C++学习之STL学习:string类使用
在之前的学习中,我们初步了解到了STL的概念,接下来我们将深入学习STL中的string类的使用,后续还会结合他们的功能进行模拟实验
目录
为什么要学习string类?
标准库中的string类
string类(了解)
auto和范围for
auto关键字
关于 typeid(b).name() 的解析
auto真正的应用
范围for
string常用接口说明
string的构造方式
string的析构 编辑
string=运算符重载
string类对象的容量操作
size
length
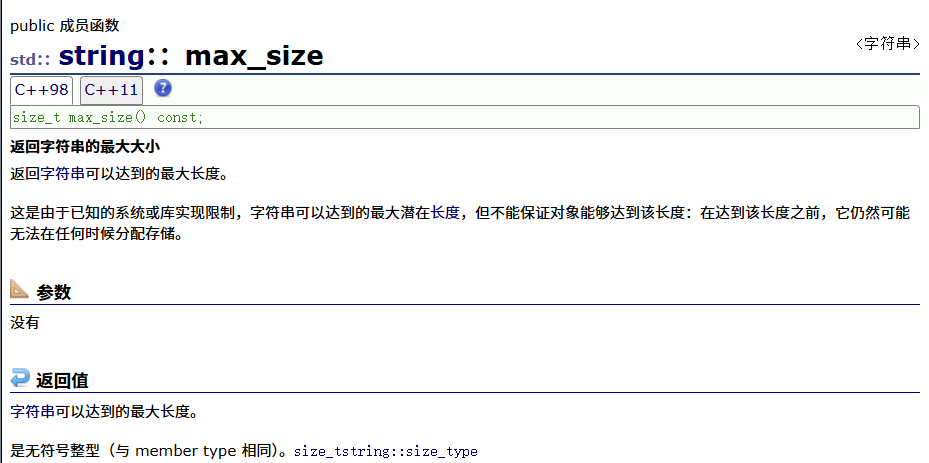
max-size
capacity
clear
empty
shrink_to_fit
reserve
resize
迭代器
迭代器分类
正向迭代器
反向迭代器
const迭代器
const反向迭代器
总源代码为:
迭代器失效问题
迭代器的作用
迭代器的意义:
string的遍历
一、运算符重载介绍
operator[]
at
back
front
二、迭代器
三、范围for (C++11)
string类对象的修改操作
push back
pop back
operator+=
