TensorRT----RepVGG模型推理与部署
题目要求:学习了解结构重参数化模型RepVGG,基于TensorRT的python环境,统计训练模型,推理模型,float32, fp16下精度和速度。
RepVGG论文:RepVGG: Making VGG-style ConvNets Great Again
RepVGG 源码:RepVGG GitHub
分析:
1)了解RepVGG的基本原理和代码理解
2)将模型转化为更加方便高效的ONNX模型并在TensorRT中完成推理过程(并验证)
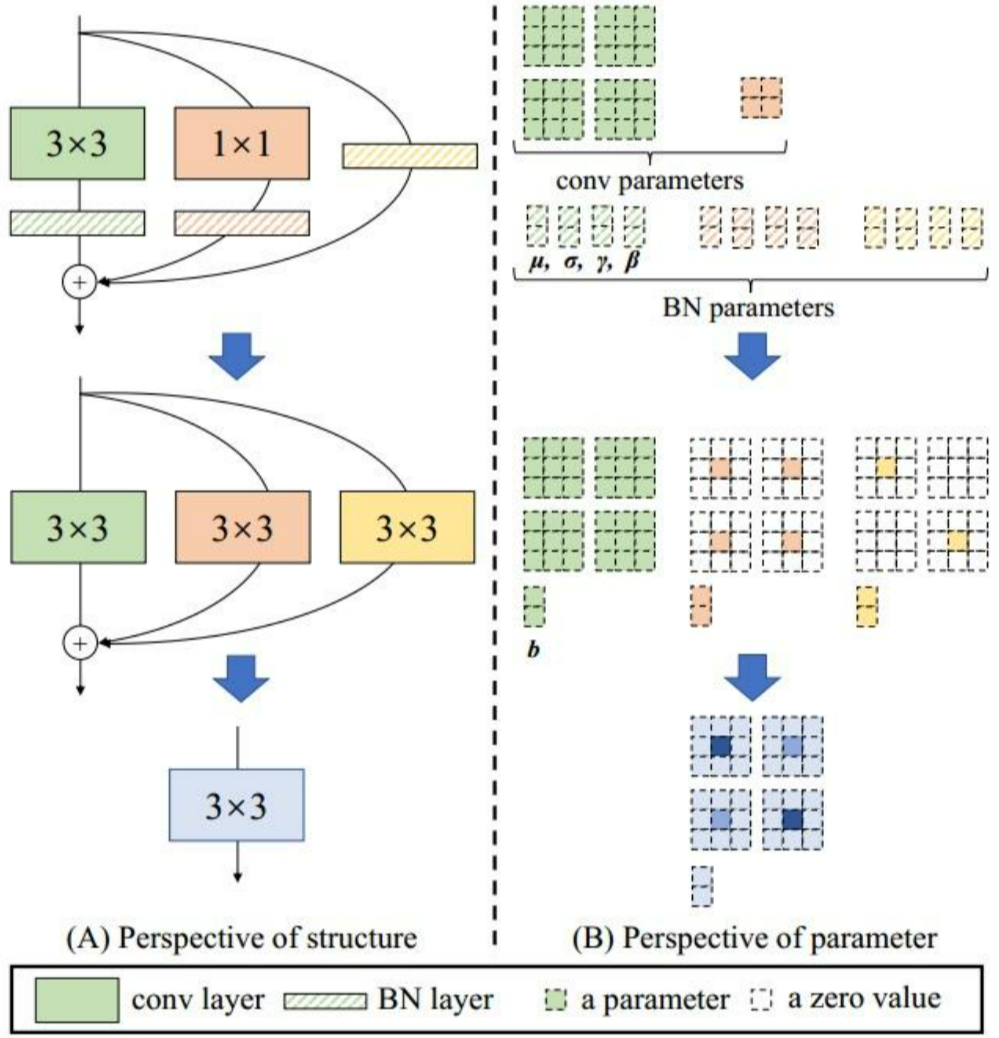
- 重参数化的数学原理:卷积算子的结合律: c o n v ( x , a ) + c o n v ( x , b ) = c o n v ( x , ( a + b ) ) conv(x,a) + conv(x,b) = conv(x, (a+b)) conv(x,a)+conv(x,b)=conv(x,(a+b))
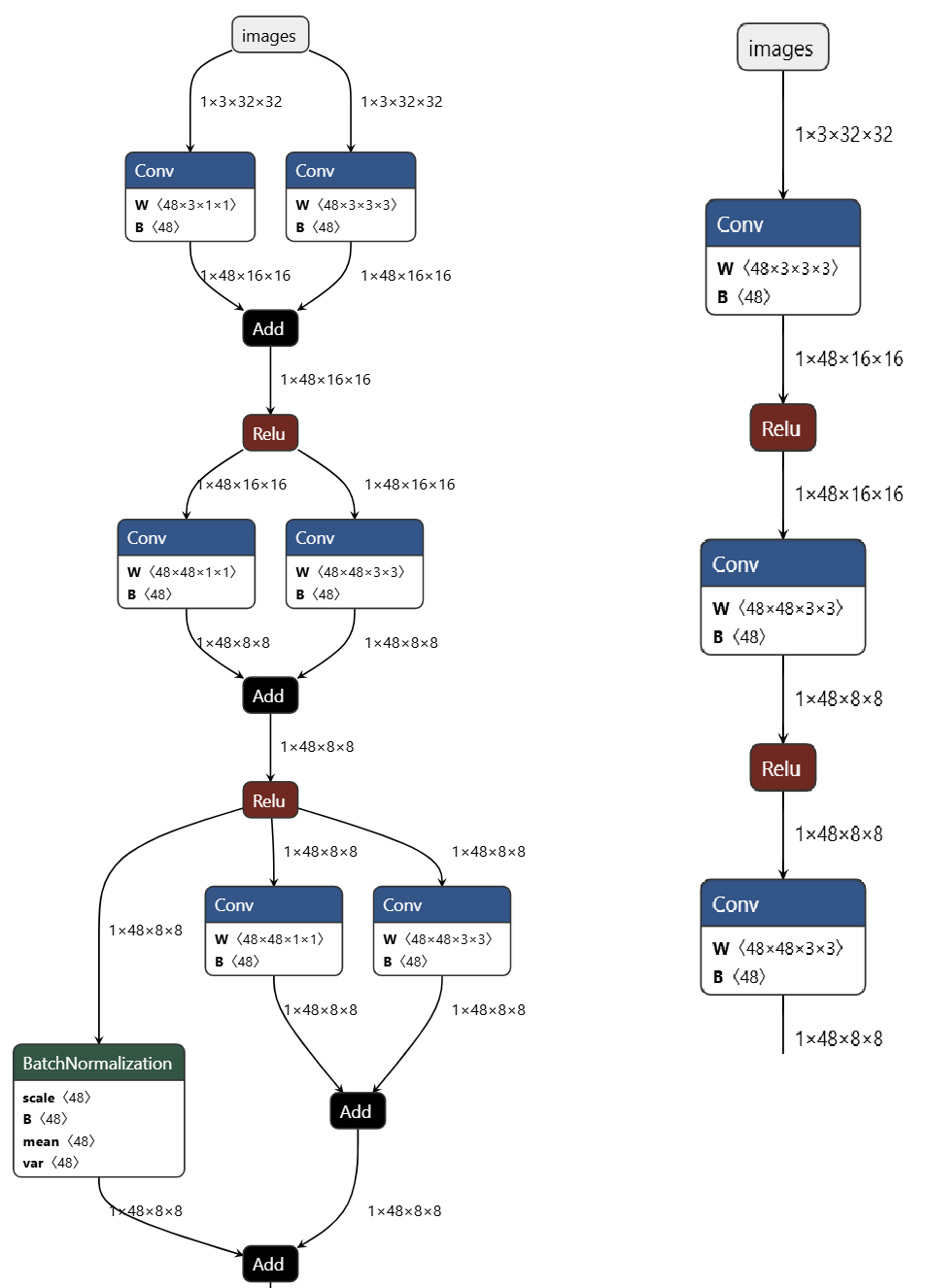
- 左图:训练模型(train.pnnx),右图:推理模型(deploy.onnx)
- 基于CIFAR10训练
from repvgg import create_RepVGG_A0
import torch
from torchvision.datasets import CIFAR10
from torchvision import transforms
import torch.nn as nn
import torch.optim as optimcifar_path = './'
device = torch.device("cuda:0")batch_size = 4
train_loader = torch.utils.data.DataLoader(CIFAR10(cifar_path, train=True, transform=transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))]), download=True), batch_size=batch_size, num_workers=0)
test_loader = torch.utils.data.DataLoader(CIFAR10(cifar_path, train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))]), download=True), batch_size=batch_size, num_workers=0)# model = RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
# width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=False)# state_dict = torch.load("weights/RepVGG-A0-train.pth", map_location='cpu')# # print(weights)
# model.load_state_dict(state_dict)
# model.linear = nn.Linear(model.linear.in_features, out_features=10)model = create_RepVGG_A0(deploy=False)model.to(device)# print(model)optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
# 每间隔几个epoch,调整学习率
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 5, 0.1)
criteration = nn.CrossEntropyLoss()# eval 的预测best_acc = 0
total_epochs = 100
for epoch in range(total_epochs):model.train()for i, (x, y) in enumerate(train_loader):x, y = x.to(device), y.to(device)optimizer.zero_grad()output = model(x)# pred = output.max(1, keepdim=True)[1]# correct += pred.eq(y.view_as(pred)).sum().item()loss = criteration(output, y)loss.backward()optimizer.step()if i % 100 == 0:print("Epoch %d/%d, iter %d/%d, loss=%.4f" % (epoch, total_epochs, i, len(train_loader), loss.item()))model.eval()total = 0correct = 0with torch.no_grad():for i, (img, target) in