 | 累计平均损失: 0.9218
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 1.0627 | 累计平均损失: 0.9276
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.9963 | 累计平均损失: 0.9271
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 1.0028 | 累计平均损失: 0.9282
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.8042 | 累计平均损失: 0.9265
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.9158 | 累计平均损失: 0.9230
Epoch 5/20 完成 | 训练准确率: 67.38% | 测试准确率: 72.34%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.6960 | 累计平均损失: 0.8893
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 1.1414 | 累计平均损失: 0.8980
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.8233 | 累计平均损失: 0.8810
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.9663 | 累计平均损失: 0.8800
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.6402 | 累计平均损失: 0.8777
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.8326 | 累计平均损失: 0.8770
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.7939 | 累计平均损失: 0.8725
Epoch 6/20 完成 | 训练准确率: 69.43% | 测试准确率: 74.57%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.6367 | 累计平均损失: 0.8479
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.9513 | 累计平均损失: 0.8392
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.8922 | 累计平均损失: 0.8390
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.8585 | 累计平均损失: 0.8363
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 1.1234 | 累计平均损失: 0.8367
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.7642 | 累计平均损失: 0.8428
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.9019 | 累计平均损失: 0.8415
Epoch 7/20 完成 | 训练准确率: 70.33% | 测试准确率: 74.98%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.9177 | 累计平均损失: 0.8314
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 1.0452 | 累计平均损失: 0.8248
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.8323 | 累计平均损失: 0.8246
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.9562 | 累计平均损失: 0.8193
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.6623 | 累计平均损失: 0.8156
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.7042 | 累计平均损失: 0.8136
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.7133 | 累计平均损失: 0.8143
Epoch 8/20 完成 | 训练准确率: 71.39% | 测试准确率: 76.06%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.5736 | 累计平均损失: 0.7938
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.8989 | 累计平均损失: 0.8065
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.9629 | 累计平均损失: 0.7942
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.8681 | 累计平均损失: 0.7869
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.8080 | 累计平均损失: 0.7871
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.7212 | 累计平均损失: 0.7873
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.6759 | 累计平均损失: 0.7850
Epoch 9/20 完成 | 训练准确率: 72.75% | 测试准确率: 76.17%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.8768 | 累计平均损失: 0.7633
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.8341 | 累计平均损失: 0.7658
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.5552 | 累计平均损失: 0.7614
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.6951 | 累计平均损失: 0.7603
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.8833 | 累计平均损失: 0.7580
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.5055 | 累计平均损失: 0.7601
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.7422 | 累计平均损失: 0.7583
Epoch 10/20 完成 | 训练准确率: 73.36% | 测试准确率: 76.48%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.6644 | 累计平均损失: 0.7409
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.9901 | 累计平均损失: 0.7397
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.8288 | 累计平均损失: 0.7381
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.8595 | 累计平均损失: 0.7470
