Elasticsearch索引机制与Lucene段合并策略深度解析
引言
在现代分布式搜索引擎Elasticsearch中,文档的索引、更新和删除操作不仅是用户交互的核心入口,更是底层存储架构设计的关键挑战。本文围绕以下核心链路展开:
- 文档生命周期管理:从客户端请求路由到分片定位,从内存缓冲区(Buffer)到事务日志(Translog)的双重写入机制,揭示数据持久化的完整路径;
- 实时性与可靠性平衡:通过剖析Translog同步/异步刷盘策略、内存缓冲区刷新(Refresh)与持久化刷盘(Flush)的触发逻辑,解读搜索可见性与故障恢复的底层保障;
- Lucene段合并优化:深入对比分层合并(TieredMergePolicy)、字节大小合并(LogByteSizeMergePolicy)和文档数量合并(LogDocMergePolicy)等策略,探讨如何通过段合并提升查询效率、释放磁盘空间并优化I/O负载。
通过系统性梳理,本文将为开发者提供从API操作到底层存储的全视角技术图谱,助力高性能搜索服务的设计与调优。
索引文档的过程
索引文档:将新的文档添加到索引中或者覆盖已经存在的文档。
并非只有协调节点可能进行数据转发,可以将请求发送到任何一个数据节点,该节点都可以处理请求或将请求转发给适当的节点以完成请求处理。
- 客户端向 Node 1 (任意一个节点)发送新建、覆盖请求。
- 节点使用文档ID(文档ID可以人工指定,不指定将自动创建唯一值) 确定文档属于分片 0(hash(_id)%number_of_primary_shards) 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 写入操作不仅保存在内存缓冲区中,同时也被记录到事务日志(Translog)中。Translog是一个位于磁盘上的追加日志,它记录了所有对索引的更改,以确保在发生故障时能够恢复数据。
- 当内存缓冲区达到一定大小,或者Translog达到一定大小时。Flush操作会将内存缓冲区中的数据以及Translog中的更改持久化到磁盘上的Lucene索引文件的Segment中,并且会清空旧的Translog。
number_of_primary_shards:索引的主分片数量。
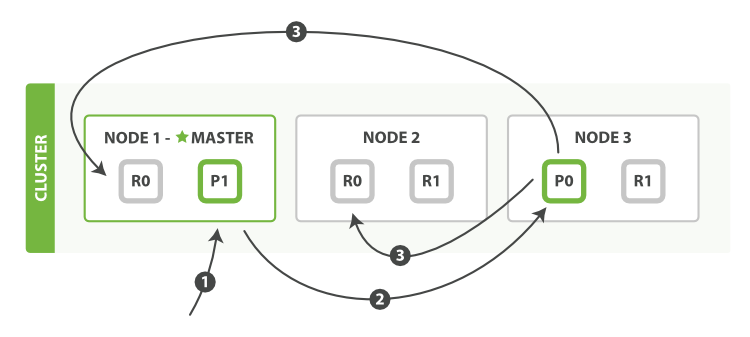
更新和删除文档的过程
- 客户端向任意节点发送更新、删除请求,协调节点并根据文档ID确定要更新的分片(Shard),将请求转发到分片的主节点上。
- 主分片会创建一个新的文档,保留相同的文档ID和一个更高的版本号。同时在段对应的.del文件中记录旧版本的文档。(更新文档)
- 在段对应的.del文件中记录旧版本的文档。(删除文档)
- 修改操作不仅保存在内存缓冲区中,同时也被记录到事务日志(Translog)中。Translog是一个位于磁盘上的追加日志,它记录了所有对索引的更改,以确保在发生故障时能够恢复数据。
- 当内存缓冲区达到一定大小,或者Translog达到一定大小时。Flush操作会将内存缓冲区中的数据以及Translog中的更改持久化到磁盘上的Lucene索引文件的Segment中,并且会清空旧的Translog。
- 废弃的文档由后台线程在段合并阶段进行删除,释放磁盘空间。
Translog刷盘(Flush)时机
Translog的刷盘:是指将Translog内存中的数据写入到Translog日志中(磁盘)。
Translog的刷盘方式有两种:同步(request)和异步(async),index.translog.durability为request表示同步(默认同步),为async表示异步。
同步方式:意味着每次写操作之后会立即将 Translog 刷新到磁盘。
异步方式:可以通过index.translog.sync_interval(默认5s),当达到配置值时触发刷盘。
Lucene中的段(Segment)
Segment是物理日志,而TransLog是逻辑日志,在Lucene中,每当有新的文档被添加时,数据首先写入内存缓冲区(buffer)。当缓冲区达到一定大小或满足特定条件时,数据会被刷新到磁盘,形成一个新的段。这个初始段的大小依赖于缓冲区的大小和写入的文档数量。多个索引的修改都会被分开写入多个段中。
Lucene中的段生成
只有生成Luence段之后,才能被搜索到。
refresh操作:index.refresh_interval(默认1s),可以适当调大例如30s。定时将内存缓冲区数据写入到新的Lucene段文件中,不会清空translog。
flush操作:当translog大小达到index.translog.flush_threshold_size(默认512m),会将translog中的数据写入到磁盘上的 Lucene 段文件中,并创建一个新的 translog 文件,并清空旧的translog。
Lucene中的段合并
段合并的好处
- 提高查询效率:多个小段可能导致查询时需要访问多个索引文件,使查询效率降低。合并段可以减少段的数量,从而减少查询过程中需要读取的文件,提高查询速度。
- 释放磁盘空间:删除文档不会立即从段中移除,而是标记为已删除。通过段合并,可以彻底清除这些标记为删除的文档,释放磁盘空间。
段合并策略
TieredMergePolicy(分层合并策略)
默认段合并策略,根据段的大小和数量将段分为不同的层级(Tiers),并在合适的时机触发段合并。
通过设置segments_per_tier参数控制每层的最大段数,每层段数超过时触发合并。通过设置max_merge_at_once参数控制一次合并的最大段数。
通过段的大小对段进行分层。具体来说,它会将段按照大小分为不同的层,每一层中的段大小范围不同。层的划分并不是固定的,而是动态调整的。
LogByteSizeMergePolicy(基于字节大小的合并策略)
基于段的字节大小来决定合并。它会尝试将小段合并成较大的段,以控制合并后的段大小。
通过设置min_merge_size参数控制段合并操作的最小段大小(小于min_merge_size优先合并)。max_merge_size参数控制段合并操作的最大段大小,当段的大小超过这个阈值时,不再参与合并。
LogDocMergePolicy(基于文档数量的合并策略)
基于段中的文档数量来决定合并。它会尝试将包含少量文档的段合并成包含更多文档的段。
通过设置min_merge_docs参数控制段合并操作的最小段的文档数量(小于min_merge_docs优先合并)。和max_merge_docs参数控制段合并操作的最大段的文档数量,当段的文档数量超过这个阈值时,不再参与合并。
感谢您的阅读!如果文章中有任何问题或不足之处,欢迎及时指出,您的反馈将帮助我不断改进与完善。期待与您共同探讨技术,共同进步!