enumerate(test_loader):img = img.to(device)out = model(img)pred = out.max(1)[1].detach().cpu().numpy()target = target.cpu().numpy()correct += (pred == target).sum()total += len(target)acc = correct/totalprint("\tValidation : Acc=%.4f" % acc, "({}/{})".format(correct, len(test_loader.dataset)))if acc > best_acc:best_acc = acctorch.save(model, "repvgg_train.pth")scheduler.step()# print("第%d个epoch的学习率:%f" % (epoch, optimizer.param_groups[0]['lr']))
print("Best Acc=%.4f" % best_acc)- pth转onnx
from repvgg import *
device = torch.device("cpu")
# 这里的大小,是图片预期的大小
img = torch.rand((1, 3, 32, 32)).to(device)def onnxer(model, weight_path):# 使得BN和Dropout失效model.eval()# 导出的时候,不需要梯度with torch.no_grad():# 初始化一次y = model(img)try:import onnxfrom onnxsim import simplifyprint('\nStarting ONNX export with onnx %s...' % onnx.__version__)f = weight_path.replace('.pth', '.onnx') # filenametorch.onnx.export(model, img, f, verbose=False,opset_version=11,input_names=['images'],output_names=['output'] if y is None else ['output'])# Checksonnx_model = onnx.load(f) # load onnx modelmodel_simp, check = simplify(onnx_model)assert check, "Simplified ONNX model could not be validated"onnx.save(model_simp, f)# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable modelprint('ONNX export success, saved as %s' % f)except Exception as e:print('ONNX export failure: %s' % e)train_path = 'repvgg_train.pth'
train_model = torch.load(train_path)
onnxer(train_model, train_path)deploy_path = 'repvgg_deploy.pth'
deploy_model = repvgg_model_convert(train_model, create_RepVGG_A0, save_path=deploy_path)
onnxer(deploy_model, deploy_path)
- onnx转trt
trtexec --onnx=repvgg_deploy.onnx --saveEngine=repvgg_deploy.trt
trtexec --onnx=repvgg_deploy.onnx --saveEngine=repvgg_deploy_fp16.trt --fp16
-
精度和速度验证
- onnx inference
import onnx import numpy as np import onnxruntime as rt import cv2 import torch from repvgg import *# 这里的大小,是图片预期的大小 img = torch.rand((1, 3, 32, 32)) img_np = img.numpy()model_path = 'repvgg_train.onnx' # model_path = 'repvgg_deploy.onnx'# 验证模型合法性 onnx_model = onnx.load(model_path) onnx.checker.check_model(onnx_model)# 设置模型session以及输入信息 sess = rt.InferenceSession(model_path) input_name = sess.get_inputs()[0].nameoutput = sess.run(None, {'images': img_np}) print(output, np.max(output), np.argmax(output[0]))- Tensorrt inference
