两阶段uplift建模(因果估计+预算分配)的讲座与自己动手实践(一)
来自分享嘉宾在datafun论坛的分享,孙泽旭 中国人民大学高瓴人工智能学院 博士生分享的【面向在线营销场景的高效 Uplift 方法】
听讲座听的云里雾里,自己做点力所能及的小实践…
关于uplift笔者之前的博客:
- 因果推断笔记——uplift建模、meta元学习、Class Transformation Method(八)
- 智能营销增益(Uplift Modeling)模型——模型介绍(一)
文章目录
- 1 笔者简单摘录
- 1.1总结Uplift建模方法论
- 1.2 最优性的差距
- 1.3 优化带预算约束的 uplift 场景
- 1.4 二阶段预算分配: 单调性约束
- 1.5 二阶段预算分配: 平滑性约束
- 1.9 一些讲座草稿
- 2 实践案例代码的简单实现
- 2.1 实践步骤一: 数据生成部分
- 2.2 实践步骤2: Uplift效应预估
- 2.3 实践步骤3:基于预算约束的优惠券分配优化
- 2.3.1 约束条件限定
- 2.3.2 不同类型用户四类券的占比分布
- 2.9 代码全部
1 笔者简单摘录
笔者听得时候,是迷迷糊糊的,不明觉厉了…
1.1总结Uplift建模方法论
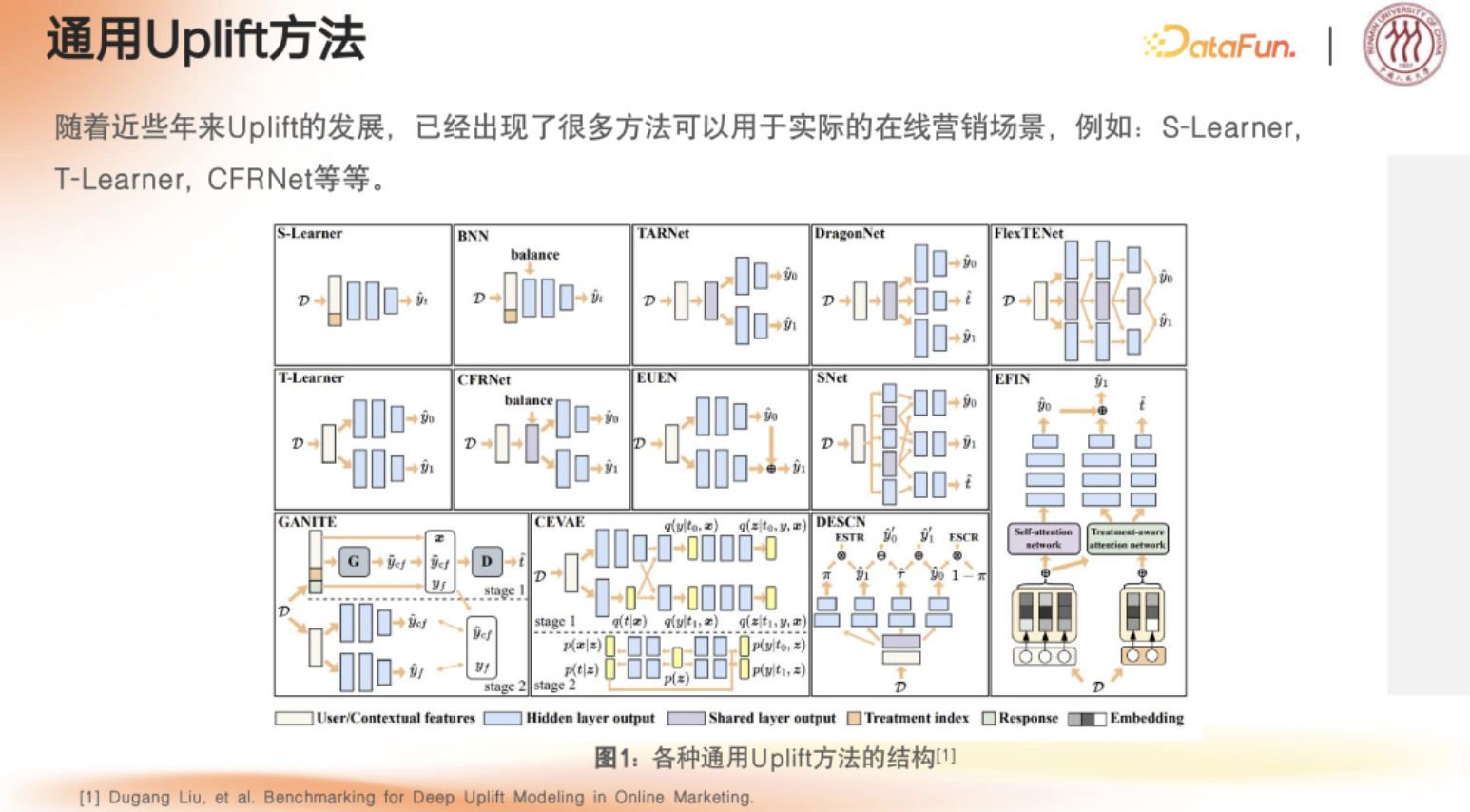
- 早期阶段:以统计模型(S/T-Learner)和简单神经网络(TARNet)为主,侧重基础建模。还有BNN(Bayesian Neural Network),CEVAE(Counterfactual Estimation via Augmented Neural Networks)
- 深度学习兴起:通过对抗训练(DragonNet)、多任务学习(EUEN)等提升性能。DragonNet,FlexTENet,EUEN(Enhanced Uplift Estimation Network), SNet
- 前沿方向:结合 GAN(GANITE)、公平性(EFIN)、结构因果模型(DESCN)等解决复杂问题。比如:GANITE(Generative Adversarial Nets for Estimating Individual Treatment Effects),EFIN(Enhanced Fairness-aware Uplift Network,DESCN(Deep Structural Causal Network)
- 混合与贝叶斯方法:结合传统统计与深度学习,或侧重贝叶斯不确定性量化。CEVAE,BNN
1.2 最优性的差距
两阶段建模最优性差距问题:
- 第一阶段:通过预估模型量化用户响应(uplift效应)的潜在价值
- 第二阶段:基于预算约束进行激励资源的最优分配
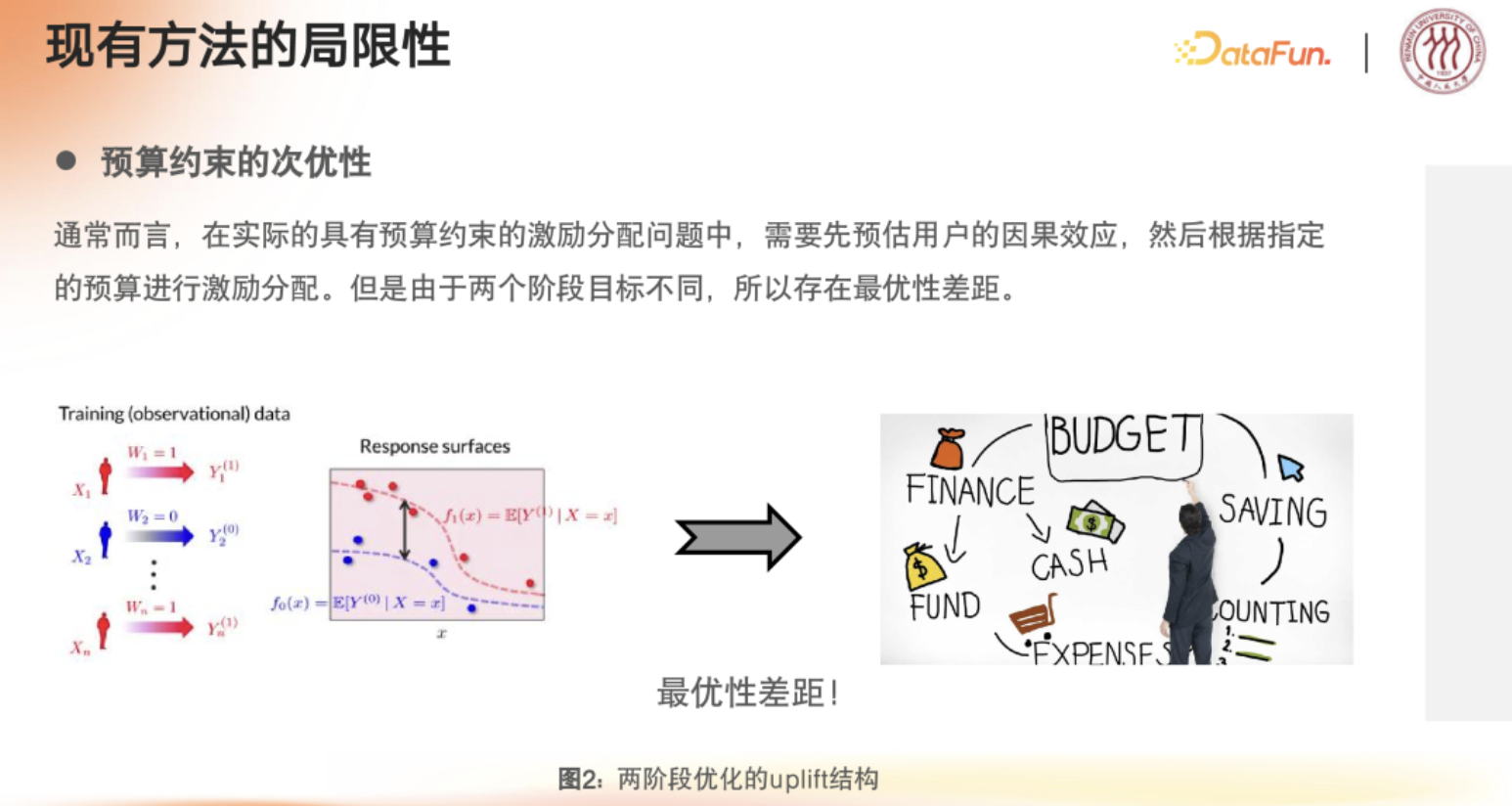
假设模型预测用户A对20元券反应最好,但预算有限,最终只能给A发10元券。这时A的实际反应可能与预测的20元券效果有很大差距,因为模型并没有针对"预算约束下的最优分配"进行端到端训练。
1.3 优化带预算约束的 uplift 场景
两阶段uplift建模存在几个问题:
- 传统方法在处理离散决策变量时可能存在的计算复杂度问题(如整数规划),或基于项目的分配策略导致的次优解风险。
- 两阶段建模导致目标差距
- 预估uplift效应与实际分配存在预测差距
- 分阶段联合建模导致次优解
此时的方案最好就是:做一个端到端的分析,才能够消除这种最优性的差距。
在带预算约束的 uplift 场景中,不仅要考虑收益(revenue uplift),即用户转化收益,同时要考虑用户成本(cost uplift)。
Uplift 的第二阶段往往规划成一个带约束的整数的分配问题。
在预算约束下的分配问题形式:
- 二值场景:分配与否的决策
- 多值场景:分配不同激励级别的优化

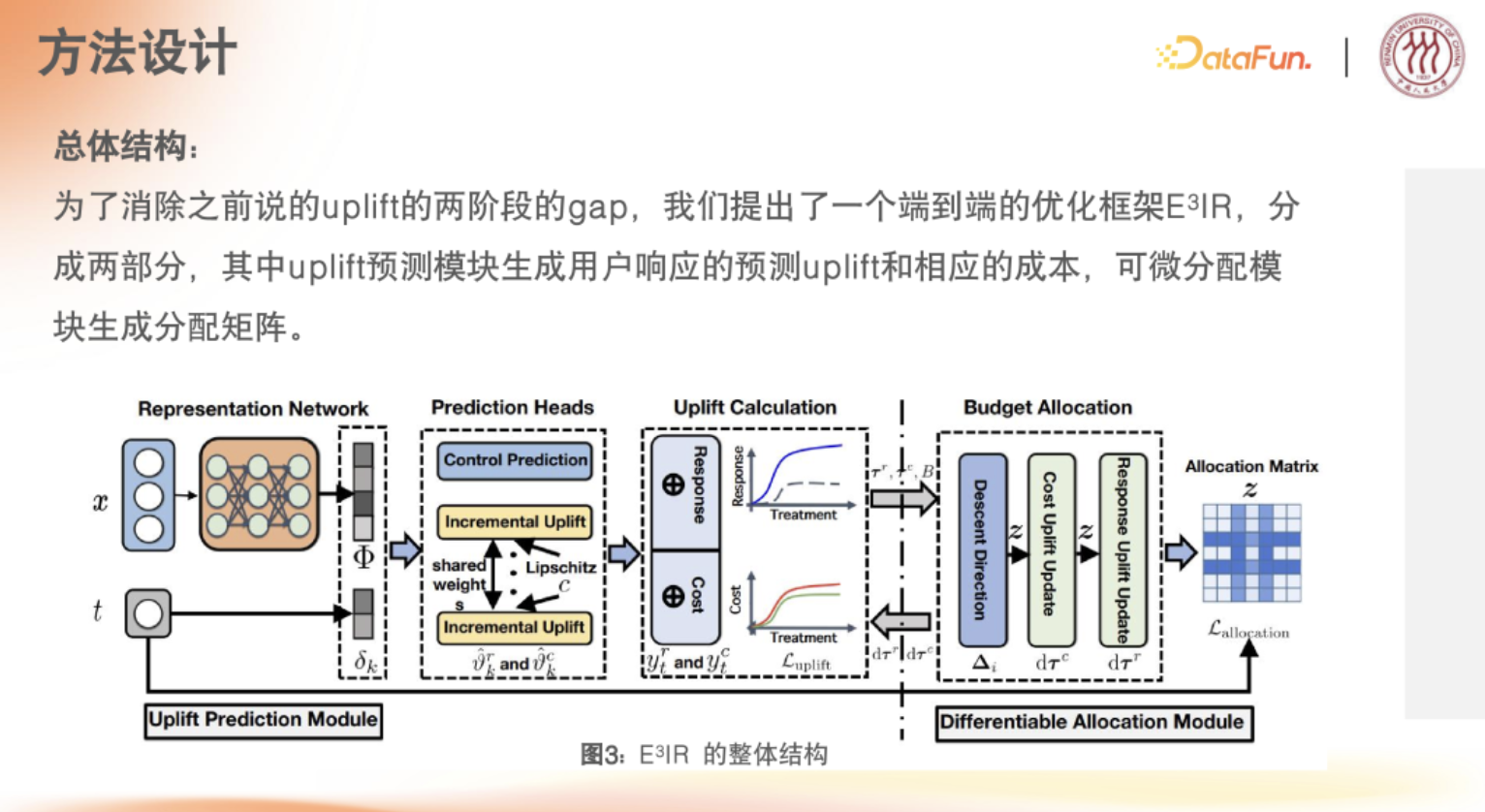
带约束的端到端的联合建模,是为了解决两阶段模块化设计导致的两阶段最优性差距问题。
端到端的优化框架 E3|R,依然分为两个模块:
- 第一模块:uplift 预测用户对不同激励的响应计算(revenue uplift 和 cost uplift)
- 第二模块:基于预测 uplift 结果进行预算计算分配,传导进分配矩阵中,实现梯度计算的设计
1.4 二阶段预算分配: 单调性约束
单调性约束要求优惠券力度与用户消费金额之间保持非递减关系,即更高的优惠券金额应对应更高的最低消费阈值(如"满 10 减 2""满 15 减 3"等)。
正常逻辑:当优惠券金额增加时,用户的实际消费金额应随之增加或保持不变。例如:
- 获得 2 元优惠券时,用户消费 10 元;
- 获得 3 元优惠券时,用户消费 15 元;
- 获得 4 元优惠券时,用户消费应≥20 元(符合常规"满减"规则)。
若出现优惠券金额增加但消费金额反而减少的情况,则违反单调性约束。
例如:获得 4 元优惠券时,用户实际消费 12 元(低于 3 元券对应的 15 元消费)。
1.5 二阶段预算分配: 平滑性约束
例如,若当前可用金额为 20 元,则选择花费 15 元(剩余 5 元)或类似小额消费是合理的;
而若剩余金额为 20 元时,选择花费 100 元则因远超当前预算且违背常规消费认知被排除。
该约束通过限制消费行为的突兀跳跃(如从 20 元直接跳到 100 元的不合理支出),确保消费金额与预算及场景合理性保持连续性和一致性。

1.9 一些讲座草稿
后面不打算贴了,太菜,看不太懂。。。
直接把整理的一部分草稿md贴出来:
## 导读本文聚焦于在线营销场景下 Uplift(因果推理中的增量效应建模)效应设计。内容围绕以下几点展开:1. 背景与问题
2. 带约束的端到端 Uplift
3. 面向大规模上下文的 Uplift
4. Q&A## 01 背景与问题### 1. 在线营销的重要性#### (1)在线营销场景**常见场景**
- 短信推送场景:通过手机短信向用户发送优惠券或营销信息。
- 应用内弹窗/活动场景:在用户打开 APP 时,通过弹窗形式展示营销活动/推广内容。**问题建模**
- 数据建模:对用户行为、偏好等数据进行分析建模,以确定推送策略及目标用户群体。
- 个性化推送执行:根据建模结果,向不同用户定向发送匹配其特征的短信、APP 弹窗等营销内容。#### (2)人群激励矩阵**四类用户类型及其行为特征:**
- **Persuadables**:激励后购买,无激励不购买
- **Sure things**:无论是否激励均购买
- **Lost causes**:无论是否激励均不购买
- **Sleeping dogs**:激励后不购买,无激励反而购买**目标人群**:识别并干预 Persuadables 用户以实现转化#### (3)核心挑战与需求- 精准激励敏感用户(Persuadables 用户)以提升活跃度和平台收入。
- 识别激励敏感用户群体(如 Persuadables 用户),实现个性化干预,自动完成转化。### 2. 现有研究与局限#### (1)传统 Uplift 建模方法**发展脉络与趋势**
- 早期阶段:以统计模型(S/T-Learner)和简单神经网络(TARNet)为主,侧重基础建模。
- 深度学习兴起:通过对抗训练(DragonNet)、多任务学习(EUEN)等提升性能。
- 前沿方向:结合 GAN(GANITE)、公平性(EFIN)、结构因果模型(DESCN)等解决复杂问题。**传统统计方法(早期传统方法)**
- 基于统计学或机器学习的经典方法,不涉及深度学习技术,通常通过两阶段或线性模型建模。
- S-Learner
- T-Learner
- BNN(Bayesian Neural Network)
- CEVAE(Counterfactual Estimation via Augmented Neural Networks)**深度学习基础方法(早期深度学习方法)**
- 首次将深度神经网络应用于 uplift 建模,但结构相对简单。
