【第四十六周】文献阅读:从 RAG 到记忆:大型语言模型的非参数持续学习
目录
- 摘要
- Abstract
- 从 RAG 到记忆:大型语言模型的非参数持续学习
- 研究背景
- 方法论
- 1. 离线索引(Offline Indexing)
- 2. 在线检索(Online Retrieval)
- 具体细节
- 创新性
- 实验结果
- 局限性
- 总结
摘要
本论文旨在解决当前检索增强生成(RAG)系统在模拟人类长期记忆动态性和关联性方面的不足。论文的核心贡献是HippoRAG 2框架,它在HippoRAG的基础上进行了多项改进,包括更深的段落整合、更有效的在线LLM使用以及基于神经生物学启发的记忆机制设计。HippoRAG 2通过结合密集-稀疏编码、上下文感知检索和识别记忆,显著提升了在事实记忆、意义构建和关联记忆任务上的性能。实验结果表明,HippoRAG 2在关联记忆任务上比当前最先进的嵌入模型提高了7%,同时在事实记忆和意义构建任务上也表现优异。HippoRAG 2的工作流程分为离线索引和在线检索两个阶段。离线阶段,LLM从段落中提取三元组构建开放知识图谱(KG),并通过编码器检测同义词以增强知识关联。在线阶段,查询通过嵌入模型与KG中的三元组和段落匹配,识别种子节点后,利用个性化PageRank(PPR)算法进行上下文感知检索,最终通过LLM生成答案。这一流程不仅模拟了人类记忆的神经生物学机制,还通过密集-稀疏编码和识别记忆等技术优化了检索效果。
Abstract
This paper aims to address the shortcomings of current Retrieval-Augmented Generation (RAG) systems in simulating the dynamics and associations of human long-term memory. The core contribution is the HippoRAG 2 framework, which improves upon the original HippoRAG system with several key upgrades: deeper paragraph integration, more efficient use of large language models (LLMs) online, and a memory mechanism inspired by neurobiology.HippoRAG 2 significantly improves performance on tasks involving factual memory, meaning construction, and associative memory by combining dense-sparse encoding, context-aware retrieval, and recognition memory.Experimental results show that HippoRAG 2 outperforms state-of-the-art embedding models by 7% on associative memory tasks, and also performs very well on factual memory and meaning construction tasks.The HippoRAG 2 workflow consists of two stages: offline indexing and online retrieval.In the offline stage, an LLM extracts triples from paragraphs to build an open knowledge graph (KG), while an encoder detects synonyms to enhance knowledge connections.In the online stage, queries are matched with triples and paragraphs in the KG using an embedding model. After identifying seed nodes, a context-aware search is performed using the Personalized PageRank (PPR) algorithm. Finally, the LLM generates the answer.This process not only mimics the neurobiological mechanisms of human memory but also optimizes retrieval performance through techniques like dense-sparse encoding and recognition memory.
从 RAG 到记忆:大型语言模型的非参数持续学习
Title: From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Author: Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, Yu Su
Source: Arxiv
Arxiv: https://arxiv.org/abs/2502.14802
研究背景
在人工智能领域,赋予大语言模型(LLMs)持续学习能力是一个重要挑战。人类能够不断吸收、整合和利用新知识,而现有的LLMs在持续学习方面存在两大问题:一是难以完全吸收新知识,二是容易发生灾难性遗忘。RAG作为一种非参数持续学习方案,通过检索外部信息避免了直接修改模型参数,但其依赖的向量检索无法模拟人类记忆的动态关联性。具体来说,标准RAG在意义构建(理解复杂上下文)和关联性(多跳推理)任务上表现不佳。
近年来,一些结构增强的RAG方法试图通过知识图谱或摘要生成来弥补这些缺陷,但这些方法在简单事实记忆任务上的性能往往下降明显。例如,HippoRAG虽然通过个性化PageRank算法提升了多跳推理能力,但在大规模语篇理解任务中表现不佳。这种性能的不均衡促使研究者提出HippoRAG 2,旨在实现更全面的记忆能力提升。
方法论
虽然HippoRAG试图从非参数RAG构建记忆,但其有效性受到一个关键缺陷的阻碍:以实体为中心的方法,该方法在索引和推理过程中导致上下文丢失,以及语义匹配困难。
如何理解上述问题呢?
- 索引阶段:上下文丢失
(1)仅提取实体和关系,忽略全局语境:HippoRAG 在构建知识图谱(KG)时,主要依赖 命名实体识别(NER) 和 开放信息抽取(OpenIE) 从文本中提取 (实体, 关系, 实体) 形式的三元组。
示例:句子 “Einstein developed the theory of relativity while working at the Swiss Patent Office.” 提取的三元组可能是 (“Einstein”, “developed”, “theory of relativity”) 和 (“Einstein”, “worked at”, “Swiss Patent Office”)。
丢失的上下文:时间背景(“while”)、因果关系(“developed while working”)等非实体信息被忽略。
(2)同义词链接缺乏上下文感知:HippoRAG 通过向量相似度连接同义实体(如 “Einstein” 和 “Albert Einstein”),但 同一实体在不同上下文中的含义可能不同。
问题案例: 句子A:“Einstein criticized quantum mechanics.” 句子B:“Einstein’s
theories revolutionized physics.” HippoRAG 会将两处的 “Einstein”
视为同一节点,但实际语义角色不同(批评者 vs. 贡献者)。 结果:KG 仅保留实体间的直接关系,而丢失了原文的叙事逻辑和隐含信息。
- 推理阶段:语义匹配困难
(1)查询解析依赖实体,忽略查询意图:HippoRAG 在检索时,首先用 NER 从查询中提取实体,再匹配 KG 中的对应节点。
示例查询:“How did Einstein’s work at the patent office influence his theories?” HippoRAG 可能只匹配 “Einstein” 和 “patent office” 节点,但 忽略关键关系(“influence”)。 对比:HippoRAG 2 直接匹配查询与三元组(如 (“Einstein”, “influenced by”, “patent office”)),更贴合意图。
(2)多跳推理的语义漂移:虽然 HippoRAG 的个性化 PageRank(PPR)支持多跳推理,但 实体中心的检索可能偏离原始查询语义。
问题案例: 查询:“What instrument did the composer of ‘Für Elise’ play?”
HippoRAG 可能从 “Für Elise” → “Beethoven” → “piano”,但若 KG 中 “Beethoven”
节点同时连接 “violin”(无关信息),PPR 可能错误激活后者。 根源:实体节点缺乏上下文约束,导致无关路径被激活。
HippoRAG 2的方法论设计深受神经生物学启发,模拟了人类大脑中概念与上下文的交互机制。其核心改进包括三个方面:密集-稀疏编码的整合、更深层次的上下文感知检索以及识别记忆的引入。
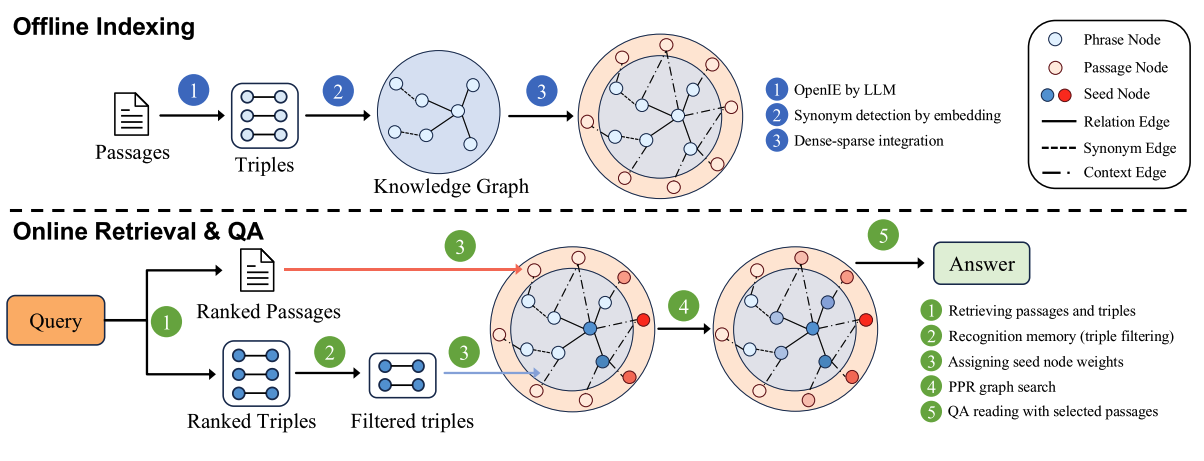
1. 离线索引(Offline Indexing)
这一阶段的目标是构建一个开放知识图谱(KG),使其能够存储和关联不同来源的知识。具体步骤如下:
(1)LLM 提取三元组
