DRF的使用
1. DRF概述
DRF即django rest framework,是一个基于Django的Web API框架,专门用于构建RESTful API接口。DRF的核心特点包括:
- 序列化:通过序列化工具,
DRF能够轻松地将Django模型转换为JSON格式,也可以将JSON格式的数据反序列化为Python对象。 - 认证与权限管理:
DRF提供了多种认证方式,如Token认证、OAuth等以及权限控制,确保API的访问是安全的。 - 视图与路由优化:
DRF简化了基于类的视图,允许快速构建RESTful API端点,减少重复代码。ViewSet是它的一大特色,使得定义和处理API端点变得更加清晰。并且可以结合Router自动生成URL路由,简化API端点配置。 - 分页与过滤:支持分页、搜索和过滤功能,可以轻松地管理大规模的数据集。
- 强大的文档生成:
DRF可以与Swagger等工具集成,自动生成API文档,帮助前端开发者和其他开发人员理解API接口。
总体来说,DRF让Django项目中的API开发更加高效、灵活、且可维护,非常适合构建前后端分离的项目。推荐使用Django 4.2 + DRF 3.15.2进行新项目的开发。包管理工具推荐使用pip,如果涉及机器学习、数据分析等才使用conda,不建议两种混用。原因如下:
- 🐍 官方标准包管理器:
Django官方文档、教程都基于pip。 - 📦 丰富的第三方库:绝大多数
Django插件、中间件都通过PyPI发布。 - ⚙️ 轻量灵活:适合现代开发流程,如结合
poetry、pipenv使用。 - 🚀 部署友好:与
requirements.txt配合良好,便于CI/CD和容器化部署。
要在现有的Django 项目中集成DRF,需要安装 djangorestframework 包,如下:
pip install django==4.2 djangorestframework==3.15.2
安装之后在settings.py中注册rest_framework,如下:
INSTALLED_APPS = [# 其他Django应用'rest_framework',
]
如果想要修改drf的配置文件,只需要在settings.py中添加配置项REST_FRAMeWORK,如下:
REST_FRAMEWORK = {# 关闭未认证用户的默认行为, 如自定义了身份认证机制[JWT、Token、Oauth2]"UNAUTHENTICATED_USER": None
}
2. 用户模型
Django的用户模型是用户认证系统的核心部分,用于表示网站的用户,包括用户名、密码、邮箱、权限等信息。Django默认的用户模型是django.contrib.auth.models.User模型,它继承自django.contrib.auth.models.AbstractUser,代码如下:
class User(AbstractUser):class Meta(AbstractUser.Meta):# 标识这个模型是可以被交换的, 允许开发者通过AUTH_USER_MODEL指定一个自定义用户模型来替代默认的User模型swappable = "AUTH_USER_MODEL"
2.1 AbstractUser
AbstractUser继承自django.contrib.auth.base_user.AbstractBaseUser,有以下默认字段:该用户模型适合功能不复杂的后台管理系统,且无需扩展用户字段的项目。
| 字段名称 | 类型 | 描述 | 默认值/约束条件 |
|---|---|---|---|
| username | CharField | 唯一用户名,用于登录系统,允许字母、数字和特定符号 | max_length=150,必填且唯一 |
| password | CharField | 加密存储的密码,使用 PBKDF2 或 Argon2 算法 | max_length=128,必填 |
EmailField | 用户邮箱地址,非必填项 | 可选,默认空字符串 | |
| first_name | CharField | 用户名字段,用于存储用户的名 | max_length=150,可选 |
| last_name | CharField | 用户姓氏字段,用于存储用户的姓 | max_length=150,可选 |
| is_staff | BooleanField | 标识用户是否有权限访问 Django Admin 后台 | 默认False |
| is_active | BooleanField | 标识用户账号是否激活 | 默认True |
| is_superuser | BooleanField | 超级管理员标识,拥有所有权限 | 默认False |
| date_joined | DateTimeField | 用户注册时间 | 默认当前时间 【timezone.now】 |
| last_login | DateTimeField | 用户最后一次登录时间 | 可为空,初始值为None |
2.2 自定义用户模型
由于AbstractUser的局限性,我们可以自定义用户模型,只需要继承AbstractUser 【推荐】或 AbstractBaseUser即可,如下:
# apps/users/models.py
from django.contrib.auth.models import AbstractUser
from django.db import modelsclass CustomUser(AbstractUser):# 扩展字段phone = models.CharField(max_length=11, unique=True, null=True, blank=True)nickname = models.CharField(max_length=20, blank=True, null=True)# 覆盖不想要的AbstractUser模型的字段first_name = Nonelast_name = Noneclass Meta:db_table = "custom_user"verbose_name = "用户"verbose_name_plural = "用户"
# 指定用户模型为自定义用户模型
AUTH_USER_MODEL = 'users.CustomUser'
操作用户模型的相关API如下:
from django.contrib.auth import get_user_model# 获取当前项目正在使用的用户模型
User = get_user_model()
# 创建用户
user = User.objects.create_user(username='aaa', email='aaa@qq.com', password='123456')
# 查询用户
user = User.objects.get(email='aaa@qq.com')
# 检查密码
user.check_password('123456')
如果是多用户角色,有以下两种常见做法:
-
单一用户模型 + 角色字段:该方法的局限性在于所有用户数据存储在一张表中,且由于不同角色字段的不同,会导致很多空字段。
class User(AbstractUser):ROLE_CHOICES = (('student', '学生'),('teacher', '教师'),('admin', '管理员'),)role = models.CharField(max_length=10, choices=ROLE_CHOICES)# 公共字段, 如手机号、头像等...# 学生专属字段...# 教师专属字段... -
User+OneToOne角色扩展表【推荐】:一个Django项目只能有一个全局的用户模型,因此多用户角色可以使用角色扩展表实现。该设计将不相同的字段存储在用户表中,将通用字段存储在了主表中。class User(AbstractUser):role = models.CharField(max_length=10, choices=[('student', '学生'), ('teacher', '教师'), ('admin', '管理员')])class Meta:verbose_name = '用户信息'verbose_name_plural = '用户信息'db_table = 'users'class StudentProfile(models.Model):user = models.OneToOneField(User, on_delete=models.CASCADE, related_name='student_profile')student_id = models.CharField(max_length=20)grade = models.CharField(max_length=10)class TeacherProfile(models.Model):user = models.OneToOneField(User, on_delete=models.CASCADE, related_name='teacher_profile')title = models.CharField(max_length=50)department = models.CharField(max_length=100)class AdminProfile(models.Model):user = models.OneToOneField(User, on_delete=models.CASCADE, related_name='admin_profile')admin_code = models.CharField(max_length=50)# 创建超级管理员, 用于登录Django后台, 信息保存在users表中 python manage.py createsuperuser# 创建其它用户角色 class CreateStudentView(APIView):def post(self, request):username = request.data.get('username')password = request.data.get('password')role = request.data.get('role')# 创建学生用户user = User.objects.create_user(username=username, password=password, role=role)StudentProfile.objects.create(user=user, student_id="S123456", grade="2023")return Response({'message': 'ok'})# 将用户模型注册到管理后台中 # users/admin.py # Register your models here. from django.contrib import admin from django.contrib.auth.admin import UserAdmin as BaseUserAdmin from .models import User, StudentProfile, TeacherProfile, AdminProfile@admin.register(User) class UserAdmin(BaseUserAdmin):# 控制页面中要展示的字段list_display = ('username', 'email', 'role', 'is_active', 'is_staff', 'is_superuser')# 添加侧边栏过滤器,快速筛选数据list_filter = ('role', 'is_active', 'is_staff')# 启用后台搜索框,支持模糊查找,允许通过哪些字段查询search_fields = ('username', 'email')# 控制用户编辑页中字段的分组和顺序fieldsets = BaseUserAdmin.fieldsets + (('角色信息', {'fields': ('role',)}),)@admin.register(StudentProfile) class StudentProfileAdmin(admin.ModelAdmin):list_display = ('user', 'student_id', 'grade')search_fields = ('student_id', 'user__username')@admin.register(TeacherProfile) class TeacherProfileAdmin(admin.ModelAdmin):list_display = ('user', 'title', 'department')# 注意双下划线search_fields = ('user__username', 'department')@admin.register(AdminProfile) class AdminProfileAdmin(admin.ModelAdmin):list_display = ('user', 'admin_code')search_fields = ('user__username', 'admin_code')
3. 认证后端
认证后端是Django中处理登录身份验证的核心机制,用来判断账户提供的用户名和密码【或其它凭证】是否合法,并返回合法的用户对象User或None。当调用authenticate方法时会触发认证后端,如下:
from django.contrib.auth import authenticate, loginuser = authenticate(request, username="admin", password="123456")# 返回成功后可以保存session
from django.contrib.auth import login
login(request, user)
# 当然也可以销毁session
logout(request)
Django会遍历AUTHENTICATION_BACKENDS 中配置的每一个认证后端,按顺序执行它们的authenticate方法,直到有一个返回User对象,否则返回None。
Django中默认的认证后端是django.contrib.auth.backends.ModelBackend,它的行为是查找用户username,比对密码password。如果想要实现邮箱登录或其他登录,则需要自定义认证后端:
# apps/users/backends.py
from django.contrib.auth.backends import ModelBackend
from django.contrib.auth import get_user_modelUser = get_user_model()class EmailBackend(ModelBackend):def authenticate(self, request, username=None, password=None, **kwargs):try:user = User.objects.get(email=username) # username 实际是 emailif user.check_password(password):return userexcept User.DoesNotExist:return None
# settings.py
AUTHENTICATION_BACKENDS = ['apps.users.backends.EmailBackend',
]
# 在登录视图中调用
@api_view(['POST'])
def login_view(request):email = request.data.get('email')password = request.data.get('password')# 仍然传入username=emailuser = authenticate(request, username=email, password=password)if user:login(request, user)return Response({'msg': '登录成功'})return Response({'msg': '登录失败'}, status=401)
认证后端与认证组件的区别与联系如下:
| 项目 | 认证后端 | 认证组件 |
|---|---|---|
| 属于 | Django核心 | DRF |
| 什么时候用 | 登录视图中调用authenticate | 每个API请求识别用户 |
| 作用 | 识别账号 + 密码的是否合法 | 识别这个请求是谁发的 |
| 输入 | 用户名/密码或其它凭证 | token、cookie、JWT |
| 举例 | 邮箱登录、自定义账号逻辑 | 自定义 token、cookie、JWT |
| 是否每次请求执行 | ❌ 只在登录时用一次 | ✅ 每个受保护 API 请求都会调用 |
是否与authenticate有关 | 是 | 无关 |
它们的配合流程如下:
[ 用户请求登录 ]↓
[ 调用 authenticate(username=xxx, password=xxx) ]↓
[ 遍历 Authentication Backend → 返回 user ]↓
[ 调用 login(request, user) → 设置 session或token ]=========================[ 之后每个 API 请求 ]↓
[ 调用 Authentication Class → 从 token/session 中识别用户 ]↓
[ 返回 (user, auth) → 自动赋值 request.user ]
✅ 正确理解整个 Token 登录流程:
| 阶段 | 你应该做的事 | 使用什么 |
|---|---|---|
| 登录视图中 | ✅ 调用 authenticate(username=..., password=...) 验证账号密码 | 调用 Django 的认证后端(AUTHENTICATION_BACKENDS) |
| 登录成功后 | ✅ 创建或获取 token | 使用 Token.objects.get_or_create(user=user) |
| 返回给前端 | ✅ 返回 {"token": "xxx"} | 用 JsonResponse / Response 返回即可 |
| 后续请求验证 | ❌ 不用你手动做,DRF 自动用 TokenAuthentication 来解析请求 | 它会从请求头中找 token,并识别用户 |
4. 认证组件
在DRF中,认证组件用于验证用户的身份【你是谁】,判断用户是否登录,确保只有经过授权的用户才能访问特定的API视图。DRF提供了多种认证类,每种认证类都实现了特定的认证逻辑。常见的认证类包括:
BasicAuthentication:基于HTTP基本认证,通过用户名和密码进行认证。SessionAuthentication:基于Django的会话机制进行认证,适用于基于浏览器的交互。TokenAuthentication:基于令牌Token进行认证,适用于前后端分离的应用。JSONWebTokenAuthentication:需要安装djangorestframework-jwt库,基于JSON Web Token即JWT进行认证,是一种无状态的认证方式。Custom Authentication:自定义认证类,有时内置的认证类无法满足特定需求,这时可以自定义认证类。DRF允许我们通过继承BaseAuthentication类来实现自己的认证逻辑。
认证组件必须配合权限组件一起使用,不然认证就没有意义,因为默认权限是AllowAny,表示所有人都可以访问。就好比你进入一栋写字楼,authentication是你出示身份证,确认你是谁?permission是保安根据规则判断你能不能进入大门。如果你只配置了认证,但没有规定保安不让陌生人进,那默认每个人都可以进 —— 所以你访问不需要登录也能成功。
4.1 BasicAuthentication
