说一说SAP系统从Non-Unicode到Unicode的演化
当前的 SAP 系统基本上都是 Unicode 系统。然而,在 SAP 的发展过程中,最初并不是 Unicode 系统,而是 Non-Unicode 系统。
1. 什么是 Non-Unicode 和 Unicode?
-
Non-Unicode 系统:
- 在 Non-Unicode 系统中,字符存储和表示是基于特定的
编码页面(Code Page)的,每个页面支持一组有限的字符。这种编码方式通常是针对一种语言或一组相关语言的。 - 比如 ASCII、Latin-1 (适用于西欧语言) 或 Shift-JIS (适用于日语) 等编码页面。
- 对于多语言支持的需求,Non-Unicode 系统通常
需要区分不同语言环境,并选择匹配的编码,这使得多语言处理变得复杂且容易出错。
- 在 Non-Unicode 系统中,字符存储和表示是基于特定的
-
Unicode 系统:
- Unicode 是一种
全球标准,能够用统一的编码表示多种语言字符,包括各种语言、特殊符号、表情符号等。 - 它解决了 Non-Unicode 系统中的
多语言兼容问题。 - 常见的 Unicode 编码包括 UTF-8、UTF-16 和 UTF-32。SAP 的 Unicode 系统通常基于
UTF-16。
- Unicode 是一种
2. SAP 系统的早期历史:Non-Unicode 系统
- SAP R/3 和更早的版本最初是基于 Non-Unicode 的架构设计的,因为当时 Unicode 尚未普及,多语言系统的需求尚未那么强烈。
- 在 Non-Unicode 系统中,SAP 使用了 Code Page 的概念,每种特定语言或语言组都有对应的编码页面。例如:
- Code Page 1100:支持 ASCII 和基本西欧语言。
- Code Page 8000:日语编码。
- 如果客户需要支持多国语言,就需要安装不同的编码页面(多 Code Page 环境)。
Non-Unicode 系统的限制:
- 多语言处理复杂: 在多语言环境中,AWS(应用服务器)必须切换编码页面,这可能导致数据丢失或编码冲突。
- 全球化支持困难: 一些语言或字符集无法被 Non-Unicode 系统支持,比如汉字、阿拉伯文等在一个系统中共存会出现挑战。
- 与其他系统的集成问题: 不同系统之间的数据交换可能因为编码不一致而导致错误。
- 维护成本高: 在 Non-Unicode 系统的多 Code Page 环境下,管理员需要花费更多时间处理字符集问题。
3. 向 Unicode 系统的演化
随着全球化业务的发展以及 Unicode 标准的普及,SAP 逐渐意识到采用 Unicode 系统的重要性。在 Unicode 系统中,可以一次性满足多语言的需求,而无需依赖复杂的编码页面配置。SAP 在版本发展中逐步引入了 Unicode 的支持:
-
