【AI论文】QuickVideo:通过系统算法协同设计实现实时长视频理解
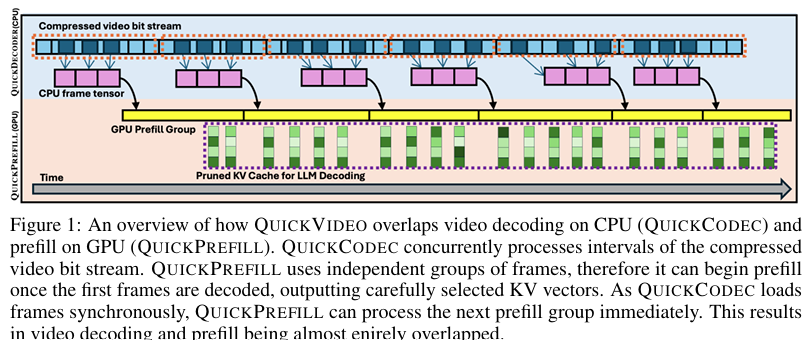
摘要:长视频理解已经成为视频监控、会议摘要、教育讲座分析和体育广播等现实应用中的一项关键能力。 然而,对于VideoLLMs来说,计算成本仍然过高,这主要是由于两个瓶颈:1)连续视频解码,将原始比特流转换为RGB帧的过程对于长达一小时的视频输入可能需要长达一分钟的时间,2)为LLM推理预先填充高达数百万个令牌的成本很高,导致延迟和内存使用很高。 为了应对这些挑战,我们提出了QuickVideo,这是一种系统算法协同设计,可以大大加速长视频理解,以支持实时下游应用。 它包括三个关键创新:QuickDecoder,一个基于CPU的并行视频解码器,通过将视频分割成关键帧对齐的区间并行处理,实现了2-3倍的速度提升; QuickPrefill,一种内存高效的预填充方法,使用KV缓存修剪来支持更多帧,减少GPU内存; 以及一种重叠方案,将CPU视频解码与GPU推理重叠。 这些组件共同推断出长视频输入的时间减少了一分钟,即使在有限的硬件上也能实现可扩展的高质量视频理解。 实验表明,QuickVideo可以跨持续时间和采样率进行泛化,使长视频处理在实践中可行。Huggingface链接:Paper page,论文链接:2505.16175
研究背景和目的
研究背景:
随着互联网的发展,视频数据已成为在线信息传递的主要形式。截至2023年,视频数据占互联网传输总数据的三分之二,其中长视频(从几分钟到几小时不等)占据了相当大的比例。这些长视频数据来源于在线会议、游戏直播、社交网络、电影流媒体等多个领域,对视频内容的自动化理解提出了迫切需求。视频大型语言模型(VideoLLMs)作为一种强大的工具,能够处理整个视频输入,展现出理解和推理视频内容的巨大潜力。然而,使用VideoLLMs进行长视频理解面临两大效率挑战:一是视频解码过程耗时较长,将原始比特流转换为RGB帧可能需要长达一分钟的时间;二是LLM推理前的预填充步骤计算和内存密集,对于长达一小时的视频输入,即使以较低的帧率(如1-2FPS)进行采样,也可能产生数百万个令牌,远超标准GPU的内存预算。
研究目的:
为了解决上述挑战,本文提出了QuickVideo框架,旨在通过系统算法协同设计加速长视频理解,以支持实时下游应用。QuickVideo的目标是减少长视频处理的时间延迟和资源需求,使得在有限硬件上也能实现高效、高质量的视频理解。
研究方法
QuickVideo框架包含三个核心创新:
- QuickCodec:并行化视频解码器
- 方法描述:QuickCodec是一个专为VideoLLMs设计的视频解码器,通过并行处理关键帧对齐的视频区间来加速解码过程。它将视频分割成多个关键帧对齐的区间,并使用多个CPU核心并行处理这些区间,从而实现2-3倍的速度提升。
- 技术细节:QuickCodec利用视频文件中的关键帧信息,通过SEEK子程序定位到关键帧位置,并从该位置开始解码,直到达到区间末尾。通过并行处理多个区间,QuickCodec显著减少了视频加载时间。
- QuickPrefill:高效的预填充方法
- 方法描述:QuickPrefill采用分组预填充和KV缓存修剪策略,显著减少预填充阶段的计算时间和内存使用。它将视频令牌序列分割成多个组,并依次对每个组进行预填充,同时保存对应的键值(KV)缓存。在预填充每个组时,通过修剪不重要的KV缓存向量来减少内存占用。
- 技术细节:QuickPrefill使用重要性评分函数(如Key Norms)来决定哪些KV缓存向量需要保留,从而在保持模型性能的同时减少内存使用。实验表明,通过修剪一半的KV缓存向量,QuickPrefill能够在大多数基准测试中保持超过95%的原始性能。
- 重叠执行方案
- 方法描述:QuickVideo通过重叠CPU视频解码和GPU推理来最大化资源利用率。在QuickCodec加载视频帧的同时,QuickPrefill开始对已加载的帧进行预填充。通过精心设计的调度策略,确保GPU在解码下一个视频区间时不会空闲,从而实现接近完全的重叠。
- 技术细节:重叠执行方案通过调整视频区间的加载顺序和预填充组的处理顺序,使得CPU和GPU能够几乎同时工作,从而显著减少整体处理时间。
研究结果
- QuickCodec性能
