赋能电力FTU,飞凌嵌入式RK3506核心板AMP双系统技术应用解析
随着配电网功能的不断扩展和升级,传统的单片机方案已经无法满足FTU(馈线终端单元)对高性能、多任务处理的需求。多核异构处理器通过集成不同架构的处理核心,能够同时处理如模拟量采集、保护逻辑运算等实时性要求高的任务,以及如多通信接口管理、加密解密等非实时性交互任务,从而显著提升FTU的整体性能和处理能力。
1、FET3506J-S核心板在FTU中的适配性
飞凌嵌入式基于瑞芯微RK3506J处理器设计开发的FET3506J-S核心板,采用3*Cortex-A7+1*Cortex-M0的多核异构架构;满载运行实测功耗仅0.7W,满载运行且无需任何散热处理即可应对+85℃的高温环境;并且有着强大的软件兼容性和灵活的系统架构,支持Linux 6.1、AMP架构以及Linux RT等多种软件生态。
以上特性使这款FET3506J-S核心板成为了电力FTU理想的主控选型方案,接下来我们展开说说。
01、实时方案: AP 或 MCU
飞凌嵌入式FET3506J-S核心板支持两种实时方案,即AP+MCU模式和AP+AP模式,两种模式各有相应的特点,适用于不同的应用领域。
① AP+MCU系统架构
