【深度学习】7. 深度卷积神经网络架构:从 ILSVRC、LeNet 到 AlexNet、ZFNet、VGGNet,含pytorch代码结构
深度卷积神经网络架构:从 ILSVRC 到 AlexNet
在2012年Alex出现之前,主要还是依赖于SVM,同时数据工程成为分类任务中很大的一个部分,对数据处理的专家依赖性高。
一、ILSVRC 与图像分类任务背景
ILSVRC 简介
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)是计算机视觉领域最具影响力的图像分类挑战之一(2010 - 2017),核心目标是推动图像分类、物体检测等算法的发展。
-
任务类型:
- 图像分类
- 物体检测
- 图像分割(后期)
-
数据规模:
- 类别数:1000
- 训练图像:120 万张
- 验证图像:5 万张
- 测试图像:15 万张
ILSVRC 的成功推动了深度卷积神经网络在视觉领域的应用。
二、分类模型的演进历程(Top-5 错误率)
| 年份 | 模型 | 错误率 | 层数 | 是否使用数据增强 | 是否使用 Dropout | 是否使用 BN |
|---|---|---|---|---|---|---|
| 2012 | AlexNet | 15.4% | 8 | ✅ | ✅ | ❌ |
| 2013 | ZFNet | 11.2% | 8 | ✅ | ✅ | ❌ |
| 2014 | GoogLeNet | 6.7% | 22 | ✅ | ❌ | ❌ |
| 2015 | ResNet | 3.57% | 152 | ✅ | ❌ | ✅ |
- 人类错误率参考值:5.1%
- 三个关键要素推动性能提升:
- 大数据(ImageNet)
- GPU 计算能力
- 算法改进(更深层结构、优化技巧)
三、CNN 早期架构回顾:LeNet
LeNet-5 架构(LeCun et al., 1998)
结构:[CONV - POOL - CONV - POOL - FC - FC]
- 卷积层(CONV):5×5 卷积核,步幅 stride = 1
- 池化层(POOL):2×2 池化核,stride = 2
- 输出层:全连接层 FC
这是最早期用于手写数字识别的神经网络之一。
四、AlexNet(Krizhevsky et al., 2012)
成绩突破
- ILSVRC2010:28.2%
- ILSVRC2011:25.8%
- ILSVRC2012:16.4%(第二名为 26.2%)
结构设计
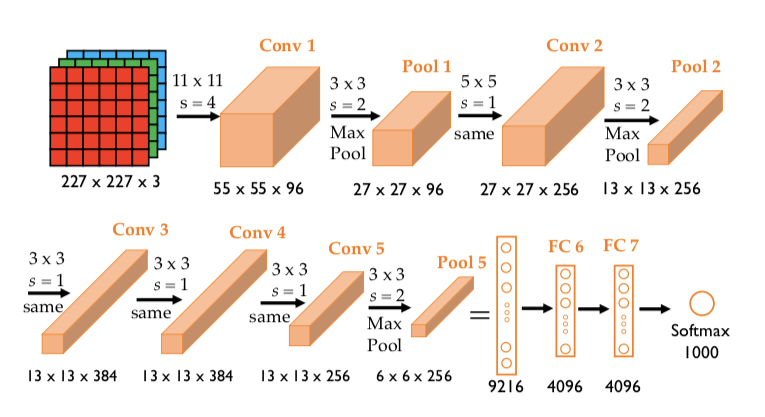
- 5 个卷积层 + 3 个全连接层
- 激活函数:ReLU(首次大规模使用)
- 核大小:
- 第一层使用 11×11 卷积核,stride = 4
- 后续使用 5×5, 3×3 卷积核
- 使用 GPU 并行:前半层在 GPU1,后半层在 GPU2
技术创新点
-
ReLU 激活函数
- 优点:
- 支持高效前向传播
- 梯度流动良好,便于反向传播
- ReLU 显著提高训练速度和非线性能力
- 缺点:
- ReLU 存在死亡问题(Dead ReLU)
- 优点:
-
数据增强:
- 随机旋转
- 图像翻转
- 平移
- 对比度增强
- 自适应直方图均衡化等
-
Dropout:
- 随机丢弃神经元以防止过拟合,训练出 2^N 个子网络的组合效果
- 通常用于全连接层,drop rate = 0.5
-
局部响应归一化(Local Response Normalization, LRN)
