LightGBM的python实现及参数优化
文章目录
- 1. LightGBM模型参数介绍
- 2. 核心优势
- 3. python实现LightGBM
- 3.1 基础实现
- 3.1.1 Scikit-learn接口示例
- 3.1.2 Python API示例
- 3.2 模型调优
- 3.2.1 GridSearchCV简介
- 3.2.2 LightGBM超参调优
- 3.2.3 GridSearchCV寻优结果
在之前的文章 Boosting算法【AdaBoost、GBDT 、XGBoost 、LightGBM】理论介绍及python代码实现 中重点介绍了AdaBoost算法的理论及实现,今天对LightGBM 如何实现以及如何调参,着重分析一下。
LightGBM是基于决策树算法的分布式梯度提升框架,属于GBDT(Gradient Boosting Decision Tree)家族,与XGBoost、CatBoost并称为三大主流GBDT工具。
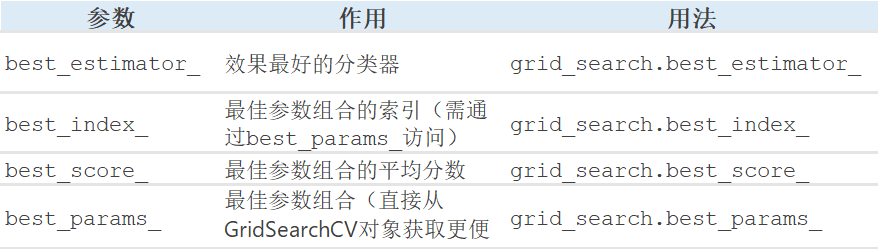
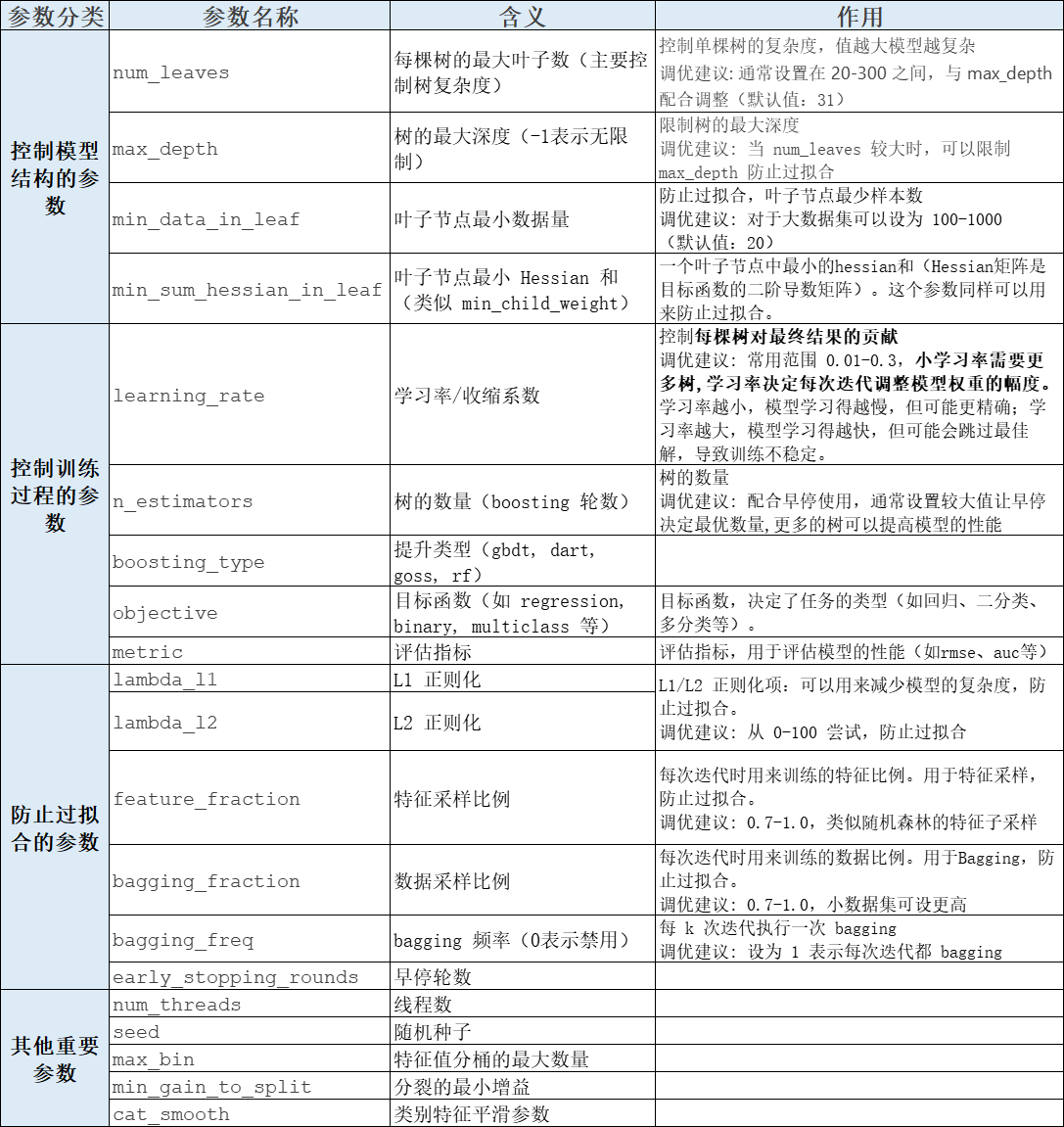
1. LightGBM模型参数介绍




2. 核心优势

与XGBoost相比较
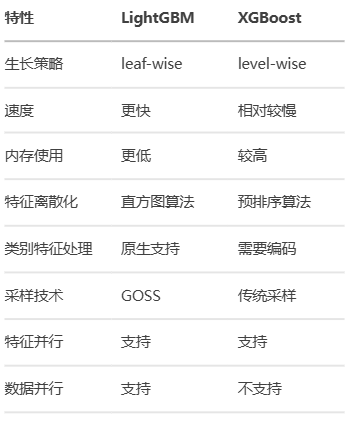
3. python实现LightGBM
3.1 基础实现
3.1.1 Scikit-learn接口示例
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix,mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#导入数据
data = load_breast_cancer()
X = data.data
y = data.target# 分割数据集,80%作为训练集,20%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)# 创建Dataset
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)# 设置参数
params = {'objective': 'binary', #目标函数,决定了任务的类型(二分类 regression 回归)'metric': 'binary_logloss', #二分类对数损失(Binary Logarithmic Loss)'num_leaves': 31,'learning_rate': 0.05,'feature_fraction': 0.9