append
assign
insert
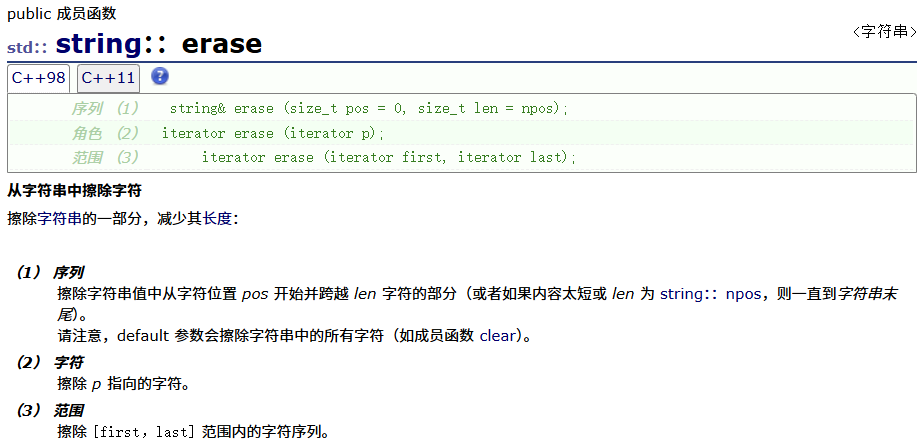
erase
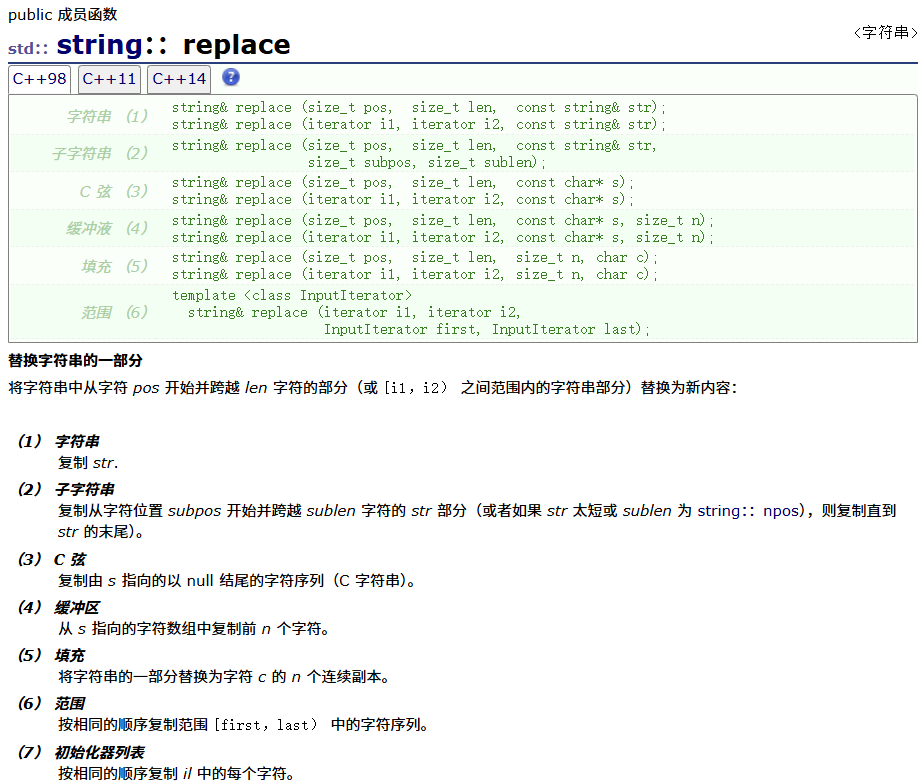
replace
swap
string类的操作
c_str
data 编辑
get_allocator
copy
substr
find
rfind
find_first_of
find_last_of
find_first_not_of
find_last_not_of
编辑 compare
string的成员常量:npos
string类非成员函数
operator+
operator>>(重点)
operator<<(重点)
getline(重点)
relation operators(重点)
swap
一些string类的例题
1、字符串相加
2.仅仅反转字母
3.查找字符串中第一个唯一的字符
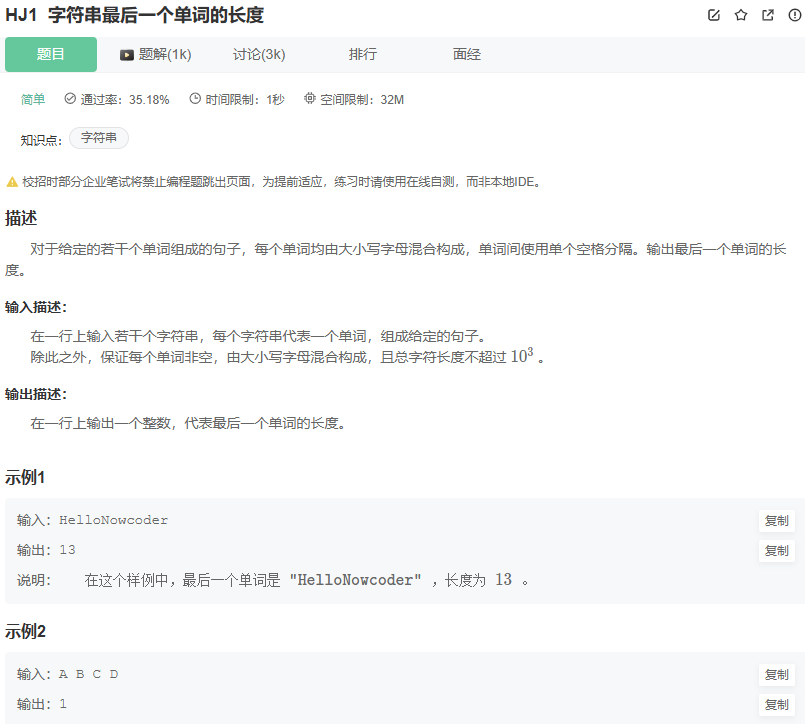
4.字符串最后一个单词的长度
5.验证回文字符串
VS和g++下string结构的说明
VS下string结构说明
string下string结构说明
为什么要学习string类?
