数据库调优与数据表的范式设计
1. 数据库调优
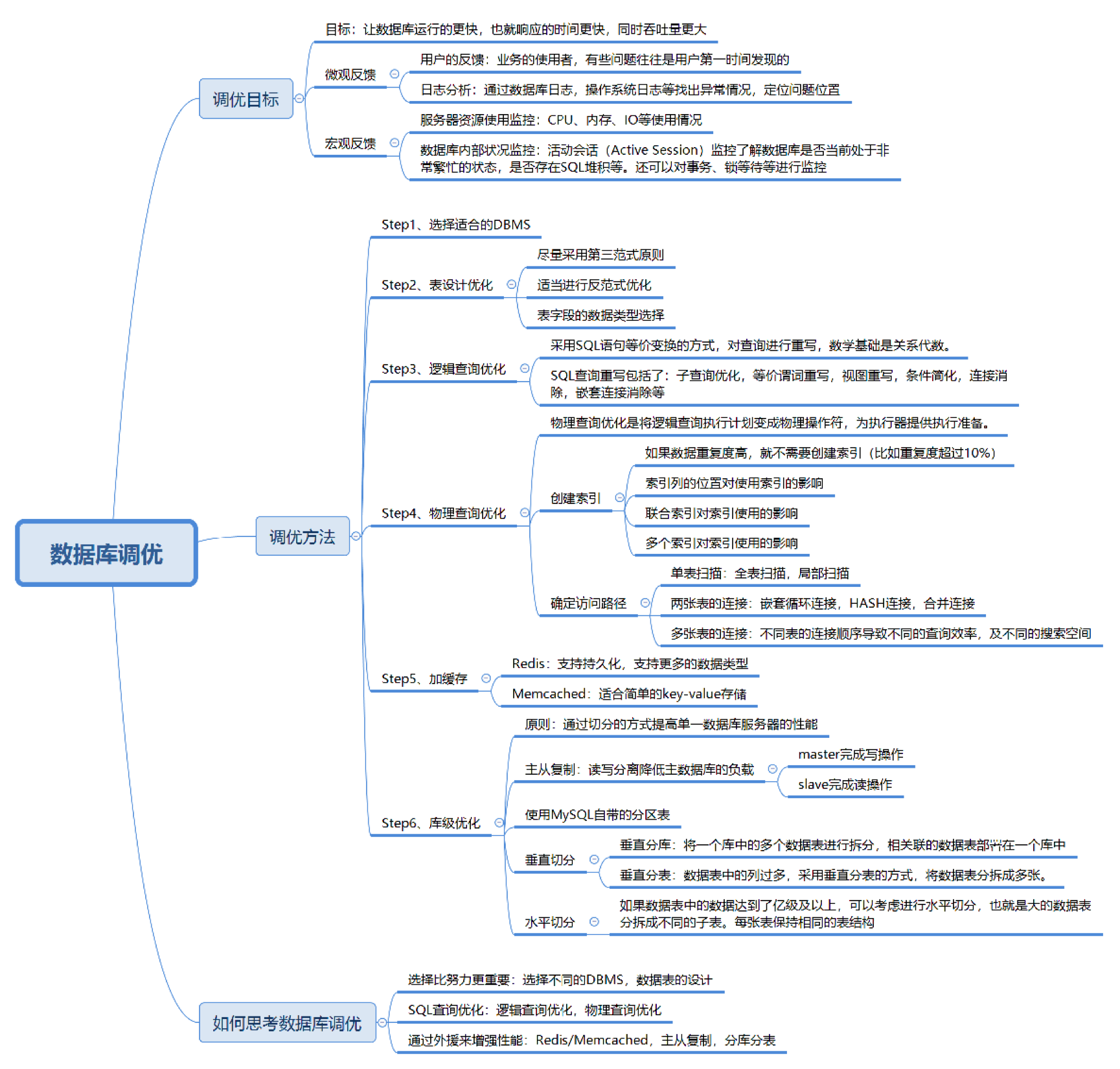
1.1. 数据库调优的目标
总体目标:让数据库运行更快,即响应时间更短,吞吐量更大。
但需注意:
不同时间段、不同业务场景、不同用户规模下,性能瓶颈各异,因此目标需要更细化定位。
获取调优目标的方式:
- 用户反馈:最直接的信号来源。
- 日志分析:查看数据库、操作系统日志,定位异常。
- 运行状态监控:
- 服务器资源监控:CPU、内存、磁盘I/O等。
- 数据库内部监控:活动会话数(Active Session)、事务状态、锁等待情况等。
1.2. 数据库调优的维度
1. 选择适合的 DBMS
- 关系型数据库(RDBMS):Oracle、SQL Server、MySQL(InnoDB、MyISAM等)
- 非关系型数据库(NoSQL):
键值型(Redis、Memcached)
文档型(MongoDB)
列式存储(HBase)
图数据库(Neo4j)
- 选择依据:
是否需要事务、安全性、并发处理能力等
使用场景:OLTP vs OLAP
2. 优化表设计
- 关键原则:
遵循第三范式:减少冗余、提高一致性
适度反范式化:空间换时间,提高查询效率
合理选择字段类型:
能用数字不用字符串
定长用 CHAR,变长用 VARCHAR
选择合适的存储引擎(如 MySQL 中的 InnoDB vs MyISAM)
3. 优化逻辑查询(SQL 语句重写)
- 核心思想:等价变换,重写 SQL,提高执行效率
- 常用优化方式:
子查询优化(如 EXISTS vs IN)
避免在 WHERE 子句中对字段使用函数(防止索引失效)
4. 优化物理查询(执行计划优化)
- 核心手段:索引
- 索引使用建议:
重复度高(如性别字段)→ 不适合建索引
避免对索引字段进行计算 → 会失效
注意联合索引顺序和最左前缀原则
索引不是越多越好,会增加维护成本
