VILT模型阅读笔记
代码地址:VILT
Abstract
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-andlanguage downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of times faster than previous VLP models, yet with competitive or better downstream task performance.
视觉-语言预训练(VLP)技术已在多种跨模态下游任务中展现出显著性能提升。当前主流的VLP方法高度依赖图像特征提取流程,其中普遍采用区域监督机制(例如目标检测)和卷积架构(例如ResNet)。尽管文献尚未对此进行深入探讨,但我们发现该范式存在两个根本性问题:其一从效率维度来看,输入特征提取环节的计算量远超多模态交互步骤的计算需求;其二就表达能力而言,其性能上限受制于视觉编码器的表达能力和预定义视觉词表的表征范围。针对上述局限,本文提出一种极简的VLP模型——视觉-语言Transformer(ViLT),其核心创新在于对视觉输入处理流程进行彻底重构,采用与文本输入完全一致的无卷积方式处理视觉信号。 实验表明,ViLT的推理速度较现有VLP模型提升高达数十倍,且在多项下游任务中展现出具有竞争力甚至更优的性能表现。
Introduction
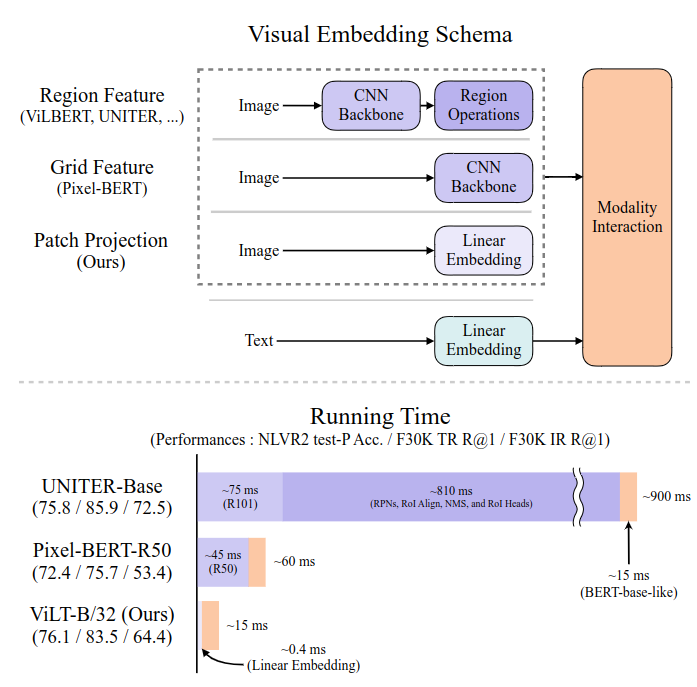
这是VILT中的第一张图,对比了三种方案:
- Region Feature (如ViLBERT、UNITER)
流程 :图像 → CNN Backbone(提取特征)→ Region Operations(区域操作,如目标检测中的ROI池化)。
特点 :依赖区域提议网络(如RPN)和复杂的后处理(如NMS),适用于需要显式区域信息的任务。 - Grid Feature (如Pixel-BERT)
流程 :图像 → CNN Backbone(直接输出网格特征)。
特点 :将图像划分为固定网格,丢弃位置信息,简化计算但可能损失细节。 - Patch Projection(本文方法)
流程 :图像 → Linear Embedding(线性投影,直接将图像块映射为嵌入向量)。
特点 :无需CNN或复杂后处理,通过简单线性变换高效生成视觉嵌入,显著降低计算量。
1. 传统VLP模型的局限性
- 计算瓶颈:现有VLP模型(如UNITER、Pixel-BERT)依赖复杂的视觉特征提取流程(如目标检测、CNN特征提取),导致训练和推理耗时显著增加(如图1中区域特征提取耗时达810ms,而Transformer交互仅需15ms)。这种设计在学术实验中常通过缓存特征规避问题,但实际应用中难以应对实时查询需求。
- 表达能力限制:基于预定义物体类别(如Visual Genome的1,600类)的区域特征存在语义覆盖盲区,且CNN的局部感受野难以捕捉长距离视觉依赖关系,限制了模型对复杂跨模态关系的建模能力。
2. ViLT的创新点与突破
- 无CNN的端到端处理:ViLT直接将图像划分为固定大小的块(patch),通过线性投影转换为向量后输入Transformer,与文本序列进行联合编码(如图1右半部分)。这一设计消除了传统CNN/RPN(区域提议网络)模块,使视觉嵌入(Visual Embed)的计算量从数百毫秒降至0.4ms,整体推理速度提升数十倍。
- 统一的模态交互框架:首次实现视觉和文本在Transformer中的同构处理,避免了多阶段流水线设计(如特征提取→融合→任务适配),增强了模型对齐跨模态语义的能力。
3. 当前研究背景下的技术关联
- Vision Transformer(ViT)的启发:ViLT借鉴了ViT(Dosovitskiy et al., 2020)中图像分块线性投影的思想,验证了Transformer在视觉领域对CNN的替代潜力。但ViT专注于单模态视觉任务,而ViLT将其扩展到跨模态场景,解决了图像-文本对齐的特殊挑战(如局部-全局语义匹配)。
- 多模态Transformer的演进:早期模型(如ViLBERT、LXMERT)采用双流架构分别处理视觉和文本,再通过跨注意力融合,导致参数冗余。ViLT通过单一流架构(如图2(d)中MI > VE=TE)实现更高效的模态交互,符合Transformer在NLP领域"越深越统一"的设计趋势。
4. 性能与效率的平衡机制
- 轻量化设计的实证有效性:尽管ViLT的视觉嵌入层参数仅为传统CNN的1/100(如ResNet-50约2,500万参数 vs. ViLT的线性投影层约20万参数),但其Transformer主干网络(如BERT-base规模)通过跨模态注意力机制弥补了浅层视觉编码的不足。实验显示,在NLVR2(76.1%)和Flickr30k(TR R@1 83.5%)等任务上,ViLT性能优于Pixel-BERT(72.4%/75.7%)和接近UNITER(75.8%/85.9%)。
- 数据增强与掩码策略的优化:首次引入整体词掩码(Whole Word Masking)和图像增强(如随机裁剪、颜色扰动),前者提升语言端的上下文理解,后者增强视觉特征的鲁棒性,共同推动下游任务性能提升(如Flickr30k IR R@1从Pixel-BERT的53.4%提升至64.4%)。
