Voice Conversion语音转换
语音转换(Voice Conversion, VC)是一种技术,允许将一个说话者的声音转换为另一个说话者的声音,同时保留内容。
Preserved:content内容
语音转换的应用:转换说话人,说话风格,提升可懂度,数据增强。
在实际应用中,常常是直接将源语音(T)转换为目标语音(T’),并通过声码器(Vocoder)实现。
声码器的选择:规则基础(Griffin-Lim算法)或深度学习(如WaveNet)。
一、Feature Disentangle特征解耦
| 组件 | 描述 |
| 内容编码器 | 处理语音的内容信息。 |
| 说话者编码器 | 处理说话者的声音特征。 |
| 解码器 | 生成目标语音。 |
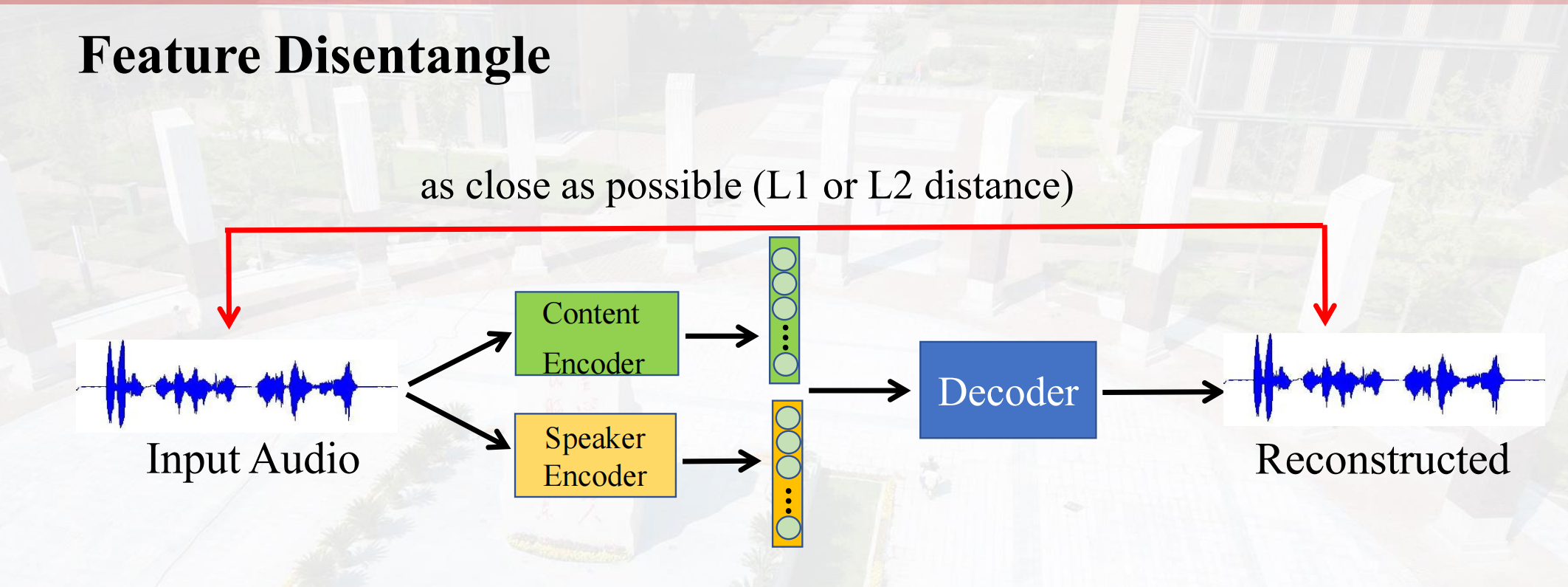
假设我们知道需要训练出的说话人,使用说话人信息,对于speaker encoder,我们可以使用one-hot编码替换。但是这样的issue是预训练编码器面临有新说话者时的挑战,可能需要使用说话者嵌入。