局部响应归一化(Local Response Normalization,LRN)是 AlexNet 中提出的一种归一化方法,其灵感来源于生物神经科学中的侧抑制机制:一个神经元的活跃会抑制邻近神经元的响应,以增强对比度、提升特征表达的稀疏性。
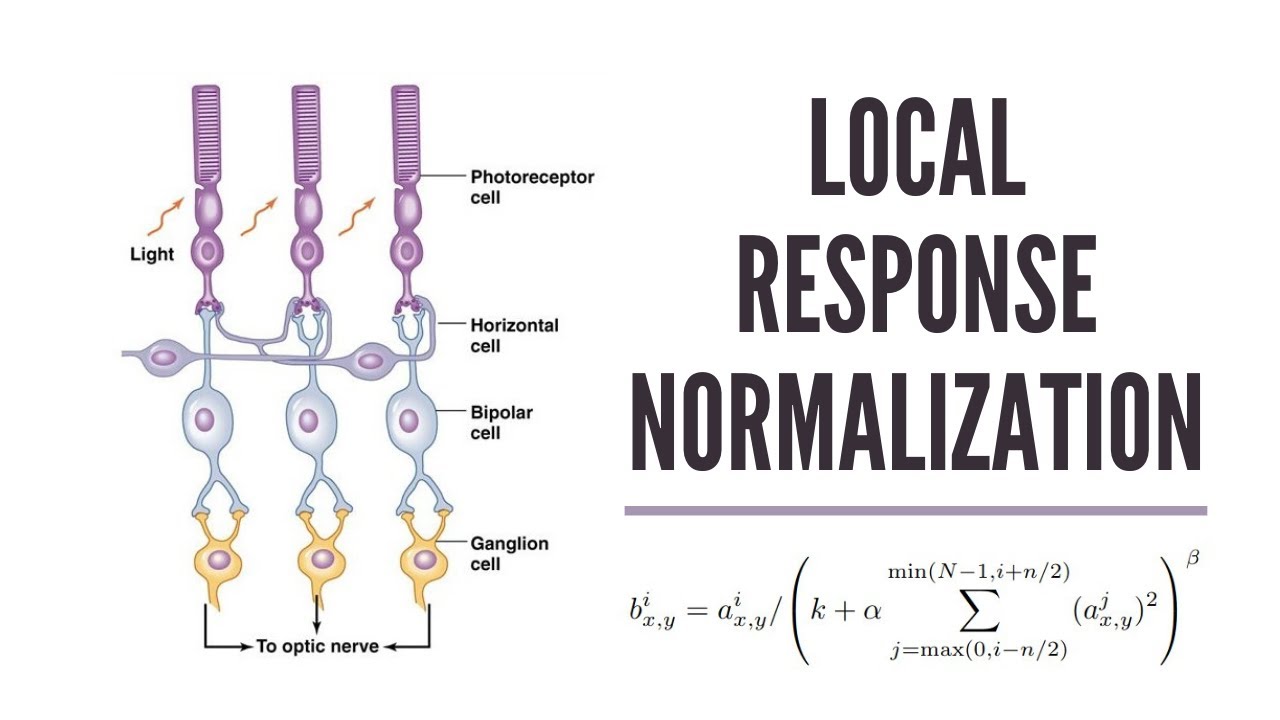
- 模拟神经抑制机制,有助于泛化能力
def manual_lrn(x, size=5, alpha=1e-4, beta=0.75, k=2.0):N, C, H, W = x.shapeout = torch.zeros_like(x)half_size = size // 2for i in range(C):# 定义通道范围start = max(0, i - half_size)end = min(C, i + half_size + 1)# 计算平方和square_sum = torch.sum(x[:, start:end, :, :] ** 2, dim=1, keepdim=True)# 归一化公式denom = (k + alpha * square_sum) ** betaout[:, i:i+1, :, :] = x[:, i:i+1, :, :] / denomreturn out -
重叠池化(Overlapping Pooling)
-
池化核大小 > stride,例如:
- 池化核:3×3,stride:2
- 避免信息过早丢失
-
优于传统非重叠池化(如 2×2,stride=2)
Strandard pooling: Pooling stride = Pooling kernel size
-
AlexNet 的成功标志着深度 CNN 的兴起,但也暴露出如卷积核大小过大、参数量庞大、计算资源消耗高等问题。
Pytorch结构实现
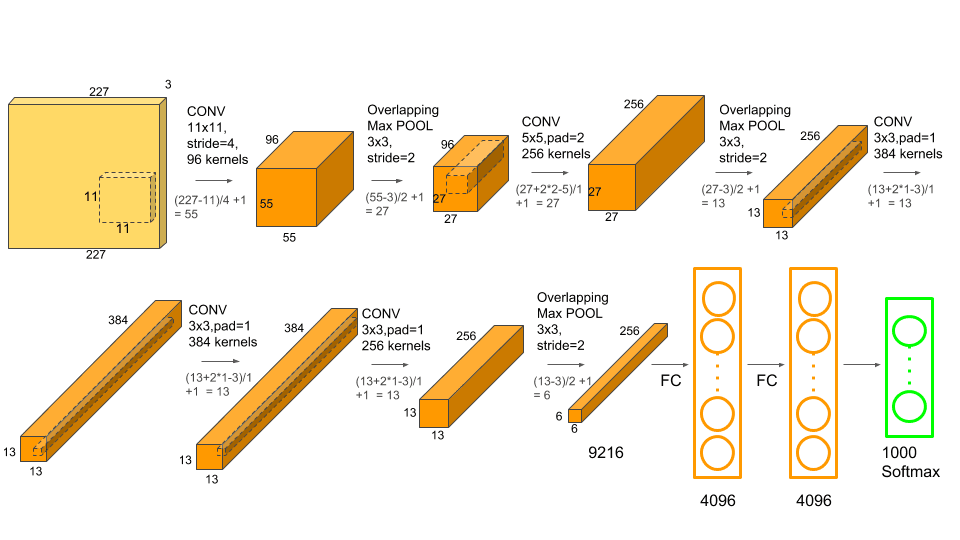
卷积输出尺寸计算公式:
输出尺寸 = ⌊ W − K + 2 P S ⌋ + 1 {输出尺寸} = \left\lfloor \frac{W - K + 2P}{S} \right\rfloor + 1 输出尺寸=⌊SW−K+2P⌋+1
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4)
用 96 个卷积核来扫描输入图像。 AlexNet 的 Conv1 层输出通道数是 96,因为它使用了 96 个 11×11×3 的卷积核,每个核对应输出一个 55×55 的特征图,组合起来就是 96×55×55
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()# Feature extraction 部分(对应 Conv1 ~ Pool5)self.features = nn.Sequential(# Conv1: 11x11, stride=4, padding=0 -> 输出: 96 x 55 x 55nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),nn.ReLU(inplace=True),# Pool1: 3x3, stride=2 -> 输出: 96 x 27 x 27nn.MaxPool2d(kernel_size=3, stride=2),# Conv2: 5x5, stride=1, padding=2 -> 输出: 256 x 27 x 27nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),nn.ReLU(inplace=True),# Pool2: 3x3, stride=2 -> 输出: 256 x 13 x 13nn.MaxPool2d(kernel_size=3, stride=2),# Conv3: 3x3, stride=1, padding=1 -> 输出: 384 x 13 x 13nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),# Conv4: 3x3, stride=1, padding=1 -> 输出: 384 x 13 x 13nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),# Conv5: 3x3, stride=1, padding=1 -> 输出: 256 x 13 x 13nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),# Pool5: 3x3, stride=2 -> 输出: 256 x 6 x 6nn.MaxPool2d(kernel_size=3, stride=2),)# 分类器部分(对应 FC6 ~ FC8)self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(256 * 6 * 6, 4096), # Flatten: 256×6×6 = 9216nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes) # 输出为1000类)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1) # 展平为 batch × 9216x = self.classifier(x)return x# 示例运行
if __name__ == "__main__":model = AlexNet(num_classes=1000)input_tensor = torch.randn(1, 3, 227, 227) # 输入大小与图一致output = model(input_tensor)print("输出 shape:", output.shape) # 应为 [1, 1000]五、ZFNet 改进
ZFNet(Zeiler and Fergus, 2013)是在 AlexNet 基础上的改进型卷积神经网络,主要优化了第一层卷积的核大小和步幅,并引入了卷积神经网络的可视化方法(Deconvolutional Network),使网络结构更加合理且更具可解释性。
核心结构变化
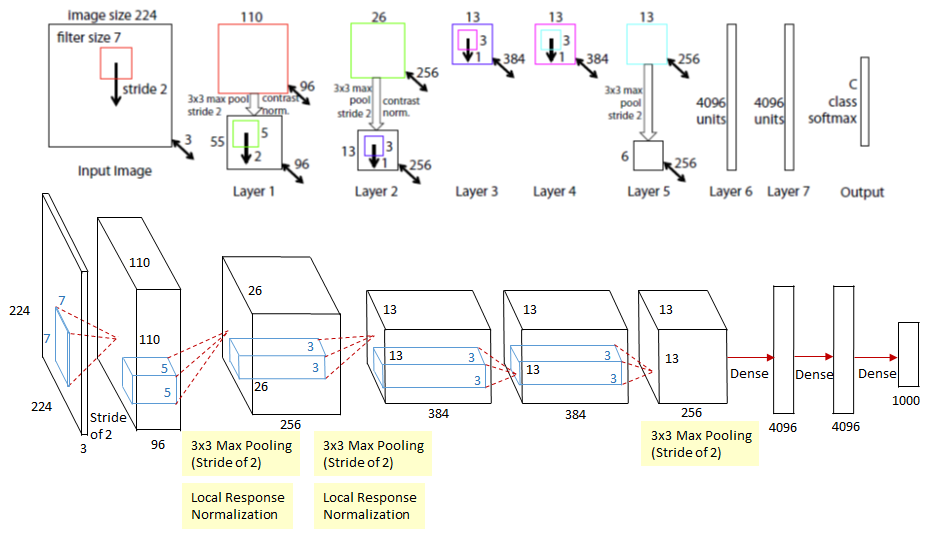
ZFNet 将第一层的卷积核从 11×11 改为更小的 7×7,同时将步幅从 4 减小为 2,从而保留了更多的空间细节,减缓了特征图分辨率下降的速度。
| 模型 | 第一层卷积核 | 步幅 | Conv1 输出尺寸 | Top-5 错误率 |
|---|---|---|---|---|
| AlexNet | 11×11 | 4 | 55×55 | 16.4% |
| ZFNet | 7×7 | 2 | 110×110 | 11.7% |
更小的卷积核与更慢的步幅配合使用,使网络能够感知更细粒度的图像信息,提升了分类精度。
网络结构概览
ZFNet 与 AlexNet 在整体结构上保持一致,包含 5 个卷积层和 3 个全连接层,但第一层卷积参数不同。
