NodeRAG: 基于异构节点的基于图的RAG结构
开源代码: https://github.com/Terry-Xu-666/NodeRAG
传统的RAG常常面临内容碎片化和冗余信息的问题。基于图的RAG在这方面有所改进,但其简单的图结构在捕捉复杂含义时显得不足。
这就是NodeRAG的用武之地——通过结合异构节点和图算法,它重建知识表示,使RAG更智能、更精确、结构更合理。
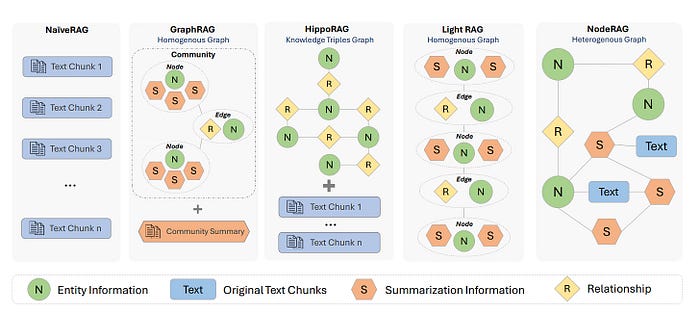
图1:NodeRAG与其他RAG系统的比较。
[来源]。
如图1所示:
- NaïveRAG检索碎片化的文本块,常常导致冗余信息。
- HippoRAG引入知识图谱,但在高层次总结方面表现不佳。
- GraphRAG试图通过检索社区摘要来解决这个问题,但结果仍然显得过于宽泛。
- LightRAG结合了一跳邻居,这在上下文中有所帮助,但也检索了冗余节点。
- NodeRAG采取了不同的方法——通过使用多种类型的节点,如高层次元素、语义单元和关系,它实现了更精确的分层检索,同时减少了无关信息。
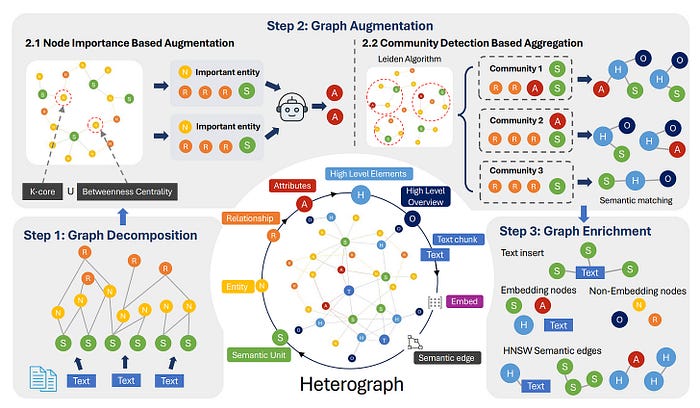
图2:NodeRAG的主要索引工作流程。
[来源]。
一种以图为中心的框架,通过引入异构图结构来解决RAG方法中的图结构设计问题
图2分解了NodeRAG如何在三个明确的步骤中构建其异构图索引:
异构图定义:异构图将信息全面展开并扁平化,形成一个完全节点化的结构。该结构通过整合七种异构节点类型来实现细粒度的分解:实体(N)、关系(R)、语义单元(S)、属性(A)、高层元素(H)、高层概览(O)和文本(T)。
- 图分解: 该过程首先使用LLM将文本分割为三种核心节点类型:语义单元(S)、实体(N)和关系(R)。
- 图增强: 接下来,它识别关键节点——如核心实体——并创建属性节点(A)以突出其重要性。它还进行社区检测,以提取高层次见解,生成摘要节点(H)和标题节点(O)。
- 图丰富: 最后,它引入原始文本(T)以保留细节,并使用HNSW添加语义相似性边,使图在检索时更强大和精确。
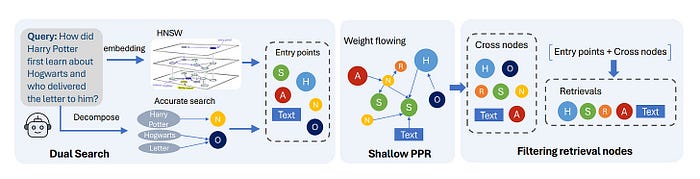
图3:查询过程,其中从原始查询中提取入口点,然后搜索需要在异构图中检索的相关节点。
[来源]。
图3说明了NodeRAG如何通过简化的三步过程处理查询:
- 双重搜索: 它首先从查询中提取实体和语义线索。然后,它将精确匹配(在N/O节点上)与向量相似性搜索(在S/A/H节点上)结合,以确定最相关的入口节点。
- 浅层个性化PageRank(PPR): 从这些入口点,NodeRAG执行轻量级图扩散,以发现图中语义相关的节点。
- 过滤检索节点: 在最后一步中,它过滤掉无关节点,仅保留有意义的节点——T、S、A、H和R节点——以形成最终结果集。
这个过程结合了结构感知和语义搜索,提供了更相关、更细致且噪声更少的结果。
问题1:NodeRAG在图结构设计方面有哪些创新之处?
NodeRAG在图结构设计方面的创新主要体现在引入了异构图(Heterograph),这是一种全面展开并扁平化的信息结构,包含七种异构节点类型:实体(N)、关系(R)、语义单元(S)、属性(A)、高层元素(H)、高层概览(O)和文本(T)。这种设计使得NodeRAG能够实现细粒度的信息分解和功能区分,从而提高检索和问答的精度和效率。具体来说,异构图不仅保留了原始文本的信息,还扩展了信息范围,包含了关键节点的属性和高层次的发现。此外,NodeRAG还通过基于节点重要性的增强和社区检测基于的聚合方法,进一步优化了图结构,提升了整体性能。
问题2:NodeRAG在图搜索过程中采用了哪些关键技术?这些技术如何提高检索效率?
NodeRAG在图搜索过程中采用了双重搜索机制和浅层个性化PageRank(PPR)算法。双重搜索机制结合了精确匹配和向量相似性搜索,首先通过精确匹配找到结构化节点(如标题节点),然后通过向量相似性搜索找到富信息节点(如包含丰富上下文的节点)。这种方法既保证了检索的精度,又提高了召回率。浅层个性化PageRank算法则通过模拟有偏随机游走,从入口点开始逐步扩展,提取与入口点相关的多跳节点。通过限制迭代次数,浅层PPR能够在保证相关性的同时减少计算开销,提高检索效率。最终,结合入口点和交叉节点过滤产生最终的检索结果,确保检索结果的准确性和高效性。
问题3:NodeRAG在多跳推理和开放式检索任务中表现如何?与其他方法相比有哪些优势?
NodeRAG在多跳推理和开放式检索任务中表现出色。在多跳推理基准测试(如HotpotQA、MuSiQue和MultiHop-RAG)中,NodeRAG一致优于现有的GraphRAG、LightRAG、NaiveRAG和HyDE方法,显示出最高的准确性,同时检索的令牌数明显较少。例如,在MuSiQue上,NodeRAG的准确率为46.29%,超过了GraphRAG的41.71%和LightRAG的36.00%。在开放式检索任务(如RAG-QA Arena)中,NodeRAG在所有六个领域中均实现了最高的胜率,显著高于其他方法。此外,NodeRAG在索引时间、存储使用、查询时间和检索令牌方面均表现出优越的系统级效率,特别是在索引时间上显著优于其他方法,这归因于其异构图的构建过程,不仅创建了更细粒度和语义上有意义的图结构,还仔细考虑了检索过程的算法复杂性。
NodeRAG 是一个基于异质图(Heterogeneous Graph)的检索增强生成(RAG, Retrieval-Augmented Generation)系统,旨在通过结构化的图模型优化信息检索与生成过程。以下是对该仓库的详细介绍:
项目代码走读
根据代码与 README 信息,NodeRAG 的核心功能包括:
-
异质图结构增强
引入包含语义单元(Text Units)、实体(Entities)、关系(Relationships)、属性(Attributes)、高层元素(High-Level Elements)等多类型节点的异质图,强化图结构对复杂信息的表达能力。 -
细粒度可解释检索
通过图结构的节点类型区分(如semantic_unit、entity、attribute等),支持精准的上下文感知检索,并通过图边关系(如weight属性)提供检索结果的可解释性。 -
统一信息检索与存储
整合原始数据(如文档)与提取的知识(如实体、属性)为图中互联节点,避免分层存储,支持无缝的增量更新(通过storage模块的append方法实现)。 -
高效性能优化
通过统一算法(如 KMeans 聚类构建高层元素)和优化实现(如并行化的嵌入生成、异步任务处理),提升图构建与检索速度。 -
增量图更新
支持对异质图的动态更新(如添加新节点、边权重调整),适应动态变化的数据源。
模块结构
仓库代码结构清晰,核心模块包括:
1. 异质图存储模块(storage/storage.py)
该模块负责异质图数据的持久化存储与管理,核心是 Storage 类和 Mapper 类,支持多格式存储(JSON/Parquet/CSV 等)和动态节点映射。
提供多格式数据的存储与加载功能,支持 JSON、Parquet、Pickle、CSV 等格式,包含:
storage类:封装save_*/load_*方法(如save_json、load_parquet),支持追加模式(append=True)。Mapper类:管理图节点与数据源(如 Parquet 文件)的映射关系,支持动态添加/删除数据源。genid工具:生成节点唯一 ID(支持 MD5、SHA256、UUID 等哈希方式)。
1.1 Storage 类:数据存储与加载
Storage 类通过统一接口封装不同格式的存储操作,核心方法包括 save、load 和 append,支持增量更新。以下是关键代码逻辑:
# storage/storage.py(核心简化版)
class Storage:def __init__(self, base_path: str):self.base_path = Path(base_path) # 存储根路径self._formats = { # 支持的存储格式与对应方法"json": (self._save_json, self._load_json),"parquet": (self._save_parquet, self._load_parquet),"csv": (self._save_csv, self._load_csv)}def save(self, data: dict, name: str, format: str = "json"):"""保存数据到指定格式文件"""save_func, _ = self._formats[format]file_path = self.base_path / f"{name}.{format}"save_func(file_path, data)def load(self, name: str, format: str = "json") -> dict:"""从指定格式文件加载数据"""_, load_func = self._formats[format]file_path = self.base_path / f"{name}.{format}"return load_func(file_path)def append(self, data: dict, name: str, format: str = "json"):"""增量追加数据(仅支持 JSON/Parquet)"""if format == "json":existing_data = self.load(name, format) if self.exists(name, format) else []existing_data.extend(data)self.save(existing_data, name, format)elif format == "parquet":# 使用 pandas 追加到 Parquet(需注意模式兼容)df = pd.DataFrame(data)df.to_parquet(self.base_path / f"{name}.parquet", append=True)else:raise ValueError(f"不支持增量追加到 {format} 格式")
关键设计点:
- 多格式兼容:通过
_formats字典注册不同存储格式的读写方法,灵活扩展(如后续添加sqlite格式)。 - 增量更新:
append方法支持动态添加新数据(如新增文档时无需重建整个图),适合动态知识库场景。
1.2 Mapper 类:节点与数据源映射
Mapper 管理图节点(如 semantic_unit、entity)与原始数据源(如文档路径)的映射关系,确保检索时能快速定位原始内容。关键代码如下:
# storage/mapper.py
class Mapper:def __init__(self):self.node_to_source = {} # {node_id: (source_type, source_path)}self.source_to_nodes = defaultdict(list) # {source_path: [node_ids]}def add_node(self, node_id: str, source_type: str, source_path: str):"""添加节点与数据源的映射"""self.node_to_source[node_id] = (source_type, source_path)self.source_to_nodes[source_path].append(node_id)def get_source(self, node_id: str) -> tuple:"""根据节点 ID 获取原始数据源"""return self.node_to_source.get(node_id, (None, None))def get_nodes_by_source(self, source_path: str) -> list:"""根据数据源路径获取关联的节点 ID"""return self.source_to_nodes.get(source_path, [])
关键设计点:
- 双向映射:通过
node_to_source和source_to_nodes实现节点与数据源的双向查询,支持“从节点回溯原文”或“从原文定位相关节点”。
2. 构建流水线(build/pipeline)
包含图构建的核心流程,覆盖文档处理、属性生成、摘要生成、嵌入计算等步骤:
- 文档流水线(
document_pipeline):将文档拆分为文本单元(Text Units)并存储。 - 属性生成(
attribute_generation):通过图节点重要性分析(K-core、介数中心性)筛选关键节点,生成属性并关联到图。 - 摘要生成(
summary_generation):基于图社区划分(Modularity 分区)生成社区摘要,构建高层元素(High-Level Elements)并关联到原始节点。 - 嵌入计算(
embedding):异步调用 LLM 生成节点嵌入并缓存。
2.1 文本单元拆分(document_pipeline)
将长文档拆分为细粒度的“文本单元”(如段落、句子),作为图的基础节点(semantic_unit 类型)。关键代码逻辑:
# build/pipeline.py(文档拆分简化版)
def document_pipeline(documents: list[Document], chunk_size: int = 512) -> list[Node]:"""将文档拆分为文本单元节点"""nodes = []for doc in documents:text = doc.content# 按 token 数量拆分(使用 Tiktoken 分词)tokenizer = get_tokenizer("cl100k_base") # OpenAI 分词器tokens = tokenizer.encode(text)chunks = [tokens[i:i+chunk_size] for i in range(0, len(tokens), chunk_size)]# 生成文本单元节点for i, chunk_tokens in enumerate(chunks):chunk_text = tokenizer.decode(chunk_tokens)node_id = genid(chunk_text, method="md5") # 基于内容生成唯一 IDnodes.append(Node(id=node_id,type="semantic_unit",content=chunk_text,metadata={"source": doc.path, "chunk_idx": i}))return nodes
关键设计点:
- 细粒度拆分:基于 token 数量(而非字符数)拆分,确保每个文本单元长度适配 LLM 输入限制(如 512 token)。
- 内容唯一 ID:通过
genid工具(如 MD5 哈希)生成节点 ID,避免重复内容生成重复节点。
2.2 属性生成(attribute_generation)
通过图算法(如 K-core、介数中心性)筛选关键节点,生成其属性(如实体、时间、数值),并关联到图中。关键代码逻辑:
# build/attribute_generation.py(简化版)
def generate_attributes(graph: Graph, top_k: int = 20) -> list[Node]:"""为关键节点生成属性"""# 计算节点重要性(K-core 分解)core_numbers = graph.compute_k_core()# 筛选 top K 重要节点important_nodes = sorted(graph.nodes, key=lambda n: core_numbers[n.id], reverse=True)[:top_k]# 调用 LLM 生成属性(如实体抽取)llm_client = LLMClient() # 预初始化的 LLM 客户端attributes = []for node in important_nodes:prompt = f"提取以下文本中的实体和关键属性:{node.content}"response = llm_client.generate(prompt, max_tokens=100)# 解析 LLM 输出为属性节点for attr in parse_attributes(response): # 自定义解析函数attr_node = Node(id=genid(attr["name"]),type="attribute",content=attr["value"],metadata={"parent_id": node.id, "name": attr["name"]})attributes.append(attr_node)return attributes
关键设计点:
- 重要性筛选:通过 K-core 等图算法减少冗余计算,仅对高重要性节点生成属性,提升效率。
- LLM 集成:利用 LLM 的语义理解能力自动抽取属性,降低人工标注成本。
3. 检索模块(search)
提供检索结果的结构化处理,包含 Retrieval 类,支持:
- HNSW(近似最近邻)检索结果与精确检索结果的融合。
- 检索结果按类型(如
entity、relationship)分类整理,生成结构化提示词(structured_prompt)和非结构化文本(unstructured_prompt)。
3.1 多策略检索融合
Retrieval 类支持 HNSW(近似最近邻)检索与精确检索的融合,提升召回率和准确性。关键代码逻辑:
# search/retrieval.py(简化版)
class Retrieval:def __init__(self, graph: Graph, embedding_model: str = "text-embedding-ada-002"):self.graph = graphself.embedding_model = embedding_modelself.hnsw_index = HNSWIndex(dim=1536) # OpenAI 嵌入维度def search(self, query: str, top_k: int = 5) -> list[Node]:"""融合 HNSW 和精确检索的混合搜索"""# 1. 生成查询嵌入query_embedding = self._get_embedding(query)# 2. HNSW 近似检索(快速召回)hnsw_results = self.hnsw_index.search(query_embedding, top_k=10)# 3. 