人工智能AI之机器学习基石系列 第 2 篇:数据为王——机器学习的燃料与预处理
专栏系列:《人工智能AI之机器学习基石》②

高质量的数据是驱动机器学习模型的强大燃料
🚀 引言:无米之炊与数据的重要性
在上一篇文章《什么是机器学习?——开启智能之门》中,我们一起揭开了机器学习的神秘面纱,了解了它的基本概念、与AI和深度学习的关系,以及机器学习的三大核心要素。我们知道了,机器学习就像一个聪明的学生,能够从“经验”中学习。
那么,这个“经验”具体是什么呢?答案就是——数据。
俗话说,“巧妇难为无米之炊”。对于机器学习而言,数据就是那至关重要的“米”。没有数据,再强大的算法也无法施展其能;数据的质量,则直接决定了模型学习的上限和最终的性能。正如汽车需要高质量的汽油才能跑得又快又远,机器学习模型也需要高质量的数据作为“燃料”。
你可能会问:
- 数据真的那么重要吗?难道不是算法更关键?
- 我们从哪里获取数据?是不是所有数据都能直接用?
- 在把数据“喂”给模型之前,我们通常需要对它做些什么“手脚”呢?
这篇文章,就让我们聚焦机器学习的“生命之源”——数据,深入探讨数据在机器学习中的核心地位,以及在模型训练开始前,我们必须进行的那些关键的数据预处理工作。
💎 一、数据:机器学习的基石与“天花板”
在机器学习领域,流传着这样一句话:“Garbage in, garbage out.”(垃圾进,垃圾出)。这句话非常形象地说明了数据质量对于模型性能的决定性影响。
- 数据决定了模型的上限: 即使拥有最顶尖的算法,如果输入的是充满噪声、错误、偏见或者与问题不相关的数据,那么训练出来的模型效果也必然大打折扣,甚至完全不可用。好的数据能够为模型提供丰富且准确的信息,让模型学习到真实世界中潜在的规律和模式。
