ClickHouse讲解
ClickHouse基础讲解
1、ClickHouse介绍
ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理(OLAP),能够使用SQL查询来实时生成分析数据报告,适用于实时数仓的应用。
关键名词讲解:
OLAP(在线分析处理)是一种数据分析技术,专注于分析处理。从数据库操作角度,OLAP是对数据的查询,属于读密集型。
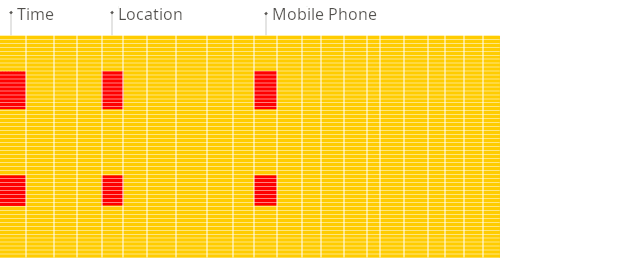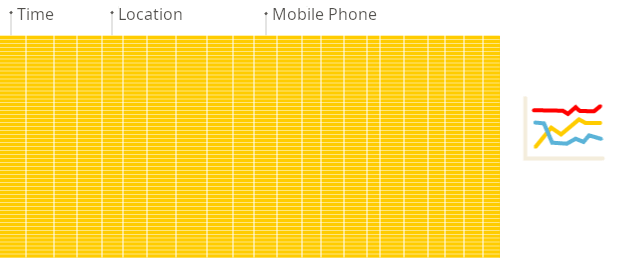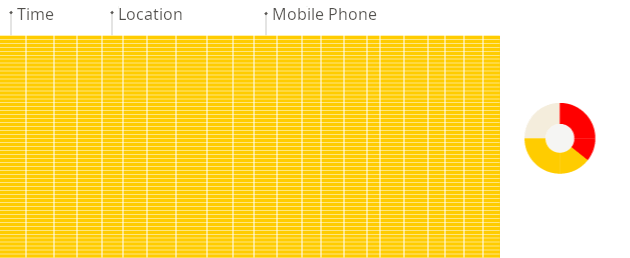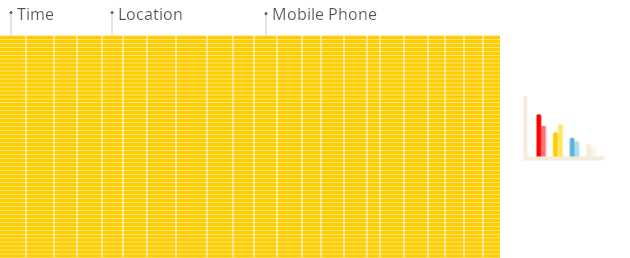
面向列的数据库更适合 OLAP 场景:它们处理大多数查询的速度至少快 100 倍。
面向【列】的数据库管理系统:
面向【行】的数据库管理系统:
OLTP(在线事务处理)则是专注于事务处理,从数据库操作角度,OLTP主要是对数据的增删改,属于写密集型。
2、ClickHouse特点
-
列式存储:在列式存储中,数据表中的每一列都被视为一个独立的单元进行存储。这意味着,如果有一个包含多个字段(列)的表,那么每个字段(列)的数据都会单独存储在一个物理位置。
为了更好的说明列式存储,以下面这个表为例:

列式存储数据在磁盘上的组织结构大致如下:

-
高速读写:类 LSM Tree结构。
1、写入过程讲解:
-
类似于HBase Memcache写入。(1)数据首先被存储在内存(Memcache)进行缓存,这些数据以较小的块(parts)形式顺序append写入磁盘。(2)ClickHouse自动定期 Compact 合并操作,在compact合并过程中Merge Sort(归并排序),使得合并后的数据块将保持有序。(3)当排序和合并操作结束后会进行落盘操作(新的、更大的数据块会被写回磁盘,替换掉旧的、小的数据块【历史版本删除】),写入操作后数据状态为只读。
★ 补充点:在合并中会有更高级操作:Major Compact。Major Compact是相对于Compact更为彻底的数据合并操作,同样会删除历史版本。Major Compact并不会像Compact操作那么频繁,具体取决于系统配置和数据量。
2、ClickHouse 充分利用所有可用的系统资源来尽快处理每个分析查询。这之所以成为可能,是因为分析能力和对实现最快 OLAP 数据库所需的低级细节的关注的独特组合。
3、ClickHouse的高速读写特性是针对OLAP场景优化的
-
-
多样化表引擎:ClickHouse和MySQL类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。包括合并树、日志、集成接口和其他特殊这四大类20多种表引擎。
-
数据分区与线程级并行:ClickHouse通过多分区(partition)和index granularity(索引粒度)划分数据,利用多CPU核心并行处理单条查询,降低查询延时。然而,这可能导致QPS(每秒查询次数)弱,CPU开销大。