BasicAuthentication 是一种简单的 HTTP 认证方式,通常用于 REST API 接口,在开发和测试环境中使用频繁,它也是Django中默认的认证组件,需配合isAuthenticated使用。客户端发送请求时,如果没有认证头时则返回401 Unauthorized响应,并且包含www-Authenticate头。当包含认证头时,则会解析认证头,提取用户民和密码,并验证其合法性。BasicAuthentication的优缺点如下:
-
优点:简单易用,兼容性好,不依赖
Cookie和Session,适用于无状态的API服务。适合用于开发和测试环境,但是不能用于生产环境。 -
缺点:安全性低,用户名及密码暴露在认证头中;无会话机制,每次请求都要携带账号密码,效率低且不适合长期登录;不支持登出机制,除非客户端不再发送请求头;用户体验差,需要频繁的输入用户名和密码等。
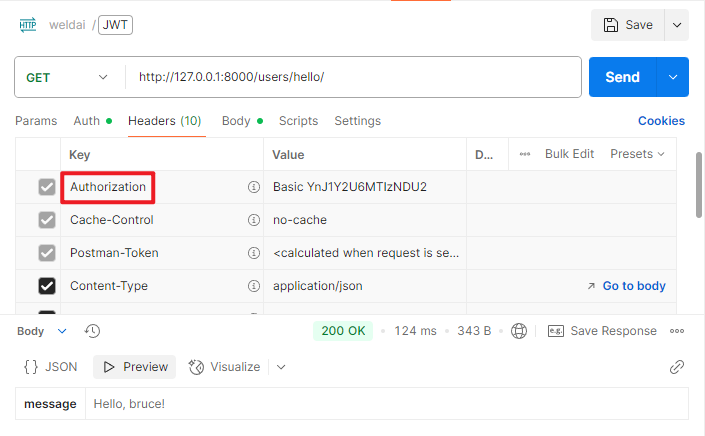
REST_FRAMEWORK = {# 'UNAUTHENTICATED_USERNAME': None'DEFAULT_AUTHENTICATION_CLASSES': ('rest_framework.authentication.BasicAuthentication',),'DEFAULT_PERMISSION_CLASSES': ('rest_framework.permissions.IsAuthenticated',), }class HelloView(APIView):def get(self, request):return Response({"message": f"Hello, {request.user.username}!"})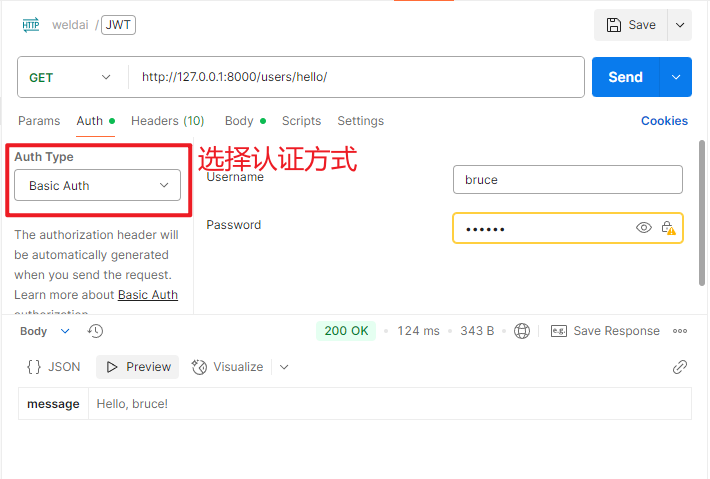
4.2 SessionAuthentication
SessionAuthentication 是基于 Django 自带的会话Session机制的认证方式。它的原理是:
-
用户通过
Django的登录视图登录成功,Django创建一个Session,服务器保存session数据,同时发给客户端一个sessionid。 -
客户端在后续请求中自动携带
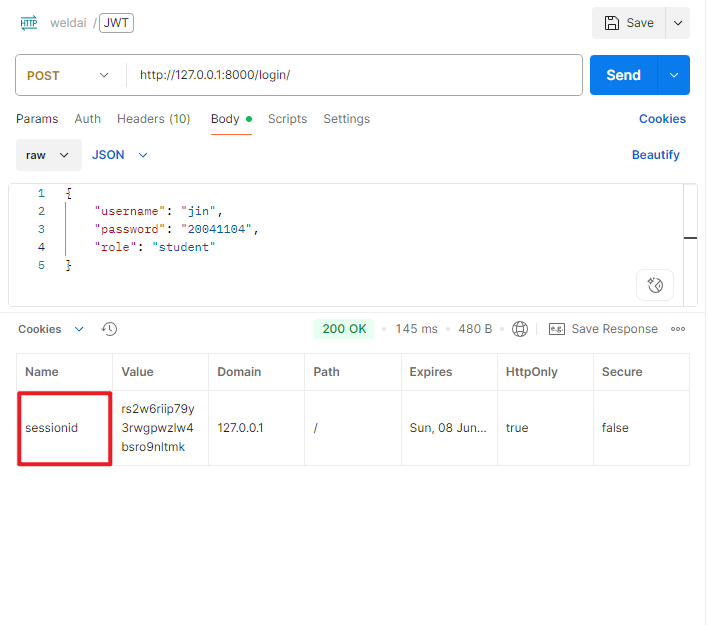
sessionid,DRF的SessionAuthentication会从这个session中获取用户身份。REST_FRAMEWORK = {'DEFAULT_AUTHENTICATION_CLASSES': ['rest_framework.authentication.SessionAuthentication',],'DEFAULT_PERMISSION_CLASSES': ['rest_framework.permissions.IsAuthenticated',], }# 自定义登录视图 def custom_login_view(request):if request.method == "POST":try:data = json.loads(request.body)username = data.get("username")password = data.get("password")except Exception:return JsonResponse({"error": "Invalid input"}, status=400)user = authenticate(request, username=username, password=password)if user:login(request, user) # 使用Django的session loginreturn JsonResponse({"message": "Login success", "username": user.username})else:return JsonResponse({"error": "Invalid credentials"}, status=401)return JsonResponse({"error": "Only POST allowed"}, status=405)登录成功后会返会
Session ID,在浏览器中,后续请求会自动携带Session ID。需要注意的是,SessionAuthentication需要依赖Cookie和CSRF,不适合前后端分离项目,有状态认证机制【需在服务端存储Session】。
SessionAuthentication支持登出,如下:
from django.contrib.auth import logout
from rest_framework.decorators import api_view, permission_classes
from rest_framework.permissions import IsAuthenticated
from rest_framework.response import Response@api_view(['POST'])
@permission_classes([IsAuthenticated])
def logout_view(request):logout(request) # 销毁 sessionreturn Response({'message': 'Logout successful'})
4.3 TokenAuthentication
TokenAuthentication是一种无状态的认证机制,其核心原理是用户登录后,服务端返回一个Token给客户端,客户端之后访问所有接口时都在请求头携带这个Token【Authorization: Token <你的token>】,服务端通过它识别用户身份,返回给前端的token也会保存在authen_token数据表中,后续认证也就是查看数据表中是否有携带的token。其使用如下:
INSTALLED_APPS = [...'rest_framework','rest_framework.authtoken',
]# 迁移数据库创建token表
python manage.py migrateREST_FRAMEWORK = {'DEFAULT_AUTHENTICATION_CLASSES': ['rest_framework.authentication.TokenAuthentication',],'DEFAULT_PERMISSION_CLASSES': ['rest_framework.permissions.IsAuthenticated',]
}
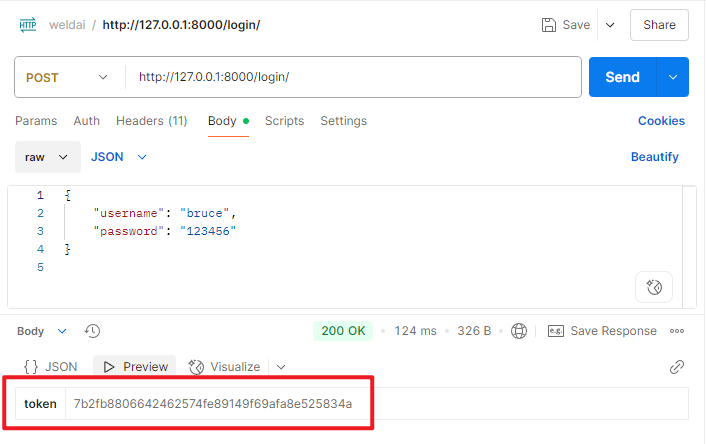
from rest_framework.authtoken.views import obtain_auth_tokenurlpatterns = [# 内置的登录视图只支持 username + password# 通过认证后端的用户会返回一个tokenpath('login/', obtain_auth_token),
]
值得注意的是,使用Djano的TokenAuthentication只接受如下的Header,这也就意味着在postman中只能手动添加请求头:并且浏览器是不会自动携带Token的。
Authorization: Bearer <token值>
Django的TokenAuthentication虽然使用很方便,但是有着很多局限性和缺点,因为生产环境中并不推荐使用TokenAuthentication。
-
Token永不过期:一旦泄露,别人可永久使用,除非手动删除。 -
不支持刷新:无法像
JWT刷新token,有效期无法动态延长。 -
不支持多端登录:默认用户只有一个
token,不能区分Web、手机或其他设备。 -
安全性低:
Token是明文存储在数据库中的,盗用风险高,依赖HTTPS保证安全。 -
无签名校验:服务端要查数据库,效率低且无法校验
token真伪。 -
不支持登出:没有标准的注销机制,只能手动删除
token或换一个。 -
不易扩展:不支持加自定义字段、角色、权限等高级内容。
4.4 JSONWebTokenAuthentication
JSONWebTokenAuthentication即JWT认证,是一种无状态的、签名验证的令牌认证机制,服务端签发token后,不再保存用户登录状态,客户端每次请求时携带token,服务端验证签名即可。在前后端分离、移动端或小程序场景中,JWT 是非常主流的认证方式。
pip install djangorestframework-simplejwt
INSTALLED_APPS = [...'rest_framework','rest_framework_simplejwt',
]REST_FRAMEWORK = {'DEFAULT_AUTHENTICATION_CLASSES': ('rest_framework_simplejwt.authentication.JWTAuthentication',),'DEFAULT_PERMISSION_CLASSES': ['rest_framework.permissions.IsAuthenticated',]
}from datetime import timedeltaSIMPLE_JWT = {'ACCESS_TOKEN_LIFETIME': timedelta(minutes=5),'REFRESH_TOKEN_LIFETIME': timedelta(days=1),# 每次刷新AccessToken时是否刷新RefreshToken'ROTATE_REFRESH_TOKENS': True,# 是否将旧Token加入黑名单,配合ROTATE_REFRESH_TOKENS=True使用'BLACKLIST_AFTER_ROTATION': True,# 自定义盐, 默认使用django的盐'SIGNING_KEY': 'my-very-secret-salt-used-to-sign-tokens-123456',
}
from django.urls import path
from rest_framework_simplejwt.views import (TokenObtainPairView, # 登录TokenRefreshView, # 刷新 tokenTokenVerifyView # 校验 token 是否有效
)urlpatterns = [# 通过认证后端时才返回tokenpath('api/token/', TokenObtainPairView.as_view(), name='token_obtain_pair'), # 登录path('api/token/refresh/', TokenRefreshView.as_view(), name='token_refresh'), # 刷新path('api/token/verify/', TokenVerifyView.as_view(), name='token_verify'), # 验证
]
4.5 Custom Authentication
首先是需要清楚为什么需要自定义认证组件,对于上述的四种认证组件,如果对它们的默认行为不满意,比如token在请求体中、实现多端控制登录、支持企业微信、微信小程序登录等等,这时就需要使用自定义认证组件才能完成需求。
对于自定义的认证类,需要继承BaseAuthentication 类并重写authenticate方法,其中authenticate方法在认证成功时必须有返回值,其返回值为(requset.user, request.auth):
user:表示经过认证的用户对象,通常是User模型的实例,或者其他表示用户身份的对象。auth:表示与认证相关的附加信息,通常是None,除非你需要传递其他信息,如Token、API Key等认证数据。
对于BaseAuthentication,有以下两个方法:
-
authenticate:执行具体的认证逻辑,验证请求的合法性。若认证成功则返回(user, auth),返回None则表示允许其它认证类继续尝试,抛出异常则明确表示认证失败,终止后续认证流程。 -
authenticate_header:用于在认证失败时,为客户端返回一个WWW - Authenticate响应头,响应状态码为401,用于指导客户端如何重新认证。如果不重写此方法,认证失败时默认返回**403 Forbidden** 而非401 Unauthorized,可能导致前端无法正确处理认证流程。from rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailedclass MyCustomAuthentication(BaseAuthentication):def authenticate(self, request):# 模拟认证失败raise AuthenticationFailed('Invalid authentication credentials.')def authenticate_header(self, request):# 返回 WWW - Authenticate 头信息return 'Bearer realm="api"'HTTP/1.1 401 Unauthorized WWW - Authenticate: MyCustomAuth realm="api" Content - Type: application/json {"detail": "Invalid authentication credentials." }
下面是【局部认证】的简单使用,一般使用CBV方式为某些视图指定认证类:
from rest_framework.authentication import BaseAuthentication
from django.contrib.auth import get_user_model
from rest_framework.exceptions import AuthenticationFailedUser = get_user_model()class CustomHeaderTokenAuthentication(BaseAuthentication):def authenticate(self, request):token = request.META.get("HTTP_X_AUTH_TOKEN") # 自定义headerif not token:return None # 返回 None 表示此认证组件不处理该请求try:user = User.objects.get(auth_token=token)except User.DoesNotExist:raise AuthenticationFailed("Invalid token")return (user, token)
REST_FRAMEWORK = {'DEFAULT_AUTHENTICATION_CLASSES': ['yourapp.auth.CustomHeaderTokenAuthentication',]
}
如果不使用【全局认证】,就需要单独给每个视图单独指定认证类,难以管理。下面是全局认证的简单使用:
REST_FRAMEWORK = {"UNAUTHENTICATED_USER": None,"DEFAULT_AUTHENTICATION_CLASSES": ["api.views.MyAuthentication",],
}
如果使用全局认证,认证类就一定不能写在视图文件中了,其原因就是出现了循环引用。如果同时使用了全局认证和局部认证,则使用局部认证,本质上就是一个覆盖的问题。
4.6 DRF中的request
dispatch 方法是视图处理请求的核心调度器,它负责接收请求,进行一系列的初始化、权限检查、异常处理等操作,最后将响应返回给客户端。其源代码如下:
def dispatch(self, request, *args, **kwargs):"""`.dispatch()` is pretty much the same as Django's regular dispatch,but with extra hooks for startup, finalize, and exception handling."""self.args = argsself.kwargs = kwargsrequest = self.initialize_request(request, *args, **kwargs)self.request = requestself.headers = self.default_response_headers # deprecate?try:self.initial(request, *args, **kwargs)# Get the appropriate handler methodif request.method.lower() in self.http_method_names:handler = getattr(self, request.method.lower(),self.http_method_not_allowed)else:handler = self.http_method_not_allowedresponse = handler(request, *args, **kwargs)except Exception as exc:response = self.handle_exception(exc)self.response = self.finalize_response(request, response, *args, **kwargs)return self.response
其中request = self.initialize_request(request, *args, **kwargs)是对原始的Django请求对象进行封装,将其转换为 DRF 的Request对象,该对象包含了更多与RESTful API相关的属性和方法,例如请求的认证信息、解析后的请求数据等。drf中的request是对原始请求对象的封装,下面是几个常用的扩展方法:
request.query_params:用于获取URL中的查询参数,等同于Django原生HttpRequest对象的request.GET。request.user:用于获取经过认证的用户对象。如果请求经过了认证,request.user将是一个有效的用户实例,如果未认证,默认是AnonymousUser。request.auth:用于获取认证后得到的认证信息,例如令牌Token。具体的值取决于使用的认证类。request.is_authenticated:检查请求是否经过了认证。
4.7 多个认证类
在DRF中,多个认证类的队列是非常重要的。DRF会按照在 settings.py 中配置的顺序依次尝试每个认证类,直到某个认证类成功认证为止,或者所有认证类都失败为止。每个认证类的 authenticate 方法会返回不同的结果,DRF 会根据这些结果进行相应处理:
- 认证成功:如果某个认证类的
authenticate方法返回一个包含用户对象和认证信息的元组(user, auth),则认为认证成功。此时,DRF会停止继续尝试后续的认证类,并将认证成功的用户对象和认证信息存储在request.user和request.auth中,供后续的权限检查和视图处理使用。 - 无法认证:如果某个认证类的
authenticate方法返回None,表示该认证类无法对当前请求进行认证。DRF会忽略这个结果,并继续尝试下一个认证类。 - 认证失败:如果某个认证类的
authenticate方法抛出AuthenticationFailed异常,则表示认证失败。DRF会立即停止认证过程,并将该异常传递给异常处理机制,最终返回一个包含错误信息的响应给客户端,通常状态码为401未授权。
如果所有配置的认证类的 authenticate 方法最终都返回 None,即没有任何一个认证类能够成功认证请求,这时候就会涉及到是否认证失败的判断,而这取决于权限类的配置:
-
权限类允许未认证访问:若权限类允许未认证的用户访问视图,例如使用