5. 研究意义与未来方向
- 理论层面:证明了区域监督和深度CNN非VLP的必要条件,为多模态学习提供新的范式。
- 工程应用:适合移动端/边缘设备部署(如实时图像检索、AR场景理解),解决传统模型因高算力需求导致的落地难题。
- 潜在挑战:
- 长尾视觉概念建模:缺乏显式物体检测可能影响对罕见类别(如特定型号汽车)的识别。
- 高分辨率处理成本:直接分块可能导致图像分辨率与计算量的线性增长,需权衡精度与效率(如ViLT-B/32使用32×32块大小)。
- 后续研究方向:
- 探索动态分块机制(如根据图像内容调整块大小)。
- 结合自监督预训练(如对比学习)进一步减少对大规模标注数据的依赖。
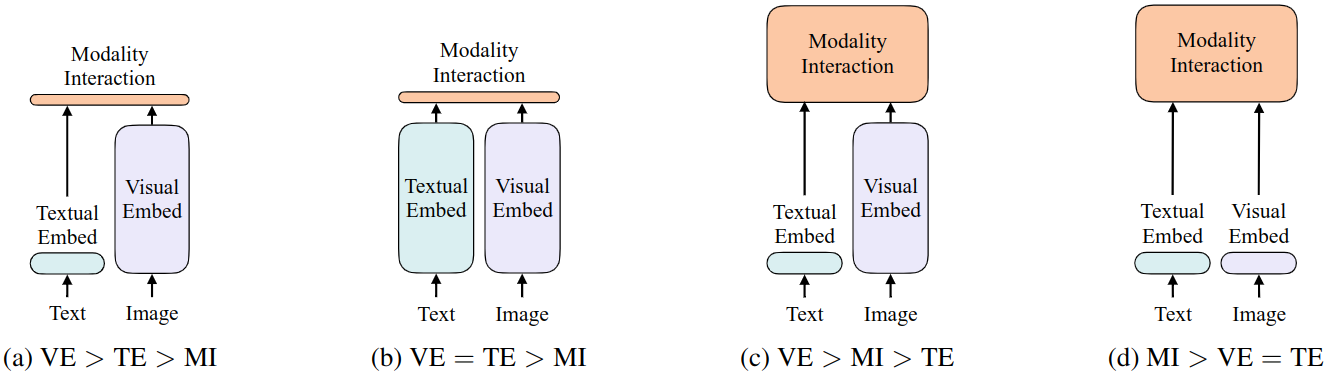
- 如图 2(a) 所示,属于是视觉模型占大部分算力,用简单的点积或浅注意层来表征两种模态中特征的相似性,代表模型是 VSE++
- 如图 2(b) 所示,属于是视觉模型和文本模型都使用较大算力,用简单的点积或浅注意层来表征两种模态中特征的相似性,代表模型是 CLIP。但是,这种方法对于视觉-语言下游任务性能很差,比如 CLIP 在 NLVR2 数据集上面性能较差,说明纵使单一模态的编码器很好,但是对其输出的简单融合可能也不足以学习复杂的视觉和语言任务,这可能就需要我们去研究更严格的跨模态交互方案了。
- 模型如图 2© 所示,属于是视觉模型占大部分算力,使用 Transformer 对图像和文本特征的交互进行建模,代表模型是 [FiLM](FiLM: Visual Reasoning with a General Conditioning Layer)和MoVie。
- 模型如图 2(d) 所示,属于是视觉模型和文本模型都极其简单,大部分计算力集中在模态的交互上面,使用 Transformer 对图像和文本特征的交互进行建模,代表模型是本文的 ViLT。
以下是对 ViLT 论文 3. Vision-and-Language Transformer 部分的详细解析,涵盖模型架构、预训练目标及关键技术细节:
Model Structure
3.1 Model Overview
核心设计:极简视觉嵌入 + 单流 Transformer
ViLT 是首个完全端到端的视觉-语言预训练(VLP)模型,其核心创新在于 极简的视觉嵌入流程 和 单流 Transformer 架构:
- 视觉嵌入(Visual Embedding)
- 输入处理:将图像 I ∈ R C × H × W I \in \mathbb{R}^{C \times H \times W} I∈RC×H×W 切分为 N = H W / P 2 N = HW/P^2 N=HW/P2 个块(patch),每个块展平为 R P 2 ⋅ C \mathbb{R}^{P^2 \cdot C} RP2⋅C,再通过线性投影 V ∈ R ( P 2 ⋅ C ) × H V \in \mathbb{R}^{(P^2 \cdot C) \times H} V∈R(P2⋅C)×H 映射为嵌入向量 v ˉ ∈ R N × H \bar{v} \in \mathbb{R}^{N \times H} vˉ∈RN×H。
- 位置编码:添加可学习的位置编码 V pos ∈ R ( N + 1 ) × H V_{\text{pos}} \in \mathbb{R}^{(N+1) \times H} Vpos∈R(N+1)×H,其中 N + 1 N+1 N+1 包含一个用于分类的
[CLS]token( v class v_{\text{class}} vclass)。 - 对比传统方法:无需 CNN 或区域特征提取(如 Faster R-CNN),直接通过线性投影生成视觉嵌入,显著降低计算成本。
参考了底层源码和claude4给出的设计,大致过程如下:
import torch
import torch.nn as nn
from transformers import BertConfigclass ViltImageEmbeddings(nn.Module):"""VILT的图像嵌入层,将图像patch转换为嵌入向量"""def __init__(self, config):super().__init__()self.config = configself.image_size = config.image_sizeself.patch_size = config.patch_sizeself.num_patches = (self.image_size // self.patch_size) ** 2# 图像patch嵌入self.patch_embeddings = nn.Conv2d( #这里虽然使用了Cov2d,但是本质上还是一个线性划分的效果,并没有进行卷积计算和CNN中的backbone各种激活函数的过程。