5月27日复盘-Transformer介绍
5月27日复盘
二、层归一化
层归一化,Layer Normalization。
Layer Normalizatioh和Batch Normalization都是用来规范化中间特征分布,稳定和加速神经网络训练的,但它们在处理方式、应用场景和结构上有本质区别。
1. 核心区别
| 特征 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化维度 | 对每个特征维度在一个batch中归一化 | 对每个样本的所有特征维度归一化 |
| 应用场景 | CNN常用 | Transformer、RNN等序列建模场景常用 |
| 依赖 batch_size | 依赖 | 不依赖 |
| 推理阶段 | 需要记录训练时的均值/方差 | 否,直接使用当前样本计算 |
2. 计算差异
从计算的角度理解二者的差异。
2.1 Batch Normalization
以 2 D 2D 2D 特征为例:
μ c = 1 N ⋅ H ⋅ W ∑ n , h , w x n c h w , σ c 2 = 1 N ⋅ H ⋅ W ∑ n , h , w ( x n c h w − μ c ) 2 \mu_c = \frac{1}{N \cdot H \cdot W} \sum_{n,h,w} x_{nchw}, \quad \sigma_c^2 = \frac{1}{N \cdot H \cdot W} \sum_{n,h,w} (x_{nchw} - \mu_c)^2 μc=N⋅H⋅W1n,h,w∑xnchw,σc2=N⋅H⋅W1n,h,w∑(xnchw−μc)2
归一化每个通道维度:
x ^ n c h w = x n c h w − μ c σ c 2 + ϵ \hat{x}_{nchw} = \frac{x_{nchw} - \mu_c}{\sqrt{\sigma_c^2 + \epsilon}} x^nchw=σc2+ϵxnchw−μc
2.2 Layer Normalization
以每个样本为单位,对其所有特征维度归一化:
μ = 1 H ∑ i = 1 H x i , σ 2 = 1 H ∑ i = 1 H ( x i − μ ) 2 \mu = \frac{1}{H} \sum_{i=1}^{H} x_i, \quad \sigma^2 = \frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 μ=H1i=1∑Hxi,σ2=H1i=1∑H(xi−μ)2
归一化:
x ^ i = x i − μ σ 2 + ϵ \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} x^i=σ2+ϵxi−μ
2.3 案例助解
假设你有一句话经过嵌入层后的表示是一个矩阵,形状是:
[句子长度, 特征维度] = [5, 4]
一句 5 5 5 个词,每个词用 4 4 4 维向量表示:
["I", "am", "a", "good", "student"]
经过 e m b e d d i n g embedding embedding 之后得到:
I -> [1.2, -0.5, 0.3, 0.7]
am -> [1.0, 0.0, 0.1, 0.6]