AllowAny权限类,即使所有认证类都返回None,请求也不会被判定为认证失败,而是可以正常访问视图。示例代码如下:from rest_framework.views import APIView from rest_framework.permissions import AllowAny from rest_framework.response import Responseclass MyView(APIView):authentication_classes = [MyAuthentication, MyAuthentication2]permission_classes = [AllowAny]def get(self, request):return Response({'message': 'This view allows unauthenticated access.'}) -
权限类要求认证:如果权限类要求用户必须经过认证才能访问视图,例如使用
IsAuthenticated权限类,当所有认证类都返回None时,就会被判定为认证失败。DRF会抛出AuthenticationFailed异常,并返回一个状态码为401的错误响应给客户端。示例代码如下:from rest_framework.views import APIView from rest_framework.permissions import IsAuthenticated from rest_framework.response import Responseclass MyProtectedView(APIView):authentication_classes = [MyAuthentication, MyAuthentication2]permission_classes = [IsAuthenticated]def get(self, request):return Response({'message': 'This is a protected view.'})
总而言之,当返回(user, auth)时表示认证成功,如果所有认证类均返回None则表示认证未通过但不是认证失败,将返回匿名用户(AnonymousUser, None),如果不想匿名用户的user为Anonymous,可以通过设置'UNAUTHENTICATED_USER': None。当用户端提供了无效的凭证,在认证组件中会明确的判断为认证失败即抛出AuthenticationFailed异常,DRF 会立即停止遍历其他认证组件。
5. 权限组件
在DRF中,权限组件用于控制对API视图的访问,确保只有满足特定条件的用户才能访问相应的资源。DRF提供了多个内置的权限类,如下:
AllowAny:允许任何用户访问,不管用户是否经过认证。使用该组件时不需要配置认证组件。IsAuthenticated:只允许经过认证的用户访问。IsAdminUser:只允许管理员用户,即is_staff为True的用户访问。IsAuthenticatedOrReadOnly:允许经过认证的用户进行任何操作,对于未认证的用户只允许进行只读操作,如GET请求。- 自定义权限组件:如果内置的权限类无法满足业务需求,你可以自定义权限类。自定义权限类需要继承
BasePermission类,并实现has_permission或has_object_permission方法。
对于权限组件,其配置方式和认证组件的配置方式一致。权限组件有以下注意点:
-
权限类的顺序:当配置多个权限类时,
DRF会按照它们在列表中的顺序依次检查权限。如果前面的权限类检查不通过,后面的权限类将不再检查。因此,需要合理安排权限类的顺序,通常将最宽松的权限类放在前面,最严格的放在后面。 -
与认证组件协同工作:权限组件依赖于认证组件,只有在认证成功后才能进行权限检查。因此,需要确保在使用权限组件之前已经正确配置了认证组件。如果认证失败,权限检查将无法正常进行。
-
异常处理:当权限检查不通过时,
DRF会抛出PermissionDenied异常,并返回一个状态码为403禁止访问的响应。可以通过自定义异常处理函数来改变默认的错误响应,以满足特定的业务需求。from rest_framework.views import exception_handler from rest_framework.response import Responsedef custom_exception_handler(exc, context):response = exception_handler(exc, context)if response is not None and isinstance(exc, rest_framework.exceptions.PermissionDenied):response.data = {'error': 'You do not have permission to access this resource.'}return responseREST_FRAMEWORK = {'EXCEPTION_HANDLER': 'your_app.utils.custom_exception_handler' }
对于自定义的权限组件,BasePermission中的has_permission和has_object_permission默认返回True,表示权限通过,反之不通过。这两个方法有以下区别:
-
has_permission:决定是否允许整个视图类的访问。- 调用时机:在调用视图的
get()、post()方法之前执行。它主要针对视图级别的权限控制,不涉及具体的对象实例。例如,当客户端发起一个请求访问某个视图时,DRF会首先调用视图所配置的权限类的has_permission方法来决定是否允许该用户继续访问这个视图。 - 应用场景:适用于对整个视图的访问进行权限控制,比如限制只有认证用户才能访问某个视图,或者只有特定角色的用户才能访问某个视图集。例如一个博客系统的文章列表视图,可能只允许已登录用户访问,就可以在
has_permission方法中进行判断。
- 调用时机:在调用视图的
-
has_object_permission:针对单个对象如详情页、更新或删除操作的权限验证。-
调用时机:该方法在视图处理涉及具体对象的操作时被调用,前提是
has_permission方法已经返回True,即用户已经通过了视图级别的权限检查。has_object_permission用于判断用户是否有权限对特定的对象实例进行操作,如对某个数据库记录进行更新或删除。 -
应用场景:适用于对具体对象的操作进行权限控制,例如只有文章的作者才能对文章进行修改或删除操作。在这种情况下,需要根据具体的文章对象来判断用户是否有权限进行操作,就可以使用
has_object_permission方法。class BasePermission(metaclass=BasePermissionMetaclass):"""A base class from which all permission classes should inherit."""# 权限拒绝时的提示信息message = {"code": 1001, "msg": "无权访问"}def has_permission(self, request, view):"""Return `True` if permission is granted, `False` otherwise."""return Truedef has_object_permission(self, request, view, obj):"""Return `True` if permission is granted, `False` otherwise."""return True
-
上述两个方法中有两个参数,view和obj,它们都是由django自动传入到你的权限类方法中的,使用如下:
-
view:当前请求的视图实例,可以访问视图的queryset、serializer_class、action,以及视图类中的自定义属性。def has_permission(self, request, view):# 若视图类中定义了scope属性if view.scope == 'admin':return request.user.is_staffreturn True -
obj:表示当前操作的具体对象的模型。def has_object_permission(self, request, view, obj):# 允许读操作,写操作需验证所有者if request.method in permissions.SAFE_METHODS:return Truereturn obj.owner == request.user
5.1 单个权限类
from rest_framework import permissionsclass IsAuthorOrAdminOrReadOnly(permissions.BasePermission):"""允许任何人进行只读操作只允许文章作者或管理员进行写操作"""def has_permission(self, request, view):"""负责视图级别的权限检查"""# SAFE_METHODS = ('GET', 'HEAD', 'OPTIONS')if request.method in permissions.SAFE_METHODS:return True# 如果是写操作如POST则要求用户必须登录return request.user and request.user.is_authenticateddef has_object_permission(self, request, view, obj):"""负责对象级别的权限检查"""if request.method in permissions.SAFE_METHODS:return True# 如果是写操作如PUT、PATCH、DELETE则检查当前用户是否是该文章的作者或者是否是管理员return obj.author == request.user or request.user.is_staff
from rest_framework import viewsets
from .models import Post
from .serializers import PostSerializer
from .permissions import IsAuthorOrAdminOrReadOnly # 导入自定义权限类class PostViewSet(viewsets.ModelViewSet):queryset = Post.objects.all()serializer_class = PostSerializer# 在这里应用我们的权限类authentication_classes = [SessionAuthentication, TokenAuthentication]permission_classes = [IsAuthorOrAdminOrReadOnly]def perform_create(self, serializer):# 在创建文章时,自动将作者设置为当前登录用户serializer.save(author=self.request.user)
5.2 多个权限类
使用方式与单个权限类一致,需要注意的是当某个权限类未通过,之后的权限类将不再执行。但是在实际开发中,有时并不需要所有权限类都通过才能访问对应的资源,符合某一个条件就可以访问该资源。为了实现这一需求,可以使用如下:
from rest_framework.permissions import IsAuthenticated, IsAdminUser
from rest_framework.combinators import Or# 满足任一权限即可
permission_classes = [Or(IsAuthenticated, IsAdminUser)]
6. 限流组件
在DRF 中,限流是一个非常有用的功能,能够限制某个用户在一定时间内能发送多少次请求。限流通常用于防止恶意攻击、避免服务过载、保护 API 资源,或者简单地控制流量。限流通常是通过对请求进行计数,并且每个用户或 IP 在一定时间内只能发起有限次数的请求来实现的,例如每个用户每分钟最多能发起100个请求。DRF提供了几种常用的限流类,我们可以在 全局配置或 视图级别设置限流。
-
AnonRateThrottle:AnonRateThrottle用于限制未认证的用户的请求次数。 -
UserRateThrottle:UserRateThrottle用于限制已认证的用户的请求次数。# settings.pyREST_FRAMEWORK = {# 限流类'DEFAULT_THROTTLE_CLASSES': ['rest_framework.throttling.UserRateThrottle', # 针对认证用户的限流'rest_framework.throttling.AnonRateThrottle', # 针对匿名用户的限流],# 限流速率'DEFAULT_THROTTLE_RATES': {'user': '100/hour', # 认证用户每小时最多 100 次请求'anon': '10/minute', # 匿名用户每分钟最多 10 次请求}, } -
ScopedRateThrottle:针对不同视图或端点的限流。ScopedRateThrottle可以为不同的视图或视图集设置不同的限流策略。class ContactListView(APIView):throttle_scope = 'contacts' # 关联限流作用域...# settings.py 配置 REST_FRAMEWORK = {'DEFAULT_THROTTLE_RATES': {'contacts': '50/day'} } -
CustomThrottle:如果内置的限流类不满足需求,DRF允许自定义限流类。你可以继承BaseThrottle类来实现自定义的限流逻辑。对于BaseThrottle类,里面限流的逻辑都需要自己实现,较为麻烦。这时可以用到BaseThrottle类的子类SimpleRateThrottle。from rest_framework.throttling import SimpleRateThrottle from django.core.cache import cache as default_cacheclass MyThrottle(SimpleRateThrottle):scope = 'user'# 配置节流THROTTLE_RATES = {scope: '3/m'}cache = default_cachedef get_cache_key(self, request, view):if request.user:ident = request.user.pkelse:# 获取用户的IP地址ident = self.get_ident(request)return self.cache_format % {'scope': self.scope,'ident': ident}
DRF 限流依赖 Django 缓存系统,默认使用 LocMemCache,若需使用其他缓存如 Redis,需在 settings.py 中配置。
# settings.py
CACHES = {"default": { # 限流默认使用此配置"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379/0", # 使用 Redis 数据库 0},"rate_limit_cache": { # 其他缓存配置"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379/1", # 使用 Redis 数据库 1}
}
from rest_framework.throttling import SimpleRateThrottle
from django.core.cache import caches # 导入多缓存管理器class CustomRedisThrottle(SimpleRateThrottle):scope = "custom" # 限流作用域cache = caches["rate_limit_cache"]rate = "100/day" # 限流频率def get_cache_key(self, request, view):# 自定义逻辑生成唯一标识(如用户 ID 或 IP)return f"custom_{request.user.id if request.user else self.get_ident(request)}"
7. 版本控制
在 DRF里,版本控制是一项重要的功能,它允许你在同一个 API 端点上提供不同版本的服务,以满足不同客户端的需求,同时确保系统的兼容性和可维护性。版本控制的作用就是随着业务的发展,API 可能会发生变化。通过版本控制,旧版本的客户端可以继续使用旧版本的 API,而新版本的客户端可以使用新功能。DRF 提供了多种版本控制的实现方式,下面分别介绍:
-
基于查询参数
QueryParameterVersion:通过在URL的查询参数中指定版本号,例如http://example.com/api/resource/?version=v1。from rest_framework.versioning import QueryParameterVersioning class OrderView(APIView):authentication_classes = []versioning_class = QueryParameterVersioningdef get(self, request):print(request.version)return Response('订单列表')# 控制版本的名称 REST_FRAMEWORK = {'DEFAULT_VERSION': 'v1','ALLOWED_VERSIONS': ['v1', 'v2'],'VERSION_PARAM': 'version' } -
基于
URL的版本控制URLPathVersioning:在URL路径中包含版本号,例如http://example.com/api/v1/resource/。REST_FRAMEWORK = {'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning' }from django.urls import path from rest_framework.views import APIView from rest_framework.response import Responseclass MyView(APIView):def get(self, request, version):return Response({'version': version})urlpatterns = [path('api/<str:version>/resource/', MyView.as_view()), ] -
基于请求头
AcceptHeaderVersioning:在请求头的Accept字段中指定版本号,例如Accept: application/json; version=v1。REST_FRAMEWORK = {'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.AcceptHeaderVersioning' }from rest_framework.views import APIView from rest_framework.response import Responseclass MyView(APIView):def get(self, request):version = request.versionreturn Response({'version': version})
在 DRF的版本控制机制里,version 和 versioning_scheme 是两个关键的概念,下面为你详细介绍它们的含义以及 versioning_scheme 的使用方法。
