计算机视觉应用 Slot Attention
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、slot attention 定义和要解决的问题
- 二、 slot attention 的工作流程
- 三、适用场景场景
- 1. 无监督学习 对象发现
- 2. 监督学习 集合预测
- 四、草图举例
- 1.场景模拟 圆,三角形,正方形
- 1.1 迭代更新步骤
- 1.2 计算注意力权重
- 2. 场景解释
- 2.1 竞争的注意力机制
- 2.2共享参数
前言
考研结束了,开始接触新的领域,暑假期间考驾照和完成导师的论文阅读,实验重现。逐渐明白原来单纯的关注学习是美好的,生活的杂事却也是一种挑战。slot attention 提炼原著论文,让我们一起学习吧!
一、slot attention 定义和要解决的问题
slot attention 是计算机视觉应用领域的算法,我们知道计算视觉应用是在模仿人类的视觉识别过程。像胶囊神经网络关注结构性学习,对以对象为中心的表征学习很困难,而这也是我们人类的视觉识别模式。为了让人工智能视觉识别更加接近人类,提出slot attention 这个学习组件插槽算法,以对象为中心的表征学习,来捕捉自然场景中的自然属性。
二、 slot attention 的工作流程
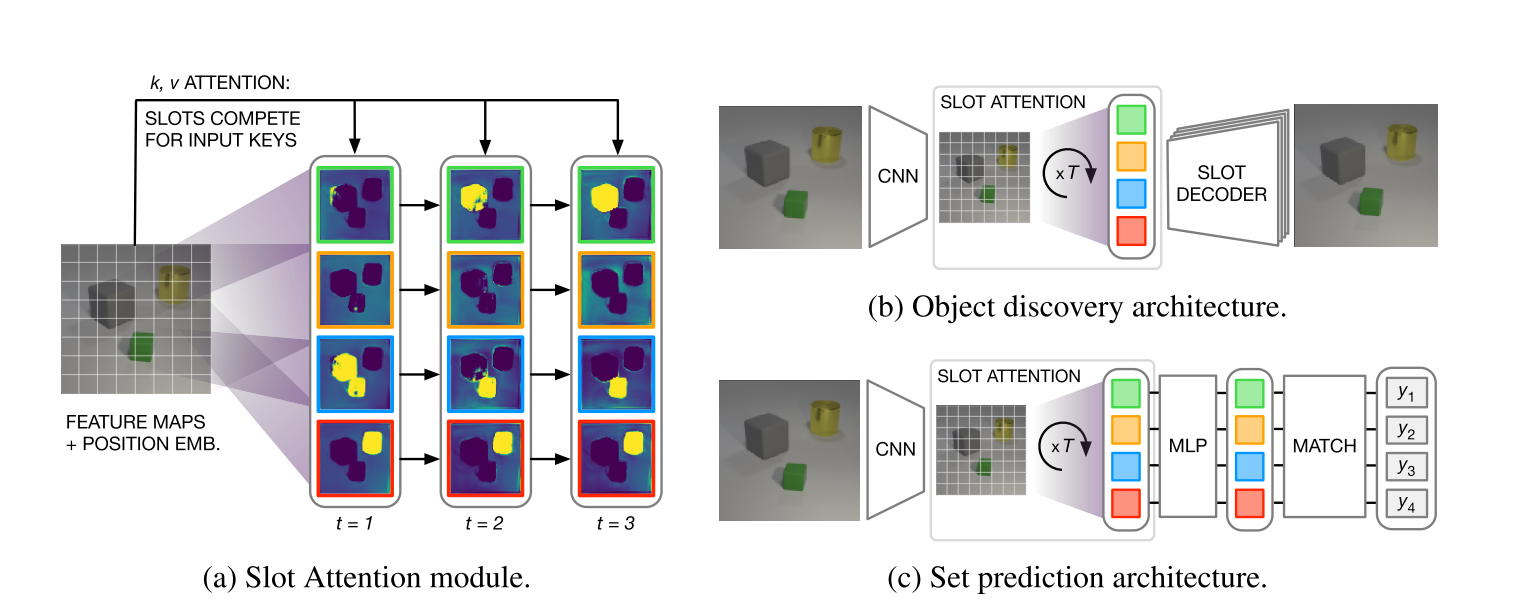
从图 1 可以看出,slot attention 把一组 N 个输入特征向量映射到一组 K 个输出向量( 一维 ),这个输出向量都可以描述输入中的一个对象和一个实体。slot attention 通过迭代注意机制将输入映射到槽中(单个的一维向量),槽可以随机初始化,但是通常初始化槽要根据样本中的对象普通分布概率,高斯分布等等,这样测试的时候才能根据这张图片生成合适的槽数量。
在每次迭代中,槽们基于softmax层来竞争解释输入的各个部分,槽的表示使用循坏更新函数来更新表示。
三、适用场景场景
1. 无监督学习 对象发现
无监督对象学习过程需要发现集合的隐藏结构:每个集合都可以捕获场景中的对象属性,并不关心这些属性的顺序。槽们将场景中的对象们映射到一组向量中,它可以作为自动编码器的一部分,将图像生成一组隐藏的表示。这些表示可以解码回到图像空间来重构原始输入。怎么说,槽作为一个对象表征的瓶颈解决架构,可以作为编码或者解码架构,每个槽仅仅表示图像中的一部分或某个区域,所有的部分或区域组合到一起可以重构这张图像。

例如,在图 2 中,假设我们有 6 个槽,这六个就可以把输入形成 6 个对象储存在槽中,而这 6 个对象当然也可以组成这张图片。以对象为中心还可以推广到更多的隐藏对象,这是意外发现。
- 编码:有两个组件构成,增强了位置表示(添加了一个偏移量)的CNN主干,和一个槽注意机制模块(获得一组槽的表示即对象为中心的表示)。
- 解码:在空间广播器的帮助下,每个槽都被单独的解码,像 IODINE 一样:每个槽的表示被广播到一个二维网格上,并通过位置嵌入进行增强。每个网格使用CNN进行编码(槽之间共享参数),生成 长 ✖️ 高 ✖️ 4 的输出。输出通道编码 RGB 颜色和未规范化的 Alpha 掩码,在使用 softmax 对 Alpha 蒙版进行归一化,并将它们用作混合权重,从而组合重构成单个的 RGB 图像。
2. 监督学习 集合预测