- 数据量与多样性同样重要:
- 数据量: 通常情况下,越多的高质量数据,越能帮助模型学习到更普适、更鲁棒的规律,减少过拟合的风险。想象一下,只看几张猫的图片就想让机器认识所有品种的猫,显然是不现实的。
- 多样性: 数据需要覆盖各种可能的情况和变化。例如,在训练人脸识别模型时,数据不仅要包含不同人的脸,还要包含不同光照、角度、表情、遮挡情况下的脸,这样模型才能在各种复杂场景下都表现良好。
- 算法与数据相辅相成: 优秀的算法能够更有效地从数据中提取信息,但算法的威力最终还是受限于数据的质量和所包含信息的丰富程度。在很多实际项目中,工程师们花费在数据收集、清洗、整理和标注上的时间,往往远超选择和调试算法的时间。
一个简单的例子:
假设我们要训练一个模型来识别图片中的苹果。
- 高质量数据: 我们提供了大量清晰的、各种品种、各种颜色、各种角度、不同背景下的苹果图片。模型就能很好地学习到苹果的通用特征。
- 低质量数据:
- 如果我们只提供了少量红富士苹果的图片,模型可能就无法识别青苹果或黄元帅。
- 如果图片中混入了很多梨,或者苹果的标签被错误地标成了橘子,模型就会学到错误的信息。
- 如果图片都非常模糊,模型也很难提取有效特征。
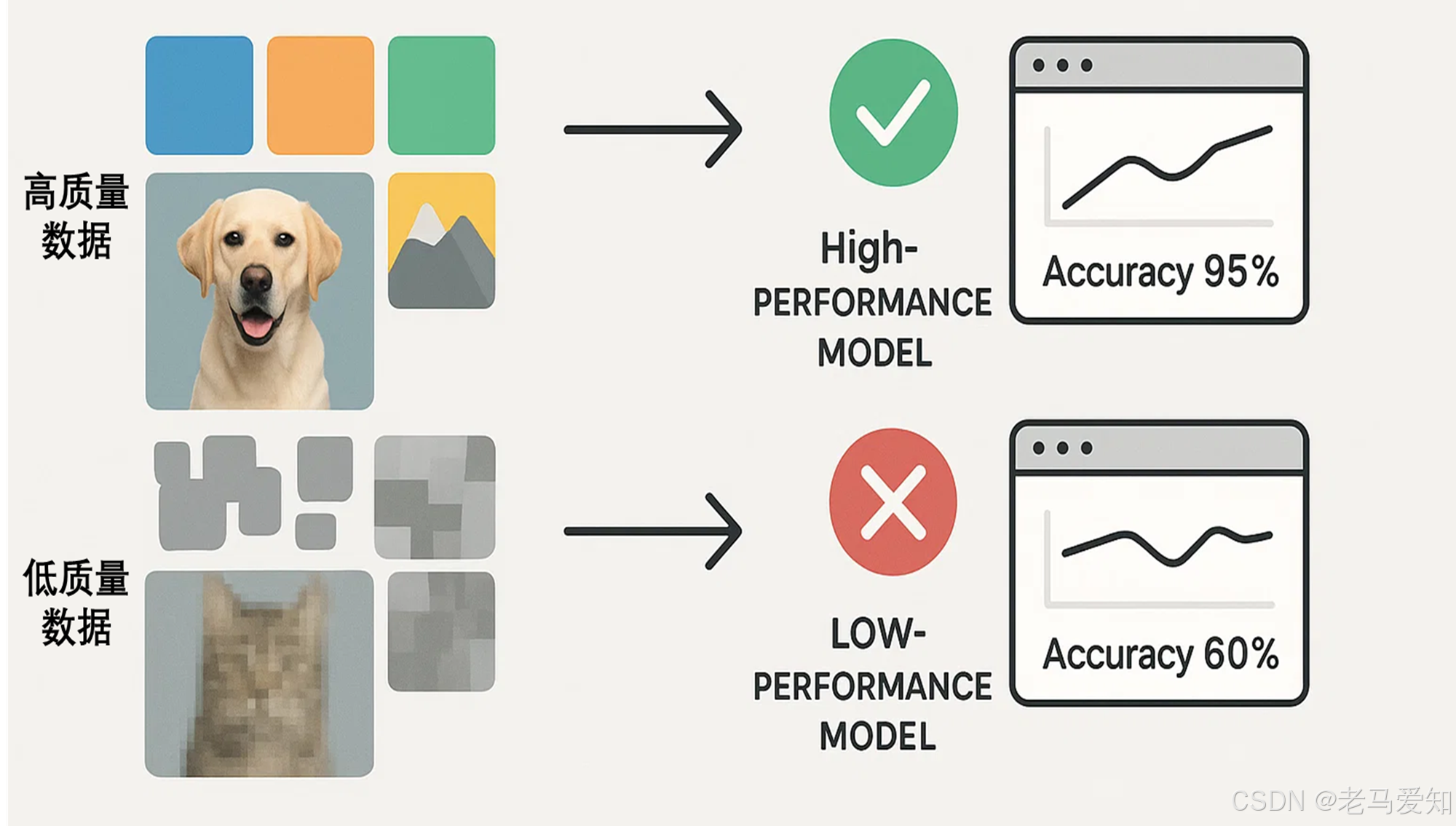 数据质量直接影响机器学习模型的学习效果
数据质量直接影响机器学习模型的学习效果
因此,在启动任何机器学习项目之前,首先要思考的问题就是:我们有什么样的数据?这些数据够不够好?我们如何才能获取到更好的数据?