a -> [0.9, 0.2, 0.4, 0.3]
good -> [1.3, -0.3, 0.5, 0.8]
student -> [1.1, -0.1, 0.2, 0.4]
它对每个词的 4 4 4 维向量分别归一化:
对 I = [ 1.2 , − 0.5 , 0.3 , 0.7 ] I = [1.2, -0.5, 0.3, 0.7] I=[1.2,−0.5,0.3,0.7] 这个词:
-
求均值 μ
μ = 1.2 + ( − 0.5 ) + 0.3 + 0.7 4 = 0.425 \mu = \frac{1.2 + (-0.5) + 0.3 + 0.7}{4} = 0.425 μ=41.2+(−0.5)+0.3+0.7=0.425 -
求方差 σ²
σ 2 = ( 1.2 − 0.425 ) 2 + ( − 0.5 − 0.425 ) 2 + . . . 4 ≈ 0.4319 \sigma^2 = \frac{(1.2 - 0.425)^2 + (-0.5 - 0.425)^2 + ...}{4} \approx 0.4319 σ2=4(1.2−0.425)2+(−0.5−0.425)2+...≈0.4319 -
归一化: 每一维都减去均值除以标准差
LayerNorm ( x i ) = x i − μ σ 2 + ϵ \text{LayerNorm}(x_i) = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} LayerNorm(xi)=σ2+ϵxi−μ
最终你得到一个新的 [ 1.2 , − 0.5 , 0.3 , 0.7 ] [1.2, -0.5, 0.3, 0.7] [1.2,−0.5,0.3,0.7] 的“归一化版本”,然后对“am”、“a”、“good”、“student”每一个词都分别做这个过程。
三、Transformer初识
模型Transformer在2017年由Google发布:Attention Is All You Need,主要用于处理序列数据,是NLP中最常用架构之一。它替代了RNN及LSTM,并以此为基础衍生出诸如BERT、GPT、DeepSeek等架构。
Transformer不使用卷积和循环网络,是一个完全基于自注意力机制的模型。
1. 主要特点
Transformer 有三大主要特征。
1.1 Self-Attention
自注意力机制,Transformer的核心是自注意力机制,它允许模型在处理某个位置的输入时,能够直接与其他位置的输入交互,而不像CNN、RNN只能顺序处理数据。自注意力机制通过计算输入序列中各位置之间的相似度来决定各位置之间的影响力,从而提高了模型的表现力。
1.2 并行化能力
由于Transformer不依赖于序列的顺序处理,它的计算过程可以并行化,这就可以显著提高了训练效率。
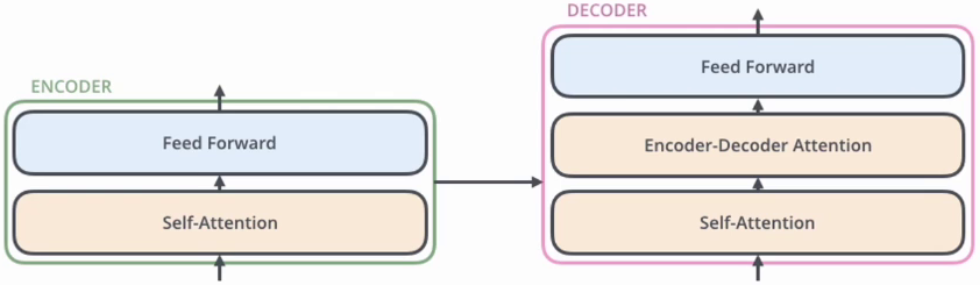
1.3 Encoder-Decoder
Transformer 采用了典型的编码器-解码器架构。编码器负责处理输入序列,将其转换为上下文相关的表示;解码器则根据这些表示生成输出序列。
2. 模型结构
Transformer主要由编码器(Encoder)和解码器(Decoder)组成,广泛应用于自然语言处理任务,尤其是机器翻译。