in_channels=3,out_channels=config.hidden_size,kernel_size=self.patch_size,stride=self.patch_size)# 位置嵌入self.position_embeddings = nn.Parameter(torch.zeros(1, self.num_patches + 1, config.hidden_size))# CLS tokenself.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))# 模态类型嵌入(区分图像和文本)self.token_type_embeddings = nn.Embedding(2, config.hidden_size)self.dropout = nn.Dropout(config.hidden_dropout_prob)def forward(self, pixel_values):batch_size = pixel_values.shape[0]# 将图像分割成patches并嵌入patch_embeddings = self.patch_embeddings(pixel_values) # (B, hidden_size, H/P, W/P)patch_embeddings = patch_embeddings.flatten(2).transpose(1, 2) # (B, num_patches, hidden_size)# 添加CLS tokencls_tokens = self.cls_token.expand(batch_size, -1, -1)embeddings = torch.cat([cls_tokens, patch_embeddings], dim=1)# 添加位置嵌入embeddings = embeddings + self.position_embeddings# 添加模态类型嵌入(图像模态为0)token_type_ids = torch.zeros(embeddings.shape[:2], dtype=torch.long, device=embeddings.device)embeddings = embeddings + self.token_type_embeddings(token_type_ids)embeddings = self.dropout(embeddings)return embeddings
- 文本嵌入(Text Embedding)
- 输入处理:文本 t ∈ R L × ∣ V ∣ t \in \mathbb{R}^{L \times |V|} t∈RL×∣V∣ 通过词嵌入矩阵 T ∈ R ∣ V ∣ × H T \in \mathbb{R}^{|V| \times H} T∈R∣V∣×H 和位置编码 T pos ∈ R ( L + 1 ) × H T_{\text{pos}} \in \mathbb{R}^{(L+1) \times H} Tpos∈R(L+1)×H 映射为 t ˉ ∈ R L × H \bar{t} \in \mathbb{R}^{L \times H} tˉ∈RL×H。
- 模态类型编码:文本和视觉嵌入分别与模态类型向量 t type , v type ∈ R H t_{\text{type}}, v_{\text{type}} \in \mathbb{R}^H ttype,vtype∈RH 相加,以区分模态来源
class ViltTextEmbeddings(nn.Module):"""VILT的文本嵌入层,处理文本token"""def __init__(self, config):super().__init__()self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)self.token_type_embeddings = nn.Embedding(2, config.hidden_size)self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)self.dropout = nn.Dropout(config.hidden_dropout_prob)def forward(self, input_ids, position_ids=None):seq_length = input_ids.size(1)if position_ids is None:position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)position_ids = position_ids.unsqueeze(0).expand_as(input_ids)# 词嵌入words_embeddings = self.word_embeddings(input_ids)# 位置嵌入position_embeddings = self.position_embeddings(position_ids)# 模态类型嵌入(文本模态为1)token_type_ids = torch.ones_like(input_ids)token_type_embeddings = self.token_type_embeddings(token_type_ids)embeddings = words_embeddings + position_embeddings + token_type_embeddingsembeddings = self.LayerNorm(embeddings)embeddings = self.dropout(embeddings)return embeddings