}# 训练模型
gbm = lgb.train(params,train_data,num_boost_round=100,valid_sets=[test_data],early_stopping_rounds=10)# 预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)# 评估
rmse = mean_squared_error(y_test, y_pred)
print(f'Test RMSE: {rmse}')
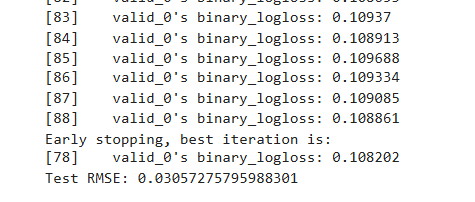
3.1.2 Python API示例
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix,mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#导入数据
data = load_breast_cancer()
X = data.data
y = data.target# 分割数据集,80%作为训练集,20%作为测试集
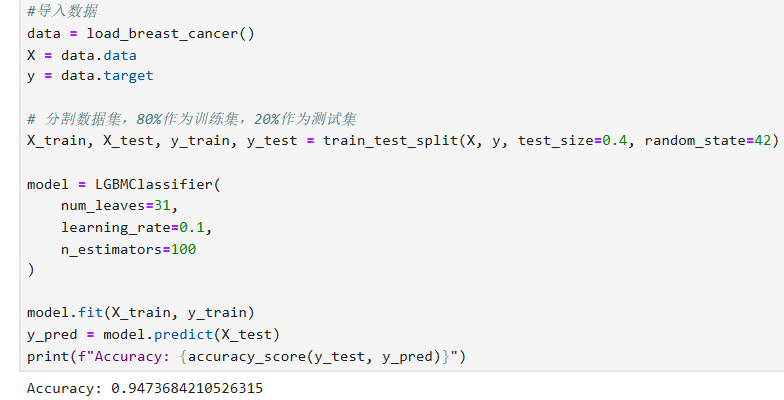
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)model = LGBMClassifier(num_leaves=31,learning_rate=0.1,n_estimators=100
)model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
3.2 模型调优
模型调优也参考之前自己写过的文档
Python模型优化超参寻优过程
GridSearchCV是scikit-learn库中用于超参数调优的重要工具,它通过网格搜索和交叉验证的方式寻找最优的模型参数组合,下面介绍使用GridSearchCV对LGBM参数调优。
3.2.1 GridSearchCV简介
关于GridSearchCV简单再介绍一下

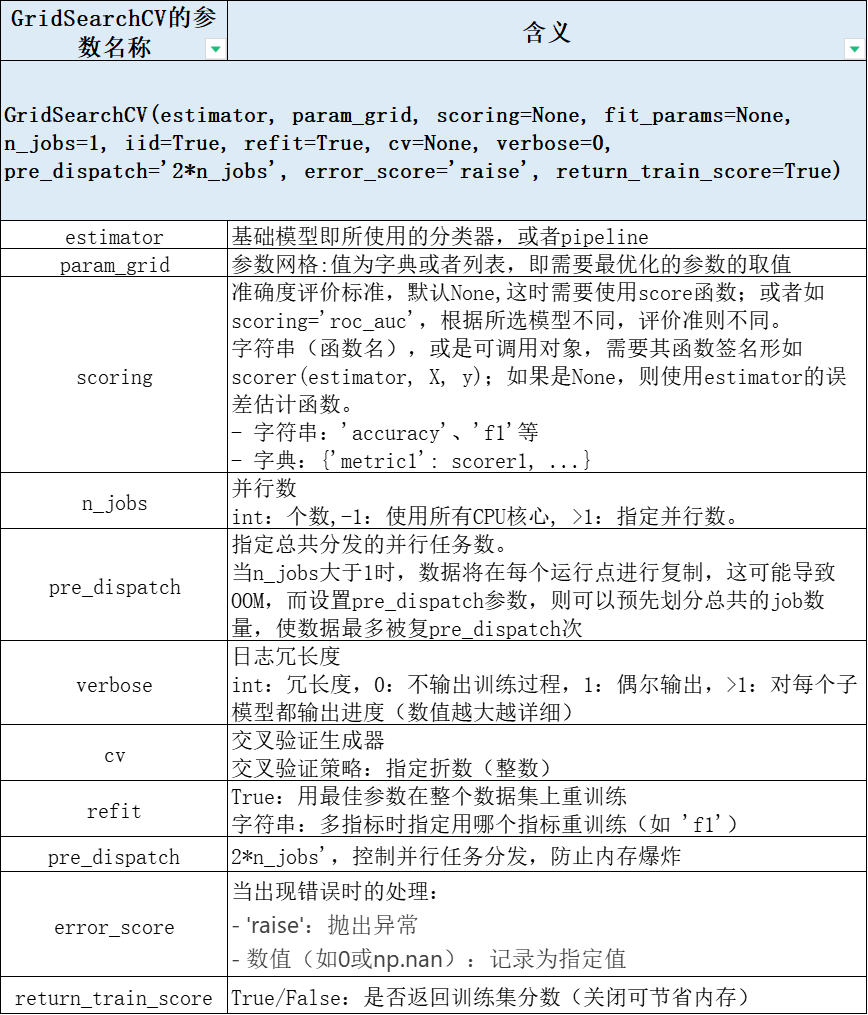
机器学习-GridSearchCV scoring 参数设置!
3.2.2 LightGBM超参调优
(三)提升树模型:Lightgbm原理深入探究 这篇文章里的关于Lightgbm优化比较深入,感兴趣的可以仔细阅读。