在瑞芯微的多核异构系统中,AP+MCU系统架构为Linux+MCU RTOS/Bare-metal。运行LinuxAP处理器核心作为主核(Master Core)。运行RTOS/Bare-metal的MCU处理器核心作为从核(Remote Core)。主核负责整个多核异构系统中共享资源的划分和管理,并运行主站服务程序。
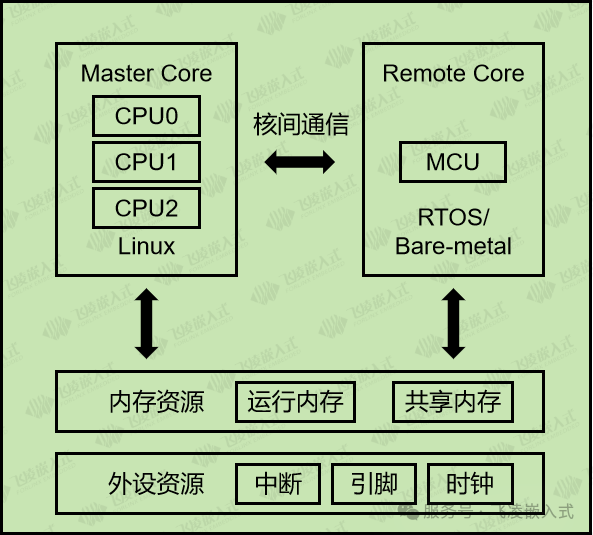
但RK3506J实时核(Cortex-M0)的主频只有200MHz,且无法访问硬件浮点单元(FPU),在应对复杂实时计算时,计算性能存在显著瓶颈。适用于一些简单控制的应用领域。FTU类似的保护测控类产品一般使用AP+AP实时方案。在此背景下,AMP(Asymmetric Multi-Processing)架构已成为主流解决方案。
② AP+AP系统架构
在瑞芯微多核异构系统中,AP+AP系统架构为Linux+RTOS/Bare-metal两种。在Linux+RTOS/Bare-metal系统架构中,运行Linux的处理器核心作为主核(MasterCore)。运行RTOS/Bare-metal 的处理器核心作为从核(Remote Core)。主核负责整个多核异构系统中共享资源的划分和管理,并运行主站服务程序。