3、数据类型
一:整型
固定长度的整型,包括有符号整型或无符号整型。
扩展:toTypeName(字段名) 获取字段类型
=> 有符号
具体内容:Int8 , Int16 , Int32 , Int64
范围:(-2n-1~2n-1 -1)
=> 无符号
具体内容:UInt8 , UInt16 , UInt32 , UInt64
范围:(0~2^n-1)
二:浮点型
👉 注意:尽量用整型,将小数放大
扩展:toTypeName(字段名) 获取字段类型
具体内容:
(1)Float32 :对应float
(2)Float64:对应double
三:Decimal型
基本格式:Decimal(s) 【s表示精度】
精准性:有符号的浮点数,可在加、减和乘法运算过程中保持精度
扩展:toTypeName(字段名) 获取字段类型
具体内容:👉 注意:尽量用整型,将小数放大
➢ Decimal32(s),相当于 Decimal(9-s,s),有效位数为 1~9
➢ Decimal64(s),相当于 Decimal(18-s,s),有效位数为 1~18
➢ Decimal128(s),相当于 Decimal(38-s,s),有效位数为 1~38
四:布尔型
具体内容:Bool
说明:布尔型(bool)在其内部存储为UInt8。因此,可以使用
UInt8类型,并将取值限制为 0 或 1 来代替。扩展:toTypeName(字段名) 获取字段类型
五:字符串
具体内容:
(1)String:相当于varchar
(2)FixedString(N):相当于char(N)
扩展:toTypeName(字段名) 获取字段类型
六:枚举类型
本质:字符串的语义映射便于存储的整数
语法:保存
“String”=Int的对应关系具体内容:Enum8,Enum16
扩展:toTypeName(字段名) 获取字段类型
基本案例:
create table t_enum(id UInt8,word Enum8('boy' = 1,'girl' = 2) ) engine = MergeTree() order by id;insert into t_enum values (1,'boy'), (2,'girl'), (3,'girl'), (4,'boy'), (5,'girl');select * from t_enum where word = 2; ----------------------------- ┌─id─┬─word─┐ │ 2 │ girl │ │ 3 │ girl │ │ 5 │ girl │ └────┴──────┘ -----------------------------特殊:通过 cast(枚举字段, Int8) 函数转为整数