本部分的实现即对LightGBM介绍的参数使用GridSearchCV进行调优,python代码见下
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.datasets import load_breast_cancer
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix,mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#导入数据
breast_cancer = load_breast_cancer()
breast_cancer_df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
breast_cancer_df['target'] = breast_cancer.targetdaoshu = 20
X = breast_cancer_df.iloc[:,:-1]
y = breast_cancer_df.iloc[:,-1]
XGB_X = X[:-daoshu]
XGB_y = y[:-daoshu]
# 分割数据集,80%作为训练集,20%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)lgb_class = lgb.LGBMClassifier()
# GridSearchCV 参数网格-----------------------------------------------------------
param_grid = {'max_depth': [5,7],'learning_rate': [0.1, 0.5],'n_estimators': [100, 500],'num_leaves':[31,51],'reg_alpha':[0.5,0.8,1],'reg_lambda':[0.5,1]
}grid_search = GridSearchCV(estimator=lgb_class, param_grid=param_grid, scoring='neg_mean_squared_error', cv=2, verbose=2)
grid_search.fit(X_train, y_train)
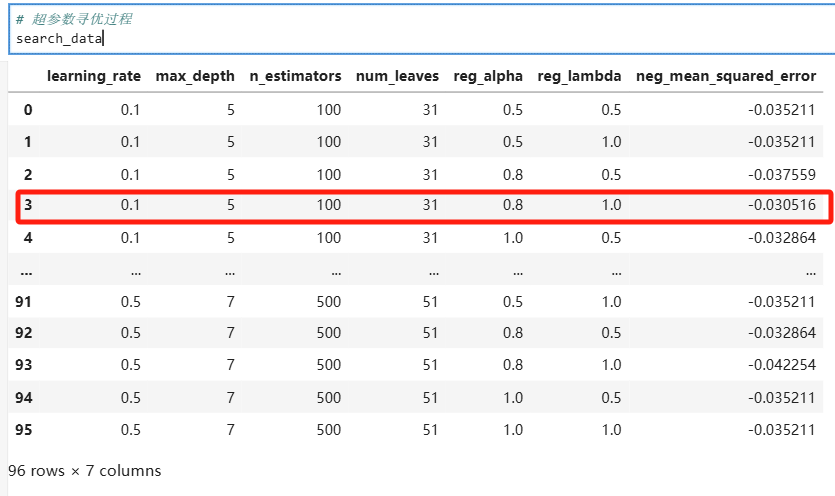
#网格查找每个参数时的-MSE
par =[]
par_mses = []