🛠️ 二、数据预处理:让“粗粮”变“精粮”
在现实世界中,我们收集到的原始数据往往是“粗糙”的,就像未经加工的“粗粮”,不能直接“喂”给机器学习模型。它们可能包含各种各样的问题:
- 缺失值 (Missing Values): 数据中某些字段的值是空的。例如,在用户注册信息中,有些用户可能没有填写年龄。
- 异常值/离群点 (Outliers): 数据中存在一些与其他数据点显著不同的极端值。例如,在记录用户年龄时,出现了“200岁”这样的数据。
- 数据格式不一致: 例如,日期格式有的是“2023-10-26”,有的是“10/26/2023”。
- 重复数据 (Duplicate Data): 数据集中存在完全相同或高度相似的记录。
- 量纲差异巨大: 不同特征的数值范围可能相差悬殊。例如,房屋面积可能是几十到几百平方米,而卧室数量通常是个位数。
- 非数值特征: 很多机器学习算法只能处理数值型数据,但原始数据中常常包含文本、类别等非数值特征。
为了解决这些问题,让数据变得更“干净”、更“规整”、更适合模型学习,我们就需要进行一系列的数据预处理 (Data Preprocessing) 操作。这就像把“粗粮”加工成“精粮”的过程。
常见的数据预处理步骤包括:
2.1 数据清洗 (Data Cleaning)
数据清洗的目的是处理数据中的“脏”部分,提高数据的准确性和一致性。
- 处理缺失值:
- 删除: 如果缺失值占比很小,或者某个样本/特征大部分都是缺失的,可以直接删除该样本或特征。
- 填充/插补 (Imputation): 用某种策略填充缺失值,例如:
- 用均值、中位数或众数填充。
- 用模型预测(如K近邻、回归模型)来填充。
- 对于时间序列数据,可以用前一个值或后一个值填充。
- 处理异常值:
- 识别: 可以通过统计方法(如3σ原则、箱线图)、可视化或领域知识来识别异常值。
- 处理:
- 删除异常值。
- 将异常值视为缺失值进行处理。
- 对异常值进行修正或替换(例如,用盖帽法将其限制在一定范围内)。
- 处理重复数据: 识别并删除重复的记录。
- 数据格式转换与一致化: 将不同格式的数据统一起来。

数据清洗:去除数据中的“杂质”
2.2 特征转换 (Feature Transformation) / 特征编码 (Feature Encoding)
很多机器学习模型,特别是基于数学公式的模型(如线性回归、逻辑回归、支持向量机、神经网络等),通常要求输入是数值型的。因此,我们需要将非数值型的特征转换为数值型表示。
- 处理类别特征 (Categorical Features):
- 标签编码 (Label Encoding): 将类别标签直接映射为整数(例如,“红”->0,“绿”->1,“蓝”->2)。适用于有序类别特征,但对于无序类别特征,可能会引入不期望的顺序关系。
- 独热编码 (One-Hot Encoding): 为每个类别创建一个新的二元特征(0或1)。例如,颜色特征有“红、绿、蓝”三个取值,独热编码后会变成三个新特征:“是否为红色”、“是否为绿色”、“是否为蓝色”。这种方法避免了顺序问题,但如果类别过多,会导致特征维度急剧增加(维度灾难)。
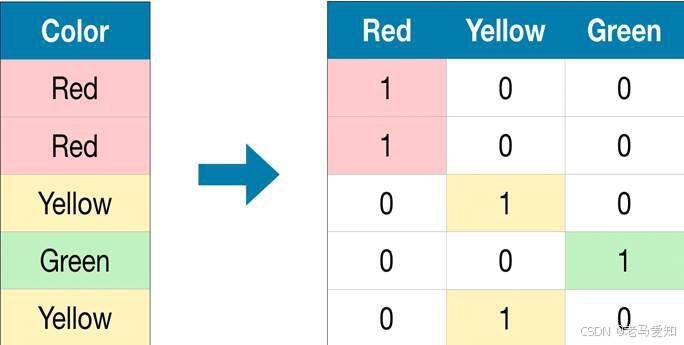
独热编码将类别特征转换为数值型
-
- 其他编码方式: 如哑变量编码 (Dummy Encoding,类似独热,但会移除一个类别以避免多重共线性)、目标编码 (Target Encoding)、频率编码等。