- 查询路径优化:
单表:全表扫描 vs 局部扫描
双表:嵌套循环连接 / Hash 连接 / 合并连接
多表连接:连接顺序影响搜索空间大小和效率
5. 使用缓存技术提升性能(Redis / Memcached)
频繁访问数据库会增加压力 → 把常用数据放到内存中
| 特性 | Redis | Memcached |
| 存储 | 内存 + 持久化 | 仅内存 |
| 数据类型 | 多(字符串、列表等) | 键值对 |
| 性能 | 稍逊于 Memcached | 非常高 |
| 适用场景 | 多功能缓存、消息队列等 | 简单高速缓存 |
6. 库级优化
- 控制单库表数量:避免一个数据库中表太多,便于管理与维护。
- 主从架构(读写分离):主库负责写操作,从库负责读操作,降低主库压力,提升并发能力。
- 分库分表:当数据量达到亿级以上时,通过拆分减轻单库/单表压力:
- 垂直分库:按业务模块拆分库,减少耦合。
- 垂直分表:按字段拆表,适用于字段很多的宽表。
- 水平分表:按数据行拆分,适用于数据量巨大的单表(如按年份或用户ID分表)。
- MySQL分区表:逻辑划分大表,简化管理,提升查询效率。
- 权衡成本:虽然拆分能提升性能,但也带来额外的开发和维护成本。
1.3. 如何思考和分析数据库调优
在思考数据库调优的时候,可以从三个维度进行考虑。
1. 首先,选择比努力更重要。
在进行 SQL 调优之前,可以先选择 DBMS 和数据表的设计方式。你能看到,不同的 DBMS 直接决定了后面的操作方式,数据表的设计方式也直接影响了后续的 SQL 查询语句。
2. 另外,可以把 SQL 查询优化分成两个部分,逻辑查询优化和物理查询优化。
虽然 SQL 查询优化的技术有很多,但是大方向上完全可以分成逻辑查询优化和物理查询优化两大块。逻辑查询优化就是通过 SQL 等价变换提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高。物理查询优化则是通过索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用。