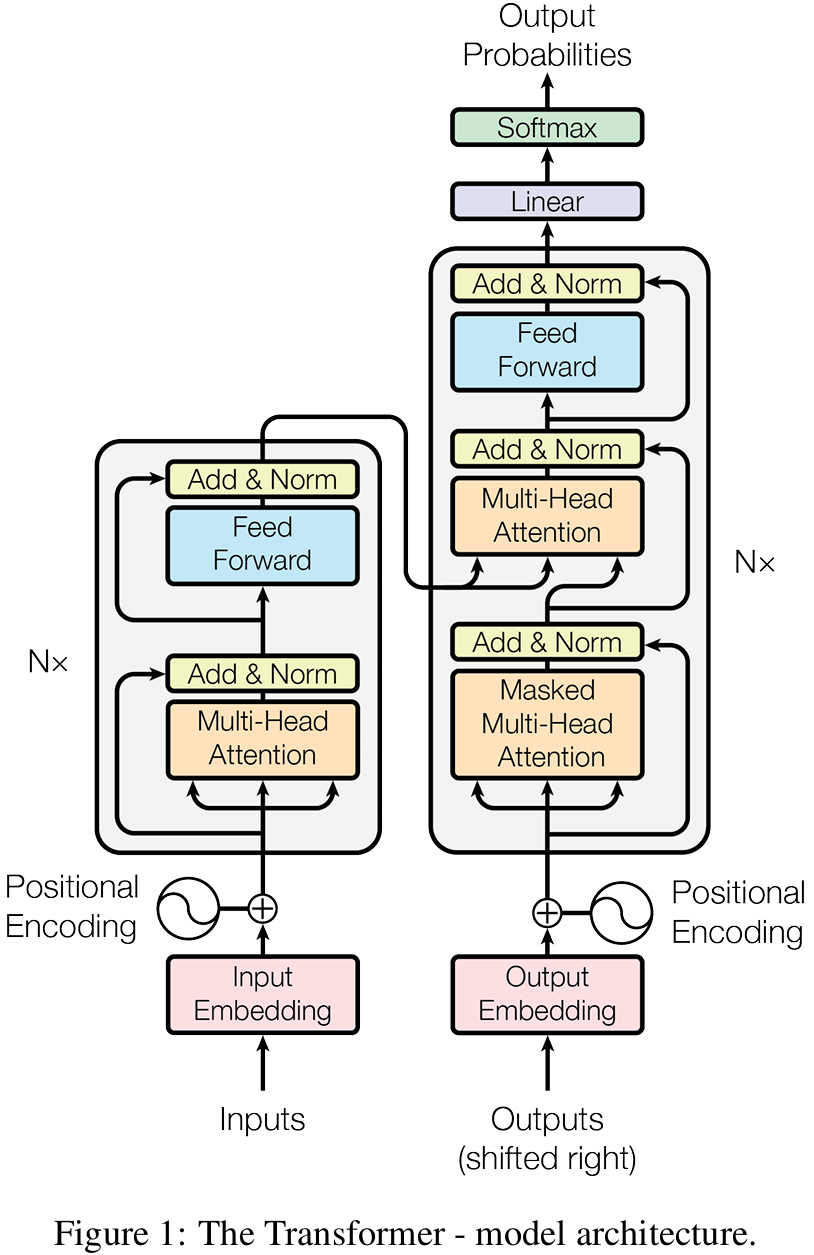
3. Encoder-Decoder框架
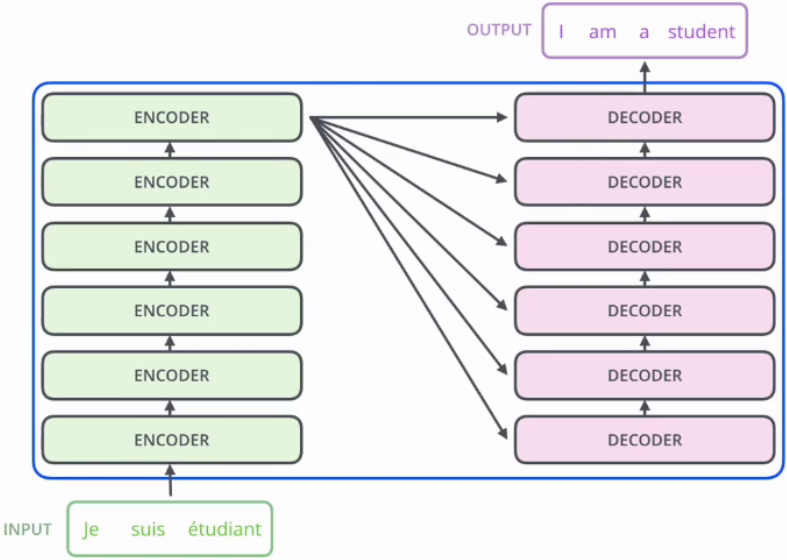 |  |
|---|---|
| 6个结构完全相同的编码器 | 6个结构完全相同的解码器 |
3.1 编码器Encoder
Encoder由N个相同结构的编码模块堆积而成,原始的Transformer是6个。
模块组成部分:Multi-Head Attention、Feed Forward、Add&Norm。
3.1.1 Multi-Head Attention
就是你认为的多头注意力机制
3.1.2 Add&Norm
经过残差连接和层归一化处理,让训练过程更稳定。残差就是你以为的残差思想。
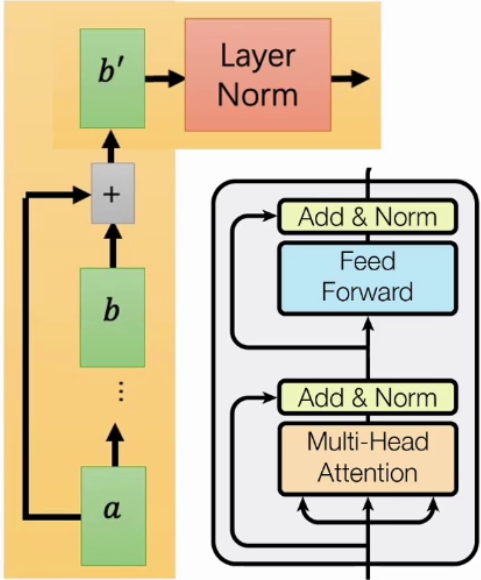 |
|---|
| Layer Normalization会将每一层神经元的输入都调整成相同均值方差,可以加快收敛。 |
3.1.3 Feed Forward
就是一个全连接层,用于对每个位置的输出进行非线性变换。

Feed Forward 层由两个全连接层组成
- F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0,xW1 +b1)W2 +b2 FFN(x)=max(0,xW1+b1)W2+b2
- 第一层激活函数为 ReLU,第二层不使用激活函数。
- x x x是输入,全连接层的输入和输出都是 512 512 512维,中间隐层维度为 2048 2048 2048。
3.2 解码器Decoder
与编码器相似,由N个相同结构的解码模块堆积而成。它还引入了“掩蔽多头自注意力(Masked Multi-Head Attention)”层。
组成部分:Masked Multi-Head Attention、Add & Norm、Multi-Head Attention、Feed Forward
3.2.0 自回归特性
Autoregressive Property,是指模型在生成序列时,每生成一个新的元素,只能依赖前面已经生成的元素,不能依赖未来的信息,而不是一次性生成整个序列。
-
逐步生成:
- 模型一次生成一个元素,并将它作为下一次生成的输入。
-
因果性:
- 自回归模型是因果的(causal),即当前时刻的输出只依赖于过去时刻的输入,而不依赖于未来的输入。
- 这种因果性确保了模型在生成序列时不会“偷看”未来的信息。
-
数学表示:
-
假设序列 x = ( x 1 , x 2 , … , x T ) x = (x_1, x_2, \dots, x_T) x=(x1,x2,…,xT),自回归模型的目标是建模序列的联合概率分布 P ( x ) P(x) P(x)。
-
根据概率链式法则,联合概率可以分解为条件概率的乘积:
P ( x ) = P ( x 1 ) ⋅ P ( x 2 ∣ x 1 ) ⋅ P ( x 3 ∣ x 1 , x 2 ) ⋅ ⋯ ⋅ P ( x T ∣ x 1 , x 2 , … , x T − 1 ) P(x) = P(x_1) \cdot P(x_2 | x_1) \cdot P(x_3 | x_1, x_2) \cdot \dots \cdot P(x_T | x_1, x_2, \dots, x_{T-1}) P(x)=P(x1)⋅P(x2∣x1)⋅P(x3∣x1,x2)⋅⋯⋅P(xT∣x1,x2,…,xT−1) -