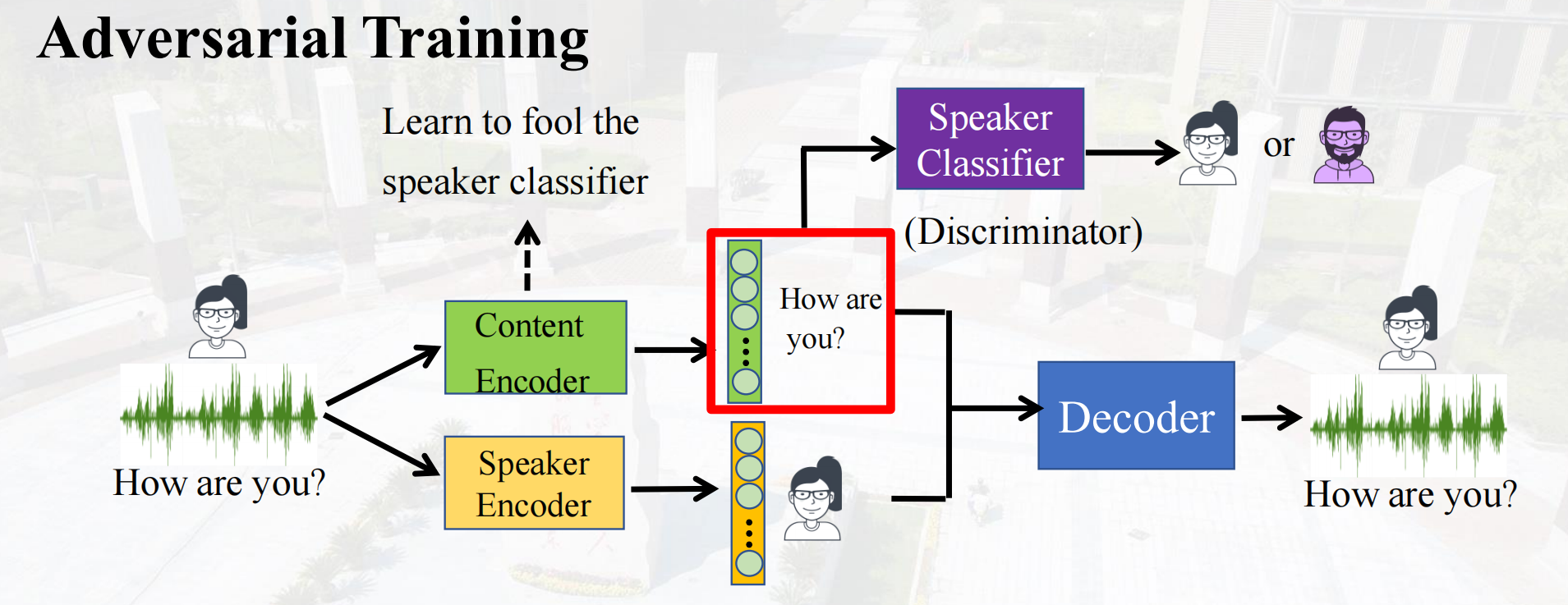
Adversarial Training对抗训练
通过对抗训练降低说话者分类器的准确性,使内容编码器学习如何“欺骗”说话者分类器。
这里的speaker classifier是在对抗训练,因为希望提取内容信息,说话人分类器分类效果不好,说明内容编码器提取效果好。
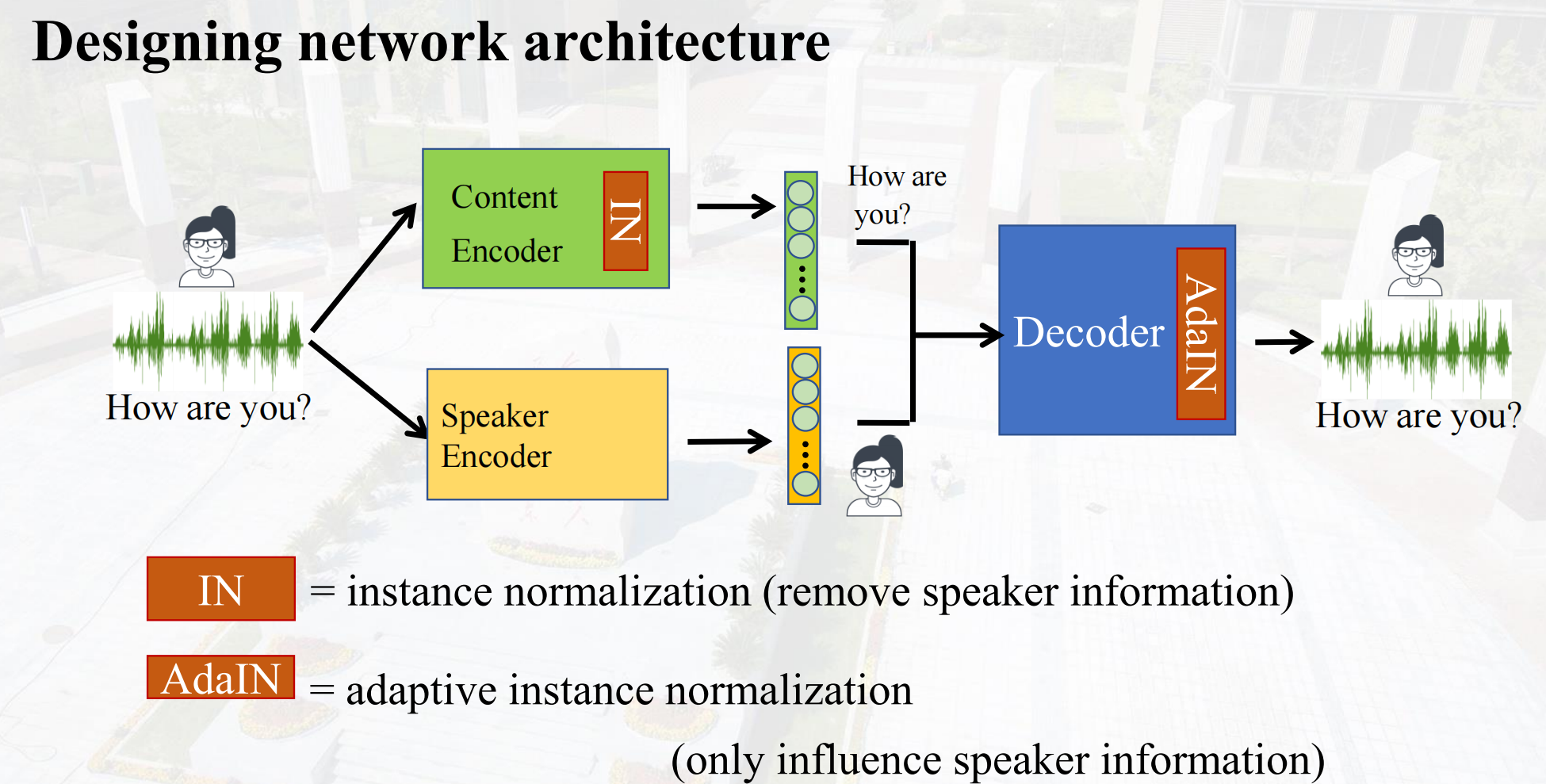