- TARNet(Twins Adapted Reverse Networks)
- CFRNet(Counterfactual Regression Network)**现代深度学习方法**
- 通过优化网络结构或引入注意力机制、对抗训练等提升 uplift 估计的准确性。
- DragonNet
- FlexTENet
- EUEN(Enhanced Uplift Estimation Network)
- SNet**增强或复杂结构方法**
- 通过 GAN、元学习等技术进一步优化,或结合其他任务(如公平性、鲁棒性)。
- GANITE(Generative Adversarial Nets for Estimating Individual Treatment Effects)
- EFIN(Enhanced Fairness-aware Uplift Network)
- DESCN(Deep Structural Causal Network)**混合与贝叶斯方法(Hybrid/Bayesian Methods)**
- 结合传统统计与深度学习,或侧重贝叶斯不确定性量化。
- CEVAE
- BNN**共同目标**
- 从各种维度为用户群体和最终响应之间去建模。
- 在线营销场景中,实现最终 uplift 的效应预估**Uplift 的本质**
- 本质上,Uplift(因果推理中的增量效应建模方法)是基于用户的特征和不同激励机制,去预估不同用户行为响应的一个方法。#### (2)现有方法的不足**①两阶段建模最优性差距问题****两阶段原理**
- 第一阶段:通过预估模型量化用户响应(uplift效应)的潜在价值
- 第二阶段:基于预算约束进行激励资源的最优分配**两阶段挑战****预算约束特性**
- 在企业级资源分配场景中,预算限制具有显著刚性约束,尤其在涉及财务激励的场景下**分配逻辑局限性**
- 传统方法依赖线性规划/整数规划等数学优化模型,需满足连续性或离散变量约束
- 因为采用两阶段决策架构,进行阶段分离预测时,一定会出现目标差距。
- 每个用户在平台中获得最后的激励分配数据和上一阶段的直接预测中间存在一定的差距,这就是目标上的预测差距。**②问题发生**
- 传统方法在处理离散决策变量时可能存在的计算复杂度问题(如整数规划),或基于项目的分配策略导致的次优解风险。
- 两阶段建模导致目标差距
- 预估uplift效应与实际分配存在预测差距
- 分阶段联合建模导致次优解**预设方案**
- 做一个端到端的分析,才能够消除这种最优性的差距。**③大规模上下文的分布偏移****原理**
- 仅依赖用户特征:忽略短视频信息,导致预测偏差
- 直接拼接用户与上下文特征,导致干预组/对照组分布不均衡。**设计场景**
- 针对短视频推荐系统的场景化建模优化问题:当前主流的推荐模型构建主要基于用户群体特征进行,但实际应用中存在显著的内容场景差异性。例如用户在浏览游戏类视频时,系统可能需要侧重推荐攻略解析或同类游戏内容;而当用户观看风景类视频时,则需转向旅游攻略或自然景观相关内容的推荐。这种因内容类型不同而产生的用户反馈与行为激励差异,导致单一用户群体模型难以精准匹配多场景下的推荐需求。**问题原因**
- 未结合项目特征进行个性化干预。
- 部分方案采用基于项目的分配策略,忽视不同用户的效应差异。## 02 带约束的端到端 Uplift### 1. 问题定义考虑预算的 uplift 实际场景:在带预算约束的 uplift 场景中,不仅要考虑收益(revenue uplift),即用户转化收益,同时要考虑用户成本(cost uplift)。Uplift 的第二阶段往往规划成一个带约束的整数的分配问题。在预算约束下的分配问题形式:
- 二值场景:分配与否的决策
- 多值场景:分配不同激励级别的优化### 2. 方法设计带约束的端到端的联合建模,是为了解决两阶段模块化设计导致的两阶段最优性差距问题。端到端的优化框架 E3|R,依然分为两个模块:
- **第一模块**:uplift 预测用户对不同激励的响应计算(revenue uplift 和 cost uplift)
- **第二模块**:基于预测 uplift 结果进行预算计算分配,传导进分配矩阵中,实现梯度计算的设计**创新点**:梯度传导设计实现端到端优化
**困难点**:二阶段之间梯度求导数据的双向输出### 3. 第一部分模块#### (1)单调性约束通过对单调性的约束建模,让它满足一个基本对应的效应。**①场景描述**在一个外卖优惠券发放的场景中,用户获得的优惠券金额与实际消费金额之间的关系需满足单调性约束。具体表现为:**正常逻辑**:当优惠券金额增加时,用户的实际消费金额应随之增加或保持不变。例如:
- 获得 2 元优惠券时,用户消费 10 元;
- 获得 3 元优惠券时,用户消费 15 元;
- 获得 4 元优惠券时,用户消费应≥20 元(符合常规"满减"规则)。**违反约束的反例**:若出现优惠券金额增加但消费金额反而减少的情况,则违反单调性约束。
例如:获得 4 元优惠券时,用户实际消费 12 元(低于 3 元券对应的 15 元消费)。**②约束核心**单调性约束要求优惠券力度与用户消费金额之间保持非递减关系,即更高的优惠券金额应对应更高的最低消费阈值(如"满 10 减 2""满 15 减 3"等)。若出现所述的"4 元券对应 12 元消费"的反例,则说明模型未满足该约束条件,需通过建模调整以确保消费金额随优惠力度递增。**③约束总结**激励力度与响应呈正相关,且激励预测值一定为正。#### (2)平滑性约束**①场景描述**例如,若当前可用金额为 20 元,则选择花费 15 元(剩余 5 元)或类似小额消费是合理的;而若剩余金额为 20 元时,选择花费 100 元则因远超当前预算且违背常规消费认知被排除。该约束通过限制消费行为的突兀跳跃(如从 20 元直接跳到 100 元的不合理支出),确保消费金额与预算及场景合理性保持连续性和一致性。**②约束核心**在消费决策场景中,当预算为 20 元时,平滑性约束要求消费金额的变化需符合现实逻辑。**③约束总结**响应变化符合 Lipschitz 条件,避免突变,即保证整体预测的曲线上是平滑的。#### (3)第一部分约束总结Uplift 预测模块损失可以写成相应的数学表达式。### 4. 第二部分模块#### (1)梯度传导方向的设计建模**response 函数的设计**:response 函数在一个基础空间内,对应着一个可微函数。建模的最终目的是为了解析 response 函数和预测损失值(Loss)互相之间的关系。这个过程采用了整数规划的算法,通过针对 Z 函数梯度传导方式进行求解。#### (2)整数规划的局限如果都是逼近某个整数点的值,按照整数规划,那么求解的能力就比较有限的。为了实现梯度传导方向求解,针对 z 函数进行盈利和成本建模以及预算分配的向量计算处理,最终获得向量分解方向的结果,再通过向量分解的结果,分别进行成本以及预估成果等内容的更新,最终实现端到端的目标。这个过程中,监督信号来源于用户行为数据。具体而言,系统通过采集用户在预估场景中受到的干预激励,构建监督信号。比如二值场景,T=0 或 1,来监督虚拟信号,以更新端到端的预测损失值方式。最后,整体上就会得到预估的目标函数。### 5. 实验与结果#### (1)基于开源试集 Hillstrom 的算法数据测算特定业务场景:针对不同的人在刷短视频时,给予不同的清晰度的范围,从整体上,实现在节省短视频 CDN 带宽的业务逻辑。T=0-3 是针对不同的视频的一个清晰度提升标准;从 0 到 3,是视频清晰度从高到低的不同参数。#### (2)论文实验展现的效果S-Learner、X-Learner、Causal Forest、CFRNetmmd、CFRNet wass、DragonNet、EUEN 等方法,都是比较常用的二值干预的方法。TPM-S、LDirect Rank、DRP 等方法也考虑到了分配场景的情况,但依然归属于两阶段建模的方式。在多值干预的场景下,需要用 Multi-TPM-SL、DRM 等方法,做多阶段的分配。从本次实验的结果反映出,相较于两阶段/多阶段的方式,端到端的建模方式会对效果有较大提升。#### (3)超参数分析以及预算(budget)分析- cost 曲线对比:超参数成本变化分析
