得物Java开发面试题及参考答案(下)
UUID 和分布式雪花算法(Snowflake)作为主键各有什么优缺点?
在分布式系统中,主键生成需满足唯一性、高并发性能、有序性及跨系统兼容性等要求。UUID 和雪花算法是两种常用方案,其优缺点对比如下:
UUID(通用唯一识别码)
核心原理:通过 MAC 地址、时间戳、随机数等要素生成 128 位字符串(如550e8400-e29b-41d4-a716-446655440000),保证全局唯一性。
优点:
- 完全分布式:无需中心化节点,本地生成,避免分布式协调开销,适合多数据中心场景。
- 高可用性:生成过程无网络依赖,抗网络分区能力强。
- 唯一性强:理论上重复概率极低(约 2^128 分之一),可视为全局唯一。
缺点:
- 无序性:UUID 是随机字符串,插入数据库时会导致聚簇索引(如 InnoDB 的主键索引)频繁页分裂,影响写入性能。例如,在 InnoDB 中,主键值无序会导致数据写入时不断移动磁盘块,降低写入效率。
- 存储空间大:128 位 UUID 通常以 36 字符的字符串存储(如包含连字符),占用字节数是自增 ID 的 3-4 倍(如 BIGINT 占 8 字节,UUID 字符串占 36 字节),增加索引和数据存储成本。
- 不具备业务含义:纯随机字符串,无法从中解析出时间、地域等信息,不利于业务追溯和监控。
适用场景:
- 分布式系统中无需排序的唯一标识(如日志 ID、临时文件 ID)。
- 多数据源合并场景(如不同数据库的数据需合并,UUID 可避免主键冲突)。
雪花算法(Snowflake)
核心原理:由 Twitter 开源,生成 64 位整数,结构如下:
1位符号位(固定0) + 41位时间戳(毫秒级,支持约69年) + 10位工作机器ID(可划分1024个节点) + 12位序列号(单节点每毫秒生成4096个ID)
优点:
- 有序性:时间戳部分保证 ID 按生成顺序递增,插入数据库时聚簇索引友好,减少页分裂,提升写入性能。
- 高性能:纯内存计算,无网络 IO,单节点每秒可生成数百万 ID,适合高并发场景。
- 可解析性:通过 ID 可反推出生成时间、机器节点等信息,便于故障定位和业务统计。
- 灵活性:可自定义工作机器 ID 的分配策略(如按数据中心、机房、进程等划分),适应复杂的分布式架构。
缺点:
- 依赖时钟同步:若节点时钟回退(如系统时间调整、硬件故障),可能生成重复 ID。需通过时钟监控、回退补偿(如等待至超过最后时间戳或增加序列号偏移)等机制解决。
- 中心化管理:工作机器 ID 需全局唯一,通常需要集中式服务(如 Zookeeper、数据库)分配,存在单点故障风险(可通过预分配号段本地生成缓解)。
- 数据迁移成本:若扩展工作机器 ID 的位数(如从 10 位增至 12 位),需修改生成逻辑并兼容旧 ID。
适用场景:
- 高并发交易系统的主键(如订单 ID、用户 ID),需保证写入性能和有序性。
- 对 ID 有业务追溯需求的场景(如通过 ID 分析请求的时间分布)。
对比总结
| 维度 | UUID | 雪花算法 |
|---|---|---|
| 唯一性 | 理论上绝对唯一,无重复风险 | 需处理时钟回退,否则可能重复 |
| 有序性 | 完全无序,不利于索引优化 | 时间戳有序,适合聚簇索引 |
| 性能 | 本地生成,无竞争,适合高并发读 | 高并发写入性能优异,需处理时钟同步 |
| 存储成本 | 字符串存储,占用空间大 | 64 位长整型,存储效率高 |
| 业务含义 | 无 | 包含时间、节点信息,可追溯 |
| 分布式依赖 | 无 | 需要时钟同步和机器 ID 管理 |
选择建议:
- 若业务需高写入性能、有序性及可追溯性,优先选择雪花算法(如电商订单系统)。
- 若业务强调分布式独立性、低耦合(如微服务间的消息 ID),或存在多源数据合并需求,可选择 UUID。
- 对于极端场景(如全球分布式、无中心节点的系统),可考虑结合两者优势,如使用 UUID 作为外层标识,雪花算法作为内层业务主键。
如何在数据库中保证插入数据的唯一性(如两条 INSERT 语句避免重复)?
在数据库中保证插入数据的唯一性需结合业务场景,从约束定义、事务控制和应用层逻辑多维度实现。以下是常见解决方案:
一、数据库层约束
通过数据库内置的唯一性约束或索引,在写入时自动阻止重复数据,这是最直接且可靠的方式。
-
唯一索引(Unique Index)
- 在表的字段或字段组合上创建唯一索引,数据库会在插入或更新时检查索引值是否重复。
- 示例:
CREATE TABLE user ( id BIGINT PRIMARY KEY AUTO_INCREMENT, email VARCHAR(100) NOT NULL, UNIQUE KEY uk_email (email) -- 邮箱字段唯一索引 );
当两条 INSERT 语句尝试插入相同邮箱时,第二条会触发唯一约束冲突,数据库返回错误(如 MySQL 的1062 Duplicate entry)。 - 优点:原子性强,完全由数据库保证,无需应用层额外逻辑。
- 缺点:并发场景下可能出现锁竞争(如乐观锁失效时转为悲观锁),影响性能;需处理约束冲突异常(如重试或提示用户)。
-
主键约束(Primary Key)
- 主键字段自动隐含唯一且非空约束,适合自增 ID 或业务唯一标识(如用户 ID)。
- 若业务主键为组合字段(如订单号 + 商品 ID),可创建联合主键:
CREATE TABLE order_item ( order_id BIGINT NOT NULL, product_id BIGINT NOT NULL, quantity INT NOT NULL, PRIMARY KEY (order_id, product_id) -- 联合主键保证唯一 );
-
分布式唯一约束(跨实例场景)
- 若数据库为分库分表架构,唯一索引仅在单个库表内有效。此时需通过以下方式实现全局唯一:
- 分布式锁:插入前通过 Redis 等中间件获取全局锁,确保同一数据仅被一个事务操作。
- 全局唯一 ID 生成器:如雪花算法生成唯一 ID 作为业务主键,避免重复。
- 若数据库为分库分表架构,唯一索引仅在单个库表内有效。此时需通过以下方式实现全局唯一:
二、事务控制与冲突处理
在高并发场景下,需结合事务和异常处理机制,确保唯一性约束的原子性。
-
使用
INSERT ... ON DUPLICATE KEY UPDATE(MySQL)- 插入数据时,若触发唯一索引冲突,则执行更新操作而非报错。
- 示例:
INSERT INTO user (email, name) VALUES ('test@example.com', 'Alice') ON DUPLICATE KEY UPDATE name = 'Alice'; -- 若邮箱已存在,更新name字段 - 适用场景:需要 upsert(插入或更新)操作的业务,如用户信息更新。
-
乐观锁(Optimistic Locking)
- 通过版本号(version)或时间戳(timestamp)字段实现,插入前检查数据是否已被修改。
- 步骤:
- 查询数据时获取版本号
v=1; - 插入或更新时附带条件
WHERE version = v; - 若版本号不一致,说明数据已被修改,放弃操作或重试。
- 查询数据时获取版本号
- 示例(更新场景):
UPDATE user SET name = 'Bob', version = 2 WHERE email = 'test@example.com' AND version = 1;
-
悲观锁(Pessimistic Locking)
- 通过
SELECT ... FOR UPDATE语句在查询时加排他锁,确保当前事务操作期间数据不被其他事务修改。 - 注意:锁范围需精准(如通过索引命中行锁),避免锁升级为表锁影响性能。
- 通过
三、应用层逻辑控制
数据库层约束是保底手段,但某些场景需在应用层提前过滤重复请求,减少数据库压力。
-
请求去重
- 对前端重复提交(如按钮快速点击),通过令牌(Token)机制确保同一请求仅被处理一次:
- 客户端请求时生成唯一 Token,存入浏览器缓存;
- 服务端接收请求时校验 Token(如存入 Redis,设置短时效),重复 Token 的请求直接拒绝。
- 示例代码(伪代码):
boolean validateToken(String token) { return redis.setIfAbsent("token:" + token, "1", 5, TimeUnit.SECONDS); }
- 对前端重复提交(如按钮快速点击),通过令牌(Token)机制确保同一请求仅被处理一次:
-
异步消息去重
- 在消息队列消费场景中,通过消息 ID 或业务唯一标识(如订单号)判断是否已处理过消息,避免重复消费。
- 可将已处理的消息 ID 存入 Redis(设置过期时间),消费前先查询缓存。
-
批量插入去重
- 处理批量数据时(如 Excel 导入),先在应用层过滤重复记录,再执行批量插入,减少数据库约束冲突次数。
四、特殊场景处理
-
跨库唯一约束
- 分库分表场景下,若需全局唯一(如用户邮箱在所有分库中唯一),可:
- 使用全局索引服务(如 Elasticsearch 维护唯一字段索引);
- 通过中间件(如 ShardingSphere)配置全局唯一约束,路由至所有相关库表检查。
- 分库分表场景下,若需全局唯一(如用户邮箱在所有分库中唯一),可:
-
高并发下的性能优化
- 唯一索引的争用可能成为瓶颈(如同一索引值被大量请求竞争),可通过以下方式缓解:
- 延迟唯一性检查:先标记数据为 “处理中”,异步执行唯一性校验(需容忍短暂不一致,适合最终一致性场景);
- 哈希分桶:将唯一字段哈希后分桶存储(如
email_hash = hash(email) % 1024),分散索引压力。
- 唯一索引的争用可能成为瓶颈(如同一索引值被大量请求竞争),可通过以下方式缓解:
深分页问题如何解决?当查询一亿条数据中的特定 3000 条时,有哪些优化策略?
深分页(如SELECT * FROM table LIMIT 1000000, 3000)在数据量庞大时会导致性能急剧下降,因为数据库需扫描前 1003000 条记录,仅返回最后 3000 条,效率极低。以下是针对深分页的优化策略,结合不同场景选择合适方案:
一、深分页性能问题根源
以 MySQL 为例,LIMIT offset, size的实现原理是先定位到offset行,再向后读取size行。当offset较大时:
- 索引失效:若查询未使用索引,全表扫描成本随
offset增大呈线性增长; - 索引回表成本高:即使使用索引,也需先扫描索引树定位到
offset行的主键,再回表查询完整数据,offset越大,回表次数越多。
二、优化策略
1. 利用索引覆盖查询(Index Covering Query)
若查询仅需部分字段,可通过覆盖索引避免回表,减少 IO 开销。
示例:
表结构:
CREATE TABLE orders ( id BIGINT PRIMARY KEY AUTO_INCREMENT, user_id BIGINT, order_time TIMESTAMP, status VARCHAR(20), INDEX idx_user_time (user_id, order_time) -- 包含查询所需字段的联合索引
);
查询语句(需user_id和order_time字段):
SELECT user_id, order_time FROM orders
WHERE user_id = 123
ORDER BY order_time DESC
LIMIT 1000000, 3000;
原理:联合索引idx_user_time已包含user_id和order_time,无需回表查询主键,直接从索引树中获取数据,提升扫描效率。
2. 基于书签记录上次查询位置(Keyset Pagination)
通过记录上一页最后一条数据的索引值,下一页查询时从该值之后开始扫描,避免重复扫描前offset条数据。
步骤:
- 第一页查询(假设按
order_time降序排列):SELECT id, user_id, order_time FROM orders WHERE user_id = 123 ORDER BY order_time DESC LIMIT 3000;
记录最后一条数据的order_time为last_time,id为last_id(用于处理相同时间戳的记录)。 - 下一页查询:
SELECT id, user_id, order_time FROM orders WHERE user_id = 123 AND (order_time < last_time OR (order_time = last_time AND id < last_id)) ORDER BY order_time DESC LIMIT 3000;
优点:查询条件基于索引字段,扫描范围固定为 3000 条左右,性能稳定,不随页码递增而下降。
适用场景:支持排序字段单调递增 / 递减的场景(如时间、自增 ID)。
3. 预计算分页总数(减少COUNT(*)开销)
若业务需要展示总页数,深分页时COUNT(*)会触发全表扫描。可通过以下方式优化:
- 缓存总数:定期更新总记录数到 Redis,查询时直接读取缓存,适用于数据更新不频繁的场景。
- 分桶统计:按日期或范围将数据分桶(如按年 / 月分区),查询时先确定桶范围,再统计各桶内记录数,减少扫描范围。
4. 延迟关联(Deferred Join)
先通过索引获取主键列表,再批量回表查询数据,减少回表次数。
MySQL 示例:
-- 传统方式:先扫描索引,再回表1003000次
SELECT o.* FROM orders o
JOIN (SELECT id FROM orders WHERE user_id = 123 ORDER BY order_time DESC LIMIT 1000000, 3000) AS t
ON o.id = t.id; -- 优化方式:先获取主键,再回表3000次
SELECT o.* FROM orders o
WHERE o.id IN ( SELECT id FROM orders WHERE user_id = 123 ORDER BY order_time DESC LIMIT 1000000, 3000
);
注意:IN子查询的性能取决于主键数量,3000 条以内效果较好,超过需结合其他方式。
5. 搜索引擎(如 Elasticsearch)
对于海量数据的复杂查询(如多条件排序、全文搜索),使用 ES 等专业搜索引擎更高效。ES 通过倒排索引和分片机制,支持快速分页和聚合查询。
示例:
{ "query": { "bool": { "filter": { "term": { "user_id": 123 } } } }, "sort": [{"order_time": "desc"}], "from": 1000000, "size": 3000
}
注意:ES 的from + size上限默认是 10000,可通过index.max_result_window调整,但深分页仍存在性能问题,需结合滚动查询(Scroll API)或 Keyset Pagination。
6. 物理分页与业务限制
- 限制分页深度:在 UI 层隐藏深分页按钮,引导用户通过筛选条件(如时间范围、分类)缩小查询范围。
- 分批加载:将一次性查询改为多次小批量查询,如每次加载 1000 条,前端通过滚动条触发后续请求(需前端配合)。
三、亿级数据下的特定场景优化(查询第 N 页 3000 条)
假设表结构为orders(id, user_id, order_time, ...),数据量 1 亿条,需查询user_id=123的第 1000 页(每页 3000 条,offset=2997000):
- 确保索引优化:
- 创建联合索引
(user_id, order_time, id),覆盖查询条件和排序字段,避免回表。
- 创建联合索引
- 采用 Keyset Pagination:
- 首次查询记录最后一条的
order_time和id,后续查询通过这两个字段过滤,确保每次扫描约 3000 条索引记录。
- 首次查询记录最后一条的
- 分库分表:
- 若单表数据量过大,按
user_id分库或按order_time分表,将数据分散到多个实例,减少单库扫描压力。
- 若单表数据量过大,按
- 异步预处理:
- 对高频查询的深分页结果,提前异步生成并缓存(如每天凌晨生成前 1000 页的数据),查询时直接返回缓存结果。
四、避免深分页的设计原则
- 业务层面:减少对深分页的需求,引导用户使用筛选、搜索等更高效的查询方式。
- 技术层面:优先使用索引覆盖和 Keyset Pagination,避免
LIMIT offset, size的原生用法;对于必须支持深分页的场景,结合搜索引擎或分库分表架构。
你熟悉哪些 Java 开源框架?请举例说明 ORM 框架的使用场景。
Java 生态中开源框架众多,常见的有 Spring 全家桶(Spring Framework、Spring Boot、Spring Cloud)、MyBatis(数据持久化)、Hibernate(ORM 框架)、Netty(网络编程)、Apache Kafka(消息队列)、Elasticsearch(搜索引擎)等。其中,ORM(对象关系映射)框架通过将数据库表与 Java 对象映射,简化了数据库操作,提升开发效率。
ORM 框架的典型使用场景:
-
快速开发 CRUD 应用
- 在企业级管理系统(如 ERP、CRM)中,ORM 框架可自动生成 SQL,减少手动编写 CRUD 代码的工作量。例如,使用 Spring Data JPA(基于 Hibernate)时,只需定义接口并继承
JpaRepository,即可获得基础的增删改查方法:public interface UserRepository extends JpaRepository<User, Long> { // 无需实现,Spring Data JPA 自动生成 SQL } - 应用场景:用户管理模块、订单管理系统等,开发效率可提升 30% 以上。
- 在企业级管理系统(如 ERP、CRM)中,ORM 框架可自动生成 SQL,减少手动编写 CRUD 代码的工作量。例如,使用 Spring Data JPA(基于 Hibernate)时,只需定义接口并继承
-
复杂对象关系映射
- 当业务模型包含复杂关联(如一对多、多对多)时,ORM 框架通过注解或 XML 配置简化映射逻辑。例如,使用 Hibernate 映射用户与订单的关系:
@Entity public class User { @OneToMany(mappedBy = "user", cascade = CascadeType.ALL) private List<Order> orders; } @Entity public class Order { @ManyToOne @JoinColumn(name = "user_id") private User user; } - 应用场景:社交平台用户关系、电商商品分类等,避免手动编写 JOIN 语句。
- 当业务模型包含复杂关联(如一对多、多对多)时,ORM 框架通过注解或 XML 配置简化映射逻辑。例如,使用 Hibernate 映射用户与订单的关系:
-
跨数据库兼容
- ORM 框架通过方言(Dialect)机制屏蔽不同数据库的差异,支持无缝切换数据库。例如,使用 MyBatis 时,通过配置不同的数据库方言,可同时支持 MySQL 和 PostgreSQL:
<!-- mybatis-config.xml --> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> </dataSource> </environment> </environments> - 应用场景:跨国企业系统需支持多种数据库,或项目初期选择轻量级数据库(如 H2),后期迁移至生产数据库(如 Oracle)。
- ORM 框架通过方言(Dialect)机制屏蔽不同数据库的差异,支持无缝切换数据库。例如,使用 MyBatis 时,通过配置不同的数据库方言,可同时支持 MySQL 和 PostgreSQL:
-
缓存优化
- 部分 ORM 框架(如 Hibernate)内置多级缓存,减少数据库访问。例如,配置 Hibernate 的二级缓存后,重复查询相同数据时直接从缓存获取:
<!-- hibernate.cfg.xml --> <property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property> - 应用场景:读多写少的系统(如新闻网站、商品详情页),缓存命中率可达 80% 以上。
- 部分 ORM 框架(如 Hibernate)内置多级缓存,减少数据库访问。例如,配置 Hibernate 的二级缓存后,重复查询相同数据时直接从缓存获取:
-
与 Spring 集成简化事务管理
- ORM 框架与 Spring 集成后,通过
@Transactional注解声明式管理事务,降低代码耦合。例如:@Service public class UserService { @Autowired private UserRepository userRepository; @Transactional public void transferMoney(Long fromUserId, Long toUserId, BigDecimal amount) { User fromUser = userRepository.findById(fromUserId).orElseThrow(); User toUser = userRepository.findById(toUserId).orElseThrow(); fromUser.setBalance(fromUser.getBalance().subtract(amount)); toUser.setBalance(toUser.getBalance().add(amount)); userRepository.save(fromUser); userRepository.save(toUser); } } - 应用场景:金融系统转账、库存扣减等需要强一致性的操作。
- ORM 框架与 Spring 集成后,通过
ORM 框架的局限性与注意事项:
- 复杂 SQL 性能问题:ORM 自动生成的 SQL 在处理复杂查询(如多表 JOIN、子查询)时可能不够优化,需结合原生 SQL 或自定义查询。
- 延迟加载陷阱:在懒加载模式下,可能触发 N+1 查询问题(主查询 1 次,关联查询 N 次),需通过
FetchType.EAGER或批量抓取优化。 - 过度依赖导致灵活性降低:过度使用 ORM 可能掩盖数据库底层特性(如存储过程、函数),需根据场景权衡。
总结:ORM 框架适用于快速开发、对象关系复杂、跨数据库兼容的场景,可显著提升开发效率。但在性能敏感、SQL 复杂度高的场景下,需谨慎使用或结合原生 SQL 优化。
Spring 的 IoC 和 AOP 原理是什么?@Autowired 和 @Resource 注解的区别是什么?如何通过 @Autowired 实现按名称注入?