- 单流 Transformer 交互
- 输入序列:拼接文本和视觉嵌入 z 0 = [ t ˉ + t type ; v ˉ + v type ] z_0 = [\bar{t} + t_{\text{type}}; \bar{v} + v_{\text{type}}] z0=[tˉ+ttype;vˉ+vtype]。
- Transformer 层:通过 D D D 层 Transformer 块更新上下文表示:
z ^ d = MSA ( LN ( z d − 1 ) ) + z d − 1 , d = 1... D (4) z d = MLP ( LN ( z ^ d ) ) + z ^ d , d = 1... D (5) \begin{aligned} \hat{z}_d = \text{MSA}(\text{LN}(z_{d-1})) + z_{d-1}, \quad d = 1...D \quad \text{(4)} \\ z_d = \text{MLP}(\text{LN}(\hat{z}_d)) + \hat{z}_d, \quad d = 1...D \quad \text{(5)} \end{aligned} z^d=MSA(LN(zd−1))+zd−1,d=1...D(4)zd=MLP(LN(z^d))+z^d,d=1...D(5)- Pre-norm vs. Post-norm:ViT 使用 Pre-norm(层归一化在 MSA/MLP 前),而 BERT 使用 Post-norm(层归一化在 MSA/MLP 后)。
- 池化表示:取最终输出 $ z_D $ 的第一个 token(对应
[CLS])并通过线性投影 W pool W_{\text{pool}} Wpool 和tanh激活得到多模态表示 p p p:
p = tanh ( z D 0 W pool ) (6) p = \tanh(z_D^0 W_{\text{pool}}) \quad \text{(6)} p=tanh(zD0Wpool)(6)
大致代码如下:
class ViltMultimodalFusion(nn.Module):"""VILT的核心:多模态融合层使用共享的Transformer来处理图像和文本"""def __init__(self, config):super().__init__()self.config = config# 图像和文本嵌入层self.image_embeddings = ViltImageEmbeddings(config)self.text_embeddings = ViltTextEmbeddings(config)# 共享的Transformer编码器self.encoder = ViltEncoder(config)def forward(self, pixel_values, input_ids, attention_mask=None):# 获取图像嵌入image_embeds = self.image_embeddings(pixel_values)# 获取文本嵌入text_embeds = self.text_embeddings(input_ids)# 拼接图像和文本嵌入multimodal_embeds = torch.cat([image_embeds, text_embeds], dim=1)# 创建注意力掩码if attention_mask is not None:# 为图像部分创建全1的掩码image_mask = torch.ones(image_embeds.shape[:2], dtype=torch.long, device=image_embeds.device)extended_attention_mask = torch.cat([image_mask, attention_mask], dim=1)else:extended_attention_mask = None# 通过共享Transformer编码器encoder_outputs = self.encoder(multimodal_embeds,attention_mask=extended_attention_mask)return encoder_outputs- 模型参数
- 基于预训练的 ViT-B/32(ImageNet 分类任务),具体参数:
- 隐藏维度 H = 768 H = 768 H=768
- Transformer 层数 D = 12 D = 12 D=12
- Patch 大小 P = 32 P = 32 P=32
- MLP 隐藏层大小 = 3072
- 注意力头数 = 12
- 基于预训练的 ViT-B/32(ImageNet 分类任务),具体参数:
3.2 Pre-training Objectives