自回归模型通过逐步预测每个条件概率 $ P(x_t | x_1, x_2, \dots, x_{t-1})$ 来生成序列。
-
简单来说,自回归特性让模型在生成序列时能够遵循时间顺序和因果关系,避免了在训练过程中“泄漏”未来信息。
3.2.1 Masked Multi-Head
Masked Multi-Head Attention,用于解决序列任务的并行计算与自回归特性冲突问题。
3.2.1.1 产生背景
解码采用矩阵并行计算,一步就把所有目标单词预测出来。所以我们要做到:
- 当解码第1个字时,只能与第1个字的特征计算相关性;
- 当解码第2个字时,只能与第1、2个字的特征计算相关性,依此类推。
- 在翻译的过程中是顺序翻译的,即翻译完第 i i i 个单词,才可以翻译第 i + 1 i+1 i+1 个单词。
- 通过 Masked 操作可以防止第 i i i 个单词知道 i + 1 i+1 i+1 个单词及其之后的信息。
于是,引入了Masked设计。
3.2.1.2 内部结构
第一个Multi-Head Attention采用了Masked操作。
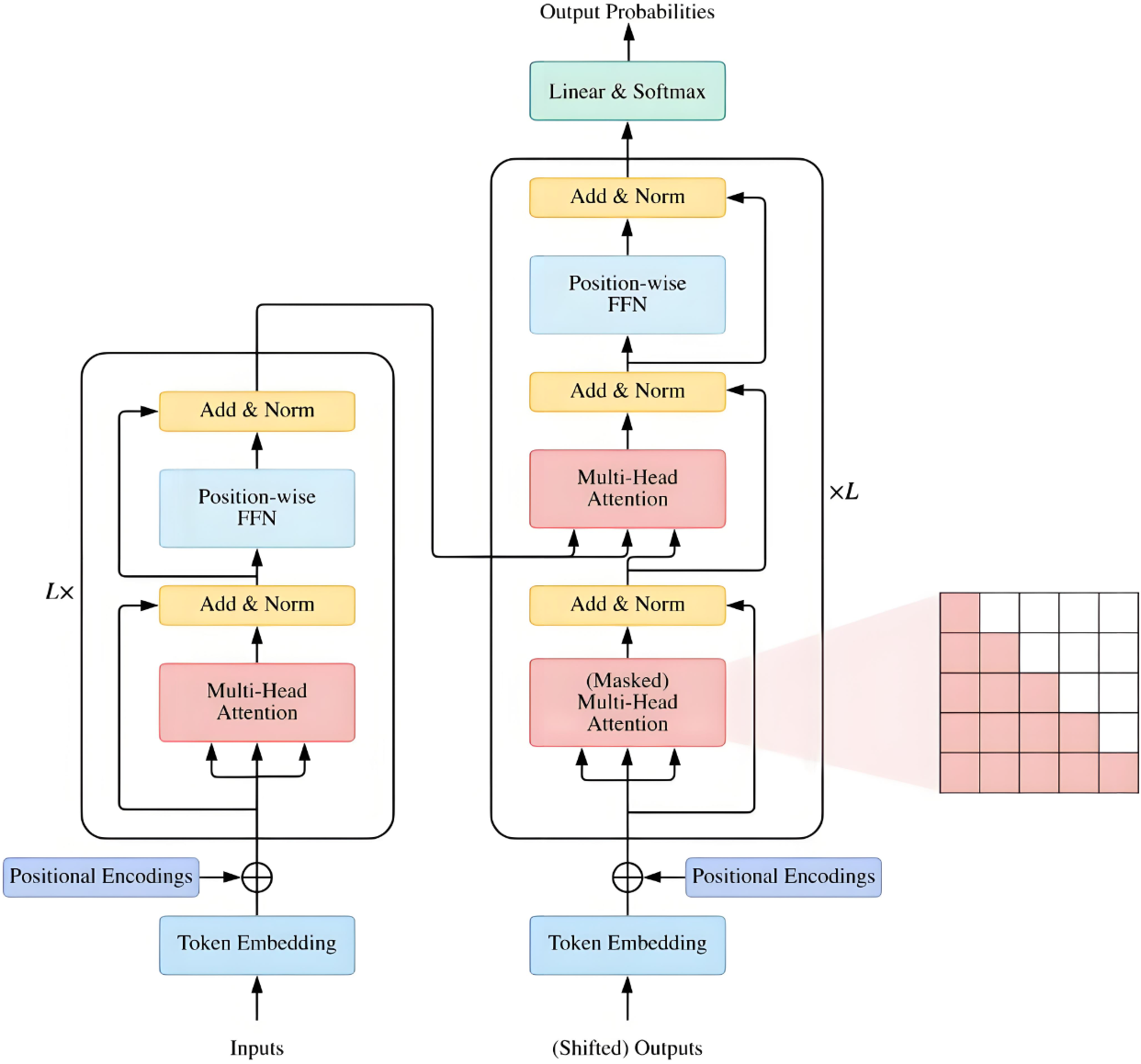
内部结构:
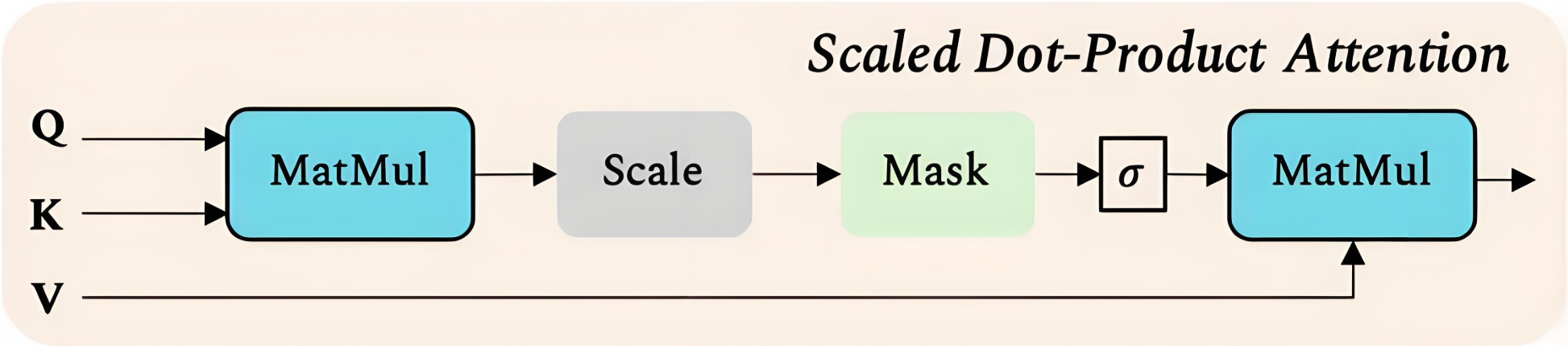
新增了Mask:先Mask,后通过 s o f t m a x softmax softmax 得到归一化的注意力权重。
Z = softmax ( Q K T d q + M ) V M ∈ R n × n Z = \text{softmax}\left( \frac{Q K^T}{\sqrt{d_q}} + M \right) V \\ M \in \mathbb{R}^{n \times n} Z=softmax(dqQKT+M)VM∈Rn×n
3.2.1.3 实现步骤
例子:以 0 1 2 3 4 5 0\:1\:2\:3\:4\:5 012345 分别表示 <Begin> I have a cat <end>,实现步骤如下:
第一步:
Decoder输入矩阵 X X X:包含 <Begin>l have a cat (0,1,2,3,4) 五个单词的表示向量。
Mask矩阵:是一个 5 × 5 5\times5 5×5 的上三角矩阵。
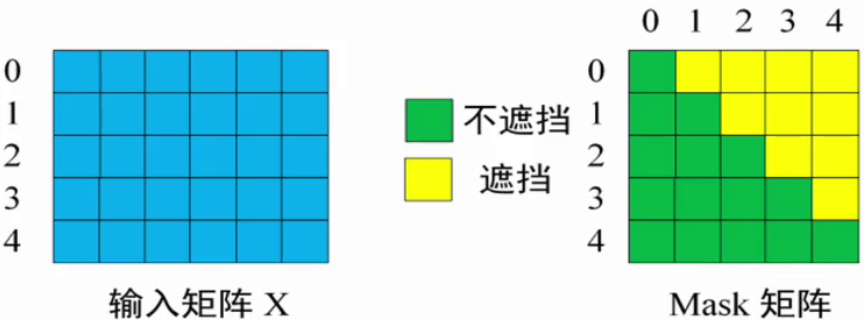
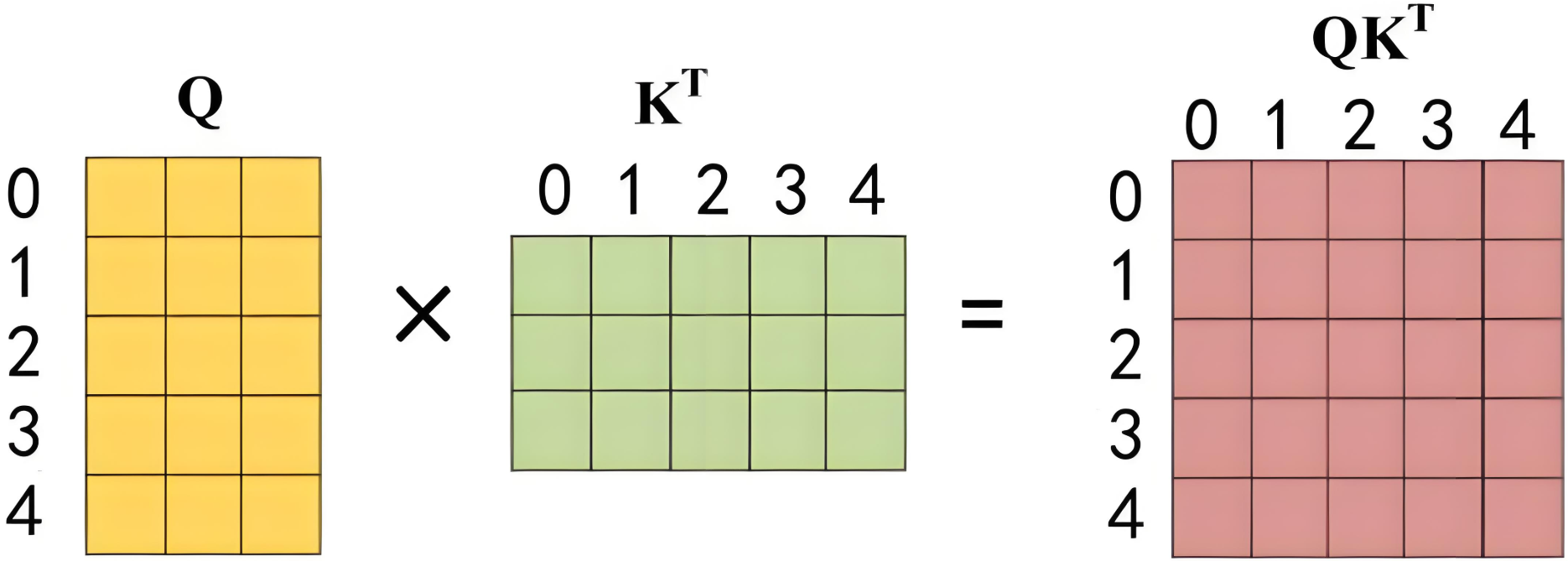
**第二步:**标准的自注意力计算中间特征,和masked无关
通过输入矩阵 X X X 计算得到 Q , K , V Q,K,V Q,K,V 矩阵,然后计算 Q Q Q 和 K T K^T KT的乘积 Q K T QK^T QKT
第三步: 计算中间特征
计算注意力分数,在 S o f t m a x Softmax Softmax 之前需要使用Mask矩阵遮挡住每个单词之后的信息。
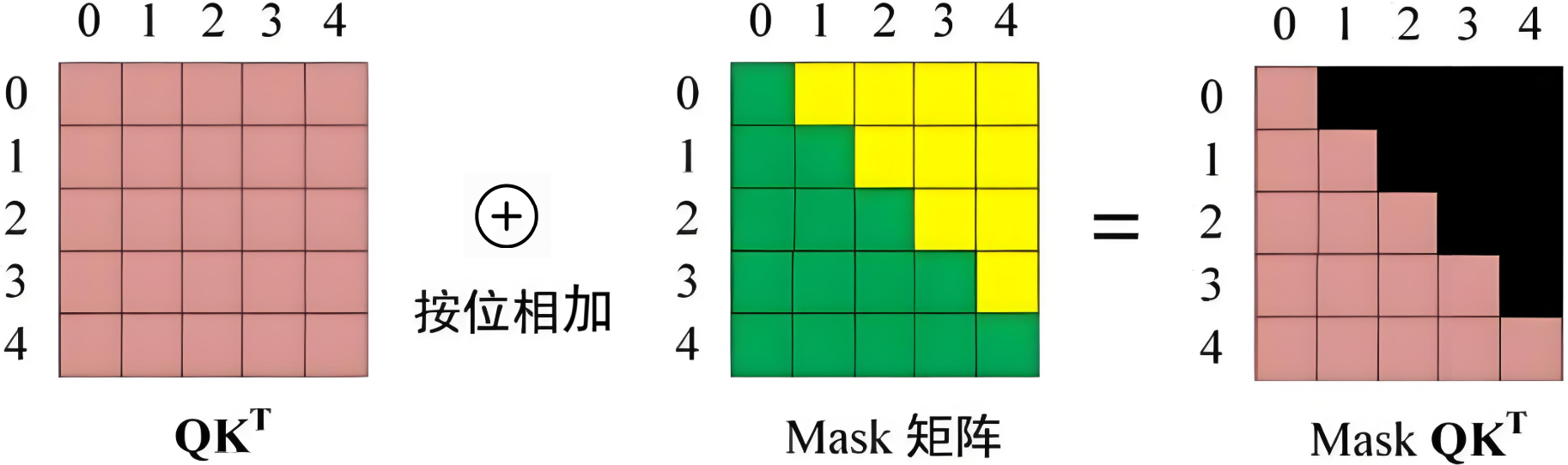
其中,黑色部分表示注意力值为 0 0 0。