-
version:当前请求所使用的API版本号。在处理请求时,DRF会根据所配置的版本控制方案从请求中提取版本信息,并将其存储在request.version属性中,方便在视图里获取和使用该版本号,从而依据不同的版本返回不同的响应。class UserView(APIView):def get(self, request):if request.version == 'v1':return Response({"name": "Alice"})elif request.version == 'v2':return Response({"name": "Alice", "email": "alice@example.com"}) -
versioning_scheme:负责实现版本解析逻辑和反向生成URL,反向生成url如下:class OrderView(APIView):authentication_classes = []versioning_class = QueryParameterVersioningdef get(self, request):url = request.versioning_scheme.reverse('order-list', request=request)print(url)
8. 解析器
在DRF中,解析器Parsers用于将传入的请求数据解析为 Python 对象,以便在视图中进行处理。DRF 提供了多种内置的解析器,其中下面的前三章解析器是drf默认的解析器:解析器仅用于格式转换,不执行任何数据验证。
-
JSONParser:用于解析JSON格式的数据。这是最常用的解析器之一,适用于处理以JSON格式发送的API请求,例如前端通过AJAX发送JSON数据到后端。 -
FormParser:用于解析表单数据,通常用于处理application/x-www-form-urlencoded格式的数据,这种格式是传统的HTML表单提交数据的方式。 -
MultiPartParser:用于处理多部分表单数据,特别是包含文件上传的情况,格式为multipart/form-data。当用户通过表单上传文件时,就需要使用这个解析器。 -
自定义解析器:如果内置的解析器无法满足项目需求,还可以自定义解析器。自定义解析器需要继承
BaseParser类,并实现parse方法。开发中使用默认的解析器足够使用。# 全局配置 REST_FRAMEWORK = {'DEFAULT_PARSER_CLASSES': ['rest_framework.parsers.JSONParser', # 解析 JSON 数据'rest_framework.parsers.FormParser', # 解析表单数据x-www-form-urlencoded'rest_framework.parsers.MultiPartParser' # 解析文件上传multipart/form-data] }from rest_framework.versioning import QueryParameterVersioning class OrderView(APIView):parser_classes = [JSONParser, FormParser]def get(self, request):# 访问解析后的数据print(request.data)
9. 序列化器
在DRF中,序列化Serialization是一个非常重要的概念,它主要用于将复杂的数据类型如 Django 模型实例、查询集转换为Python原生数据类型,以便可以轻松地将其渲染为 JSON、XML 等格式的响应数据。同时,也能将传入的原始数据反序列化为 Django 模型实例或其他复杂数据类型,方便进行数据验证和保存到数据库。
如果没有序列化器,通过model.Depart.objects.all().first()获得的模型实例是一个复杂的python对象,又或是model.Depart.objects.all()返回的一个QuerySet对象,是不能直接通过Response转换为JSON格式的,应该将其转换为python中的原生对象再传入Response,这时就需要用到序列化器。
对于创建序列化器实例时的参数问题,如下:
- 序列化:传入
instance参数,如ArticleSerializer(instance=article),通常发生在Get请求中。 - 反序列化:传入
data参数,如ArticleSerializer(data=article),通常发生在Post、Put、Patch请求中。通常会涉及serializer.save()方法的使用,用于修改或保存数据,对于参数方面也有以下两种使用方式:serializer = MySerializer(data=request.data):用于创建,会触发create方法。serializer = MySerializer(instance=obj, data=request.data):用于更新,会触发update方法。
9.1 Serializer
Serializer:这是最基础的序列化器,需要手动定义每个字段。适用于需要自定义序列化和反序列化逻辑的复杂场景,如当你的数据源不涉及 Django 模型、需要高度定制序列化行为即默认行为create、update不满足需求时才使用。
# reports/serializers.py
from rest_framework import serializers
from datetime import datetime, timedeltaclass EventSerializer(serializers.Serializer):# 字段定义-----------------------------------------------------------------------------------------------# 不涉及django模型时,序列化器字段必须与处理的数据字典的键名一致才能正确获取到值,因为Serializer不具有自动推断的功能-----------------------------------------------------------------------------------------------event_id = serializers.UUIDField(format='hex_verbose', read_only=True) # UUID格式event_type = serializers.CharField(max_length=50)source_system = serializers.CharField(max_length=100, required=False, allow_blank=True, default="UNKNOWN")payload = serializers.JSONField() # 任意JSON数据timestamp = serializers.DateTimeField(read_only=True) # 表示处理时间# --- 字段级别验证示例 ---def validate_event_type(self, value):"""验证事件类型是否为预定义类型之一"""allowed_types = ['login', 'logout', 'purchase', 'error', 'page_view']if value.lower() not in allowed_types:raise serializers.ValidationError(f"无效的事件类型 允许的类型是: {', '.join(allowed_types)}")return value# --- 对象级别验证示例 ---def validate(self, data):"""验证特定事件类型下的数据规则。例如,如果是 'purchase' 事件,payload 必须包含 'amount' 字段。"""if data['event_type'].lower() == 'purchase':if 'amount' not in data['payload'] or not isinstance(data['payload']['amount'], (int, float)):raise serializers.ValidationError({"payload": "Purchase事件的payload必须包含有效的'amount'字段"})if data['payload']['amount'] <= 0:raise serializers.ValidationError({"payload": "Purchase事件的'amount'必须大于零"})return data# --- create 方法示例 反序列化时使用 ---def create(self, validated_data):# 模拟生成一个事件IDvalidated_data['event_id'] = f"evt-{datetime.now().timestamp()}"validated_data['timestamp'] = datetime.now()# 模拟将事件数据发送到日志系统或消息队列print(f"--- 接收到并处理了新事件 ---")print(f" Event Type: {validated_data['event_type']}")print(f" Source: {validated_data['source_system']}")print(f" Payload: {validated_data['payload']}")print(f" Processed At: {validated_data['timestamp']}")print(f"---------------------------\n")# 返回处理后的数据,通常包含新生成的ID和时间戳return validated_data# --- update 方法示例 反序列化时使用 ---def update(self, instance, validated_data):"""对于像事件日志这样的数据,通常是只创建不更新所以这里不实现 update 方法,或者直接抛出 NotImplementedError如果需要更新,例如更新一个临时事件的状态,你可以修改这里"""# 简单模拟更新 instance 的部分字段instance['event_type'] = validated_data.get('event_type', instance['event_type'])instance['source_system'] = validated_data.get('source_system', instance['source_system'])instance['payload'] = validated_data.get('payload', instance['payload'])instance['timestamp'] = datetime.now() # 更新时间戳print(f"--- 更新了事件 ---")print(f" Event ID: {instance.get('event_id', 'N/A')}")print(f" New Type: {instance['event_type']}")print(f" Updated At: {instance['timestamp']}")print(f"-------------------\n")return instancefrom rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from rest_framework.permissions import AllowAny
from .serializers import EventSerializer# 模拟一些内存中的事件数据 (实际应用中可能从数据库、缓存、文件等获取)
_mock_events_data = [{"event_id": uuid.UUID("a1b2c3d4-e5f6-7890-1234-567890abcdef"),"event_type": "login","source_system": "web_app","payload": {"user_id": 101, "ip_address": "192.168.1.1"},"timestamp": datetime.now() - timedelta(hours=2)},{"event_id": uuid.UUID("f0e9d8c7-b6a5-4321-fedc-ba9876543210"),"event_type": "page_view","source_system": "mobile_app","payload": {"page_url": "/dashboard", "user_id": 102},"timestamp": datetime.now() - timedelta(minutes=30)}
]class EventListAPIView(APIView):permission_classes = [AllowAny]def get(self, request, format=None):"""序列化操作:将Python列表转换为可供API响应的格式"""serializer = EventSerializer(instance=_mock_events_data, many=True)# serializer.data 包含序列化后的 Python 字典或列表print("GET Request - Serialized data:", serializer.data) # 如{'id': 1, 'name': 'Alice', 'age': 30, 'email': 'alice@example.com'}return Response(serializer.data, status=status.HTTP_200_OK)def post(self, request, format=None):"""反序列化操作:接收客户端数据,进行验证,并模拟处理"""# 实例化序列化器,传入客户端发送的数据serializer = EventSerializer(data=request.data)# 调用is_valid()进行数据验证if serializer.is_valid():# serializer.validated_data包含了验证通过并转换后的Python字典print("POST Request - Validated data type:", type(serializer.validated_data))print("POST Request - Validated data:", serializer.validated_data)processed_event = serializer.save()# 将处理后的数据作为响应返回return Response(processed_event, status=status.HTTP_201_CREATED)else:# 如果验证失败,serializer.errors 包含错误信息print("POST Request - Validation Errors:", serializer.errors)return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)class EventDetailAPIView(APIView):permission_classes = [AllowAny]def get_object(self, event_id):# 模拟从 _mock_events_data 中查找一个事件for event in _mock_events_data:print("GET Request - Event ID:", event['event_id'])if event['event_id'] == event_id:return eventraise status.HTTP_404_NOT_FOUNDdef get(self, request, event_id, format=None):print("GET Request - Event IDaaaaa:", event_id)"""单个对象的序列化"""try:event = self.get_object(event_id)except Exception:return Response({"detail": "Event not found."}, status=status.HTTP_404_NOT_FOUND)serializer = EventSerializer(event) # 传入单个Python字典进行序列化return Response(serializer.data, status=status.HTTP_200_OK)def put(self, request, event_id, format=None):"""单个对象的反序列化 更新操作"""try:event = self.get_object(event_id)except Exception:return Response({"detail": "Event not found."}, status=status.HTTP_404_NOT_FOUND)# 实例化序列化器,传入现有实例 event 和新数据request.data# 传入一个instance调用的就是update而不是createserializer = EventSerializer(instance=event, data=request.data, partial=True) # partial=True 允许部分更新if serializer.is_valid():# 调用 serializer.save(), 会触发 EventSerializer的update()方法updated_event = serializer.save()return Response(updated_event, status=status.HTTP_200_OK)return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
# 路由
path('events/', views.EventListAPIView.as_view(), name='event-list'),
path('events/<uuid:event_id>/', views.EventDetailAPIView.as_view(), name='event-detail'), # 使用 UUID 路径转换器
9.2 ModelSerializer
ModelSerializer:基于 Django 模型自动生成序列化器字段,大大减少了代码量,适用于大多数与模型相关的序列化需求。
from django.db import modelsclass Article(models.Model):title = models.CharField(max_length=200)content = models.TextField()author = models.CharField(max_length=100)published_date = models.DateTimeField(auto_now_add=True)def __str__(self):return self.title
from rest_framework import serializers
from .models import Articleclass ArticleSerializer(serializers.ModelSerializer):# 增强和定制模型的序列化行为,而不是覆盖模型本身# 时间输出格式published_date = models.DateTimeField(format="%Y-%m-%d %H:%M")class Meta:model = Article# fields = "__all__"# exclude = ['id', 'title'],用于排除指定字段fields = ['id', 'title', 'content', 'author', 'published_date']