- EOM 曲线对比:预算(budget)的变化对实验结果预估的变化影响### 6. 端到端解决方案总结端到端的解决方案是一种基于预算约束的在线营销"预测+优化"的解决方案,该方案包含两个核心模块:
- 融合营销领域知识的提升预测模块,可生成单调平滑的用户响应曲线
- 采用整数线性规划(ILP),可微优化技术以减少两阶段方法的性能差距实际的问题中,很多场景需要端到端去做建模,以此获得效果上的提升。## 03 面向大规模上下文的 Uplift 与问题Uplift 预估是指,在特定场景中,将不同特征拼接形成整体数据的情况下,去实现因果效应建模的优化方法。### 1. 案例定义在线上开展 AB 实验的时候,仅可以控制用户的基本特征。在短视频场景下,基于用户本身的特征,再结合视频特征,把两类特征通过上下文进行拼接,重构一个数据整体去计算特征。**场景约束**:
- 特征空间构建时,可能会特别大。
- 会破坏 AB 实验的无偏分布效果。**场景问题**:
在这种视频场景下,如何能够进行因果效应建模,是需要重点解决的问题。整体形式上,面向大规模上下文的 Uplift 和基本的 uplift 预估是基本一致的。因为在标准的 AB 实验的场景下,只考虑用户特征,X 参数在确定组跟控制组是一致的;在考虑到上下文特征的时候,产生的分布偏移如何消除,是这个方法中需要解决的主要的问题。### 2. 方法设计#### (1)总体结构**设计逻辑**首先,视频场景中特征维度极高,直接使用原始特征易导致计算负载过载。为此,需在用户特征融合的基础上,通过稀疏编码或注意力加权实现特征空间降维。由于数据集直接拼接所有的用户特征,所以数据集的维度极高。比如短视频场景,一个用户看几个短视频,一个用户的特征就会被分散到几百个视频特征里,然后再复制一遍。数据直接拼接,依然有很多视频特征仅在记录层面上,没有进行深度的数据洞察。即实际情况下,通过不同的平台收集的信息,在可记录的特征上没有特别明显的区分。从这个角度出发,对用户的数据从更高维的引用空间,去做特征类别的区分,然后再进行空间的缩小。其次需要考虑如何把处理后的特征空间的特征和用户特征结合来考虑,做第二阶段的 uplift 的建模。#### (2)第一部分:响应引导的上下文分组**处理特征**:包括处理用户特征,处理项目 item(上下文特征),或者是短视频特征**聚类逻辑设计**:首先最直接的方式是用户特征和 item 特征拼接,即上下文特征拼接,再设计回归逻辑,即结合 treatment 模块实现 response Y 的预估。这个阶段主要是靠 response 引导,即用用户的对应的 Y 标签,去做这部分特征的信号监督。**embedding 设计**:针对上下文特征的 embedding 模型。embedding 模型满足一些基础的条件,即假设 1 和假设 2。**假设一**:有一些上下文特征对这个用户的最终影响比较相似。**假设二**:得到函数会满足某些性质。2 实践案例代码的简单实现
本环节是对上述讲座的一些实践,从manus模拟了一些数据,跑了一个非常简单的案例。
当然,与讲座里的算法可谓是天差地别,但是主打的就是接地气,可操作性强。。。
电商平台优惠券分发 - Uplift模型与预算分配模拟
本代码模拟电商平台基于Uplift模型的优惠券分发场景,包括:
- 数据生成:模拟用户特征和对不同优惠券的反应
- 第一阶段:Uplift效应预估(预测不同优惠券对不同用户的增量效应)
- 第二阶段:基于预算约束的优惠券分配优化
2.1 实践步骤一: 数据生成部分
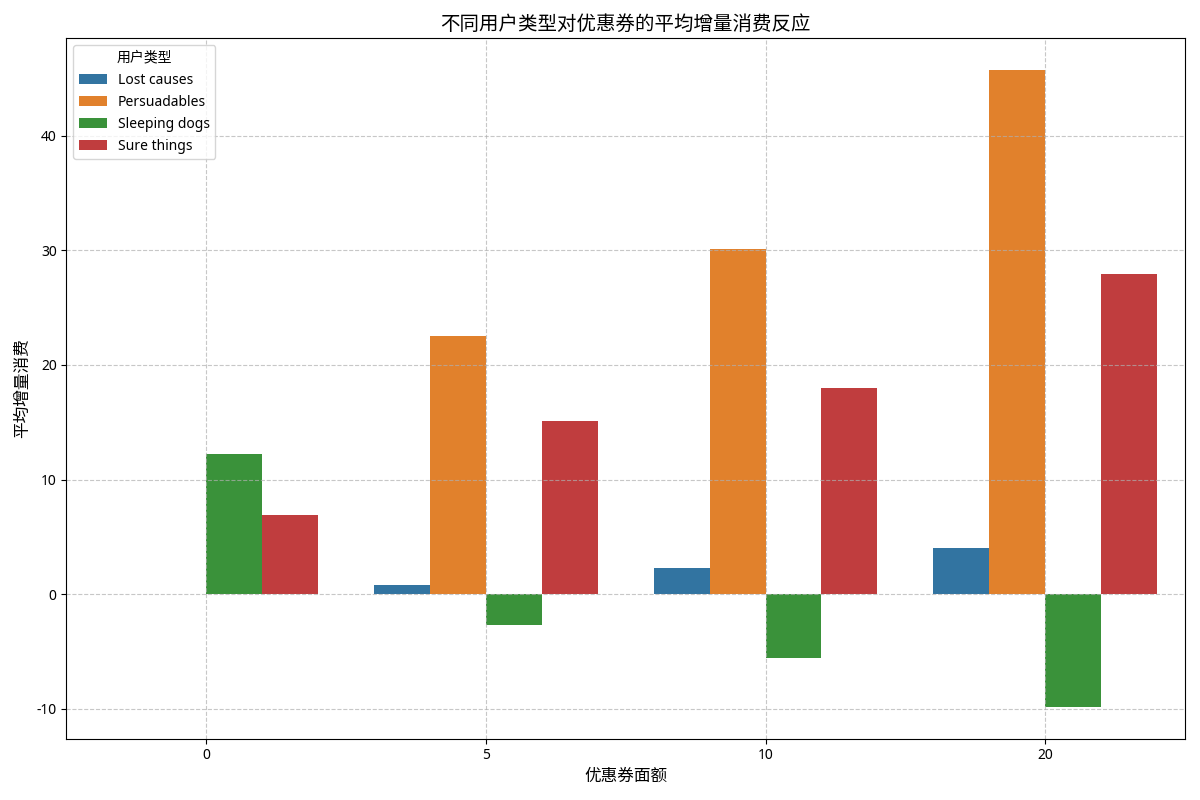
模拟了1000名用户的特征数据(年龄、购买频率、平均订单价值、忠诚度)
将用户分为四类:Persuadables(可说服型)、Sure things(必然型)、Lost causes(无效型)和Sleeping dogs(反效型)
模拟了不同用户对不同优惠券面额(0元、5元、10元、20元)的反应,假设的值,现实情况很难拿到:
-
- Persuadables: 对优惠券有强烈正面反应
-
- Sure things: 无论是否有优惠券都会消费
-
- Lost causes: 无论是否有优惠券都不会增加消费
-
- Sleeping dogs: 优惠券反而降低消费
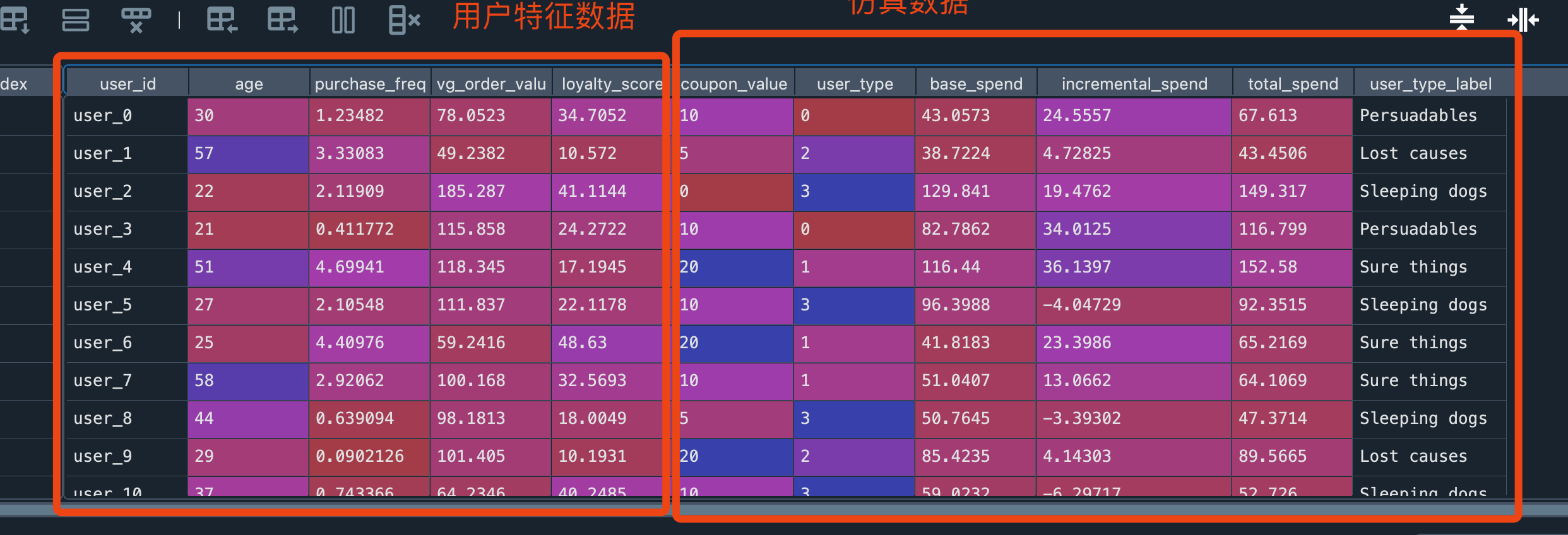
后面的coupon_value开始的字段,都是模拟现实数据,实际是没有的,
base_spend,是没有优惠券,不同类型的用户可能会产生多少购买incremental_spend,是在有coupon_value优惠券下,可能多买多少total_spend = base_spend + incremental_spend
大概分布如下:
2.2 实践步骤2: Uplift效应预估
步骤:
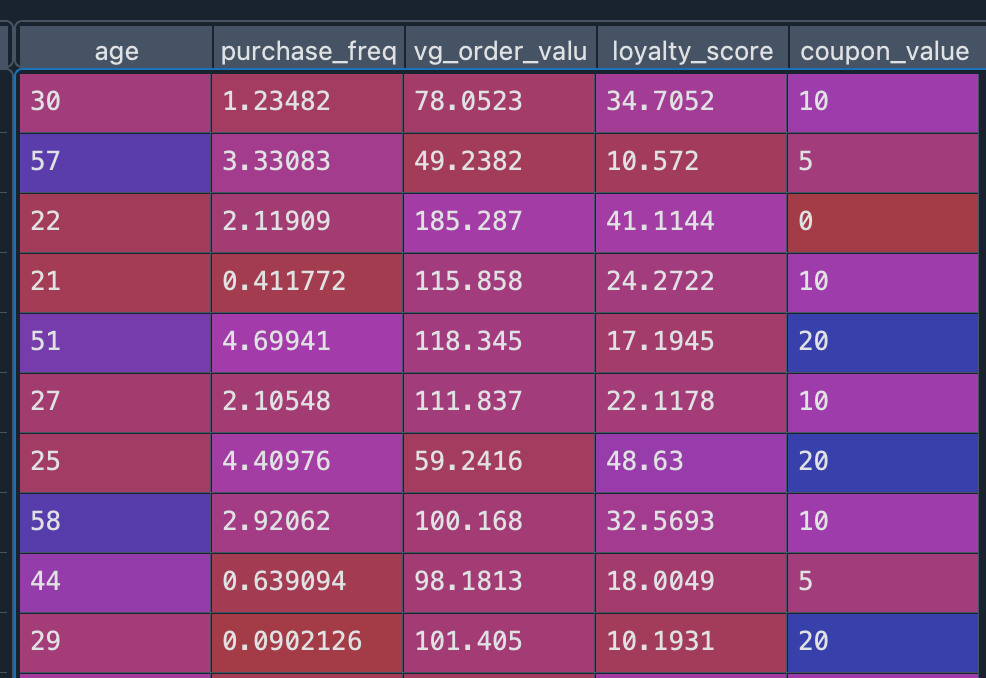
- 使用随机森林回归模型预测不同优惠券对不同用户的增量效应,使用的是s-learner,coupon_value (treatment)当做特征计入模型
- 评估预测的准确性,计算MAE和RMSE等指标
- 计算每一位用户在不同优惠券面额(0元、5元、10元、20元)的预测值,所以1000名用户需要计算4000次
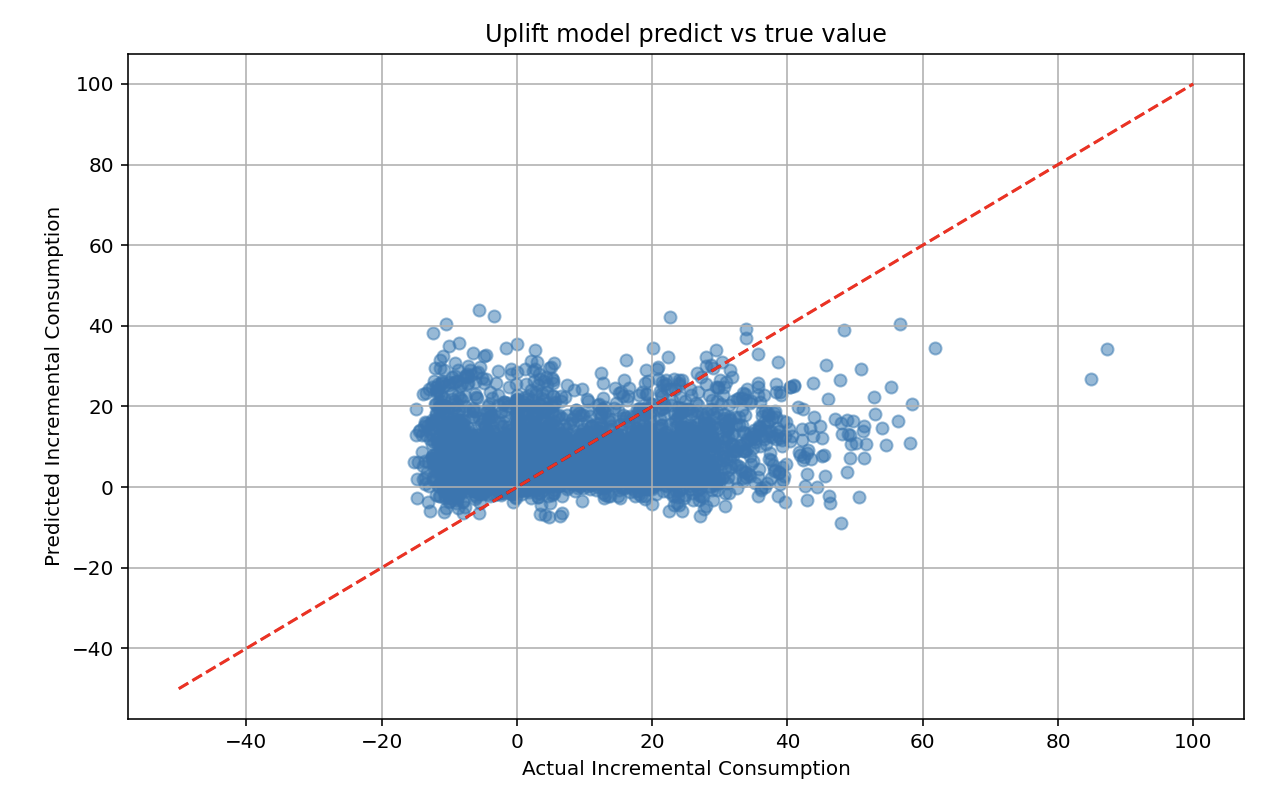
以下是评估的图,Uplift预测的准确性,包括Actual Incremental Consumption-实际增量消费 - X轴;预测增量消费-Y轴的对比:
2.3 实践步骤3:基于预算约束的优惠券分配优化
步骤:
- 使用整数线性规划(PuLP库)在预算约束下优化优惠券分配
- 最大化总体增量消费效果
- 与随机分配和统一分配等基准策略进行比较
2.3.1 约束条件限定
此时设定的线性规划有两个约束条件:
- 约束条件1:每个用户最多分配一种优惠券
- 约束条件2:总预算限制
此时可以得到在约束条件下,每个人最好使用哪张券
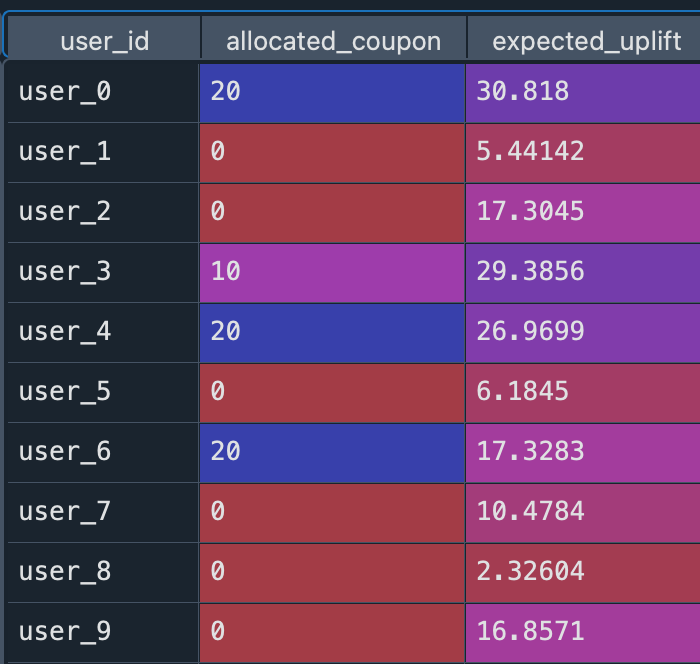
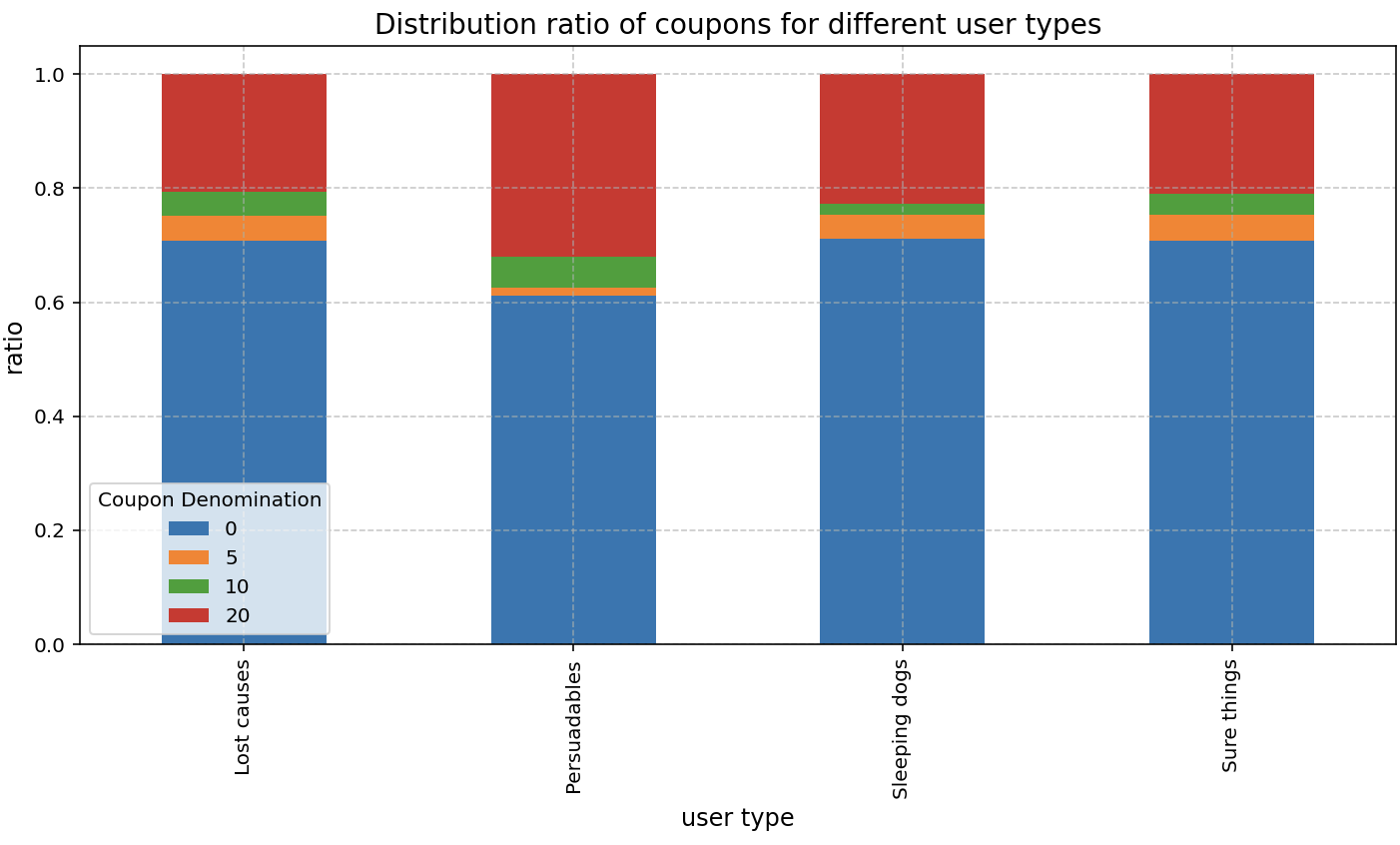
# 目标函数:最大化总增量消费prob += lpSum([predictions_df[(predictions_df['user_id'] == user) & (predictions_df['coupon_value'] == coupon)]['predicted_incremental_spend'].values[0] * x[(user, coupon)]for user in users for coupon in coupons])# 约束条件1:每个用户最多分配一种优惠券for user in users:prob += lpSum([x[(user, coupon)] for coupon in coupons]) <= 1# 约束条件2:总预算限制prob += lpSum([coupon * x[(user, coupon)]for user in users for coupon in coupons if coupon > 0 # 只考虑非零优惠券]) <= budget# 求解优化问题prob.solve()2.3.2 不同类型用户四类券的占比分布
会得到以下内容:
总预期增量消费: 11330.37
总真实增量消费: 7585.27
预测与实际差异: 3745.10 (49.37%)按用户类型的分配效果:用户类型 用户数量 平均优惠券面额 真实总增量消费 预期总增量消费
0 Lost causes 222 4.774775 214.503054 2424.866933
1 Persuadables 72 7.013889 1103.624498 1011.737317
2 Sleeping dogs 357 4.943978 1934.182192 4021.118718
3 Sure things 349 4.785100 4332.957424 3872.642623
<Figure size 1728x1152 with 0 Axes>
另外还对比了一下,不同策略的差异:
- 随机分配:为选中的用户随机分配优惠券
- 统一分配:所有用户相同面额
不同策略比较:策略 总成本 总增量消费 投资回报率
0 随机分配 5000 6600.832582 1.320167
1 统一分配 5000 6220.763731 1.244153
2.9 代码全部
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import seaborn as sns
from pulp import *# 设置随机种子,确保结果可复现
np.random.seed(42)#################################################
# 第0部分:数据生成 - 模拟电商平台用户和优惠券效果
#################################################def generate_user_data(n_users=1000):"""生成模拟的用户数据参数:n_users: 用户数量返回:users_df: 包含用户特征的DataFrame"""# 生成用户IDuser_ids = [f"user_{i}" for i in range(n_users)]# 生成用户特征age = np.random.normal(35, 10, n_users).astype(int) # 年龄,均值35,标准差10age = np.clip(age, 18, 70) # 限制年龄在18-70之间purchase_freq = np.random.gamma(2, 1.5, n_users) # 购买频率,使用gamma分布模拟偏态分布purchase_freq = np.clip(purchase_freq, 0, 10) # 限制购买频率在0-10之间avg_order_value = np.random.gamma(5, 20, n_users) # 平均订单价值,使用gamma分布avg_order_value = np.clip(avg_order_value, 10, 500) # 限制平均订单价值在10-500之间loyalty_score = np.random.beta(2, 5, n_users) * 100 # 忠诚度评分,使用beta分布,范围0-100# 创建用户特征DataFrameusers_df = pd.DataFrame({'user_id': user_ids,'age': age,'purchase_freq': purchase_freq,'avg_order_value': avg_order_value,'loyalty_score': loyalty_score})return users_dfdef generate_treatment_data(users_df, treatment_values=[0, 5, 10, 20]):"""生成模拟的实验数据,包括不同优惠券面额的处理效果参数:users_df: 用户特征DataFrametreatment_values: 优惠券面额列表,0表示不发放优惠券返回:experiment_df: 包含实验结果的DataFrame"""n_users = len(users_df)n_treatments = len(treatment_values)# 为每个用户随机分配一种处理(优惠券面额)treatment_assignments = np.random.choice(treatment_values, n_users)# 创建实验数据框架experiment_df = users_df.copy()experiment_df['coupon_value'] = treatment_assignments# 模拟用户对不同优惠券的反应(增量消费)# 基础消费(无优惠券时的消费)base_spend = experiment_df['avg_order_value'] * (0.5 + 0.5 * np.random.random(n_users))# 定义不同用户类型对优惠券的反应模式# 1. Persuadables: 对优惠券有强烈正面反应# 2. Sure things: 无论是否有优惠券都会消费# 3. Lost causes: 无论是否有优惠券都不会增加消费# 4. Sleeping dogs: 优惠券反而降低消费# 基于用户特征确定用户类型user_type_prob = np.zeros((n_users, 4))# 高忠诚度、高购买频率的用户更可能是"Sure things"user_type_prob[:, 1] = 0.3 + 0.5 * (experiment_df['loyalty_score'] / 100) * (experiment_df['purchase_freq'] / 10)# 中等忠诚度、低购买频率的用户更可能是"Persuadables"user_type_prob[:, 0] = 0.4 * (1 - experiment_df['purchase_freq'] / 10) * (experiment_df['loyalty_score'] / 100)# 低忠诚度的用户更可能是"Lost causes"user_type_prob[:, 2] = 0.3 * (1 - experiment_df['loyalty_score'] / 100)# 剩余概率分配给"Sleeping dogs"user_type_prob[:, 3] = 1 - user_type_prob[:, 0] - user_type_prob[:, 1] - user_type_prob[:, 2]# 为每个用户分配一个类型user_types = np.array([np.random.choice(4, p=user_type_prob[i]) for i in range(n_users)])experiment_df['user_type'] = user_types# 根据用户类型和优惠券面额计算增量消费incremental_spend = np.zeros(n_users)for i in range(n_users):coupon = experiment_df.loc[i, 'coupon_value']user_type = user_types[i]base = base_spend[i]if coupon == 0:# 无优惠券情况if user_type == 0: # Persuadablesincremental_spend[i] = 0elif user_type == 1: # Sure thingsincremental_spend[i] = base * 0.1 # 仍有小幅增长elif user_type == 2: # Lost causesincremental_spend[i] = 0else: # Sleeping dogsincremental_spend[i] = base * 0.15 # 无优惠券反而消费更多else:# 有优惠券情况if user_type == 0: # Persuadables# 优惠券面额越大,增量效应越明显incremental_spend[i] = base * 0.2 + coupon * 1.5 + np.random.normal(0, 5)elif user_type == 1: # Sure things# 优惠券效果适中incremental_spend[i] = base * 0.15 + coupon * 0.8 + np.random.normal(0, 3)elif user_type == 2: # Lost causes# 优惠券效果很小incremental_spend[i] = coupon * 0.2 + np.random.normal(0, 2)else: # Sleeping dogs# 优惠券反而降低消费incremental_spend[i] = -coupon * 0.5 + np.random.normal(0, 2)# 确保增量消费不会使总消费为负incremental_spend = np.maximum(incremental_spend, -base_spend * 0.9)# 计算总消费total_spend = base_spend + incremental_spend# 添加到数据框experiment_df['base_spend'] = base_spendexperiment_df['incremental_spend'] = incremental_spendexperiment_df['total_spend'] = total_spend# 添加用户类型标签user_type_labels = ['Persuadables', 'Sure things', 'Lost causes', 'Sleeping dogs']experiment_df['user_type_label'] = [user_type_labels[t] for t in user_types]return experiment_dfdef generate_full_potential_data(users_df, treatment_values=[0, 5, 10, 20]):"""生成每个用户在每种优惠券面额下的潜在结果这是为了模拟我们在现实中无法观察到的反事实数据参数:users_df: 用户特征DataFrametreatment_values: 优惠券面额列表返回:potential_outcomes: 包含所有潜在结果的DataFrame"""n_users = len(users_df)n_treatments = len(treatment_values)# 扩展用户数据,为每个用户创建多行(每种优惠券面额一行)potential_df = pd.DataFrame()for treatment in treatment_values:temp_df = users_df.copy()temp_df['coupon_value'] = treatmentpotential_df = pd.concat([potential_df, temp_df])# 重置索引potential_df.reset_index(drop=True, inplace=True)# 模拟用户对不同优惠券的反应(与generate_treatment_data类似,但为所有可能的处理)# 基础消费(无优惠券时的消费)base_spend = np.zeros(len(potential_df))for i, user_id in enumerate(potential_df['user_id']):# 确保同一用户的基础消费一致user_index = users_df[users_df['user_id'] == user_id].index[0]base_spend[i] = users_df.loc[user_index, 'avg_order_value'] * (0.5 + 0.5 * np.random.random())# 定义不同用户类型user_type_prob = np.zeros((n_users, 4))# 高忠诚度、高购买频率的用户更可能是"Sure things"user_type_prob[:, 1] = 0.3 + 0.5 * (users_df['loyalty_score'] / 100) * (users_df['purchase_freq'] / 10)# 中等忠诚度、低购买频率的用户更可能是"Persuadables"user_type_prob[:, 0] = 0.4 * (1 - users_df['purchase_freq'] / 10) * (users_df['loyalty_score'] / 100)# 低忠诚度的用户更可能是"Lost causes"user_type_prob[:, 2] = 0.3 * (1 - users_df['loyalty_score'] / 100)# 剩余概率分配给"Sleeping dogs"user_type_prob[:, 3] = 1 - user_type_prob[:, 0] - user_type_prob[:, 1] - user_type_prob[:, 2]# 为每个用户分配一个类型user_types = np.array([np.random.choice(4, p=user_type_prob[i]) for i in range(n_users)])user_type_dict = dict(zip(users_df['user_id'], user_types))# 为扩展后的DataFrame添加用户类型potential_df['user_type'] = potential_df['user_id'].map(user_type_dict)# 根据用户类型和优惠券面额计算增量消费incremental_spend = np.zeros(len(potential_df))for i in range(len(potential_df)):coupon = potential_df.loc[i, 'coupon_value']user_type = potential_df.loc[i, 'user_type']base = base_spend[i]if coupon == 0:# 无优惠券情况if user_type == 0: # Persuadablesincremental_spend[i] = 0elif user_type == 1: # Sure thingsincremental_spend[i] = base * 0.1 # 仍有小幅增长elif user_type == 2: # Lost causesincremental_spend[i] = 0else: # Sleeping dogsincremental_spend[i] = base * 0.15 # 无优惠券反而消费更多else:# 有优惠券情况if user_type == 0: # Persuadables# 优惠券面额越大,增量效应越明显incremental_spend[i] = base * 0.2 + coupon * 1.5 + np.random.normal(0, 5)elif user_type == 1: # Sure things# 优惠券效果适中incremental_spend[i] = base * 0.15 + coupon * 0.8 + np.random.normal(0, 3)elif user_type == 2: # Lost causes# 优惠券效果很小incremental_spend[i] = coupon * 0.2 + np.random.normal(0, 2)else: # Sleeping dogs# 优惠券反而降低消费incremental_spend[i] = -coupon * 0.5 + np.random.normal(0, 2)# 确保增量消费不会使总消费为负incremental_spend = np.maximum(incremental_spend, -base_spend * 0.9)# 计算总消费total_spend = base_spend + incremental_spend# 添加到数据框potential_df['base_spend'] = base_spendpotential_df['incremental_spend'] = incremental_spendpotential_df['total_spend'] = total_spend# 