3. 最后,可以通过外援来增强数据库的性能。
单一的数据库总会遇到各种限制,不如取长补短,利用外援的方式。
另外通过对数据库进行垂直或者水平切分,突破单一数据库或数据表的访问限制,提升查询的性能。
6个维度总结:
| 调优维度 | 主要内容 |
| DBMS选择 | 关系型 vs 非关系型,按业务场景选型 |
| 表设计优化 | 第三范式、反范式、字段类型、存储引擎选择等 |
| 逻辑查询优化 | SQL 等价重写、避免函数、简化条件 |
| 物理查询优化 | 索引使用、连接方式选择、执行路径估算 |
| 缓存优化 | 使用 Redis / Memcached 缓解数据库访问压力 |
| 库级优化 | 控制单库表数量、主从分离、分库分表(垂直/水平)、使用分区表、权衡维护成本 |
2. 数据表的范式设计

设计范式越高阶,数据表就会越精细,数据的冗余度也就越少,在一定程度上可以让数据库在内部关联上更好地组织数据。但有时候我们也需要采用反范进行优化,通过空间来换取时间。
2.1. 设计范式的重要性
- 规范性 vs. 实用性:规范有助于正确性与严谨性,但过度约束可能影响效率。
- 设计初期的重要性:错误的数据表设计在运行后再修改成本高(如数据迁移、程序改动)。
- 范式(NF):数据表设计的标准,用于减少冗余、避免异常(插入、更新、删除异常)。
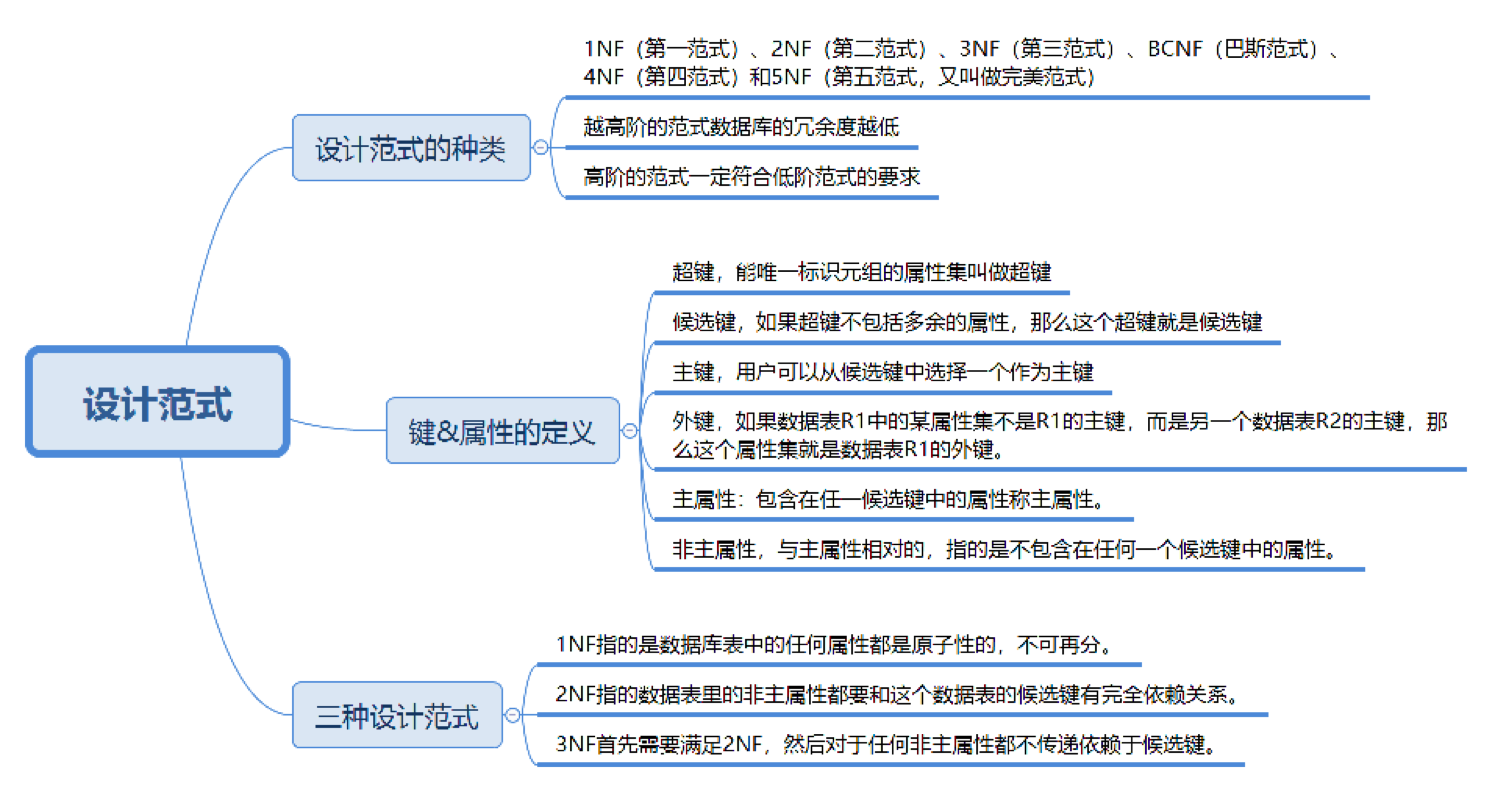
2.2. 6种设计范式
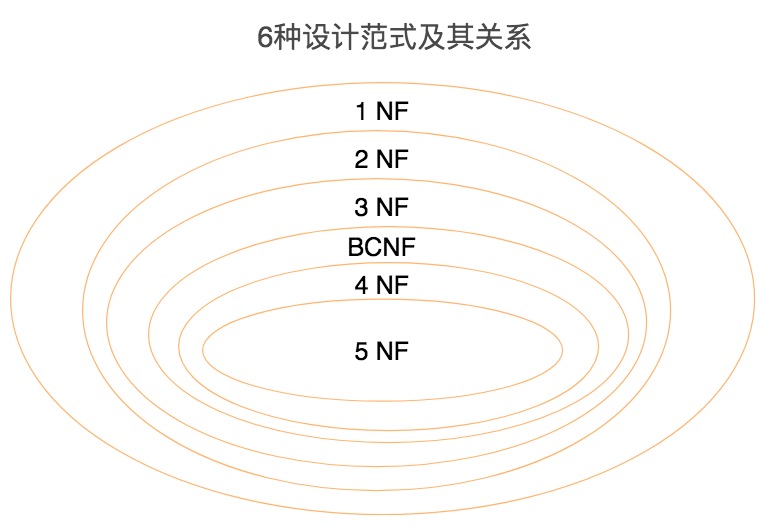
范式的定义会使用到主键和候选键(因为主键和候选键可以唯一标识元组),数据库中的键(Key)由一个或者多个属性组成。我总结了下数据表中常用的几种键和属性的定义:
- 超键:能唯一标识元组的属性集叫做超键。
- 候选键:如果超键不包括多余的属性,那么这个超键就是候选键。
- 主键:用户可以从候选键中选择一个作为主键。
- 外键:如果数据表 R1 中的某属性集不是 R1 的主键,而是另一个数据表 R2 的主键,那么这个属性集就是数据表 R1 的外键。
- 主属性:包含在任一候选键中的属性称为主属性。
- 非主属性:与主属性相对,指的是不包含在任何一个候选键中的属性。
通常,我们也将候选键称之为“码”,把主键也称为“主码”。因为键可能是由多个属性组成的,针对单个属性,我们还可以用主属性和非主属性来进行区分。
1. 1NF
1NF 指的是数据库表中的任何属性都是原子性的,不可再分。
我们在设计某个字段的时候,对于字段 X 来说,就不能把字段 X 拆分成字段 X-1 和字段 X-2。事实上,任何的 DBMS 都会满足第一范式的要求,不会将字段进行拆分。
2. 2NF
2NF 指的数据表里的非主属性都要和这个数据表的候选键有完全依赖关系。所谓完全依赖不同于部分依赖,也就是不能仅依赖候选键的一部分属性,而必须依赖全部属性。
这里我举一个没有满足 2NF 的例子,比如说我们设计一张球员比赛表 player_game,里面包含球员编号、姓名、年龄、比赛编号、比赛时间和比赛场地等属性,这里候选键和主键都为(球员编号,比赛编号),我们可以通过候选键来决定如下的关系:
(球员编号, 比赛编号) → (姓名, 年龄, 比赛时间, 比赛场地,得分)
上面这个关系说明球员编号和比赛编号的组合决定了球员的姓名、年龄、比赛时间、比赛地点和该比赛的得分数据。
但是这个数据表不满足第二范式,因为数据表中的字段之间还存在着如下的对应关系:
(球员编号) → (姓名,年龄)
(比赛编号) → (比赛时间, 比赛场地)
也就是说候选键中的某个字段决定了非主属性。你也可以理解为,对于非主属性来说,并非完全依赖候选键。这样会产生怎样的问题呢?