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
标准库中的string类
string类(了解)
官方string类的介绍文档:
<string> - C++ 参考
string - C++ 参考
在使用string类的时候,必须要包含头文件<string.h>以及
using namespace stdauto和范围for
auto关键字
早期C/C++中auto的含义是:使用auto修饰的变量是具有自动储存器的局部变量,后来这个不重要了。在C++11 中auto有了全新的含义:auto不再是一个储存类型的指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
用auto声明指针类型时,用auto和auto*没有任何区别,但是用auto声明引用类型时候必须加&,否则只是拷贝而无法通过它去改变指向的值
int main(){int x = 10;auto y = x;auto *z= &x;auto& m = x;cout<<typeid(y).name()<<endl;cout<<typeid(z).name()<<endl;cout<<typeid(m).name()<<endl;return 0;}这么写也可以
auto p1=&x;
auto* p2=&x;但是不可以这么写
auto *p2=x;当同一行声明多个变量的时候,这些变量必须是相同类型的,否则编译器会报错。因为编译器实际上只对第一个类型进行推导,然后用推导出来的类型去定义其他变量
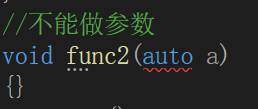
auto不能作为函数的参数,可以做返回值,但是建议谨慎使用
#include <iostream>
using namespace std;
int func1()
{return 10;
}
//不能做参数
void func2(auto a)
{}
//可以做返回值但是谨慎使用
auto func3()
{return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = func1();//编译错误:“e”包含类型“auto”必须要有初始值auto e;cout<<typeid(b).name()<<endl;cout<<typeid(c).name()<<endl;cout<<typeid(d).name()<<endl;return 0;
}
auto不能直接声明数组
int main()
{auto aa = 1, bb = 2;//编译错误:声明符列表中,“auto”必须始终推到为同一类型auto cc = 3, dd = 4.0;//编译错误:不能将“auto[]”用作函数参数类型auto arr[] ={4,5,6};return 0;
}关于 typeid(b).name() 的解析
typeid(b):
使用 typeid 运算符获取变量 b 的类型信息,返回一个 std::type_info 对象的常量引用。