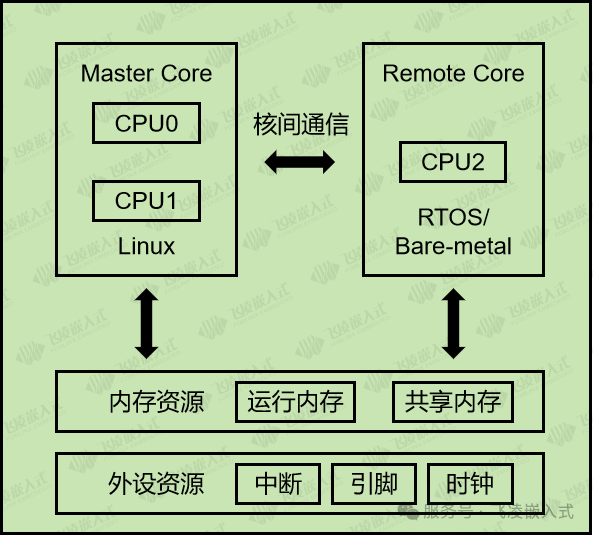
在该方案中,系统将CPU2核心配置为实时核。CPU0和CPU1依旧运行Linux系统,凭借Cortex-A7的1.5GHz高主频,能调用硬浮点单元加速等特性,在处理诸如高精度采样、实时计算、故障检测等对实时性要求严苛的任务时,能大幅降低任务响应延迟,提升系统整体的实时处理效能 ,确保系统对关键事件的快速响应与稳定运行。
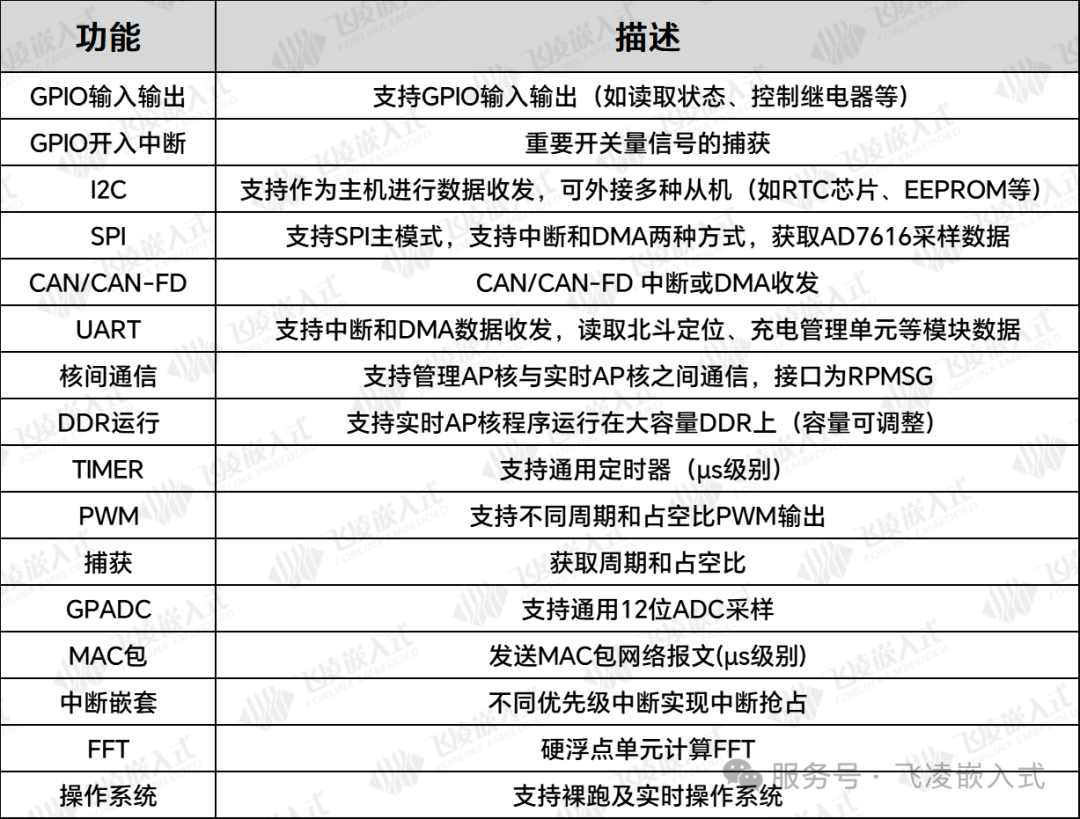
2、FTU方案资源框图
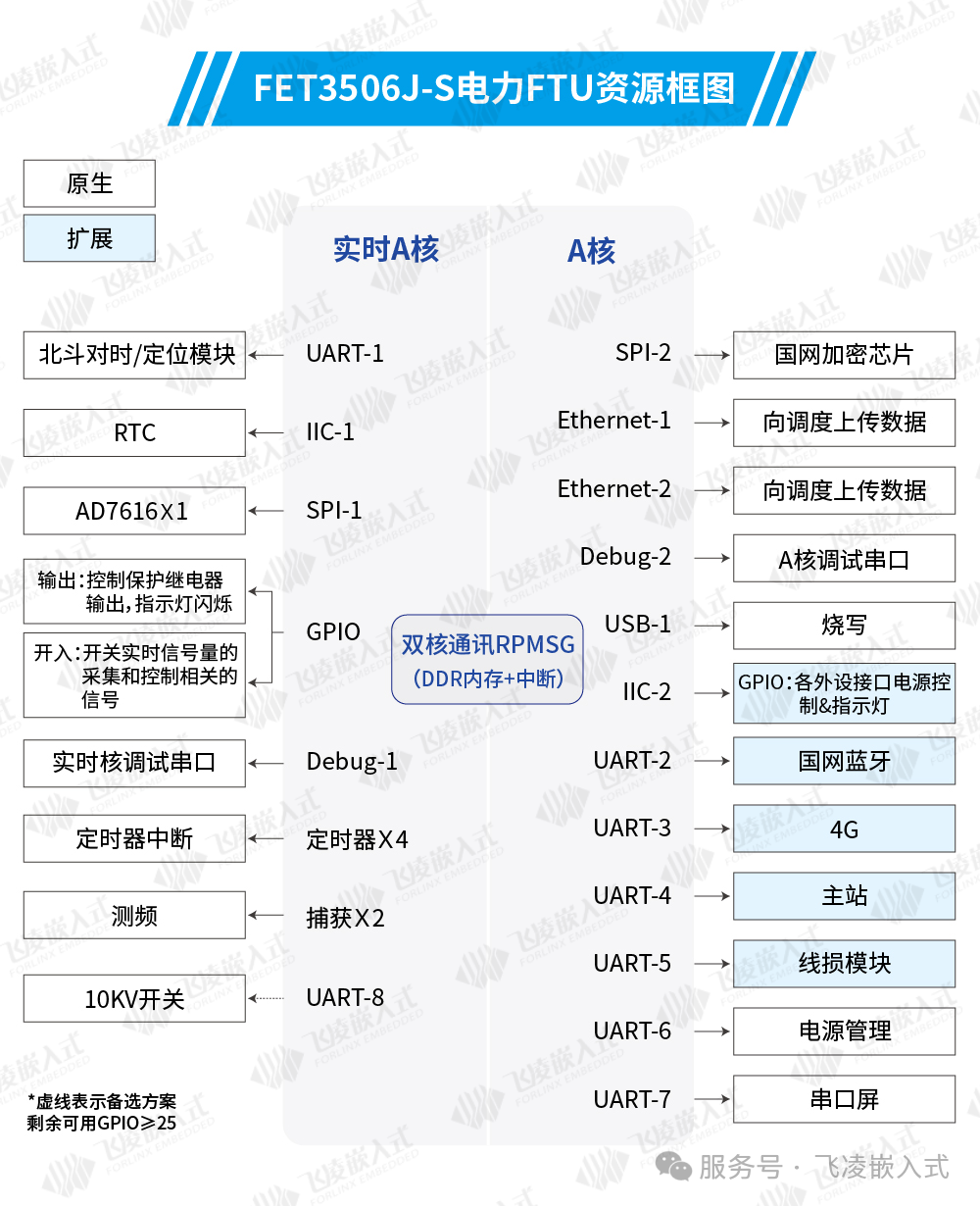
01、实时A核
北斗定位、实时时钟、多路模拟量采集、FFT运算、保护逻辑、故障处理及录波等高实时性任务由实时A核承载。该核心可同步处理多间隔单元的实时业务:通过50MHz SPI总线实现多路AD7616高速采样,动态配置DDR存储空间适配不同周期录波需求,并利用RPMsg双核通信机制将录波数据高效传输至管理核心生成标准化文件。
02、管理A核
管理A核集成多类型通信接口,可同时完成:
① 传感器数据协议适配与接入管理;
② 按IEC101/IEC104标准对采集数据进行加密处理,并通过专用通道向调度中心转发规范报文。双核通过共享内存与消息队列实现实时数据流与控制指令的高效交互。