import pycuda import pycuda.driver as cuda import pycuda.autoinit import tensorrt as trt import torch import numpy as np# 前处理 def preprocess(data):data = np.asarray(data)return data# 后处理 def postprocess(data):data = np.reshape(data, (B, 3, H, W))return data# 创建build_engine类 class build_engine():def __init__(self, onnx_path):super(build_engine, self).__init__()self.onnx = onnx_pathself.engine = self.onnx2engine() # 调用 onnx2engine 函数生成 enginedef onnx2engine(self):# 创建日志记录器TRT_LOGGER = trt.Logger(trt.Logger.WARNING)# 显式batch_size,batch_size有显式和隐式之分EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)# 创建builder,用于创建networkbuilder = trt.Builder(TRT_LOGGER)network = builder.create_network(EXPLICIT_BATCH) # 创建network(初始为空)# 创建configconfig = builder.create_builder_config()profile = builder.create_optimization_profile() # 创建profileprofile.set_shape("input", (1,3,32,32), (2,3,32,32), (4,3,32,32)) # 设置动态输入,分别对应:最小尺寸、最佳尺寸、最大尺寸config.add_optimization_profile(profile)# config.max_workspace_size = 1<<30 # 允许TensorRT使用1GB的GPU内存,<<表示左移,左移30位即扩大2^30倍,使用2^30 bytes即 1 GB# 创建parser用于解析模型parser = trt.OnnxParser(network, TRT_LOGGER)# 读取并解析模型onnx_model_file = self.onnx # Onnx模型的地址model = open(onnx_model_file, 'rb')if not parser.parse(model.read()): # 解析模型for error in range(parser.num_errors):print(parser.get_error(error)) # 打印错误(如果解析失败,根据打印的错误进行Debug)# 创建序列化engineengine = builder.build_serialized_network(network, config)return enginedef get_engine(self):return self.engine # 返回 engine# 分配内存缓冲区 def Allocate_memory(engine, context):bindings = []for binding in engine:binding_idx = engine.get_binding_index(binding) # 遍历获取对应的索引size = trt.volume(context.get_binding_shape(binding_idx))# context.get_binding_shape(binding_idx): 获取对应索引的Shape,例如input的Shape为(1, 3, H, W)# trt.volume(shape): 根据shape计算分配内存 dtype = trt.nptype(engine.get_binding_dtype(binding))# engine.get_binding_dtype(binding): 获取对应index或name的类型# trt.nptype(): 映射到numpy类型if engine.binding_is_input(binding): # 当前index为网络的输入inputinput_buffer = np.ascontiguousarray(input_data) # 将内存不连续存储的数组转换为内存连续存储的数组,运行速度更快input_memory = cuda.mem_alloc(input_data.nbytes) # cuda.mem_alloc()申请内存bindings.append(int(input_memory))else:output_buffer = cuda.pagelocked_empty(size, dtype)output_memory = cuda.mem_alloc(output_buffer.nbytes)bindings.append(int(output_memory))return input_buffer, input_memory, output_buffer, output_memory, bindingsif __name__ == "__main__":# 设置输入参数,生成输入数据Batch_size = 1Channel = 3Height = 32Width = 32input_data = torch.rand((Batch_size, Channel, Height, Width))# 前处理input_data = preprocess(input_data)# 生成engine# onnx_model_file = "repvgg_deploy.onnx"onnx_model_file = "repvgg_train.onnx"engine_build = build_engine(onnx_model_file)engine = engine_build.get_engine()# 生成contextTRT_LOGGER = trt.Logger(trt.Logger.WARNING)runtime = trt.Runtime(TRT_LOGGER)engine = runtime.deserialize_cuda_engine(engine)context = engine.create_execution_context()# 绑定上下文B, C, H, W = input_data.shapecontext.set_binding_shape(engine.get_binding_index("input"), (B, C, H, W))# 分配内存缓冲区input_buffer, input_memory, output_buffer, output_memory, bindings = Allocate_memory(engine, context)# 创建Cuda流stream = cuda.Stream()# 拷贝数据到GPU (host -> device)cuda.memcpy_htod_async(input_memory, input_buffer, stream) # 异步拷贝数据# 推理context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)# 将GPU得到的推理结果 拷贝到主机(device -> host)cuda.memcpy_dtoh_async(output_buffer, output_memory, stream)# 同步Cuda流stream.synchronize()# 后处理# output_data = postprocess(output_buffer)max_value = np.max(output_buffer)max_indexes = np.argwhere(output_buffer == max_value).flatten()print("output.shape is : ", output_buffer.shape, max_indexes)- TensorRT time test
from time import time import numpy as np import tensorrt as trt from cuda import cudart # 安装 pip install cuda-python import torchnp.random.seed(1024) nWarmUp = 10 nTest = 30nB, nC, nH, nW = 1, 3, 32, 32 # dummy_input = np.random.rand(nB,nC,nH,nW) dummy_input = torch.rand((1, 3, 32, 32)) data = dummy_input.cpu().numpy()def run1(engine):input_name = engine.get_tensor_name(0)output_name = engine.get_tensor_name(1)output_type = engine.get_tensor_dtype(output_name)output_shape = engine.get_tensor_shape(output_name)context = engine.create_execution_context()context.set_input_shape(input_name, [nB, nC, nH, nW])_, stream = cudart.cudaStreamCreate()inputH0 = np.ascontiguousarray(data.reshape(-1))outputH0 = np.empty(output_shape, dtype=trt.nptype(output_type))_, inputD0 = cudart.cudaMallocAsync(inputH0.nbytes, stream)_, outputD0 = cudart.cudaMallocAsync(outputH0.nbytes, stream)# do a complete inferencecudart.cudaMemcpyAsync(inputD0, inputH0.ctypes.data, inputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice, stream)context.execute_async_v2([int(inputD0), int(outputD0)], stream)cudart.cudaMemcpyAsync(outputH0.ctypes.data, outputD0, outputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost, stream)cudart.cudaStreamSynchronize(stream)# Count time of memory copy from host to devicefor i in range(nWarmUp):cudart.cudaMemcpyAsync(inputD0, inputH0.ctypes.data, inputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice, stream)trtTimeStart = time()for i in range(nTest):cudart.cudaMemcpyAsync(inputD0, inputH0.ctypes.data, inputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice, stream)cudart.cudaStreamSynchronize(stream)trtTimeEnd = time()print("%6.3fms - 1 stream, DataCopyHtoD" % ((trtTimeEnd - trtTimeStart) / nTest * 1000))# Count time of inferencefor i in range(nWarmUp):context.execute_async_v2([int(inputD0), int(outputD0)], stream)trtTimeStart = time()for i in range(nTest):context.execute_async_v2([int(inputD0), int(outputD0)], stream)cudart.cudaStreamSynchronize(stream)trtTimeEnd = time()print("%6.3fms - 1 stream, Inference" % ((trtTimeEnd - trtTimeStart) / nTest * 1000))# Count time of memory copy from device to hostfor i in range(nWarmUp):cudart.cudaMemcpyAsync(outputH0.ctypes.data, outputD0, outputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost, stream)trtTimeStart = time()for i in range(nTest):cudart.cudaMemcpyAsync(outputH0.ctypes.data, outputD0, outputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost, stream)cudart.cudaStreamSynchronize(stream)trtTimeEnd = time()print("%6.3fms - 1 stream, DataCopyDtoH" % ((trtTimeEnd - trtTimeStart) / nTest * 1000))# Count time of end to endfor i in range(nWarmUp):context.execute_async_v2([int(inputD0), int(outputD0)], stream)trtTimeStart = time()for i in range(nTest):cudart.cudaMemcpyAsync(inputD0, inputH0.ctypes.data, inputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice, stream)context.execute_async_v2([int(inputD0), int(outputD0)], stream)cudart.cudaMemcpyAsync(outputH0.ctypes.data, outputD0, outputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost, stream)cudart.cudaStreamSynchronize(stream)trtTimeEnd = time()print("%6.3fms - 1 stream, DataCopy + Inference" % ((trtTimeEnd - trtTimeStart) / nTest * 1000))cudart.cudaStreamDestroy(stream)cudart.cudaFree(inputD0)cudart.cudaFree(outputD0)print("tensorrt result:", np.argmax(outputH0))if __name__ == "__main__":cudart.cudaDeviceSynchronize()# f = open("repvgg_train.trt", "rb") # 读取trt模型# f = open("repvgg_deploy.trt", "rb") # 读取trt模型f = open("repvgg_deploy_fp16.trt", "rb") # 读取trt模型runtime = trt.Runtime(trt.Logger(trt.Logger.WARNING)) # 创建一个Runtime(传入记录器Logger)engine = runtime.deserialize_cuda_engine(f.read()) # 从文件中加载trt引擎run1(engine) # do inference with single streamprint(dummy_input.shape, dummy_input.dtype)3. Inference time results
################## train.onnx float32 ################################0.033ms - 1 stream, DataCopyHtoD2.870ms - 1 stream, Inference0.033ms - 1 stream, DataCopyDtoH3.000ms - 1 stream, DataCopy + Inference
tensorrt result: 8
torch.Size([1, 3, 32, 32]) DataType.FLOAT DataType.FLOAT################## train.onnx fp16 ################################0.033ms - 1 stream, DataCopyHtoD1.376ms - 1 stream, Inference0.033ms - 1 stream, DataCopyDtoH1.239ms - 1 stream, DataCopy + Inference
tensorrt result: 8
torch.Size([1, 3, 32, 32]) DataType.FLOAT DataType.FLOAT################## deploy.onnx float32 ################################0.000ms - 1 stream, DataCopyHtoD1.114ms - 1 stream, Inference0.000ms - 1 stream, DataCopyDtoH1.234ms - 1 stream, DataCopy + Inference
tensorrt result: 8
torch.Size([1, 3, 32, 32]) DataType.FLOAT DataType.FLOAT
################## deploy.onnx fp16 ################################0.033ms - 1 stream, DataCopyHtoD0.655ms - 1 stream, Inference0.034ms - 1 stream, DataCopyDtoH0.733ms - 1 stream, DataCopy + Inference
tensorrt result: 9
torch.Size([1, 3, 32, 32]) DataType.FLOAT DataType.FLOAT
- 小结
1.RegVGG是一种典型的模型Low cost方案,从理论原理到实践证明了该设计思路的有效性,可以适用于大多数由 conv-BN-Residual 构成的特征提取模块,对实际推理加速具有显著优势;
2.本次实验基于CIFAR10分类模型使用最简单的create_RepVGG_A0模型,RegVGG相比于原始模型,同等条件下,能提升一倍以上的推理速度,同时保持精度相当,当然在Low Level网络(如Denoise, Demosaic, Derain, Deblur等)设计上需要进一步验证精度和速度,后面有时间会进一步对该模型进行验证设计;
3.多数研究提到,RepVGG是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。在低算力设备上,可能不如MobileNet和ShuffleNet系列适用。后续也可能考虑进行对比验证。
参考资料:
结构重参数化:利用参数转换解耦训练和推理结构
利用RepVGG训练一个cifar-10数据