for i, par_mse in zip(grid_search.cv_results_['params'],grid_search.cv_results_['mean_test_score']):# print(i, par_mse)par.append(i)par_data = pd.DataFrame(par) par_mses.append(par_mse)par_rmsedata = pd.DataFrame(par_mses)
search_data = pd.concat([par_data,par_rmsedata],axis=1)
search_data = search_data.rename(columns={0:"neg_mean_squared_error"})
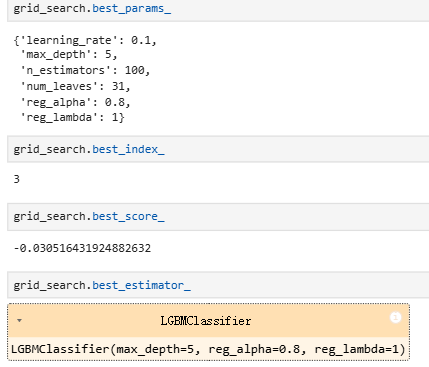
# 输出最优参数信息
best_params = grid_search.best_params_
print('best_score:',grid_search.best_score_)
print(f"best_params: {best_params}")
print('best_index:',grid_search.best_index_)
print('best_estimator:',grid_search.best_estimator_)# 使用最优参数训练模型
lgb_class_optimized = lgb.LGBMClassifier(**best_params)
lgb_class_optimized.fit(XGB_X, XGB_y)
# 预测
y_pred_optimized = lgb_class_optimized.predict(X)
rmse_optimized = np.sqrt(mean_squared_error(y, y_pred_optimized))
print(f"Optimized RMSE: {rmse_optimized:.4f}") #最终预测结果的 RMSE #可视化展示
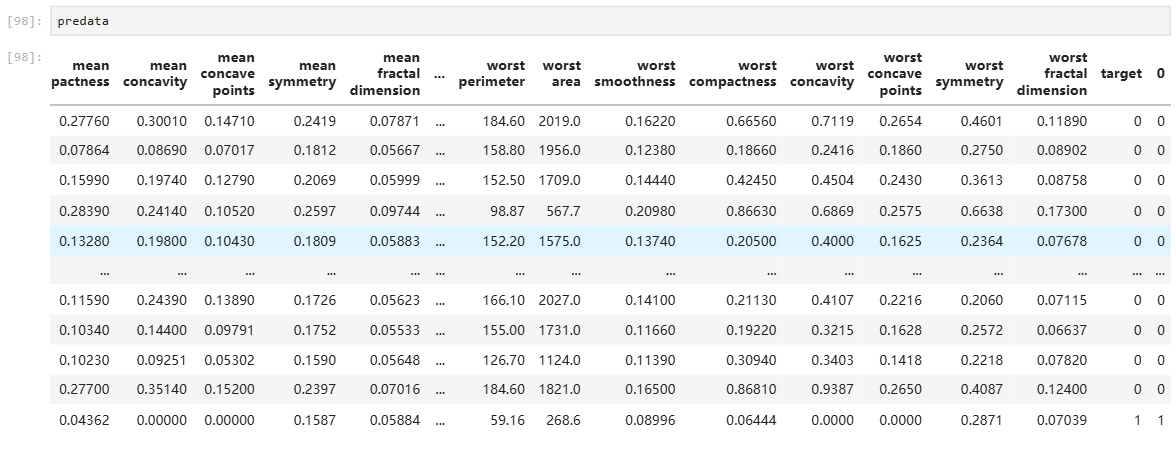
pre_target = pd.DataFrame(y_pred_optimized)
predata= pd.concat([breast_cancer_df,pre_target],axis=1)
plt.figure(figsize=(6,3))
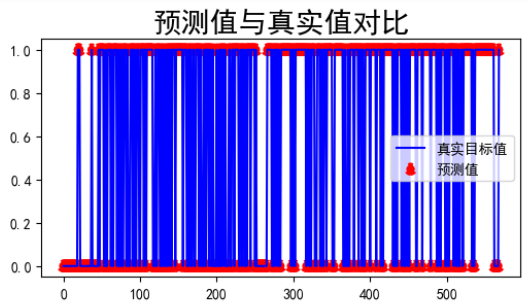