ViLT 通过两个目标联合训练:
- 图像-文本匹配(Image Text Matching, ITM)
- 任务定义:判断输入的图像和文本是否匹配。
- 实现:
- 50% 概率替换对齐的图像为负样本。
- 使用单层线性分类器(ITM Head)对池化表示 p p p 分类(二分类:匹配/不匹配)。
- 损失函数:负对数似然损失(Negative Log-Likelihood Loss)。
class ITMLoss(nn.Module):"""图像-文本匹配损失"""def __init__(self, config):super().__init__()self.itm_head = nn.Linear(config.hidden_size, 2) # 二分类:匹配/不匹配self.loss_fct = nn.CrossEntropyLoss()def forward(self, pooled_output, labels):"""Args:pooled_output: [CLS] token的池化表示 (batch_size, hidden_size)labels: 0表示不匹配,1表示匹配 (batch_size,)"""# 通过线性分类器得到logitsitm_logits = self.itm_head(pooled_output) # (batch_size, 2)# 计算交叉熵损失itm_loss = self.loss_fct(itm_logits, labels)return itm_loss, itm_logits
def create_negative_samples(images, texts, negative_ratio=0.5):"""创建负样本"""batch_size = images.size(0)labels = torch.ones(batch_size, dtype=torch.long) # 初始都是正样本# 随机选择一半样本作为负样本num_negatives = int(batch_size * negative_ratio)negative_indices = torch.randperm(batch_size)[:num_negatives]# 对选中的样本,随机替换图像for idx in negative_indices:# 随机选择一个不同的图像random_img_idx = torch.randint(0, batch_size, (1,)).item()while random_img_idx == idx:random_img_idx = torch.randint(0, batch_size, (1,)).item()images[idx] = images[random_img_idx]labels[idx] = 0 # 标记为负样本return images, texts, labels```
2. **掩码语言建模(Masked Language Modeling, MLM)** - **任务定义**:预测被掩码的文本 token。 - **实现**: - 15% 概率随机掩码文本 token(遵循 BERT 的启发式策略)。 - 使用两层 MLP 分类器(MLM Head)对掩码位置的上下文表示 $z_D^{\text{masked}|t}$ 预测词汇表概率。 - 损失函数:掩码 token 的负对数似然损失。 大致代码如下:```python
class MLMLoss(nn.Module):"""掩码语言建模损失"""def __init__(self, config):super().__init__()# 两层MLP分类器self.mlm_head = nn.Sequential(nn.Linear(config.hidden_size, config.hidden_size),nn.GELU(),nn.LayerNorm(config.hidden_size),nn.Linear(config.hidden_size, config.vocab_size))self.loss_fct = nn.CrossEntropyLoss(ignore_index=-100)def forward(self, sequence_output, masked_lm_labels):"""Args:sequence_output: Transformer输出 (batch_size, seq_len, hidden_size)masked_lm_labels: 掩码标签,-100表示非掩码位置 (batch_size, seq_len)"""# 只对掩码位置计算损失masked_indices = (masked_lm_labels != -100)if masked_indices.sum() == 0:return torch.tensor(0.0, device=sequence_output.device)# 获取掩码位置的表示masked_output = sequence_output[masked_indices] # (num_masked, hidden_size)# 