大模型微调(3):Hugging Face Transformers 快速入门
1. Hugging Face Transformers 简介
在前面的文章中,我们已经介绍了 Hugging Face 这个平台,了解了它是当下大模型领域最核心的开源社区,里面托管了大量的开源模型(Models)、数据集(Datasets)和应用(Speces)。
在 Hugging Face 中,最核心的就是 Transformers 库,它是一个基于预训练模型的Python库,构建于经典的深度学习框架 TensorFlow 、PyTorch 和 JAX 之上,并提供了更高层的抽象,允许用户高效地下载和训练机器学习模型。
Transformers最初被创建用于开发语言模型,现在功能已扩展到包括多模态、计算机视觉和音频处理等其他用途的模型,已经成为了大模型 pre-train 和 fine-tune 工程的事实标准,几乎所有大模型微调的项目都会使用到 Transformers 库。
Transformers 库的价值主要在于以下几个方面:
- 丰富的预训练模型:提供广泛的预训练模型,如 BERT、GPT、T5 等,适用于各种NLP任务。
- 易于使用:设计注重易用性,使得即使没有深厚机器学习背景的开发者也能快速上手。
- 快速集成最新研究成果:Transformers 的更新非常活跃,会第一时间跟进最新的研究成果和模型。
- 强大的社区支持:活跃的社区不断更新和维护库,提供技术支持和新功能。
- 跨框架兼容性:支持多种深度学习框架,如 PyTorch、TensorFlow 和 JAX,并提供灵活选择。
- 高度灵活和可定制化:允许用户根据需求定制和调整模型,进行微调或应用于特定任务。
- 广泛的应用范围:适用于从文本分类到语言生成等多种 NLP 应用,以及多模态的扩展。
2. Pipeline 运行原理
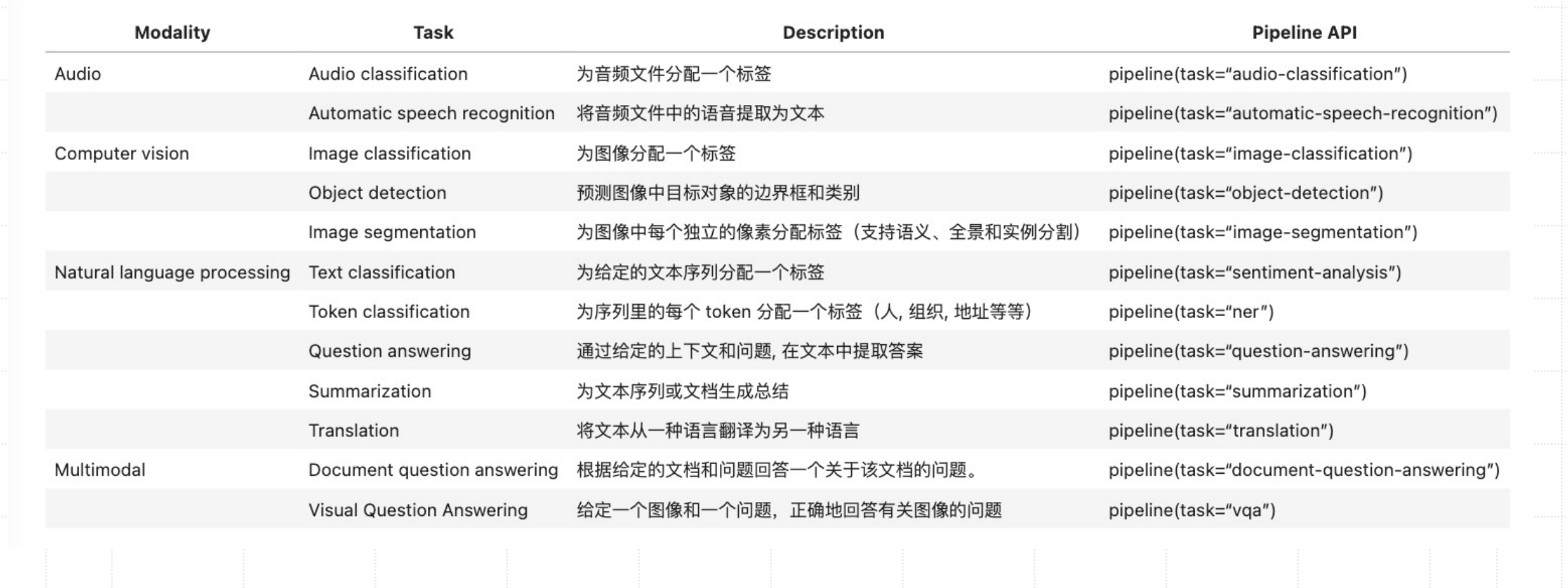
在 Transformers 库中,提供了一个 Pipeline(管道) API,它封装了 Transformers 库中大部分复杂的逻辑处理,并暴露给用户一个简单易用的、可用于处理多种模型任务的接口,包括命名实体识别、情感分析、特征提取、问答等等,可以有效地降低模型推理的学习和使用成本。

可以概览下 Pipeline 所支持的核心功能:
Pipeline 封装了整个数据预处理、模型推理与特定任务后处理的过程,我们以一个具体的情感分析场景为例:输入一句话 "AI changes the world!",让模型判断出出这句话的情感倾向是正面还是负面。
其核心原理可以参考下图:
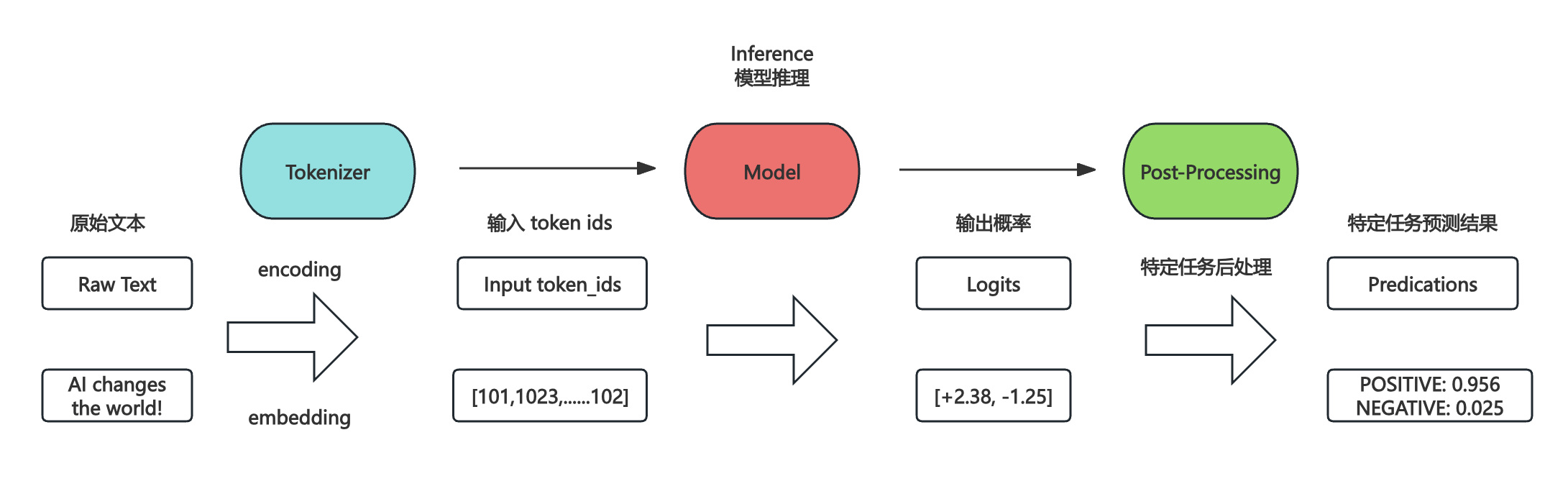
- Tokenizer 分词器:针对文本类大模型来说,通过每个大模型都有一个与其一一对应的 Tokenizer 分词器。因为模型是没法直接处理文本的,它只能进行向量和矩阵计算,因此需要 Tokenizer 先将原始文本编码成对应的 token_ids,这样才能交给模型进行处理。
- Model 大模型:预训练好的 LLM 大模型,例如 BERT、GPT 等,对输入的 token_ids 进行推理计算,输出特定的概率。
- Post-Processing 特定任务后处理:通常模型的原始输入无法直接使用,需要进行特定业务场景的后处理,在本例子,就需要将模型输出的概率,转换成正向、负向的标签及其对应的置信度(Score)。
3. 使用 Pipeline API 实战情感分析
接下来,我们就以上面的情感分析功能为例,实战下 Pipeline API 的使用。代码非常简单:
from transformers import pipeline # 导入Transforms Pipeline API# 创建Pipeline
# 使用tabularisai/multilingual-sentiment-analysis模型
pip = pipeline(task="sentiment-analysis", # 任务类型为sentiment-analysis情感分析model="tabularisai/multilingual-sentiment-analysis") # 指定模型# 进行情感分析
result = pip("AI changes the world!")
print(result)执行结果如下 :

模型将 "AI changes the world!" 这句话判定成了 Very Positive,并且置信度分数为 0.69,这比较符合我们的常识。
可以看到,使用 Pipeline API,可以非常方便地实现各种常见的机器学习任务,大幅提高了开发效率。