from rest_framework.response import Response
from rest_framework.views import APIView
from .models import Article
from .serializers import ArticleSerializerclass ArticleList(APIView):def get(self, request):# 获取所有文章实例articles = Article.objects.all()# 创建序列化器实例,many=True 表示处理QuertSetserializer = ArticleSerializer(instance=articles, many=True)return Response(serializer.data)
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework import status
from .models import Article
from .serializers import ArticleSerializerclass ArticleCreate(APIView):def post(self, request):# 创建序列化器实例并传入请求数据serializer = ArticleSerializer(data=request.data)# 验证数据if serializer.is_valid():# 保存数据到数据库# 通过序列化器中参数决定调用create还是update方法serializer.save()return Response(serializer.data, status=status.HTTP_201_CREATED)return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
在ModelSerializer和Serializer中都可以自定义字段,并传入一些相关参数:意味着你可以在序列化器中定义一些不直接对应模型字段的额外字段,或者对现有模型字段的表示方式进行修改。MdoelSerializer支持自动类型推断,因此序列化器字段名和模型字段可以不一致,但是需要指定数据来源source。
from django.db import modelsclass Role(models.Model):title = models.CharField(verbose_name="标题", max_length=32)order = models.IntegerField(verbose_name="顺序")class UserInfo(models.Model):name = models.CharField(verbose_name="姓名", max_length=32)gender = models.SmallIntegerField(verbose_name="性别", choices=((1, "男"), (2, "女")))role = models.ForeignKey(verbose_name="角色", to="Role", on_delete=models.CASCADE)ctime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
from api import modelsclass InfoSerializer(serializers.ModelSerializer):# 调用UserInfo实例上的 get_gender_display()方法,这是Django模型choices字段自带的一个方法,用于获取选项的友好显示值-------------------------------------------------------------gender = serializers.CharField(source="get_gender_display")-------------------------------------------------------------role = serializers.CharField(source="role.title")ctime = serializers.DateTimeField(format="%Y-%m-%d")other_name = serializers.CharField(source="name")-------------------------------------------------------# 定义额外字段mine = serializers.SerializerMethodField()-------------------------------------------------------class Meta:model = models.UserInfofields = ['id', 'name', 'gender', "role", 'ctime', "other_name", "mine"]# 固定搭配,以get_开头,这个方法返回的值就是 mine 字段在序列化输出中的值def get_mine(self, obj):# obj表示当前正在被序列化的模型实例return "x-x-{}".format(obj.name)# 视图
class InfoView(APIView):def get(self, request):queryset = models.UserInfo.objects.all()ser = InfoSerializer(instance=queryset, many=True)print(type(ser.data), ser.data)return Response(ser.data)
9.3 序列化类的嵌套使用
在DRF中,当处理包含 ForeignKey 和 ManyToManyField 字段的 Django 模型时,我们可以使用序列化类的嵌套来完成关联表数据的序列化。下面将分别介绍基于 SerializerMethodField 自定义方法和基于嵌套的序列化类这两种实现方式。首先定义以下模型:
# models.py
from django.db import modelsclass Author(models.Model):name = models.CharField(max_length=100)def __str__(self):return self.nameclass Category(models.Model):name = models.CharField(max_length=100)def __str__(self):return self.nameclass Book(models.Model):title = models.CharField(max_length=200)author = models.ForeignKey(Author, on_delete=models.CASCADE, related_name='books')categories = models.ManyToManyField(Category, related_name='books')def __str__(self):return self.title
对于外键,也就是多对一关系,获取外键字段可以按照如下方法:
-
获取
ID:直接使用外键字段名或_id后缀【多对一/一对一】class BookSerializer(serializers.ModelSerializer):class Meta:model = Book# fields = ['id', 'title', 'author']fields = ['id', 'title', 'author_id']# 效果一致 -
获取关联对象的某个特定属性 如
name:使用source参数class BookSerializer(serializers.ModelSerializer):author_name = serializers.CharField(source='author.name', read_only=True)class Meta:model = Bookfields = ['id', 'title', 'author_name'] -
获取关联对象的完整序列化表示:使用嵌套序列化
# serializers.py from rest_framework import serializers from .models import Author, Category, Bookclass AuthorSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name']class CategorySerializer(serializers.ModelSerializer):class Meta:model = Categoryfields = ['id', 'name']class BookSerializer(serializers.ModelSerializer):author = AuthorSerializer()class Meta:model = Bookfields = ['id', 'title', 'author']
对于多对多关系,获取字段可以按照如下方法:
-
获取
ID列表:直接使用字段名# serializers.py from rest_framework import serializers from .models import Author, Category, Bookclass AuthorSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name']class CategorySerializer(serializers.ModelSerializer):class Meta:model = Categoryfields = ['id', 'name']class BookSerializer(serializers.ModelSerializer):class Meta:model = Bookfields = ['id', 'title', 'categories']--------------------------------------------- {"id": 1,"title": "My Article","categories": [1, 2] // 关联的Tag对象的ID列表 } -
获取关联对象的某个特定属性列表:使用
serializers.SlugRelatedField(many=True)class BookSerializer(serializers.ModelSerializer):categories = serializers.SlugRelatedField(queryset=Category.objects.all(),slug_field='name',many=True)class Meta:model = Bookfields = ['id', 'title', 'categories'] # 此时 'categories' 将是 name 列表 -
获取完整关联对象列表:使用嵌套序列化
# serializers.py from rest_framework import serializers from .models import Author, Category, Bookclass AuthorSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name']class CategorySerializer(serializers.ModelSerializer):class Meta:model = Categoryfields = ['id', 'name']class BookSerializer(serializers.ModelSerializer):author = AuthorSerializer()# 注意many=Truecategories = CategorySerializer(many=True)class Meta:model = Bookfields = ['id', 'title', 'author', 'categories']
不管是多对一还是多对多,如果是想要以对象的形式获取关联对象中的部分属性,可以使用自定义方法实现:
# serializers.py
from rest_framework import serializers
from .models import Author, Category, Bookclass AuthorSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name']class CategorySerializer(serializers.ModelSerializer):class Meta:model = Categoryfields = ['id', 'name']class BookSerializer(serializers.ModelSerializer):author_info = serializers.SerializerMethodField()category_info = serializers.SerializerMethodField()def get_author_info(self, obj):author = obj.authorreturn {'id': author.id,'name': author.name}def get_category_info(self, obj):categories = obj.categories.all()return [{'id': category.id,'name': category.name} for category in categories]class Meta:model = Bookfields = ['id', 'title', 'author_info', 'category_info']
9.4 序列化类的继承
在DRF中,序列化类的继承是一种强大的机制,它允许你复用已有的序列化逻辑,如继承所有字段、Meta类及其属性、验证方法、create方法等,提高代码的可维护性和可扩展性,两个具有继承关系的序列化器,它们对应的模型不一定必须是继承关系。序列化类继承的常见使用常见如下:
REST_FRAMEWORK = {'DEFAULT_PERMISSION_CLASSES': ['rest_framework.permissions.AllowAny',],'DEFAULT_RENDERER_CLASSES': [# 'rest_framework.renderers.JSONRenderer','rest_framework.renderers.BrowsableAPIRenderer',],
}
# people/models.py
from django.db import modelsclass Person(models.Model):"""基础人员模型"""name = models.CharField(max_length=100, verbose_name="姓名")age = models.IntegerField(verbose_name="年龄")email = models.EmailField(verbose_name="邮箱", unique=True) # 邮箱唯一class Meta:verbose_name = "人员"verbose_name_plural = "人员"ordering = ['name'] # 按姓名排序def __str__(self):return self.nameclass Employee(Person):"""员工模型,继承自 Person"""department = models.CharField(max_length=100, verbose_name="部门")employee_id = models.CharField(max_length=50, unique=True, verbose_name="员工编号")hire_date = models.DateField(verbose_name="入职日期")class Meta:verbose_name = "员工"verbose_name_plural = "员工"ordering = ['department', 'name'] # 按部门和姓名排序def __str__(self):return f"{self.name} ({self.employee_id})"
# people/serializers.py
from rest_framework import serializers
from .models import Person, Employeeclass PersonSerializer(serializers.ModelSerializer):"""Person 模型的序列化器"""# status = serializers.SerializerMethodField()# def get_status(self, obj):# return "Active" if obj.age > 18 else "Minor"class Meta:model = Person# 包含所有 Person 模型的字段fields = ['id', 'name', 'age', 'email']read_only_fields = ['id'] # ID 通常是只读的class EmployeeSerializer(PersonSerializer): # 继承 PersonSerializer"""Employee 模型的序列化器,继承自 PersonSerializer"""# 可以在这里添加 Employee 特有的计算字段或自定义显示hire_year = serializers.SerializerMethodField()class Meta(PersonSerializer.Meta): # 继承父类的 Meta 类model = Employee # 覆盖 model 属性,指向 Employee 模型# 继承父类的fields,并添加Employee 特有的字段fields = PersonSerializer.Meta.fields + ['department', 'employee_id', 'hire_date', 'hire_year']# 可以添加或覆盖 read_only_fields 等其他 Meta 配置read_only_fields = PersonSerializer.Meta.read_only_fields + ['employee_id', 'hire_year'] # 员工编号和入职年份是只读的def get_hire_year(self, obj):# 计算并返回入职年份if obj.hire_date:return obj.hire_date.yearreturn None# 可以重写 create/update 方法来添加 Employee 特有的逻辑# 例如在创建 Employee 时,生成一个默认的 employee_id# def create(self, validated_data):# if 'employee_id' not in validated_data or not validated_data['employee_id']:# validated_data['employee_id'] = f"EMP-{datetime.now().strftime('%Y%m%d%H%M%S')}"# return super().create(validated_data)