plt.plot(range(len(predata['target'])),predata['target'],c='blue')
plt.scatter(range(len(predata['target'])),predata.iloc[:,-1:],ls=':',c='red',lw=3)
plt.title('预测值与真实值对比', size= 20)
plt.legend(['真实目标值','预测值'])
plt.show()predata.tail()
部分结果展示

红色框为最优组合。
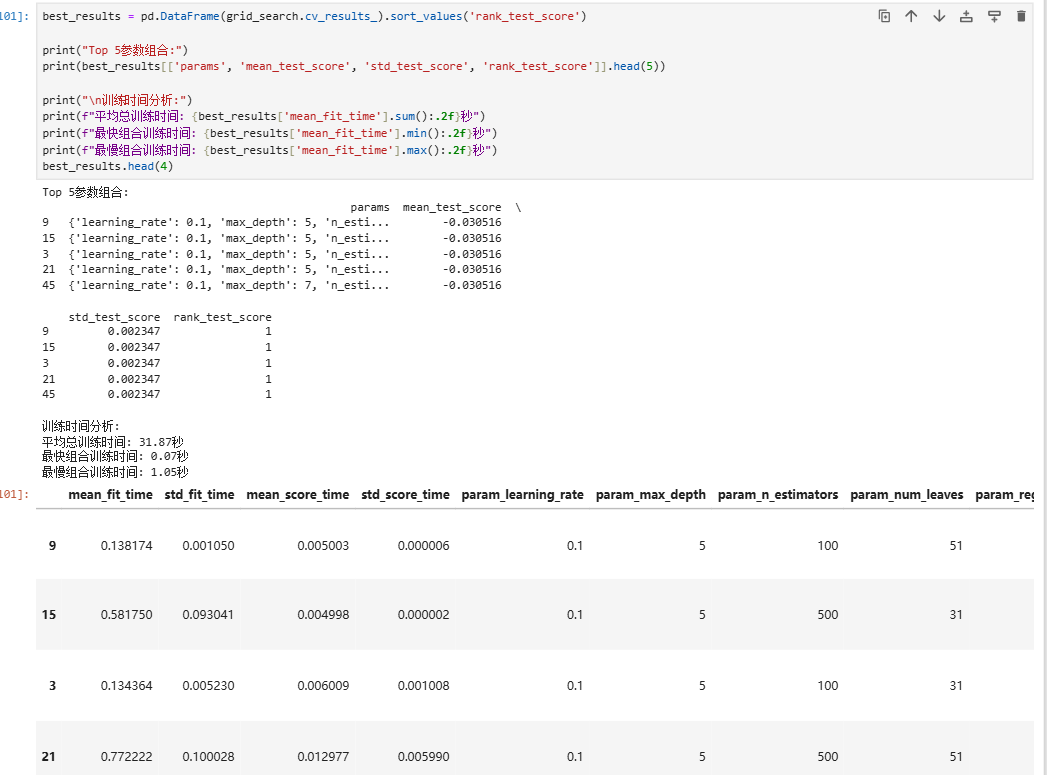
3.2.3 GridSearchCV寻优结果
# 最佳参数组合的详细信息
best_idx = grid_search.best_index_ # 即search_data表里的索引为 3
print(f"最佳参数组合: {grid_search.cv_results_['params'][best_idx]}")
print(f"平均验证分数: {grid_search.cv_results_['mean_test_score'][best_idx]:.4f}")
print(f"各折验证分数: {grid_search.cv_results_['split0_test_score'][best_idx]:.4f}, "f"{grid_search.cv_results_['split1_test_score'][best_idx]:.4f}, ...")

best_results = pd.DataFrame(grid_search.cv_results_).sort_values('rank_test_score')print("Top 5参数组合:")
print(best_results[['params', 'mean_test_score', 'std_test_score', 'rank_test_score']].head(5))print("\n训练时间分析:")
print(f"平均总训练时间: {best_results['mean_fit_time'].sum():.2f}秒")
print(f"最快组合训练时间: {best_results['mean_fit_time'].min():.2f}秒")
print(f"最慢组合训练时间: {best_results['mean_fit_time'].max():.2f}秒")
best_results.head(4)