使用大语言模型(如 Llama-3.3-70B-Instruct)从文本段落(Passages)中提取 (主语,关系,宾语) 形式的三元组(Triples)。
示例:从句子 “Albert Einstein was born in Ulm, Germany.” 可以提取三元组:
(“Albert Einstein”, “born in”, “Ulm”)
(“Ulm”, “located in”, “Germany”)
这些三元组构成 KG 的关系边(Relation Edges),而主语和宾语称为短语节点(Phrase Nodes)。
(2)同义词检测(Synonym Detection)
使用嵌入模型(如 NV-Embed-v2)计算短语节点之间的语义相似度。
如果两个短语的相似度超过阈值(如 0.8),则添加同义词边(Synonym Edge)连接它们。
示例:(“Einstein”, “synonym”, “Albert Einstein”)
这使得 KG 能够关联不同表述但含义相同的概念,增强检索的鲁棒性。
(3)段落节点(Passage Nodes)与上下文边(Context Edges)
每个原始段落被表示为 KG 中的一个段落节点。
通过 “contains” 边(Context Edge)将段落节点与其包含的所有短语节点连接起来。
示例:段落 “Einstein was born in Ulm.” 会连接到 “Einstein” 和 “Ulm” 两个短语节点。
这样,KG 同时包含概念(短语节点)和上下文(段落节点),模拟人类记忆的密集-稀疏编码机制。
2. 在线检索(Online Retrieval)
这一阶段利用构建好的 KG 进行查询相关的检索,具体步骤如下:
(1)查询到三元组匹配(Query to Triple)
给定一个查询(Query),使用嵌入模型计算其与 KG 中所有三元组的相似度,选择最相关的若干三元组(如 Top-5)。
示例:查询 “Where was Einstein born?” 可能匹配到三元组 (“Einstein”, “born in”, “Ulm”)。
(2)识别记忆过滤(Recognition Memory)
使用 LLM 对候选三元组进行过滤,剔除无关项。
示例:如果查询是 “Einstein’s nationality”,但检索到 (“Einstein”, “worked at”, “Princeton”),LLM 会过滤掉该三元组。
这一步模拟人类记忆的“识别”过程,减少噪声。
(3)种子节点选择(Seed Node Selection)
从过滤后的三元组中提取短语节点(如 “Einstein” 和 “Ulm”)作为 PPR 算法的种子节点。
段落节点也会被纳入种子,但其权重较低(如 0.05),以平衡概念与上下文的影响。
(4)个性化 PageRank(PPR)检索
在 KG 上运行 PPR 算法,从种子节点出发进行随机游走,计算每个段落节点的权重(PageRank 分数)。
深色节点表示高概率(更相关),浅色节点表示低概率。
示例:“Einstein” → “Ulm” → 包含 “Ulm” 的段落会被赋予高分。
(5)最终检索结果
按 PageRank 分数排序,返回 Top-K 段落作为 RAG 的上下文输入。
示例:对于查询 “Einstein’s birthplace”,可能返回段落 “Einstein was born in Ulm, Germany.”