IoC(控制反转)原理:
IoC 是 Spring 的核心特性之一,通过将对象的创建和依赖关系管理交给容器,实现解耦。其核心机制包括:
- BeanFactory:Spring 的基础容器,负责实例化、配置和管理 Bean。通过读取配置元数据(XML、注解或 Java 配置),动态创建对象并注入依赖。
- ApplicationContext:BeanFactory 的子接口,扩展了国际化、事件传播、资源加载等功能,是更高级的容器实现。
- 依赖注入(DI):IoC 的具体实现方式,通过构造器注入、Setter 注入或字段注入,将依赖对象动态注入到目标对象中。
示例:
// 服务接口
public interface UserService { void createUser(String username);
} // 服务实现
@Service
public class UserServiceImpl implements UserService { @Autowired private UserRepository userRepository; // 依赖注入 @Override public void createUser(String username) { userRepository.save(new User(username)); }
}
原理流程:
- Spring 容器启动时,扫描
@Component、@Service等注解,生成 BeanDefinition 元数据。 - 根据 BeanDefinition 创建 Bean 实例,并通过反射注入依赖(如
userRepository)。 - Bean 生命周期管理(初始化、销毁回调)由容器自动处理。
AOP(面向切面编程)原理:
AOP 通过代理模式实现横切关注点(如日志、事务、权限)与业务逻辑的分离。核心机制包括:
- 切面(Aspect):包含通知(Advice)和切点(Pointcut)的模块,定义横切逻辑。
- 通知(Advice):在目标方法前后执行的代码,包括前置通知(Before)、后置通知(After)、环绕通知(Around)等。
- 切点(Pointcut):定义哪些方法需要被增强的表达式,如
execution(* com.example.service.*.*(..))。 - 代理(Proxy):Spring 通过 JDK 动态代理(接口代理)或 CGLIB 代理(类代理)生成增强后的对象。
示例:
@Aspect
@Component
public class LoggingAspect { @Before("execution(* com.example.service.*.*(..))") public void logBefore(JoinPoint joinPoint) { System.out.println("Before method: " + joinPoint.getSignature().getName()); }
}
原理流程:
- Spring 容器检测到
@Aspect注解的 Bean 时,创建 Advisor(包含 Advice 和 Pointcut)。 - 目标对象创建时,根据 Advisor 判断是否需要代理。若需要,则生成代理对象。
- 调用代理对象方法时,触发 Advice 逻辑,再执行目标方法。
@Autowired 与 @Resource 的区别:
| 对比项 | @Autowired | @Resource |
|---|---|---|
| 所属规范 | Spring 框架 | JSR-250(Java 标准) |
| 依赖查找顺序 | 类型(Type)优先,若存在多个同类型 Bean,需配合 @Qualifier 指定名称 | 名称(Name)优先,通过 name 属性指定;若未指定,则使用字段名或方法名 |
| 参数 | 支持 required 属性(默认 true,找不到依赖时抛异常) | 支持 name 和 type 属性,用于精确匹配 |
| 使用场景 | Spring 项目中推荐使用 | 跨框架项目(需兼容 Java EE 标准) |
通过 @Autowired 实现按名称注入:
- 使用 @Qualifier 注解:
@Service public class OrderService { @Autowired @Qualifier("paypalPaymentProcessor") // 指定 Bean 名称 private PaymentProcessor paymentProcessor; } @Component("paypalPaymentProcessor") public class PaypalPaymentProcessor implements PaymentProcessor { // 实现逻辑 } - 字段名与 Bean 名称一致:
@Service public class OrderService { @Autowired private PaymentProcessor paypalPaymentProcessor; // 字段名与 Bean 名称匹配 } - 构造器注入时指定名称:
@Service public class OrderService { private final PaymentProcessor paymentProcessor; @Autowired public OrderService(@Qualifier("paypalPaymentProcessor") PaymentProcessor paymentProcessor) { this.paymentProcessor = paymentProcessor; } }
总结:IoC 通过容器管理对象生命周期和依赖关系,实现解耦;AOP 通过代理增强目标方法,实现横切逻辑复用。@Autowired 与 @Resource 的主要区别在于依赖查找顺序,按名称注入可通过 @Qualifier 或字段名匹配实现。
Spring Boot 的自动装配原理是什么?
Spring Boot 的自动装配是其核心特性之一,通过 “约定大于配置” 的理念,减少手动配置,提升开发效率。其原理基于以下机制:
1. 启动类与 @SpringBootApplication 注解
Spring Boot 应用通过 @SpringBootApplication 注解标记主类,该注解是一个组合注解,包含:
@SpringBootConfiguration:等同于@Configuration,声明当前类是配置类。@EnableAutoConfiguration:启用自动装配机制。@ComponentScan:扫描@Component、@Service等注解标记的类,注册为 Bean。
2. @EnableAutoConfiguration 注解的核心作用
该注解通过 @Import(AutoConfigurationImportSelector.class) 导入自动配置类,核心流程如下:
- 读取 META-INF/spring.factories:
Spring Boot 在启动时会扫描所有依赖 jar 包中的META-INF/spring.factories文件,从中读取EnableAutoConfiguration对应的配置类列表。例如:org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration,\ org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration,\ ... - 条件过滤(@Conditional 注解):
自动配置类通过@Conditional系列注解(如@ConditionalOnClass、@ConditionalOnMissingBean)进行条件判断,仅在满足条件时生效。例如:@Configuration @ConditionalOnClass(DataSource.class) // 当类路径存在 DataSource 类时生效 public class DataSourceAutoConfiguration { // 配置逻辑 } - 加载生效的配置类:
经过条件过滤后,符合条件的配置类被加载,向容器中注册 Bean。
3. 条件注解的类型与作用
Spring Boot 提供多种条件注解,控制自动配置的生效时机:
@ConditionalOnClass:类路径中存在指定类时生效。@ConditionalOnMissingClass:类路径中不存在指定类时生效。@ConditionalOnBean:容器中存在指定 Bean 时生效。@ConditionalOnMissingBean:容器中不存在指定 Bean 时生效。@ConditionalOnProperty:配置文件中存在指定属性时生效。@ConditionalOnWebApplication:在 Web 应用环境中生效。
示例:
@Configuration
@ConditionalOnClass(JdbcTemplate.class)
@ConditionalOnMissingBean(DataSource.class)
public class DataSourceAutoConfiguration { @Bean @ConditionalOnProperty(prefix = "spring.datasource", name = "url") public DataSource dataSource() { // 根据配置创建 DataSource }
}
该配置类仅在:
- 类路径存在
JdbcTemplate类; - 容器中不存在手动定义的
DataSourceBean; - 配置文件中存在
spring.datasource.url属性时生效。
4. 自定义自动配置
开发者可通过以下步骤创建自定义自动配置:
- 创建配置类,使用
@Configuration和条件注解:@Configuration @ConditionalOnClass(RedisTemplate.class) public class RedisAutoConfiguration { @Bean @ConditionalOnMissingBean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { // 配置 RedisTemplate } } - 在
src/main/resources/META-INF目录下创建spring.factories文件,指定自动配置类:org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.example.autoconfigure.RedisAutoConfiguration
5. 自动装配的顺序控制
通过 @AutoConfigureBefore、@AutoConfigureAfter 和 @AutoConfigureOrder 注解控制自动配置类的加载顺序:
@AutoConfigureAfter(DataSourceAutoConfiguration.class)
public class MyAutoConfiguration { // 配置逻辑
}
Spring Cloud 在调用其他服务时,采用什么机制实现远程调用?
Spring Cloud 提供多种远程调用机制,核心方案包括 RestTemplate、OpenFeign 和 Spring Cloud Gateway,分别适用于不同场景。
1. RestTemplate(基础实现)
RestTemplate 是 Spring 提供的 HTTP 客户端工具,通过 RESTful API 调用远程服务。在 Spring Cloud 中,结合 Ribbon(客户端负载均衡)可实现服务间调用:
@Service
public class UserService { @Autowired private RestTemplate restTemplate; public User getUser(Long userId) { // 直接调用服务名,Ribbon 自动负载均衡 return restTemplate.getForObject("http://user-service/users/{id}", User.class, userId); }
} // 配置 RestTemplate 和 Ribbon
@Configuration
public class AppConfig { @Bean @LoadBalanced // 启用 Ribbon 负载均衡 public RestTemplate restTemplate() { return new RestTemplate(); }
}
流程:
- 服务提供者注册到服务注册中心(如 Eureka、Consul)。
- 服务消费者通过服务名(如
user-service)调用,Ribbon 根据负载均衡策略选择实例。 - RestTemplate 发送 HTTP 请求到实际服务实例。
2. OpenFeign(声明式 REST 客户端)
OpenFeign 是 Spring Cloud 基于 Feign 改进的声明式 HTTP 客户端,通过接口和注解简化远程调用:
// 定义 Feign 客户端接口
@FeignClient(name = "user-service") // 指定服务名
public interface UserClient { @GetMapping("/users/{id}") User getUser(@PathVariable("id") Long userId);
} // 服务中直接注入使用
@Service
public class OrderService { @Autowired private UserClient userClient; public Order createOrder(Long userId) { User user = userClient.getUser(userId); // 像调用本地方法一样调用远程服务 // 创建订单逻辑 }
}
核心特性:
- 声明式调用:通过接口和注解定义 API,无需编写实现类。
- 负载均衡:内置 Ribbon,支持多种负载均衡策略。
- 熔断降级:集成 Hystrix 或 Resilience4j,提供服务容错能力。
- 请求 / 响应拦截:可自定义拦截器处理 HTTP 头、参数等。
3. Spring Cloud Gateway(API 网关)
Spring Cloud Gateway 作为 API 网关,处理所有客户端请求,再路由到后端服务。远程调用通常发生在网关与微服务之间:
# 配置路由规则
spring: cloud: gateway: routes: - id: user_route uri: lb://user-service # lb 表示使用 LoadBalancerClient predicates: - Path=/api/users/**
流程:
- 客户端请求发送到 Gateway。
- Gateway 根据路由规则(如路径匹配)将请求转发到目标服务(如
user-service)。 - Gateway 可集成过滤器链,实现权限校验、限流、日志等功能。
4. 负载均衡与服务发现
Spring Cloud 的远程调用依赖 服务发现 和 负载均衡 机制:
- 服务发现:通过 Eureka、Consul 或 Nacos 等注册中心,服务实例自动注册与发现。
- 负载均衡:Ribbon(客户端负载均衡)根据策略(如轮询、随机)选择服务实例。
示例(Ribbon 配置):
user-service: # 服务名 ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 随机负载均衡
5. 熔断与降级(服务容错)
为防止级联故障,Spring Cloud 集成 Hystrix 或 Resilience4j 实现熔断降级:
@Service
public class UserService { @Autowired private UserClient userClient; @HystrixCommand(fallbackMethod = "getUserFallback") // Hystrix 熔断 public User getUser(Long userId) { return userClient.getUser(userId); } public User getUserFallback(Long userId) { return new User(-1L, "default-user"); // 降级逻辑 }
}
6. 异步调用(WebClient)
对于响应式应用,Spring Cloud 提供 WebClient(Reactor 库的一部分)实现非阻塞远程调用:
@Service
public class UserService { private final WebClient webClient; public UserService(WebClient.Builder builder) { this.webClient = builder.baseUrl("http://user-service").build(); } public Mono<User> getUser(Long userId) { return webClient.get() .uri("/users/{id}", userId) .retrieve() .bodyToMono(User.class); }
}
如何使用注解实现反射功能?
Java 注解与反射结合可实现代码的动态解析和处理,常用于框架开发(如 Spring、MyBatis)、配置注入、AOP 等场景。以下是实现步骤和示例:
1. 定义注解
使用 @interface 定义注解,并通过元注解(如 @Retention、@Target)指定注解的保留策略和使用范围:
// 自定义注解:用于标记需要注入的字段
@Retention(RetentionPolicy.RUNTIME) // 运行时可见
@Target(ElementType.FIELD) // 作用于字段
public @interface AutoInject { String value() default ""; // 可选参数,用于指定 Bean 名称
}
2. 创建目标类并使用注解
在目标类的字段上使用自定义注解:
public class UserService { @AutoInject // 标记需要注入的字段 private UserRepository userRepository; public void createUser(String username) { userRepository.save(new User(username)); }
} public class UserRepository { public void save(User user) { System.out.println("Saving user: " + user.getUsername()); }
}
3. 通过反射处理注解
编写工具类,使用反射扫描类的注解并执行相应逻辑(如依赖注入):
public class AnnotationProcessor { public static void injectDependencies(Object obj) throws Exception { Class<?> clazz = obj.getClass(); // 获取所有字段 Field[] fields = clazz.getDeclaredFields(); for (Field field : fields) { // 检查字段是否有 @AutoInject 注解 if (field.isAnnotationPresent(AutoInject.class)) { field.setAccessible(true); // 允许访问私有字段 // 获取注解实例 AutoInject autoInject = field.getAnnotation(AutoInject.class); String beanName = autoInject.value(); // 获取注解参数 // 根据字段类型创建实例(简化示例,实际场景可能从容器获取) Class<?> fieldType = field.getType(); Object instance = fieldType.getDeclaredConstructor().newInstance(); // 注入实例 field.set(obj, instance); } } }
}
4. 使用示例
在运行时调用工具类处理注解:
public class Main { public static void main(String[] args) throws Exception { // 创建 UserService 实例 UserService userService = new UserService(); // 通过注解处理器注入依赖 AnnotationProcessor.injectDependencies(userService); // 调用方法测试 userService.createUser("Alice"); // 输出:Saving user: Alice }
}
5. 进阶应用:扫描包内所有类
可扩展工具类,扫描指定包下的所有类并处理注解:
public class PackageScanner { public static void scan(String packageName) throws Exception { ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); String path = packageName.replace('.', '/'); Enumeration<URL> resources = classLoader.getResources(path); while (resources.hasMoreElements()) { URL resource = resources.nextElement(); File directory = new File(resource.getFile()); if (directory.exists()) { for (File file : directory.listFiles()) { String fileName = file.getName(); if (fileName.endsWith(".class")) { String className = packageName + '.' + fileName.substring(0, fileName.length() - 6); Class<?> clazz = Class.forName(className); // 处理带有特定注解的类 if (clazz.isAnnotationPresent(Component.class)) { Object instance = clazz.getDeclaredConstructor().newInstance(); AnnotationProcessor.injectDependencies(instance); // 注册实例到容器 } } } } } }
}
6. 结合 Spring 框架的注解处理
Spring 框架大量使用注解与反射结合的机制,例如 @Autowired 注解的实现原理:
// 简化版的 Spring 自动注入处理器
public class SpringAutowiredProcessor { public void process(Object bean) throws Exception { Class<?> clazz = bean.getClass(); for (Field field : clazz.getDeclaredFields()) { if (field.isAnnotationPresent(Autowired.class)) { field.setAccessible(true); // 根据类型从 Spring 容器获取 Bean Class<?> fieldType = field.getType(); Object dependency = getBeanFromContext(fieldType); field.set(bean, dependency); } } } private Object getBeanFromContext(Class<?> type) { // 实际从 Spring 容器获取 Bean 的逻辑 return null; }
}
7. 注意事项
- 性能开销:反射操作涉及动态解析,性能低于直接调用,需避免在高频场景使用。
- 访问权限:通过
setAccessible(true)可访问私有字段,但可能违反封装原则。 - 泛型擦除:运行时无法获取泛型的具体类型,需通过其他方式(如 TypeToken)保留类型信息。
简述 MQ(消息队列)的原理和架构。如何保证消息的顺序消费?
消息队列(MQ)的核心原理是通过异步解耦实现生产者与消费者之间的消息传递,其架构通常包含 生产者(Producer)、消息服务器(Broker)、消费者(Consumer)** 三大组件。生产者将消息发送至 Broker 的指定主题(Topic)或队列(Queue),消费者通过订阅主题或拉取队列中的消息进行处理。Broker 作为中间件,负责存储、路由和分发消息,同时提供持久化、负载均衡等功能。
以 Kafka 为例,其架构基于分布式分区(Partition)机制,每个 Topic 划分为多个分区以实现吞吐量扩展。生产者发送消息时指定分区键(Partition Key),相同键的消息会被路由到同一分区,确保局部有序性;消费者通过分区分配策略(如 Round Robin 或 Range)获取分区消息,按顺序消费。RabbitMQ 则通过 Exchange 机制路由消息,消费者通过信道(Channel)与 Broker 建立连接,通过队列绑定(Binding)规则获取消息。
保证消息顺序消费的关键策略如下:
- 分区 / 队列级顺序:将需要顺序处理的消息发送至同一分区或队列。例如,同一用户的操作日志按用户 ID 哈希到固定分区,确保同一用户的消息按顺序进入分区,消费者按分区顺序拉取。
- 消息顺序标记:在消息中添加全局唯一的顺序号(如时间戳或递增 ID),消费者接收消息后按顺序号排序处理。此方法适用于跨分区的全局顺序场景,但需额外维护内存排序缓冲区,可能增加处理延迟。
- 事务性消息与幂等性保障:通过分布式事务确保消息发送与业务操作的原子性,避免重复消息导致顺序混乱。同时,消费者需实现幂等性(如通过唯一请求 ID 校验),即使消息重复也能保证最终结果一致。
- 单线程消费模型:为每个分区或队列分配单一消费者线程,避免多线程并发处理导致的顺序错乱。例如,Kafka 的消费者组(Consumer Group)通过分区分配机制确保每个分区仅由一个消费者实例处理。
- 顺序消息专用队列:某些 MQ(如 RocketMQ)提供 “顺序消息” 特性,强制同一队列的消息按 FIFO 顺序投递,生产者和消费者需配合使用该特性。
需要注意的是,顺序性与吞吐量存在权衡。全局顺序性通常需要牺牲分布式并行处理能力,而分区级顺序性在保证局部有序的同时允许分区间并行消费。实际应用中需根据业务场景选择合适的策略,例如金融交易场景要求严格顺序,而日志统计场景可接受最终一致性。
如何解决 MQ 的消息堆积问题?需要考虑哪些下游业务影响?
消息堆积是指消息队列中未被及时消费的消息持续累积,可能由生产者速率远超消费者处理能力、消费者故障或下游系统瓶颈导致。解决该问题需从流量控制、消费能力提升、消息存储优化三方面入手,同时评估对下游业务的影响。
解决策略
-
临时扩容消费者
- 增加消费者实例数量或并行线程数,提升消费吞吐量。例如,Kafka 通过增加 Consumer Group 中的消费者实例,利用分区并行消费特性快速拉取堆积消息;RabbitMQ 可通过创建多个消费者监听同一队列,或开启消费者的并发预取(Prefetch)机制。
- 注意分区数限制:若分区数固定,消费者实例数超过分区数时无法进一步提升并行度,需先调整 Topic 的分区数(需重启服务或通过管理工具动态调整)。
-
优化消费逻辑
- 减少消费端的业务处理耗时,例如将同步操作改为异步、批量处理消息(如将多条消息合并为一个批次写入数据库)、移除非必要的日志打印或监控逻辑。
- 示例:若消费者需将消息写入数据库,可将单条插入改为
batchInsert批量操作,减少数据库连接开销。
-
流量削峰与限流
- 在生产者端增加流量控制,例如通过令牌桶(Token Bucket)或漏桶(Leaky Bucket)算法限制消息发送速率,避免短时间内大量消息涌入队列。
- 在 MQ 层启用流控机制,如 RabbitMQ 的
publisher confirm配合背压(Backpressure)策略,当 Broker 内存不足时阻塞生产者发送。
-
消息持久化与回溯处理
- 若堆积消息需长期保留,可将消息从 MQ 转移至持久化存储(如 HDFS、S3),释放队列空间后再通过离线任务逐步处理。
- 对于需要重新消费的场景(如消费逻辑修复后),利用 MQ 的消息回溯功能(如 Kafka 的 offset 重置)重新消费历史消息。
-
分层处理与死信队列
- 将堆积消息按优先级分类,优先处理关键业务消息(如支付通知),次要消息(如日志上报)延后处理。
- 将无法消费的消息(如格式错误、业务校验失败)路由至死信队列(Dead Letter Queue),避免无限重试占用正常队列资源。
下游业务影响分析
-
数据一致性风险
- 快速消费堆积消息可能导致下游系统(如数据库、微服务)瞬间压力激增,引发超时、锁竞争或数据不一致。例如,大量订单消息同时处理可能导致库存扣减超卖,需通过事务、分布式锁或版本号控制保证一致性。
-
消息顺序与重复
- 扩容消费者或调整分区可能破坏消息顺序(除非采用单分区单消费者模式),需评估业务是否允许乱序处理。若必须保证顺序,需结合分区策略和消费端排序(如按消息时间戳重组)。
- 重试机制可能导致消息重复消费,下游业务需实现幂等性(如通过唯一 ID 校验),避免重复执行引发异常(如重复扣款)。
-
监控与告警延迟
- 堆积期间的监控指标(如消息延迟、消费耗时)可能滞后,影响运维人员对系统状态的实时判断。需临时增强监控频率,或设置独立的堆积告警阈值(如队列长度超过阈值时触发预警)。
-
资源占用与成本
- 临时扩容可能增加计算资源成本(如 EC2 实例、容器节点),需评估性价比。对于偶发堆积场景,可结合云服务商的弹性扩缩容机制(如 Kubernetes HPA)自动调整资源。
预防措施
- 建立常态化的流量监控与容量评估机制,根据历史峰值流量预留一定的消费能力冗余(如消费者处理速率为生产者峰值的 1.5 倍)。
- 设计可降级的消费链路,当堆积严重时优先保证核心业务消息的处理,非关键消息可延迟或丢弃(需业务允许)。
- 定期进行压测,模拟极端流量下的堆积场景,验证解决方案的有效性。
Redis 有哪些数据结构?ZSet 的底层实现是什么?为什么选择跳表而非 B + 树?