3、应用实例
01、SPI数据收发
本案例为SPI回环测试,将SPI的MOSI和MISO两个引脚短接进行数据收发。
① 功能介绍
② 效果展现
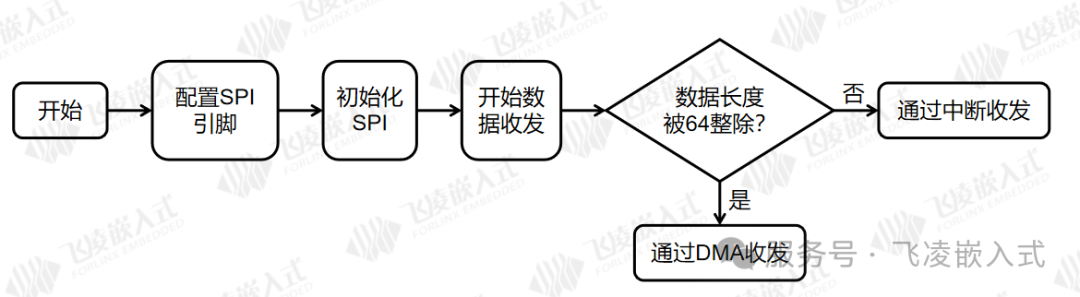
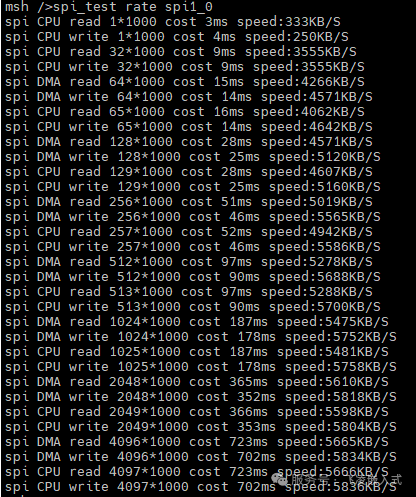
SPI的发送和接收FIFO均为64个,在底层hal库程序中,当数据长度被64整除时,采用DMA方式,否则采用CPU中断模式。通过此demo,展示了SPI的中端和DMA两种使用方法,设置SPI速率为50M全双工,案例中读或写平均传输速率为45.59Mbit/s,接近理论带宽。
传输效果:
02、GOOSE
本案例采用GMAC0发送Goose数据包测试。
① 功能介绍
② 效果展现
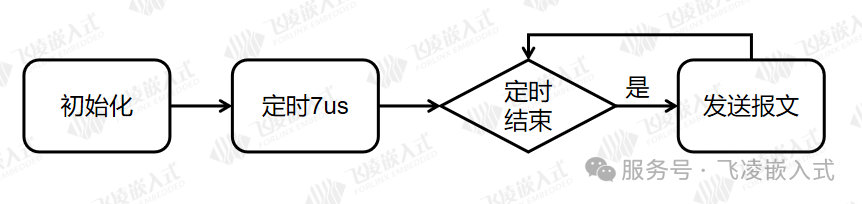
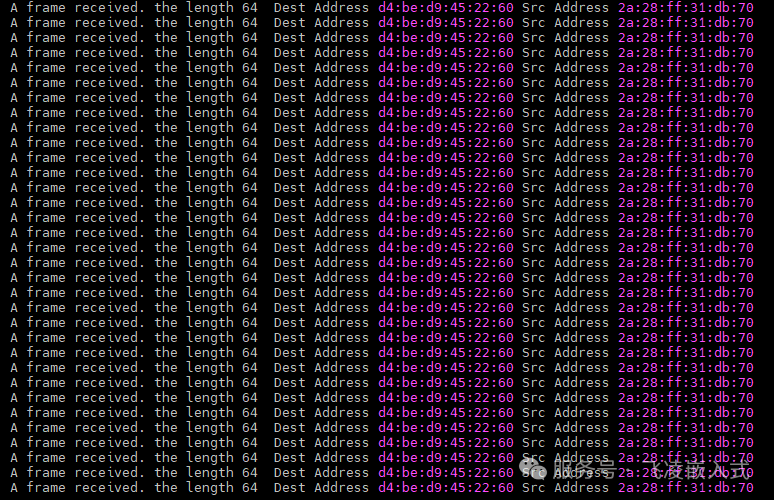
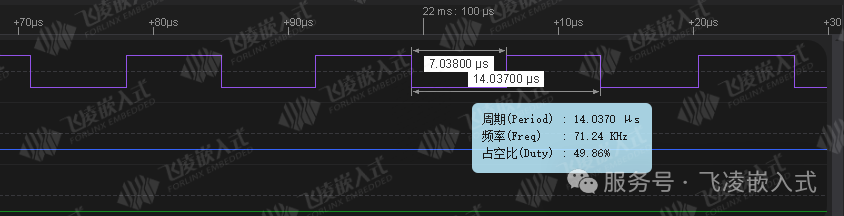
测试方法:采用单片机进行接收,接收完成后将GPIO进行反转,使用示波器测量GPIO波形。实测64字节数据,用时7μs,接近百兆理论带宽。
