基于Flask实现豆瓣Top250电影可视化
项目截图
概述
该项目旨在对豆瓣Top 250电影进行全面的数据分析,使用了Python爬虫、Flask框架进行开发,并采用了Echarts进行数据可视化以及WordCloud进行词云分析。应用展示了多个功能,如电影列表、评分分布、词频统计和团队信息。
主要功能
-
首页: 显示项目的概述和统计数据,包括经典电影数量、评分统计、词汇统计和团队成员数量。
-
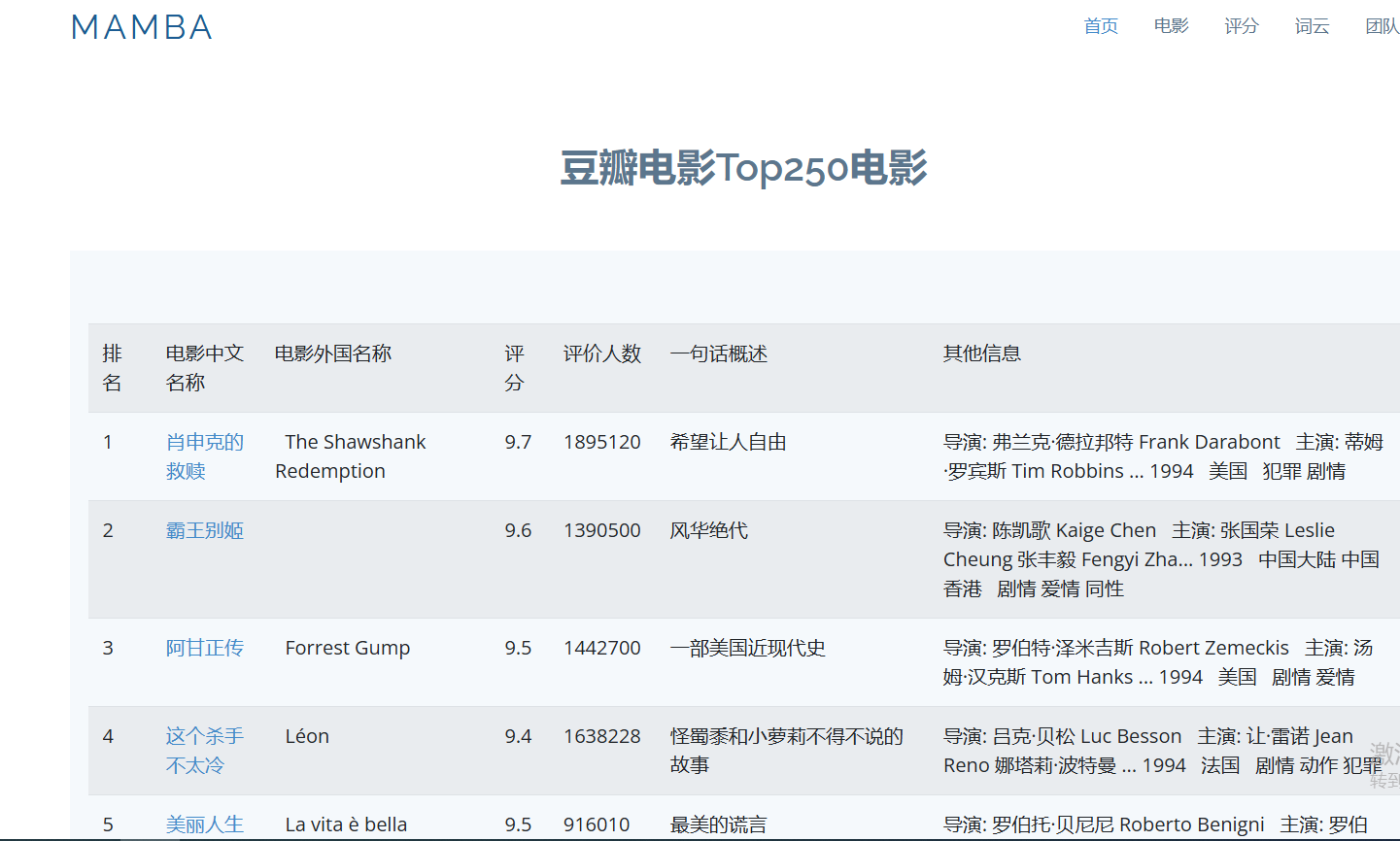
电影列表页: 展示豆瓣Top 250电影的详细信息,包括电影中文名称、外文名称、评分、评价人数、一句话概述及其他信息。
-
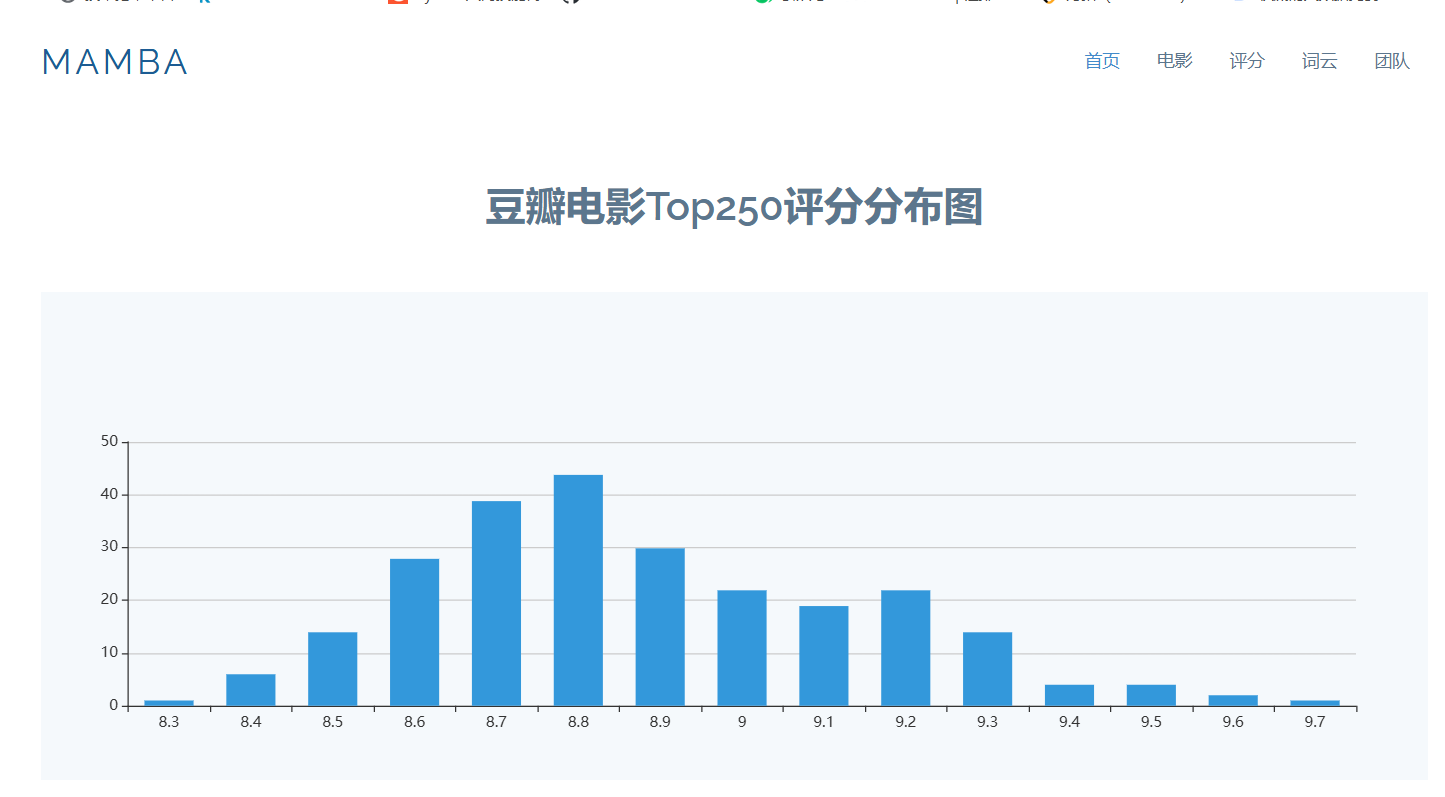
评分分布页: 通过柱状图展示豆瓣Top 250电影的评分分布情况,提供用户对评分分布的直观了解。
-
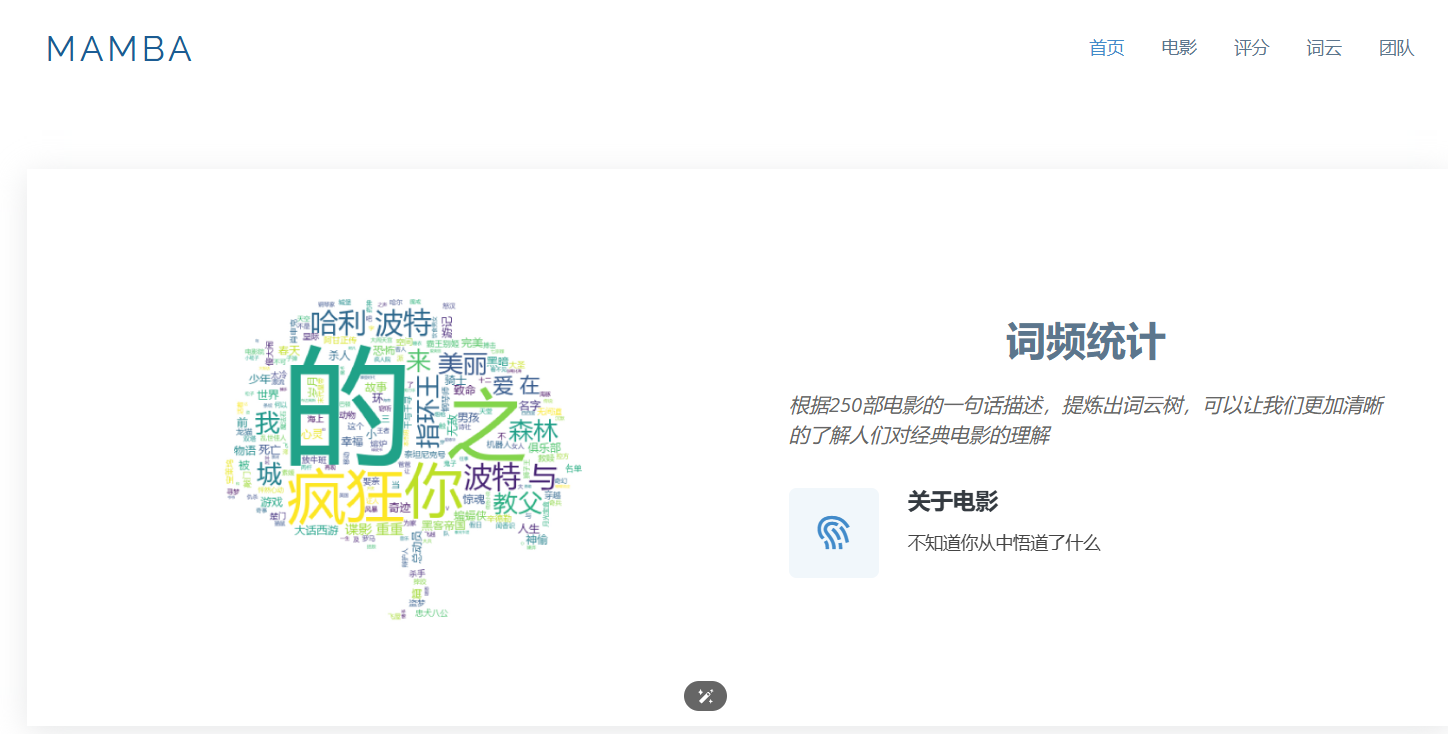
词云统计页: 根据250部电影的一句话描述,提炼出词云树,通过词云图展示词汇的频率,让用户更清晰地了解人们对经典电影的理解。
-
团队页: 展示团队成员的信息。
技术实现
-
Python爬虫: 使用Python爬虫从豆瓣网站上抓取电影数据。
-
Flask框架: 使用Flask搭建Web应用,实现前后端的交互。
-
SQLite数据库: 使用SQLite数据库存储爬取到的电影数据。
-
Echarts: 使用Echarts进行数据的可视化,生成评分分布的柱状图。
-
WordCloud: 使用WordCloud生成词云图,进行词频统计和展示。
-
Matplotlib: 配合WordCloud进行词云图的绘制和保存。
数据库结构
- movie250表: 存储豆瓣Top 250电影的详细信息,包括电影中文名称、外文名称、评分、评价人数等字段。
使用方法
-
启动Flask应用:
if __name__ == '__main__':app.run() -
访问首页,通过浏览器访问