添加用户类型标签user_type_labels = ['Persuadables', 'Sure things', 'Lost causes', 'Sleeping dogs']potential_df['user_type_label'] = [user_type_labels[int(t)] for t in potential_df['user_type']]return potential_dfdef visualize_user_types(experiment_df):"""可视化不同用户类型对优惠券的反应参数:experiment_df: 包含实验结果的DataFrame"""plt.figure(figsize=(12, 8))# 按用户类型和优惠券面额分组计算平均增量消费grouped_data = experiment_df.groupby(['user_type_label', 'coupon_value'])['incremental_spend'].mean().reset_index()# 绘制不同用户类型的增量消费sns.barplot(x='coupon_value', y='incremental_spend', hue='user_type_label', data=grouped_data)plt.title('不同用户类型对优惠券的平均增量消费反应', fontsize=14)plt.xlabel('优惠券面额', fontsize=12)plt.ylabel('平均增量消费', fontsize=12)plt.legend(title='用户类型')plt.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()plt.savefig('uplift/ser_types_response.png')plt.close()#################################################
# 第1部分:Uplift效应预估 - 预测不同优惠券对不同用户的增量效应
#################################################def train_uplift_model(experiment_df, features):"""训练Uplift模型,预测不同优惠券面额对用户的增量效应参数:experiment_df: 包含实验结果的DataFramefeatures: 用于训练的特征列表返回:model: 训练好的模型"""# 准备训练数据X = experiment_df[features + ['coupon_value']]y = experiment_df['incremental_spend']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机森林回归模型model = RandomForestRegressor(n_estimators=100, random_state=42)model.fit(X_train, y_train)# 评估模型train_score = model.score(X_train, y_train)test_score = model.score(X_test, y_test)print(f"模型训练集R²: {train_score:.4f}")print(f"模型测试集R²: {test_score:.4f}")return modeldef predict_uplift_for_all_treatments(model, users_df, features, treatment_values=[0, 5, 10, 20]):"""为所有用户预测在每种优惠券面额下的增量效应参数:model: 训练好的Uplift模型users_df: 用户特征DataFramefeatures: 用于预测的特征列表treatment_values: 优惠券面额列表返回:predictions_df: 包含所有预测结果的DataFrame"""# 创建空的预测结果DataFramepredictions = []# 为每个用户和每种优惠券面额生成预测for _, user in users_df.iterrows():for coupon in treatment_values:# 准备预测数据user_features = user[features].copy()user_features['coupon_value'] = coupon# 预测增量消费pred_incremental = model.predict([user_features])[0]# 存储预测结果predictions.append({'user_id': user['user_id'],'coupon_value': coupon,'predicted_incremental_spend': pred_incremental})# 转换为DataFramepredictions_df = pd.DataFrame(predictions)return predictions_dfdef evaluate_uplift_predictions(predictions_df, potential_outcomes):"""评估Uplift预测的准确性参数:predictions_df: 包含预测结果的DataFramepotential_outcomes: 包含真实潜在结果的DataFrame返回:evaluation_df: 包含评估结果的DataFrame"""# 合并预测和真实结果merged_df = pd.merge(predictions_df,potential_outcomes[['user_id', 'coupon_value', 'incremental_spend']],on=['user_id', 'coupon_value'])# 计算预测误差merged_df['error'] = merged_df['predicted_incremental_spend'] - merged_df['incremental_spend']merged_df['abs_error'] = np.abs(merged_df['error'])# 计算评估指标mae = merged_df['abs_error'].mean()rmse = np.sqrt((merged_df['error'] ** 2).mean())print(f"平均绝对误差 (MAE): {mae:.2f}")print(f"均方根误差 (RMSE): {rmse:.2f}")# 可视化预测vs真实值plt.figure(figsize=(10, 6))plt.scatter(merged_df['incremental_spend'], merged_df['predicted_incremental_spend'], alpha=0.5)plt.plot([-50, 100], [-50, 100], 'r--') # 理想预测线plt.xlabel('真实增量消费')plt.ylabel('预测增量消费')plt.title('Uplift模型预测vs真实值')plt.grid(True)plt.savefig('uplift/uplift_prediction_evaluation.png')plt.close()return merged_df#################################################