可视化贡献:反卷积网络(DeconvNet)
ZFNet 的重要贡献之一是提出了 Deconvolutional Network(反卷积网络)方法,用于分析和可视化 CNN 的内部工作机制。通过将某一神经元的激活反投影回输入图像空间,研究者能够观察到网络到底在“看哪里”。
该方法过程包括:
- 选择某层的强激活区域,抑制其他位置
- 通过反卷积和反池化操作逐层还原
- 显示出该神经元最关注的原始图像区域
这种可视化揭示了 AlexNet 中由于卷积核过大、步幅过快导致的信息丢失,从而指导了 ZFNet 的结构改进。
Pytorch 实现
import torch
import torch.nn as nnclass ZFNet(nn.Module):def __init__(self, num_classes=1000):super(ZFNet, self).__init__()self.features = nn.Sequential(# Conv1: 7x7 kernel, stride=2, padding=1 → Output: 96x110x110nn.Conv2d(3, 96, kernel_size=7, stride=2, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Output: 96x54x54# Conv2: 5x5, padding=2 → Output: 256x54x54nn.Conv2d(96, 256, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Output: 256x26x26# Conv3: 3x3, padding=1nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),# Conv4: 3x3, padding=1nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),# Conv5: 3x3, padding=1nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Output: 256x12x12)self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(256 * 12 * 12, 4096),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1) # Flattenx = self.classifier(x)return x# 示例运行
if __name__ == "__main__":model = ZFNet(num_classes=1000)dummy_input = torch.randn(1, 3, 224, 224) # 与 ImageNet 尺寸一致output = model(dummy_input)print("Output shape:", output.shape) # 应为 [1, 1000]
六、VGGNet 结构
VGGNet(Simonyan and Zisserman, 2014)是深度卷积网络发展的重要里程碑,其主要设计思想是用统一的小卷积核(3×3)和最大池化(2×2)层,堆叠出一个非常深但结构规则的网络架构。它不仅在 ImageNet 挑战中取得了优异成绩,还广泛应用于后续各类视觉任务。