具体细节
在密集-稀疏编码整合中,HippoRAG 2将短语节点(稀疏编码)与段落节点(密集编码)结合,通过“包含”边连接段落及其衍生的短语。这种设计模拟了人类大脑中信息的不同粒度表示,既保留了概念的简洁性,又通过上下文丰富了语义。例如,一个关于“爱因斯坦”的段落会通过“包含”边连接到“相对论”等短语节点,从而在检索时同时激活概念和上下文。
在上下文感知检索中,HippoRAG 2摒弃了HippoRAG的实体中心主义,采用查询到三元组的匹配策略。具体来说,查询不再仅通过命名实体识别(NER)与KG节点匹配,而是直接与三元组匹配,利用三元组中的关系信息更全面地捕捉查询意图。例如,对于查询“爱因斯坦在哪里出生?”,传统方法可能仅匹配“爱因斯坦”这一实体,而HippoRAG 2会匹配“(爱因斯坦,出生于,乌尔姆)”这样的三元组,从而更精准地定位答案。
识别记忆的引入进一步优化了检索过程。在查询到三元组匹配后,HippoRAG 2使用LLM过滤无关三元组,模拟人类记忆中的识别过程。例如,对于查询“莫扎特的父亲是谁?”,系统可能检索到多个包含“莫扎特”的三元组,但通过识别记忆过滤后,仅保留“(莫扎特,父亲,利奥波德·莫扎特)”这一相关三元组。这一步骤显著减少了噪声,提升了检索效率。
在线检索阶段,HippoRAG 2通过PPR算法在KG上进行随机游走,结合短语节点和段落节点的重置概率,实现多跳推理。例如,回答“爱因斯坦的母校的创始人是谁?”需要从“爱因斯坦”节点跳转到“苏黎世联邦理工学院”节点,再跳转到“创始人”节点。HippoRAG 2通过动态调整节点权重,确保检索结果既覆盖多跳路径,又聚焦于相关段落。
创新性
HippoRAG 2的创新性主要体现在三个方面:一是首次将密集-稀疏编码理论应用于RAG系统,通过KG中短语节点和段落节点的结合,实现了概念与上下文的无缝整合;二是提出了查询到三元组的匹配策略,突破了传统实体中心检索的局限性;三是引入识别记忆机制,通过LLM在线过滤无关三元组,显著提升了检索精度。
与现有方法相比,HippoRAG 2的独特之处在于其全面的性能提升。例如,RAPTOR和GraphRAG虽然通过摘要生成增强了意义构建能力,但在简单QA任务上表现下降;HippoRAG在多跳推理上表现优异,但缺乏上下文感知。HippoRAG 2则通过平衡概念与上下文、结合PPR算法与识别记忆,实现了在事实记忆、意义构建和关联记忆任务上的全面领先。
实验结果
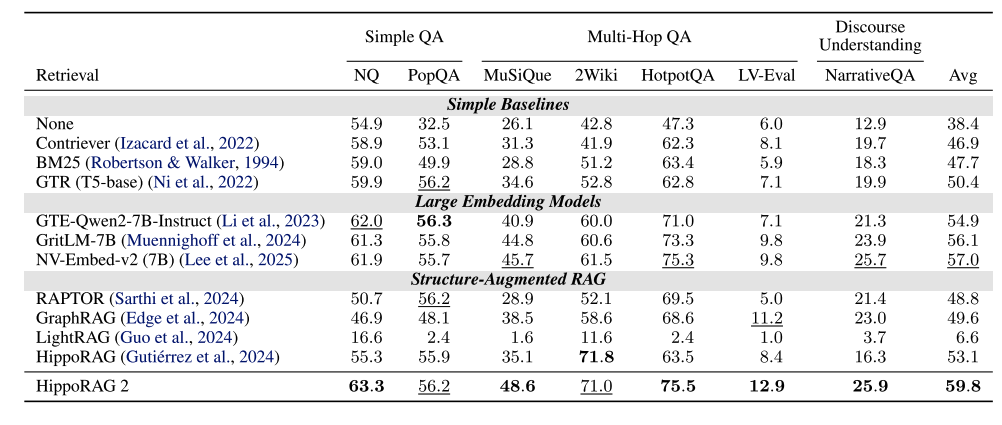
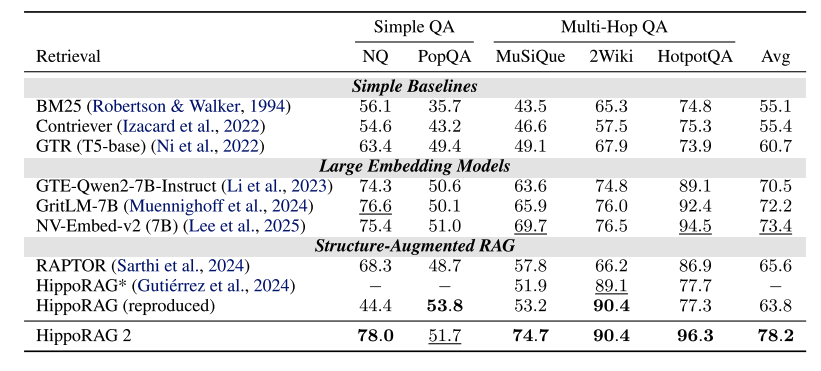