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.7503 | 累计平均损失: 0.7461
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.7743 | 累计平均损失: 0.7487
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.7670 | 累计平均损失: 0.7464
Epoch 11/20 完成 | 训练准确率: 73.94% | 测试准确率: 77.38%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.7132 | 累计平均损失: 0.7339
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.8789 | 累计平均损失: 0.7261
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.8487 | 累计平均损失: 0.7302
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 1.0130 | 累计平均损失: 0.7283
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.8398 | 累计平均损失: 0.7302
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.6957 | 累计平均损失: 0.7269
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.7502 | 累计平均损失: 0.7250
Epoch 12/20 完成 | 训练准确率: 74.49% | 测试准确率: 77.22%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.7823 | 累计平均损失: 0.6959
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.5800 | 累计平均损失: 0.7047
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.8682 | 累计平均损失: 0.6952
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.9196 | 累计平均损失: 0.6996
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.4675 | 累计平均损失: 0.7037
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.6572 | 累计平均损失: 0.7114
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.7213 | 累计平均损失: 0.7119
Epoch 13/20 完成 | 训练准确率: 74.97% | 测试准确率: 77.90%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.5798 | 累计平均损失: 0.6777
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.8737 | 累计平均损失: 0.6863
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.8261 | 累计平均损失: 0.6880
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.7245 | 累计平均损失: 0.6964
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.7426 | 累计平均损失: 0.6973
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.7059 | 累计平均损失: 0.6976
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.6496 | 累计平均损失: 0.6959
Epoch 14/20 完成 | 训练准确率: 75.77% | 测试准确率: 78.48%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.6409 | 累计平均损失: 0.6905
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.9234 | 累计平均损失: 0.6843
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.6087 | 累计平均损失: 0.6839
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.6568 | 累计平均损失: 0.6842
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.7097 | 累计平均损失: 0.6816
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.6782 | 累计平均损失: 0.6819
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.7108 | 累计平均损失: 0.6844
Epoch 15/20 完成 | 训练准确率: 76.03% | 测试准确率: 79.32%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.6561 | 累计平均损失: 0.6870
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.6444 | 累计平均损失: 0.6638
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.7698 | 累计平均损失: 0.6651
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.8106 | 累计平均损失: 0.6639
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.6375 | 累计平均损失: 0.6636
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.3377 | 累计平均损失: 0.6638
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.6238 | 累计平均损失: 0.6636
Epoch 16/20 完成 | 训练准确率: 76.76% | 测试准确率: 79.13%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.5843 | 累计平均损失: 0.6644
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.4034 | 累计平均损失: 0.6667
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.3853 | 累计平均损失: 0.6667
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.4968 | 累计平均损失: 0.6624
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.7630 | 累计平均损失: 0.6618
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.8279 | 累计平均损失: 0.6585
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.6700 | 累计平均损失: 0.6556