# people/views.py
from rest_framework import generics
from rest_framework.permissions import AllowAny # 允许匿名访问,实际应用中可能需要认证
from .models import Person, Employee
from .serializers import PersonSerializer, EmployeeSerializerclass PersonListCreateAPIView(generics.ListCreateAPIView):"""GET: 获取所有人员列表POST: 创建新人员"""queryset = Person.objects.all()serializer_class = PersonSerializerpermission_classes = [AllowAny]class PersonRetrieveUpdateDestroyAPIView(generics.RetrieveUpdateDestroyAPIView):"""GET: 获取单个人员详情PUT/PATCH: 更新人员信息DELETE: 删除人员"""queryset = Person.objects.all()serializer_class = PersonSerializerpermission_classes = [AllowAny]lookup_field = 'pk' # 默认就是pk,可以省略class EmployeeListCreateAPIView(generics.ListCreateAPIView):"""GET: 获取所有员工列表POST: 创建新员工"""queryset = Employee.objects.all()serializer_class = EmployeeSerializerpermission_classes = [AllowAny]class EmployeeRetrieveUpdateDestroyAPIView(generics.RetrieveUpdateDestroyAPIView):"""GET: 获取单个员工详情PUT/PATCH: 更新员工信息DELETE: 删除员工"""queryset = Employee.objects.all()serializer_class = EmployeeSerializerpermission_classes = [AllowAny]lookup_field = 'pk'
9.5 序列化器的校验
9.5.1 字段级别的验证
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializersclass InfoSerializer(serializers.Serializer):# 字段级别的验证title = serializers.CharField(required=True, max_length=20, min_length=6)order = serializers.IntegerField(required=False, max_value=100, min_value=10)level = serializers.ChoiceField(choices=[("1", "高级"), (2, "中级")])class InfoView(APIView):def post(self, request):ser = InfoSerializer(data=request.data)ser.is_valid(raise_exeption=True):# ser.validated_data 是一个字典,包含通过验证的数据return Response(ser.validated_data)
除了字段自带的验证规则,还可以自定义的字段验证方法,即钩子验证,方法名遵循 validate_<field_name> 的命名规则。is_valid() 方法会调用这些自定义方法进行额外的验证。
from rest_framework import serializersclass UserSerializer(serializers.Serializer):username = serializers.CharField()def validate_username(self, value):if 'admin' in value.lower():raise serializers.ValidationError("用户名不能包含 'admin'")return valuedata = {"username": "john_doe"
}serializer = UserSerializer(data=data)
if serializer.is_valid():print("数据验证通过")
else:print("数据验证失败")
当任何一个字段的验证不通过时,serializer.is_valid() 方法会捕获这些错误,并采取以下行动:
-
serializer.is_valid()返回False -
serializer.errors属性被填充,如下:{"title": ["此字段是必填项。", // required=True 失败"确保此字段的长度不大于 20。", // max_length 失败"确保此字段的长度不小于 6。" // min_length 失败],"order": ["确保此值不大于 100。", // max_value 失败"确保此值不小于 10。" // min_value 失败],"level": ["“invalid_choice”不是一个有效的选项。" // ChoiceField 失败],"non_field_errors": [ // 如果有对象级别的验证错误"某个字段组合不合法。"] }
9.5.2 对象级别的验证
可以通过定义 validate 方法对整个对象的数据进行综合验证,检查多个字段之间的关系。is_valid() 方法会调用这个方法进行验证。对象级别验证在字段验证之后进行。
from rest_framework import serializersclass UserSerializer(serializers.Serializer):password = serializers.CharField()confirm_password = serializers.CharField()def validate(self, data):if data['password'] != data['confirm_password']:raise serializers.ValidationError("两次输入的密码不一致")return datadata = {"password": "abc123","confirm_password": "abc123"
}serializer = UserSerializer(data=data)
if serializer.is_valid():print("数据验证通过")
else:print("数据验证失败")
9.5.3 验证器的使用
可以在字段定义时使用 validators 参数传入自定义的验证器列表,is_valid() 方法会调用这些验证器进行验证。
-
正则验证器可借助正则表达式来校验数据是否符合特定的格式。在
DRF里,可使用RegexValidator来实现正则验证。from rest_framework import serializers from django.core.validators import RegexValidator# 定义一个正则表达式,用于验证手机号码 phone_regex = RegexValidator(regex=r'^1[3-9]\d{9}$',message="手机号码格式不正确,必须以1开头,第二位是3-9,后面跟9位数字" )class UserSerializer(serializers.Serializer):phone_number = serializers.CharField(validators=[phone_regex])data = {"phone_number": "13800138000" }serializer = UserSerializer(data=data) if serializer.is_valid():print("数据验证通过") else:print(serializer.errors) -
EmailValidator:用于验证字符串是否为有效的电子邮件地址。from rest_framework import serializers from django.core.validators import EmailValidatorclass UserSerializer(serializers.Serializer):email = serializers.CharField(validators=[EmailValidator(message="邮箱格式错误")])data = {"email": "test@example.com" }serializer = UserSerializer(data=data) if serializer.is_valid():print("数据验证通过") else:print(serializer.errors) -
URLValidator:用于验证字符串是否为有效的URL地址。from rest_framework import serializers from django.core.validators import URLValidatorclass ArticleSerializer(serializers.Serializer):link = serializers.CharField(validators=[URLValidator()])data = {"link": "https://www.example.com" }serializer = ArticleSerializer(data=data) if serializer.is_valid():print("数据验证通过") else:print(serializer.errors) -
MinValueValidator和MaxValueValidator:分别用于验证数值字段的最小值和最大值。from rest_framework import serializers from django.core.validators import MinValueValidator, MaxValueValidatorclass ProductSerializer(serializers.Serializer):price = serializers.IntegerField(validators=[MinValueValidator(0, message="价格不能为负数"),MaxValueValidator(1000, message="价格不能超过 1000")])data = {"price": 500 }serializer = ProductSerializer(data=data) if serializer.is_valid():print("数据验证通过") else:print(serializer.errors) -
MinLengthValidator和MaxLengthValidator:分别用于验证字符串字段的最小长度和最大长度。 -
自定义验证器:可以同时使用多个验证器。
from rest_framework import serializersdef validate_email_domain(value):if not value.endswith('@example.com'):raise serializers.ValidationError("邮箱必须使用 @example.com 域名")return valueclass UserSerializer(serializers.Serializer):email = serializers.EmailField(validators=[validate_email_domain])data = {"email": "john@example.com" }serializer = UserSerializer(data=data) if serializer.is_valid():print("数据验证通过") else:print("数据验证失败")
9.5.4 Model验证
允许你为那些由 ModelSerializer 自动创即由模型字段推断而来的序列化器字段,指定或覆盖它们的额外参数和行为。
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
from rest_framework import exceptions
from api import models
from django.core.validators import RegexValidatorclass RoleSerializer(serializers.ModelSerializer):more = serializers.CharField(required=True)class Meta:model = models.Rolefields = ["title", "order", "more"]extra_kwargs = {"title": {"validators": [RegexValidator(r"\d+", message="格式错误")]},"order": {"min_value": 5},}def validate_more(self, value):return valuedef validate(self, attrs):return attrsclass InfoView(APIView):def post(self, request):ser = RoleSerializer(data=request.data)if ser.is_valid():return Response(ser.validated_data)else:return Response(ser.errors)
| 参数名 | 类型 | 作用 | 示例用法 |
|---|---|---|---|
| read_only | 布尔值 | 字段仅用于序列化输出,不参与反序列化创建/更新 | {'read_only': True} |
| write_only | 布尔值 | 字段仅用于反序列化输入,不包含在API响应中 | {'write_only': True} |
| required | 布尔值 | 控制反序列化时是否必须提供字段值 | {'required': False} |
| validators | 列表 | 添加自定义验证逻辑 | {'validators': [UniqueValidator(...)]} |
| error_messages | 字典 | 自定义字段验证错误提示 | {'error_messages': {'required': '必填项'}} |
| min_length | 整数 | 字符串字段最小长度验证 | {'min_length': 5} |
| max_length | 整数 | 字符串字段最大长度验证 | {'max_length': 100} |
| min_value | 数字 | 数值字段最小值验证 | {'min_value': 0} |
| max_value | 数字 | 数值字段最大值验证 | {'max_value': 100} |
| allow_null | 布尔值 | 是否接受null作为有效输入 | {'allow_null': True} |
| format | 字符串 | 控制日期时间字段的序列化输出格式 | {'format': '%Y-%m-%d %H:%M'} |
| input_formats | 字符串列表 | 指定日期时间字段反序列化时的可接受输入格式 | {'input_formats': ['%Y/%m/%d']} |
9.5.5 ser.save()
ser.save() 方法主要用于将经过序列化器验证后的数据保存到数据库中。ser.validated_data是一个字典,包含了经过验证和清理后的数据,可以用于创建或更新数据库记录等操作。save()可以通过关键字参数的形式传入额外的数据,这些数据会和验证后的数据合并,然后用于创建或更新对象。
-
创建新对象:
RoleSerializer(data=request.data)from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers from .models import Roleclass RoleSerializer(serializers.ModelSerializer):class Meta:model = Rolefields = '__all__'class InfoView(APIView):def post(self, request):ser = RoleSerializer(data=request.data)if ser.is_valid():# 创建新的 Role 对象并保存到数据库new_role = ser.save()return Response(ser.data)return Response(ser.errors) -
更新现有对象:
RoleSerializer(instance=role, data=request.data)from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers from .models import Roleclass RoleSerializer(serializers.ModelSerializer):class Meta:model = Rolefields = '__all__'class InfoView(APIView):def put(self, request, pk):try:role = Role.objects.get(pk=pk)except Role.DoesNotExist:return Response(status=404)ser = RoleSerializer(role, data=request.data)if ser.is_valid():# 更新现有的 Role 对象并保存到数据库updated_role = ser.save()return Response(ser.data)return Response(ser.errors) -
自定义保存逻辑
from rest_framework import serializers from .models import Roleclass RoleSerializer(serializers.ModelSerializer):class Meta:model = Rolefields = '__all__'def create(self, validated_data):# 自定义创建逻辑role = Role.objects.create(**validated_data)# 可以在这里添加额外的操作,比如记录日志等return roledef update(self, instance, validated_data):# 自定义更新逻辑for attr, value in validated_data.items():setattr(instance, attr, value)instance.save()# 可以在这里添加额外的操作,比如发送通知等return instance
当使用 serializer.save() 方法来保存新对象或更新现有对象时,其背后的原理是它会尝试将 serializer.validated_data 中的键值对映射到模型实例的字段上。如果 validated_data 中的键与模型字段无法匹配,或者缺少必要的字段,就可能导致错误。