**Mask $ QK^T$ **每一行的和为 1 1 1,词 0 0 0 在词 1 , 2 , 3 , 4 1,2,3,4 1,2,3,4 上注意力值为 0 0 0,词 1 1 1 在词 2 , 3 , 4 2,3,4 2,3,4 上注意力值为 0 0 0,以此类推。
Mask矩阵数学表示如下:
M i j = { 0 , if i ≥ j − ∞ , if i < j M_{ij} = \begin{cases} 0, & \text{if } i \geq j \\ -\infty, & \text{if } i < j \end{cases} Mij={0,−∞,if i≥jif i<j
其中:
- M i j = 0 当 i ≥ j M_{ij} = 0 \quad 当 i \geq j Mij=0当i≥j,即当前位置 i i i 可以看到自己及之前的所有位置。
- M i j = − ∞ 当 i < j M_{ij} = -\infty \quad 当i < j Mij=−∞当i<j,即当前位置 i i i 不允许看到未来的任何位置。
针对当前例子Masked矩阵如下:
M = ( 0 − ∞ − ∞ − ∞ − ∞ 0 0 − ∞ − ∞ − ∞ 0 0 0 − ∞ − ∞ 0 0 0 0 − ∞ 0 0 0 0 0 ) M = \begin{pmatrix} 0 & -\infty & -\infty & -\infty & -\infty \\ 0 & 0 & -\infty & -\infty & -\infty \\ 0 & 0 & 0 & -\infty & -\infty \\ 0 & 0 & 0 & 0 & -\infty \\ 0 & 0 & 0 & 0 & 0 \end{pmatrix} M= 00000−∞0000−∞−∞000−∞−∞−∞00−∞−∞−∞−∞0
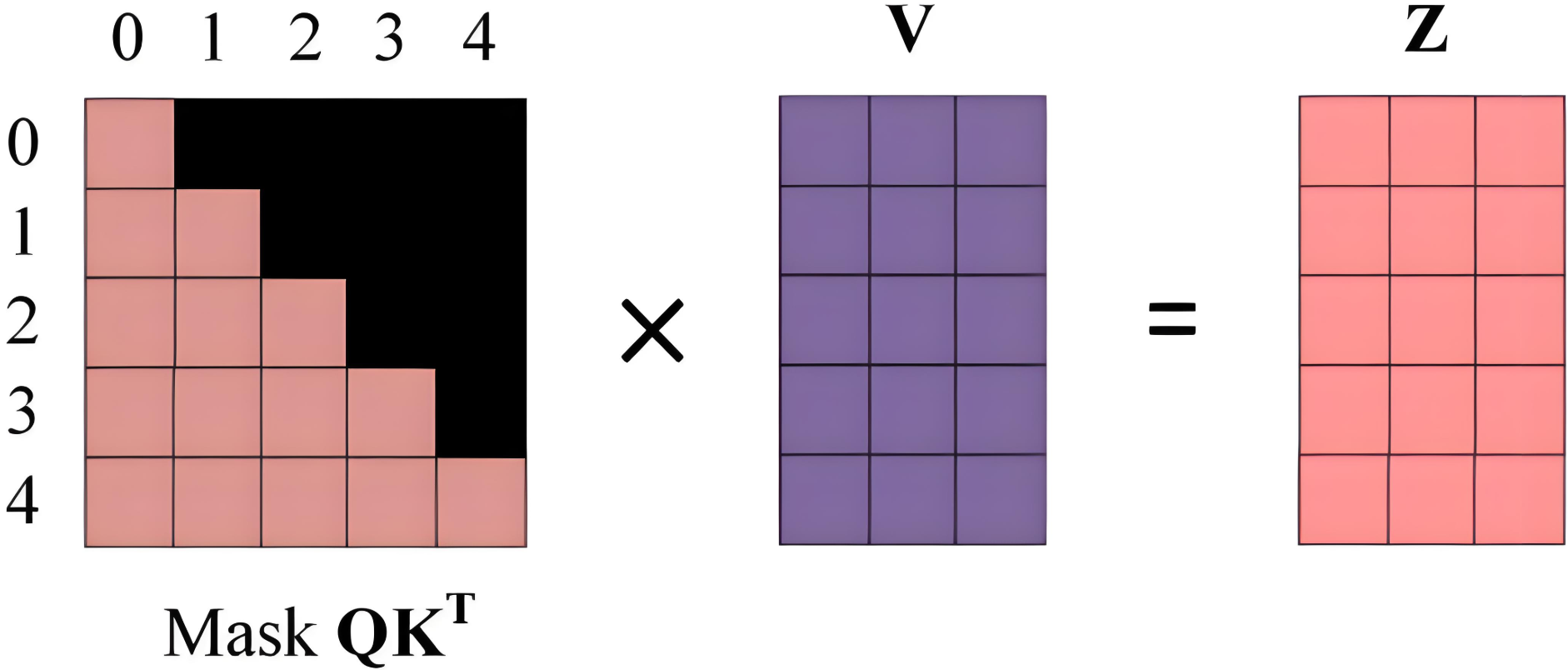
第四步: 计算输出特征
使用注意力矩阵**Mask $ QK^T$ **与矩阵 V V V 相乘,得到输出 Z Z Z,单词 1 1 1 的输出向量 Z 1 Z_1 Z1,只包含单词 1 1 1 信息,单词 2 2 2 的输出向量 Z 2 Z_2 Z2,只包含单词 1 、 2 1、2 1、2 信息,以此类推。
3.2.2 Add&Norm
同上:代码实现的时候,先Norm后Add
3.2.3 Multi-Head Attention
这是解码模块第二个Multi-Head Attention
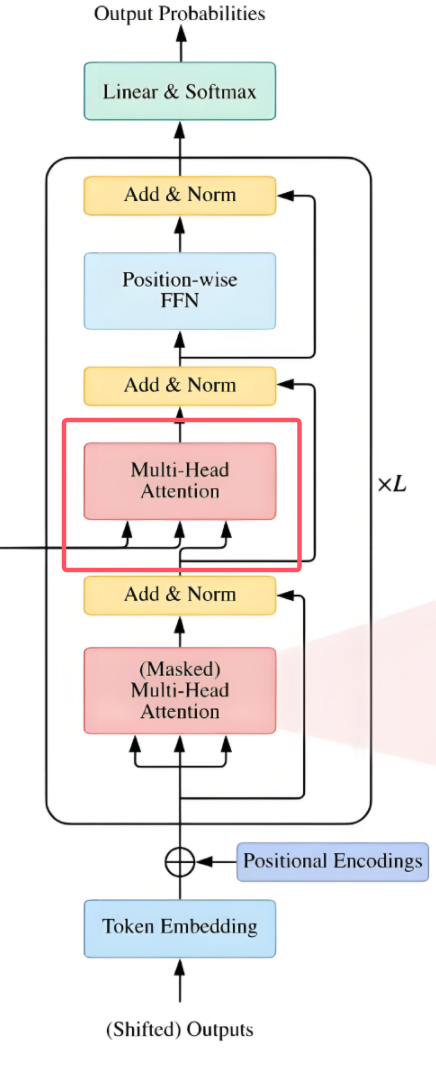
说明:
- 根据Encoder的输出 C C C 计算得到 K , V K,V K,V;
- 根据上一个 Decoder block 的输出 Z Z Z 计算 Q Q Q;
- 如果是第一个Decoder block则使用输入矩阵 X X X 进行计算;
3.2.4 Feed Forward
就是以前的知识点
4. 输入模块
输入模块是将原始输入数据转换为适合网络处理的向量表示:单词嵌入向量 + 位置编码向量。
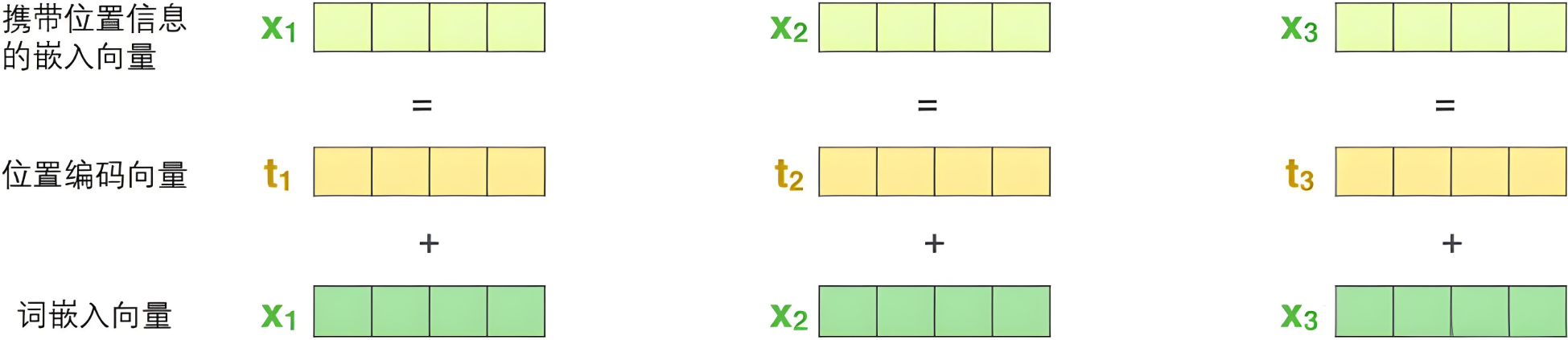
词嵌入向量:
可以采用 Word2Vec、Fasttext、Glove等算法预训练得到,也可以在 Transformer 中训练得到。