通过MLM头预测词汇表概率prediction_scores = self.mlm_head(masked_output) # (num_masked, vocab_size)# 获取真实标签masked_labels = masked_lm_labels[masked_indices] # (num_masked,)# 计算交叉熵损失mlm_loss = self.loss_fct(prediction_scores, masked_labels)return mlm_loss, prediction_scoresdef mask_tokens(input_ids, tokenizer, mlm_probability=0.15):"""按照BERT策略掩码tokens- 80%的时间替换为[MASK]- 10%的时间替换为随机token- 10%的时间保持不变"""labels = input_ids.clone()# 创建掩码概率矩阵probability_matrix = torch.full(labels.shape, mlm_probability)special_tokens_mask = [tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()]probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)# 确定哪些token被掩码masked_indices = torch.bernoulli(probability_matrix).bool()labels[~masked_indices] = -100 # 非掩码位置标记为-100# 80%的时间替换为[MASK]indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indicesinput_ids[indices_replaced] = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)# 10%的时间替换为随机tokenindices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replacedrandom_words = torch.randint(len(tokenizer), labels.shape, dtype=torch.long)input_ids[indices_random] = random_words[indices_random]# 剩余10%保持不变return input_ids, labels
- 词-块对齐(Word-Patch Alignment, WPA)
- 动机:增强细粒度跨模态对齐,解决传统区域特征缺失的问题。
- 实现:
- 计算文本子集 z D ∣ t z_D|t zD∣t 和视觉子集 z D ∣ v z_D|v zD∣v 的对齐得分,使用 IPOT 算法(近似最优传输)计算 Wasserstein 距离。
- 超参数设置: β = 0.5 \beta = 0.5 β=0.5, N = 50 N = 50 N=50(参考 Chen et al., 2019)。
- 损失函数:将 IPOT 计算的近似 Wasserstein 距离乘以 0.1 后加入 ITM 损失。
大致代码如下:
class WPALoss(nn.Module):"""词-块对齐损失,使用IPOT算法计算最优传输距离"""def __init__(self, config):super().__init__()self.beta = 0.5 # IPOT算法参数self.max_iter = 50 # 最大迭代次数self.weight = 0.1 # WPA损失权重def forward(self, text_features, visual_features):"""Args:text_features: 文本特征 (batch_size, text_len, hidden_size)visual_features: 视觉特征 (batch_size, patch_len, hidden_size)"""batch_size = text_features.size(0)total_loss = 0.0for i in range(batch_size):# 获取单个样本的特征text_feat = text_features[i] # (text_len, hidden_size)visual_feat = visual_features[i] # (patch_len, hidden_size)# 计算成本矩阵(余弦距离)cost_matrix = self.compute_cost_matrix(text_feat, visual_feat)# 使用IPOT算法计算近似Wasserstein距离wpa_loss = self.ipot_distance(cost_matrix)total_loss += wpa_lossreturn total_loss / batch_size * self.weightdef