从认识AI开始-----解密LSTM:RNN的进化之路
前言
我在上一篇文章中介绍了 RNN,它是一个隐变量模型,主要通过隐藏状态连接时间序列,实现了序列信息的记忆与建模。然而,RNN在实践中面临严重的“梯度消失”与“长期依赖建模困难”问题:
- 难以捕捉相隔很远的时间步之间的关系
- 隐状态在不断更新中容易遗忘早期信息。
为了解决这些问题,LSTM(Long Short-Term Memory) 网络于 1997 年被 Hochreiter等人提出,该模型是对RNN的一次重大改进。
一、LSTM相比RNN的核心改进
接下来,我们通过对比RNN、LSTM,来看一下具体的改进:
| 模型 | 特点 | 优势 | 缺点 |
| RNN | 单一隐藏转态,时间步传递 | 结构简答 | 容易造成梯度消失/爆炸,对长期依赖差 |
| LSTM | 多门控机制 + 单独的“记忆单元” | 解决长距离依赖问题,保留长期信息 | 结构复杂,计算开销大 |
通过对比,我们可以发现,其实LSTM的核心思想是:引入了一个专门的“记忆单元”,在通过门控机制对信息进行有选择的保留、遗忘与更新。
二、LSTM的核心结构
LSTM的核心结构如下图所示:
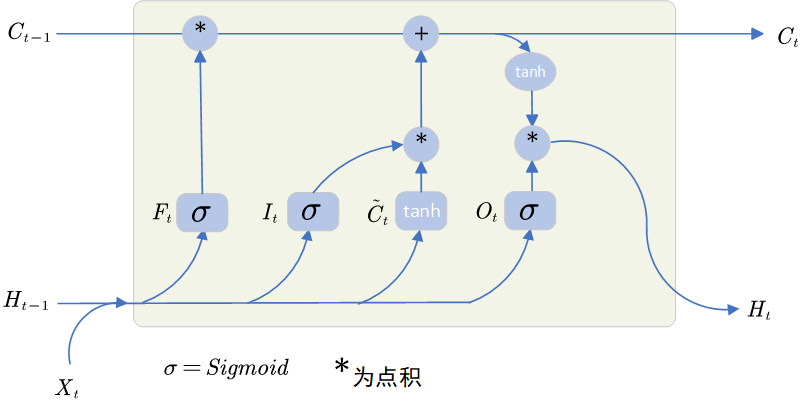
如图可以轻松的看出,LSTM主要由门控机制和候选记忆单元组成,对于每个时间步,LSTM都会进行以下操作:
1. 忘记门
忘记门()主要的作用是:控制保留多少之前的记忆:
2. 输入门
输入门()主要的作用是:决定当前输入中哪些信息信息被写入记忆:
3. 候选记忆单元
4. 输出门
输出门()的作用是:决定是是否使用隐状态:
5. 真正记忆单元
记忆单元( )用于长期存储信息,解决RNN容易遗忘的问题:
7. 隐藏转态
LSTM引入了专门的记忆单元
,长期存储信息,解决了传统RNN容易遗忘的问题。
三、手写LSTM
通过上面的介绍,我们现在已经知道了LSTM的实现原理,现在,我们试着手写一个LSTM核心层:
首先,初始化需要训练的参数:
import torch
import torch.nn as nn
import torch.nn.functional as Fdef params(input_size, output_size, hidden_size):W_xi, W_hi, b_i = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xf, W_hf, b_f = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xo, W_ho, b_o = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xc, W_hc, b_c = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_hq = torch.randn(hidden_size, output_size) * 0.1b_q = torch.zeros(output_size)params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]for param in params:param.requires_grad = Truereturn params
接着,我们需要初始化0时刻的隐藏转态:
import torchdef init_state(batch_size, hidden_size):return (torch.zeros((batch_size, hidden_size)), torch.zeros((batch_size, hidden_size)))
然后, 就是LSTM的核心操作:
import torch
import torch.nn as nn
def lstm(X, state, params):[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params(H, C) = stateoutputs = []for x in X:I = torch.sigmoid(torch.mm(x, W_xi) + torch.mm(H, W_hi) + b_i)F = torch.sigmoid(torch.mm(x, W_xf) + torch.mm(H, W_hf) + b_f)O = torch.sigmoid(torch.mm(x, W_xo) + torch.mm(H, W_ho) + b_o)C_tilde = torch.tanh(torch.mm(x, W_xc) + torch.mm(H, W_hc) + b_c)C = F * C + I * C_tildeH = O * torch.tanh(C)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=1), (H, C)四、使用Pytroch实现简单的LSTM
在Pytroch中,已经内置了lstm函数,我们只需要调用就可以实现上述操作:
import torch
import torch.nn as nnclass mylstm(nn.Module):def __init__(self, input_size, output_size, hidden_size):super(mylstm, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, h0, c0):out, (hn, cn) = self.lstm(x, h0, c0)out = self.fc(out)return out, (hn, cn)# 示例
input_size = 10
hidden_size = 20
output_size = 10
batch_size = 1
seq_len = 5
num_layer = 1 # lstm堆叠层数h0 = torch.zeros(num_layer, batch_size, hidden_size)
c0 = torch.randn(num_layer, batch_size, hidden_size)
x = torch.randn(batch_size, seq_len, hidden_size)model = mylstm(input_size=input_size, hidden_size=hidden_size, output_size=output_size)out, _ = model(x, (h0, c0))
print(out.shape)总结
在现实中,LSTM的实际应用场景很多,比如语言模型、文本生成、时间序列预测、情感分析等长序列任务重,这是因为相比于RNN而言,LSTM能够更高地捕捉长期依赖,而且也更好的缓解了梯度消失问题;但是由于LSTM引入了三个门控机制,导致参数量比RNN要多,训练慢。
总的来说,LSTM是对传统RNN的一次革命性升级,引入门控机制和记忆单元,使模型能够选择性地记忆与遗忘,从而有效地捕捉长距离依赖。尽管LSTM近年来Transformer所取代,但LSTM依然是理解深度学习序列模型不可绕开的一环,有时在其他任务上甚至优于Transformer。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!