LangGraph 实战指南:长期记忆管理
LangGraph为智能对话系统设计了一种独特的“记忆”机制,它包括长期记忆和短期记忆两种类型。
基本信息
- 模型调用通义千问(阿里Tongyi大模型)
- 短期记忆:通过维护会话中的消息的历史记录,来跟踪正在进行的对话。短期记忆也称为线程级记忆。
- 长期记忆:跨会话存储用户特定或应用程序级数据。长期记忆又称为跨线程记忆。
长期记忆就像是一个“记忆仓库”,可以存储用户的各种信息,比如名字、语言偏好、历史对话记录等。这些信息被组织成一个个“记忆单元”,每个单元都有自己的“文件夹”(命名空间)和“文件名”(键)。比如,一个聊天机器人可以为每个用户创建一个独立的命名空间,里面存储着用户的各种偏好信息。
使用 LangGraph 管理长期记忆
通过三个简单的demo例子来看看LangGraph是如何在实际中工作的。
要使用长期记忆,需要:
- 配置存储以在调用之间保留数据
- 使用该get_store功能从工具或提示中访问LangSmith商店
1 保存用户信息
首先,初始化一个内存存储,然后定义一个保存用户信息的函数。这个函数会把用户的信息存储到长期记忆中。
把用户的名字“小何慢行”保存到了长期记忆中。
# -*- coding: utf-8 -*-
from langgraph.prebuilt import create_react_agent
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from typing_extensions import TypedDictfrom langgraph.store.memory import InMemoryStore
from langgraph.config import get_store#模型初始化
llm = ChatTongyi(model="qwen-turbo",#qwen-max-latest qwen-plustemperature=0,verbose=True,)# 写入get_store()
store = InMemoryStore() class UserInfo(TypedDict): name: str# 类似于文件夹
user_namespace = "users" def save_user_info(user_info: UserInfo, config: RunnableConfig) -> str: """保存用户信息"""# 与create_react_agent提供的一样store = get_store() user_id = config["configurable"].get("user_id")store.put((user_namespace,), user_id, user_info) return "已成功保存!"#构建一个智能体
agent = create_react_agent(model=llm,tools=[save_user_info],store=store
)# #智能体的调用
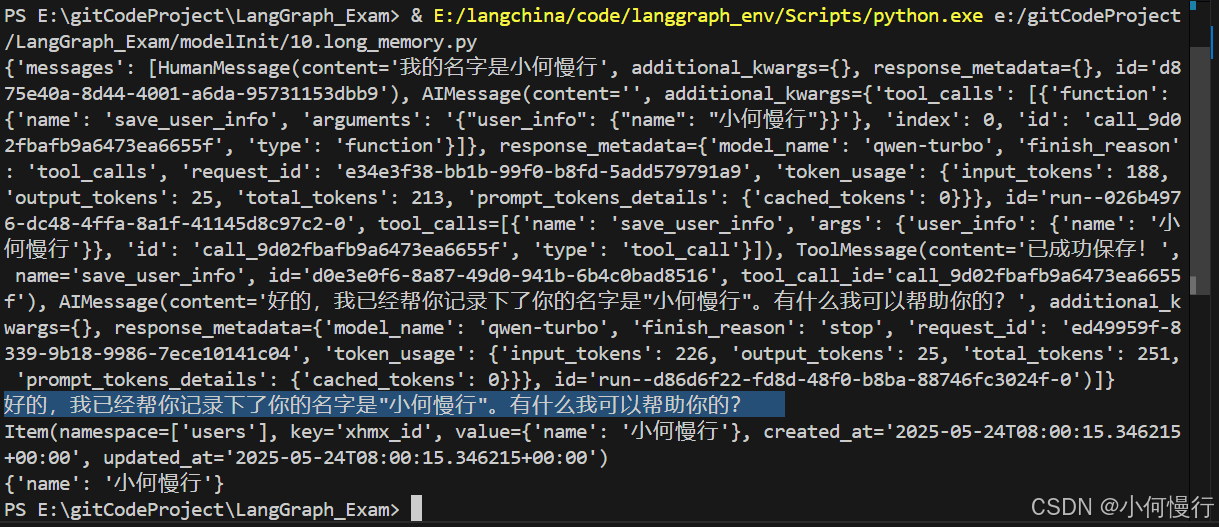
response = agent.invoke({"messages": [{"role": "user", "content": "我的名字是小何慢行"}]},config={"configurable": {"user_id": "xhmx_id"}}
)print(response)