在一张图片中,将多个对象进行分类,通常给出一张图片和一组预测目标,每个目标描述场景中的一种对象。预测集的关键挑战在于:假设有 K 个种类,那么对应于 K! 个可能,等价于 K 个槽来表示(消除顺序)。这种归纳偏差需要在体系架构中进行显示建模,以避免学习过程中的不连续性,例如:在两个语义专用槽中可以交换其内容。槽注意机制的输出顺序是随机的,因此很好的解决了这个问题。所以我们可以把场景中的分布式表示转换成集合表示,每个对象可以使用分类器单独分类。
- 编码:与对象发现的架构相同
- 解码:每个槽使用共享参数的MPL(多层感知机),由于预测标签的随机性,采用 Hungarian 算法进行进行匹配。
四、草图举例
论文中的数学公式和具体参数讲解很大篇幅,对于新手而言很不友好,特别是没有跑出代码的朋友。为此我专门在参考了一位博主的文章,加深对 slot attention 算法的理解。
-
初始化采用高斯分布,而且每个 slot 都是随机绑定。输入特征经线性变化生成 key、queries、value。
-
注意力计算:使用点积计算每个 slot 与特征之间的相似性。通过 slots 的查询和输入特征的键进行点积运算得到一个相似性分数矩阵。这些分数矩阵经过 softmax 层归一化后,使得 slots 之间进行竞争,从而争夺对输入对象的解释权,从而使得 slots 绑定到输入的不同部分(互斥的)。
-
通过多次迭代更新 slots,论文中采用三次迭代,随着迭代次数的增加,slots 绑定的区域更加准确和稳定。
-
slots 到达更新轮次,进行输出,这些 slots 对应着图片的特征和对象信息,可以使用到发现对象(无监督),预测对象(有监督)这类下游任务中。
1.场景模拟 圆,三角形,正方形
这个例子也是基于上述博主的,只不过我改了一下数据,自己在算一遍加深对 slots 的理解。
假设一张图片中有三个对象,圆,正方形,三角形。采用卷积神经网络提取图像特征:
圆:[0.4, 0.6]
正方形:[0.3, 0.5]
三角形:[0.1, 0.8]
假设两个 slot初始化为:
slot1 : [0.1, 0.3]
slot2 : [0.2, 0.6]
1.1 迭代更新步骤
计算key和queries: 通常要经过一个可逆的线性变换,为了简单起见,我们假设可逆线性变换的矩阵是一个单位矩阵。
那么可以得到输入特征 和 lots 矩阵形式:
inputs = [ 0.4 0.6 0.3 0.5 0.1 0.8 ] \begin{bmatrix} 0.4 &0.6 \\ 0.3& 0.5 \\ 0.1 & 0.8 \end{bmatrix} 0.40.30.10.60.50.8
slots = [ 0.1 0.3 0.2 0.4 ] \begin{bmatrix} 0.1 & 0.3 \\ 0.2 & 0.4 \end{bmatrix} [0.10.20.30.4]
1.2 计算注意力权重
我们知道输入矩阵是一个 3 x 2 的矩阵,slots 是一个 2 x 2 的矩阵。点积运算就是两个相同纬度的向量进行对应位置相乘再求和,看我操作来获得相似性矩阵。
slots1
- 与圆的特征相似性:0.4 x 0.1 + 0.6 x 0.3 = 0.22
- 与正方形的特征相似性:0.3 x 0.1 + 0.5 x 0.3 = 0.18
- 与三角形的特征相似性:0.1 x 0.1 + 0.8 x 0.3 = 0.25
slots2
- 与圆的特征相似性 :0.4 x 0.2 + 0.6 x 0.4 = 0.32
