Day02
1. 编译型语言和解释型语言的区别
编译型语言是指在程序运行之前,将源代码通过编译器一次性转换成机器码,生成可执行文件,运行时直接执行机器码,速度快且效率高,比如C、C++。
解释型语言是指在程序运行时,由解释器逐行读取、翻译并执行源代码,启动快但运行效率相对较低,比如Python、JavaScript。
2. ArrayList和Vector的比较
ArrayList 和 Vector 都是动态数组实现,区别在于 Vector 是同步的,线程安全但性能较低;ArrayList是非同步的,性能更好但线程不安全。扩容策略上,Vector 每次扩容容量翻倍,而 ArrayList 扩容约1.5倍。一般推荐单线程用 ArrayList,多线程需要线程安全时用 Vector。
3. HashMap的扩容条件是什么?
Java7中,HashMap扩容必须同时满足两个条件:
- 当前元素数量达到阈值(容量 x 加载因子,比如默认 16 x 0.75 = 12)。
- 新插入的元素发生了哈希冲突(即位置已被占用)。这样导致在某些特殊情况下,HashMap可能存入超过阈值的元素后才扩容,例如大量元素哈希冲突在同一槽位时扩容延迟。
Java8中,扩容条件简化为只要元素数量达到阈值就扩容,不再要求新插入元素必须发生哈希冲突,避免了Java7中扩容延迟带来的性能问题。
4. RabbitMQ怎么保证消息可靠性的?
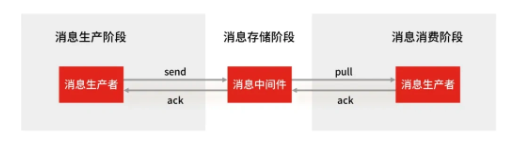
RabbitMQ 保证消息可靠性主要从生产、存储和消费三个阶段来实现。首先,在消息生产阶段,生产者发送消息后必须等待 RabbitMQ 返回确认(ack),如果出现异常则需要重试,确保消息成功写入队列,避免消息丢失。其次,在消息存储阶段,RabbitMQ 通常以集群方式部署,消息会同步写入多个节点副本,即使某个节点宕机,也能保证数据不丢失,提高系统的高可用性和容错能力。最后在消息消费阶段,消费者在完成消息处理后才发送确认,这样如果消费者异常宕机,消息不会丢失,RabbitMQ 会将未确认的消息重新投递给其他消费者。
5. Redis的ZSet使用了什么数据结构?
ZSet主要使用了跳表(Skip List)和哈希表(Hash Table)这两种数据结构。
跳表用于按照分数(score)进行排序,支持高效的范围查询和按排名排序操作,时间复杂度大约是O(logn)。
哈希表用于快速定位元素是否存在,实现元素的快速查找,时间复杂度是O(1)。
6. 了解Skip List吗?
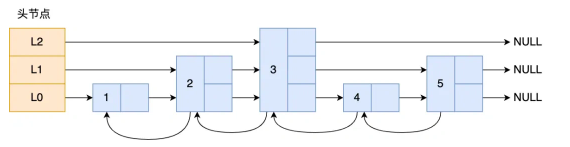
跳表的底层结构是多层的链表组成,每一层都是一个有序链表。最底层链表包含所有节点,其他层是对底层链表节点的“抽样”索引节点,层级越高节点越少。每个节点除了存储元素的值和指向下一节点的指针外,还包含多级的“forward”指针数组,用于指向不同层级的下一节节点,实现跨层跳跃。这样设计使得跳表在查找、插入、删除时,能够跳过大量节点,达到平均 O(logn) 的性能。
7. 为什么MySQL不用Skip List ?
B+树的高度在3层时存储的数据可能已达千万级别,但对于跳表而言同样去维护千万的数据量那么所造成的跳表层数过高而导致磁盘I/O次数增多,也就是使用B+树在存储同样的数据下磁盘I/O次数更少。
8. redis的使用场景
redis 是一个高性能的内存数据库,常用于缓存热点数据以减轻数据库压力,支持快速的计数器和限流操作,适合实现消息队列、排行榜、会话管理和分布式锁等功能。同时,redis 支持多种数据结构,方便实时数据分析和临时数据存储,广泛应用于对响应速度要求极高且持久性要求相对较低的场景。
9. redis性能好的原因是什么?
单线程的redis吞吐量可以达到10w/每秒,原因如下:
- 内存存储:redis的数据全部存储在内存中,避免了磁盘读写瓶颈,访问速度非常快。
- 单线程模型:采用单线程处理请求,避免了多线程竞争、上下文切换和死锁带来的性能损耗。
- I/O多路复用机制:使用select、epoll等多路复用技术,一个线程即可同时处理大量客户端连接,实现高并发。
- 高效数据结构:redis内置各种高效数据结构(如跳表、哈希表等),提升数据操作效率。
- 瓶颈在内存和网络:由于CPU不是瓶颈,reids的性能主要受限于机器内存和网络带宽。
10. Redis和MySQL结合使用时,如何保证两者数据的一致性?
Redis和MySQL联合使用时,一致性核心问题是数据更新时缓存和数据库的数据不一致。常见的解决方案是采用“先更新数据库,再删除缓存”的策略,这样可以避免旧数据被重新写回缓存;同时,配合设置缓存的过期时间来兜底,确保最终一致性。
对于高并发或对一致性要求更高的场景,可以引入消息队列异步删除或更新缓存,确保即使缓存操作失败也能最终完成。另外,通过分布式锁防止并发写冲突,也是保障一致性的重要手段。