- 数据冗余:如果一个球员可以参加 m 场比赛,那么球员的姓名和年龄就重复了 m-1 次。一个比赛也可能会有 n 个球员参加,比赛的时间和地点就重复了 n-1 次。
- 插入异常:如果我们想要添加一场新的比赛,但是这时还没有确定参加的球员都有谁,那么就没法插入。
- 删除异常:如果我要删除某个球员编号,如果没有单独保存比赛表的话,就会同时把比赛信息删除掉。
- 更新异常:如果我们调整了某个比赛的时间,那么数据表中所有这个比赛的时间都需要进行调整,否则就会出现一场比赛时间不同的情况。
为了避免出现上述的情况,我们可以把球员比赛表设计为下面的三张表。
球员 player 表包含球员编号、姓名和年龄等属性;比赛 game 表包含比赛编号、比赛时间和比赛场地等属性;球员比赛关系 player_game 表包含球员编号、比赛编号和得分等属性。
这样的话,每张数据表都符合第二范式,也就避免了异常情况的发生。某种程度上 2NF 是对 1NF 原子性的升级。1NF 告诉我们字段属性需要是原子性的,而 2NF 告诉我们一张表就是一个独立的对象,也就是说一张表只表达一个意思。
3. 3NF
3NF 在满足 2NF 的同时,对任何非主属性都不传递依赖于候选键。也就是说不能存在非主属性 A 依赖于非主属性 B,非主属性 B 依赖于候选键的情况。
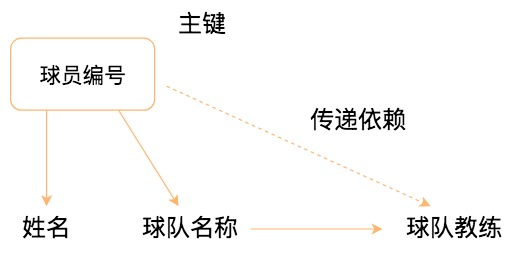
我们用球员 player 表举例子,这张表包含的属性包括球员编号、姓名、球队名称和球队主教练。现在,我们把属性之间的依赖关系画出来,如下图所示:
你能看到球员编号决定了球队名称,同时球队名称决定了球队主教练,非主属性球队主教练就会传递依赖于球员编号,因此不符合 3NF 的要求。如果要达到 3NF 的要求,需要把数据表拆成下面这样:
球员表的属性包括球员编号、姓名和球队名称;球队表的属性包括球队名称、球队主教练。
4. BCNF(巴斯范式)
BCNF,也叫做巴斯 - 科德范式,它在 3NF 的基础上消除了主属性对候选键的部分依赖或者传递依赖关系。
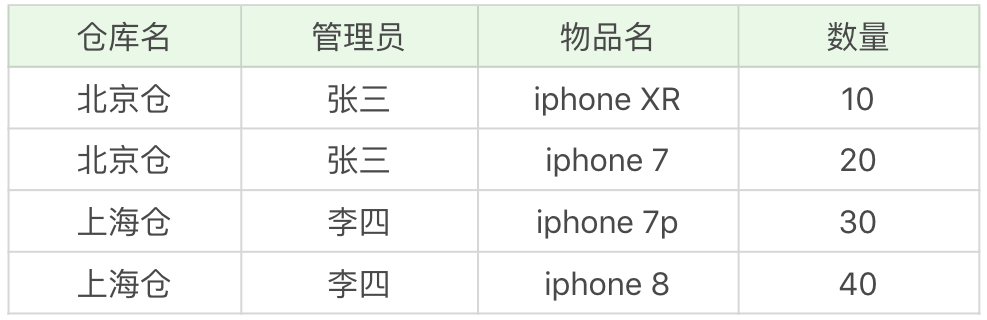
如果数据表的关系模式符合 3NF 的要求,就不存在问题了吗?我们来看下这张仓库管理关系 warehouse_keeper 表:
在这个数据表中,一个仓库只有一个管理员,同时一个管理员也只管理一个仓库。仓库名决定了管理员,管理员也决定了仓库名,同时(仓库名,物品名)的属性集合可以决定数量这个属性。
这样,我们就可以找到数据表的候选键是(管理员,物品名)和(仓库名,物品名),
