【大模型Pre-Training实战总结】实现Qwen3增量预训练,Lora训练与合并
摘要
大模型一般分三个阶段(现在有很多个阶段的,比如DeepSeek),首先要完成的是Pre-Training阶段。预训练是指在大量无标签数据上进行训练,使模型学习到一些基础的语言表示和知识。常见的预训练方法包括自回归语言模型(如GPT系列)、自编码器等。这些方法通过在大规模语料库上训练,使模型能够理解语言的语法、语义和上下文信息。这篇文章试图告诉大家如何去实现增量Pre-Training。
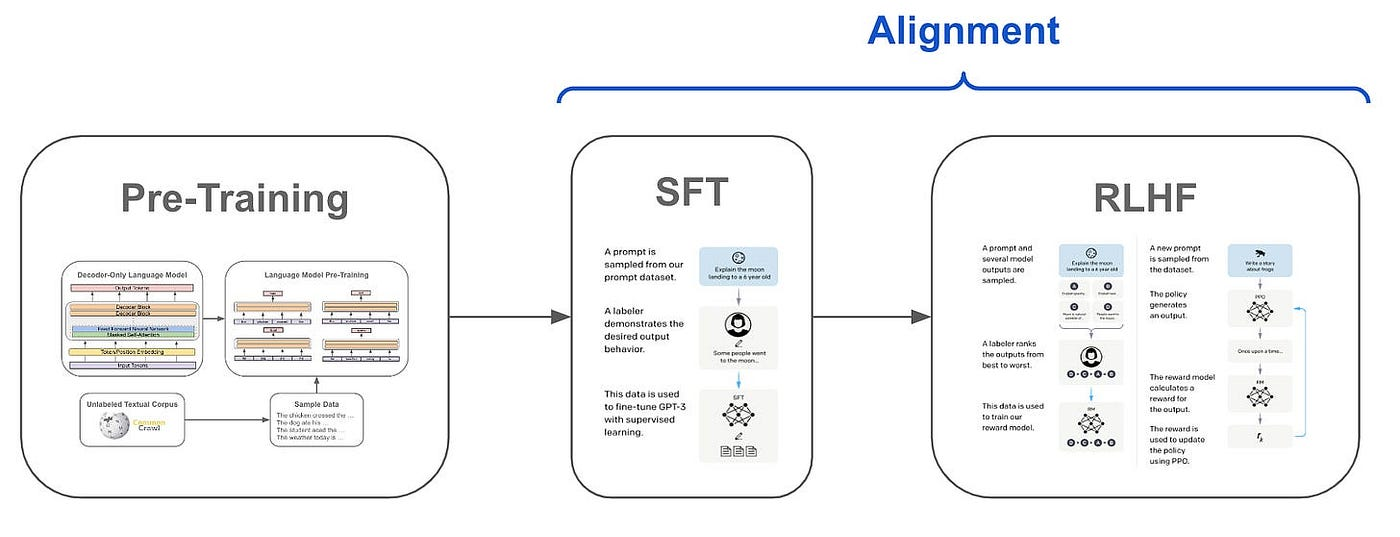
为什么要增量Pre-Training
增量预训练的本质是在已有预训练模型基础上,通过新数据或新任务进一步优化模型参数或者针对特定需求对已有基座模型进行定向增强。我总结了一下几个方面需要用到增量Pre-Training:
1. 领域知识注入(Domain Adaptation)
- 问题:通用大模型(如LLaMA、GPT)在垂直领域(医疗、法律、金融)表现不足,缺乏专业术语和逻辑。