http://localhost:5000/查看应用的各个功能页面。
代码示例
-
Flask路由配置:
from flask import Flask, render_template import sqlite3 app = Flask(__name__)@app.route('/') def index():return render_template("/index.html")@app.route('/index') def home():return render_template("/index.html")@app.route('/movie') def movie():datalist = []conn = sqlite3.connect("movie.db")cur = conn.cursor()sql = '''select * from movie250''';data = cur.execute(sql)for item in data:datalist.append(item)cur.close()conn.close()return render_template("/movie.html",movies = datalist)@app.route('/score') def score():score = []num = []conn = sqlite3.connect("movie.db")cur = conn.cursor()sql = '''select score,count(score) from movie250 group by score'''data = cur.execute(sql)for item in data:score.append(str(item[0]))num.append(item[1])cur.close()conn.close()return render_template("score.html", score=score,num=num)@app.route('/word') def word():return render_template("/word.html")@app.route('/team') def team():return render_template("/team.html")if __name__ == '__main__':app.run() -
词云图生成:
import jieba from matplotlib import pyplot as plt from wordcloud import WordCloud from PIL import Image import numpy as np import sqlite3conn = sqlite3.connect('movie.db') cur = conn.cursor() sql = 'select cname from movie250' data =cur.execute(sql) text = "" for item in data:text = text + item[0] cur.close() conn.close()cut = jieba.cut(text) string = ' '.join(cut) print(len(string))img = Image.open(r'.\static\assets\img\tree.jpg') img_array = np.array(img) wc = WordCloud(background_color = 'white',mask = img_array,font_path = "msyh.ttc" ) wc.generate_from_text(string) fig = plt.figure(1) plt.imshow(wc) plt.axis('off') plt.savefig(r'.\static\assets\img\word.jpg',dpi=500)
这个项目通过整合多个技术栈,实现了对豆瓣Top 250电影数据的分析和可视化展示,是一个完整的全栈项目示例。