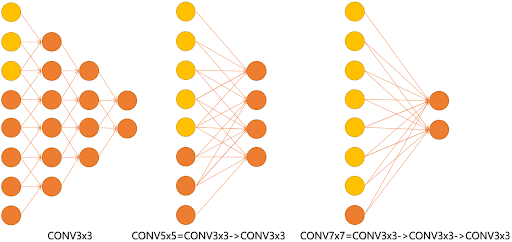
统一小卷积核设计
VGGNet 放弃了之前 AlexNet 和 ZFNet 中使用的大卷积核(如 11×11、7×7),转而采用大量 3×3 卷积核的堆叠构建特征提取层。
这种设计的优势包括:
- 两个连续的 3×3 卷积层相当于一个 5×5 卷积(感受野扩大)
- 三个连续的 3×3 卷积层相当于一个 7×7 卷积
- 多层堆叠带来更多非线性、参数更少、表达能力更强
层数对比与模型变体
VGGNet 系列包括多个深度版本,主要有:
- VGG-11、VGG-13、VGG-16、VGG-19
- 常用版本为 VGG-16 和 VGG-19(数字表示层数)
其中:
- AlexNet:8 层(5 conv + 3 fc)
- VGG-16:13 个卷积层 + 3 个全连接层
- VGG-19:16 个卷积层 + 3 个全连接层
卷积层数量显著增加,深度带来了更强的表达能力。
网络结构组成
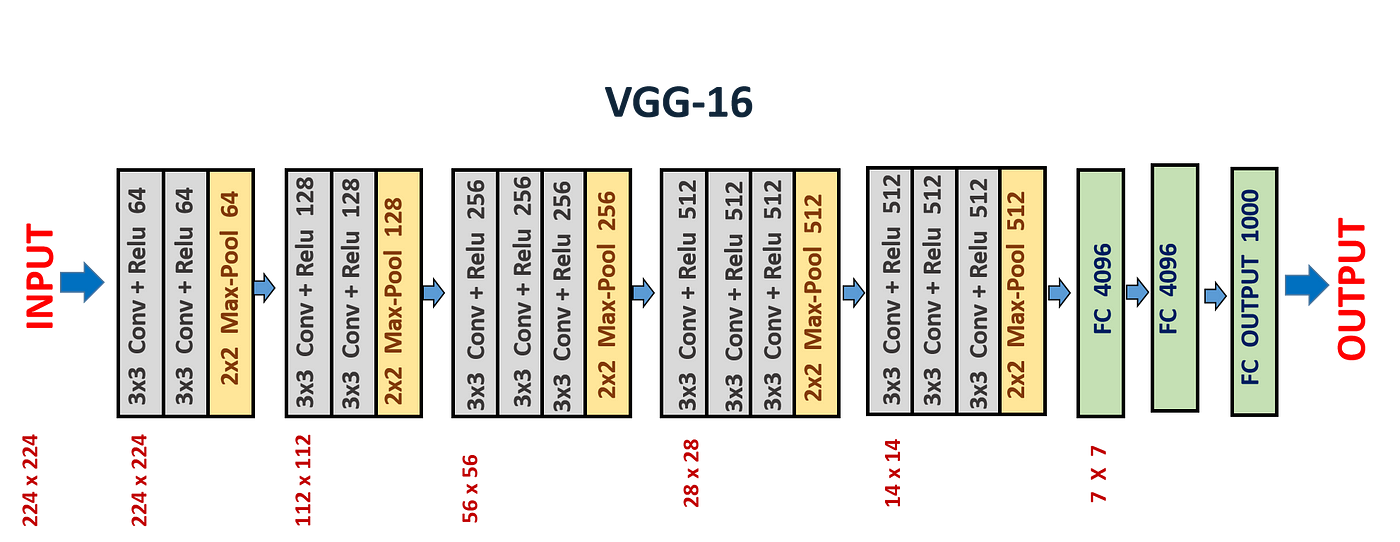
VGGNet 的典型结构如下(以 VGG-16 为例):
- 输入图像大小:224 × 224 × 3
- 卷积核:全部为 3 × 3,stride = 1,padding = 1
- 池化层:2 × 2 最大池化,stride = 2
- 激活函数:ReLU
- 最终全连接层:4096 → 4096 → 1000
整体结构是:
为什么小卷积核更好?
VGGNet 强调多个小卷积核堆叠而不是大卷积核的原因包括:
- 更深层数提供更多非线性变换,提高网络表达力
- 更少参数:3×3 比 5×5、7×7 参数更少,便于训练
- 更易堆叠、结构更统一,适合硬件优化和迁移使用
迁移性与通用性
VGGNet 特别有代表性的一点是:
- 中间层(如 FC7 或 Conv5-3)提取的特征在其他任务上也很有效
- 广泛用于图像检索、物体检测、风格迁移等下游任务
这种“可迁移的中层特征”概念,为后来 ResNet、FPN 等模型的模块化设计打下基础。
Pytorch
import torch
import torch.nn as nnclass VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()self.features = nn.Sequential(# Block 1nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 2nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 3nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 4nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 5nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1) # Flattenx = self.classifier(x)return x# 示例运行
if __name__ == "__main__":model = VGG16(num_classes=1000)x = torch.randn(1, 3, 224, 224) # 输入图像大小为 224×224×3out = model(x)print("Output shape:", out.shape) # 应为 [1, 1000]