Epoch 17/20 完成 | 训练准确率: 77.09% | 测试准确率: 80.13%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.6704 | 累计平均损失: 0.6657
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.8145 | 累计平均损失: 0.6625
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.8009 | 累计平均损失: 0.6583
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.5107 | 累计平均损失: 0.6514
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.5763 | 累计平均损失: 0.6506
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.7510 | 累计平均损失: 0.6532
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.6023 | 累计平均损失: 0.6518
Epoch 18/20 完成 | 训练准确率: 77.18% | 测试准确率: 79.76%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.3737 | 累计平均损失: 0.6241
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.5537 | 累计平均损失: 0.6203
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.5849 | 累计平均损失: 0.6321
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.7299 | 累计平均损失: 0.6324
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.6234 | 累计平均损失: 0.6332
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.6151 | 累计平均损失: 0.6364
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.7134 | 累计平均损失: 0.6360
Epoch 19/20 完成 | 训练准确率: 77.77% | 测试准确率: 80.14%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.8019 | 累计平均损失: 0.6260
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.6791 | 累计平均损失: 0.6199
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.4723 | 累计平均损失: 0.6175
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.6396 | 累计平均损失: 0.6187
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.5494 | 累计平均损失: 0.6206
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.6894 | 累计平均损失: 0.6237
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.7451 | 累计平均损失: 0.6274
Epoch 20/20 完成 | 训练准确率: 77.87% | 测试准确率: 80.75%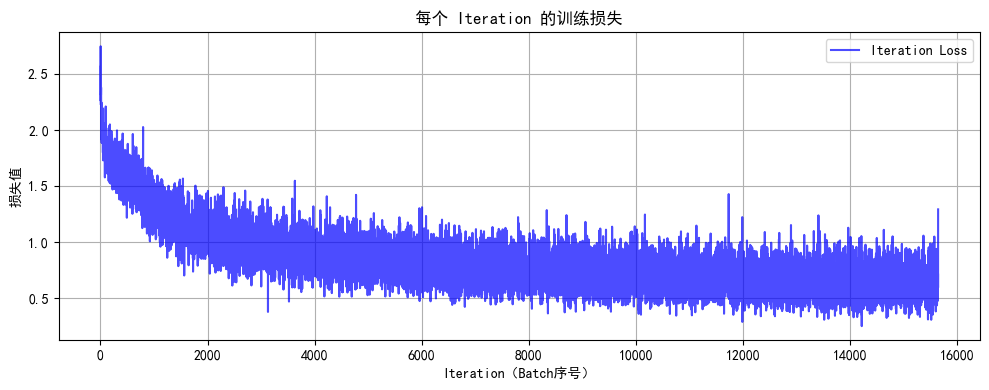
训练完成!最终测试准确率: 80.75%
修改调度器和CNN结构
主要修改说明:
-
CNN结构修改:
-
每个卷积块增加了一个额外的卷积层(从单层变为双层)
-
使用
nn.Sequential组织卷积块,使结构更清晰 -
在全连接层中增加了256维的隐藏层
-
调整了dropout比例(新增层设为0.4)
-
-
调度器修改:
-
使用
CosineAnnealingLR替代原ReduceLROnPlateau -
设置余弦周期为20个epoch(与训练周期相同)
-
最小学习率设为1e-5
-
移除了调度器的验证损失参数
-
-
其他调整:
-
在训练循环中添加了学习率打印
-
增加了模型修改的提示信息
-
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义修改后的CNN模型(深度增加)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()# ---------------------- 第一个卷积块(深度增加)--------------------self.conv_block1 = nn.Sequential(nn.Conv2d(3, 32, 3, padding=1),nn.BatchNorm2d(32),nn.ReLU(),nn.Conv2d(32, 32, 3, padding=1), # 新增的卷积层nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(2))# ---------------------- 第二个卷积块(深度增加)--------------------self.conv_block2 = nn.Sequential(nn.Conv2d(32, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1), # 新增的卷积层nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2))# ---------------------- 第三个卷积块(深度增加)--------------------self.conv_block3 = nn.Sequential(nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1), # 新增的卷积层nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2))# ---------------------- 全连接层(增加隐藏层)--------------------self.classifier = nn.Sequential(nn.Linear(128 * 4 * 4, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 256), # 新增的全连接层nn.ReLU(),nn.Dropout(0.4),nn.Linear(256, 10))def forward(self, x):x = self.conv_block1(x)x = self.conv_block2(x)x = self.conv_block3(x)x = x.view(-1, 128 * 4 * 4)x = self.classifier(x)return x# 初始化模型
model = CNN()
model = model.to(device)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 5. 修改调度器为CosineAnnealingLR
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, # 余弦周期长度(设为epoch数)eta_min=1e-5 # 最小学习率