- 处理文本特征:
- 词袋模型 (Bag-of-Words, BoW): 将文本表示为一个词频向量。
- TF-IDF (Term Frequency-Inverse Document Frequency): 衡量一个词对于一篇文档的重要性。
- 词嵌入 (Word Embeddings): 如Word2Vec, GloVe, FastText,将词语映射到低维稠密向量空间,捕捉词语间的语义关系。这是现代自然语言处理中非常重要的方法。
- 处理日期和时间特征: 可以从中提取年、月、日、星期几、小时等作为新的数值特征。
2.3 特征缩放 (Feature Scaling)
当不同特征的数值范围(量纲)差异很大时,某些机器学习算法(如梯度下降法、K近邻、支持向量机等)可能会受到影响,使得数值范围大的特征在模型中占据主导地位,而数值范围小的特征被忽略。特征缩放可以将所有特征的值调整到相似的范围。
- 归一化 (Normalization / Min-Max Scaling): 将特征值缩放到一个固定的区间,通常是 [0, 1] 或 [-1, 1]。
公式:X_scaled = (X - X_min) / (X_max - X_min) - 标准化 (Standardization / Z-score Scaling): 将特征值转换为均值为0,标准差为1的分布。处理后的数据没有固定的范围,但对异常值不那么敏感。
公式:X_scaled = (X - μ) / σ (其中 μ 是均值,σ 是标准差)
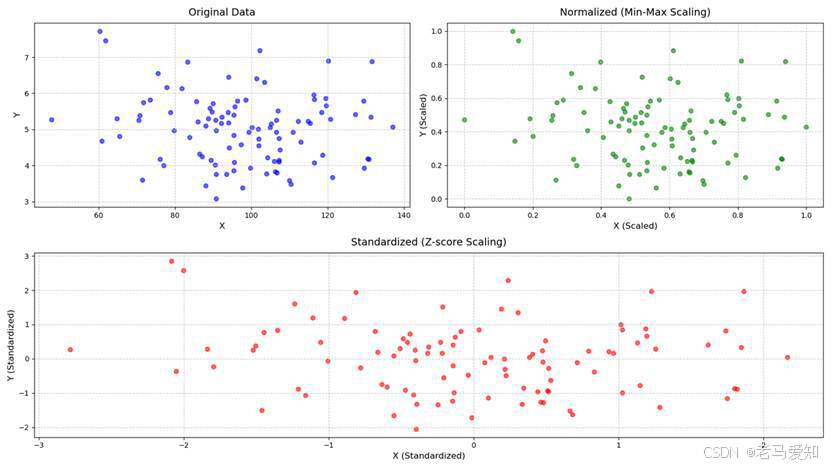
特征缩放可以消除不同特征量纲带来的影响
何时选择归一化或标准化?
- 如果算法对数据的分布有假设(如高斯分布),或者数据中异常值较多,标准化通常是更好的选择。
- 如果希望将数据严格限制在某个范围内(例如,在图像处理中像素值通常在0-255或0-1),或者算法对输入范围敏感(如某些神经网络激活函数),归一化可能更合适。
- 对于不依赖距离计算或梯度下降的算法(如决策树、随机森林),特征缩放通常不是必需的。
2.4 数据集划分 (Dataset Splitting)
在训练模型之前,我们通常需要将整个数据集划分为几个部分,以评估模型的性能并防止过拟合。
- 训练集 (Training Set): 用于训练模型,让模型学习数据中的规律。这是模型唯一能“看到”并从中学习的数据。
- 验证集 (Validation Set): 用于在训练过程中调整模型的超参数(例如,学习率、网络层数、正则化系数等),并对模型的性能进行初步评估。模型不会直接从验证集中学习参数,但验证集的表现会指导我们如何调整模型结构和训练过程。
- 测试集 (Test Set): 在模型训练和超参数调整都完成后,用于最终评估模型在未见过的新数据上的泛化能力。测试集的结果是衡量模型好坏的“最终成绩单”,它应该在整个训练和调优过程中保持“盲盒”状态,直到最后才使用。
常见的划分比例可能是 70% 训练集,15% 验证集,15% 测试集;或者 80% 训练集,20% 测试集(如果不需要显式的验证集,或者使用交叉验证)。

将数据集划分为训练集、验证集和测试集
交叉验证 (Cross-Validation): 当数据量较少时,为了更可靠地评估模型性能并充分利用数据,可以使用交叉验证。最常见的是K折交叉验证:将训练集分成K个互不相交的子集,每次用K-1个子集作为训练数据,剩下的1个子集作为验证数据,重复K次,最后取K次评估结果的平均值。