Redis 提供了丰富的数据结构以适应不同场景,核心数据结构包括:
- String:基于动态字符串(SDS)实现,支持二进制安全存储,可用于缓存对象、计数器(如
INCR命令)或分布式锁的键值对。 - List:双向链表结构,支持头部和尾部快速插入 / 删除,适用于消息队列(如 LPUSH/RPOP 实现栈或队列)、排行榜的最新列表(如保留最近 10 条日志)。
- Hash:键值对的集合,底层使用哈希表,适合存储对象属性(如用户信息
user:1001包含name、age等字段)。 - Set:无序唯一集合,基于哈希表或整数集合(intset)实现,支持交集、并集、差集运算,常用于标签管理(如用户关注的标签集合)或去重(如统计独立访客数)。
- ZSet(Sorted Set):有序集合,每个元素关联一个分数(score),按分数排序,底层通过跳表(SkipList)或压缩列表(ziplist)实现,适用于排行榜(如按分数排序的用户排名)、时间线(按时间戳排序的动态)。
ZSet 的底层实现
ZSet 的底层数据结构由 ** 哈希表(Hash Table)和跳表(SkipList)** 组合构成:
- 哈希表:存储成员到分数的映射,用于快速查询成员的分数(时间复杂度 O (1))。
- 跳表:按分数排序存储所有成员,支持快速范围查询(如
ZRANGE获取排名前 10 的成员)。
当 ZSet 元素数量较少且分数范围较小时,会使用压缩列表(ziplist)存储以节省内存;当元素数量或分数范围超过阈值(默认 128 个元素或分数为 64 位整数)时,自动切换为跳表 + 哈希表结构。
为什么选择跳表而非 B+ 树?
在 Redis 的 ZSet 场景中,跳表相比 B+ 树具有以下优势:
-
实现简单,维护成本低
- 跳表的节点结构和操作逻辑(插入、删除、查询)比 B+ 树更简单,尤其在并发场景下,跳表通过分层索引和随机层高生成机制,无需像 B+ 树那样处理复杂的节点分裂、合并操作,更适合 Redis 这种需要快速实现和高并发的内存数据库。
-
高效的范围查询
- ZSet 的核心操作(如
ZRANGE、ZREVRANGE)需要按顺序遍历元素,跳表的有序性使其可以通过指针直接遍历节点,时间复杂度为 O (logN + M)(M 为结果集大小)。而 B+ 树的范围查询需先找到范围起点,再通过叶子节点链表遍历,虽然时间复杂度相近,但跳表的内存布局更连续(节点按顺序存储),在 CPU 缓存利用率上更优(局部性原理),尤其在频繁范围查询时性能更突出。
- ZSet 的核心操作(如
-
内存占用与访问效率平衡
- 跳表的每个节点包含多层指针,指针占用的内存空间相对固定,而 B+ 树的节点需要存储键值对和子节点指针,在内存中存储时节点大小不固定,可能导致更多的内存碎片。此外,跳表的随机层高机制(通常基于幂次定律生成)使得大部分操作的时间复杂度接近 O (logN),与 B+ 树的 O (logN) 相当,但实现更轻量。
-
并发场景下的性能优势
- Redis 采用单线程模型处理命令,跳表的操作无需复杂的锁机制(仅需在执行命令时获取全局锁),而 B+ 树若要支持多线程并发访问,需实现更复杂的锁粒度控制(如读写锁),可能增加代码复杂度和性能损耗。
与哈希表的对比
虽然哈希表可以实现 O (1) 的单点查询,但无法支持范围查询,而跳表弥补了这一缺陷。ZSet 通过组合两种数据结构,既保证了成员与分数映射的快速查询,又支持高效的范围操作,是空间与时间复杂度的平衡选择。
Redis 分布式锁的实现机制有哪些?如何实现可重入锁?
Redis 分布式锁用于在分布式系统中协调多个节点对共享资源的访问,常见实现机制包括基于命令的简单锁、RedLock 算法和Redisson 封装的可重入锁,其核心目标是保证锁的原子性、互斥性、可重入性、锁超时等特性。
1. 基于 SET 命令的简单分布式锁
通过 SET key value NX PX timeout 命令实现(Redis 2.6.12+ 支持):
NX(Only if Not exists)保证锁的互斥性,仅当键不存在时创建锁。PX timeout设置锁的过期时间,避免服务崩溃导致的死锁。value通常为随机字符串(如 UUID),用于释放锁时校验,避免误删其他进程的锁。
释放锁的逻辑需通过 Lua 脚本保证原子性,例如:
if redis.call("GET",KEYS[1]) == ARGV[1] thenreturn redis.call("DEL",KEYS[1])
elsereturn 0
end
此方法实现简单,但存在以下缺陷:
- 主从模式下的一致性问题:若持有锁的主节点未同步数据到从节点就宕机,新主节点可能允许其他客户端获取锁,导致锁失效。
- 不支持可重入性:同一线程多次获取锁会被阻塞,需额外处理。
2. RedLock 算法(解决主从一致性问题)
RedLock 算法通过部署多个独立的 Redis 实例(通常 5 个),利用多数派机制提升可靠性:
- 客户端获取当前时间戳(T1)。
- 依次向每个 Redis 实例请求获取锁(使用相同的 key 和超时时间),超时时间需远小于锁的有效时间。
- 收集成功获取锁的实例列表,计算总耗时(T2 - T1)。若成功实例数 ≥ N/2 + 1(N 为实例总数,如 5 个中至少 3 个成功),且总耗时 < 锁的有效时间,则认为锁获取成功,锁的有效时间为原超时时间减去总耗时。
- 若获取失败,需向所有已成功的实例释放锁。
RedLock 提升了分布式场景下的锁可靠性,但实现复杂,且在网络分区等极端情况下仍可能存在一致性问题,适用于对可靠性要求极高的场景(如金融交易)。
3. 可重入锁的实现(基于哈希表记录持有线程)
普通分布式锁不支持同一线程多次获取锁,可通过在锁的 value 中记录线程标识和重入次数实现可重入性:
- 锁的存储结构:使用 Redis 的 Hash 类型,键为锁名称(如
lock:resource),字段为线程 ID(如thread-123),值为该线程持有锁的次数。 - 获取锁逻辑:
- 检查当前线程是否已持有锁(通过
HGET lock:resource thread-123)。 - 若已持有,增加重入次数(
HINCRBY lock:resource thread-123 1)。 - 若未持有,通过
HSETNX lock:resource thread-123 1 PX timeout尝试获取锁,成功则返回,失败则等待。
- 检查当前线程是否已持有锁(通过
- 释放锁逻辑:
- 获取当前线程的持有次数,若大于 1 则递减(
HINCRBY lock:resource thread-123 -1)。 - 若次数减为 0,删除整个哈希键(
DEL lock:resource),避免残留无效记录。
- 获取当前线程的持有次数,若大于 1 则递减(
示例代码(伪代码):
// 获取锁
String threadId = Thread.currentThread().getId();
Jedis jedis = redisClient.getJedis();
try {// 检查是否已持有锁Long count = jedis.hget("lock:resource", threadId);if (count != null && count > 0) {jedis.hincrBy("lock:resource", threadId, 1);return true;}// 尝试获取新锁String result = jedis.set("lock:resource", threadId, "NX", "PX", 10000);return "OK".equals(result);
} finally {jedis.close();
}// 释放锁
try {Long count = jedis.hdecrBy("lock:resource", threadId, 1);if (count != null && count <= 0) {jedis.del("lock:resource");}
} finally {jedis.close();
}
4. Redisson 框架的可重入锁
Redisson 是 Redis 的 Java 客户端,封装了分布式锁的复杂逻辑,其可重入锁(RLock)实现原理如下:
- 使用 Lua 脚本保证锁操作的原子性,通过
REDLOCK算法实现跨实例的锁安全。 - 内部维护一个
Hash结构记录线程 ID 和重入次数,与上述自定义方案类似,但集成了连接池管理、自动续锁(Watchdog 机制)等功能,避免因业务处理耗时超过锁超时时间导致的锁提前释放。
优势:相比手动实现,Redisson 提供了更健壮的异常处理、锁超时自动续租、可重入支持和跨语言兼容性,是生产环境的首选方案。
关键问题总结
- 互斥性:通过
SET NX或HSETNX保证同一时刻只有一个线程持有锁。 - 可重入性:记录线程标识和重入次数,允许同一线程多次获取锁而不阻塞。
- 防死锁:设置合理的锁超时时间,并通过 Watchdog 机制动态延长锁有效期(如 Redisson 默认续锁时间为 30 秒)。
- 一致性:单实例模式下通过
SET PX保证,分布式场景需使用 RedLock 或多主架构。
Redis 除了作为缓存,还有哪些应用场景?
Redis 凭借其高性能、丰富的数据结构和原子操作能力,不仅是优秀的缓存工具,还可用于实现多种复杂的业务场景,以下是主要应用方向:
1. 分布式锁与同步机制
Redis 提供的SET NX、GETSET等命令可实现轻量级分布式锁,用于协调分布式系统中多个节点对共享资源的访问(如分布式定时任务的互斥执行)。结合 Lua 脚本和PX过期时间,可保证锁的原子性和防死锁特性。例如,在电商系统中,通过 Redis 锁保证库存扣减的唯一性,避免超卖。
2. 计数器与限速器
利用 Redis 的INCR、DECR等原子操作,可实现高并发场景下的计数器,例如:
- 分布式计数器:统计网站 PV、UV,或生成全局唯一递增 ID(如订单号)。
- 接口限流:通过
INCR命令记录请求次数,结合EXPIRE设置过期时间,实现令牌桶或漏桶算法的限流逻辑。例如,限制某个 IP 每分钟最多访问 100 次接口:// key为"rate_limit:ip:192.168.1.1",值为当前计数 long count = jedis.incr("rate_limit:ip:192.168.1.1"); if (count == 1) {jedis.expire("rate_limit:ip:192.168.1.1", 60); // 设置1分钟过期 } if (count > 100) {throw new TooManyRequestsException("请求频率过高"); }
3. 消息队列与发布订阅(Pub/Sub)
Redis 支持基于频道(Channel)的发布订阅模式,适用于实时通信、异步通知等场景:
- 实时聊天系统:用户发布消息到频道,其他订阅该频道的用户实时接收。
- 微服务异步通信:替代传统 MQ 实现轻量级事件通知,例如订单状态变更时通知库存、物流等服务。
- 临时队列:通过
LPUSH和RPOP命令实现简单的 FIFO 队列,用于处理非持久化的实时任务(如日志收集)。
4. 排行榜与实时数据统计
利用 ZSet 数据结构的有序性,可高效实现各种排行榜功能:
- 实时排名:如游戏玩家分数排名、商品销量 Top100,通过
ZADD更新分数,ZRANGE获取排名。 - 时间窗口统计:结合
ZREMRANGEBYTIME命令,统计指定时间范围内的活跃用户数、点击量等。例如,统计过去 1 小时内登录的用户列表:ZADD active_users 1690000000 "user:1001" ZREMRANGEBYTIME active_users 0 (now-3600) ZCARD active_users # 获取当前活跃用户数
5. 分布式会话存储
在分布式架构中,多个服务节点需共享用户会话信息,Redis 提供的SET、GET命令可高效存储会话数据(如 JWT 令牌、用户登录状态),并通过EXPIRE设置会话过期时间,替代传统的 Cookie 或本地 Session 存储。例如,Spring Session 框架可集成 Redis 实现分布式会话管理。
6. 地理位置信息处理
Redis 3.2+ 引入GEO命令集,支持存储和查询地理位置数据(如经纬度),适用于 LBS 场景:
- 附近用户查询:通过
GEOADD存储用户位置,GEORADIUS查询指定半径内的用户。 - 路线规划与距离计算:利用
GEODIST命令计算两点之间的距离。
7. 缓存以外的数据持久化存储
虽然 Redis 主要用于内存数据存储,但其持久化机制(RDB 和 AOF)使其可作为高性能的 NoSQL 数据库使用,适合存储高频访问的小数据量结构化数据,例如:
- 实时统计结果存储:如电商大促期间的实时交易额、库存余量,需频繁更新并快速查询。
- 元数据管理:存储微服务的配置信息、服务注册列表(类似 Consul),利用
SET和GET实现键值对的快速读写。
8. 分布式协调与状态机
通过 Redis 的原子操作(如INCR、SETNX)和发布订阅机制,可实现分布式系统中的协调逻辑:
- 分布式选举:模拟 Zookeeper 的 Leader 选举机制,通过竞争获取特定锁(如
leader_lock)确定主节点。 - 状态机同步:多个节点通过监听 Redis 中的状态变更(如通过 Pub/Sub 发布状态消息),保持业务状态的一致性。
Redis 主从同步的机制是什么?当 Slave 重连时如何保证数据一致性?
Redis 主从同步的核心目标是实现数据冗余备份和读写分离,其机制基于异步复制和增量同步,通过三个阶段完成:初始化同步、命令传播和断线重连后的差异补偿。
初始化同步流程:
- Slave 向 Master 发送
PSYNC命令(Redis 2.8+),携带自身复制偏移量(replication offset)和运行 ID(run_id)。若为首次连接,发送PSYNC ? -1。 - Master 接收到命令后,执行 BGSAVE 生成 RDB 文件,并记录期间执行的写命令到缓冲区(replication buffer)。
- Master 将 RDB 文件发送给 Slave,Slave 清空当前数据并加载 RDB 文件。
- Master 发送缓冲区中的写命令到 Slave,Slave 执行这些命令,实现数据最终一致性。
命令传播阶段:
初始化同步完成后,Master 持续将写命令发送给 Slave,Slave 实时执行这些命令,保持与 Master 的数据同步。此过程是异步的,Master 无需等待 Slave 确认即可继续处理新请求,因此可能存在短暂的数据不一致。
断线重连后的差异补偿:
当 Slave 因网络故障等原因断线重连后,通过以下机制保证数据一致性:
- 部分重同步(Partial Resynchronization):
- Master 维护一个复制积压缓冲区(replication backlog),存储最近执行的写命令(默认 1MB,可通过
repl-backlog-size配置)。 - Slave 重连后,发送自身保存的复制偏移量。若该偏移量仍在 Master 的积压缓冲区中,Master 仅发送偏移量之后的命令给 Slave,避免全量同步。
- Master 维护一个复制积压缓冲区(replication backlog),存储最近执行的写命令(默认 1MB,可通过
- 全量重同步(Full Resynchronization):
- 若 Slave 的偏移量超出积压缓冲区范围,或 Master 运行 ID 已变更(如 Master 重启后生成新 ID),则触发全量同步,重复初始化阶段的流程。
保证数据一致性的关键措施:
- 配置合理的复制积压缓冲区:根据写操作频率调整
repl-backlog-size,确保大部分断线场景下可通过部分重同步恢复。 - 监控复制延迟:通过
INFO replication命令查看master_repl_offset和slave_repl_offset的差值,评估数据延迟情况。 - 使用 Sentinel 或 Cluster 架构:自动检测 Master 故障并进行主从切换,减少人工干预导致的不一致风险。
- 设置安全参数:如
min-slaves-to-write和min-slaves-max-lag,确保至少有指定数量的 Slave 与 Master 延迟不超过阈值时,才允许 Master 执行写操作。
注意事项:
- 主从同步是异步的,极端情况下(如 Master 突然宕机且未完成数据同步)可能丢失部分数据。
- 若 Slave 长时间断线,重连后可能因积压缓冲区不足而触发全量同步,需评估 RDB 生成和传输对系统的性能影响。
Redis 的内存淘汰策略有哪些?
Redis 的内存淘汰策略用于在内存使用达到上限(maxmemory配置)时,决定哪些数据将被优先删除,以保证新数据的写入。Redis 提供多种淘汰策略,可通过maxmemory-policy配置项选择。
六种主要淘汰策略:
- volatile-lru(默认):
从设置了过期时间(expire)的键中,选择最近最少使用(LRU)的键进行淘汰。适用于缓存场景,优先淘汰冷数据。 - allkeys-lru:
从所有键中选择最近最少使用(LRU)的键进行淘汰。若应用对所有数据的访问频率无明显差异,此策略更合适。 - volatile-lfu:
从设置了过期时间的键中,选择最不经常使用(LFU)的键进行淘汰。LFU 基于访问频率计数,比 LRU 更精准地识别冷数据。 - allkeys-lfu:
从所有键中选择最不经常使用(LFU)的键进行淘汰。适用于需要全面淘汰冷数据的场景。 - volatile-random:
从设置了过期时间的键中随机淘汰。适用于对数据淘汰顺序无特殊要求的场景。 - allkeys-random:
从所有键中随机淘汰。适用于所有数据平等重要、无冷热区分的场景。
两种特殊策略:
- volatile-ttl:
从设置了过期时间的键中,选择剩余生存时间(TTL)最短的键进行淘汰。适用于需要尽快释放内存的场景。 - noeviction:
当内存不足时,拒绝写入操作(但允许读取),返回错误。适用于不能容忍数据丢失的场景,如持久化存储。
选择建议:
- 若需缓存热点数据,优先使用
allkeys-lru或allkeys-lfu,确保未设置过期时间的键也能参与淘汰。 - 若业务有明确的淘汰优先级(如临时数据设置了过期时间),可使用
volatile-lru或volatile-lfu。 - 若对淘汰顺序无要求,可使用随机淘汰策略(
volatile-random或allkeys-random)。 - 若不能接受数据丢失,使用
noeviction,但需确保内存充足或有其他降级策略。
LFU 与 LRU 的区别:
- LRU(Least Recently Used):基于访问时间,淘汰最久未使用的数据,可能误删偶尔访问但重要的数据。
- LFU(Least Frequently Used):基于访问频率,淘汰使用次数最少的数据,更精准地识别冷数据,但需要维护频率计数器,内存开销略高。
配置示例:
# 设置最大内存为 2GB
maxmemory 2gb
# 使用 LFU 淘汰策略
maxmemory-policy allkeys-lfu
注意事项:
- Redis 的 LRU 和 LFU 实现并非严格算法,而是基于采样(默认采样 5 个键,可通过
maxmemory-samples调整),以平衡性能和准确性。 - 频繁的内存淘汰可能导致性能波动,建议监控内存使用情况,提前扩容或优化数据结构。
简述 Zookeeper 的作用和特性,如何实现分布式锁?