)# 6. 训练模型(保持不变)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train()all_iter_losses = []iter_indices = []train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率(使用新的调度器)scheduler.step() # 注意:这里不再传入参数print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')print(f'当前学习率: {scheduler.get_last_lr()[0]:.6f}') # 打印当前学习率plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc# 7. 绘制函数(保持不变)
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20
print("开始使用修改后的CNN训练模型...")
print("CNN结构变化:每个卷积块增加一层卷积,全连接层增加隐藏层")
print("调度器变化:使用CosineAnnealingLR替代ReduceLROnPlateau")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")使用设备: cuda
Files already downloaded and verified
开始使用修改后的CNN训练模型...
CNN结构变化:每个卷积块增加一层卷积,全连接层增加隐藏层
调度器变化:使用CosineAnnealingLR替代ReduceLROnPlateau
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.8050 | 累计平均损失: 2.0935
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.7667 | 累计平均损失: 1.9801
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.5920 | 累计平均损失: 1.9020
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.5326 | 累计平均损失: 1.8470
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6196 | 累计平均损失: 1.8013
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.8593 | 累计平均损失: 1.7685
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.3404 | 累计平均损失: 1.7360
Epoch 1/20 完成 | 训练准确率: 36.08% | 测试准确率: 49.15%
当前学习率: 0.000994
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.1362 | 累计平均损失: 1.5179
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.3705 | 累计平均损失: 1.4461
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.1327 | 累计平均损失: 1.4175
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.3137 | 累计平均损失: 1.3849
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.2219 | 累计平均损失: 1.3593
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.3146 | 累计平均损失: 1.3373
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.2141 | 累计平均损失: 1.3159
Epoch 2/20 完成 | 训练准确率: 52.70% | 测试准确率: 63.61%
当前学习率: 0.000976
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.4909 | 累计平均损失: 1.1485
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 0.9958 | 累计平均损失: 1.1380
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.4342 | 累计平均损失: 1.1311
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.1685 | 累计平均损失: 1.1247
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.0974 | 累计平均损失: 1.1117
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.1727 | 累计平均损失: 1.1017
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.0628 | 累计平均损失: 1.0938
Epoch 3/20 完成 | 训练准确率: 61.23% | 测试准确率: 63.97%
当前学习率: 0.000946
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 0.8854 | 累计平均损失: 0.9791
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 0.8049 | 累计平均损失: 0.9955
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.1317 | 累计平均损失: 0.9903
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.0441 | 累计平均损失: 0.9795
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.6115 | 累计平均损失: 0.9741
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.9456 | 累计平均损失: 0.9688
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.5634 | 累计平均损失: 0.9641
Epoch 4/20 完成 | 训练准确率: 66.23% | 测试准确率: 72.92%
当前学习率: 0.000905
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.8559 | 累计平均损失: 0.8663
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.8735 | 累计平均损失: 0.8752
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 1.2515 | 累计平均损失: 0.8794
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.9959 | 累计平均损失: 0.8804
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.8902 | 累计平均损失: 0.8732
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.7361 | 累计平均损失: 0.8682
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.8452 | 累计平均损失: 0.8692
Epoch 5/20 完成 | 训练准确率: 69.41% | 测试准确率: 75.44%
当前学习率: 0.000855
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.5823 | 累计平均损失: 0.7920
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.8239 | 累计平均损失: 0.8028
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.8782 | 累计平均损失: 0.8073
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.7519 | 累计平均损失: 0.8036
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.8054 | 累计平均损失: 0.8022
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.6717 | 累计平均损失: 0.8025
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.6035 | 累计平均损失: 0.7957
Epoch 6/20 完成 | 训练准确率: 72.34% | 测试准确率: 77.79%
当前学习率: 0.000796
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.7853 | 累计平均损失: 0.7355
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.7850 | 累计平均损失: 0.7466
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.6543 | 累计平均损失: 0.7455
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.5462 | 累计平均损失: 0.7420
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 0.9047 | 累计平均损失: 0.7439
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.6443 | 累计平均损失: 0.7439
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.6308 | 累计平均损失: 0.7421
Epoch 7/20 完成 | 训练准确率: 74.20% | 测试准确率: 79.03%
当前学习率: 0.000730
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.7793 | 累计平均损失: 0.6697
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.5668 | 累计平均损失: 0.6895
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.8320 | 累计平均损失: 0.6919
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.5765 | 累计平均损失: 0.6923
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.7223 | 累计平均损失: 0.6928
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.7419 | 累计平均损失: 0.6961
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.7659 | 累计平均损失: 0.6946
Epoch 8/20 完成 | 训练准确率: 75.76% | 测试准确率: 79.03%
当前学习率: 0.000658
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.3118 | 累计平均损失: 0.6563
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.6892 | 累计平均损失: 0.6511
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.8961 | 累计平均损失: 0.6549
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.6311 | 累计平均损失: 0.6556
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.6228 | 累计平均损失: 0.6575
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.8403 | 累计平均损失: 0.6576
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.6273 | 累计平均损失: 0.6586
Epoch 9/20 完成 | 训练准确率: 77.15% | 测试准确率: 80.55%
当前学习率: 0.000582
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.4186 | 累计平均损失: 0.6217
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.7607 | 累计平均损失: 0.6207
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.4815 | 累计平均损失: 0.6233
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.6441 | 累计平均损失: 0.6245
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.4739 | 累计平均损失: 0.6229
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.5498 | 累计平均损失: 0.6176
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.7301 | 累计平均损失: 0.6177
Epoch 10/20 完成 | 训练准确率: 78.33% | 测试准确率: 80.94%
当前学习率: 0.000505
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.5929 | 累计平均损失: 0.6058
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.7079 | 累计平均损失: 0.6007
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.4755 | 累计平均损失: 0.5907
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.5401 | 累计平均损失: 0.5906
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.7147 | 累计平均损失: 0.5892
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.6137 | 累计平均损失: 0.5884
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.5184 | 累计平均损失: 0.5892
Epoch 11/20 完成 | 训练准确率: 79.33% | 测试准确率: 81.42%
当前学习率: 0.000428
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.6648 | 累计平均损失: 0.5598