print(response["messages"][-1].content)#直接访问仓库来获取值。
print(store.get((user_namespace,), "xhmx_id"))
print(store.get((user_namespace,), "xhmx_id").value)运行结果截图
2 读取用户信息
需要读取用户信息时,可以定义一个读取函数,从长期记忆中获取用户的信息。
假设第一个用例中保存了用户信息,现在我们来读取它。
# -*- coding: utf-8 -*-
from langgraph.prebuilt import create_react_agent
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from typing_extensions import TypedDictfrom langgraph.store.memory import InMemoryStore
from langgraph.config import get_store#模型初始化
llm = ChatTongyi(model="qwen-turbo",#qwen-max-latest qwen-plustemperature=0,verbose=True,)
# 读取get_store()
store = InMemoryStore() #类似于文件夹
user_namespace = "users"
#类似于文件名
user_key = "xhmx_id"store.put( (user_namespace,), #可以多个user_key, {"name": "小何慢行","sex": "男","language": "汉语",}
)def get_user_info(config: RunnableConfig) -> str:"""查询用户信息"""store = get_store() user_id = config["configurable"].get("user_id")user_info = store.get((user_namespace,), user_id) return str(user_info.value) if user_info else "未记录该用户"#构建一个智能体
agent = create_react_agent(model=llm,tools=[get_user_info],store=store
)#直接访问仓库来获取值。
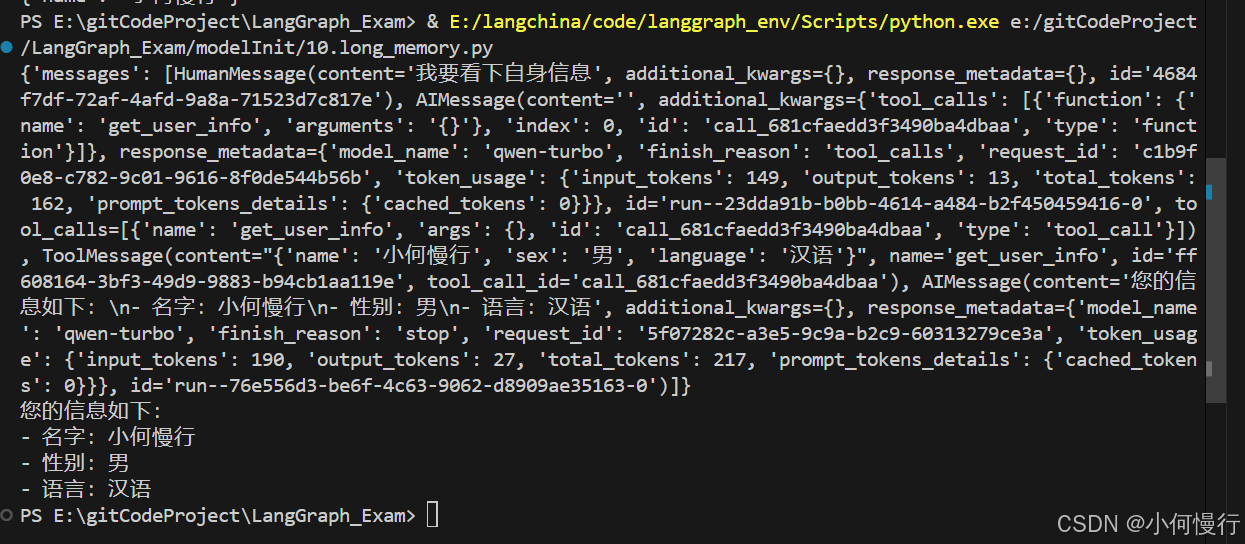
response = agent.invoke({"messages": [{"role": "user", "content": "我要看下自身信息"}]},config={"configurable": {"user_id": user_key}}
)print(response)
print(response["messages"][-1].content)运行结果截图
3 语义搜索:找到相关记忆
LangGraph 还允许通过语义相似性搜索长期记忆中的项目。
有时候,我们可能需要根据内容的相似性来搜索记忆,而不仅仅是通过关键词。可以通过描述来找到相关的信息。
# -*- coding: utf-8 -*-
from langgraph.prebuilt import create_react_agent