Zookeeper 是 Apache 旗下的分布式协调服务,提供高可用的分布式数据存储和协调机制,常用于服务注册与发现、配置管理、分布式锁等场景。其核心特性包括:
1. 分层命名空间(Hierarchical Namespace)
Zookeeper 数据模型类似文件系统,由 ** 节点(ZNode)** 组成树形结构。每个节点可存储数据(最大 1MB),并可拥有子节点。节点分为四种类型:
- 持久节点(Persistent):创建后持续存在,直到被显式删除。
- 临时节点(Ephemeral):与客户端会话绑定,会话结束时自动删除。
- 持久顺序节点(Persistent Sequential):创建时自动添加递增序号(如
/lock_00000001)。 - 临时顺序节点(Ephemeral Sequential):兼具临时节点和顺序节点特性。
2. 原子性与一致性保证
- 全局一致性:所有客户端看到的视图相同,无论连接到哪个服务器。
- 顺序性:来自同一客户端的更新按发送顺序执行。
- 原子性:更新操作要么完全成功,要么完全失败。
3. 事件通知机制(Watch)
客户端可对节点设置 Watch,当节点变化(如创建、删除、数据更新)时,Zookeeper 会向注册 Watch 的客户端发送通知。此机制用于实现配置变更实时感知、分布式锁释放通知等。
4. 高可用性与容错
Zookeeper 通过 Leader-Follower 集群模式保证可用性,集群中半数以上节点存活即可正常服务。Leader 处理写请求,Follower 处理读请求,选举过程使用 Zab(Zookeeper Atomic Broadcast)协议。
分布式锁实现方式
1. 基于临时节点的排他锁
- 获取锁:客户端尝试在特定路径(如
/lock)下创建临时节点,若成功则获得锁;若节点已存在,则监听该节点的删除事件,进入等待状态。 - 释放锁:客户端会话结束或主动删除临时节点,触发 Watch 通知其他等待的客户端重新竞争。
示例流程:
- 客户端 A 尝试创建
/lock节点,成功则获得锁。 - 客户端 B 尝试创建
/lock节点,失败则监听该节点。 - 客户端 A 执行完业务逻辑后删除节点,触发 B 的 Watch 通知。
- B 重新尝试创建节点,循环上述流程。
问题:此方式存在羊群效应(Herd Effect),当锁释放时,所有等待的客户端同时竞争,导致性能开销大。
2. 基于临时顺序节点的公平锁
- 获取锁:客户端在
/lock路径下创建临时顺序节点(如/lock_00000001),检查自身序号是否最小,若是则获得锁;否则监听前一个节点的删除事件。 - 释放锁:删除自身创建的节点,触发后续节点的 Watch 通知。
示例流程:
- 客户端 A、B、C 依次创建节点
/lock_00000001、/lock_00000002、/lock_00000003。 - A 发现自己序号最小,获得锁;B 监听
/lock_00000001,C 监听/lock_00000002。 - A 释放锁后,B 收到通知,发现自己序号最小,获得锁,依此类推。
优势:避免羊群效应,每个客户端只需监听前一个节点,降低竞争压力。
3. Curator 框架的分布式锁实现
Apache Curator 是 Zookeeper 的官方客户端,提供了封装好的分布式锁实现:
// 创建 Curator 客户端
CuratorFramework client = CuratorFrameworkFactory.newClient("zk1:2181,zk2:2181,zk3:2181",new ExponentialBackoffRetry(1000, 3)
);
client.start();// 创建可重入锁
InterProcessMutex lock = new InterProcessMutex(client, "/my-lock");try {// 获取锁,最多等待 10 秒if (lock.acquire(10, TimeUnit.SECONDS)) {// 获得锁后执行临界区代码System.out.println("获得锁,执行业务逻辑");}
} finally {// 释放锁lock.release();
}
注意事项:
- 确保 Zookeeper 集群的高可用性,避免单点故障导致锁服务不可用。
- 合理设置会话超时时间,避免因网络抖动导致锁意外释放。
- 锁路径的设计应考虑业务隔离,不同业务使用不同路径。
什么是 CAP 理论?你的项目更侧重哪两个要素?
CAP 理论由 Eric Brewer 于 2000 年提出,指出分布式系统在以下三个特性中,最多只能同时满足两个:
- 一致性(Consistency):所有节点在同一时间看到的数据完全一致,客户端读取操作总能返回最新写入结果。
- 可用性(Availability):每个请求都能收到非错误响应,但不保证返回最新数据。
- 分区容错性(Partition Tolerance):系统在网络分区(节点间通信中断)时仍能继续运行。
理论核心:在分布式系统中,网络分区是不可避免的,因此必须在一致性和可用性之间做出权衡。
项目中的取舍策略
不同类型的项目对 CAP 的侧重不同,常见场景如下:
1. 侧重 CP(一致性 + 分区容错性)
- 场景:对数据一致性要求极高,允许在网络分区时牺牲可用性。
- 案例:
- 金融交易系统:转账操作必须保证所有节点数据一致,否则可能导致资金丢失。
- 分布式文件系统(如 Ceph):多个副本间强一致性保证数据完整性。
- 技术实现:
- 使用 Paxos、Raft 等共识算法(如 Zookeeper、etcd),确保数据在多数节点写入成功后才返回成功。
- 当发生网络分区时,可能拒绝部分节点的请求,直到分区恢复。
2. 侧重 AP(可用性 + 分区容错性)
- 场景:对系统可用性要求高,允许短暂的数据不一致,但最终要达成一致(最终一致性)。
- 案例:
- 电商购物车:用户添加商品后,允许在不同节点间延迟同步,但最终显示正确的商品列表。
- 社交平台动态发布:允许用户快速发布内容,后续通过异步复制保证数据最终一致。
- 技术实现:
- 使用最终一致性模型(如 Amazon DynamoDB),通过版本控制、冲突检测和合并机制解决数据不一致问题。
- 在网络分区时,各分区继续服务,分区恢复后进行数据同步。
3. 放弃 P(分区容错性)
- 场景:在单机或局域网环境中,假设网络不会发生分区,可同时保证 C 和 A。
- 案例:传统单体应用数据库(如 MySQL 主从复制),在网络稳定的局域网环境中运行。
- 局限性:现实中网络故障无法完全避免,放弃 P 实际是假设分区不会发生,不适用于分布式系统。
我的项目选择
在实际项目中,需根据业务特性选择侧重点:
- 支付系统:选择 CP,宁可拒绝交易也不能出现资金不一致。例如,使用两阶段提交(2PC)或 TCC(Try-Confirm-Cancel)模式保证强一致性。
- 内容推荐系统:选择 AP,允许推荐结果存在短暂延迟,但要保证系统始终可用。例如,使用 Redis 缓存用户行为数据,通过异步同步到数据库。
- 配置中心:选择 CP,确保所有服务节点获取的配置一致。例如,使用 Zookeeper 或 etcd 存储配置,当发生分区时优先保证数据一致性。
权衡技巧:
- 对关键业务(如订单、支付)采用 CP,对非关键业务(如日志、统计)采用 AP。
- 通过 “读写分离” 策略,读操作采用 AP(保证可用性),写操作采用 CP(保证一致性)。
- 使用 “最终一致性” 结合业务补偿机制,在保证可用性的前提下,通过定时对账、人工干预等方式解决数据不一致问题。
简述 RPC(远程过程调用)的原理和流程。
RPC(Remote Procedure Call)是一种允许程序调用远程服务器上的方法的技术,使开发者无需关心网络通信细节,如同调用本地方法一样简洁。其核心原理是通过序列化、网络传输、反序列化实现进程间通信,主要流程包括以下步骤:
1. 客户端调用
客户端代码直接调用本地代理对象(Stub)的方法,传递参数。例如:
// 客户端代码
UserService userService = new UserServiceProxy(); // 本地代理
User user = userService.getUser(1001); // 调用远程方法
2. 请求封装(序列化)
Stub 将方法名、参数等信息封装为请求对象,并序列化为二进制数据。常见序列化协议包括 JSON、Protobuf、Thrift 等。例如:
// 请求封装示例
Request request = new Request();
request.setMethodName("getUser");
request.setParameters(new Object[]{1001});
byte[] requestData = serializer.serialize(request); // 序列化为字节流
3. 网络传输
客户端通过网络将请求数据发送至服务端。传输协议可基于 TCP、UDP 或 HTTP,常见实现包括:
- 基于 TCP:如 gRPC、Dubbo,性能较高,适合内部服务调用。
- 基于 HTTP:如 REST API,跨语言兼容性好,适合对外服务。
4. 服务端接收与解析
服务端接收到请求数据后,反序列化为请求对象,根据方法名查找对应的服务实现:
// 服务端处理示例
Request request = deserializer.deserialize(requestData, Request.class);
Method method = serviceClass.getMethod(request.getMethodName(), paramTypes);
Object result = method.invoke(serviceInstance, request.getParameters()); // 执行本地方法
5. 结果返回
服务端将方法执行结果封装为响应对象,序列化为二进制数据并通过网络返回给客户端:
// 响应封装示例
Response response = new Response();
response.setResult(result);
byte[] responseData = serializer.serialize(response);
6. 客户端接收与解析
客户端接收响应数据,反序列化为结果对象并返回给调用者:
// 客户端处理响应
Response response = deserializer.deserialize(responseData, Response.class);
return response.getResult(); // 返回结果给调用者
关键组件
- 服务注册与发现:服务端将服务信息注册到注册中心(如 Consul、Nacos),客户端通过注册中心获取服务地址,实现动态负载均衡。
- 序列化协议:决定数据传输的效率和兼容性,如 Protobuf 比 JSON 更高效但需预定义 schema。
- 网络传输层:处理连接管理、超时重试、心跳检测等,如 Netty 提供高性能的网络通信能力。
- 代理生成:通过代码生成工具(如 Protobuf 的 protoc)或动态代理(如 Java 的 InvocationHandler)生成客户端 Stub 和服务端 Skeleton。
典型框架
- gRPC:基于 HTTP/2 和 Protobuf,支持多语言,性能高,适合微服务内部通信。
- Dubbo:阿里巴巴开源的高性能 RPC 框架,支持多种注册中心和序列化协议,功能丰富。
- Thrift:Facebook 开源的跨语言 RPC 框架,支持多种传输协议和序列化方式。
- Spring Cloud OpenFeign:基于 HTTP 协议,简化 RESTful API 调用,与 Spring 生态集成紧密。
优缺点
优点:
- 简化分布式系统开发,降低网络编程复杂度。
- 提高代码可维护性,调用方式与本地方法一致。
- 支持服务间的解耦和水平扩展。
缺点:
- 网络延迟引入额外开销,性能低于本地调用。
- 故障排查复杂,需考虑网络分区、超时、重试等问题。
- 依赖服务注册中心,存在单点故障风险(需高可用设计)。
与 REST API 的对比
- RPC:更适合内部服务间的高频调用,性能更高,协议更紧凑。
- REST API:更适合对外服务,基于 HTTP 协议,跨语言和跨平台兼容性好。
总结:RPC 通过封装网络通信细节,使分布式系统中的服务调用更简单高效,是构建微服务架构的核心技术之一。选择合适的 RPC 框架需综合考虑性能需求、语言兼容性、生态成熟度等因素。
Netty 框架的核心原理是什么?
Netty 是基于 Java 的高性能网络编程框架,其核心原理围绕事件驱动模型、异步非阻塞 IO和灵活的组件设计展开。
Netty 的核心架构包含以下关键组件:
- EventLoopGroup:由多个 EventLoop 组成的线程池,负责处理 IO 事件。通常分为 Boss 组和 Worker 组,前者用于接收客户端连接,后者用于处理连接后的读写操作,实现了主从 Reactor 模式。
- Channel:代表与客户端的连接,是 Netty 中数据传输的载体,封装了 Socket 连接的操作,并绑定唯一的 EventLoop 以保证线程安全。
- ChannelHandler:业务逻辑的核心处理器,通过链式结构(ChannelPipeline)对数据进行拦截和处理。用户自定义的 Handler 可通过重写
channelRead等方法实现编解码、业务逻辑等功能。 - ChannelPipeline:管理 ChannelHandler 的链表,数据在其中按顺序流动,入站(Inbound)和出站(Outbound)事件分别沿链表正向和反向传播,支持动态添加或删除处理器,提升灵活性。
- ByteBuf:Netty 自定义的缓冲区,相比 Java 原生 ByteBuffer 更易用,提供读写索引分离、自动扩容等特性,减少内存拷贝和 GC 压力。
Netty 的异步特性通过 Future 和 Promise 实现。所有 IO 操作均为异步,立即返回未完成的 Future,通过回调(addListener)或阻塞(sync)方式获取结果,避免线程阻塞,提升吞吐量。
在 IO 模型层面,Netty 基于 Java NIO(Non-blocking IO),利用 Selector 实现多路复用,一个 EventLoop 可管理多个 Channel 的 IO 事件,通过轮询机制处理就绪事件,大幅降低线程数量和上下文切换开销。
此外,Netty 提供了编解码框架(如 ByteToMessageDecoder),简化了协议解析和组装流程,支持自定义协议(如 HTTP、WebSocket)的处理。其内存管理机制(如对象池、直接内存分配)进一步优化了性能,减少内存碎片和分配开销。
总结来看,Netty 通过事件驱动的 Reactor 模式、灵活的组件架构、高效的异步 IO 和内存管理,构建了高性能、可扩展的网络通信基础,广泛应用于 RPC 框架、消息中间件、实时通信等场景。
TCP 三次握手的过程是什么?为什么需要三次握手?
TCP 三次握手是建立可靠连接的核心机制,其过程如下:
- 第一次握手(客户端发起 SYN):客户端向服务器发送带有
SYN(同步标志位)的数据包,其中包含客户端生成的初始序列号Seq = x,表示客户端请求建立连接。 - 第二次握手(服务器确认 SYN+ACK):服务器收到客户端的 SYN 包后,返回带有
SYN和ACK(确认标志位)的数据包,其中Seq = y(服务器初始序列号),Ack = x + 1(确认客户端序列号有效),表示服务器同意建立连接。 - 第三次握手(客户端确认 ACK):客户端收到服务器的 SYN+ACK 包后,发送带有
ACK的数据包,Seq = x + 1,Ack = y + 1,表示客户端确认收到服务器的响应,连接正式建立。
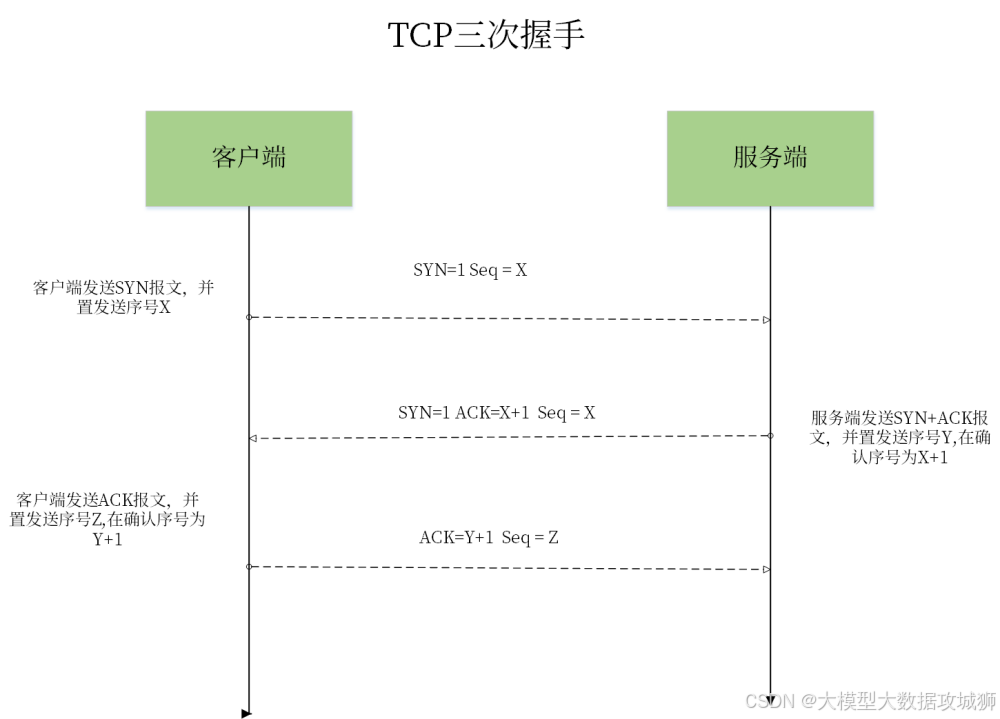
需要三次握手的原因主要与可靠连接的双向确认和防止历史连接初始化有关:
-
双向连通性验证:
第一次握手后,服务器知道客户端具备发送能力,但不确定客户端是否具备接收能力(因服务器的 SYN+ACK 可能在传输中丢失);
第二次握手后,客户端知道服务器具备接收和发送能力,但服务器仍不确定客户端是否收到第二次握手的响应(可能导致服务器单方面认为连接已建立);
第三次握手后,服务器通过客户端的 ACK 确认客户端已收到响应,至此双方均确认对方的收发能力正常,确保连接可靠。 -
避免历史连接的干扰:
若客户端因网络延迟重发旧的 SYN 包(如前一次连接的残留包),服务器返回 SYN+ACK 后,客户端会发现当前序列号与预期不符,从而拒绝该连接,避免错误初始化连接状态,防止资源浪费。
常见误区与细节:
- 第三次握手的 ACK 若丢失,服务器会超时重传 SYN+ACK,直至客户端重新确认或连接超时。
- 三次握手期间,双方的状态变化为:
- 客户端:
CLOSED → SYN_SENT → ESTABLISHED - 服务器:
CLOSED → LISTEN → SYN_RCVD → ESTABLISHED
- 客户端:
- 握手过程中,初始序列号(ISN)由随机函数生成,目的是防止序列号被猜测,增强安全性(尤其在防止 SYN 泛洪攻击场景中)。
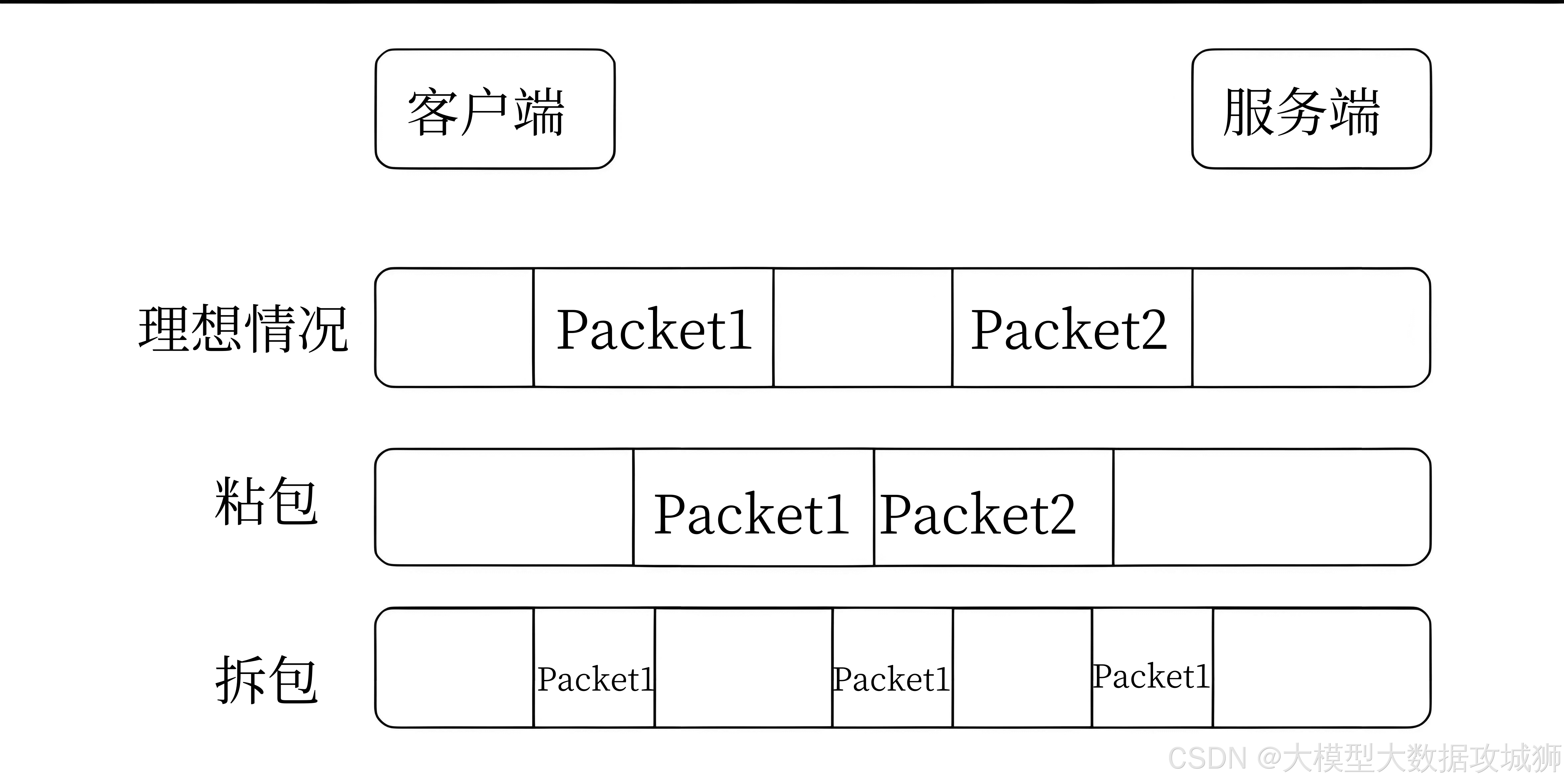
如何解决 TCP 粘包和拆包问题?