# 第2部分:预算约束下的优惠券分配优化
#################################################def optimize_coupon_allocation(predictions_df, budget, treatment_values=[0, 5, 10, 20]):"""在预算约束下优化优惠券分配参数:predictions_df: 包含预测增量效应的DataFramebudget: 总预算treatment_values: 优惠券面额列表返回:allocation_df: 包含最优分配结果的DataFrame"""# 准备优化数据users = predictions_df['user_id'].unique()coupons = treatment_values.copy()# 创建优化问题prob = LpProblem("Coupon_Allocation", LpMaximize)# 创建决策变量:x[user_id, coupon_value] = 1表示给用户分配该面额的优惠券x = LpVariable.dicts("allocation", [(user, coupon) for user in users for coupon in coupons],cat='Binary')# 目标函数:最大化总增量消费prob += lpSum([predictions_df[(predictions_df['user_id'] == user) & (predictions_df['coupon_value'] == coupon)]['predicted_incremental_spend'].values[0] * x[(user, coupon)]for user in users for coupon in coupons])# 约束条件1:每个用户最多分配一种优惠券for user in users:prob += lpSum([x[(user, coupon)] for coupon in coupons]) <= 1# 约束条件2:总预算限制prob += lpSum([coupon * x[(user, coupon)]for user in users for coupon in coupons if coupon > 0 # 只考虑非零优惠券]) <= budget# 求解优化问题prob.solve()print(f"优化状态: {LpStatus[prob.status]}")print(f"最优目标值 (总预期增量消费): {value(prob.objective):.2f}")# 提取最优分配结果allocation_results = []total_cost = 0for user in users:allocated_coupon = 0for coupon in coupons:if value(x[(user, coupon)]) > 0.5: # 考虑二进制变量的舍入误差allocated_coupon = couponif coupon > 0:total_cost += couponbreak# 获取该分配下的预期增量消费expected_uplift = predictions_df[(predictions_df['user_id'] == user) & (predictions_df['coupon_value'] == allocated_coupon)]['predicted_incremental_spend'].values[0]allocation_results.append({'user_id': user,'allocated_coupon': allocated_coupon,'expected_uplift': expected_uplift})# 转换为DataFrameallocation_df = pd.DataFrame(allocation_results)print(f"总分配成本: {total_cost}")print(f"预算使用率: {total_cost/budget*100:.2f}%")# 统计不同面额优惠券的分配数量coupon_counts = allocation_df['allocated_coupon'].value_counts().sort_index()print("\n优惠券分配统计:")for coupon, count in coupon_counts.items():print(f" {coupon}元优惠券: {count}张")return allocation_dfdef evaluate_allocation_effectiveness(allocation_df, potential_outcomes):"""评估优惠券分配的有效性参数:allocation_df: 包含分配结果的DataFramepotential_outcomes: 包含真实潜在结果的DataFrame返回:evaluation_df: 包含评估结果的DataFrame"""# 合并分配结果和真实潜在结果merged_df = pd.merge(allocation_df,potential_outcomes[['user_id', 'coupon_value', 'incremental_spend', 'user_type_label']],left_on=['user_id', 'allocated_coupon'],right_on=['user_id', 'coupon_value'])# 计算总真实增量消费total_real_uplift = merged_df['incremental_spend'].sum()total_expected_uplift = merged_df['expected_uplift'].sum()print(f"总预期增量消费: {total_expected_uplift:.2f}")print(f"总真实增量消费: {total_real_uplift:.2f}")print(f"预测与实际差异: {(total_expected_uplift - total_real_uplift):.2f} ({(total_expected_uplift - total_real_uplift)/total_real_uplift*100:.2f}%)")# 按用户类型分析分配效果user_type_analysis = merged_df.groupby('user_type_label').agg({'user_id': 'count','allocated_coupon': 'mean','incremental_spend': 'sum','expected_uplift': 'sum'}).reset_index()user_type_analysis.columns = ['用户类型', '用户数量', '平均优惠券面额', '真实总增量消费', '预期总增量消费']print("\n按用户类型的分配效果:")print(user_type_analysis)# 可视化不同用户类型的分配结果plt.figure(figsize=(12, 8))# 绘制不同用户类型的优惠券分配情况coupon_dist = pd.crosstab(merged_df['user_type_label'], merged_df['allocated_coupon'],normalize='index')ax = coupon_dist.plot(kind='bar', stacked=True, figsize=(10, 6))plt.title('不同用户类型的优惠券分配比例', fontsize=14)plt.xlabel('用户类型', fontsize=12)plt.ylabel('比例', fontsize=12)plt.legend(title='优惠券面额')plt.