SAP R/3 4.7(2001年):首次提供 Unicode 支持。SAP 允许客户在安装 SAP 系统时选择使用 Unicode 或 Non-Unicode 系统。 此时,Unicode 系统仍然是可选的选项,大多数早期客户依然选择了 Non-Unicode 系统。
-
SAP NetWeaver 系统(SAP Basis 6.20/6.40之后):进一步增强了 Unicode 支持。此时,Unicode 已经成为开发和实施多语言系统的标准推荐。
-
SAP S/4HANA 系统: 从 SAP HANA 和 S/4HANA 开始,SAP 系统完全基于 Unicode 编码架构,不再支持 Non-Unicode 系统。SAP 强制要求客户在转移到新的平台(例如 S/4HANA)时必须完成 Unicode 转换(Unicode Conversion)。
4. Unicode 系统的优势
- 多语言支持: 使用 Unicode 的 SAP 系统可以同时处理跨语言的字符集,而无需担心数据丢失或编码冲突。
- 简化系统维护: 因为不需要管理繁杂的编码页面配置,系统更加简化且维护成本更低。
- 增强系统兼容性: Unicode 是广泛采用的国际标准,与其他 Unicode 系统的一致性降低了字符集转换复杂度。
- 全球化业务的支持: 对于需要支持全球多语言的企业来说,Unicode 是唯一切实可行的选择。
5. Non-Unicode 系统迁移到 Unicode 系统的挑战
对于老客户来说,从 Non-Unicode 系统迁移到 Unicode 系统可能涉及到比较复杂的转换过程,具体挑战包括:
- 数据一致性问题: 非 Unicode 系统中存储的多语言数据可能在迁移到 Unicode 系统时出现乱码或不兼容问题。
- 程序调整: ABAP 程序中很多 String 相关的代码可能依赖于固定的字符编码长度(如 2 字节的字符表示),这些需要在 Unicode 环境下进行调整。
- 性能考量: Unicode 系统可能需要更多的存储空间。(例如 UTF-16 通常占用双倍的存储空间。)
- 测试成本: 因为整个转换过程可能涉及核心业务逻辑和数据结构变更,因此需要进行充分的测试以确保数据完整性和业务功能正常。
为了解决这些问题,SAP 提供了一些工具来辅助转换和验证过程。例如:
- SAP Unicode Conversion Tools
- Transaction SPUMG:用于提前分析和处理数据格式问题。
- Transaction SUM:SAP Software Update Manager 支持 Unicode Conversion 合并到系统升级过程。
6. 当前 SAP 系统的 Unicode 状态
- 自 SAP S/4HANA(以及任何基于 SAP HANA 数据库的解决方案)开始,所有 SAP 系统都强制要求是 Unicode 系统,不再支持 Non-Unicode 安装。
- 对于现有老旧 Non-Unicode 系统的客户,SAP 强烈建议首先进行 Unicode Conversion,然后再迁移到现代化的平台(如 S/4HANA)。