TCP 是面向字节流的协议,发送方和接收方的缓冲区可能导致数据边界模糊,产生粘包(多个数据包合并成一个)或拆包(一个数据包被分成多个)问题。解决该问题的核心是明确数据边界,常见方案如下:
1. 固定长度消息
定义每条消息的长度为固定值,接收方每次读取固定长度的字节作为一条完整消息。
适用场景:消息长度已知且固定(如某些通信协议)。
示例:
若规定每条消息为 1024 字节,接收方每次从缓冲区读取 1024 字节,不足时等待后续数据。
局限性:无法处理变长消息,可能浪费空间(如短消息需填充无效字节)。
2. 分隔符标识边界
在消息末尾添加特殊分隔符(如 \r\n、EOF 等),接收方通过扫描分隔符判断消息结束。
适用场景:文本协议(如 HTTP、FTP)或自定义简单协议。
示例:
HTTP 请求头通过 \r\n 分隔字段,消息体通过 Content-Length 或 Transfer-Encoding: chunked 配合分隔符标识边界。
注意事项:需确保分隔符不出现在消息正文中,否则可能误判边界(可通过转义处理)。
3. 消息长度前缀
在消息头部添加长度字段(如 4 字节整数表示后续消息体的字节数),接收方先读取长度字段,再按长度读取完整消息。
适用场景:二进制协议或需要高效解析的场景(如 Protobuf、Thrift)。
实现步骤:
- 发送方:将消息体序列化后,计算长度并写入头部(通常为网络字节序),组合成完整数据包发送。
- 接收方:
- 读取固定长度的头部(如 4 字节),解析出消息体长度
len; - 从缓冲区读取
len字节作为消息体。
示例代码(伪代码):
- 读取固定长度的头部(如 4 字节),解析出消息体长度
// 发送方
byte[] body = "Hello, Netty!".getBytes();
ByteBuffer buffer = ByteBuffer.allocate(4 + body.length);
buffer.putInt(body.length); // 写入长度字段
buffer.put(body);
channel.writeAndFlush(buffer); // 接收方(ChannelHandler)
private int readLength; // 记录待读取的长度
private byte[] bodyBuffer; // 存储消息体 @Override
public void channelRead(ChannelHandlerContext ctx, Object msg) { ByteBuf in = (ByteBuf) msg; if (readLength == 0) { if (in.readableBytes() >= 4) { // 先读取长度字段 readLength = in.readInt(); bodyBuffer = new byte[readLength]; } } if (readLength > 0 && in.readableBytes() >= readLength) { in.readBytes(bodyBuffer); // 读取完整消息体 processMessage(bodyBuffer); // 处理消息 readLength = 0; // 重置状态 }
}
优势:支持变长消息,解析效率高,无需担心分隔符冲突,是最常用的方案之一。
4. 组合使用多种方式
复杂场景下可结合多种策略。例如:
- 先通过固定长度字段确定消息总长度,再通过分隔符处理子字段(如某些混合协议)。
- 使用协议缓冲区(如 Protobuf),其序列化格式自带字段长度标识,天然支持拆包。
核心原理总结
解决粘包 / 拆包的本质是在应用层人为定义数据边界,让接收方能够准确识别每条消息的起始和结束位置。选择方案时需结合协议类型(文本 / 二进制)、消息特性(固定长度 / 变长)和性能需求,其中消息长度前缀法因通用性和高效性成为主流选择,尤其在 Netty 等框架中通过 LengthFieldBasedFrameDecoder 组件直接支持。
从浏览器发起 HTTP 请求到收到响应的完整流程是什么?(针对 HTTPS 连接)
HTTPS 是基于 HTTP 的安全通信协议,通过 TLS/SSL 层加密传输数据。从浏览器发起请求到收到响应的完整流程涉及网络层、传输层、应用层的多重交互,具体步骤如下:
1. 域名解析(DNS 解析)
浏览器首先解析目标 URL 中的域名(如 www.example.com):
- 先查询本地 DNS 缓存,若未命中则向本地 DNS 服务器(如运营商提供的 DNS)发起递归查询;
- 本地 DNS 服务器通过迭代查询根 DNS 服务器、顶级域名(TLD)服务器、权威 DNS 服务器,最终获取域名对应的 IP 地址。
2. 建立 TCP 连接(三次握手)
获取 IP 地址后,浏览器与服务器建立 TCP 连接(见前面对三次握手的详细描述)。
- 客户端(浏览器)发送 SYN 包,服务器返回 SYN+ACK,客户端确认 ACK,连接建立完成。
3. 协商 TLS/SSL 连接(TLS 握手)
HTTPS 的核心安全机制通过 TLS 握手实现,流程如下:
- 客户端发起 ClientHello:
客户端发送包含支持的 TLS 版本、加密算法列表(Cipher Suite)、随机数(Client Random)等信息的请求。 - 服务器响应 ServerHello:
服务器选择双方支持的最高 TLS 版本、加密算法,返回服务器随机数(Server Random)和服务器证书(含公钥)。 - 客户端验证证书:
浏览器通过内置的 CA 根证书验证服务器证书的有效性(检查颁发者、有效期、域名是否匹配等),若验证失败则提示用户风险。 - 生成预主密钥(Pre-Master Secret):
客户端生成随机的预主密钥,用服务器证书中的公钥加密后发送给服务器。 - 计算会话密钥:
客户端和服务器根据 Client Random、Server Random、Pre-Master Secret,通过相同算法生成对称加密的会话密钥(用于后续数据加密)。 - 验证密钥交换完整性:
双方通过密钥生成哈希值,确保握手过程未被篡改(通过 TLS 的完整性校验机制)。
4. 发送 HTTP 请求
TLS 握手完成后,浏览器通过加密通道发送 HTTP 请求:
- 请求包含方法(如 GET/POST)、URL、请求头(如
User-Agent、Cookie)和请求体(若有)。 - 数据经 TLS 层加密后,由 TCP 层分段传输至服务器。
5. 服务器处理请求并返回响应
服务器接收加密的请求数据后:
- 通过 TLS 层解密得到原始 HTTP 请求;
- 解析请求路径,调用后端服务处理业务逻辑(如查询数据库、生成动态内容);
- 构造 HTTP 响应(状态码、响应头、响应体),经 TLS 加密后返回给浏览器。
6. 浏览器解析并渲染响应
浏览器接收加密的响应数据:
- 通过 TLS 层解密得到原始响应内容;
- 解析响应头(如
Content-Type确定内容类型):- 若为 HTML,触发渲染引擎解析 DOM 树、计算样式、布局渲染;
- 若为 JS/CSS/ 图片等资源,发起异步请求加载并缓存;
- 处理响应中的
Set-Cookie头,更新本地 Cookie。
7. 关闭连接
- 若
Connection头为keep-alive,则保持 TCP 连接复用(HTTP/1.1 默认为长连接); - 若为
close或主动断开(如超时),则通过 TCP 四次挥手关闭连接。
关键细节与安全机制
- 证书链验证:服务器证书可能由中间 CA 签发,浏览器需逐级验证证书链直至根 CA,确保信任路径完整。
- 加密算法协商:TLS 握手期间双方通过
Cipher Suite协商确定加密算法(如 RSA 用于密钥交换,AES 用于数据加密,HMAC 用于完整性校验)。 - 会话重用:通过
Session ID或Session Ticket机制,避免重复进行完整 TLS 握手,提升后续请求性能。
HTTPS 通过结合对称加密(高效)和非对称加密(安全认证),确保数据传输的机密性、完整性和身份验证,是现代 Web 安全的基石。
HTTPS 如何通过数字证书防止中间人攻击?
HTTPS 通过数字证书构建信任链和公钥认证机制,有效防止中间人(MITM)篡改通信内容或冒充服务器身份,其核心原理如下:
1. 数字证书的本质与结构
数字证书是由证书颁发机构(CA)签发的电子文件,包含以下关键信息:
- 证书持有者公钥:服务器用于加密数据的公钥。
- 持有者标识:如域名(
www.example.com)、组织名称等。 - CA 签名:CA 使用自身私钥对证书内容的哈希值进行签名,确保证书未被篡改。
- 有效期:证书的有效时间范围,过期后需重新申请。
证书结构示例(简化):
证书内容:
- 版本号
- 序列号
- 签名算法
- 颁发者(CA 信息)
- 主体(服务器域名等)
- 公钥
- 有效期
- 扩展字段(如用途限制) 签名:CA私钥加密(SHA-256(证书内容))
2. 防止中间人攻击的核心流程
(1) 证书颁发与信任链建立
- 服务器申请证书:
服务器生成公私钥对,将公钥和域名等信息提交给 CA。CA 通过域名验证(如 DNS 验证、文件验证)确认服务器对域名的控制权,然后用 CA 私钥为服务器证书签名,生成数字证书。 - 浏览器内置根证书:
操作系统和浏览器预先内置受信任的根 CA 证书(如 DigiCert、Let’s Encrypt),这些根证书的公钥用于验证下游证书的合法性,形成信任链(根 CA → 中间 CA → 服务器证书)。
(2) TLS 握手阶段的证书验证
在 HTTPS 连接的 TLS 握手过程中,浏览器通过以下步骤验证服务器证书:
- 接收服务器证书:服务器在
ServerHello阶段返回自身证书(可能包含中间 CA 证书链)。 - 构建信任链:
- 浏览器从服务器证书中提取颁发者信息,查找是否有对应的 CA 证书(内置根证书或已信任的中间证书)。
- 若颁发者是中间 CA,继续向上验证直至根 CA,确保证书链完整。
- 验证签名有效性:
- 浏览器使用 CA 公钥解密证书中的签名,得到证书内容的哈希值(预期值)。
- 浏览器对收到的证书内容重新计算哈希值(实际值),对比两者是否一致。若一致,说明证书未被篡改。
- 检查域名匹配:
- 验证证书中的「主体备用名」(SAN)或「公用名」(CN)是否包含当前访问的域名,防止证书被用于其他域名(如钓鱼网站)。
- 检查有效期:确认证书未过期,且当前时间在有效期内。
(3) 密钥交换的安全性
若证书验证通过,浏览器生成预主密钥(Pre-Master Secret),用服务器证书中的公钥加密后发送给服务器。由于中间人无法伪造有效的服务器证书(无 CA 私钥签名),即使拦截通信,也无法获取服务器公钥,因此无法解密预主密钥,从而无法计算出最终的会话密钥,确保后续通信加密的安全性。
3. 中间人攻击的失败场景
假设中间人试图冒充服务器:
- 场景 1:中间人伪造证书
中间人自行生成证书(包含伪造的公钥和域名),但由于未通过 CA 签名,浏览器验证签名时会失败,提示「证书不受信任」。 - 场景 2:中间人使用合法证书但域名不匹配
若中间人使用其他域名的合法证书(如example.com的证书用于attack.com),浏览器检查域名时会发现不匹配,拒绝建立连接。 - 场景 3:中间人劫持证书链
中间人若能篡改证书链(如替换为伪造的中间 CA),但浏览器内置的根 CA 公钥未被篡改,仍可检测到证书链异常。
4. 补充机制:OCSP 与 CRL
为应对证书中途被吊销的情况,HTTPS 还可结合以下机制:
- OCSP(在线证书状态协议):浏览器向 CA 发送请求,查询证书是否被吊销(实时验证)。
- CRL(证书吊销列表):CA 定期发布吊销证书列表,浏览器下载后本地校验(存在滞后性)。
断点续传的原理是什么?
断点续传的核心思想是将一个大文件的传输过程拆分成多个片段,允许在传输中断后从上次结束的位置继续传输,避免重复下载或上传整个文件。这一机制主要通过以下技术实现:
首先,客户端与服务器需要协商支持断点续传的协议,常见于 HTTP/1.1 及以上版本,通过请求头中的Range字段指定需要传输的字节范围,服务器响应时返回206 Partial Content状态码,并在Content-Range头中告知实际传输的范围。例如,客户端请求Range: bytes=1000-表示从第 1000 字节开始获取数据,服务器则返回该位置之后的内容。
其次,需要记录断点位置。客户端在传输过程中实时记录已传输的字节数,通常保存到本地文件或数据库中。若传输中断(如网络断开、程序崩溃),重启后读取记录的位置,重新向服务器发起带Range的请求。服务器端则需根据请求定位到对应的文件偏移量,继续发送数据。
此外,文件分块处理是关键。大文件会被分割成若干固定大小的块(如 1MB / 块),每个块有唯一标识。客户端下载或上传每个块后,校验其完整性(如通过 MD5、SHA 哈希值),确保数据无误后才标记为完成。若某个块传输失败,只需重新传输该块,而非整个文件。
在实现时需注意以下问题:
- 并发控制:多个线程或连接同时传输不同块时,需避免资源竞争,确保块按顺序拼接或合并。
- 状态一致性:服务器需维护每个文件的传输状态,防止重复处理同一请求或块数据错乱。
- 安全性:对于敏感文件,需在断点续传过程中保持加密传输(如 HTTPS),避免中途数据泄露。
断点续传在网盘、在线视频下载、大文件上传等场景中广泛应用。例如,用户下载电影时中途暂停,下次可从暂停处继续下载;云存储服务上传大文件时,支持中断后继续上传,节省时间和流量。其核心优势在于提升传输效率、容错性和用户体验,尤其适用于网络不稳定或大文件传输的场景。
如何设计一个高并发的秒杀系统?如何保证优惠券库存的一致性?
设计高并发秒杀系统需从流量拦截、业务优化、资源隔离等多维度入手,核心目标是在短时间内处理海量请求,避免系统崩溃,并确保库存数据的一致性。以下是关键设计要点:
流量层优化
-
前端限流与缓存
- 在客户端(如 APP、网页)增加防抖机制,限制用户快速点击(如按钮点击后禁用一段时间),减少无效请求。
- 提前将秒杀活动信息(如开始时间、商品详情)缓存到前端,避免大量请求冲击后端获取基础数据。
-
网关层流量过滤
- 使用 Nginx 或 Spring Cloud Gateway 作为入口,设置请求频率限制(如同一 IP 每秒最多 5 次请求),拦截恶意刷接口的行为。
- 采用令牌桶、漏桶算法实现限流,确保进入后端的请求量在系统承载范围内。
- 对静态资源(如商品图片)使用 CDN 加速,减少服务器压力。
业务层削峰填谷
-
消息队列缓冲请求
- 将用户的秒杀请求先发送到消息队列(如 RabbitMQ、Kafka),通过队列削峰,避免瞬间高并发冲击数据库。消费者(后台服务)按队列顺序处理请求,控制处理速度。
- 需注意队列长度限制,若队列积压超过阈值,可拒绝后续请求并返回 “活动太火爆” 等提示,防止内存溢出。
-
库存预热与预扣
- 提前将库存数量加载到 Redis 等缓存中,避免频繁访问数据库。用户下单时,先在缓存中预扣库存(如使用
INCRBY负数操作),成功后再异步更新数据库。 - 缓存中的库存需设置合理的过期时间,并通过分布式锁(如 Redisson)保证同一时刻只有一个线程操作库存,避免超卖。
- 提前将库存数量加载到 Redis 等缓存中,避免频繁访问数据库。用户下单时,先在缓存中预扣库存(如使用
数据层一致性保障
-
数据库乐观锁
- 在库存表中增加
version字段,更新库存时通过UPDATE stock SET count=count-1, version=version+1 WHERE id=? AND version=?语句,利用数据库乐观锁机制确保库存扣减的原子性,防止并发更新导致的数据不一致。
- 在库存表中增加
-
异步对账与补偿
- 记录所有订单操作日志,通过定时任务或消息监听,对比缓存库存与数据库库存,发现差异时自动触发补偿逻辑(如回滚无效订单、补扣库存)。
- 对于支付环节,采用异步回调机制,确保支付结果与库存状态最终一致。若支付成功但库存扣减失败,需人工介入处理。
优惠券库存一致性方案
- 独立库存表:优惠券库存单独存储在一张表中,字段包括
coupon_id、total(总库存)、remaining(剩余库存),避免与商品库存混合导致锁冲突。 - 分布式锁控制:在扣减优惠券库存时,使用 Redis 分布式锁(如
SET key value NX PX 5000)确保同一用户或同一时刻只有一个请求操作库存,锁的有效时间需大于业务处理耗时,防止锁提前释放导致重复扣减。 - 库存预扣与释放:用户进入秒杀排队时,先在缓存中预占库存(如设置
coupon:user:123为true),若用户超时未支付,则释放预占库存并删除锁,通过定时任务扫描超时订单实现。
其他关键优化
- 无状态服务:后端服务设计为无状态,便于水平扩展,通过负载均衡(如 LVS、Nginx)分配流量。
- 熔断与降级:当系统压力超过阈值时,自动熔断非核心业务(如用户积分记录),优先保证秒杀主流程正常运行,待流量下降后恢复。
- 压测与监控:通过 JMeter、Gatling 等工具模拟高并发场景,提前发现瓶颈(如数据库连接不足、缓存穿透);实时监控服务器 CPU、内存、队列积压量、接口响应时间等指标,及时调整资源配置。
通过以上分层设计,可有效应对秒杀场景的高并发挑战,同时借助缓存、锁机制、数据库事务等技术手段,确保优惠券库存的一致性。
分布式 ID 的实现方案有哪些?
分布式 ID 需满足全局唯一性、递增性、高可用性、低延迟等特性,常见实现方案包括:
UUID(通用唯一识别码)
- 原理:基于 MAC 地址、时间戳、随机数生成 128 位字符串(如
550e8400-e29b-41d4-a716-446655440000),通过算法保证唯一性。 - 优点:本地生成,无需远程调用,性能高;实现简单,跨语言支持好。
- 缺点:长度较长(36 字节),占用存储空间大;无序性导致索引效率低(如 MySQL 主键索引性能下降);不包含业务含义。
- 适用场景:非主键场景(如日志 ID)、对性能要求极高且不要求有序的场景。
数据库自增主键(单库 / 多库模式)
- 单库自增:利用数据库自增字段(如 MySQL 的
AUTO_INCREMENT)生成 ID,单机场景下唯一且递增。- 缺点:无法满足分布式需求,需配合分库分表扩展。
- 多库号段模式:
- 预先分配号段给每个数据库节点,例如节点 1 分配
1-1000,节点 2 分配1001-2000,每个节点在自己的号段内自增。 - 优点:减少数据库压力,支持水平扩展;ID 有序,利于索引优化。
- 缺点:号段预分配可能导致浪费(如节点未用完号段即扩容);需定期调整号段范围,存在维护成本。
- 预先分配号段给每个数据库节点,例如节点 1 分配
- 适用场景:中小规模分布式系统,对 ID 有序性要求高的场景(如订单号)。
Redis 生成 ID
- 原理:利用 Redis 的
INCR或INCRBY命令原子性递增生成 ID,可通过设置不同的 key 前缀区分业务类型(如order_id、user_id)。 - 优点:性能高(Redis 单线程处理,QPS 可达数万);支持自定义格式(如
业务前缀+时间戳+递增数);可通过集群模式扩展。 - 缺点:依赖 Redis 服务,需保证其高可用性;若 Redis 宕机且未持久化,可能导致 ID 重复(可通过 RDB/AOF 持久化缓解)。
- 示例代码:
// 使用Jedis获取ID Jedis jedis = new Jedis("localhost"); String orderId = "ORDER_" + jedis.incr("order_id");
雪花算法(Snowflake)
- 原理:由 Twitter 开源的算法,生成 64 位二进制数,结构如下:
- 1 位符号位:固定为 0(保证 ID 为正数)。
- 41 位时间戳:精确到毫秒,支持约 69 年(2^41/1000/60/60/24/365≈69 年)。
- 10 位工作机器 ID:其中 5 位用于数据中心 ID,5 位用于机器 ID,支持 1024 个节点。
- 12 位序列号:同一毫秒内最多生成 4096 个 ID。
- 优点:高性能(单机每秒可生成数百万 ID);ID 有序,便于分页和排序;可根据业务需求调整各部分位数(如减少机器 ID 位数,增加序列号位数)。
- 缺点:强依赖系统时钟,若节点时钟回退可能导致 ID 重复(需通过时钟校验和补偿机制解决);分布式部署时需提前规划机器 ID 分配。
- 适用场景:高并发分布式系统,如电商订单、用户注册等场景。
美团 Leaf(开源方案)
- 分层设计:
- 号段模式:通过数据库预分配号段(如每次获取 1000 个 ID),缓存到内存中,本地自增使用,减少对数据库的频繁访问。
- 雪花模式:支持通过 Zookeeper 或 Redis 生成分布式 ID,适用于对时钟敏感的场景。
- 优点:结合号段和雪花算法的优势,既保证高性能,又支持 ID 有序性;提供可视化的管理平台,方便监控和配置。
- 适用场景:大规模互联网系统,需要灵活切换 ID 生成策略的场景。
其他方案
- UUID 的变种(如 TimeUUID):结合时间戳的 UUID,部分解决无序问题,但仍存在长度和索引问题。
- MongoDB 的 ObjectId:由 12 字节组成(时间戳 + 机器 ID + 进程 ID + 计数器),适用于 MongoDB 数据库,但跨系统使用需转换。
方案对比:
| 方案 | 唯一性 | 有序性 | 性能 | 依赖组件 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|---|
| UUID | 高 | 无 | 高 | 无 | 低 | 非主键、性能优先场景 |
| 数据库自增 | 高 | 高 | 中 | 数据库 | 中 | 中小规模、有序性场景 |
| Redis | 高 | 高 | 极高 | Redis | 中 | 高并发、需自定义格式场景 |
| 雪花算法 | 高 | 高 | 极高 | 系统时钟 | 高 | 大规模分布式系统 |
| Leaf | 高 | 可选 | 极高 | 数据库 / Redis/ZK | 高 | 复杂业务场景 |
选择时需根据业务规模、性能需求、ID 格式要求综合考量。例如,电商订单系统通常采用雪花算法或 Leaf,而日志系统更适合 UUID。
如何保证分布式系统中消息的可靠性和幂等性?