作用:在运行时(RTTI,Run-Time Type Information)或编译时获取类型信息。
头文件:需包含 <typeinfo>。
.name():
std::type_info 的成员函数,返回一个表示类型名称的字符串(格式取决于编译器实现)。
输出示例:
GCC/Clang:i(表示 int)
MSVC:intcout << ... << endl:
输出 typeid(b).name() 返回的字符串,并换行
auto真正的应用
#include <iostream>
#include<string>
#include<map>
using namespace std;
int main()
{std::map<std::string, std::string> dict = { {"apple","苹果"},{"orange","橘子"},{"pear","梨"}};//auto的应用//std::map<std::string, std::string>::iterator it = dict.begin();auto it =dict.begin();while (it != dict.end()){cout<<it->first<<" "<<it->second<<endl;++it;}return 0;
}范围for
对于有范围的集合而言,程序员说明循环的范围是多余的,有时候还会容易犯错误。因此C++11引入了基于范围的for循环。for循环后括号由冒号“:”分为两部分:第一部分是范围用于迭代的变量,第二部分则表示被迭代的范围,自动迭代自动取数据,自动判断结束
范围for可以作用到数组和容器对象上遍历。
范围for的底层很简单,容器遍历实际上就是替换为迭代器,从汇编也可以看到
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main()
{int arr[] = {1,2,3,4,5};C++98的遍历//for (int i = 0;i < sizeof(arr) / sizeof(arr[0]);i++)//{// cout<<arr[i]<<endl;//}//C++11的遍历for (auto& e : arr){e *= 2;}for (auto&e : arr){cout<<e<<" " << endl;}string str("hello world");for (auto ch : str){cout<<ch<<" ";}cout<<endl;return 0;
}string常用接口说明
string的构造方式

他们的特点分别为:

| (constructor)构造函数名称 | 功能说明 |
| string(重点) | 构造空的string类,即空字符串 |
| string(const char*s)(重点) | 用C-string来构造string类对象 |
| string(size_t n,char c) | string类对象包含n个字符c |
| string(const string &s)(重点) | 拷贝构造函数 |
一个简单的string程序
#include <iostream>
#include<string>
using namespace std;
void test()
{//最常见的两种string构造方式string s1; //构造空字符串string s2 = "hello world"; //构造常量字符串string s3(s2); //拷贝构造string s4(s2, 1, 5); //从s2中构造子串string s5(s2, 1, 50);string s6(s2, 1);const char* str = "hello world";//常量字符串string s7(str, 5); //从常量字符串构造string s8(100,'#'); //从常量字符串构造cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;cout << s4 << endl;cout << s5 << endl;cout << s6 << endl;cout << s7 << endl;cout << s8 << endl;
}
int main()
{test();return 0;
}结果为:

string的析构 
string=运算符重载
string的=运算符重载有以下三种
作用是字符串赋值,即为字符串分配一个新值,替换其当前内容。
参数为:
返回的是this指针
string类对象的容量操作
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty(重点) | 检测字符串释放为空串,是返回true,否返回false |
| clear(重点) | 清空有效字符 |
| reserve(重点) | 给字符串预留空间 |
| resize(重点) | 讲有效字符的个数改成n个,多出的空间用字符c填充 |
| shrink_to_fit | 给字符串缩容以适配合适的大小 |
参考文献:string - C++ 参考
以下进行介绍
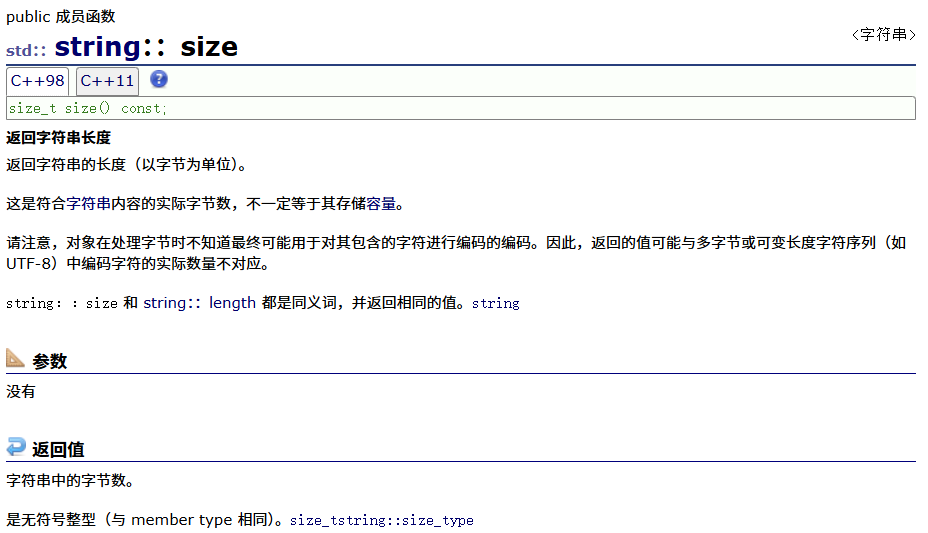
size
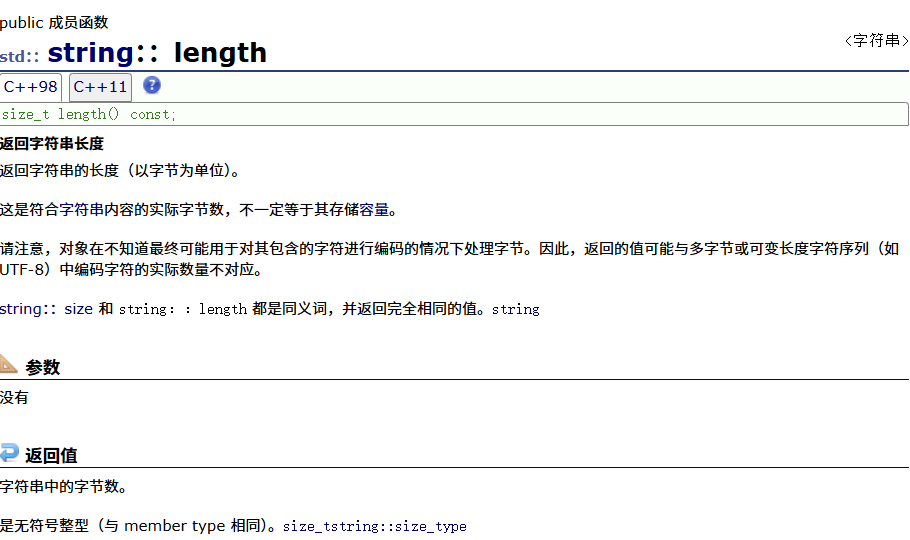
length
max-size
max_size的结果取决于编译器,且其值在应用中意义不大,仅具有理论的价值
capacity
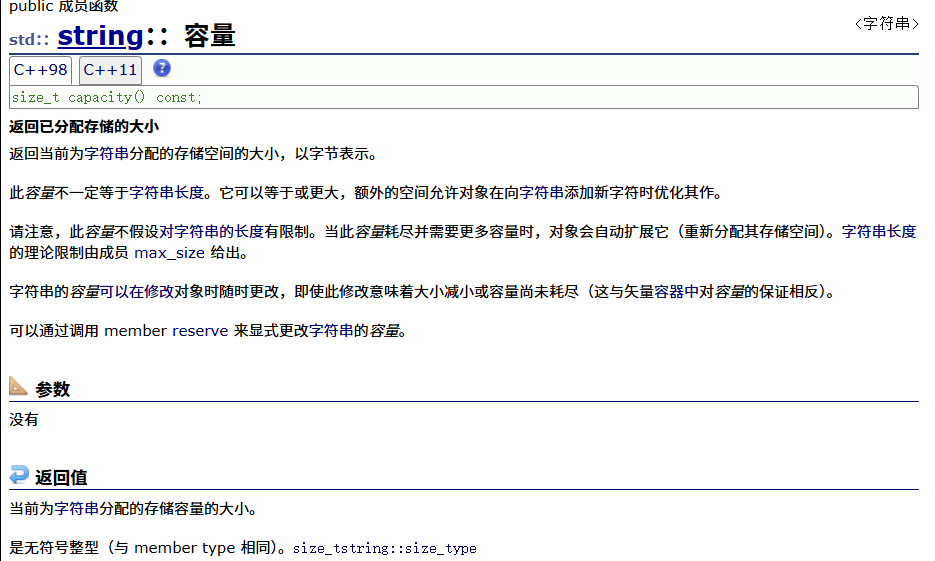
size与capacity均不包含'\0'
代码举例:
#include<iostream>
using namespace std;
void string_test2()
{string s1("1234567");//size与capacity均不包含'\0'cout<<s1.size()<<endl;cout<<s1.length()<<endl;
}
int main()
{//string_test1();string_test2();return 0;
