Python 内存管理机制详解:从分配到回收的全流程剖析
在 Python 编程中,开发者无需像 C/C++ 那样手动分配和释放内存,但这并不意味着内存管理与我们无关。了解 Python 内存管理机制,能帮助我们编写出更高效、稳定的代码。接下来,我们将深入剖析 Python 内存管理的各个环节,并辅以丰富的图示与源码示例。
1.Python 内存管理架构概览
Python 的内存管理并非单一机制,而是由多个协同工作的模块构成,从底层操作系统到上层 Python 对象,形成了一个层次分明的架构。其核心组成部分包括内存分配器、垃圾回收器和对象管理,它们各司其职,确保内存的高效使用与合理回收。
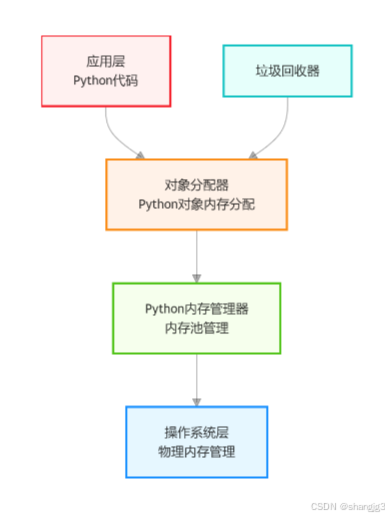
2.内存分配机制:按需索取
Python 的内存分配器会根据对象大小采取不同策略,主要分为小对象分配和大对象分配。
2.1小对象分配:内存池的高效利用
对于小于 512 字节的小对象,Python 通过预先创建的内存池进行分配。内存池就像一个仓库,按照固定大小划分成多个 "格子",每个 "格子" 对应一种特定大小的内存块。当需要创建小对象时,直接从对应大小的内存池中取出空闲内存块,无需向操作系统申请,这大大减少了内存碎片,提高了分配效率。
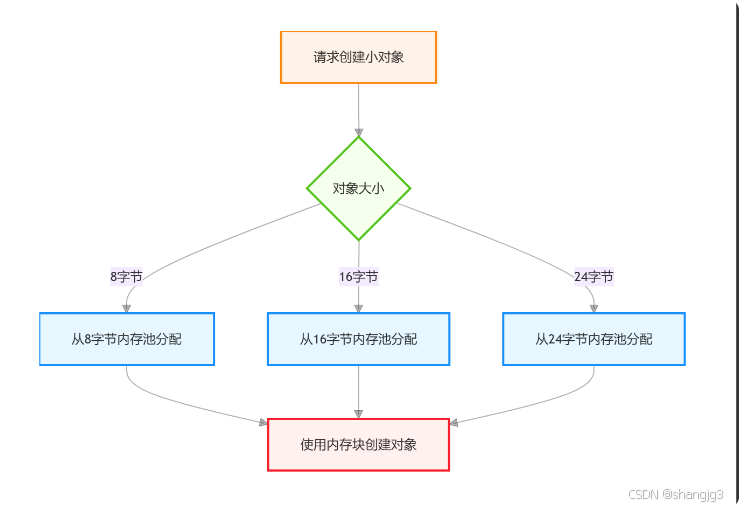
以下是一个简单示例,展示小对象的创建与内存分配:
a = "hello" # 创建字符串对象,从对应大小的内存池分配内存
b = 10 # 创建整数对象,同样从内存池获取内存
2.2大对象分配:直接向操作系统申请
当对象大小超过 512 字节时,Python 会跳过内存池,直接向操作系统申请内存。这种方式虽然灵活,但频繁申请和释放大内存块容易产生内存碎片,影响系统性能。
large_list = [i for i in range(1000000)] # 创建大列表,向操作系统申请内存
3.垃圾回收机制:自动清理 "内存垃圾"
Python 通过引用计数和分代回收两种机制,自动回收不再使用的内存,防止内存泄漏。
3.1引用计数:实时监控对象引用
每个 Python 对象都有一个引用计数,记录当前指向该对象的引用数量。当引用计数变为 0 时,意味着没有任何变量引用该对象,Python 会立即回收其占用的内存。我们可以使用`sys.getrefcount()`函数查看对象的引用计数(由于函数调用本身会增加一次引用,结果需减 1)。
import sysx = [1, 2, 3]
print(sys.getrefcount(x) - 1) # 输出1,x引用该列表y = x
print(sys.getrefcount(x) - 1) # 输出2,x和y都引用该列表del y
print(sys.getrefcount(x) - 1) # 输出1,仅剩x引用该列表del x
# 此时列表对象引用计数为0,内存被回收
3.2分代回收:处理循环引用难题
引用计数虽然高效,但无法解决循环引用问题,即多个对象相互引用,导致引用计数始终不为 0。为此,Python 引入分代回收机制。它将对象分为三代,根据对象存活时间划分:存活时间短的对象位于第 0 代,存活时间长的对象逐步晋升至更高代。垃圾回收时,优先扫描第 0 代,回收废弃对象;当第 0 代扫描次数达到阈值,才会扫描更高代。这种策略能有效处理循环引用,同时减少不必要的扫描开销。
import gcclass Node:def __init__(self):
self.next = Nonea = Node()
b = Node()
a.next = b
b.next = a # 形成循环引用del a
del b
# 若仅靠引用计数,a和b占用的内存无法回收gc.collect() # 手动触发垃圾回收,回收循环引用对象
4.内存优化实用技巧
掌握内存管理机制后,我们可以通过一些技巧优化代码的内存使用。
1. 使用生成器替代列表:生成器采用惰性计算,仅在需要时生成数据,避免一次性占用大量内存。
# 列表推导式,占用较多内存
squares_list = [x ** 2 for x in range(1000000)]# 生成器表达式,节省内存
squares_generator = (x ** 2 for x in range(1000000))
2. 及时删除不再使用的对象:使用`del`语句手动删除不再使用的变量,加速内存回收。
data = load_large_data() # 假设load_large_data返回大数据
process_data(data)
del data # 处理完后删除引用,释放内存
3. 选择合适的数据结构:根据需求选择内存占用更少的数据结构,如用`tuple`存储不可变数据,用`set`进行快速成员判断。
# tuple比list占用内存更少
point = (10, 20)# set用于快速查找,比list更高效
fruits = {"apple", "banana", "cherry"}
5.总结
Python 内存管理机制通过巧妙的设计,在易用性和性能之间取得了平衡。内存分配器按需提供内存,垃圾回收器自动清理废弃对象,而我们通过合理运用优化技巧,能进一步提升程序的内存效率。理解这些机制,不仅有助于编写高质量代码,还能在遇到内存相关问题时快速定位和解决。