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from typing_extensions import TypedDictfrom langgraph.store.memory import InMemoryStore
from langgraph.config import get_store#模型初始化
llm = ChatTongyi(model="qwen-turbo",#qwen-max-latest qwen-plustemperature=0,verbose=True,)
#返回嵌入向量占位符列表
def embed(texts: list[str]) -> list[list[float]]:# 可以替换为实际的嵌入函数。 embed": init_embeddings("openai:text-embedding-3-small")return [[1.0, 2.0] * len(texts)]# from langchain_community.embeddings import DashScopeEmbeddings
# from langchain.embeddings import init_embeddings
# embeddings = DashScopeEmbeddings(dashscope_api_key="sk-b8b221d506c041e08db52e622d48b2")# 数据保存到内存中的字典。可以使用基于数据库的存储 如postgresql
store = InMemoryStore(index={"embed": embed, "dims": 2})user_id = "users"
application_context = "chitchat"
namespace = (user_id, application_context)user_key = "xhmx_id_memory"store.put(namespace,user_key,{"rules": ["用户只会说汉语和Python。","用户喜欢简洁直白的语言。",],"my-key": "my-value",},
)# 通过ID获取memory信息
item = store.get(namespace, user_key)
print(item)print("------------------------")
# 按内容等价性进行筛选,按向量相似性会排序
items = store.search(namespace, filter={"my-key": "my-value"}, query="语言偏好"
)
print(items)运行结果截图
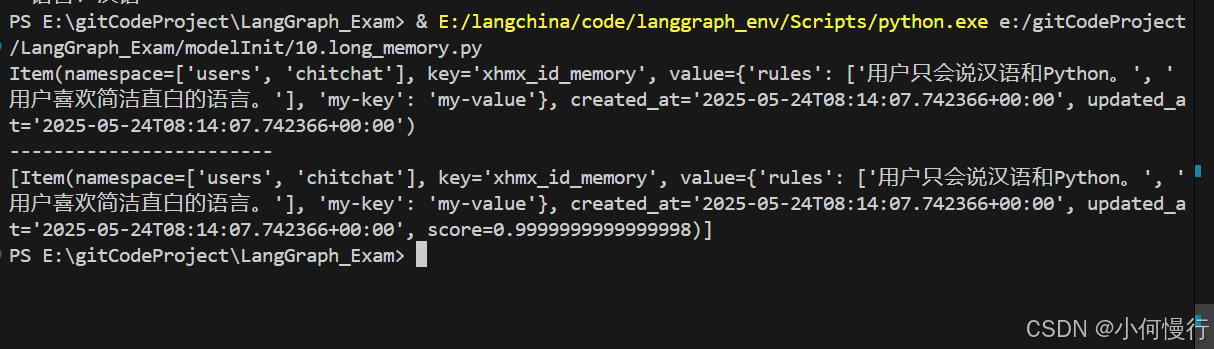
通过语义搜索找到了与“语言偏好”相关的记忆,即使我们没有直接使用这个关键词来保存记忆。
预建记忆工具
LangMem是由 LangChain 维护的一个库,它提供了用于管理代理中长期记忆的工具。可以参阅LangMem 文档以获取使用示例。
LangGraph的长期记忆,为智能对话系统提供了一个强大的“记忆”功能。它不仅能够让系统记住用户的信息和偏好,还能通过语义搜索快速找到相关信息。
这种记忆机制的设计,让智能对话系统更加人性化,能够更好地满足用户的需求。无论是智能客服还是个人助手,LangGraph都能让它们变得更加智能和贴心。
下一节:
1.langgraph的新特性:支持人工参与的循环审查