}结果为:
![]()
capacity的扩容
#include<iostream>
using namespace std;
void string_test2()
{string s2;size_t old = s2.capacity();cout<<"初始容量:"<<old<<endl;for (size_t i=0;i<50;i++){s2.push_back('a');if (s2.capacity() != old){cout<<"s2.capacity():" <<s2.capacity() << endl;old = s2.capacity();}}
}
int main()
{string_test2();return 0;
}结果为:
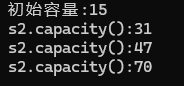
结论:除了第一次扩容为2倍,后续均为1.5倍的扩容
但是在Linux系统的g++编译器上,该扩容均为2倍扩容
clear
-
#include<iostream>
using namespace std;
void string_test2()
{string s1("1234567");cout<<s1.size()<<endl;cout<<s1.length()<<endl;cout << s1 << endl;s1.clear();cout << s1 << endl;
}
int main()
{ string_test2();return 0;
}结果为:
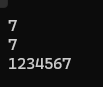
可以看到,s1 只打印了一次,第二次已经被清空了
clear只会清楚size的内存,一般不会改变capacity的内存
#include<iostream>
using namespace std;
void string_test2()
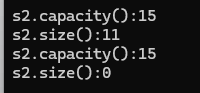
{string s2("hello world");size_t old = s2.capacity();cout << "s2.capacity():" << s2.capacity() << endl;cout << "s2.size():" << s2.size() << endl;//clear只清理size,一般不变capacity的内存s2.clear();cout << "s2.capacity():" << s2.capacity() << endl;cout << "s2.size():" << s2.size() << endl;
}
int main()
{ string_test2();return 0;
}结果为:
empty

#include<iostream>
using namespace std;
void string_test2()
{string s1("1234567");cout<<s1.size()<<endl;cout<<s1.length()<<endl;cout << s1 << endl;s1.clear();cout << s1 << endl;if (s1.empty() == true){cout<<"s1 is empty"<<endl;}
}
int main()
{ string_test2();return 0;
}结果为:
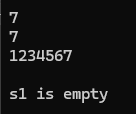
shrink_to_fit
缩容的代价很大
缩容的本质是异地创建一个新的空间,放弃所有没有应用的空间。然后存入其中,是一种以时间换空间的行为
reserve
扩容接口
#include<iostream>
using namespace std;
void string_test2()
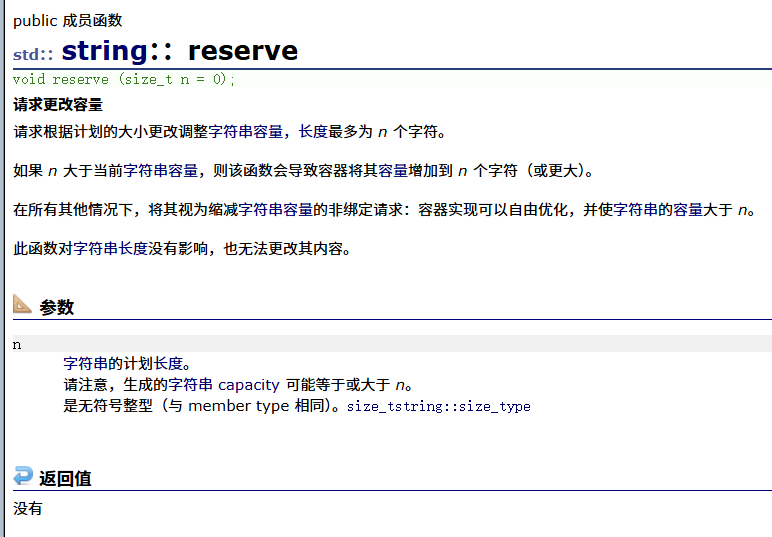
{string s2("hello world");size_t old = s2.capacity(); cout << "s2.capacity():" << s2.capacity() << endl;cout << "s2.size():" << s2.size() << endl;s2.reserve(100);cout << "s2.capacity()经过reserve后:" << s2.capacity() << endl;
}
int main()
{ string_test2();return 0;
}结果为:
避免扩容的做法
#include<iostream>
using namespace std;
void string_test2()
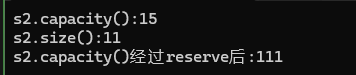
{string s2("hello world");s2.reserve(100);size_t old = s2.capacity();cout << "初始容量:" << old << endl;for (size_t i = 0;i < 50;i++){s2.push_back('a');if (s2.capacity() != old){cout << "s2.capacity():" << s2.capacity() << endl;old = s2.capacity();}}cout << "s2.capacity():" << s2.capacity() << endl;cout << "s2.size():" << s2.size() << endl;
}
int main()
{ string_test2();return 0;
}结果为;
应用场景:确定知道需要多少空间,提前开好,避免扩容,提高效率
但是reserve对缩容没有强制规定(g++可能缩容但是不按照预想的缩容)
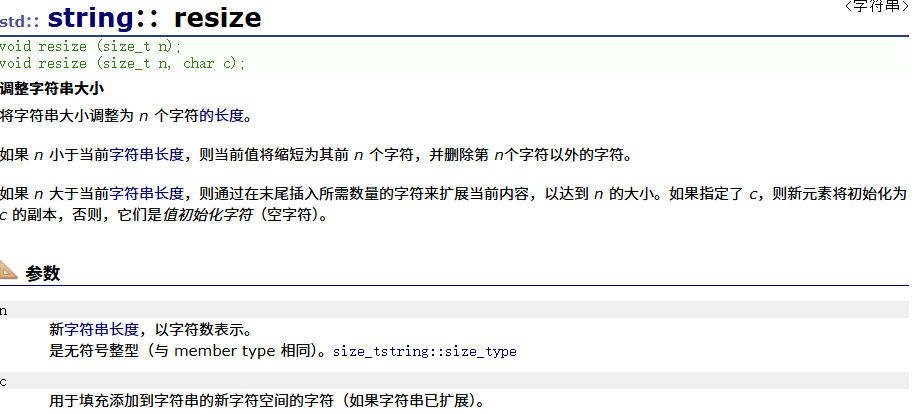
resize
resize是针对length的改变
#include<iostream>
using namespace std;