select CAST(word as Int8) as Int_value from t_enum order by id; --------------------- ┌─Int_value─┐ │ 1 │ │ 2 │ │ 2 │ │ 1 │ │ 2 │ └───────────┘ ---------------------
七:时间类型
扩展:toTypeName(字段名) 获取字段类型
ClickHouse通常有三种时间类型:
Date接受yyyy-MM-dd的字符串,比如:2018-07-16;Datetime接受yyyy-MM-dd HH:mm:ss的字符串,比如2024-08-12 09:06:10;Datetime64(精度, 时间的时区)接受yyyy-MM-dd HH:mm:ss.SSS(SSS表示亚秒)的字符串,比如2024-08-12 09:06:10.66。对Datetime64(精度, 时间的时区)进行讲解:
精度有三个选择:3(毫秒)、6(微秒)、9(纳秒)
小型案列:
create table if not exists t_date(id UInt8,time datetime64(3,'Asia/Shanghai') )engine = MergeTree() order by id;insert into t_date values (1,'2024-08-12 16:06:10.32'), (2,'2024-06-22 10:06:20.14'), (3,'2024-07-07 09:16:17.65'), (4,'2024-08-10 17:05:00.16');select * from t_date; ----------------------------------- ┌─id─┬────────────────────time─┐ │ 1 │ 2024-08-12 16:06:10.320 │ │ 2 │ 2024-06-22 10:06:20.140 │ │ 3 │ 2024-07-07 09:16:17.650 │ │ 4 │ 2024-08-10 17:05:00.160 │ └────┴─────────────────────────┘ -----------------------------------
八:数组
具体内容:Array(T)
- T:类似泛型,但不建议 T 为数组,尤其是 MergeTree 引擎
扩展:toTypeName(字段名) 获取字段类型
小型案例:
create table if not exists t_array(id UInt8,x Array(Nullable(String)) -- Nullable表示允许空值 )engine = MergeTree() order by id;-- 使用语法:array(1,2,3) | [1,2,3] insert into t_array values (1,array('i','am','boy')), (2,array('i','am','girl')), (3,array('how','are','you'));select * from t_array; -------------------------------- ┌─id─┬─x───────────────────┐ │ 1 │ ['i','am','boy'] │ │ 2 │ ['i','am','girl'] │ │ 3 │ ['how','are','you'] │ └────┴─────────────────────┘ --------------------------------
九:元组
具体内容:Tuple(T1, T2, …)
扩展:toTypeName(字段名) 获取字段类型
小型案例:
create table if not exists t_tuple(id UInt8,attributes Tuple(age UInt8, height UInt16) )engine = MergeTree() order by id;insert into t_tuple values (1,(17,178)), (2,(24,160)), (3,(20,177));select * from t_tuple; ---------------------- ┌─id─┬─attributes─┐ │ 1 │ (17,178) │ │ 2 │ (24,160) │ │ 3 │ (20,177) │ └────┴────────────┘ ----------------------
十:键值对
具体内容:Map(K,V)
注意:需提前开启map开关(set allow_experimental_map_type = 1;)
扩展:toTypeName(字段名) 获取字段类型
小型案例:
set allow_experimental_map_type = 1; -- 开启map开关create table if not exists t_map(id UInt8,scores Map(String,UInt8) )engine = MergeTree() order by id;insert into t_map values (1,{'java':69, 'mysql':98}), (2,{'java':71, 'mysql':78}), (3,{'java':90, 'mysql':68});select * from t_map; --------------------------------- ┌─id─┬─scores─────────────────┐ │ 1 │ {'java':69,'mysql':98} │ │ 2 │ {'java':71,'mysql':78} │ │ 3 │ {'java':90,'mysql':68} │ └────┴────────────────────────┘ ---------------------------------
4、引擎介绍
ClickHouse 和 MySql 一样存在多个引擎
一:数据库引擎
- Atomic
- 默认,且推荐,由 clickhouse 管理数据
- MySQL
- MaterializedMySQL
- Lazy
- 非频繁访问,适用于 Log
- PostgreSQL
- MaterializedPostgreSQL
- Replicated
- SQLite
二:表引擎
- 决定数据的存储方式和位置
- 支持的查询类型
- 是否支持数据并发访问
- 是否支持多线程
- 如果使用索引
- 数据复制参数
👉 注意:引擎名称大小写敏感,不能写错
合并树家族
- 👉 MergeTree
- 支持索引和分区
- ReplacingMergeTree
- 去重
- SummingMergeTree
- 求和
- AggregatingMergeTree
- 聚合
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
日志家族
- TinyLog
- 小表,无索引,无并发
- StripeLog
- Log
集成家族
ODBC
JDBC
MySQL
MongoDB
Redis
HDFS
S3
👉 Kafka
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] (name1 [type1] [ALIAS expr1],name2 [type2] [ALIAS expr2],... ) ENGINE = Kafka() SETTINGSkafka_broker_list = 'host:port',kafka_topic_list = 'topic1,topic2,...',kafka_group_name = 'group_name',kafka_format = 'data_format'[,][kafka_schema = '',][kafka_num_consumers = N,][kafka_max_block_size = 0,][kafka_skip_broken_messages = N,][kafka_commit_every_batch = 0,][kafka_client_id = '',][kafka_poll_timeout_ms = 0,][kafka_poll_max_batch_size = 0,][kafka_flush_interval_ms = 0,][kafka_thread_per_consumer = 0,][kafka_handle_error_mode = 'default',][kafka_commit_on_select = false,][kafka_max_rows_per_message = 1];CREATE TABLE queue2 (timestamp UInt64,level String,message String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'localhost:9092', kafka_topic_list = 'topic', kafka_group_name = 'group1', kafka_format = 'JSONEachRow', kafka_num_consumers = 4;CREATE TABLE daily (day Date,level String,total UInt64 ) ENGINE = SummingMergeTree(day, (day, level), 8192);CREATE MATERIALIZED VIEW consumer TO dailyAS SELECT toDate(toDateTime(timestamp)) AS day, level, count() as totalFROM queue GROUP BY day, level;SELECT level, sum(total) FROM daily GROUP BY level;必选参数
kafka_broker_list
Kafka代理(Broker)列表(如:master01:9092,master02:9092,worker01:9092)
kafka_topic_list
Kafka主题的列表,每个主题都是Kafka中用于存储消息的逻辑分区。
kafka_group_name
Kafka消费者的组名。Kafka的消费者组用于跟踪每个消费者的读取进度,确保消息在组内的消费者之间均衡分配,且每条消息只被组内的一个消费者读取。如果你不希望消息在集群中被重复读取,那么应该在所有地方使用相同的组名。
kafka_format
Kafka消息格式。这个参数使用与SQL的FORMAT函数相同的表示法。
指定了Kafka消息的序列化和反序列化格式。
不同的格式支持不同的数据表示方式,如JSONEachRow、CSV等。
选择合适的格式取决于你的具体需求和数据结构。可选参数
kafka_schema
如果格式要求定义模式(schema),则必须使用的参数。这个参数确保了在序列化和反序列化消息时,数据符合预定的数据结构。
kafka_num_consumers
每个表的消费者数量。如果单个消费者的吞吐量不足,可以指定更多的消费者。但消费者总数不应超过主题中的分区数,因为每个分区只能分配给一个消费者,同时也不应大于部署ClickHouse的服务器上的物理核心数。默认值:1。
kafka_max_block_size
poll操作的最大批次大小(以消息数计)。这有助于控制一次性从Kafka读取和处理的数据量。默认值:max_insert_block_size。kafka_skip_broken_messages
Kafka消息解析器对每个块中模式不兼容消息的容忍度。如果
kafka_skip_broken_messages = N,则引擎会跳过N个无法解析的Kafka消息(一个消息等于一行数据)。这有助于跳过因模式变更等原因导致的不兼容消息。默认值:0。kafka_commit_every_batch
是否每消费并处理一个批次就提交一次,而不是在写入整个块后才进行单次提交。这有助于更频繁地更新消费者的偏移量,但可能增加写入的开销。默认值:0(不每批次提交)。
kafka_client_id
客户端标识符。默认情况下为空。这有助于在Kafka的日志和监控中标识来自不同来源的客户端请求。
kafka_poll_timeout_ms
从Kafka进行单次
poll操作的超时时间。这定义了等待从Kafka服务器接收数据的时间长度。默认值:stream_poll_timeout_ms。kafka_poll_max_batch_size
单次Kafka
poll操作中要拉取的最大消息数量。这有助于控制从Kafka一次性读取的数据量。默认值:max_block_size。kafka_flush_interval_ms
从Kafka刷新数据的超时时间。这定义了将数据从Kafka写入到ClickHouse(或其他存储系统)的时间间隔。默认值:
stream_flush_interval_ms。kafka_thread_per_consumer
是否为每个消费者提供独立的线程。启用时,每个消费者将独立并行地刷新数据(否则,来自多个消费者的行将被压缩以形成一个块)。这可以增加并行性,但也可能增加资源消耗。默认值:0(不使用独立线程)。
kafka_handle_error_mode
Kafka引擎处理错误的方式。可能的值包括:
default(如果无法解析消息,则抛出异常),stream(异常消息和原始消息将被保存在虚拟列_error和_raw_message中)。kafka_commit_on_select
在执行选择查询时是否提交消息。这通常不是推荐的做法,因为它可能会导致消息被重复处理,但如果出于某些特殊需求需要这样做,可以启用此选项。默认值:
false。kafka_max_rows_per_message
对于基于行的格式,每个Kafka消息中写入的最大行数。这有助于控制消息的大小和处理的复杂性。默认值:1(每个消息只写一行)。
EmbeddedRocksDB
RabbitMQ
PostgreSQL
S3Queue
其他特殊
- Distributed
- Dictionary
- Merge
- File
- Null
- Set
- Join
- URL
- View
- Memory
- 不压缩,进内存,重启后数据丢失,无索引,简单查询
- Buffer
- KeeperMap
5、ClickHouse与IDEA连接
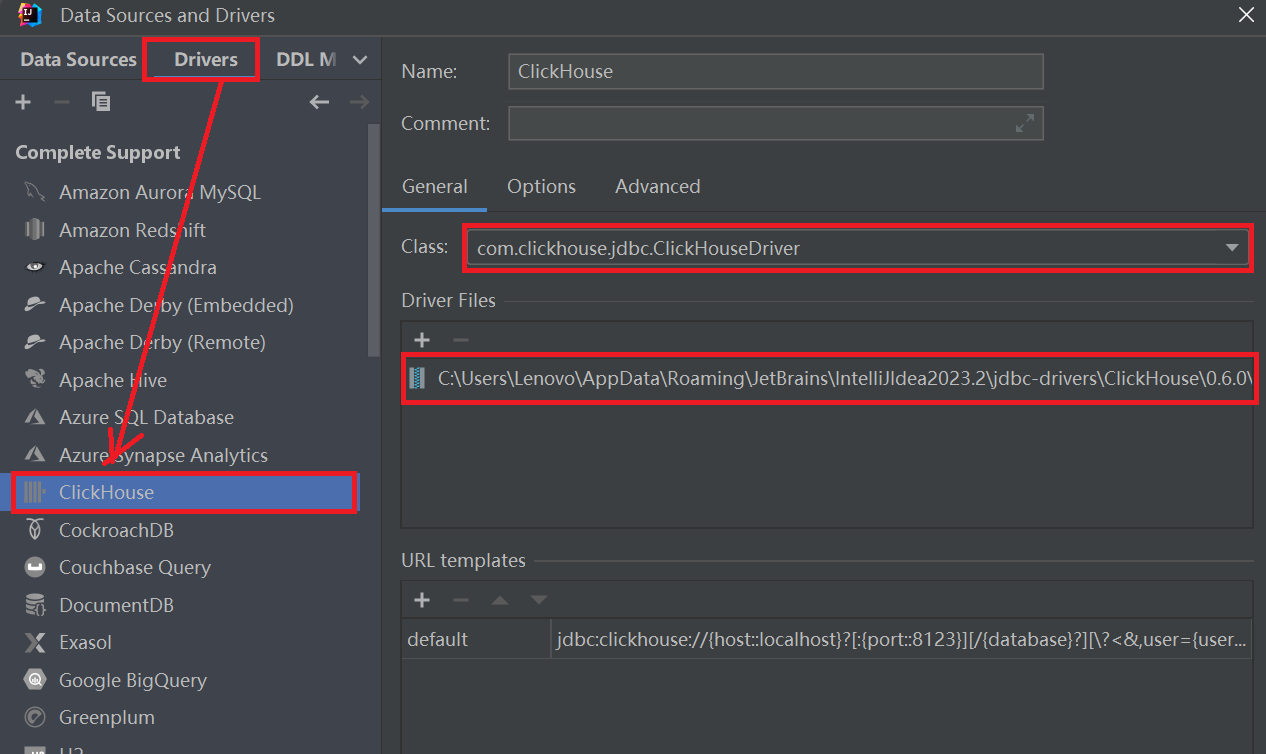
1、驱动可能不能正常下载:选择手动本地添加,将驱动放置C:\Users\Chen\AppData\Roaming\JetBrains\IntelliJIdea2021.3\jdbc-drivers\ClickHouse\0.6.0 目录下
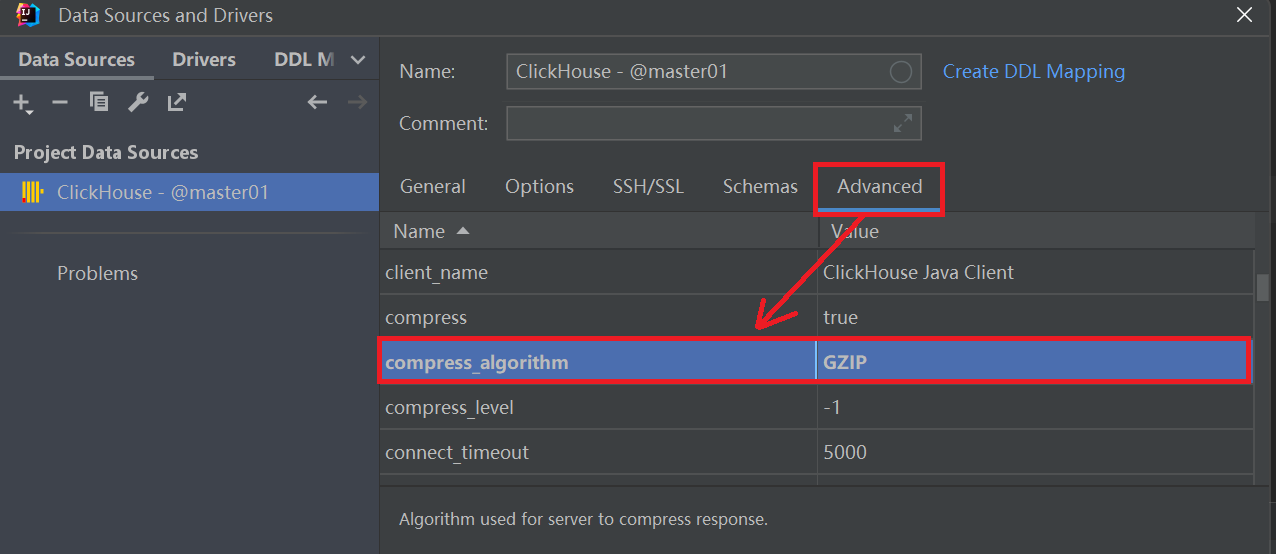
2、LZ4 压缩算法不支持报错:修改
具体操作:Data Source & Drivers => Advanced => compress_algorithm => 从 lz4 修改为 gzip
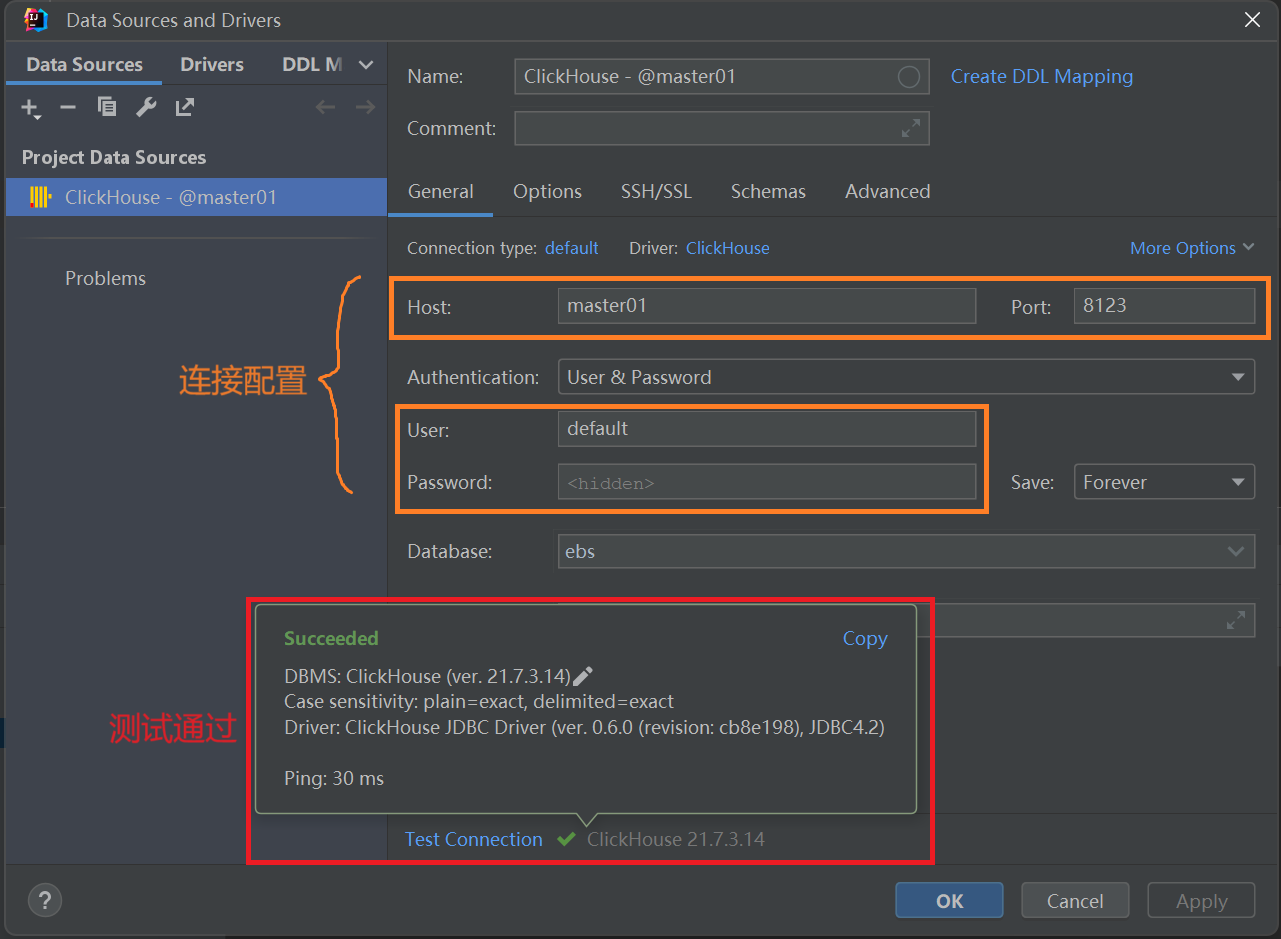
3、连接相关的配置操作,进行测试