位置编码向量:
- Transformer模型没有像RNN或CNN那样的顺序信息;
- 需要显式地将位置信息加入到输入中,以让模型知道各个元素在序列中的位置;
- 位置编码通过添加一个与词嵌入同维度的向量来实现,它为每个位置提供一个唯一的表示;
- 位置编码可以是固定函数或可学习的。
4.1 单词输入
单词输入采用词嵌入就可以了,比较直接。

4.1.1 向量填充
不同训练句子单词个数通常是不一样,为了确保同一batch中的序列长度一致,便于批量处理,我们需要做向量填充操作。
- 可以简单统计所有训练句子的单词个数,取最大值,如 10 10 10;
- 编码器输入是 10 × 512 10\times512 10×512,额外填充的512维向量可以采用固定的标志编码得到,例如$$、0。
- 如果遇到极端的特别长的,可以丢掉一部分特殊字符。
- 需要PaddingMask进行掩盖。
4.2 位置编码
自注意力机制无法捕捉输入元素序列的顺序,所以需要一种方法将单词的顺序合并到Transformer架构中,于是位置编码应运而生。
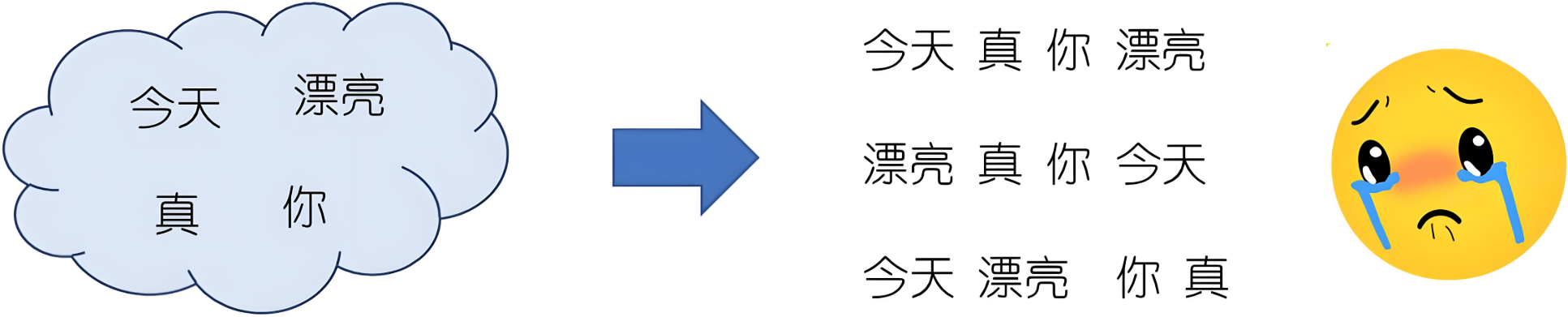
位置编码可以通过正弦和余弦函数生成,也可以通过学习得到。
4.2.1 固定函数
给定输入序列的长度 N N N 和词向量的维度 d d d,对于第 i i i 个位置和第 j j j 个维度的编码,位置编码的计算公式如下:
$$
PE(i, 2j) = \sin\left(\frac{i}{10000^{2j/d}}\right) \
PE(i, 2j+1) = \cos\left(\frac{i}{10000^{2j/d}}\right)
$$
sentence = “ 我 喜欢 自然语言 处理” N = 5 d = 512
说明:
-
i i i 是序列中位置的索引(从 0 0 0 开始)。
-
j j j 是词向量的维度索引(从 0 0 0 到 d / 2 − 1 d/2 - 1 d/2−1)。
-
10000 10000 10000 是一个超参数,用于控制频率的衰减。

-
计算得到的位置编码会直接加到词嵌入中。
-
所有句子共享这个位置编码矩阵。
4.2.1.1 函数特点
- 连续性:通过正弦和余弦的方式,位置编码具有平滑的特性,便于捕捉位置间的连续性。
- 可区分性:每个位置编码的值都是唯一的,可以帮助模型区分不同位置。
4.2.1.2 位置可控性
正弦余弦函数特征:
sin ( α + β ) = sin α cos β + cos α sin β cos ( α + β ) = cos α cos β − sin α sin β \sin(\alpha + \beta) = \sin \alpha \cos \beta + \cos \alpha \sin \beta \\ \cos(\alpha + \beta) = \cos \alpha \cos \beta - \sin \alpha \sin \beta sin(α+β)=sinαcosβ+cosαsinβcos(α+β)=cosαcosβ−sinαsinβ
基于此特性,对于固定长度的间距 k k k, P E ( p o s + k ) PE(pos+k) PE(pos+k) 可以用 P E ( p o s ) PE(pos) PE(pos) 计算得到。