03、核间通信RPMsg
① 标准框架
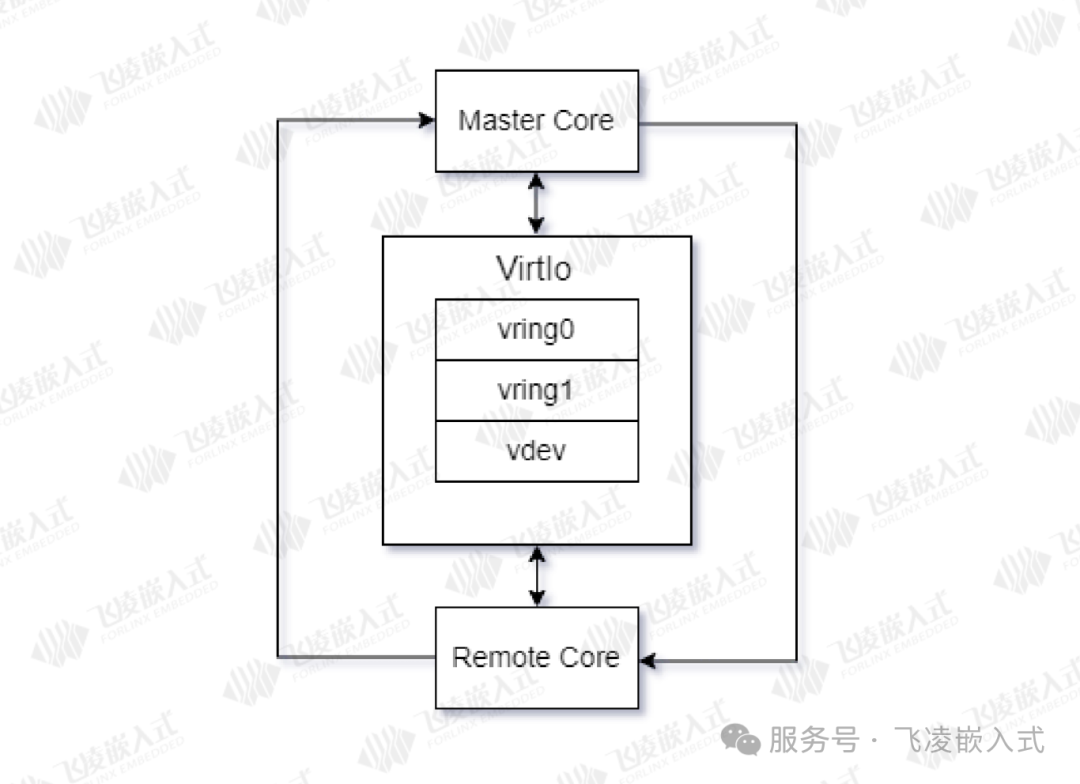
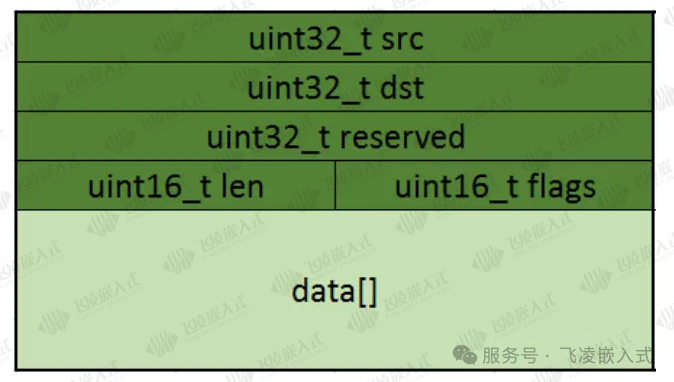
瑞芯微为多核异构系统设计了RPMsg通信框架:Linux内核采用标准RPMsg,RTOS/Bare-metal使用轻量化RPMsg-Lite,作为AMP系统核间通信的标准化二进制接口。
该协议基于VirtIo虚拟化IO架构(同虚拟网卡/虚拟磁盘等技术),通过VirtIo-Ring共享内存机制实现数据传输,采用单向vring设计(vring0发数据、vring1收数据)配合vdev-buffer缓冲区。
整体框架由核间中断及vring0、vring1、vdev-buffer三段共享内存区域构成。
② 通信流程
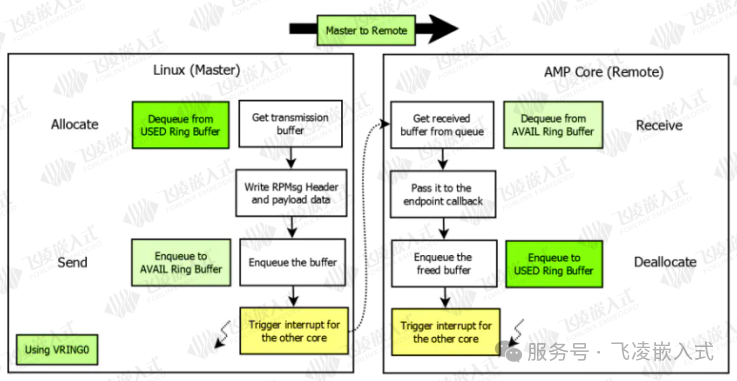
在RPMsg中,主-从核心通过中断和共享内存的方式进行通信,内存的管理由主核负责,在每个通信方向上都有USED和AVAIL两个缓冲区,这两个缓冲区可以按照RPMsg的消息格式分成一块一块,由这些内存块可以链接成一个环。

因此当主核(Master Core)和从核(Reomte Core)进行通信时:
1. Master Core发送时,从vring0(USED)中取得一块 buffer,再将消息按照RPMsg协议填充;
2. 将处理好的内存 buffer 链接到 ving1(AVAIL);
3. 触发中断通知 Remote Core 有数据处理待处理。
当从核需要和主核进行通信时:
1. 从核根据队列从 vring1(AVAIL) 中取得一块 buffer,再将消息按照 RPMsg 协议填充;
2. 将处理好的内存 buffer 链接到 ving0(USED);
3. 触发中断通知 Master Core 有数据处理待处理。
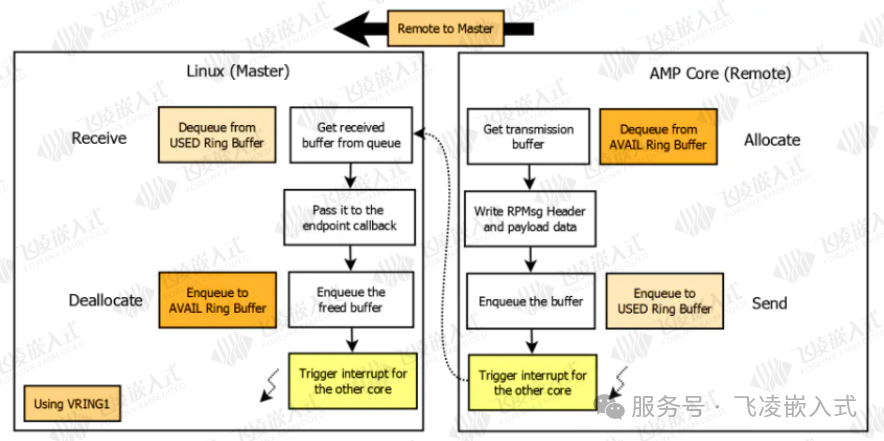
完成消息传递后,释放使用的 buffer,并等待下一笔数据发送。从核发送时,与主核发送流程相反。通信过程中的共享数据放在 vdev buffer 中。
RPMsg 每次发送的最大数据长度取决于 payload 长度,这个长度在SDK中默认为 512 Bytes,由于 RPMsg还带有16 Bytes的数据头,因此一次性传输的最大数据量为 496 Bytes。
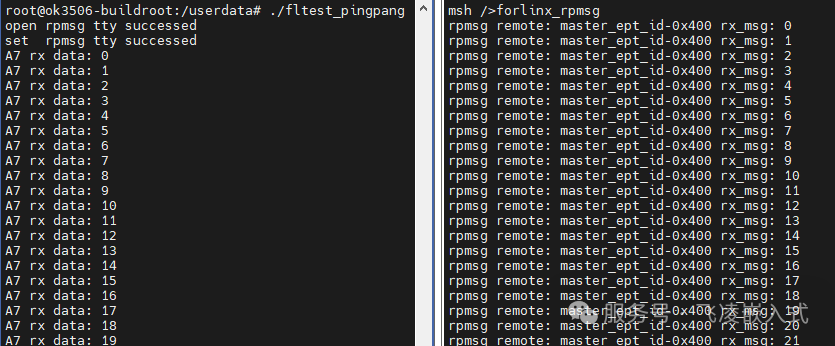