- 与正方形的特征相似性:0.3 x 0.2 + 0.5 x 0.4 = 0.26
- 与三角形的特征相似性:0.1 x 0.2 + 0.8 x 0.4 = 0.34
进一步得到相似性矩阵:
Similarity Matrix = [ 0.22 0.18 0.25 0.32 0.26 0.34 ] \begin{bmatrix} 0.22 & 0.18 & 0.25 \\ 0.32 & 0.26 & 0.34 \end{bmatrix} [0.220.320.180.260.250.34]
相似性矩阵在 softmax 层归一化 (列向量归一化) ,可以得到注意力权重矩阵:
- 特征1归一化:Softmax(0.22, 0.32) = (0.41, 0.59)
- 特征2归一化:Softmax(0.18, 0.26) = (0.41, 0.59)
- 特征3归一化:Softmax(0.25, 0.34) = (0.42, 0.58)
Attention Weights = [ 0.41 0.41 0.42 0.59 0.59 0.58 ] \begin{bmatrix} 0.41 &0.41 & 0.42 \\ 0.59 & 0.59 & 0.58 \end{bmatrix} [0.410.590.410.590.420.58]
1.3 更新slots
Attention Weight 的一行对应一个slot,每一列就是对象的特征的系数
- 更新slots1: 0.41 x (0.4,0.6) + 0.41 x (0.3, 0.5) + 0.42 x (0.1,0.8) = (0.33,0.79)
- 更新slots2:0.59 x (0.4, 0.6) + 0.59 x (0.3, 0.5) + 0.58 x (0.1, 0.8)=(0.47,1.1)
更新后的 slots = [ 0.33 0.79 0.47 1.1 ] \begin{bmatrix} 0.33 & 0.79 \\ 0.47& 1.1 \end{bmatrix} [0.330.470.791.1]
通过这轮迭代,我们可以看到,slot1 的趋势偏向于绑定圆的特征,而 slot2 的趋势偏向于绑定三角形的特征,至于正方形我们需要往后继续迭代,可以看见其归属于哪个slot.
2. 场景解释
slots 通过竞争的注意力机制来解释输入的对象信息,槽之间绑定的对象是互斥的,但是所有的槽绑定的区域可以复原组成原始像,随着槽的数目增多和迭代次数增多,这种绑定对象特征的关系会更加精确和稳定。我们从理论上来分析这个形成过程。
2.1 竞争的注意力机制
- 在计算Attention Weights 的时候,通过 slots 实现与每个输入对象的交互(包括每个对象的每个特征),相似矩阵归一化得到ttention Weights 矩阵包含了每个对象的特征信息。
- 这种归一化在slots纬度上面进行,使得每个slots都会去竞争解释同一个对象特征,随着迭代的进行,slots会找到自己最能解释的特征,仅仅关注该部分的输入。
- 这个过程会让slots努力分开,去解释不同的输入特征。
2.2共享参数
- 所有的slots初始化都是符合高斯分布随机生成,开始并没有绑定那个特征,都是在同一个特征空间中进行竞争解释,这是一个自适应的过程,参数自动调整。
- 这种灵活性在面对无监督对象发现时,可以很好的推广到更多的发现上,取得很好的效果。