IN:实例规范化,每个通道减去均值,使得均值为0,除以方差,以去除说话人信息。
AdaIN:自适应实例规范化
Issue:如果在训练时,使用内容编码器和说话人编码器编码的说话人是同一个,那么在编码不同说话人时合成质量不好。
2nd Stage Training两阶段训练
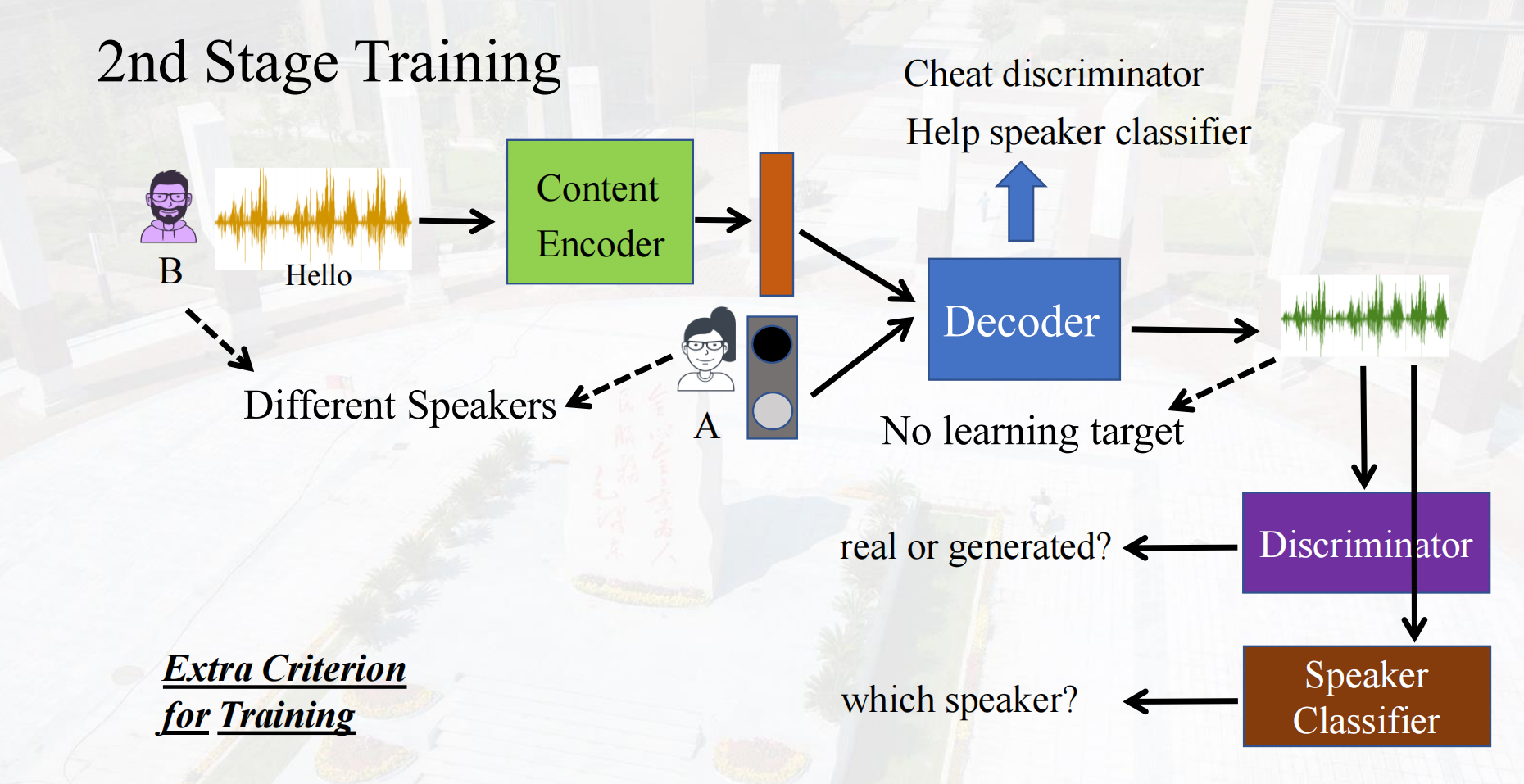
这里的speaker classifier并不是对抗,而是在判断是哪个说话人,鉴别器才是在对抗,合成的语音想要欺骗鉴别器,而鉴别器要将合成的语音识别出来。