③ 效果展示
普通传输:乒乓示例
大数据传输:
在实际使用中采用原始RPMsg框架通信具有一定的局限性,默认单次发送数据最大为496字节,如果传输1MB数据,需要发送1024*1024/496=2114次才可传输完成;且每次传输需要触发两次中断,共计需要触发4228次中断,耗时1.05ms,综合上面两个因素可知,传输1MB数据时间大概为2.2s,且频繁中断占用CPU资源较多。
而飞凌嵌入式在RPMsg基础上优化了大数据传输的性能,在FET3506J-S核心板上的具体表现如下所示。传输6MB的数据,用时仅111ms,且仅需要触发4次中断,大大提高了传输效率,减少了对CPU资源的占用。

飞凌嵌入式FET3506J-S核心板在AMP异构多核架构下展现出卓越的通信性能,其双系统间数据交互速率达到行业领先水平,为电力FTU(馈线终端装置)应用提供了高效可靠的核心支撑。该板卡采用工业级设计标准,工作温宽覆盖-40℃至+85℃严苛环境,配备的丰富功能接口(包括多路串口、以太网、CAN总线等)可全面满足配电自动化终端的多场景接入需求。
凭借出色的通信效率、环境适应性和接口扩展能力,FET3506J-S核心板已成为电力FTU设备主控方案的理想选择,特别适用于对实时性和稳定性要求极高的智能电网应用场景。