P E ( i + k , 2 j ) = P E ( i , 2 j ) × P E ( k , 2 j + 1 ) + P E ( i , 2 j + 1 ) × P E ( k , 2 j ) P E ( i + k , 2 j + 1 ) = P E ( i , 2 j + 1 ) × P E ( k , 2 j + 1 ) − P E ( i , 2 j ) × P E ( k , 2 j ) PE(i+k,2j)=PE(i,2j)\times PE(k,2j+1)+PE(i,2j+1)\times PE(k,2j) \\ PE(i+k,2j+1)=PE(i,2j+1)\times PE(k,2j+1)-PE(i,2j)\times PE(k,2j) PE(i+k,2j)=PE(i,2j)×PE(k,2j+1)+PE(i,2j+1)×PE(k,2j)PE(i+k,2j+1)=PE(i,2j+1)×PE(k,2j+1)−PE(i,2j)×PE(k,2j)
那这个有啥玩意用处呢?假设k=1,那么:
- 下一个词语的位置编码向量可由前面的编码向量线性表示;
- 使模型能适应比训练集里面最长的句子更长的句子。
假设训练集最长的句子是 20 20 20 个单词,输入长度为 21 21 21 个单词的句子,则可以计算出第 21 21 21 位的位置向量
4.2.1.3 位置编码可视化
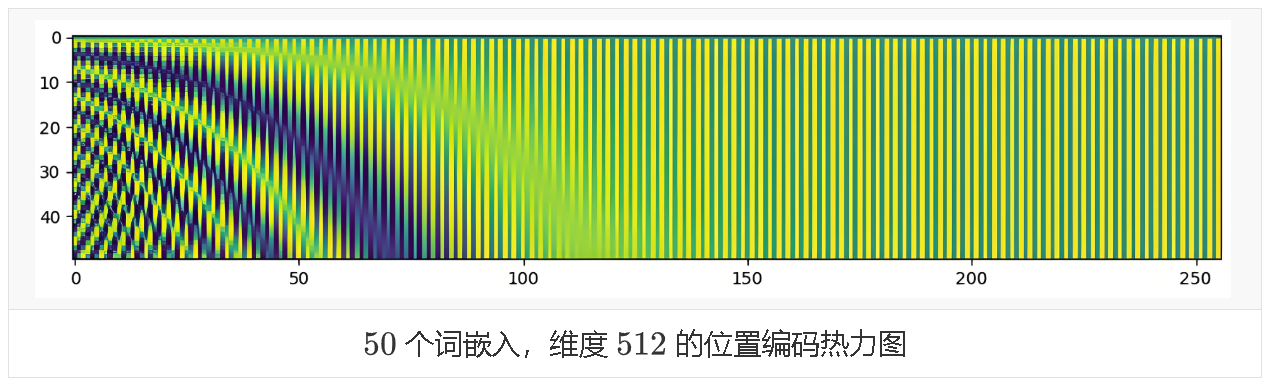
4.2.2 可学习位置编码
也有研究者提出了可学习的位置编码。可学习的位置编码通过训练优化得到位置向量。相比之下,固定函数位置编码不需要训练,但表现有时不如学习到的位置编码。
5. 解码输出
解码器的最终输出通过线性变换和 S o f t m a x Softmax Softmax 函数,生成每个时间步的概率分布。
5.1 基本流程
-
编码器输出:K 和 V;
- 通过线性变换映射出 K 和 V
- 输入到解码器的第二个注意力模块,这就是Cross-Attention
-
解码器输入:
- 第一个编码器:<BOS> + K 和 V
- 后续的解码器:已有解码器输出 + K 和 V
-
针对案例:
- 输入开始解码==[<BOS>]== ,预测 i i i
- 输入已解码的==[<BOS>, i i i]==,预测 a m am am
- 输入已解码的==[<BOS>, i , a m i, am i,am]==,预测 a a a,以此类推
- 输入已解码的==[<BOS> , i , a m , a , s t u d e n t i ,am,a,student i,am,a,student]==,预测 <EOS>
- 预测结束
5.2 预测输出
解码器经线性变换后,基于 S o f t m a x Softmax Softmax 输出概率值,它表示对词汇表中每个词的概率。
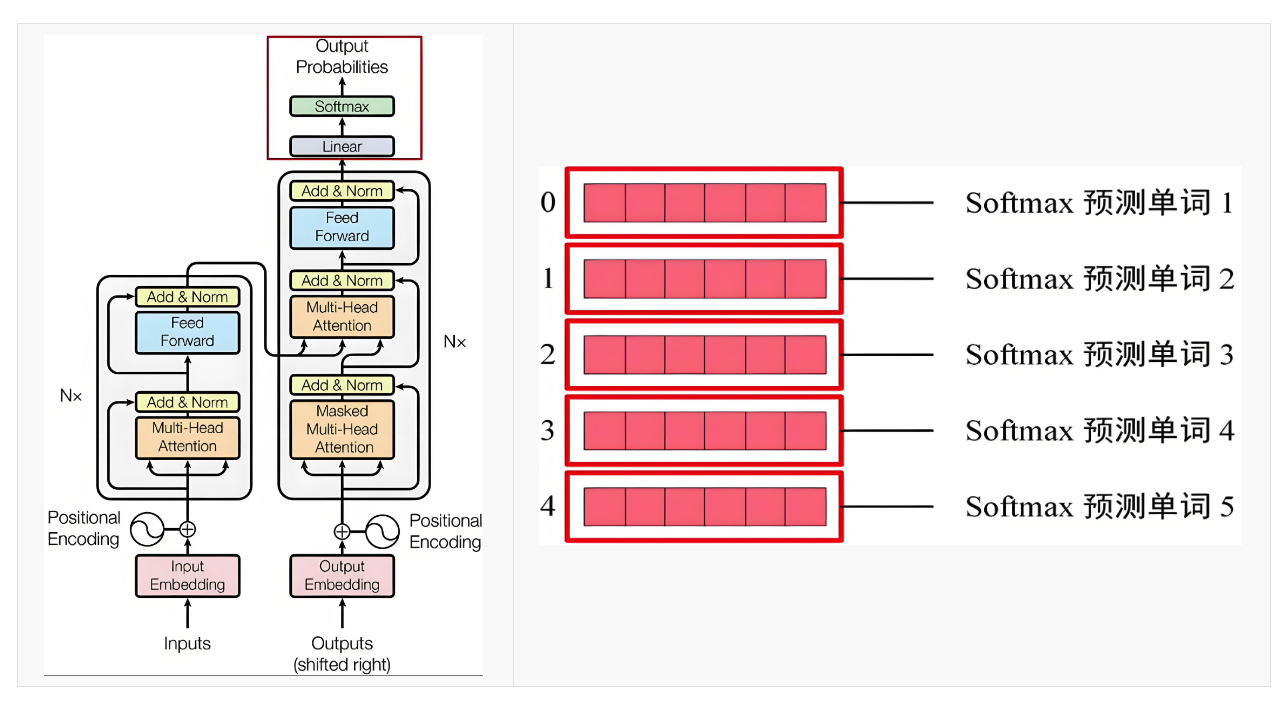
具体过程:
- 解码器输出:每个时间步输出一个隐藏状态。
- 线性层:解码器的输出经线性变换层映射到目标词汇表,得到一个原始分数。
- S o f t m a x Softmax Softmax: 经 S o f t m a x Softmax Softmax后,得到一个概率分布,最大概率值对应的词就是预测结果。