精确检索(基于文本相似度)exact_results = self._exact_search(query, top_k=5)# 4. 融合结果(按分数加权)merged = self._merge_results(hnsw_results, exact_results)return merged[:top_k]def _exact_search(self, query: str, top_k: int) -> list[Node]:"""基于 BM25 或余弦相似度的精确检索"""# 计算查询与所有节点的文本相似度similarities = [cos_sim(query, node.content) for node in self.graph.nodes]# 按相似度排序并返回前 top_kreturn sorted(zip(self.graph.nodes, similarities), key=lambda x: x[1], reverse=True)[:top_k]
关键设计点:
- 混合检索:HNSW 提供快速近似召回,精确检索(如 BM25、余弦相似度)保证准确性,平衡效率与效果。
3.2 结构化提示词生成
检索结果按节点类型(如 semantic_unit、entity)分类,生成适合 LLM 的结构化提示词。关键代码:
# search/retrieval.py(提示词生成)
def generate_prompt(self, results: list[Node]) -> str:"""根据检索结果生成结构化提示词"""structured = {"semantic_units": [],"entities": [],"attributes": []}for node in results:if node.type == "semantic_unit":structured["semantic_units"].append(node.content)elif node.type == "entity":structured["entities"].append(f"{node.content}(ID: {node.id})")elif node.type == "attribute":structured["attributes"].append(f"{node.metadata['name']}: {node.content}")# 拼接为 LLM 友好的提示词prompt = "以下是与查询相关的信息:\n"prompt += "文本单元:\n" + "\n".join(structured["semantic_units"]) + "\n"prompt += "实体:\n" + "\n".join(structured["entities"]) + "\n"prompt += "属性:\n" + "\n".join(structured["attributes"]) + "\n"prompt += "请根据以上信息回答问题:"return prompt
关键设计点:
- 类型区分:将结果按节点类型分类,避免 LLM 处理冗余信息,提升生成准确性。
4. LLM 集成(LLM)
封装大语言模型(如 OpenAI)的嵌入生成接口,支持同步/异步调用,并包含速率限制与错误重试机制(通过 backoff 库实现)。
5. 工具与配置(utils、config)
lazy_import:延迟导入模块,优化启动速度。yaml_operation:YAML 配置文件的读写与嵌套更新。token_utils:基于 Tiktoken 的令牌计数,用于提示词长度限制。NodeConfig:系统核心配置,管理路径、LLM 客户端、跟踪器(Tracker)等。
快速使用
根据 README,NodeRAG 的基础使用流程如下:
- 环境准备:通过 Conda 创建 Python 3.10+ 环境。
- 安装:使用
uv(加速工具)或pip安装 NodeRAG。 - 索引构建:通过文档流水线处理原始数据,生成文本单元、实体、关系等图节点。
- 检索与生成:基于构建的异质图,通过检索模块获取相关信息,结合 LLM 生成答案。
适用场景
NodeRAG 适用于需要结构化信息支持的 RAG 任务,例如:
- 文档问答(支持细粒度文本单元与高层摘要的联合检索)。
- 知识图谱增强生成(通过实体、属性、关系的图结构提供上下文)。
- 动态知识库维护(支持增量图更新,适应数据实时变化)。
思考与见解
我们在过去讨论了许多图RAG的改进,NodeRAG走了一条不同的道路。它的重点是构建更详细的图结构,并整合经典的图算法,如PPR和K-core。换句话说,NodeRAG将图本身置于系统的中心——将结构视为不仅仅是存储格式,而是理解知识的关键。
当然,由于NodeRAG在传统RAG的基础上更深入地使用图算法,它自然带来了额外的复杂性和新的挑战——特别是在结构和鲁棒性方面。两个领域,尤其需要更严格的控制和验证:如何使用LLM构建语义结构,以及图扩散算法在语义上的表现如何。
这些不仅仅是技术细节——它们是真实的障碍,需要在图增强RAG更接近实际应用时加以解决。