基于 ColBERT 框架的后交互 (late interaction) 模型速递:Reason-ModernColBERT
一、Reason-ModernColBERT 模型概述
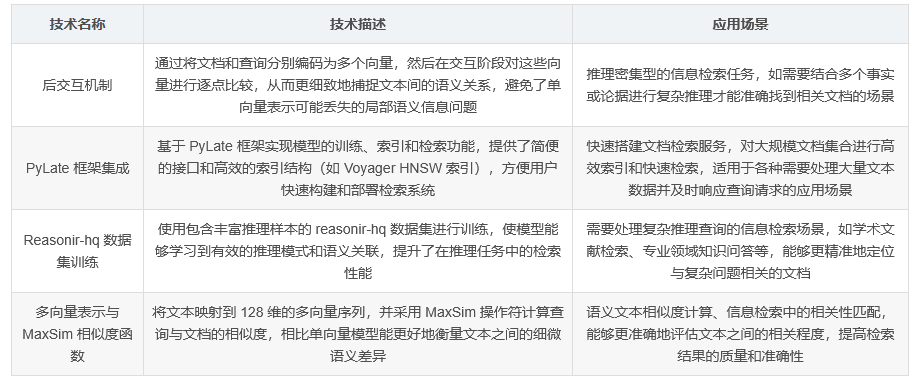
Reason-ModernColBERT 是一种基于 ColBERT 框架的后交互 (late interaction) 模型,专为信息检索任务中的推理密集型场景设计。该模型在 reasonir-hq 数据集上进行训练,于 BRIGHT 基准测试中取得了极具竞争力的性能表现。具体来说,它超越了所有尺寸达到 7B(其自身尺寸的 45 倍以上)的现有模型,并在 Stack Exchange 分割中平均提升了 ReasonIR-8B(基于相同数据训练的 8B 模型)的 NDCG@10 性能指标达 2.5 以上。据研究人员认为,这种出色的结果应归功于其后交互机制,与通常由其他模型执行的密集(单向量)检索相比,后交互方式能更有效地处理复杂推理任务。
二、模型使用方法
(一)环境准备
首先,需要安装 PyLate 库,该库提供了与 ColBERT 模型相关的便捷接口。通过运行 “pip install -U pylate” 命令即可完成安装。
(二)文档索引与检索
-
加载 ColBERT 模型并初始化 Voyager 索引。指定模型路径,然后创建索引实例,可选择是否覆盖已有索引。
-
编码并索引文档。将文档文本及其标识符输入模型,生成文档嵌入向量,并将其添加到索引中。
-
检索文档。初始化 ColBERT 检索器,编码查询文本,然后检索出与查询最相关的前 k 个文档,获取其标识符和相关性分数。
(三)重排序
若不想构建索引,仅利用 ColBERT 模型在初始检索流程的基础上进行重排序,可直接使用 rank 函数。对查询和文档进行编码后,将文档标识符、查询嵌入向量和文档嵌入向量输入 rerank 函数,即可获得重排序后的文档列表。
三、模型评估
(一)BRIGHT 基准测试表现
BRIGHT 基准测试聚焦于评估模型在推理密集型检索任务中的性能。Reason-ModernColBERT 在测试中各个领域(如生物学、地球科学、经济学、心理学、机器人学、Stackoverflow、可持续发展等)的成绩均优于众多模型,包括不同规模的开源模型和部分专有模型,甚至在多个领域的平均表现超越了同数据集训练的 8B 模型 ReasonIR-8B。
(二)与密集模型的比较
为了验证 Reason-ModernColBERT 的性能提升是否仅仅是由于其使用了 ReasonIR 数据,研究人员进行了对比实验。他们采用 Sentence Transformers 训练了一个密集(单向量)模型,并与 Reason-ModernColBERT(多向量、后交互模型)进行比较。结果显示,在相同设置下,Reason-ModernColBERT 的性能远超密集模型,这说明其后交互机制对提升性能起到了关键作用,而不仅仅依赖于数据本身。
四、模型训练细节
(一)训练数据集
Reason-ModernColBERT 基于 reasonir-hq 数据集进行训练。该数据集包含 100,521 个训练样本,每个样本包括 “query”(查询)、“pos”(正样本)和 “neg”(负样本)三个列。据统计,在前 1,000 个样本中,查询的最小、平均、最大 tokens 数分别为 38、97.84、128,正样本的最小、平均、最大 tokens 数分别为 85、127.63、128,负样本的最小、平均、最大值分别为 8、暂未明确、1。
(二)模型架构
该模型的架构基于 ColBERT,包含一个 Transformer 组件和一个密集层。Transformer 组件负责对输入文本进行编码,生成高维表示;密集层则将编码后的表示映射到 128 维的密集向量空间,以便用于语义文本相似度计算。
以下是 Reason-ModernColBERT 的核心技术汇总表格: