图解 | 大模型智能体LLM Agents
文章目录
- 正文
- 1. 存储 Memory
- 1.1 短期记忆 Short-Term Memory
- 1.1.1 模型的上下文窗口
- 1.1.2 对话历史
- 1.1.3 总结对话历史
- 1.2 长期记忆Long-term Memory
- 2. 工具Tools
- 2.1 工具的类型
- 2.2 function calling
- 2.3 Toolformer
- 2.3.1 大模型调研工具的过程
- 2.3.2 生成工具调用数据集
- 2.4 模型上下文协议 Model Context Protocol (MCP)
- 2.4.1 为什么需要 MCP?
- 2.4.2 MCP 组成
- 2.4.3 MCP 工作流程
资料来源文档:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-llm-agents
中文翻译:https://mp.weixin.qq.com/s/QFJyS0TUCv-TT39isRLu3w
正文
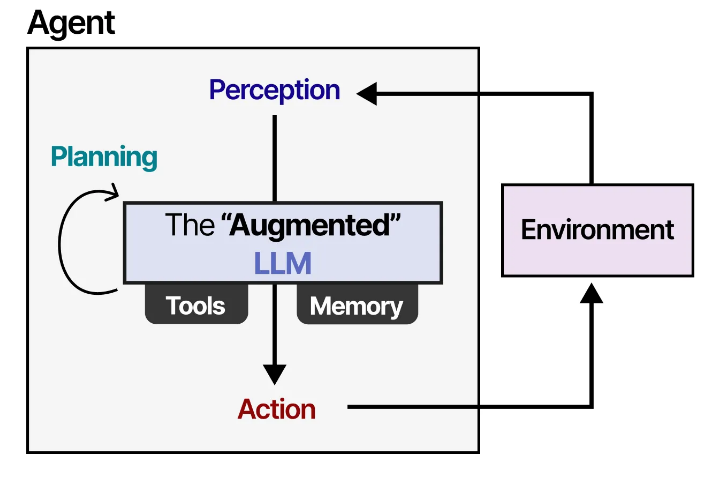
1. 存储 Memory
LLM 是健忘的系统,或者更准确地说,在与它们交互时根本不执行任何记忆。例如,当你问一个 LLM 问题,然后接着问另一个问题时,它不会记住前者。
以下是一个没有对话依赖的例子:
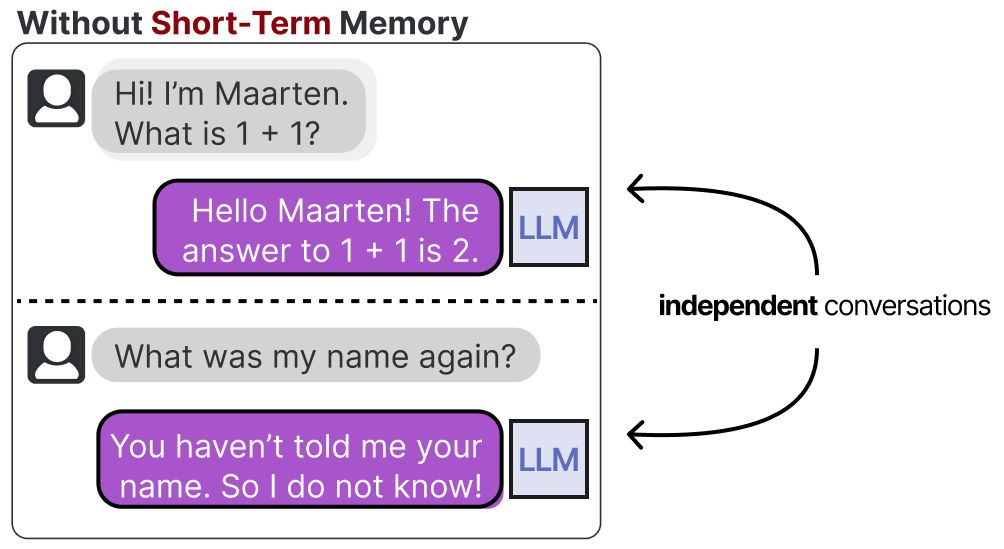
我们通常将其称为**短期记忆(Short-Term Memory),也称为工作记忆,它的功能是(近乎)即时环境的缓冲。这包括LLM代理最近采取的行动 Atcion。**
但是,LLM代理还需要跟踪可能有几十个步骤,而不仅仅是最近的操作。
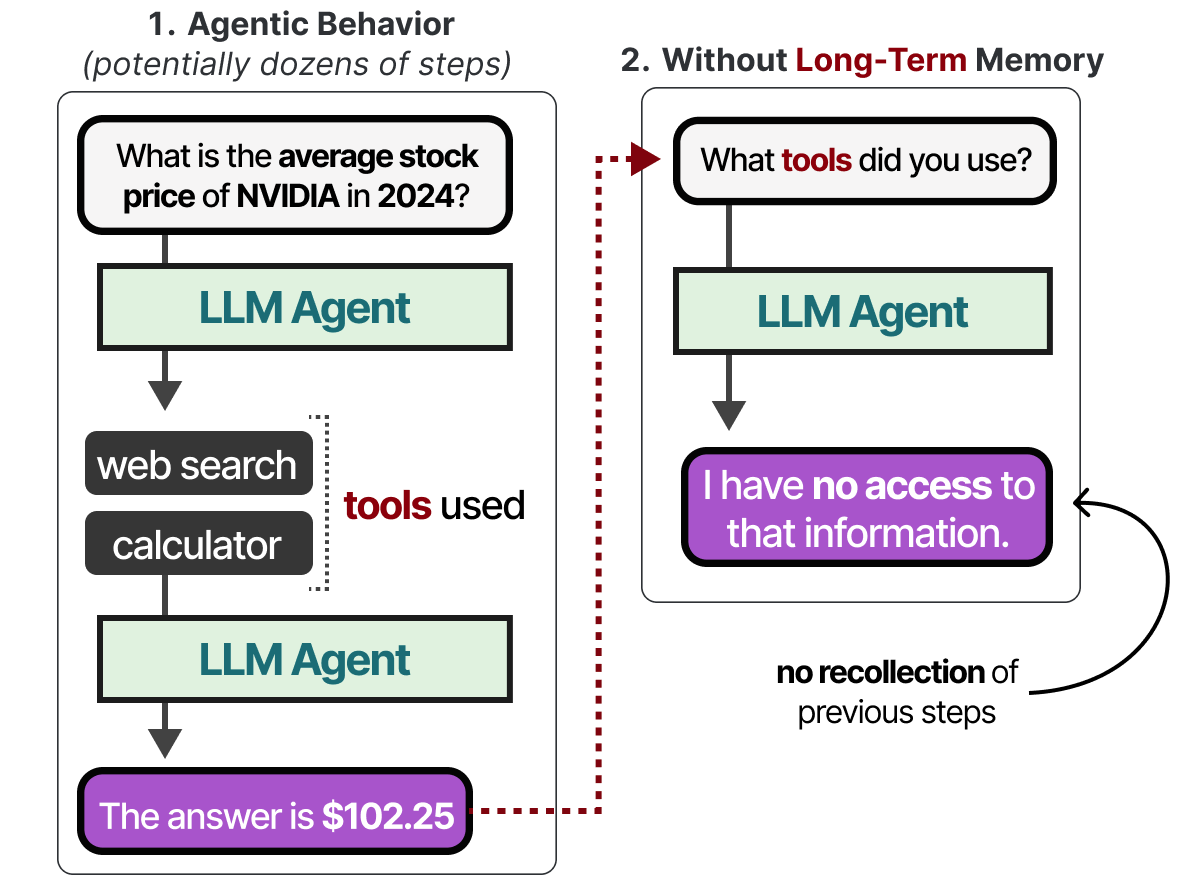
让我们探索为这些模型提供内存的几个技巧。
1.1 短期记忆 Short-Term Memory
1.1.1 模型的上下文窗口
启用短期记忆的最直接方法是使用**模型的上下文窗口**,这实际上是LLM可以处理的令牌数量。
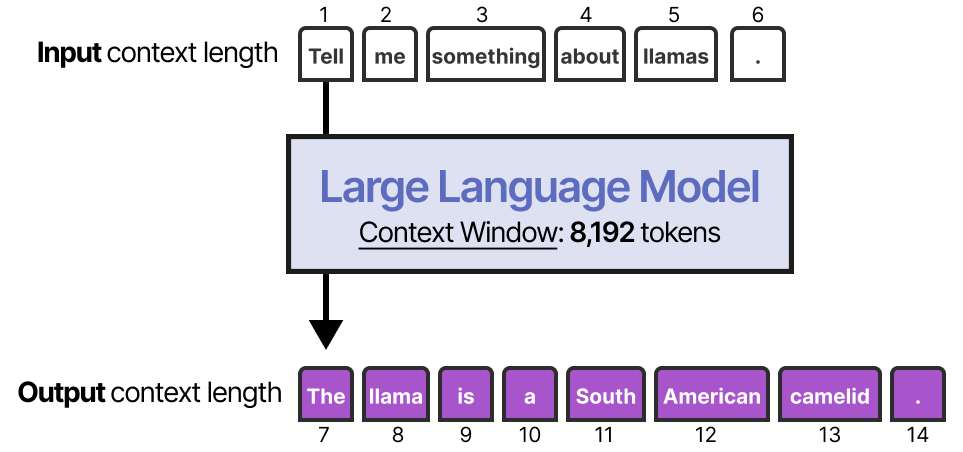
上下文窗口往往至少有8192(8k)个令牌,有时可以扩展到数十万个令牌!
1.1.2 对话历史
作为输入提示符的一部分,可以使用一个大的上下文窗口来跟踪完整的对话历史。
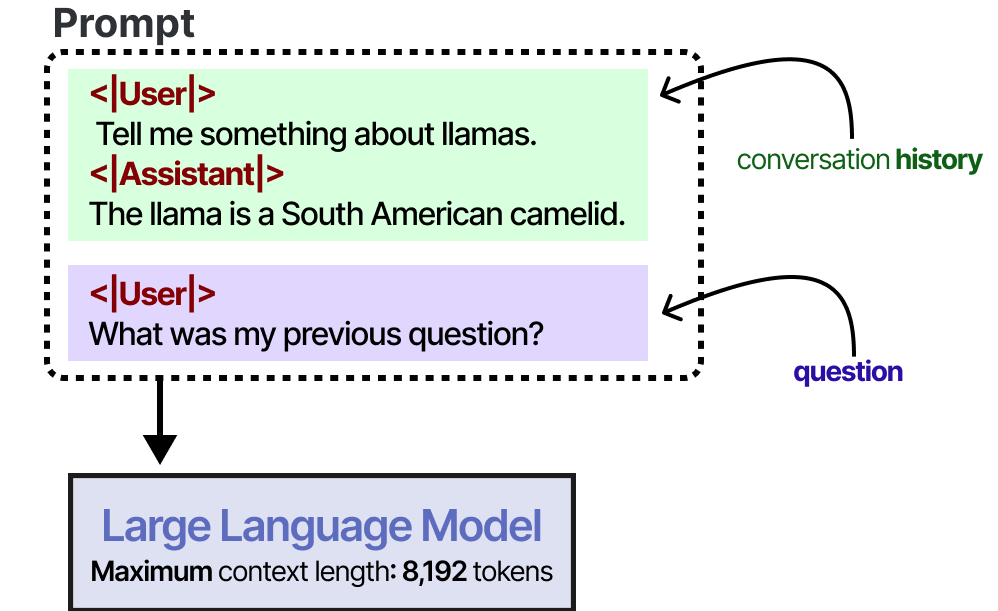
只要会话历史符合LLM的上下文窗口,这就可以工作,并且是模仿记忆的好方法。然而,我们实际上并没有记住一段对话,而是“告诉”LLM 这段对话是什么。
1.1.3 总结对话历史
对于具有较小上下文窗口的模型,或者当会话历史记录很大时,我们可以使用另一个LLM来总结到目前为止发生的会话。
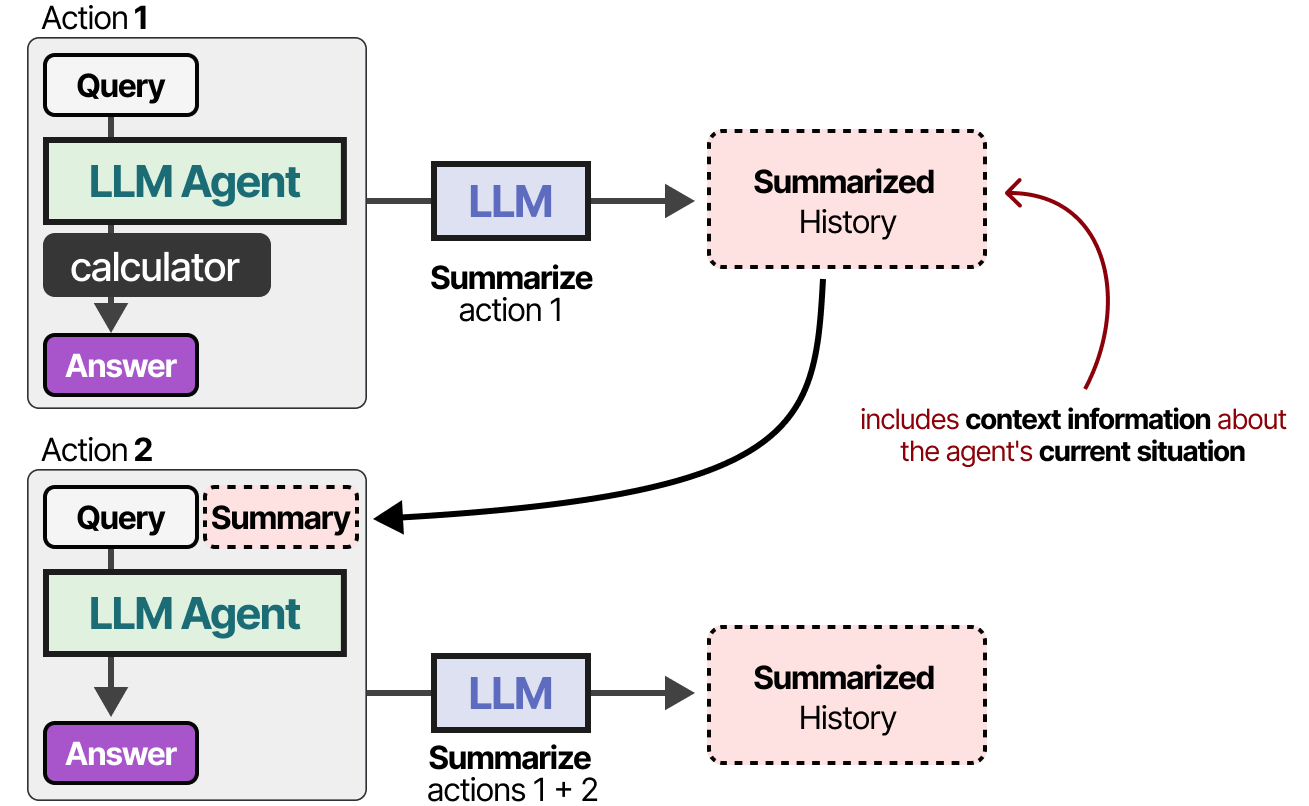
通过不断总结对话,我们可以保持对话的规模较小。它将减少令牌的数量,同时只跟踪最重要的信息。
1.2 长期记忆Long-term Memory
LLM代理中的长期记忆包括代理过去的操作空间,需要在一段较长的时间内保留。
实现长期记忆的一种常用技术是将所有以前的**交互、操作和对话存储在外部向量数据库中。
为了建立这样一个数据库,首先将对话嵌入**到捕捉其含义的数字表示中。
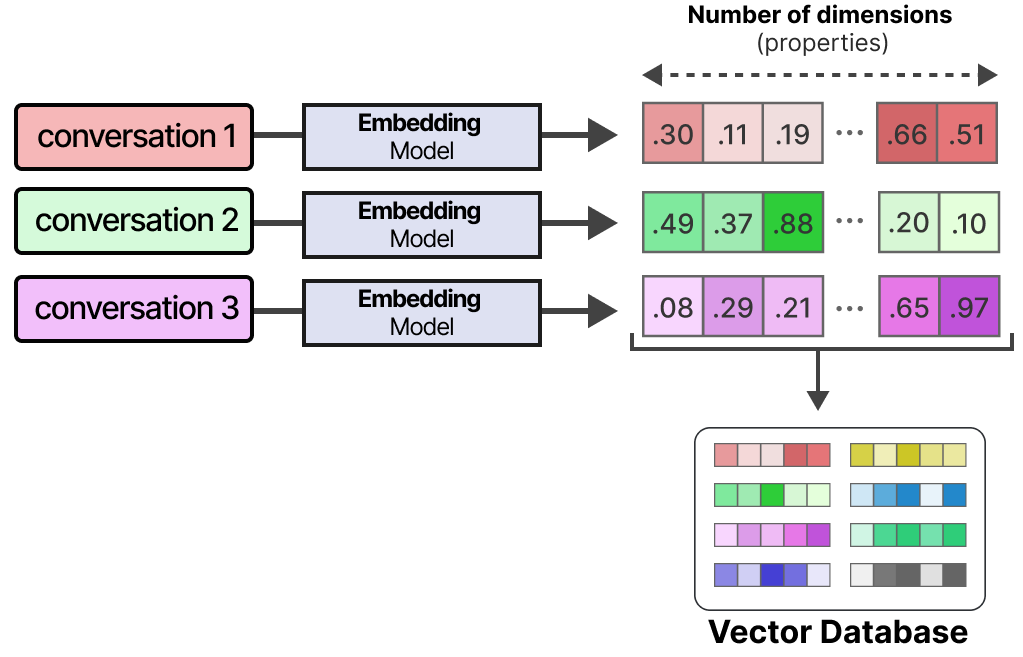
在建立数据库后,我们可以嵌入任何给定的提示符,并通过将提示符嵌入与数据库嵌入进行比较,在矢量数据库中找到最相关的信息。
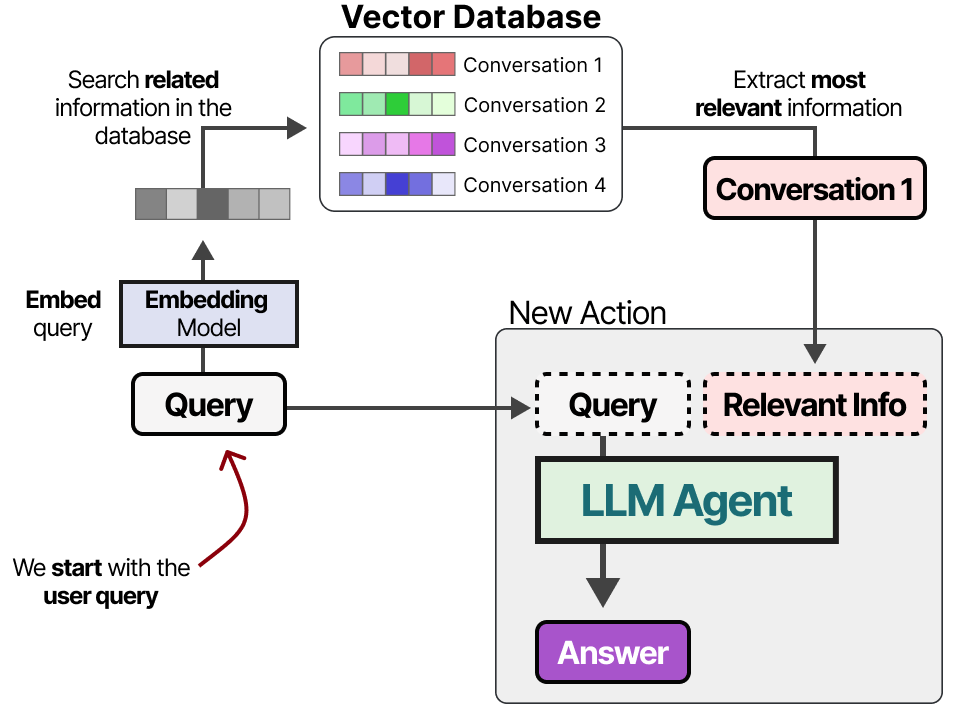
这种方法通常被称为检索增强生成(RAG)。
长期记忆还包括保留不同时段的信息。
例如,您可能希望LLM代理记住它在以前的会话中所做的任何研究。
不同类型的信息也可以与不同类型的记忆相关联。在心理学中,有许多类型的记忆需要区分,但是《Cognitive Architectures for Language Agents》语言代理的认知架构论文将其中的四种结合到LLM代理中。

这种区分有助于构建代理框架。语义记忆(关于世界的事实)可能存储在与工作记忆(当前和最近的情况)不同的数据库中。
2. 工具Tools
2.1 工具的类型
工具允许给定的LLM与外部环境(如数据库)交互或使用外部应用程序(如运行自定义代码)。

工具通常有两种用例:
- fetching data: 实时获取数据;
- taking action:执行命令,例如:执行代码、执行命令、setting a meeting。
2.2 function calling
要实际使用工具,LLM必须生成与给定工具的API 输入相匹配的文本。我们倾向于期望字符串可以格式化为JSON,以便它可以很容易地提供给代码解释器。

您还可以生成LLM可以使用的自定义函数,例如:基本的乘法函数。
这通常被称为函数调用function calling。
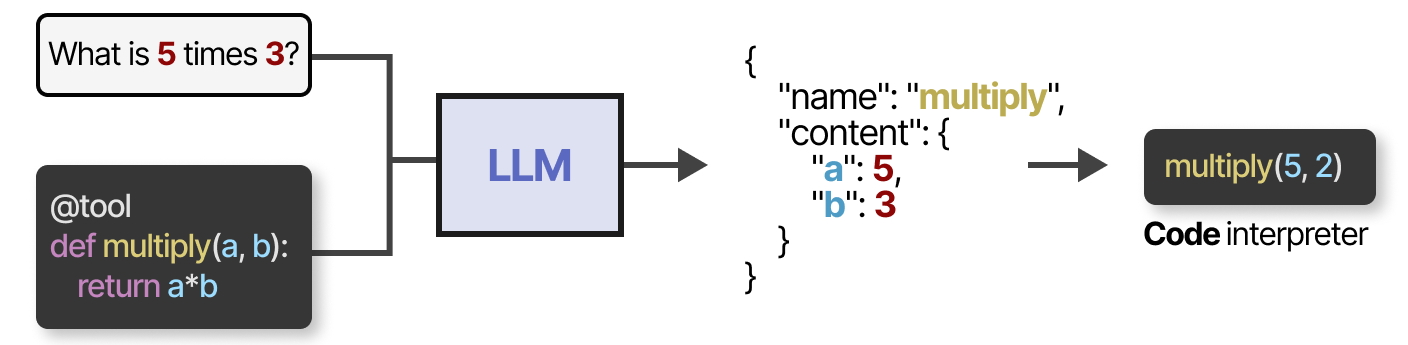
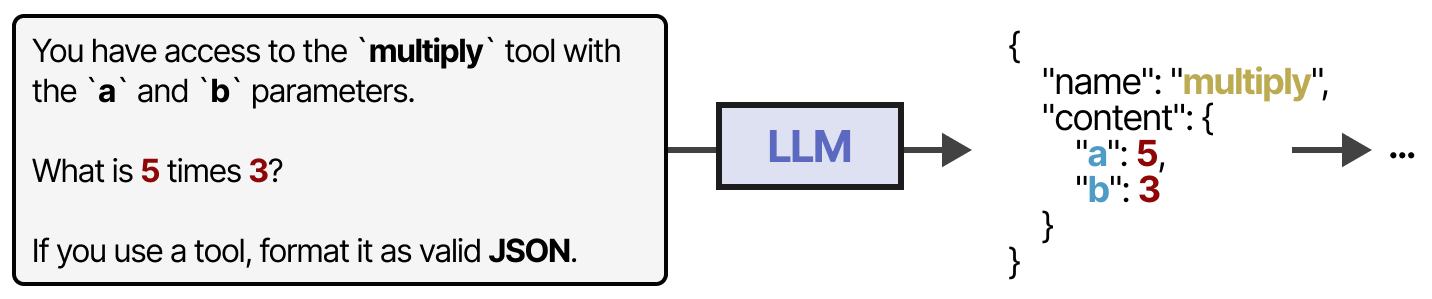
如果得到正确和广泛的提示,一些 LLM 可以使用任何工具。
工具的使用是目前大多数 LLM 都能做到的。
访问工具的一种更稳定的方法是对LLM进行微调(稍后会详细介绍!)
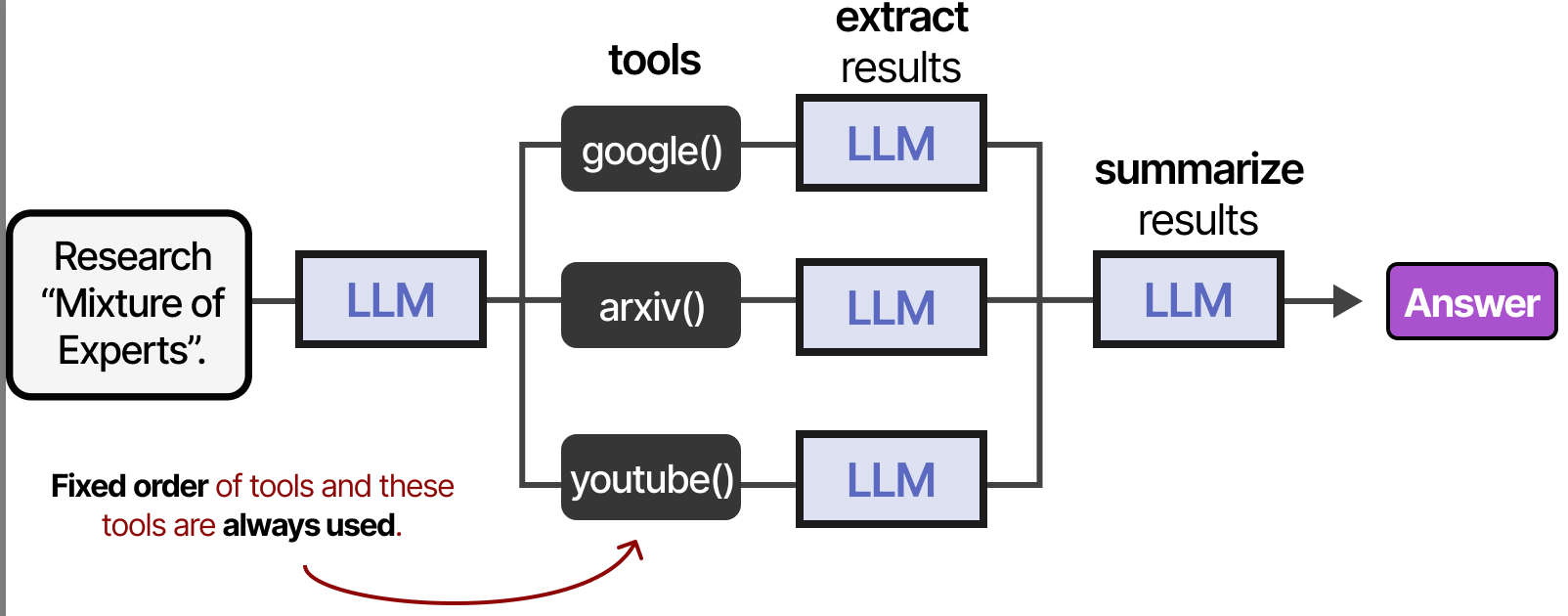
如果代理框架是固定的,工具可以按照给定的顺序使用……
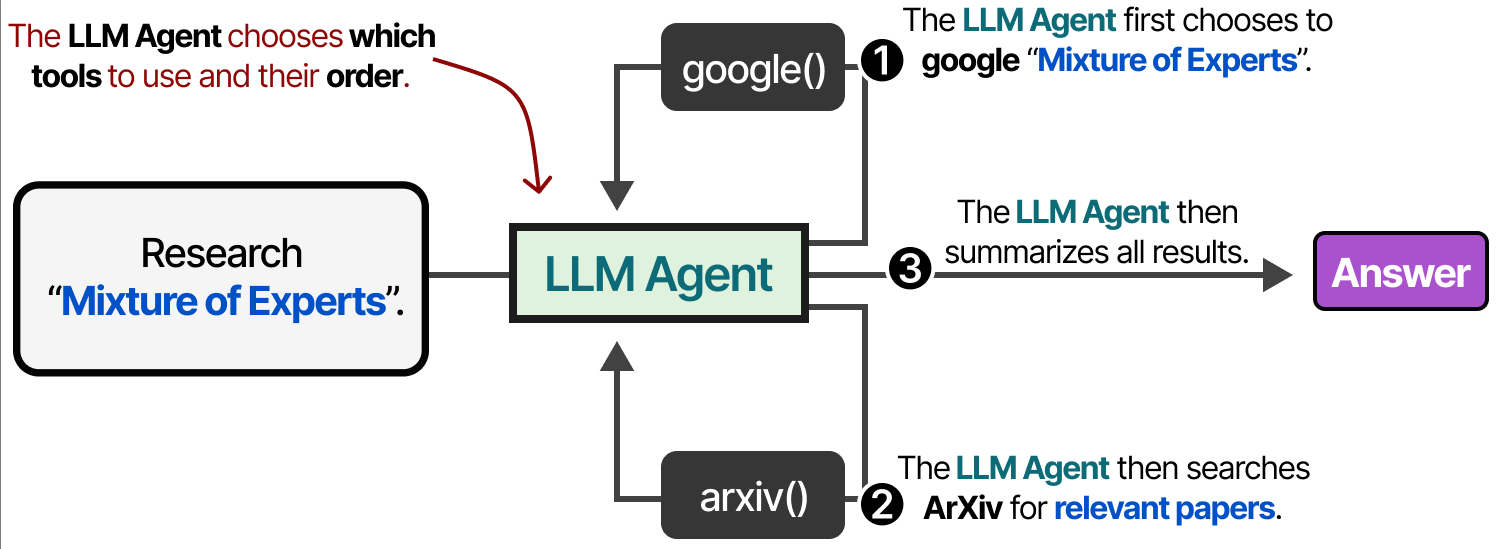
或者LLM可以自主选择使用哪种工具以及何时使用。
与上图一样,LLM代理本质上是LLM调用的序列(但具有自主选择动作/工具等)。
2.3 Toolformer
工具的使用是增强 LLM 能力和弥补其缺点的有力技术。
因此,在过去几年中,对工具使用和学习的研究工作出现了快速增长。
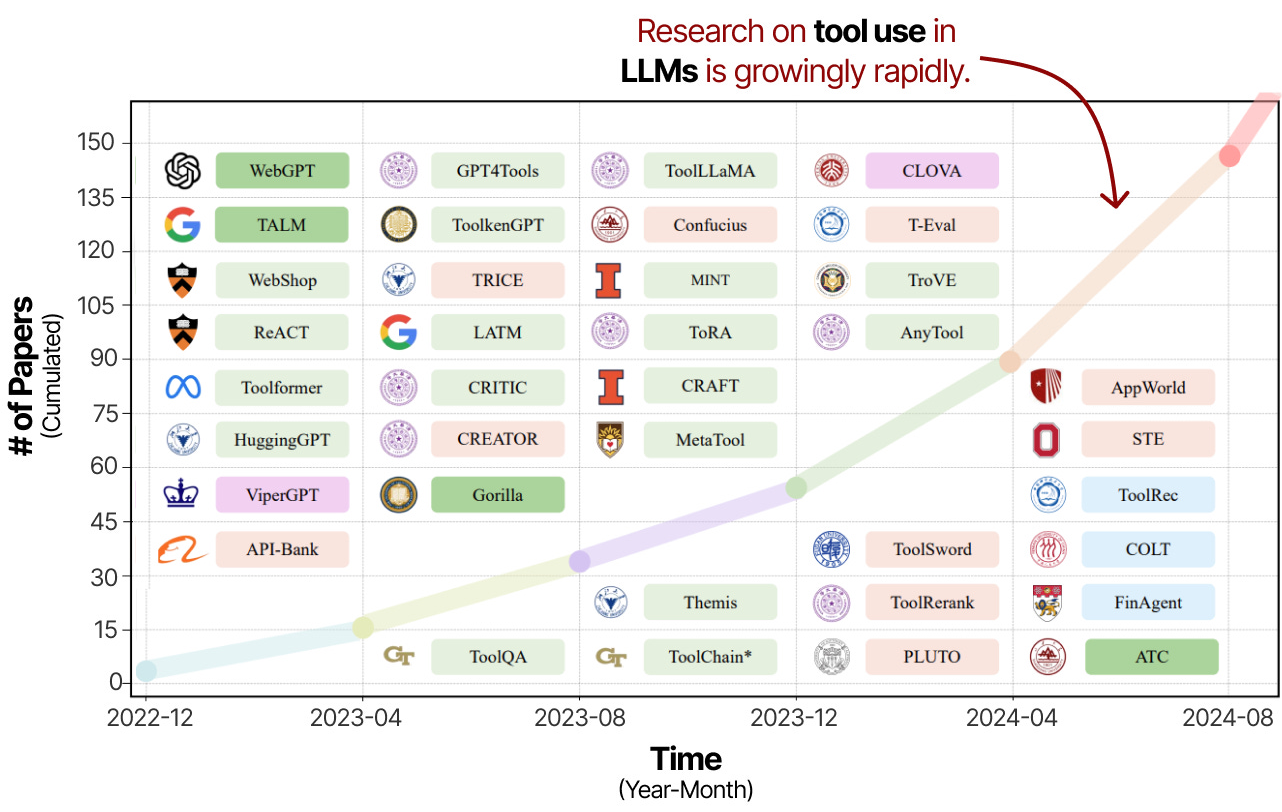
这项研究的大部分内容不仅涉及鼓励 LLM 使用工具,还涉及专门训练他们如何使用工具。
2.3.1 大模型调研工具的过程
最早做到这一点的技术之一是Toolformer,这是一种经过训练的模型,可以决定调用哪些api以及如何调用。
它通过使用 [ 和 ] 标记来指示调用工具的开始和结束来实现这一点。
当给出提示时,例如“5乘以3等于多少?”,它开始生成令牌,直到输出 [ 令牌。

之后,它生成令牌,直到到达“→”token,这表明LLM停止生成令牌。

然后,将调用该工具,并将输出添加到目前生成的令牌中。
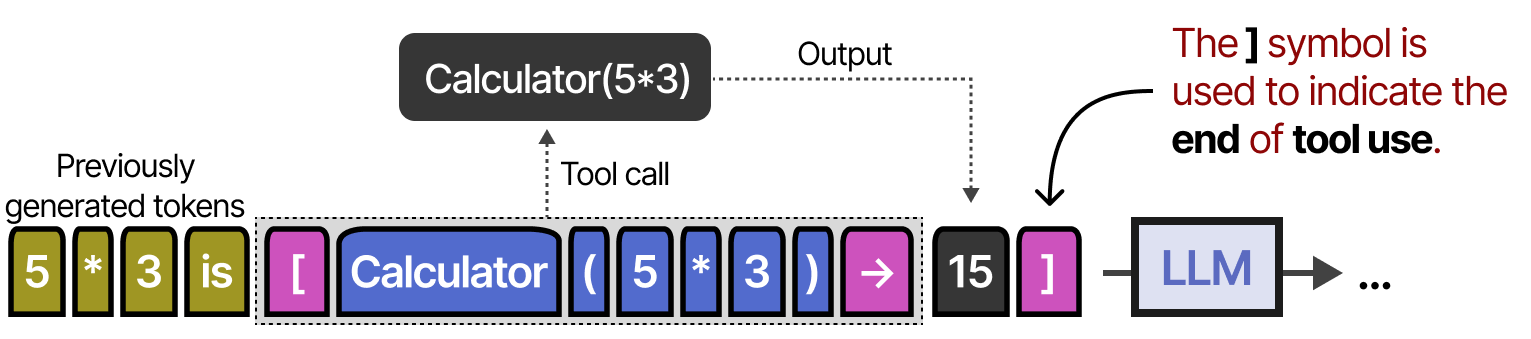
输出 ] 符号表示LLM现在可以在必要时继续生成。
2.3.2 生成工具调用数据集
Toolformer通过仔细生成一个数据集来创建这种行为,该数据集包含许多模型可以训练的工具。对于每个工具,将手动创建几个提示符,并用于对使用这些工具的输出进行采样。
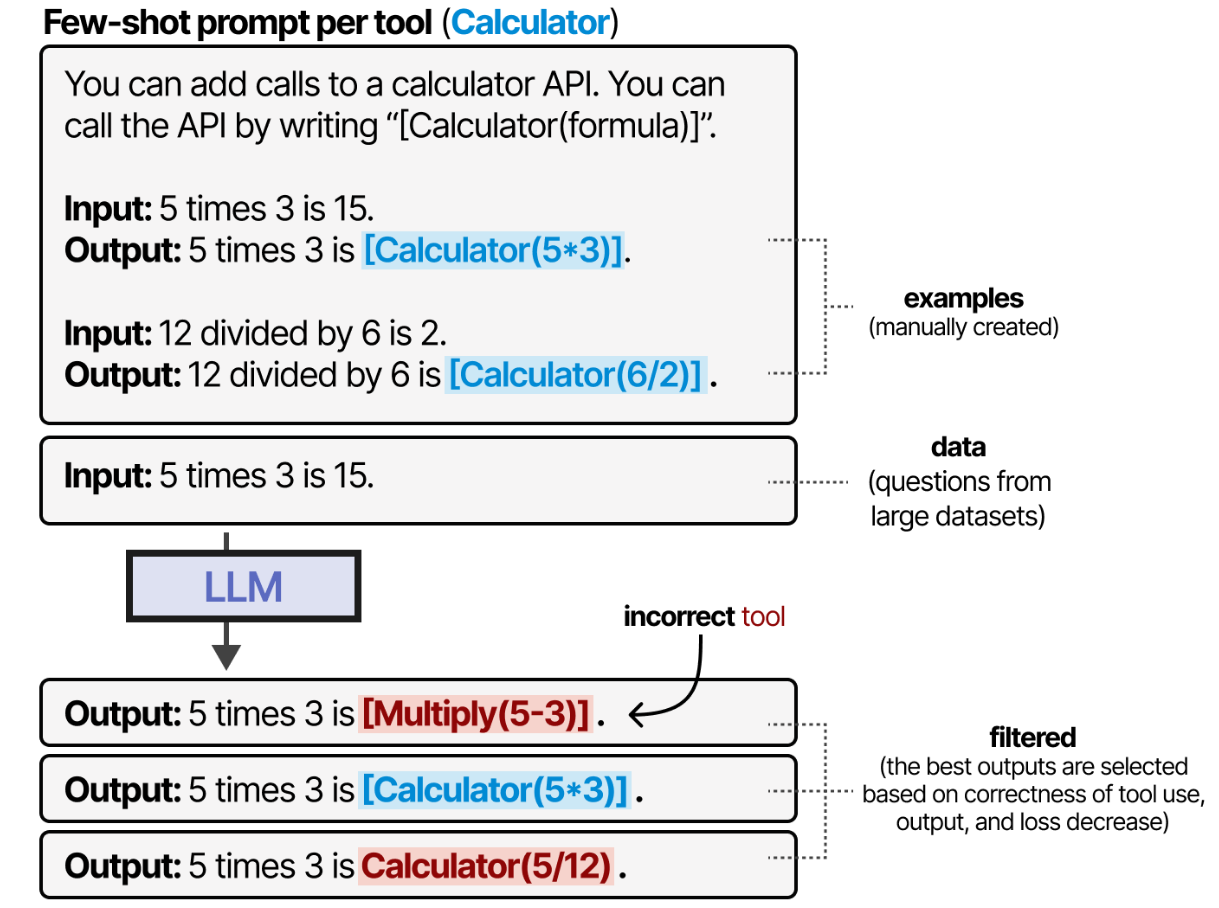
根据工具使用的正确性、输出和减少损耗对输出进行过滤。
生成的数据集用于训练LLM遵守这种工具使用格式。
自Toolformer发布以来,出现了许多令人兴奋的技术,例如可以使用数千种工具的llm (ToolLLM4)或可以轻松检索最相关工具的llm (Gorilla5)。
无论哪种方式,大多数当前的 LLM(2025年开始)已经被训练成通过JSON生成轻松调用工具(正如我们之前看到的)。
2.4 模型上下文协议 Model Context Protocol (MCP)
2.4.1 为什么需要 MCP?
工具是代理框架的重要组成部分,允许 LLM 与世界互动并扩展其功能。但是,当您有许多不同的API时启用工具使用会变得麻烦,因为任何工具都需要:
- 手动跟踪并反馈给LLM;
- 手动描述(包括预期的JSON模式);
- 每当其API 变化时手动更新;
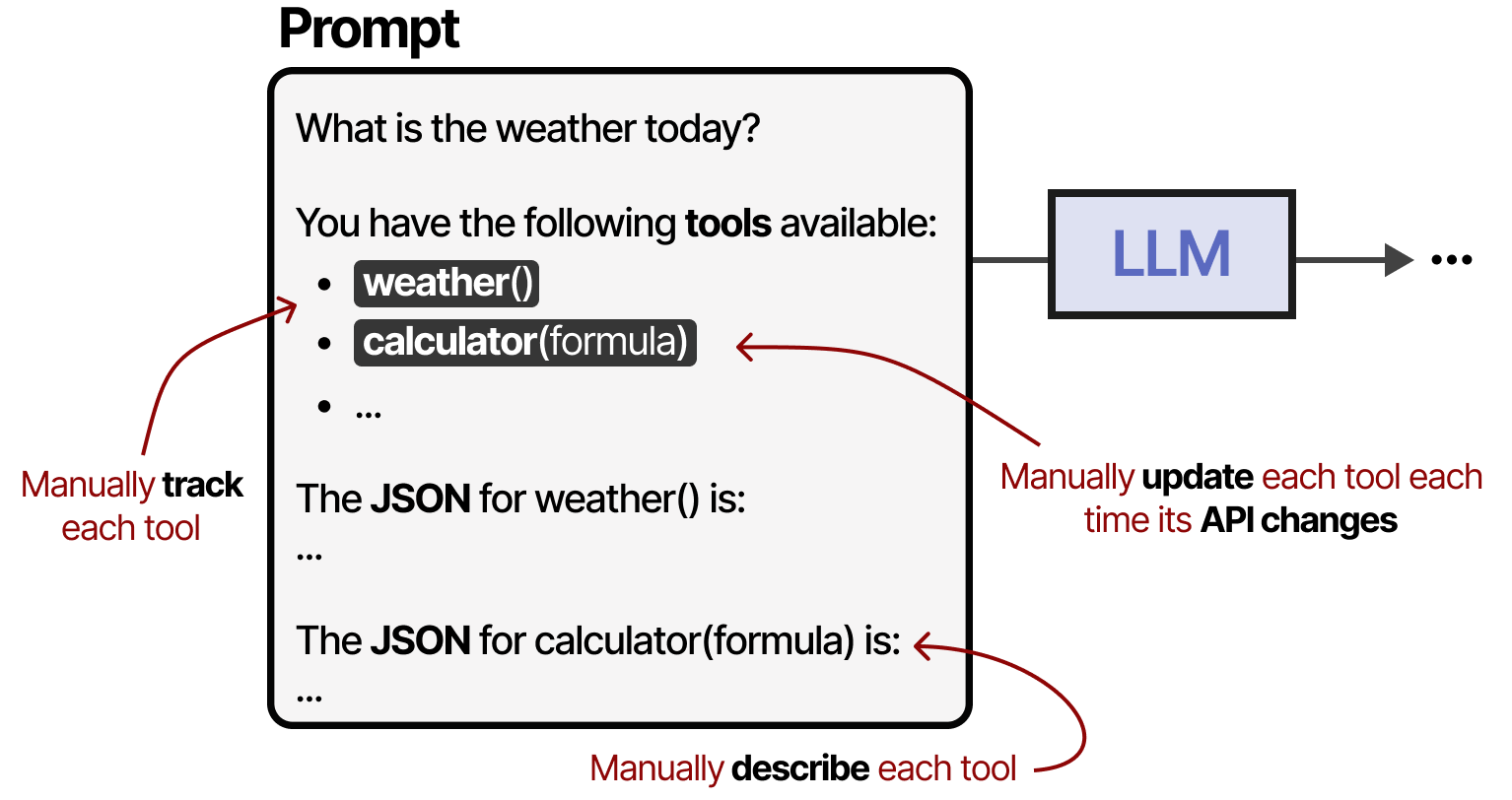
为了使工具更容易实现任何给定的代理框架,Anthropic开发了模型上下文协议(MCP);
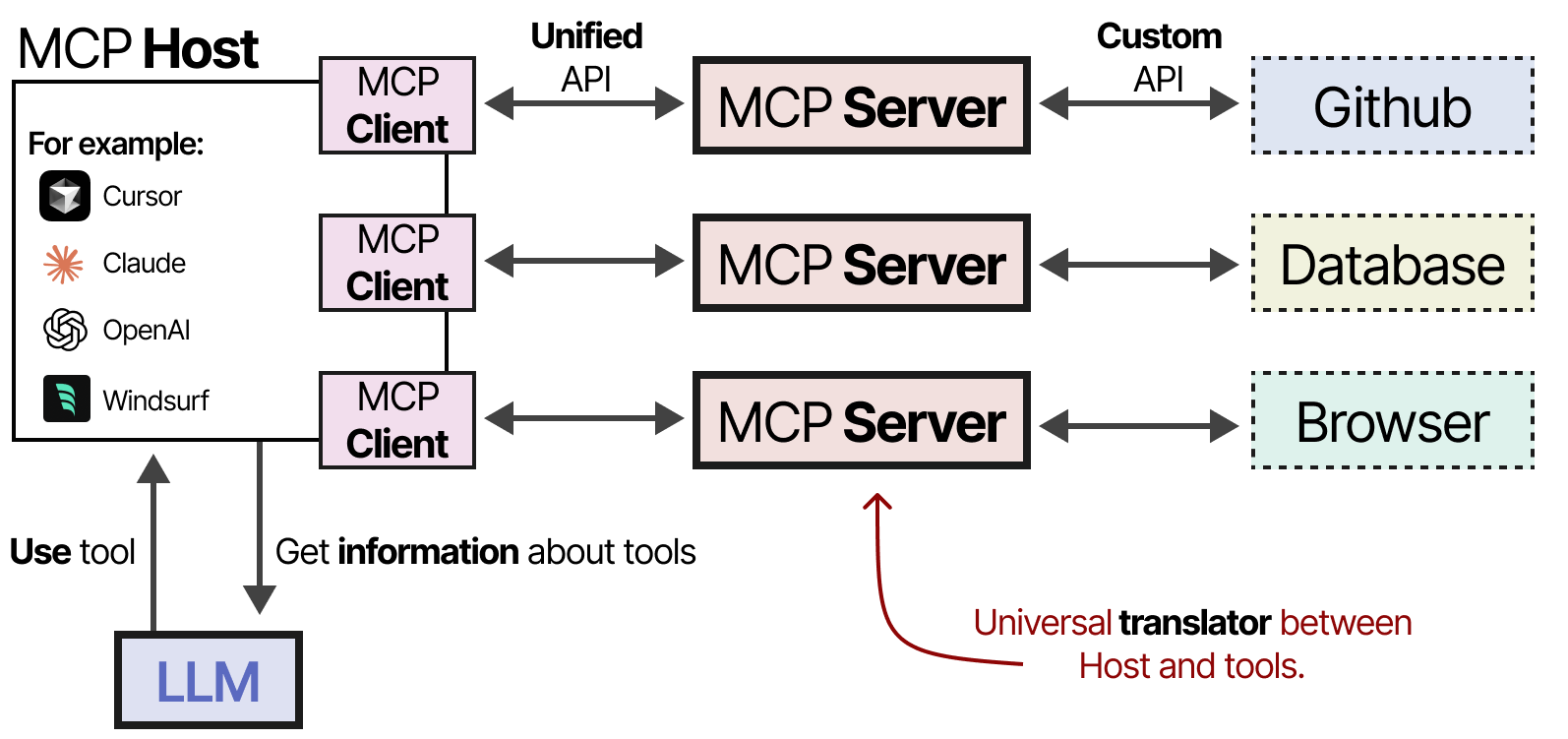
2.4.2 MCP 组成
MCP标准化了天气应用和GitHub等服务的API访问。
它由三个部分组成:
- MCP Host — 管理连接的LLM应用程序(如Cursor)
- MCP Client — 与MCP服务器保持1:1的连接
- MCP Server — 为llm提供上下文、工具等功能;
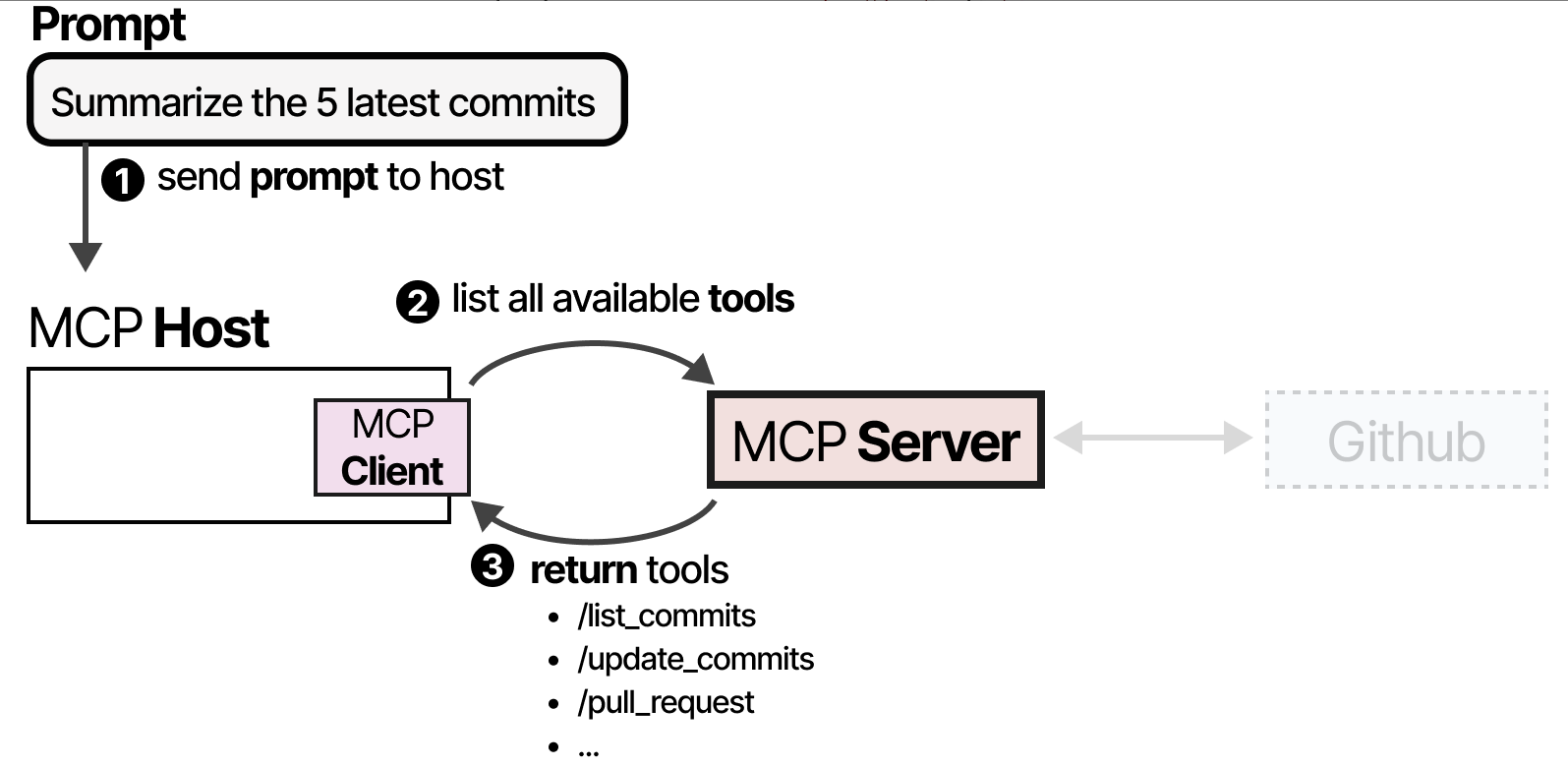
2.4.3 MCP 工作流程
例如,假设您希望LLM应用程序总结你的 github 仓库中的5个最新提交 commit。
MCP主机(连同客户端)将首先调用MCP服务器询问哪些工具可用。
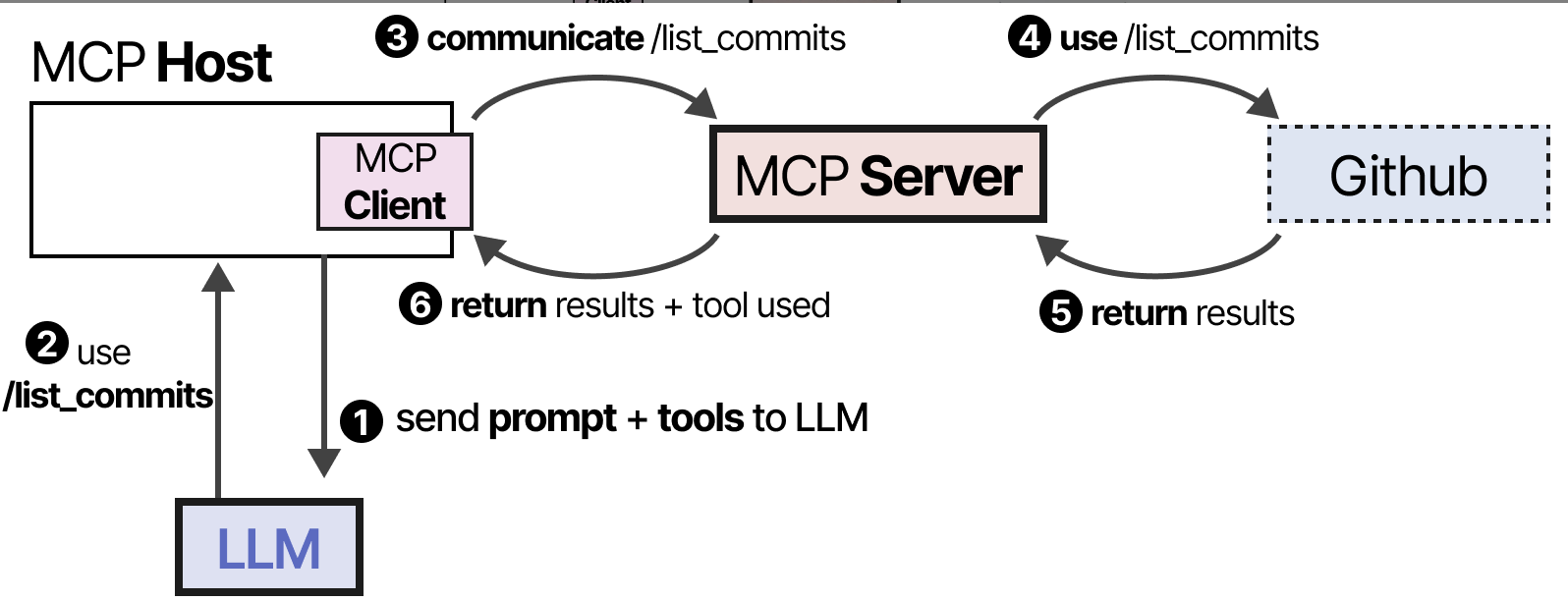
LLM接收信息,并可以选择使用工具。它通过主机向MCP服务器发送请求,然后接收结果,包括使用的工具。
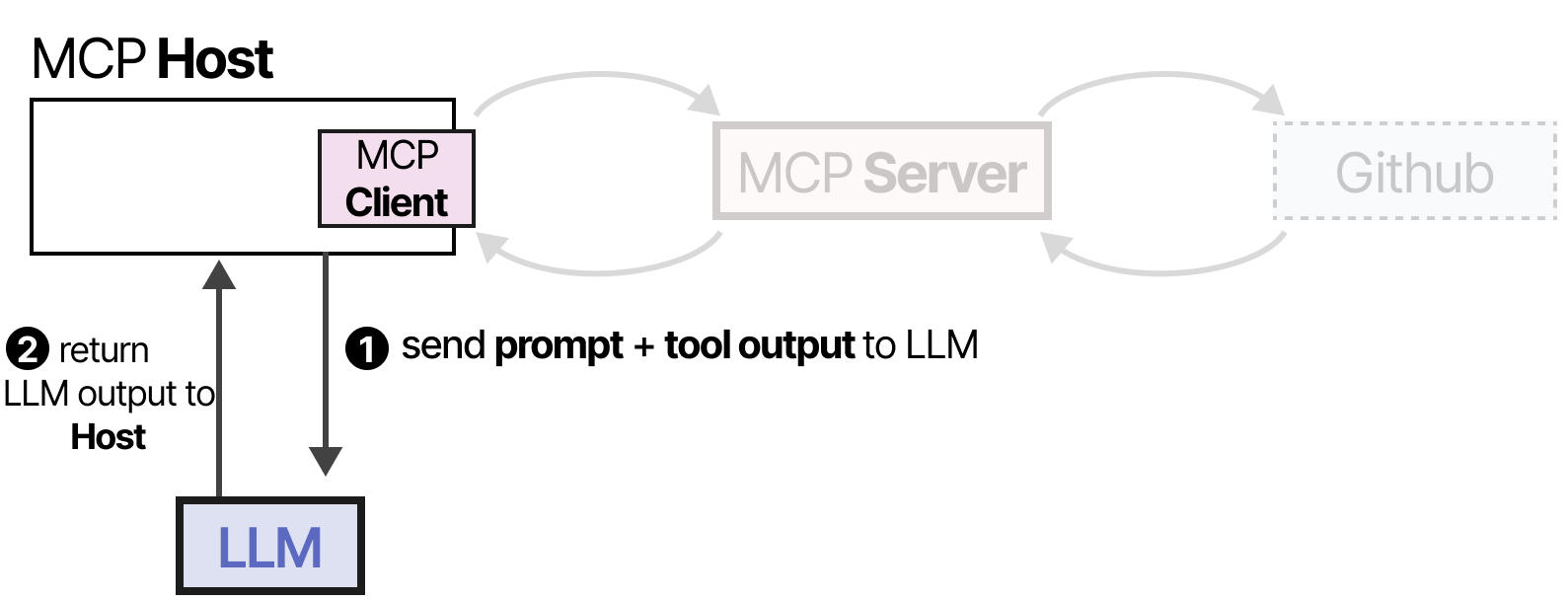
最后,LLM接收结果并解析答案给用户。
该框架通过连接到任何LLM应用程序都可以使用的MCP服务器,使创建工具变得更加容易。
因此,当您创建MCP服务器与Github交互时,任何支持MCP的LLM应用程序都可以使用它。
如果有用,请点个三连呗 点赞、关注、收藏。
你的鼓励是我创作最大的动力