-
序列化器接收的参数多于模型字段:在使用
save前使用pop()移除多余的字段。validated_data.pop('category_name', None) ser.save() -
序列化器接收的参数少于模型必需的字段:通过
**kwargs传递额外参数。serializer.save(last_modified_by=self.request.user, ...)
对于FK,其默认验证规则是外键的表的主键值是否存在,存在即通过不存在即不通过。如果不满足需求,可以自定义验证钩子,如下:
# myapp/serializers.py
from rest_framework import serializers
from .models import UserInfo, Departmentclass UserInfoSerializer(serializers.ModelSerializer):# 隐式,自动关联到外键表的主键# depart = serializers.PrimaryKeyRelatedField(queryset=Department.objects.all())class Meta:model = UserInfofields = ['id', 'name', 'age', 'depart']def validate_depaer(self, value):# 这里的value是一个depart对象if value.id > 1:return valueraise exceptions.ValidationError("部门错误")
对于多对多关系的字段,与外键【多对一】有所不同,如下:
# myapp/models.py
from django.db import modelsclass Tag(models.Model):name = models.CharField(max_length=50, unique=True)def __str__(self):return self.nameclass Article(models.Model):title = models.CharField(max_length=200)content = models.TextField()tags = models.ManyToManyField(Tag, related_name='articles') # 多对多字段def __str__(self):return self.title
# myapp/serializers.py
from rest_framework import serializers
from .models import Article, Tagclass ArticleSerializer(serializers.ModelSerializer):# tags 字段会自动被 ModelSerializer 映射为 PrimaryKeyRelatedField(many=True)class Meta:model = Articlefields = ['id', 'title', 'content', 'tags']
# 有效请求
{"title": "学习DRF","content": "这是一篇关于DRF的文章。","tags": [1, 2] // 存在 Tag ID 为 1 和 2
}
# 默认也是查看id是存在,也可以自定义验证规则
class ArticleSerializer(serializers.ModelSerializer):class Meta:model = Articlefields = ['id', 'title', 'content', 'tags']def validate_tags(self, values): # values 是 Tag 实例的列表,而不是ID列表if len(values) > 5:raise serializers.ValidationError("文章标签不能超过5个")# 检查是否有禁用标签disabled_tag_names = ["禁止标签"]for tag in values:if tag.name in disabled_tag_names:raise serializers.ValidationError(f"'{tag.name}' 标签已被禁用")return values
10. 分页组件
在 DRF中,分页是处理大量数据时非常重要的功能,它允许将数据分成多个页面进行展示,避免一次性返回过多数据,从而提高系统性能和用户体验。分页的核心目的是将数据集分成多个小块,每个小块称为一页,客户端可以通过指定页码或偏移量来获取特定页面的数据。DRF 中的分页器负责处理分页逻辑,包括计算总页数、当前页的数据范围等。常见的分页器如下:
-
PageNumberPagination:这是最常用的分页方式,通过页码来访问不同页面的数据。客户端可以通过page参数指定要访问的页码。响应会包含总记录数、当前页码、下一页和上一页的链接,查询参数通常是?page=X和?page_size=Y。-
全局配置:只要视图继承了
GenericAPIView或ViewSet,就会自动使用全局配置中的分页器。APIView不会自动执行全局配置的分页器,但是可以按照如下使用内置的分页器。# settings.py # 全局配置 REST_FRAMEWORK = {'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination','PAGE_SIZE': 10 # 每页显示 10 条数据 }# 局部配置 # views.py from rest_framework import generics from.models import Book from.serializers import BookSerializerclass BookList(generics.ListAPIView):queryset = Book.objects.all()from rest_framework.pagination import PageNumberPagination# 分页处理pager = PageNumberPagination()result = pager.paginate_queryset(queryset, request, view.self)# 序列化ser = BookSerializer(instance=result, many=True)response = pager.get_paginated_response(ser.data) -
自定义:自定义
PageNumberPagination可以修改一些相关的配置项:class PageNumberPagination(BasePagination):page_size = api_settings.PAGE_SIZE# 用于指定页码的查询参数名称page_query_param = 'page'page_query_description = _('A page number within the paginated result set.')# 设置为None时客户端不能通过查询参数指定page_size, 设置为字符串时表示通过该字符串设置page_sizepage_size_query_param = Nonepage_size_query_description = _('Number of results to return per page.')# 最大每页记录数量max_page_size = None# 客户端请求最后一页时可以使用的字符串,?page=lastlast_page_strings = ('last',)template = 'rest_framework/pagination/numbers.html'invalid_page_message = _('Invalid page.') -
局部配置:对于
generics.ListAPIView/ViewSet,局部配置指定pagination_class属性即可。对于APIView使用较为繁琐,因为也不建议分页数据通过APIView返回。对于generics.ListAPIView/ViewSet,还是跟之前一样使用Response返回数据即可。# myapp/views.py from rest_framework.views import APIView from rest_framework.response import Response from rest_framework.pagination import PageNumberPagination, LimitOffsetPaginationfrom .models import Product from .serializers import ProductSerializerclass ProductListAPIView(APIView):pagination_class = ProductPageNumberPagination # 使用自定义分页器def get(self, request, *args, **kwargs):queryset = Product.objects.all().order_by('created_at')paginator = self.pagination_class()# 对查询集进行分页page_data = paginator.paginate_queryset(queryset, request, view=self)# 序列化分页后的数据serializer = ProductSerializer(page_data, many=True)# 4. 返回分页响应return paginator.get_paginated_response(serializer.data)# 访问示例: /products-apiview/?page=2&page_size=10
-
-
LimitOffsetPagination:这种分页方式通过limit和offset参数来控制数据的显示。limit表示每页显示的数据数量,offset表示从数据集的哪个位置开始获取数据。客户端可以通过?limit=20&offset=10这样的参数来获取从第 10 条数据开始的 20 条数据。使用方法与PageNumberPagination一致。class LimitOffsetPagination(BasePagination):"""A limit/offset based style. For example:http://api.example.org/accounts/?limit=100http://api.example.org/accounts/?offset=400&limit=100"""default_limit = api_settings.PAGE_SIZElimit_query_param = 'limit'limit_query_description = _('Number of results to return per page.')offset_query_param = 'offset'offset_query_description = _('The initial index from which to return the results.')max_limit = Nonetemplate = 'rest_framework/pagination/numbers.html' -
CursorPagination:CursorPagination是一种基于游标的分页方式,它使用一个加密的游标来标记当前页面的位置,适用于处理大量数据和需要高效分页的场景。这种分页方式不支持任意页码的访问,只能依次向前或向后翻页。客户端可以通过响应中返回的next和previous链接来进行翻页操作。# settings.py REST_FRAMEWORK = {'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.CursorPagination','PAGE_SIZE': 10 # 每页显示 10 条数据 }# views.py from rest_framework import generics from.models import Book from.serializers import BookSerializerclass BookList(generics.ListAPIView):queryset = Book.objects.all()serializer_class = BookSerializerordering = '-id' # 必须指定排序字段
10. 视图
在DRF里,视图是处理客户端请求并返回响应的核心组件。DRF 提供了多种类型的视图,能满足不同场景下的开发需求。
10.1. 基于函数的视图
基于函数的视图是最基础的视图类型,本质上就是普通的 Python 函数,接收 request 对象作为参数,并返回 Response 对象。
from rest_framework.decorators import api_view
from rest_framework.response import Response
from.models import Book
from.serializers import BookSerializer@api_view(['GET', 'POST'])
def book_list(request):if request.method == 'GET':books = Book.objects.all()serializer = BookSerializer(books, many=True)return Response(serializer.data)elif request.method == 'POST':serializer = BookSerializer(data=request.data)if serializer.is_valid():serializer.save()return Response(serializer.data, status=201)return Response(serializer.errors, status=400)
10.2 基于类的视图
APIView:APIView 是 DRF 中最基础的基于类的视图,需要手动实现各个 HTTP 方法的处理逻辑。只提供认证、权限、限流、内容协商等核心 DRF 功能,不处理模型和查询集。在开发中,对于视图的选择,可以按照如下规则:
- 优先使用
ModelViewSet或ReadOnlyModelViewSet:它们是 DRF 中最推荐的方式,能以最少的代码提供最丰富的功能,并且与路由器完美配合。 - 其次考虑通用视图:如果你只需要一个特定操作的 API,例如,只列出不创建,或者不想使用
ViewSet的全部功能,它们提供了一个很好的折衷。 - 最后才考虑
APIView:只有当你的需求非常特殊,不符合任何标准 RESTful 模式,或者需要完全手写 HTTP 方法处理逻辑时,才使用APIView。
10.2.1 GenericAPIView
GenericAPIView 是 DRF 中一个非常重要的基类,它扩展了最基本的 APIView,并为构建 RESTful API 的常见模式提供了许多开箱即用的功能和属性。它被称为通用视图是因为它抽象了许多与模型相关的、通用的 API 行为。
在 APIView 的基础上,增加了与模型、查询集、序列化器、分页、过滤相关的通用行为和方法。它本身不提供 HTTP 方法如 get, post的实现,通常需要与 DRF 提供的 Mixins 结合使用。其核心属性如下:
queryset:用于从此视图返回对象的默认查询集。它是你的 API 要操作的数据的基础。如queryset = Product.objects.all()。serializer_class:用于验证和反序列化输入数据,以及序列化输出数据的序列化器类。如serializer_class = ProductSerializer。lookup_field:用于获取单个模型实例时,模型实例上用于查找的字段名称。默认值是主键,其它需设置如lookup_field = 'slug'【如果你的 URL 中通过slug查找对象】,当你的URL pattern使用了lookup_field以外的名称例如/products/<str:product_slug>/,你还需要设置Workspace_kwarg。Workspace_kwarg:URLconf中用于查找的关键字参数名称,默认值与lookup_field的值相同,如果你的URL是path('products/<slug:item_slug>/', ProductDetail.as_view())且lookup_field = 'slug',你就需要设置Workspace_kwarg = 'item_slug'。
其核心方法如下:这些方法是GenericAPIView的对APIView中处理查询结果、序列化、分页的方法的封装,包括但不限于以下方法。
-
get_queryset(self):返回视图应该操作的查询集。当你需要根据请求如request.user、URL 参数动态地调整查询集时,应该重写此方法而不是直接设置queryset属性,则需要重写。def get_queryset(self):user = self.request.userreturn Product.objects.filter(owner=user).order_by('-created_at') -
get_serializer_class(self):返回视图应该使用的序列化器类。 当你需要根据请求的类型【GET vs. POST】、用户角色或其他条件,动态地选择不同的序列化器时,则需要重写。def get_serializer_class(self):if self.request.method == 'GET':return ProductReadOnlySerializerreturn ProductWriteSerializer -
get_serializer(self, *args, **kwargs):返回序列化器实例。这是实际创建序列化器对象的方法。在视图方法内部需要一个序列化器实例时调用,如serializer = self.get_serializer(instance=obj)。
GenericAPIView 本身不实现任何 HTTP 方法如 get, post, put 等。它需要与 DRF 提供的 Mixins 结合使用才能提供具体的行为。如下:
-
ListModelMixin:提供list()方法来获取一个对象列表。 -
CreateModelMixin:提供create()方法来创建一个新对象。 -
RetrieveModelMixin:提供retrieve()方法来获取单个对象。 -
UpdateModelMixin:提供update()方法来更新单个对象。 -
DestroyModelMixin:提供destroy()方法来删除单个对象。# myapp/views.py from rest_framework import generics, mixins from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedclass ProductListCreateAPIView(mixins.ListModelMixin, # 提供 list() 方法mixins.CreateModelMixin, # 提供 create() 方法generics.GenericAPIView # 提供 get_queryset, get_serializer_class, pagination_class 等核心功能 ):queryset = Product.objects.all().order_by('created_at')serializer_class = ProductSerializerpermission_classes = [IsAuthenticated] # 示例权限设置pagination_class = generics.PageNumberPagination # 示例分页设置def get(self, request, *args, **kwargs):# 调用 ListModelMixin 提供的 list 方法return self.list(request, *args, **kwargs)def post(self, request, *args, **kwargs):# 调用 CreateModelMixin 提供的 create 方法return self.create(request, *args, **kwargs)
在 DRF 的实际开发中,**直接使用 GenericAPIView 的情况相对较少,但它是一个非常重要的基石,理解它能帮助你更好地理解 DRF 的工作原理,并在需要高度定制化时使用它。**通常情况下,开发者会优先选择使用:
- 具体通用视图:这是最常见和推荐的方式,例如
ListAPIView、CreateAPIView、RetrieveAPIView,、UpdateAPIView,、DestroyAPIView,ListCreateAPIView、RetrieveUpdateDestroyAPIView等。其实它们就是它们是GenericAPIView和不同Mixins的预组合,旨在快速构建标准的RESTful API端点。 ModelViewSet或ReadOnlyModelViewSet: 对于资源集合的操作,ViewSets是一个更强大的抽象,可以将多个视图逻辑封装在一个类中,配合Routers使用可以大大简化URL配置。它们进一步封装了GenericAPIView和Mixins,提供了完整的CRUD行为,并能与DRF的路由系统无缝集成。
10.2.2 具体通用视图
-
ListAPIView:GenericAPIView+ListModelMixin,供只读的列表视图。处理GET请求,返回一个资源集合。当你需要获取某个资源的所有实例列表时使用。GET /products/。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedOrReadOnly # 导入权限类class ProductListView(generics.ListAPIView):queryset = Product.objects.all().order_by('name') # 列表视图需要排序serializer_class = ProductSerializerpermission_classes = [IsAuthenticatedOrReadOnly] # 允许认证用户和匿名用户查看# pagination_class = PageNumberPagination # 如果需要分页,在这里或settings.py配置 -
CreateAPIView:GenericAPIView+CreateModelMixin,提供只写的创建视图。处理POST请求,用于创建一个新资源。当你需要创建某个资源的单个实例时时使用。POST /products/。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticated # 导入权限类class ProductCreateView(generics.CreateAPIView):queryset = Product.objects.all() # queryset 仍然需要,即使 CreateAPIView 不直接查询它serializer_class = ProductSerializerpermission_classes = [IsAuthenticated] # 只有认证用户才能创建 -
RetrieveAPIView:GenericAPIView+RetrieveModelMixin, 提供只读的详情视图。处理GET请求,返回单个资源实例。当你需要获取某个资源的单个特定实例详情时使用。``GET /products/1/`。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedOrReadOnlyclass ProductDetailView(generics.RetrieveAPIView):queryset = Product.objects.all()serializer_class = ProductSerializerpermission_classes = [IsAuthenticatedOrReadOnly]# lookup_field = 'slug' # 如果你通过 slug 查找,可以设置# lookup_url_kwarg = 'product_slug' # 如果 URL 参数名不同于 lookup_field -
UpdateAPIView:GenericAPIView+UpdateModelMixin,提供只写的更新视图。处理PUT和PATCH请求,用于更新单个资源实例。当你需要修改某个资源的单个特定实例时使用。PUT /products/{id}/或PATCH /products/{id}/。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedclass ProductUpdateView(generics.UpdateAPIView):queryset = Product.objects.all()serializer_class = ProductSerializerpermission_classes = [IsAuthenticated] -