5.3 训练与推理
在训练与推理过程中,解码器的工作机制是有差异的。
5.3.1 训练阶段
- 在训练时,解码器的当前输入是真实目标序列,叫做teacher forcing。
- 直接使用真实标签输入,避免了错误传播,模型能更快收敛。
| 输入给解码器 | 目标标签(预测目标) |
|---|---|
<BOS> | I |
<BOS>, I | am |
<BOS>, I, am | a |
| … | … |
5.3.2 推理阶段
-
没有真实答案提供,模型只能自己一步步预测出来!
-
每一步的输出会被作为下一步的输入
当前输入给解码器 模型预测输出 <BOS>I(模型预测的)<BOS>, Iam(模型预测)<BOS>, I, ama<BOS>, I, am, astudent<BOS>, I, am, a, student<EOS> -
如前面预测错了,后面会受到影响,这就是所谓的 暴露偏差 问题。
6. 认知掩码
Padding Mask和Sequence Mask是两种常见的掩码机制。
6.1 PaddingMask
填充掩码。
输入的序列长度通常不同,为了进行批处理,需要对短序列进行填充,使得所有输入序列长度一致。填充符号(如 <PAD>)并不代表实际信息,因此需要被掩盖,以确保不会影响模型计算。
[‘我’, ‘喜欢’, , ]
6.1.1 使用场景
- 填充掩码用于自注意力计算中,避免填充部分对模型产生影响。
- 填充掩码一般用于编码器部分,也会传递到解码器部分,确保解码器不会基于填充符号做决策。
6.1.2 具体实现
- 实现:填充掩码通常是一个与输入序列长度相同的向量,把填充位置标记为 1 1 1,其他标记为 0 0 0。
- 掩膜过程:在计算注意力权重时,把填充位置的注意力值设为 − ∞ -∞ −∞, S o f t m a x Softmax Softmax 后为 0 0 0,从而忽略这些位置。
6.2 SequenceMask
序列掩码主要用于解码阶段,尤其在生成任务中,确保模型在生成每个词时只依赖已生成部分,而不会看到未来的词。
6.2.1 使用场景
- 在生成任务中,解码器的自注意力机制需要被限制,以确保只使用已生成的词进行生成。
- Sequence Mask主要用于解码器的自注意力层中,防止模型在生成当前词时,看到后续词汇。
6.2.2 具体实现
- 实现:序列掩码通常是一个上三角矩阵,掩码位置标记为 − ∞ -∞ −∞,表示这些位置的词在当前步骤不可见。
- 掩膜过程:在计算解码器自注意力时,序列掩码将未来的词的注意力设为 − ∞ -∞ −∞,确保模型只能“看到”已生成的词。
6.3 掩码对比
| 掩码类型 | 使用场景 | 描述 |
|---|---|---|
| Padding Mask | 输入序列存在填充符号时 | 避免填充符号对自注意力计算产生影响,确保模型只关注有效单词。 |
| Sequence Mask | 解码阶段,生成任务中的自回归生成 | 防止模型看到当前时间步之后的词,确保生成顺序的正确性。 |
- Padding Mask主要用于编码器和解码器中处理输入填充符号的问题。
- Sequence Mask主要应用于解码器,确保生成过程中模型只依赖于已经生成的部分,而不能访问未来的词。
掩码机制确保了自注意力机制能够在不同任务中正确处理输入和生成序列,保障模型的有效性和稳定性。