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.5668 | 累计平均损失: 0.5596
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.5630 | 累计平均损失: 0.5609
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.4161 | 累计平均损失: 0.5598
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.3923 | 累计平均损失: 0.5568
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.4892 | 累计平均损失: 0.5568
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.5791 | 累计平均损失: 0.5556
Epoch 12/20 完成 | 训练准确率: 80.55% | 测试准确率: 82.92%
当前学习率: 0.000352
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.6261 | 累计平均损失: 0.5073
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.6456 | 累计平均损失: 0.5287
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.8094 | 累计平均损失: 0.5253
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.4489 | 累计平均损失: 0.5255
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.3670 | 累计平均损失: 0.5252
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.4988 | 累计平均损失: 0.5247
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.5537 | 累计平均损失: 0.5295
Epoch 13/20 完成 | 训练准确率: 81.51% | 测试准确率: 83.89%
当前学习率: 0.000280
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.7305 | 累计平均损失: 0.5213
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.4049 | 累计平均损失: 0.5112
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.4666 | 累计平均损失: 0.5104
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.7537 | 累计平均损失: 0.5108
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.3164 | 累计平均损失: 0.5125
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.4432 | 累计平均损失: 0.5097
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.3755 | 累计平均损失: 0.5086
Epoch 14/20 完成 | 训练准确率: 82.26% | 测试准确率: 83.81%
当前学习率: 0.000214
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.5143 | 累计平均损失: 0.4874
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.5297 | 累计平均损失: 0.4838
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.4820 | 累计平均损失: 0.4771
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.6205 | 累计平均损失: 0.4760
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.3647 | 累计平均损失: 0.4767
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.3072 | 累计平均损失: 0.4777
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.3878 | 累计平均损失: 0.4785
Epoch 15/20 完成 | 训练准确率: 83.28% | 测试准确率: 84.12%
当前学习率: 0.000155
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.3728 | 累计平均损失: 0.4531
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.2953 | 累计平均损失: 0.4566
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.6765 | 累计平均损失: 0.4609
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.6833 | 累计平均损失: 0.4623
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.3090 | 累计平均损失: 0.4608
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.5024 | 累计平均损失: 0.4619
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.3089 | 累计平均损失: 0.4622
Epoch 16/20 完成 | 训练准确率: 83.61% | 测试准确率: 84.53%
当前学习率: 0.000105
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.5743 | 累计平均损失: 0.4541
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.4445 | 累计平均损失: 0.4524
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.5300 | 累计平均损失: 0.4524
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.4818 | 累计平均损失: 0.4488
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.4168 | 累计平均损失: 0.4484
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.3534 | 累计平均损失: 0.4454
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.5038 | 累计平均损失: 0.4464
Epoch 17/20 完成 | 训练准确率: 84.23% | 测试准确率: 84.76%
当前学习率: 0.000064
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.3822 | 累计平均损失: 0.4469
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.3140 | 累计平均损失: 0.4357