然后我们从候选键中选择一个作为主键,比如(仓库名,物品名)。
在这里,主属性是包含在任一候选键中的属性,也就是仓库名,管理员和物品名。非主属性是数量这个属性。
判断一张表的范式,根据范式的等级,从低到高来进行判断。
首先,数据表每个属性都是原子性的,符合 1NF 的要求;其次,数据表中非主属性”数量“都与候选键全部依赖,(仓库名,物品名)决定数量,(管理员,物品名)决定数量,因此,数据表符合 2NF 的要求;最后,数据表中的非主属性,不传递依赖于候选键。因此符合 3NF 的要求。
存在的问题:
- 增加一个仓库,但是还没有存放任何物品。根据数据表实体完整性的要求,主键不能有空值,因此会出现插入异常;
- 如果仓库更换了管理员,我们就可能会修改数据表中的多条记录;
- 如果仓库里的商品都卖空了,那么此时仓库名称和相应的管理员名称也会随之被删除。
即便数据表符合 3NF 的要求,同样可能存在插入,更新和删除数据的异常情况。
解决办法:
首先我们需要确认造成异常的原因:主属性仓库名对于候选键(管理员,物品名)是部分依赖的关系,这样就有可能导致上面的异常情况。根据 BCNF 的要求,我们需要把仓库管理关系 warehouse_keeper 表拆分成下面这样:
仓库表:(仓库名,管理员)
库存表:(仓库名,物品名,数量)
这样就不存在主属性对于候选键的部分依赖或传递依赖,上面数据表的设计就符合 BCNF。
四个范式:
1NF 需要保证表中每个属性都保持原子性;
2NF 需要保证表中的非主属性与候选键完全依赖;
3NF 需要保证表中的非主属性与候选键不存在传递依赖。
4NF需要保证主属性与候选键不存在部分依赖或者传递依赖关系。
2.3. 反范式设计
什么是反范式:
为了提升查询效率,有时可以有意保留冗余,用空间换取时间。适用于读多写少的场景。
查询效率对比:
比如我们想要在百万条商品评论中查询某个商品的前 1000 条评论,会涉及到两张表。
商品评论表 product_comment,对应的字段名称及含义如下:

用户表 user,对应的字段名称及含义如下:

- 范式表(需 JOIN 查询用户昵称):耗时:约 0.395 秒
- 反范式表(商品评论表种新增 user_name 字段):耗时:约 0.039 秒,查询时间提升 约 10 倍
2.4. 反范式设计的利弊
优点:
- 提升读性能,减少 JOIN;
- 提升大数据量场景下查询响应速度;
- 适用于电商、社交、资讯类系统。
缺点:
- 写入、更新成本高(如用户昵称更改需同步多个表);
- 数据冗余增加,增加存储成本;
- 系统维护更复杂(如需引入触发器或存储过程同步数据)。