DestroyAPIView:GenericAPIView+DestroyModelMixin,提供只写的删除视图。处理DELETE请求,用于删除单个资源实例。当你需要删除某个资源的单个特定实例时使用。DELETE /products/{id}/。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedclass ProductDestroyView(generics.DestroyAPIView):queryset = Product.objects.all()serializer_class = ProductSerializer # serializer_class 仍然需要,尽管不用于序列化输出permission_classes = [IsAuthenticated] -
ListCreateAPIView:GenericAPIView+ListModelMixin+CreateModelMixin,提供列表和创建功能。处理GET列表 和POST创建 请求。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedOrReadOnlyclass ProductListCreateAPIView(generics.ListCreateAPIView):queryset = Product.objects.all().order_by('created_at')serializer_class = ProductSerializerpermission_classes = [IsAuthenticatedOrReadOnly]# pagination_class = PageNumberPagination # 列表部分会分页 -
RetrieveUpdateDestroyAPIView:GenericAPIView+RetrieveModelMixin+UpdateModelMixin+DestroyModelMixin, 提供详情、更新和删除功能。# views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from rest_framework.permissions import IsAuthenticatedOrReadOnlyclass ProductRetrieveUpdateDestroyAPIView(generics.RetrieveUpdateDestroyAPIView):queryset = Product.objects.all()serializer_class = ProductSerializerpermission_classes = [IsAuthenticatedOrReadOnly]
10.2.3 视图集
-
ModelViewSet:ModelViewSet提供了完整的CRUD功能,是最常用的ViewSet类型。五种mixin+GenericAPIView。# myapp/models.py from django.db import models from django.contrib.auth.models import Userclass Product(models.Model):name = models.CharField(max_length=100)description = models.TextField(blank=True)price = models.DecimalField(max_digits=10, decimal_places=2)owner = models.ForeignKey(User, on_delete=models.CASCADE, related_name='products')created_at = models.DateTimeField(auto_now_add=True)def __str__(self):return self.name# myapp/serializers.py from rest_framework import serializers from .models import Product from django.contrib.auth.models import User # 假设User模型存在class UserSerializer(serializers.ModelSerializer):class Meta:model = Userfields = ['id', 'username']class ProductSerializer(serializers.ModelSerializer):owner = UserSerializer(read_only=True) # 嵌套序列化,只读显示owner信息class Meta:model = Productfields = ['id', 'name', 'description', 'price', 'owner', 'created_at']read_only_fields = ['owner', 'created_at'] # owner和created_at自动设置def create(self, validated_data):# 在创建时,将当前请求用户设置为ownervalidated_data['owner'] = self.context['request'].userreturn Product.objects.create(**validated_data)# myapp/views.py from rest_framework import viewsets from rest_framework.permissions import IsAuthenticatedOrReadOnly, IsAuthenticated from .models import Product from .serializers import ProductSerializerclass ProductViewSet(viewsets.ModelViewSet):"""一个用于查看、编辑、创建或删除产品的视图集"""queryset = Product.objects.all().order_by('-created_at') # 列表通常需要排序serializer_class = ProductSerializerpermission_classes = [IsAuthenticatedOrReadOnly] # 允许认证用户写,匿名用户读# 如果需要,可以重写 get_queryset 来根据用户过滤# def get_queryset(self):# user = self.request.user# if user.is_authenticated:# return Product.objects.filter(owner=user).order_by('-created_at')# return Product.objects.none() # 匿名用户不允许看任何产品# 可以添加自定义动作 使用@action装饰器# from rest_framework.decorators import action# from rest_framework.response import Response# @action(detail=True, methods=['post']) # detail=True 表示作用于单个实例# def mark_as_sold(self, request, pk=None):# product = self.get_object()# product.status = 'sold'# product.save()# return Response({'status': 'product marked as sold'}) -
ReadOnlyModelViewSet:mixins.ListModelMixin+mixins.RetrieveModelMixin+GenericViewSet,提供了只读功能。# myapp/views.py (继续上面的示例) from rest_framework import viewsets from rest_framework.permissions import AllowAny # 导入权限类class ReadOnlyProductViewSet(viewsets.ReadOnlyModelViewSet):"""一个只读的,用于查看产品列表和详情的视图集。"""queryset = Product.objects.all().order_by('name')serializer_class = ProductSerializerpermission_classes = [AllowAny] # 允许任何人访问
当定义好视图集后,需要配置路由,如下:
urlpatterns = [path('admin/', admin.site.urls),# 定义资源列表和创建的路由# GET 请求映射到 list 动作# POST 请求映射到 create 动作path('api/products/', ProductViewSet.as_view({'get': 'list','post': 'create'}), name='product-list-create'),# 定义单个资源详情、更新和删除的路由# GET 请求映射到 retrieve 动作# PUT 请求映射到 update 动作# PATCH 请求映射到 partial_update 动作# DELETE 请求映射到 destroy 动作path('api/products/<int:pk>/', ProductViewSet.as_view({'get': 'retrieve','put': 'update','patch': 'partial_update','delete': 'destroy'}), name='product-detail-update-destroy'),# 如果你有自定义动作,也需要手动映射# ProductViewSet有一个@action(detail=False, methods=['get']) def recent(self, request):# path('api/products/recent/', ProductViewSet.as_view({# 'get': 'recent'# }), name='product-recent'),
]
10.2.4 路由器
当使用视图集后,路由配置也是较为繁琐的,这时可以使用路由器,DRF中提供了两种路由器:
-
DefaultRouter:推荐使用,自动为你的ViewSet生成所有标准的CRUD URL, -
SimpleRouter:DefaultRouter的简化版本,# myapp/models.py from django.db import modelsclass Product(models.Model):name = models.CharField(max_length=100)price = models.DecimalField(max_digits=10, decimal_places=2)def __str__(self): return self.name# myapp/serializers.py from rest_framework import serializers from .models import Productclass ProductSerializer(serializers.ModelSerializer):class Meta:model = Productfields = '__all__'# myapp/views.py from rest_framework import viewsets from rest_framework.permissions import IsAuthenticatedOrReadOnly from .models import Product from .serializers import ProductSerializerclass ProductViewSet(viewsets.ModelViewSet):queryset = Product.objects.all().order_by('name')serializer_class = ProductSerializerpermission_classes = [IsAuthenticatedOrReadOnly]# 你也可以有 ReadOnlyModelViewSet 或者自定义的 GenericViewSet # class CategoryViewSet(viewsets.ReadOnlyModelViewSet): # queryset = Category.objects.all() # serializer_class = CategorySerializer# myproject/urls.py from django.contrib import admin from django.urls import path, include from rest_framework.routers import DefaultRouter, SimpleRouter # 导入路由器# 导入你的 ViewSets from myapp.views import ProductViewSet # CategoryViewSet# 创建路由器实例 # router = SimpleRouter() router = DefaultRouter()# 注册你的 ViewSets # router.register(r'URL前缀', ViewSet类, basename='可选,建议设置') # basename 用于生成URL名称,例如 'product-list', 'product-detail' # 如果 ViewSet 没有定义 queryset 属性,basename 必须显式设置 # 如果 ViewSet 定义了 queryset 属性,DRF 可以从 queryset.model._meta.model_name 推断出 basenamerouter.register(r'products', ProductViewSet, basename='product') # router.register(r'categories', CategoryViewSet, basename='category')urlpatterns = [path('admin/', admin.site.urls),# 将路由器生成的 URL 模式包含到你的 URL 配置中path('api/', include(router.urls)), # 所有的 ViewSet URL 都会在 /api/ 下 ]URL 模式 对应动作 HTTP 方法 说明 /api/products/list()GET 获取全部产品列表 /api/products/create()POST 创建新产品 /api/products/{pk}/retrieve()GET 获取单个产品详情 /api/products/{pk}/update()PUT 全量更新产品信息 /api/products/{pk}/partial_update()PATCH 部分更新产品信息 /api/products/{pk}/destroy()DELETE 删除指定产品 /api/products/{action_name}/【detail=False】action_name自定义 自定义动作 /api/products/{pk}/{action_name}/【detail=True】action_name自定义 自定义动作
10.2.5 筛选器
在 DRF中,筛选器Filters 允许你的 API 用户通过 URL 查询参数来细化他们请求的数据集。这对于构建灵活和功能强大的 API 至关重要,因为你不太可能总是想返回所有数据。DRF 提供了多种方式来实现数据筛选:
-
基于
Django ORM的简单查询,纯手动# myapp/views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializerclass ProductListManualFilterView(generics.ListAPIView):serializer_class = ProductSerializerdef get_queryset(self):# 总是先获取完整的 querysetqueryset = Product.objects.all()# 根据查询参数进行过滤name = self.request.query_params.get('name')price = self.request.query_params.get('price')min_price = self.request.query_params.get('min_price')max_price = self.request.query_params.get('max_price')if name:# 模糊查询,不区分大小写queryset = queryset.filter(name__icontains=name)if price:# 精确查询queryset = queryset.filter(price=price)if min_price:# 大于等于查询queryset = queryset.filter(price__gte=min_price)if max_price:# 小于等于查询queryset = queryset.filter(price__lte=max_price)# 确保始终有排序,尤其是在分页时return queryset.order_by('id')# URL /products/?name=apple&min_price=10.00 -
使用
DRF内置的DjangoFilterBackend,推荐且最常用pip install django-filterINSTALLED_APPS = [# ...'django_filters', # 确保在rest_framework之前或之后'rest_framework','myapp',# ... ]REST_FRAMEWORK = {'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend'],# ... 其他 DRF 设置 }# 局部配置 class ProductListFilteredView(generics.ListAPIView):# ...filter_backends = [DjangoFilterBackend]# ...# 创建fileSet类 # myapp/filters.py import django_filters from .models import Productclass ProductFilter(django_filters.FilterSet):# name 字段支持模糊查询 containsname = django_filters.CharFilter(lookup_expr='icontains') # icontains 不区分大小写# price 支持范围查询min_price = django_filters.NumberFilter(field_name='price', lookup_expr='gte')max_price = django_filters.NumberFilter(field_name='price', lookup_expr='lte')# created_at 支持日期范围start_date = django_filters.DateFilter(field_name='created_at', lookup_expr='date__gte')end_date = django_filters.DateFilter(field_name='created_at', lookup_expr='date__lte')class Meta:model = Product# 直接列出允许精确匹配的字段fields = ['name', 'price', 'owner'] # 'owner' 默认是精确匹配,例如 ?owner=1# 也可以在这里指定所有可筛选的字段# fields = {# 'name': ['exact', 'icontains'],# 'price': ['exact', 'gte', 'lte'],# 'owner': ['exact'],# 'created_at': ['date__gte', 'date__lte'],# }# myapp/views.py from rest_framework import generics from django_filters.rest_framework import DjangoFilterBackend from .models import Product from .serializers import ProductSerializer from .filters import ProductFilter # 导入你定义的 FilterSetclass ProductListFilteredView(generics.ListAPIView):queryset = Product.objects.all().order_by('id')serializer_class = ProductSerializerfilter_backends = [DjangoFilterBackend] # 使用 DjangoFilterBackendfilterset_class = ProductFilter # 指定你的 FilterSet 类# url示例 GET /products/?name=apple GET /products/?price=9.99 GET /products/?min_price=10.00&max_price=50.00 GET /products/?owner=1 GET /products/?start_date=2023-01-01&end_date=2023-12-31 -
自定义筛选后端:如果你有非常复杂的筛选逻辑,
django-filter无法满足,或者你需要一种完全不同的筛选方式,例如基于请求头、自定义JSON体等,你可以创建自己的筛选后端。# myapp/filters_custom.py from rest_framework import filtersclass IsOwnerFilterBackend(filters.BaseFilterBackend):"""Filter that only allows users to see their own objects."""def filter_queryset(self, request, queryset, view):if request.user.is_authenticated:return queryset.filter(owner=request.user)return queryset.none() # 匿名用户不能看到任何产品# myapp/views.py from rest_framework import generics from .models import Product from .serializers import ProductSerializer from .filters_custom import IsOwnerFilterBackendclass ProductListOwnerFilterView(generics.ListAPIView):queryset = Product.objects.all().order_by('id')serializer_class = ProductSerializerfilter_backends = [IsOwnerFilterBackend] # 使用自定义筛选后端
你可以在 filter_backends 属性中指定多个筛选后端。它们会按顺序应用到查询集上,每个后端在前一个后端过滤的基础上继续过滤。
# myapp/views.py
from rest_framework import generics
from django_filters.rest_framework import DjangoFilterBackend
from rest_framework.filters import SearchFilter, OrderingFilter # DRF 内置的搜索和排序过滤器
from .models import Product
from .serializers import ProductSerializer
from .filters import ProductFilter # 导入 ProductFilterclass ProductListCombinedFilterView(generics.ListAPIView):queryset = Product.objects.all().order_by('id')serializer_class = ProductSerializerfilter_backends = [DjangoFilterBackend, # 允许 ?name=X, ?min_price=Y 等SearchFilter, # 允许 ?search=KeywordOrderingFilter # 允许 ?ordering=-price, ?ordering=name]filterset_class = ProductFilter # 配合 DjangoFilterBackendsearch_fields = ['name', 'description'] # SearchFilter 搜索的字段ordering_fields = ['name', 'price', 'created_at'] # OrderingFilter 排序的字段# ordering = ['-created_at'] # 默认排序