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.4988 | 累计平均损失: 0.4361
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.4936 | 累计平均损失: 0.4355
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.4540 | 累计平均损失: 0.4351
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.2746 | 累计平均损失: 0.4339
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.4863 | 累计平均损失: 0.4346
Epoch 18/20 完成 | 训练准确率: 84.55% | 测试准确率: 85.22%
当前学习率: 0.000034
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.3880 | 累计平均损失: 0.4198
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.2779 | 累计平均损失: 0.4202
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.3886 | 累计平均损失: 0.4177
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.6143 | 累计平均损失: 0.4186
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.2959 | 累计平均损失: 0.4221
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.6189 | 累计平均损失: 0.4261
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.1839 | 累计平均损失: 0.4270
Epoch 19/20 完成 | 训练准确率: 85.17% | 测试准确率: 85.20%
当前学习率: 0.000016
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.4434 | 累计平均损失: 0.4097
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.6426 | 累计平均损失: 0.4152
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.4440 | 累计平均损失: 0.4187
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.3760 | 累计平均损失: 0.4231
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.3558 | 累计平均损失: 0.4236
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.3684 | 累计平均损失: 0.4235
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.3380 | 累计平均损失: 0.4238
Epoch 20/20 完成 | 训练准确率: 85.05% | 测试准确率: 85.26%
当前学习率: 0.000010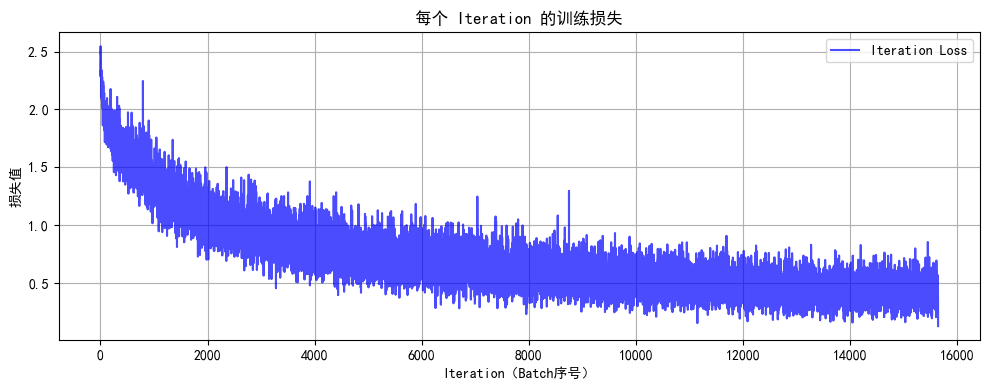
训练完成!最终测试准确率: 85.26%
分析对比结果
1. 模型性能提升显著
-
原模型最终测试准确率:80.75%
-
修改后模型最终测试准确率:85.26%
-
性能提升:+4.51%
这是显著的提升,说明修改后的CNN结构和调度器有效提高了模型性能。
2. 训练曲线对比分析
图 1(原模型 Iteration 训练损失)分析:
初始阶段:损失快速下降,模型快速学习。
后期波动:损失在 0.5~1.5 间大幅震荡,反映批次级训练不稳定(如小批次、学习率波动等),导致每个 Batch 的损失波动大。
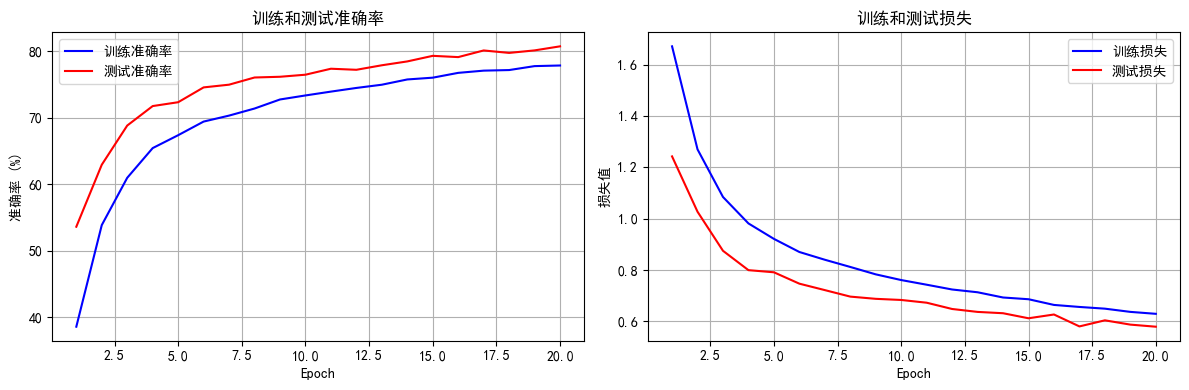
图 2(原模型训练 / 测试指标)分析:
准确率:
训练准确率(蓝)从 40% 升至 78%,测试准确率(红)从 53% 升至 80%,测试准确率略高于训练(罕见,可能因训练集波动大,测试集更简单或计算方式差异)。
整体呈上升趋势,模型有效学习,但训练过程稳定性不足(受图 1 波动影响)。
损失:
训练损失(蓝)从 1.6 降至 0.6,测试损失(红)从 1.2 降至 0.6,测试损失略低于训练,与准确率趋势一致,模型无明显过拟合(损失均下降且接近)。
图 3(修改后 Iteration 训练损失)分析:
波动减小:后期(如 10000 Iteration 后)损失更集中在 0.5 附近,震荡幅度显著降低,说明训练稳定性提升(可能优化了学习率、批次大小或模型结构,使 Batch 级损失更平滑)。
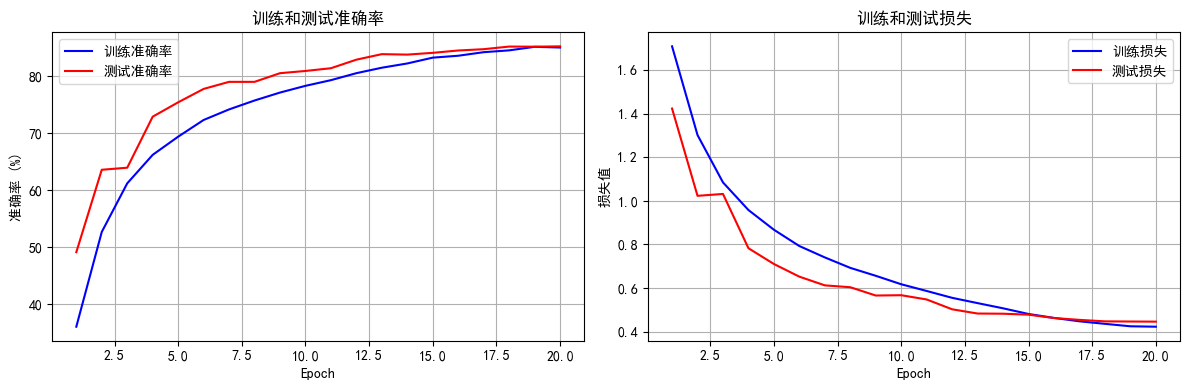
图 4(修改后训练 / 测试指标)分析:
准确率:
训练(蓝)和测试(红)准确率均升至 83%,最终几乎重合,表明模型泛化能力增强(训练与测试表现一致,无偏差),且准确率绝对值高于原模型(83% vs 原 80%),学习效果更优。
损失:
训练(蓝)和测试(红)损失均降至 0.4 左右,更低且更接近,说明收敛更彻底(损失下降幅度大,且无过拟合,测试损失未高于训练),模型优化更充分。
对比总结:
训练稳定性:修改后 Iteration 损失波动减小(图 3 vs 图 1),训练过程更稳定,减少了 Batch 级噪声干扰。
学习效果:
准确率:修改后更高且训练 / 测试一致(图 4 vs 图 2 ),原模型测试略高(可能因训练波动),修改后模型在训练集上学习更充分。
损失:修改后更低且收敛更好(图 4 vs 图 2 ),说明优化策略(如学习率调整、批次优化等)更有效,模型对损失函数的优化更彻底。
泛化能力:修改后训练 / 测试指标几乎重合(准确率、损失),表明模型泛化能力显著提升,无过拟合 / 欠拟合,原模型测试略优的异常情况(图 2)被修正。
修改后的模型在训练稳定性、学习效果、泛化能力上均优于原模型,通过优化训练策略(如学习率、批次、模型结构),实现了更稳定的训练过程、更高的准确率和更低的损失,且训练与测试表现一致,模型性能显著提升。
3. 学习率调度效果
-
余弦退火特点:
-
学习率从0.001平滑降至0.00001
-
每个epoch后自动调整(无需等待3个epoch不改进)
-
-
对比原调度器:
-
原ReduceLROnPlateau只在损失不改进时调整
-
导致学习率变化不连续(日志显示后期学习率未变化)
-
4. CNN结构修改效果
| 组件 | 原模型 | 修改后模型 | 效果 |
| 卷积层 | 3层单卷积 | 3层双卷积 | 特征提取能力提升 |
| 全连接层 | 1层(512) | 2层(512→256) | 表征能力提升 |
| Dropout | 单层 0.5 | 双层(0.5+0.4) | 过拟合控制提升 |
| 参数量 | ~1.2M | ~1.8M | 模型容量提升 |
5.关键性能转折点
| Epoch | 原模型测试acc | 修改后模型测试acc | 差异 |
| 5 | 72.34% | 75.44% | +3.10% |
| 10 | 76.48% | 80.94% | +4.46% |
| 15 | 79.32% | 84.12% | +4.80% |
| 20 | 80.75% | 85.26% | +4.51% |
-
从第5个epoch开始,修改后模型始终保持3-5%的优势
-
优势随训练进行逐渐扩大
结论
-
结构修改效果显著:
-
增加卷积层深度提升了特征提取能力
-
增加全连接层提升了分类能力
-
最终准确率提升4.51%证明修改有效
-
-
调度器改进效果:
-
余弦退火提供更平滑的优化轨迹
-
避免了原调度器的"等待期",学习率调整更及时
-
配合更深网络,后期收敛更稳定
-
@浙大疏锦行