在分布式系统中,消息的可靠性(确保消息不丢失、不重复)和幂等性(多次处理同一消息结果一致)是关键挑战,需结合消息中间件特性和业务逻辑实现。
一、消息可靠性保障
消息传递过程可分为生产者发送消息、消息中间件存储消息、消费者处理消息三个阶段,每个阶段均需防丢失策略。
1. 生产者端:确保消息成功发送
-
同步发送与回调机制
生产者发送消息时采用同步模式(如 RabbitMQ 的confirm机制),消息到达 Broker 后,Broker 会返回确认(ACK)或失败(NACK)信号。生产者收到 NACK 时,可重试发送或记录到数据库待后续补偿。// RabbitMQ示例:开启confirm模式并监听回调 channel.confirmSelect(); channel.addConfirmListener(new ConfirmListener() { public void handleAck(long deliveryTag, boolean multiple) { // 消息成功发送,记录日志或删除本地缓存 } public void handleNack(long deliveryTag, boolean multiple) { // 消息发送失败,重试或记录到DB retrySend(message); } }); -
事务消息(两阶段提交)
对于需要保证消息与业务操作一致性的场景(如 “下单后发送通知”),可使用事务消息。例如 RocketMQ 的事务消息流程:- 生产者发送半消息(仅存储不投递)到 Broker。
- 生产者执行本地业务(如创建订单)。
- 根据业务执行结果,生产者通知 Broker 提交或回滚半消息:
- 提交:Broker 将消息投递到消费者。
- 回滚:Broker 删除半消息,不触发消费。
- 若生产者未及时响应(如崩溃),Broker 通过定时任务回查生产者状态,确保最终一致性。
2. 消息中间件端:确保消息不丢失
-
持久化存储
消息中间件需将消息持久化到磁盘(如 Kafka 的分区日志、RabbitMQ 的队列持久化),并通过副本机制(如 Kafka 的 ISR 副本集、RabbitMQ 的镜像队列)保证数据冗余,防止单节点宕机导致消息丢失。 -
分区与顺序性
对于有顺序要求的消息(如订单状态变更),可通过将同一业务 ID 的消息路由到同一分区(Partition),确保消费者按顺序消费。
3. 消费者端:确保消息被正确处理
-
手动 ACK 机制
消费者收到消息后,先处理业务逻辑,再向 Broker 发送 ACK 确认。若处理过程中崩溃,未发送 ACK 的消息会被 Broker 重新投递(如 RabbitMQ 的basic_consume设置autoAck=false)。// RabbitMQ手动ACK示例 channel.basicConsume(queueName, false, new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { try { processMessage(body); // 处理业务逻辑 channel.basicAck(envelope.getDeliveryTag(), false); // 成功后手动ACK } catch (Exception e) { channel.basicReject(envelope.getDeliveryTag(), true); // 失败后重新入队 } } }); -
重试与死信队列
若消息处理失败,可设置重试机制(如最多重试 3 次),每次重试间隔递增(如 1 秒、5 秒、10 秒)。若多次重试仍失败,将消息路由到死信队列(Dead Letter Queue),由人工处理或触发补偿逻辑。
二、消息幂等性实现
幂等性要求同一消息被多次消费时结果一致,常见实现方式如下:
1. 唯一标识校验
-
业务唯一键:为每条消息分配唯一 ID(如 UUID、订单号),消费者处理消息前,先通过数据库或 Redis 校验该 ID 是否已处理过。
// 伪代码:基于Redis的幂等性校验 String messageId = message.get("messageId"); if (redis.exists("processed:" + messageId)) { return; // 已处理过,直接跳过 } processMessage(message); redis.setex("processed:" + messageId, 3600, "1"); // 设置1小时过期 -
分布式锁:使用 Redis 或 Zookeeper 的分布式锁,确保同一消息在处理过程中被锁定,避免并发消费导致重复处理。
2. 数据库唯一约束
- 在业务表中设置唯一索引(如订单号 + 用户 ID),当重复消息触发插入操作时,数据库会抛出唯一约束异常,消费者捕获异常并忽略重复请求。
CREATE UNIQUE INDEX idx_order_user ON orders(order_no, user_id);
3. 状态机控制
- 业务对象设计为状态机(如订单状态:待支付→已支付→已发货),消费者仅处理符合当前状态的消息。例如,已支付的订单不会再次处理支付消息。
4. 令牌桶(Token Bucket)
- 生产者在发送消息时附带一个令牌(Token),消费者通过令牌校验请求的唯一性,通常与分布式缓存结合使用,适用于接口幂等性场景(如重复提交表单)。
三、综合方案示例(以 RocketMQ 为例)
-
可靠性:
- 生产者开启事务消息,确保本地业务与消息发送一致。
- RocketMQ 启用 DLQ(死信队列)存储重试失败的消息,管理员定期处理。
- 消费者使用手动 ACK,处理成功后提交确认。
-
幂等性:
- 消息携带
transactionId作为唯一标识,消费者通过 Redis 缓存已处理的transactionId,重复消息直接过滤。 - 数据库表对
transactionId设置唯一索引,防止重复插入。
- 消息携带
通过以上措施,可在分布式系统中构建可靠且幂等的消息处理链路,确保业务数据的一致性和正确性。
缓存击穿、穿透的概念是什么?如何解决?
缓存击穿、穿透是分布式缓存中常见的性能问题,二者均会导致大量请求直达数据库,引发性能瓶颈甚至服务雪崩,但成因和解决方案不同。
一、缓存击穿(Cache Breakdown)
概念:
缓存击穿指热点数据在缓存中失效的瞬间(如过期时间到达时),大量并发请求同时访问数据库,导致数据库压力激增。例如,秒杀活动中的商品库存信息是热点数据,若缓存过期时恰好有十万级请求并发访问,会瞬间击穿缓存,冲击数据库。
核心原因:
- 热点数据存在单点失效问题,缓存过期时间集中,导致请求同时落库。
- 未对缓存失效时的请求进行限流或降级。
解决方案:
-
热点数据永不过期
- 对热点数据不设置过期时间,通过异步线程定期更新缓存(如定时任务每 5 分钟刷新数据),或在数据变更时主动更新缓存(如数据库更新后触发消息通知缓存刷新)。
- 优点:彻底避免缓存过期导致的击穿问题;缺点:数据一致性略低(存在缓存与数据库短时间不一致),需结合业务容忍度使用。
-
加锁预加载(Mutex Key)
- 当发现缓存失效时,先通过分布式锁(如 Redis 的
SET key value NX PX 5000)获取锁,只有获得锁的线程执行数据库查询并更新缓存,其他线程等待锁释放后从缓存获取数据。 - 示例代码(伪代码):
String lockKey = "lock:product:123"; if (redis.set(lockKey, "1", NX, PX, 5000)) { // 加锁 try { Object data = db.query("SELECT * FROM products WHERE id=123"); redis.set("product:123", data, EX, 3600); // 更新缓存 } finally { redis.del(lockKey); // 释放锁 } } else { Thread.sleep(100); // 等待重试 return redis.get("product:123"); } - 优点:保证同一时刻只有一个线程查询数据库,避免大量请求同时落库;缺点:引入锁机制,可能增加响应延迟,需合理设置锁过期时间防止死锁。
- 当发现缓存失效时,先通过分布式锁(如 Redis 的
-
缓存时间随机化
- 为同类热点数据设置不同的过期时间(如基础时间 ± 随机偏移量),避免集中失效。例如,商品缓存过期时间设为 300 秒 ±60 秒,使过期时间分散在 240-360 秒之间。
二、缓存穿透(Cache Penetration)
概念:
缓存穿透指请求查询一个不存在的数据,由于缓存和数据库中均无该数据,导致每次请求都直接访问数据库。若恶意用户使用大量不存在的 Key 发起攻击,会导致数据库负载激增,甚至崩溃。例如,黑客利用随机生成的无效用户 ID 频繁请求接口,每次都触发数据库查询。
核心原因:
- 未对无效请求做预处理,直接透传到数据库;
- 缓存无法存储不存在的数据(如 NULL 值),导致重复查询。
解决方案:
-
布隆过滤器(Bloom Filter)拦截
- 在请求进入业务层前,通过布隆过滤器判断 Key 是否存在。若不存在,直接返回 “数据不存在”,避免访问数据库。
- 实现步骤:
- 提前将数据库中存在的 Key 添加到布隆过滤器(如 Redis 的 BitMap 实现)。
- 每次请求先查询布隆过滤器,若 Key 不存在则拒绝请求。
- 优点:空间效率高(相比存储所有 Key),查询速度快;缺点:存在误判率(布隆过滤器可能误判存在,需通过数据库二次校验),不支持删除操作。
-
缓存空值或默认值
- 当查询结果为 NULL 时,在缓存中存储一个特殊值(如
NULL、""),并设置较短的过期时间(如 5 分钟)。后续相同请求可直接从缓存获取,避免多次查询数据库。 - 示例:
Object data = redis.get("user:123456"); if (data == null) { data = db.query("SELECT * FROM users WHERE id=123456"); if (data == null) { redis.set("user:123456", "NULL", EX, 300); // 缓存空值 return "数据不存在"; } redis.set("user:123456", data, EX, 3600); } return data; - 优点:简单易实现;缺点:缓存空值会占用一定内存,需合理设置过期时间,避免脏数据长期存在。
- 当查询结果为 NULL 时,在缓存中存储一个特殊值(如
-
接口校验与限流
- 对请求参数进行合法性校验(如用户 ID 格式、长度限制),拦截明显无效的请求(如 ID 为负数、包含非法字符)。
- 结合网关层限流(如 IP 频率限制),对同一 IP 短时间内的大量请求进行拦截,防止恶意攻击。
三、方案对比与选择
| 问题类型 | 核心特征 | 典型场景 | 优先解决方案 |
|---|---|---|---|
| 缓存击穿 | 热点数据缓存失效瞬间 | 秒杀、抢购活动 | 加锁预加载、热点数据永不过期 |
| 缓存穿透 | 请求不存在的数据 | 恶意攻击、非法参数 | 布隆过滤器、缓存空值 |
实际应用中需结合业务特点综合处理。例如,电商秒杀场景可同时采用 “热点数据永不过期 + 分布式锁预加载” 防止击穿,通过 “参数校验 + 布隆过滤器” 防范穿透。此外,定期监控缓存命中率、数据库慢查询等指标,及时调整策略,也是保障系统稳定性的关键。
Redis 的集群模式如何分配数据?哈希槽的优势是什么?
Redis 集群模式主要通过 哈希槽(Hash Slot) 机制分配数据,典型方案如 Redis Cluster。在该模式中,整个键空间被划分为 16384 个哈希槽,每个节点负责其中一部分槽位。当客户端访问数据时,先通过哈希函数(如 CRC16)计算键的哈希值,再对 16384 取模确定对应的槽位,进而定位到目标节点。这种分配方式实现了数据的分片存储,解决了单机内存限制问题,同时支持动态扩缩容 —— 新增节点时,只需迁移部分槽位及其数据即可,无需重建整个集群。
哈希槽的核心优势体现在以下方面:
- 动态扩展性:节点增删时仅需迁移部分槽位,避免了传统哈希算法(如一致性哈希)中数据重新分布的复杂性,提升了扩缩容效率。
- 负载均衡:通过均匀分配槽位到各节点,确保数据和请求流量在集群中均衡分布,避免单点热点问题。
- 简化路由逻辑:客户端或代理只需维护槽位与节点的映射关系,无需关注具体键的存储位置,降低了路由复杂度。
- 故障转移支持:当节点故障时,集群可将其负责的槽位迁移至其他节点,快速恢复服务可用性,且对客户端透明。
对比传统的分片方式(如按范围分片或固定哈希分区),哈希槽通过离散的槽位分配,避免了数据倾斜和节点负载不均,尤其适合大规模分布式场景。例如,在电商订单系统中,通过哈希槽将不同用户的订单数据分散到多个节点,既能提升查询性能,又便于根据业务增长动态扩展集群。
常见的设计模式有哪些?请举例说明应用场景。
设计模式是软件开发中针对常见问题的通用解决方案,可分为创建型、结构型和行为型三类。以下是几类典型模式及其应用场景:
创建型模式
- 单例模式:确保类仅有一个实例,如日志管理器(
java.util.logging.Logger)、数据库连接池。 - 工厂模式:通过工厂类封装对象创建逻辑,如 Spring 的
BeanFactory根据配置生成 Bean 对象;JDBC 中DriverManager创建数据库连接。 - 建造者模式:分步构建复杂对象,如
StringBuilder拼接字符串、MyBatis 的SqlSessionFactoryBuilder构建会话工厂。
结构型模式
- 代理模式:通过代理对象控制对目标对象的访问,如 MyBatis 的 Mapper 接口代理、Spring AOP 的动态代理实现切面逻辑。
- 装饰器模式:动态添加对象功能,如 Java IO 中的
BufferedInputStream为InputStream添加缓冲功能,不修改原有类结构。 - 适配器模式:转换接口兼容不同实现,如 JDBC 驱动适配不同数据库的协议,或在微服务中转换不同系统的数据格式。
行为型模式
- 观察者模式:定义对象间的依赖关系,当状态变化时通知观察者,如 Android 的
Listener机制、Spring 的事件发布 - 订阅模型。 - 策略模式:封装不同算法并可动态切换,如电商系统中不同促销策略(满减、折扣)的实现,或日志系统中不同级别日志的输出策略。
- 模板方法模式:定义算法骨架,子类实现具体步骤,如 HttpServlet 的
doGet/doPost方法,或 MyBatis 中Executor的查询模板。
应用示例:在电商系统中,订单支付模块可使用 策略模式 支持多种支付方式(支付宝、微信支付、银联),通过统一接口 PaymentStrategy 封装不同实现类,运行时根据用户选择动态切换策略。库存管理模块可采用 观察者模式,当库存数量变化时自动通知物流、客服等模块更新状态。系统配置模块则适合 单例模式,确保全局唯一的配置实例被各组件共享访问。
设计模式的核心价值在于提升代码的可复用性、可维护性和扩展性,开发者需根据具体场景选择合适的模式,避免过度设计。
单例模式的实现方式有哪些?一个类作为单例需要满足什么条件?
单例模式用于确保类在全局只有一个实例,并提供统一访问点。其实现方式可分为 饿汉式、懒汉式、静态内部类式 和 枚举式,核心区别在于实例创建的时机和线程安全的处理。
常见实现方式
-
饿汉式(线程安全)
- 特点:类加载时立即创建实例,基于类加载机制保证线程安全。
- 代码示例:
public class Singleton { private static final Singleton instance = new Singleton(); private Singleton() {} public static Singleton getInstance() { return instance; } } - 场景:适用于实例创建成本低、需提前初始化的场景,如日志工具类。
-
懒汉式(线程不安全)
- 特点:首次调用时创建实例,但多线程环境下可能创建多个实例。
- 代码示例:
public class Singleton { private static Singleton instance; private Singleton() {} public static Singleton getInstance() { if (instance == null) instance = new Singleton(); // 线程不安全 return instance; } } - 改进:通过
synchronized修饰方法实现线程安全(同步懒汉式),但性能较低。
-
静态内部类式(线程安全)
- 特点:利用类加载机制,将实例放在静态内部类中,避免饿汉式的提前创建,同时保证线程安全。
- 代码示例:
public class Singleton { private static class Holder { static final Singleton INSTANCE = new Singleton(); } private Singleton() {} public static Singleton getInstance() { return Holder.INSTANCE; } } - 原理:JVM 保证静态内部类在首次调用时加载,且仅加载一次,确保线程安全。
-
枚举式(线程安全、反序列化安全)
- 特点:通过枚举类型天然支持单例,防止反射攻击和反序列化创建新实例。
- 代码示例:
public enum Singleton { INSTANCE; // 可添加自定义方法 } - 优势:实现简单,推荐用于需要防止反序列化攻击的场景。
单例类的必要条件
- 私有构造函数:阻止外部通过
new关键字创建实例,确保实例只能由类内部创建。 - 静态实例存储:通过静态变量持有唯一实例,提供全局访问点。
- 公共访问方法:通过静态方法(如
getInstance())暴露实例,允许其他类获取。 - 线程安全保障:在多线程环境下,需通过同步机制(如
synchronized、类加载机制)确保实例唯一性。 - 防止反射攻击:部分实现需在构造函数中添加逻辑,防止通过
Reflection突破私有构造函数创建新实例(枚举式天然支持)。 - 防止反序列化攻击:若实例需序列化,需实现
readResolve()方法返回现有实例,避免反序列化时创建新对象(枚举式无需处理)。
应用场景:单例模式适用于资源管理器(如数据库连接池、线程池)、全局配置类、工具类等需要全局唯一控制的场景。选择实现方式时,需权衡初始化时机、线程安全和性能需求,枚举式和静态内部类式是较为推荐的写法。
AOP 使用了哪些设计模式?