论文在多个基准数据集上验证了HippoRAG 2的性能,包括简单QA(NaturalQuestions、PopQA)、多跳QA(MuSiQue、2Wiki、HotpotQA、LV-Eval)和语篇理解(NarrativeQA)。实验结果表明,HippoRAG 2在几乎所有任务上均优于基线方法。
在简单QA任务中,HippoRAG 2的F1分数比最强的密集检索模型NV-Embed-v2提高了1.4%(63.3 vs. 61.9)。在多跳QA任务中,其优势更为显著,例如在MuSiQue上,HippoRAG 2的召回率@5达到74.7%,比NV-Embed-v2提高了5%。在最具挑战性的LV-Eval数据集上,HippoRAG 2的F1分数为12.9%,远超其他方法(NV-Embed-v2为9.8%)。此外,HippoRAG 2在语篇理解任务(NarrativeQA)上也表现最佳,F1分数为25.9%,比NV-Embed-v2提高了0.2%。
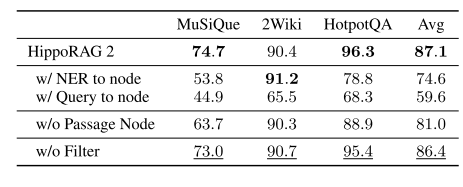
消融实验进一步验证了各组件的重要性。例如,移除段落节点后,HippoRAG 2在MuSiQue上的召回率@5下降了10.4%(从74.7%降至63.7%);禁用识别记忆过滤后,性能下降1.1%。此外,HippoRAG 2展示了良好的灵活性,能够兼容不同的密集检索模型(如GTE-Qwen2-7B、GritLM-7B等),且在不同检索器上均表现优于直接密集检索。
局限性
尽管HippoRAG 2表现优异,但仍存在一些局限性。首先,其离线索引阶段依赖LLM提取三元组,计算成本较高。例如,使用Llama-3.3-70B-Instruct处理MuSiQue语料库(11,656个段落)需要约3.5小时。其次,识别记忆的过滤精度仍有提升空间,在部分复杂查询中可能误删相关三元组。例如,在LV-Eval数据集的错误分析中,26%的样本因过滤后丢失关键短语而导致检索失败。此外,HippoRAG 2对多跳推理的依赖可能在某些简单任务中引入不必要的复杂性,例如直接向量检索即可解决的问题。
总结
HippoRAG 2通过神经生物学启发的设计,将RAG系统的记忆能力推向了一个新高度。其核心贡献在于平衡了概念与上下文、检索精度与覆盖范围,从而实现了在事实记忆、意义构建和关联记忆任务上的全面领先。这一工作不仅为LLMs的非参数持续学习提供了新思路,也为未来研究指明了方向——例如,如何进一步降低计算成本,或结合图检索增强对话系统中的情景记忆能力。从更广阔的视角看,HippoRAG 2的成功体现了跨学科研究的力量。通过借鉴神经科学中的密集-稀疏编码理论和记忆机制,AI研究者能够设计出更接近人类智能的系统。未来,随着LLMs和检索技术的进一步发展,HippoRAG 2的框架有望在更多复杂场景中展现其潜力,例如法律文档分析、科学文献综述等需要长期记忆和复杂推理的领域。