compute_cost_matrix(self, text_feat, visual_feat):"""计算文本和视觉特征之间的成本矩阵"""# L2归一化text_feat = F.normalize(text_feat, p=2, dim=-1)visual_feat = F.normalize(visual_feat, p=2, dim=-1)# 计算余弦距离矩阵similarity = torch.mm(text_feat, visual_feat.t()) # (text_len, patch_len)cost_matrix = 1.0 - similarity # 转换为距离return cost_matrixdef ipot_distance(self, cost_matrix):"""IPOT算法计算近似最优传输距离参考: Chen et al., 2019"""m, n = cost_matrix.shape# 初始化传输计划T = torch.ones(m, n, device=cost_matrix.device) / (m * n)# 边际分布(均匀分布)mu = torch.ones(m, device=cost_matrix.device) / mnu = torch.ones(n, device=cost_matrix.device) / n# IPOT迭代for _ in range(self.max_iter):# 更新行Q = torch.exp(-cost_matrix / self.beta)T = T * Q# 行归一化row_sum = T.sum(dim=1, keepdim=True)T = T / (row_sum + 1e-8) * mu.unsqueeze(1)# 列归一化col_sum = T.sum(dim=0, keepdim=True)T = T / (col_sum + 1e-8) * nu.unsqueeze(0)# 计算最优传输距离distance = torch.sum(T * cost_matrix)return distancedef sinkhorn_algorithm(cost_matrix, mu, nu, reg=0.1, max_iter=100):"""Sinkhorn算法的替代实现(更稳定)"""m, n = cost_matrix.shape# 初始化对偶变量u = torch.zeros(m, device=cost_matrix.device)v = torch.zeros(n, device=cost_matrix.device)# Sinkhorn迭代for _ in range(max_iter):u_prev = u.clone()# 更新uu = reg * (torch.log(mu + 1e-8) - torch.logsumexp(-cost_matrix / reg + v.unsqueeze(0), dim=1))# 更新vv = reg * (torch.log(nu + 1e-8) - torch.logsumexp(-cost_matrix / reg + u.unsqueeze(1), dim=0))# 检查收敛if torch.norm(u - u_prev) < 1e-6:break# 计算传输计划T = torch.exp((-cost_matrix + u.unsqueeze(1) + v.unsqueeze(0)) / reg)# 计算距离distance = torch.sum(T * cost_matrix)return distance3.3 Whole Word Masking
- 目的:提升模型利用跨模态信息的能力。
- 实现:
- 掩码整个单词的所有子词(如 “giraffe” 的子词 [“gi”, “##raf”, “##fe”] 全部掩码),避免模型依赖局部语言信息。
- 掩码概率:15%。
- 效果:迫使模型必须结合图像信息才能恢复完整单词,增强多模态协同能力。
3.4 Image Augmentation
- 动机:提升视觉嵌入的泛化能力。
- 实现:
- 使用 RandAugment(Cubuk et al., 2020),但去除以下两种操作:
- 颜色反转:文本可能包含颜色信息。
- Cutout:可能遮挡图像中的小物体。
- 超参数: N = 2 N = 2 N=2(增强策略数量), M = 9 M = 9 M=9(增强强度)。
- 使用 RandAugment(Cubuk et al., 2020),但去除以下两种操作:
- 对比传统方法:
- 区域特征模型(如 Faster R-CNN)无法灵活应用数据增强。
- ViLT 的线性嵌入支持端到端增强,提升训练效果。
总结:ViLT 的创新点
- 极简视觉嵌入:用线性投影替代 CNN,推理速度达 15 ms。
- 单流 Transformer:统一处理多模态信息,减少冗余计算。
- 跨模态对齐增强:WPA 损失 + Whole Word Masking 提升细粒度交互能力。
- 端到端增强:支持图像数据增强,提升泛化性能。
ViLT 通过简化视觉嵌入流程,在保持高性能的同时显著降低了计算成本,为轻量级视觉-语言模型提供了新范式。