AOP(面向切面编程)通过分离业务逻辑和横切关注点(如日志、事务、权限)提升代码复用性,其实现过程中融合了多种设计模式,核心包括以下几种:
代理模式(核心模式)
AOP 的本质是通过代理对象包裹目标对象,在不修改目标类代码的前提下插入切面逻辑。代理模式分为 静态代理 和 动态代理:
- 静态代理:手动创建代理类,实现与目标类相同的接口,在代理方法中调用目标方法并织入切面逻辑。
- 示例:
public interface Service { void doTask(); } public class ServiceImpl implements Service { /* 实现方法 */ } public class ServiceProxy implements Service { private final Service target; public ServiceProxy(Service target) { this.target = target; } public void doTask() { logBefore(); // 前置通知 target.doTask(); logAfter(); // 后置通知 } }
- 示例:
- 动态代理:通过 Java 反射(
Proxy.newProxyInstance)或字节码增强(如 CGLIB)动态生成代理类,无需手动编写代码。- Spring AOP 的选择:若目标对象实现接口,使用 JDK 动态代理;否则使用 CGLIB 生成子类代理。
模板方法模式
AOP 中的通知(Advice)执行流程可视为模板方法的应用。例如,环绕通知(Around Advice)定义了方法执行的模板框架:
public Object around(ProceedingJoinPoint joinPoint) throws Throwable { beforeAdvice(); // 前置逻辑(模板步骤) Object result = joinPoint.proceed(); // 执行目标方法(子类实现) afterAdvice(); // 后置逻辑(模板步骤) return result;
}
模板方法模式确保了切面逻辑的执行顺序(如前置、目标方法、后置),同时允许不同通知类型(如前置、后置、异常通知)自定义具体步骤。
工厂模式
在 AOP 框架中,代理对象的创建通常由工厂类负责。例如,Spring 通过 BeanFactory 或 ApplicationContext 生成代理 Bean,根据配置决定是否为目标 Bean 织入切面逻辑。工厂模式将代理对象的创建细节封装,客户端无需关心具体实现,只需通过工厂获取所需 Bean。
责任链模式
当存在多个切面时,AOP 需按顺序执行这些切面,形成通知链。责任链模式用于管理多个通知的执行顺序,确保每个通知按配置依次调用。例如,Spring AOP 通过 AdvisorChainFactory 构建通知链,每个通知作为链中的节点,依次对目标方法进行增强。
装饰器模式
装饰器模式通过包装对象动态添加功能,与 AOP 的代理机制类似。不同之处在于,装饰器模式更注重 “层层包裹” 的透明性,而 AOP 更关注横切逻辑的分离。例如,一个日志切面可视为对目标方法的 “装饰”,在不改变方法签名的前提下添加日志记录功能。
总结
AOP 的核心实现依赖 代理模式,通过动态代理或静态代理生成增强后的对象;同时借助 模板方法模式 定义通知执行流程,利用 工厂模式 管理代理对象的创建,并通过 责任链模式 协调多个切面的执行顺序。这些模式的组合使用,使得 AOP 能够高效、优雅地实现横切逻辑与业务逻辑的解耦,是面向切面编程思想落地的关键技术支撑。
如何设计一个高可用的系统?Redis 的高可用性体现在哪些方面?
高可用系统的设计原则
高可用系统需通过架构设计和技术手段,确保在部分组件故障时仍能持续提供服务,核心策略包括:
- 冗余与故障转移:关键组件(如服务器、数据库、缓存)采用多实例部署,通过主从、集群或分布式架构实现冗余。当主节点故障时,自动切换至从节点(故障转移),避免单点失效。
- 负载均衡:通过负载均衡器(如 Nginx、LVS)将流量分散到多个实例,避免单个节点过载,并支持动态扩缩容。
- 限流与降级:设置请求阈值,超出时拒绝或排队(限流);故障时自动关闭非核心功能(降级),优先保障核心业务。
- 数据持久化与一致性:重要数据需持久化存储(如数据库落盘、缓存持久化),并通过复制机制(如主从同步、分布式共识算法)保证多副本一致性。
- 监控与告警:实时监控系统指标(如响应时间、吞吐量、错误率),配置告警规则,及时发现并处理潜在问题。
- 自动化运维:通过自动化工具(如 Kubernetes)实现部署、扩缩容、故障转移的自动化,减少人工干预延迟。
应用示例:在电商秒杀系统中,可通过以下方式提升高可用性:
- 前端使用 CDN 缓存静态资源,减轻后端压力;
- 应用层采用多实例部署,通过 Nginx 负载均衡;
- 缓存层使用 Redis 集群,结合主从复制和哨兵机制实现故障转移;
- 数据库采用分库分表 + 读写分离,通过分布式事务框架保证数据一致性;
- 对秒杀接口设置令牌桶限流,防止流量激增导致系统崩溃。
Redis 的高可用性实现
Redis 作为内存数据库,通过多种机制保障高可用性,主要体现在以下方面:
1. 主从复制(Master-Slave Replication)
- 原理:主节点(Master)负责写操作,从节点(Slave)异步复制主节点数据,实现读请求分流。当主节点故障时,可手动或自动提升从节点为新主节点。
- 关键机制:
- 全量复制:从节点首次连接主节点时,主节点生成 RDB 快照并传输给从节点,同时缓存期间写命令,快照完成后重放命令以保证数据一致性。
- 增量复制:主节点将写命令通过缓冲区持续发送给从节点,确保数据实时同步。
- 应用场景:读多写少场景(如缓存、计数器),通过增加从节点提升读性能,同时提供故障转移的冗余备份。
2. 哨兵机制(Sentinel)
- 作用:自动监控主从节点状态,当主节点故障时,自动选举从节点为新主节点,并通知客户端更新连接信息。
- 核心功能:
- 监控:持续检查主节点和从节点是否可达;
- 通知:发现故障时向其他哨兵和客户端发送告警;
- 故障转移:执行自动 failover,选举新主节点并重新配置从节点。
- 部署要求:哨兵需至少部署 3 个实例,通过多数派投票(Quorum)避免脑裂问题。
3. Redis Cluster(集群模式)
- 架构:分布式集群,通过哈希槽(Hash Slot)机制将数据分片存储在多个节点,每个节点负责部分槽位,节点间通过 Gossip 协议通信。
- 高可用特性:
- 数据分片:避免单机内存限制,支持横向扩展;
- 自动故障转移:每个节点有对应的从节点,主节点故障时,从节点自动升级为主节点,槽位映射关系重新分布,客户端通过重定向机制访问新节点。
- 适用场景:大规模数据存储和高并发场景,如社交平台的用户状态缓存、电商的商品浏览记录存储。
4. 持久化机制(RDB/AOF)
- RDB(快照):定期将内存数据写入磁盘生成快照文件,故障后可通过快照恢复数据,适用于大规模数据的快速恢复。
- AOF(日志追加):实时记录写命令到日志文件,故障后通过重放命令恢复数据,数据一致性更高,但恢复速度较慢。
- 组合使用:同时开启 RDB 和 AOF,兼顾恢复速度和数据安全性,避免因单一持久化方式故障导致数据丢失。
5. 内存优化与淘汰策略
- 淘汰策略:当内存不足时,按策略(如 LRU、LFU、TTL)自动删除旧数据,避免因内存溢出导致服务不可用。
- 数据分片:通过集群模式将数据分散到多个节点,避免单个节点内存耗尽,提升整体系统稳定性。
OAuth2 的核心概念和流程是什么?
OAuth2(Open Authorization 2.0)是一种授权框架,用于在不直接暴露用户凭证的前提下,允许第三方应用获取用户资源的访问权限。其核心概念包括:
- 资源所有者(Resource Owner):拥有资源访问权限的用户,如网站用户。
- 客户端(Client):请求访问资源的第三方应用,需提前在授权服务器注册并获取客户端 ID 和密钥。
- 授权服务器(Authorization Server):验证资源所有者身份并发放访问令牌的服务,如 Google、微信的授权中心。
- 资源服务器(Resource Server):存储资源的服务器,通过验证访问令牌来决定是否允许客户端访问资源。
- 访问令牌(Access Token):客户端获取的临时凭证,用于向资源服务器请求资源,通常带有有效期。
- 刷新令牌(Refresh Token):用于在访问令牌过期后重新获取新令牌,避免用户频繁重新授权。
OAuth2 的核心流程基于不同的授权模式,以 ** 授权码模式(Authorization Code Grant)** 为例,流程如下:
- 用户访问客户端:用户通过客户端发起资源访问请求,客户端重定向至授权服务器的登录页面。
- 用户授权:用户在授权服务器页面输入凭证并选择是否授权客户端访问其资源。
- 授权服务器返回授权码:若用户授权,授权服务器生成临时授权码(Authorization Code),并将用户重定向回客户端指定的回调 URL。
- 客户端换取访问令牌:客户端通过授权码和自身凭证(如客户端密钥)向授权服务器发送请求,获取访问令牌和刷新令牌。
- 客户端访问资源:客户端携带访问令牌向资源服务器请求资源,资源服务器验证令牌有效性后返回资源数据。
其他授权模式包括隐式模式(Implicit Grant)(适用于前端应用,直接返回令牌)、密码模式(Resource Owner Password Credentials Grant)(用户直接提供用户名 / 密码,需高度信任客户端)和客户端凭证模式(Client Credentials Grant)(用于客户端自身访问资源,无需用户参与)。OAuth2 通过分层设计解耦了用户认证和资源访问,广泛应用于第三方登录、API 权限控制等场景,确保了安全性和灵活性。
如何统计英文文章中每个单词的出现频率?
统计英文文章中单词的频率需解决文本解析、单词标准化和计数统计三个核心问题,常见实现方式如下:
一、文本解析与单词提取
首先需要将文章内容拆分为独立单词。英文单词通常以空格、标点符号(如逗号、句号、问号)或换行符分隔,可通过正则表达式匹配单词。例如,使用正则表达式\b\w+\b匹配由字母组成的单词(\b为单词边界,\w+匹配一个或多个字母),同时需考虑大小写转换(如将所有单词转为小写或大写,确保 “Hello” 和 “hello” 视为同一单词)。
二、单词标准化处理
处理特殊情况以确保统计准确性:
- 连字符单词:如 “mother-in-law” 可能需保留为一个单词或拆分为多个,需根据业务需求决定(可通过正则表达式
\b[\w-]+\b匹配包含连字符的单词)。 - 撇号单词:如 “don’t” 应视为 “don't” 或转换为 “dont”(需根据实际需求处理缩写)。
- 标点符号附着:单词可能尾随标点(如 “word,”),需通过正则表达式去除末尾标点,例如使用
\b\w+[^\w]?匹配并捕获单词部分。
三、计数与统计
使用数据结构记录单词频率,常见方案包括:
- 哈希表(HashMap):以单词为键,出现次数为值,遍历单词列表时逐个更新计数。
Map<String, Integer> wordCount = new HashMap<>(); for (String word : words) { wordCount.put(word, wordCount.getOrDefault(word, 0) + 1); } - Guava 库的 Multiset:Google Guava 提供的
HashMultiset可直接统计元素出现次数,简化代码逻辑。Multiset<String> wordMultiset = HashMultiset.create(); wordMultiset.addAll(words); // 通过wordMultiset.count(word)获取频率 - 流式处理(Java 8+):利用 Stream API 的
groupingBy和count进行分组统计。Map<String, Long> wordCount = Arrays.stream(words) .collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
四、优化与扩展
- 性能优化:对于超大型文本(如 GB 级),可采用分块读取(逐行或按缓冲区读取)避免内存溢出,或使用多线程并行处理(如 Java 的
Fork/Join框架)。 - 分布式处理:若文本规模极大,可借助 Hadoop MapReduce 或 Spark,将文本分片后在集群中并行统计,最终合并结果。
- 结果展示:统计完成后可按频率排序(如降序排列),输出高频单词列表。使用
TreeMap或流式处理的sorted方法实现排序:wordCount.entrySet().stream() .sorted(Map.Entry.<String, Long>comparingByValue().reversed()) .forEach(entry -> System.out.println(entry.getKey() + ": " + entry.getValue()));
示例流程总结
- 读取英文文章内容,转换为字符串。
- 使用正则表达式分割单词,去除标点并统一大小写。
- 过滤无效单词(如空字符串)。
- 选择合适的数据结构统计频率。
- 按需排序和输出结果。
此方案需注意处理边界情况(如连续标点、多行文本),确保单词提取规则符合业务需求。对于包含非英文内容的文本,可先通过语言检测库(如 Apache Tika)过滤,仅保留英文部分再进行统计。
如何处理一个超大型文件,并在 20 分钟内完成处理和落盘?
处理超大型文件(如数十 GB 至 TB 级)需解决内存限制、IO 性能和处理时间的问题,核心思路是分治策略和流式处理,结合硬件资源优化实现高效处理。以下是具体方案:
一、分块读取与处理
将文件拆分为多个小块,逐块加载到内存处理,避免一次性加载整个文件导致内存溢出。常见方法包括:
- 按固定字节拆分:使用
RandomAccessFile或FileChannel按指定大小(如 1GB)读取数据块,例如:try (RandomAccessFile file = new RandomAccessFile("large_file.txt", "r")) { long blockSize = 1024 * 1024 * 1024; // 1GB long fileLength = file.length(); long offset = 0; byte[] buffer = new byte[(int) Math.min(blockSize, fileLength)]; while (offset < fileLength) { int read = file.read(buffer, 0, (int) Math.min(blockSize, fileLength - offset)); processBlock(buffer, read); // 处理当前块 offset += read; } } - 按行拆分:若文件为文本格式(如日志文件),可使用
BufferedReader逐行读取,避免内存占用过高:try (BufferedReader reader = new BufferedReader(new FileReader("large_file.txt"))) { String line; while ((line = reader.readLine()) != null) { processLine(line); // 逐行处理 } }
二、并行处理与多线程
利用多核 CPU 并行处理多个数据块,缩短处理时间。可通过 Java 线程池(如ExecutorService)分配任务,例如:
- 将文件划分为 N 个块,每个块对应一个处理任务。
- 提交任务到线程池,设置线程数为 CPU 核心数(如
Runtime.getRuntime().availableProcessors())。 - 等待所有任务完成后合并结果。
ExecutorService executor = Executors.newFixedThreadPool(4); // 4核CPU
List<Future<?>> futures = new ArrayList<>();
long fileLength = new File("large_file.txt").length();
long blockSize = fileLength / 4; // 假设分为4块
for (int i = 0; i < 4; i++) { long start = i * blockSize; long end = (i == 3) ? fileLength : (i + 1) * blockSize; futures.add(executor.submit(() -> processBlock(start, end)));
}
executor.shutdown();
try { for (Future<?> future : futures) { future.get(); // 等待所有任务完成 }
} catch (InterruptedException | ExecutionException e) { // 处理异常
}
三、优化 IO 性能
- 使用内存映射文件(MappedByteBuffer):将文件部分区域映射到内存,直接操作虚拟地址,减少 IO 拷贝次数,适用于随机访问场景:
try (FileChannel channel = new FileInputStream("large_file.txt").getChannel()) { MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, 0, fileLength); while (buffer.hasRemaining()) { // 处理buffer中的数据 } } - 批量读写:避免频繁小额 IO 操作,使用较大的缓冲区(如 8KB 或 16KB),减少系统调用次数。
四、算法与数据结构优化
- 流式处理而非缓存中间结果:若处理逻辑允许,逐块处理并直接输出结果到目标文件,避免在内存中累积中间数据。
- 选择轻量级数据结构:例如用数组替代链表,使用
StringBuilder处理字符串拼接,减少内存占用和 GC 压力。 - 压缩与编码:若文件可压缩(如日志文件),先解压缩再处理,或直接处理压缩流(如
GZIPInputStream)。
五、任务优先级与资源监控
- 设置线程优先级:对处理线程设置较高优先级(如
Thread.MAX_PRIORITY),确保 CPU 资源倾斜。 - 监控处理进度:记录已处理数据量和耗时,动态调整块大小或线程数。若处理速度过慢,可增加线程数或扩大块大小(需测试最佳阈值)。
六、落盘策略
处理后的数据需高效写入磁盘,可采用:
- 异步写入:使用单独的线程池将处理结果写入文件,避免阻塞处理线程。
- 分文件存储:将结果按块写入多个临时文件,最后合并为完整文件,减少单文件写入竞争。
- 使用 NIO 的 FileChannel:通过
FileChannel.write()批量写入 ByteBuffer,提升写入性能。
注意事项
- 异常处理:处理过程中若发生错误(如文件损坏、内存不足),需记录断点(如当前偏移量),支持重启后继续处理。
- 数据一致性:若处理逻辑涉及全局状态(如统计总数),需通过线程安全的结构(如
AtomicLong)或锁机制保证一致性。 - 硬件瓶颈:若磁盘 IO 为瓶颈(如机械硬盘),可更换为 SSD 或使用 RAID 加速;若 CPU 为瓶颈,可优化算法或增加集群节点(分布式处理)。
通过分块处理、并行计算、IO 优化和合理的资源调度,可在 20 分钟内完成超大型文件的处理与落盘。实际性能取决于文件格式、处理逻辑复杂度和硬件配置,需通过基准测试调整参数(如块大小、线程数)以达到最优效果。
如何实现一个最小线程数为 1、最大线程数为 10 的线程池?当任务数超过 10 时,如何设计拒绝策略?