🌟 三、特征工程:点石成金的艺术
除了上述基础的数据预处理步骤,还有一个更具创造性和经验性的环节,对模型性能的提升往往起到至关重要的作用,那就是特征工程 (Feature Engineering)。
特征工程是指利用领域知识和数据分析技能,从原始数据中提取、构建或组合出对机器学习模型更有用、更能表达问题本质的新特征的过程。 好的特征工程能够:
- 提升模型性能: 让模型更容易学习到数据中的规律。
- 简化模型: 用更少的、但更有效的特征达到同样甚至更好的效果。
- 增强模型的可解释性: 有意义的特征更容易理解模型的决策过程。
特征工程的一些常见方法:
- 特征构建 (Feature Construction):
- 从现有特征组合出新特征。例如,从“长度”和“宽度”构建出“面积”特征。
- 从日期时间特征中提取“是否为周末”、“是否为节假日”等。
- 对数值特征进行分箱(Binning),将其转换为类别特征。例如,将年龄分为“青年”、“中年”、“老年”。
- 特征选择 (Feature Selection):
- 从众多特征中挑选出对模型预测最有帮助的子集,去除冗余或不相关的特征,以降低模型复杂度、减少过拟合、提高训练效率。
- 方法包括:过滤法(Filter methods,如卡方检验、互信息)、包裹法(Wrapper methods,如递归特征消除)、嵌入法(Embedded methods,如L1正则化)。
- 特征提取 (Feature Extraction):
- 通过某种变换将高维特征数据映射到低维空间,同时保留主要信息。
- 例如:主成分分析 (Principal Component Analysis, PCA)、线性判别分析 (Linear Discriminant Analysis, LDA)。
特征工程往往需要对业务问题和数据有深入的理解,是一个不断尝试和迭代的过程,有时甚至被认为是机器学习中的“艺术”。
💡 小结:数据准备是成功的一半
通过本篇文章,我们了解到:
- 数据是机器学习的基石,其质量和数量直接决定了模型的上限。
- 原始数据往往是“脏”的,需要进行一系列数据预处理操作,包括数据清洗、特征转换/编码、特征缩放和数据集划分。
- 特征工程是提升模型性能的关键步骤,它依赖于领域知识和创造性思维。
可以说,在整个机器学习项目中,数据准备工作(包括数据收集、预处理和特征工程)占据了绝大部分的时间和精力,但这也是最能体现“内功”和产生价值的地方。一个精心准备的数据集,往往比一个复杂高深的算法更能带来性能上的突破。
“Garbage in, garbage out.” 这句话时刻提醒我们,在踏上模型训练的征途之前,务必先打磨好我们手中的“利器”——数据。
🔭 下一篇预告:选择你的“学习方法”——初探监督学习与无监督学习
我们已经了解了机器学习是什么,以及数据的重要性。那么,机器具体是如何从数据中“学习”的呢?不同的学习任务需要不同的“学习方法”。下一篇文章,我们将开始探索机器学习的几种主要学习范式:
- 什么是监督学习 (Supervised Learning)?它如何解决分类和回归问题?
- 什么是无监督学习 (Unsupervised Learning)?它如何帮助我们发现数据中的隐藏结构,比如聚类和降维?
- 它们之间有什么区别和联系?各自适用于哪些场景?
敬请期待《人工智能AI之机器学习基石》系列的下一篇内容!