在两阶段训练中,还有一个patcher补丁,它合成的语音对一些读音缺失信息进行补充
Only learn the patcher in the 2nd stage
二、Direct Transformation直接转换法
能够在没有成对数据的情况下有效工作。
Cycle GAN
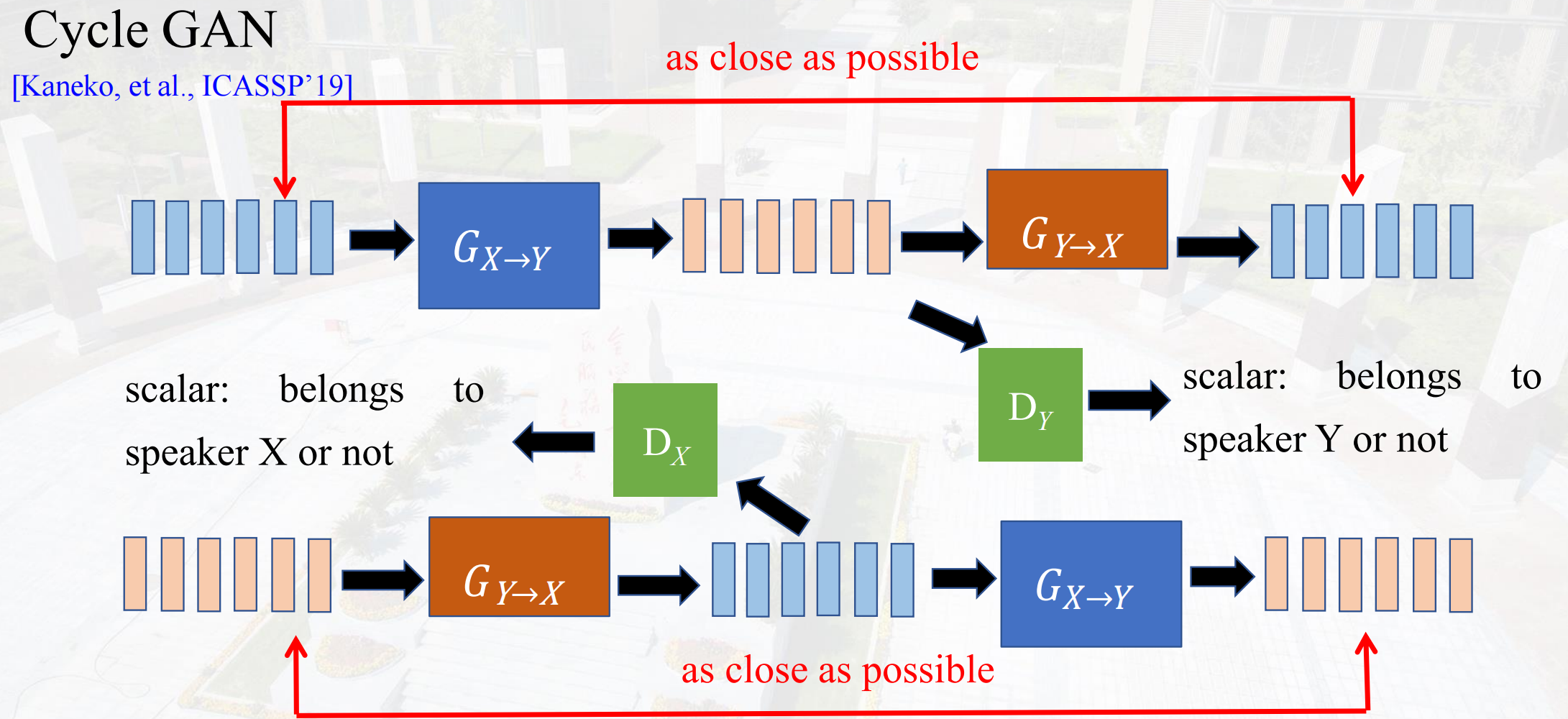