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()plt.savefig('uplift/coupon_allocation_by_user_type.png')plt.close()return merged_dfdef compare_strategies(potential_outcomes, budget, treatment_values=[0, 5, 10, 20]):"""比较不同优惠券分配策略的效果参数:potential_outcomes: 包含真实潜在结果的DataFramebudget: 总预算treatment_values: 优惠券面额列表返回:comparison_df: 包含策略比较结果的DataFrame"""# 策略1:随机分配users = potential_outcomes['user_id'].unique()n_users = len(users)# 计算在预算内可以分配的最大优惠券数量max_coupons = budget // min([t for t in treatment_values if t > 0])# 随机选择用户np.random.seed(42)selected_users = np.random.choice(users, size=min(int(max_coupons), n_users), replace=False)# 为选中的用户随机分配优惠券random_allocation = {}total_cost = 0for user in users:if user in selected_users and total_cost < budget:# 随机选择非零优惠券non_zero_coupons = [t for t in treatment_values if t > 0]coupon = np.random.choice(non_zero_coupons)if total_cost + coupon <= budget:random_allocation[user] = coupontotal_cost += couponelse:random_allocation[user] = 0else:random_allocation[user] = 0# 策略2:统一分配(所有用户相同面额)uniform_coupon = max([t for t in treatment_values if t > 0 and t * n_users <= budget], default=0)uniform_allocation = {user: uniform_coupon for user in users}# 计算每种策略的总增量消费strategies = {'随机分配': random_allocation,'统一分配': uniform_allocation}results = []for strategy_name, allocation in strategies.items():total_uplift = 0total_cost = 0for user in users:coupon = allocation[user]# 获取该用户在该优惠券面额下的真实增量消费user_outcome = potential_outcomes[(potential_outcomes['user_id'] == user) & (potential_outcomes['coupon_value'] == coupon)]if not user_outcome.empty:total_uplift += user_outcome['incremental_spend'].values[0]total_cost += couponresults.append({'策略': strategy_name,'总成本': total_cost,'总增量消费': total_uplift,'投资回报率': total_uplift / total_cost if total_cost > 0 else 0})# 转换为DataFramecomparison_df = pd.DataFrame(results)print("\n不同策略比较:")print(comparison_df)return comparison_df#################################################
# 主函数:运行完整的优惠券分配流程
#################################################def main():"""运行完整的优惠券分配流程"""print("="*50)print("电商平台优惠券分发 - Uplift模型与预算分配模拟")print("="*50)# 步骤1:生成模拟数据print("\n步骤1:生成模拟数据")print("-"*50)# 生成用户数据users_df = generate_user_data(n_users=1000)print(f"生成了{len(users_df)}个用户的数据")# 定义优惠券面额treatment_values = [0, 5, 10, 20] # 0表示不发放优惠券# 生成实验数据experiment_df = generate_treatment_data(users_df, treatment_values)print(f"生成了实验数据,包含{len(experiment_df)}条记录")# 生成所有潜在结果(用于评估,在实际场景中无法获得)potential_outcomes = generate_full_potential_data(users_df, treatment_values)print(f"生成了所有潜在结果,包含{len(potential_outcomes)}条记录")# 可视化不同用户类型visualize_user_types(experiment_df)print("已生成用户类型反应可视化图表")# 步骤2:Uplift效应预估print("\n步骤2:Uplift效应预估")print("-"*50)# 定义用于训练的特征features = ['age', 'purchase_freq', 'avg_order_value', 'loyalty_score']# 训练Uplift模型uplift_model = train_uplift_model(experiment_df, features)# 为所有用户预测在每种优惠券面额下的增量效应predictions_df = predict_uplift_for_all_treatments(uplift_model, users_df, features, treatment_values)print(f"为{len(users_df)}个用户生成了{len(treatment_values)}种优惠券面额下的预测,共{len(predictions_df)}条预测")# 评估预测准确性evaluation_df = evaluate_uplift_predictions(predictions_df, potential_outcomes)# 步骤3:预算约束下的优惠券分配优化print("\n步骤3:预算约束下的优惠券分配优化")print("-"*50)# 设定总预算budget = 5000 # 总预算5000元print(f"总预算: {budget}元")# 优化优惠券分配allocation_df = optimize_coupon_allocation(predictions_df, budget, treatment_values)# 评估分配效果allocation_evaluation = evaluate_allocation_effectiveness(allocation_df, potential_outcomes)# 比较不同策略strategy_comparison = compare_strategies(potential_outcomes, budget, treatment_values)print("\n优惠券分配流程完成!")if __name__ == "__main__":main()