在 Java 中,线程池通过ThreadPoolExecutor类实现,可通过构造参数精确控制线程数量和任务处理逻辑。以下是实现最小线程数 1、最大线程数 10 的线程池的步骤,以及任务队列满时的拒绝策略设计:
一、创建线程池实例
使用ThreadPoolExecutor的构造方法,传入以下参数:
- corePoolSize=1:最小线程数,即使线程空闲也不会被销毁(除非设置
allowCoreThreadTimeOut(true))。 - maximumPoolSize=10:最大线程数,当任务队列已满时,最多创建 10 个线程处理任务。
- keepAliveTime:非核心线程(超过 corePoolSize 的线程)的空闲存活时间,例如
30 seconds。 - unit:存活时间单位,如
TimeUnit.SECONDS。 - workQueue:任务队列,用于存储待处理的任务。常用队列包括:
- ArrayBlockingQueue:有界队列,需指定容量(如
new ArrayBlockingQueue<>(50)表示最多缓存 50 个任务)。 - LinkedBlockingQueue:无界队列(容量默认为
Integer.MAX_VALUE),但若使用无界队列,maximumPoolSize将失效,因为任务队列不会满,因此推荐使用有界队列以触发最大线程数。
- ArrayBlockingQueue:有界队列,需指定容量(如
- threadFactory:线程工厂,用于创建线程(可选,默认使用
Executors.defaultThreadFactory())。 - handler:拒绝策略,当任务队列已满且线程数达到最大值时的处理逻辑。
示例代码:
import java.util.concurrent.*; public class CustomThreadPool { public static void main(String[] args) { // 定义任务队列,容量为50 BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(50); // 创建线程池 ThreadPoolExecutor threadPool = new ThreadPoolExecutor( 1, // corePoolSize 10, // maximumPoolSize 30, // keepAliveTime TimeUnit.SECONDS, // unit workQueue, // workQueue new ThreadPoolExecutor.AbortPolicy() // 拒绝策略(默认) ); // 提交任务 for (int i = 0; i < 100; i++) { int taskId = i; threadPool.submit(() -> { System.out.println("Task " + taskId + " is being processed by " + Thread.currentThread().getName()); // 模拟任务处理时间 try { Thread.sleep(100); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } }); } // 关闭线程池 threadPool.shutdown(); }
}
二、拒绝策略(RejectedExecutionHandler)设计
当任务提交时,线程池的处理顺序为:
- 若当前线程数小于
corePoolSize,创建新线程处理任务。 - 若线程数等于
corePoolSize,任务进入队列等待。 - 若队列已满且线程数小于
maximumPoolSize,创建新线程(非核心线程)处理任务。 - 若队列已满且线程数等于
maximumPoolSize,触发拒绝策略。
Java 提供了四种内置拒绝策略,可根据业务需求选择或自定义:
| 拒绝策略 | 行为描述 | 使用场景 |
|---|---|---|
| AbortPolicy(默认) | 直接抛出RejectedExecutionException,阻止任务提交。 | 需要立即知晓任务失败的场景,如实时计算任务。 |
| CallerRunsPolicy | 由提交任务的线程(调用者)直接执行任务,不使用线程池。 | 希望降低提交任务的速率,适用于任务提交频率不稳定的场景。 |
| DiscardPolicy | 静默丢弃无法处理的任务,不抛出异常。 | 允许丢失非关键任务的场景,如日志记录。 |
| DiscardOldestPolicy | 丢弃队列中最旧的未处理任务,然后重新提交当前任务。 | 优先处理新任务,适用于任务时效性强的场景,如实时监控数据。 |
自定义拒绝策略
若内置策略无法满足需求,可实现RejectedExecutionHandler接口自定义逻辑,例如:
public class CustomRejectedHandler implements RejectedExecutionHandler { @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { // 记录日志 System.err.println("Task rejected: " + r.toString() + ", queue size: " + executor.getQueue().size()); // 尝试重新提交任务(可设置重试次数或延迟) if (!executor.isShutdown() && executor.getQueue().size() < executor.getQueue().capacity()) { try { System.out.println("Retrying to submit task..."); executor.getQueue().put(r); // 阻塞直到队列有空闲位置 } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } else { // 其他处理逻辑,如写入数据库异步处理 saveToDatabase(r); } } private void saveToDatabase(Runnable task) { // 将任务信息存入数据库,后续由独立服务消费 System.out.println("Task saved to database for later processing: " + task); }
}
使用自定义拒绝策略时,在创建线程池时传入实例:
ThreadPoolExecutor threadPool = new ThreadPoolExecutor( 1, 10, 30, TimeUnit.SECONDS, new ArrayBlockingQueue<>(50), new CustomRejectedHandler()
);
三、参数调优与注意事项
- 任务队列容量选择:需根据任务处理速度和提交频率评估。若任务处理耗时短、提交频率高,可设置较大的队列容量(如 1000),减少线程创建销毁开销;若任务耗时较长,需限制队列容量以避免内存溢出。
- 线程存活时间(keepAliveTime):非核心线程在空闲超过
keepAliveTime后会被销毁,可根据任务峰值持续时间调整,例如峰值期间设置较长存活时间,避免频繁创建线程。 - 线程命名:自定义
ThreadFactory为线程命名,便于调试和监控:ThreadFactory threadFactory = new ThreadFactory() { private int counter = 1; @Override public Thread newThread(Runnable r) { Thread thread = new Thread(r); thread.setName("CustomThread-" + counter++); thread.setDaemon(false); // 是否为守护线程 return thread; } }; - 监控与关闭:通过
getActiveCount()、getCompletedTaskCount()等方法监控线程池状态,任务完成后调用shutdown()或shutdownNow()优雅关闭,避免资源泄漏。
四、任务数超过 10 时的处理逻辑总结
当任务数超过线程池处理能力(最大线程数 10 + 队列容量 N)时,拒绝策略决定任务的去向:
- 若选择
AbortPolicy,提交任务时会抛出异常,需在调用端捕获并处理(如重试或提示用户)。 - 若选择
CallerRunsPolicy,提交任务的主线程会直接执行任务,可能阻塞主线程,需确保主线程有足够处理能力。 - 若选择
DiscardPolicy或DiscardOldestPolicy,需确保丢失任务不会影响业务逻辑,例如非实时日志采集。 - 自定义策略可结合业务需求实现灵活处理,如异步持久化任务、发送告警通知等。
通过合理配置线程池参数和拒绝策略,可有效管理高并发任务,平衡系统资源利用率和稳定性。
请描述你在之前项目中的主要职责和技术挑战
在之前参与的分布式电商交易系统项目中,我的主要职责是负责订单服务模块的开发与优化,以及协调团队完成微服务架构下的系统设计与落地。以下从职责内容和技术挑战两方面展开说明:
一、主要职责
-
核心业务开发
- 设计并实现订单创建、支付回调、库存锁定、物流状态更新等核心流程,确保业务逻辑的准确性和事务一致性。例如,订单创建时需通过分布式事务机制(如 Seata AT 模式)协调库存服务和支付服务,避免出现 “下单成功但库存不足” 或 “重复扣库存” 的问题。
- 开发订单状态机管理模块,通过状态枚举(如待支付、已支付、待发货、已取消等)和状态转换规则,确保订单流程的可追溯性和幂等性。
-
性能优化与高并发处理
- 针对大促期间的高并发场景(如每秒万级订单请求),对订单服务进行压测和优化。通过引入 Redis 缓存热点数据(如商品基础信息、用户优惠券),减少数据库查询压力;使用本地缓存(Caffeine)存储高频访问的字典数据(如支付方式枚举),提升响应速度。
- 重构订单号生成逻辑,将原有的数据库自增主键改为分布式 ID 生成器(基于 Snowflake 算法),解决单机主键生成瓶颈,支持水平扩展。
-
微服务架构落地
- 参与设计服务拆分方案,将订单服务从单体架构拆分为独立微服务,通过 Spring Cloud Alibaba 实现服务注册与发现(Nacos)、负载均衡(Ribbon)和服务调用(Feign)。
- 实现熔断降级机制,使用 Sentinel 对下游依赖服务(如库存服务、支付服务)进行流量控制和故障隔离,防止级联故障导致系统雪崩。
-
系统稳定性保障
- 设计订单补偿机制,通过异步消息队列(RocketMQ)实现订单状态的最终一致性。例如,当支付回调超时或库存锁定失败时,通过定时任务扫描异常订单并触发重试,同时记录操作日志以便问题追溯。
- 开发监控与告警模块,集成 Prometheus 和 Grafana 监控订单服务的关键指标(如 QPS、响应时间、线程池状态),设置阈值自动触发告警(如飞书机器人通知)。
二、技术挑战与解决方案
-
分布式事务一致性问题
- 挑战:订单流程涉及多个微服务(订单、库存、支付)的写操作,传统数据库事务无法跨服务保证一致性,需解决 “部分成功、部分失败” 导致的数据不一致问题。
- 方案:采用 Seata AT 模式实现柔性事务,通过数据库本地事务 + 全局事务协调器完成两阶段提交。在订单创建时,首先通过 Seata 开启全局事务,库存服务扣减库存(记录 UNDO 日志),支付服务冻结金额,若任一环节失败则全局回滚,确保最终一致性。
-
高并发下的库存超卖问题
- 挑战:大促期间大量订单同时请求库存,传统数据库行锁在高并发下性能瓶颈明显,可能导致库存扣减不准确或服务响应延迟。
- 方案:
- Redis 预扣库存:在接收到订单请求时,先通过 Redis 的
INCRBY原子操作预扣库存,若返回值小于 0 则直接拒绝订单,避免大量请求压到数据库。 - 数据库乐观锁:在实际扣减库存时,使用 SQL 语句
UPDATE stock SET count = count - 1 WHERE id = ? AND count >= ?,通过版本号或库存数量条件确保扣减操作的原子性。 - 队列削峰:将订单请求写入 RocketMQ 队列,通过有限线程池顺序消费队列中的消息,控制库存扣减的并发量,避免瞬间压力击穿数据库。
- Redis 预扣库存:在接收到订单请求时,先通过 Redis 的
-
分布式环境下的幂等性保障
- 挑战:由于网络波动、重试机制等原因,同一请求可能被多次处理,导致订单重复创建或库存重复扣减。
- 方案:
- 唯一请求号(Token):客户端在请求中携带唯一标识(如 UUID),服务端通过 Redis 缓存已处理的请求号,每次处理前校验是否存在,避免重复处理。
- 数据库唯一索引:为订单号、支付流水号等字段添加唯一索引,利用数据库特性防止重复数据插入。
- 状态机幂等:在订单状态转换时,仅允许从 “待支付” 转为 “已支付” 一次,通过数据库事务和状态校验确保幂等性。
-
微服务调用的链路追踪与调试
- 挑战:分布式系统中请求链路复杂(订单服务→库存服务→支付服务→物流服务),故障定位困难,需快速追踪请求在各服务中的处理状态。
- 方案:集成 Spring Cloud Sleuth 和 Zipkin 实现分布式链路追踪,为每个请求生成唯一的 Trace ID 和 Span ID,记录各服务节点的调用时间、参数和返回结果。通过 Zipkin 可视化界面查询完整调用链路,定位响应缓慢或报错的节点,结合日志系统(ELK Stack)快速排查问题。
-
流量突发时的系统可用性
- 挑战:大促期间流量可能瞬间达到日常峰值的 10 倍以上,传统扩容机制难以实时响应,可能导致服务不可用。
- 方案:
- 弹性扩容:基于 Kubernetes 实现自动扩缩容,通过 HPA(Horizontal Pod Autoscaler)监控 CPU / 内存使用率,动态调整订单服务的 Pod 数量,分钟级完成扩容。
- 流量分级管控:通过 Sentinel 定义不同的流量等级(如普通用户、VIP 用户),为核心业务(如支付链路)预留流量配额,当系统负载过高时,对非核心请求(如订单查询)进行限流或降级,保障核心流程的可用性。
三、总结
通过上述职责的履行和挑战的解决,订单服务在高并发场景下的响应时间降低了 40%,系统可用性达到 99.95%,成功支撑了多次大促活动。过程中积累的分布式事务设计、缓存与数据库协同优化、微服务治理等经验,为后续参与的金融级交易系统开发提供了重要参考。未来需持续关注云原生技术(如 Service Mesh)和 Serverless 架构,进一步提升系统的可扩展性和运维效率。
如何优化一个响应缓慢的接口?
优化响应缓慢的接口需从多个维度分析,包括代码逻辑、数据库查询、缓存使用、网络通信等。以下是系统性的优化策略:
一、性能瓶颈定位
- 监控与分析工具:使用 APM 工具(如 Skywalking、Pinpoint)追踪接口调用链路,识别耗时最长的环节;通过 JVM 监控工具(如 VisualVM、JProfiler)分析 CPU、内存使用情况,排查是否存在线程阻塞或内存泄漏。
- 日志埋点:在接口关键路径添加耗时日志(如方法入口 / 出口时间戳),分段记录执行时间,定位具体耗时模块。
- 负载测试:使用 JMeter、LoadRunner 等工具模拟高并发场景,观察接口在不同压力下的表现,确定性能拐点。
二、代码层面优化
- 减少阻塞操作:避免同步调用耗时操作(如远程 RPC、文件 IO),可将非核心逻辑异步化(如通过线程池或消息队列处理)。
- 优化循环与递归:避免在循环中执行数据库查询或远程调用,可批量处理数据;检查递归是否存在栈溢出风险或重复计算,考虑使用迭代或缓存中间结果。
- 减少内存分配:避免在循环中频繁创建对象,使用
StringBuilder替代+拼接字符串,减少 GC 压力。
三、数据库优化
- 索引优化:通过慢查询日志(如 MySQL 的
slow_query_log)定位耗时 SQL,为查询条件字段添加合适索引;避免全表扫描和索引失效(如模糊查询以%开头)。 - 查询优化:减少
SELECT *,仅查询需要的字段;避免子查询,使用JOIN替代;批量插入 / 更新数据,减少 SQL 执行次数。 - 读写分离:对读多写少的场景,采用主从复制架构,将读请求分流到从库。
- 分库分表:数据量过大时,按业务维度分库(如订单库、用户库),按哈希或范围分表(如订单表按用户 ID 哈希分 1024 张表)。
四、缓存与异步
- 缓存热点数据:将高频访问的数据(如配置信息、商品详情)存入 Redis 或本地缓存(Caffeine),减少数据库访问。
- 异步处理非关键逻辑:通过消息队列(如 RocketMQ、Kafka)异步处理通知、日志等非核心业务,避免阻塞主流程。
- 预计算与定时刷新:对复杂统计数据(如报表),定时预计算结果存入缓存,避免实时计算。
五、架构优化
- 服务拆分与负载均衡:将接口从单体服务拆分为微服务,通过 Nginx 或 Spring Cloud Gateway 实现负载均衡,分摊流量压力。
- 降级与熔断:使用 Sentinel 或 Hystrix 对下游依赖服务设置熔断阈值,当服务不可用时快速失败,避免级联故障。
- CDN 与静态资源分离:将 JS、CSS、图片等静态资源分发至 CDN,减少服务器负载。
六、网络与 IO 优化
- 压缩响应数据:启用 Gzip 压缩,减少数据传输量;对二进制数据(如图像)使用更高效的压缩算法(如 WebP)。
- 长连接与连接池:使用 HTTP/2 或 gRPC 替代 HTTP/1.1,复用连接;配置合理的数据库连接池(如 HikariCP),避免频繁创建连接。
- 异步 IO:对 IO 密集型操作,使用 NIO 替代 BIO,提升并发处理能力。
示例优化过程
假设一个查询用户订单列表的接口响应缓慢,优化步骤如下:
- 通过 APM 发现 90% 的耗时在数据库查询。
- 分析 SQL 发现缺少索引,为
user_id和create_time添加复合索引。 - 将高频访问的订单摘要数据缓存至 Redis,查询时优先读取缓存。
- 对订单详情页的非关键信息(如商品描述)改为异步加载。
- 压测验证,接口响应时间从 800ms 降至 150ms。
通过全方位排查和针对性优化,可显著提升接口性能。需注意性能优化是持续过程,需定期监控和调整策略。
如何保证分布式事务的一致性?
在分布式系统中,保证跨服务操作的一致性需通过特定技术手段实现。常见方案可分为强一致性和最终一致性两类,需根据业务场景选择合适的模式。
一、强一致性方案
-
两阶段提交(2PC)
- 原理:引入协调者(Coordinator),将事务分为准备(Prepare)和提交(Commit)两个阶段。所有参与者在准备阶段确认操作可执行,协调者收到全部确认后发起提交命令。
- 实现:Java 中可通过 JTA(Java Transaction API)实现,如 Atomikos 框架。
- 缺点:同步阻塞,性能差;存在单点故障(协调者崩溃可能导致参与者阻塞);不适合高并发场景。
-
三阶段提交(3PC)
- 改进:在 2PC 基础上增加 CanCommit 阶段,参与者可提前响应是否就绪;引入超时机制,避免参与者长时间阻塞。
- 应用:实际中较少使用,仍存在性能问题。
二、最终一致性方案
-
TCC(Try-Confirm-Cancel)
- 流程:
- Try:尝试执行业务,预留资源(如冻结账户余额)。
- Confirm:确认提交,使用预留资源完成操作。
- Cancel:取消操作,释放预留资源。
- 实现:通过编程实现三个接口,如 Seata 的 TCC 模式。
- 优点:性能优于 2PC,适合高并发场景。
- 缺点:开发成本高,需保证 Confirm/Cancel 幂等性。
- 流程:
-
本地消息表(eBay 模式)
- 流程:
- 主业务操作与消息记录在同一本地事务中。
- 消息服务异步消费消息,执行下游业务。
- 通过定时任务扫描未确认的消息并重试。
- 示例:订单服务创建订单时,在本地数据库插入订单记录和消息记录,消息服务读取消息并调用库存服务扣减库存。
- 实现:结合数据库事务和消息队列(如 RocketMQ),如阿里云的 GTS(Global Transaction Service)。
- 流程:
-
可靠消息最终一致性
- 流程:
- 业务系统发送消息到消息中间件(预发送)。
- 执行本地业务操作。
- 根据业务结果确认或取消消息。
- 消费者确保幂等性消费。
- 实现:使用支持事务消息的 MQ(如 RocketMQ、Kafka),如 Seata 的 MQ 模式。
- 流程:
-
Saga 模式
- 原理:将长事务拆分为多个短事务,每个短事务对应一个 Saga 子事务,通过补偿机制回滚。
- 实现:
- 正向补偿:按顺序执行各子事务,失败时反向执行补偿操作。
- 反向补偿:按逆序执行各子事务,失败时正向执行补偿操作。
- 应用:适合流程较长的业务(如电商订单流程),可通过状态机实现(如 Camunda)。
三、选择策略
| 方案 | 一致性级别 | 性能 | 适用场景 | 技术实现 |
|---|---|---|---|---|
| 2PC | 强一致 | 低 | 对一致性要求极高的场景 | JTA、Atomikos |
| TCC | 最终一致 | 中 | 高性能、可补偿的业务 | Seata、ByteTCC |
| 本地消息表 | 最终一致 | 高 | 业务流程简单的系统 | RocketMQ + 数据库 |
| 可靠消息 | 最终一致 | 高 | 跨服务的异步调用 | RocketMQ、Kafka |
| Saga | 最终一致 | 高 | 长流程、多服务协作的业务 | Seata、Camunda |
四、关键技术要点
- 幂等性设计:所有补偿操作必须支持重试,通过唯一标识(如 UUID)确保多次调用效果相同。
- 柔性事务监控:建立事务状态监控系统,实时跟踪事务执行情况,对超时或失败的事务人工干预。
- 降级策略:对非关键业务,允许短暂不一致,如电商库存显示与实际库存存在短暂延迟。
示例:电商订单支付流程
-
TCC 方案:
- Try:订单服务冻结商品库存,支付服务冻结用户账户余额。
- Confirm:订单服务确认订单,支付服务扣款。
- Cancel:订单服务释放库存,支付服务解冻余额。
-
可靠消息方案:
- 支付成功后,发送 “支付成功” 消息到 MQ。
- 订单服务消费消息,更新订单状态。
- 库存服务消费消息,扣减库存。
- 通过消息重试和幂等消费确保最终一致。
分布式事务的实现需权衡一致性、可用性和性能,根据业务场景选择合适的方案,并通过监控和补偿机制保障系统稳定运行。
如何设计一个高并发的支付系统?
设计高并发支付系统需从架构、性能、安全和可用性等多维度考虑,以下是关键设计要点:
一、系统架构设计
-
分层架构:
- 接入层:负载均衡(如 Nginx)、流量控制(如 Sentinel)、协议转换(HTTP→内部 RPC)。
- 业务层:支付核心逻辑(订单创建、支付处理、退款)、账户管理、风控系统。
- 数据层:数据库(订单库、账户库)、缓存(Redis)、分布式文件系统(存储凭证)。
- 外部接口层:对接银行、第三方支付渠道(如支付宝、微信)。
-
微服务拆分:
- 按业务边界拆分为支付服务、账户服务、渠道服务、风控服务等,通过服务注册与发现(如 Nacos)实现松耦合。
二、高性能设计
-
异步处理:
- 核心链路同步处理(如支付受理),非核心链路异步化(如支付通知、对账)。
- 使用消息队列(如 RocketMQ)处理高并发请求,削峰填谷。
-
缓存优化:
- 高频数据(如用户余额、支付配置)缓存至 Redis,减少数据库访问。
- 本地缓存(Caffeine)存储热点数据(如支付渠道白名单),降低远程调用延迟。
-
分库分表:
- 按用户 ID 或商户 ID 分库(如 1024 个库),订单表按时间分表(如每月一张表)。
- 使用 ShardingSphere 或 MyCat 实现数据分片。
-
读写分离:
- 对查询密集的场景(如交易查询),通过主从复制将读请求分流至从库。
三、高可用设计
-
集群部署:
- 所有服务无状态化,支持横向扩展,通过 Kubernetes 实现自动扩缩容。
- 关键组件(如 Redis、MQ)采用集群模式,避免单点故障。
-
熔断与降级:
- 使用 Sentinel 设置熔断阈值,当第三方支付渠道响应超时或错误率超过阈值时,自动熔断并降级(如切换备用渠道)。
-
幂等设计:
- 所有接口支持幂等性,通过唯一支付流水号防止重复提交。
-
数据一致性保障:
- 核心交易使用 TCC 或可靠消息确保最终一致性,如支付成功后通过消息队列通知库存服务扣减库存。
四、安全设计
-
数据加密:
- 敏感数据(如银行卡号、CVV 码)使用国密算法(SM4)加密存储。
- 传输层使用 HTTPS,关键接口(如支付接口)使用双向认证。
-
风控系统:
- 实时监控交易行为,通过规则引擎(如 Drools)识别异常交易(如异地登录、大额高频支付)。
- 接入第三方风控服务(如阿里云风险识别),提升反欺诈能力。
-
权限控制:
- 基于 RBAC 模型控制用户访问权限,关键操作(如资金调拨)需多级审批。
五、支付流程优化
-
支付渠道路由:
- 根据交易金额、用户地域、渠道可用性动态选择最优支付渠道。
- 维护渠道权重和健康状态,自动降级不可用渠道。
-
并发控制:
- 对同一账户的并发支付请求,通过 Redis 分布式锁或数据库行锁串行化处理。
-
异步回调:
- 支付结果通过异步回调通知商户系统,避免同步等待导致的连接超时。
六、监控与告警
-
指标监控:
- 核心指标:QPS、响应时间、成功率、渠道可用性。
- 系统指标:CPU、内存、磁盘 IO、网络带宽。
-
告警机制:
- 设置多级告警阈值,通过短信、邮件、IM(如飞书)实时通知。
- 关键指标异常时触发自动告警(如支付成功率低于 99%)。
-
链路追踪:
- 集成 Zipkin 或 Skywalking,记录完整支付链路(用户→支付网关→渠道→回调),快速定位故障点。
七、灾备与应急
-
异地多活:
- 部署多个可用区,当主可用区故障时,自动切换至备用区。
-
应急预案:
- 制定降级策略(如关闭非核心功能)、熔断策略(如切断异常渠道)。
- 定期演练故障恢复流程,确保团队熟悉灾备操作。
八、容量规划
-
压测验证:
- 定期进行全链路压测(如每秒 10 万笔交易),验证系统在极端情况下的稳定性。
-
弹性伸缩:
- 根据历史流量数据预测峰值,提前扩容;通过 Kubernetes 实现自动化弹性伸缩。
九、合规与审计
-
交易审计:
- 记录所有资金交易日志,支持监管审计和内部合规检查。
-
数据备份:
- 实时备份关键数据(如订单、账户)至异地存储,确保数据可恢复。
通过以上设计,支付系统可支持每秒万级交易,保证高可用性(99.99%)和数据安全,满足电商、金融等行业的高并发支付需求。