如果想快速查看当前SAP系统的Unicode状态,可以通过系统属性查看(Transaction Code: SU01 或 System -> Status)**
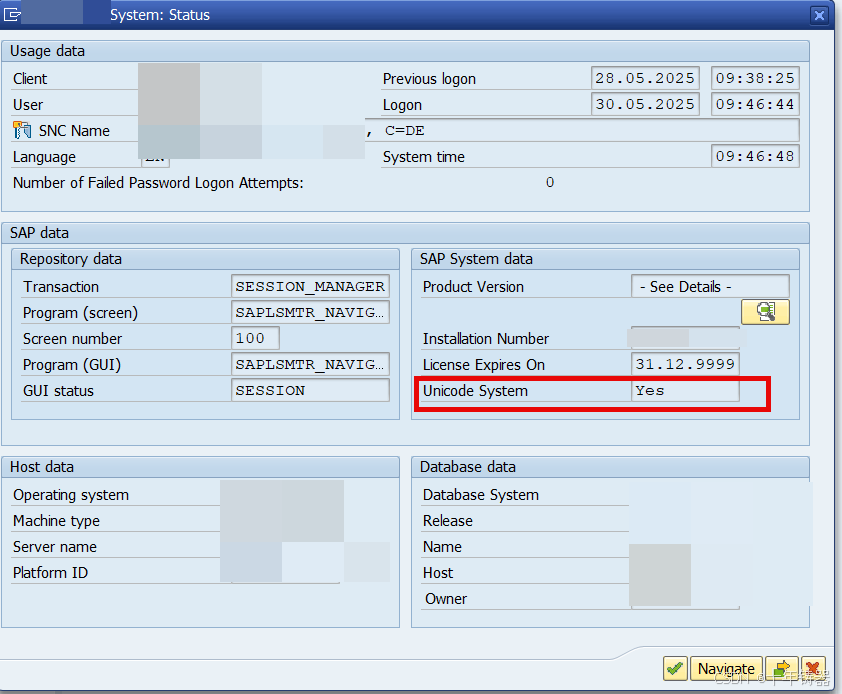
7. SM59中,要注意Unicode 选项配置
在 SAP 系统中,配置 RFC (Remote Function Call) 连接时,Unicode 的选项是一个非常重要的设置,尤其是在涉及跨系统通信的场景下,例如当一个系统是 Unicode 系统,另一个可能是 Non-Unicode 系统时,正确配置 Unicode 选项可以确保字符编码的正确转换和无缝通信。
- SAP 系统可以使用 RFC destination 来连接其他 SAP 系统(或者第三方系统),从而实现远程的函数调用或数据传输。
- 如果两个系统字符编码不一致(即一个系统使用 Unicode,而另一个系统使用 Non-Unicode),则在数据传输过程中可能会因为字符集的不一致而导致乱码或数据错误。
- 为了解决这种问题,SAP 在 RFC destination 中提供了 Unicode 设置选项,用于指定远程系统是否支持 Unicode,并确保正确执行字符编码的转换。
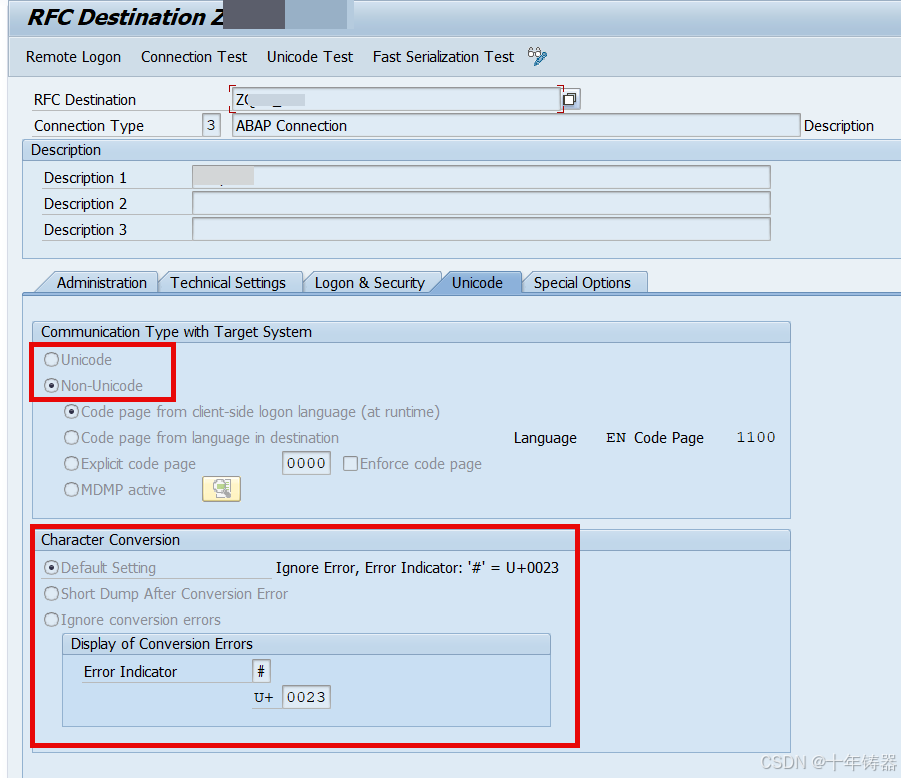
Unicode 选项的含义
在 SM59 的配置界面中,Unicode 相关的选项出现在 RFC destination 的具体设置页面(例如 Connection Test 或 Attributes 页面),通常有以下选项:
-
Communication type(通讯方式):
Non-Unicode System:表示远程系统是 Non-Unicode 系统。Unicode System:表示远程系统是 Unicode 系统。
-
Character conversion(编码转换):
- 当启用此选项时,SAP 会根据源系统和目标系统的 Unicode 状态,自动将字符编码从源系统的编码转换为目标系统的编码。
- 例如,在 Unicode 和 Non-Unicode 系统之间通信时,SAP 可以将 Unicode 转换为相应的 Code Page,或者从指定的 Code Page 转换为 Unicode。
注意: 在 Unicode 与 Unicode 系统之间通信时,此选项通常无关紧要,因为两者的编码一致。
Unicode 相关选项
-
目标系统是 Unicode 系统:
- 如果目标系统是 Unicode 系统,则在 RFC 配置中,应该选择 Unicode System。
- 这将启用 Unicode 环境下的通信,同时避免不必要的字符编码转换。
-
目标系统是 Non-Unicode 系统:
- 如果目标系统是 Non-Unicode 系统,则应选择 Non-Unicode System。
- 这样配置可以让源系统根据目标系统的字符编码,自动调整字符编码(从 Unicode 转换为目标系统的 Code Page 编码)。