为什么还有G(Y to X)因为判别器D(Y)根据某些特征判断合成的语音是否属于speaker Y,但是在这种情况下很可能生成器为了使判别器将结果判断为speaker Y,放弃应该保留的信息,因此为了保证保留需要的信息,加入G(Y to X)。
Issue:如果有N个speaker,需要N*(N-1)次合成,且一旦有新的speaker加入需要全部重新训练一遍。
Strat GAN
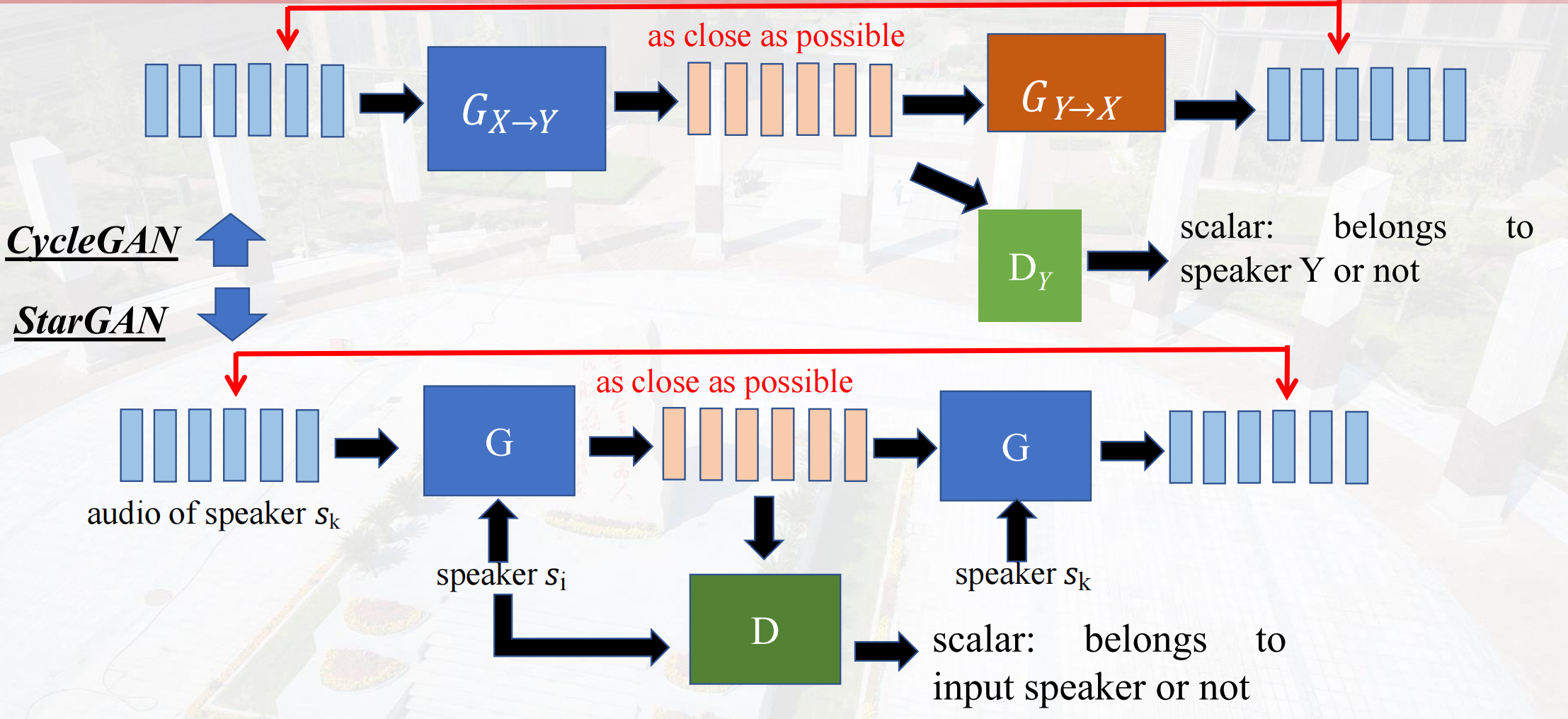
没有固定生成器和判别器,只需要这一个架构就可以。