- 视频加载速度:在加载一小时长的24FPS 1080p高清视频(采样率为1FPS并调整为448x448像素)时,QuickCodec相比其他解码框架(如Decord和TorchCodec)表现出显著的速度提升。特别是在使用16-32个CPU核心时,QuickCodec的加载时间比其他框架快2-3倍,减少了超过20秒的视频加载时间。
- 不同视频长度的性能:QuickCodec在处理不同长度的视频时也表现出良好的扩展性。对于10分钟到一小时长的视频,QuickCodec的加载时间随着视频长度的增加而线性增长,但始终优于其他解码框架。
- QuickPrefill性能
- KV缓存修剪效果:通过对比不同KV缓存修剪方法(如Value Norms、Attention Scores和Key Norms)的效果,发现Key Norms方法在保持模型性能的同时实现了最高的内存节省。在修剪一半KV缓存向量的情况下,Key Norms方法在多个基准测试中保持了超过95%的原始性能。
- 组大小和保留比率的影响:通过改变组大小和KV缓存保留比率,发现组大小对模型性能的影响较小,而增加保留比率可以显著提高准确性。较小的组大小可以降低激活内存,而较低的保留比率可以减少KV缓存内存。
- 端到端推理延迟
- 整体性能提升:通过集成QuickCodec和QuickPrefill,并采用重叠执行方案,QuickVideo显著减少了长视频推理的端到端延迟。在处理30分钟长的视频时,QuickVideo的推理时间从69.7秒减少到20.0秒,实现了超过3倍的速度提升。
研究局限
- 视频解码器的局限性:
- QuickCodec目前主要支持H.264编码的视频文件,尽管H.264是主导标准,但并非所有视频都使用此编码格式。未来需要扩展对其他编码格式的支持。
- 对于非常短的视频(如几分钟以内),QuickCodec的性能提升可能不如长视频显著,因为解码开销在总处理时间中所占比例较小。
- 预填充方法的局限性:
- 尽管QuickPrefill通过KV缓存修剪显著减少了内存使用,但在某些对准确性要求极高的应用场景中,可能需要保留更多的KV缓存向量以确保模型性能。
- 当前的KV缓存修剪策略主要基于静态的重要性评分函数,未来可以探索更动态的修剪策略,以适应不同视频内容和推理需求。
- 重叠执行方案的局限性:
- 重叠执行方案依赖于精心设计的调度策略,以确保CPU和GPU能够几乎同时工作。然而,在实际应用中,由于硬件资源限制和系统负载变化,可能难以实现完美的重叠。
- 对于非常长的视频(如数小时以上),即使采用QuickVideo框架,也可能面临内存和计算资源的瓶颈。未来需要进一步优化系统架构和算法设计,以支持更长时间的视频处理。
未来研究方向
- 扩展视频解码器的支持范围:
- 未来研究可以探索对更多视频编码格式的支持,如H.265、VP9等,以提高QuickVideo框架的通用性和适用性。
- 针对不同长度的视频,可以设计更智能的解码策略,以在保持性能的同时减少不必要的计算开销。
- 优化预填充方法:
- 探索更动态的KV缓存修剪策略,以适应不同视频内容和推理需求。例如,可以根据视频内容的复杂度和重要性动态调整保留比率。
- 研究其他预填充优化技术,如增量预填充、分布式预填充等,以进一步提高预填充阶段的效率和可扩展性。
- 改进重叠执行方案:
- 开发更智能的调度算法,以更好地适应不同硬件资源和系统负载变化。例如,可以根据CPU和GPU的实时利用率动态调整视频区间的加载顺序和预填充组的处理顺序。
- 探索将QuickVideo框架与其他并行计算技术(如多GPU并行、分布式计算等)相结合的可能性,以支持更长时间的视频处理和更大规模的推理任务。
- 探索新的应用场景:
- 将QuickVideo框架应用于更多领域,如视频监控、自动驾驶、虚拟现实等,以验证其在实际应用中的有效性和可靠性。
- 研究QuickVideo框架在边缘计算设备上的部署可能性,以支持低延迟、高带宽的视频处理需求。
- 关注隐私和安全问题:
- 在开发和应用QuickVideo框架时,需要充分考虑隐私和安全问题。例如,确保视频数据在处理过程中不被泄露或滥用,以及防止恶意用户利用QuickVideo框架进行非法活动。
综上所述,QuickVideo框架通过系统算法协同设计显著加速了长视频理解过程,为实时下游应用提供了有力支持。未来研究可以进一步扩展其支持范围、优化预填充方法、改进重叠执行方案,并探索新的应用场景和关注隐私安全问题,以推动长视频理解技术的持续发展和广泛应用。