void string_test2()
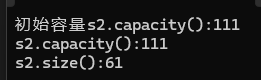
{string s2("hello world");cout<<"s2.size():" << s2.size() << endl;cout<<"s2.capacity():" << s2.capacity() << endl;cout << s2 << endl;//大于capacitys2.resize(20,'V');cout << "s2.size():" << s2.size() << endl;cout << "s2.capacity():" << s2.capacity() << endl;cout<<s2<<endl;//小于capacity大于sizes2.resize(13, 'V');cout << "s2.size():" << s2.size() << endl;cout << "s2.capacity():" << s2.capacity() << endl;cout << s2 << endl;//小于capacitys2.resize(10, 'V');cout << "s2.size():" << s2.size() << endl;cout << "s2.capacity():" << s2.capacity() << endl;cout << s2 << endl;
}
int main()
{ string_test2();return 0;
} 结果
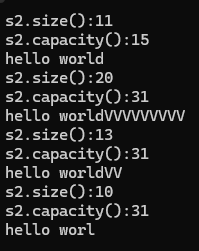
当大于size的时候,补充字符;小于size的时候,打印到缩容位置即可
注意:
1. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
2.size与capacity均不包含"\0'
3. clear()只是将string中有效字符清空,不改变底层空间大小。
4. resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, charc)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。4. reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
迭代器
迭代器是STL中访问容器元素的通用接口。迭代器是一种类似指针一样的东西(但是它并不是指针且抽象程度更高)。在string类中迭代器有以下4类(2组一类)
正向迭代器、反向迭代器、const迭代器、const反向迭代器

迭代器分类
正向迭代器
正向迭代器主要有两个:begin和end
他们的介绍分别是这样的
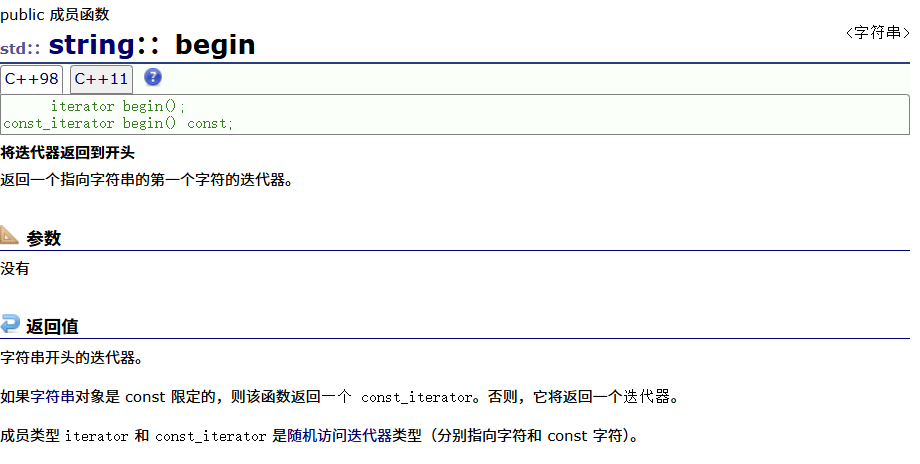
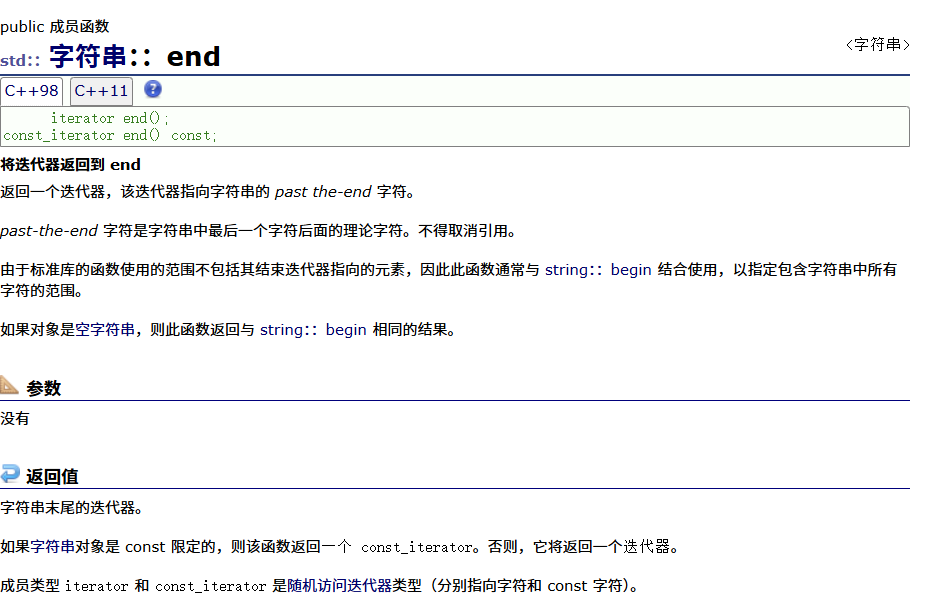
代码举例:
#include<iostream>
using namespace std;
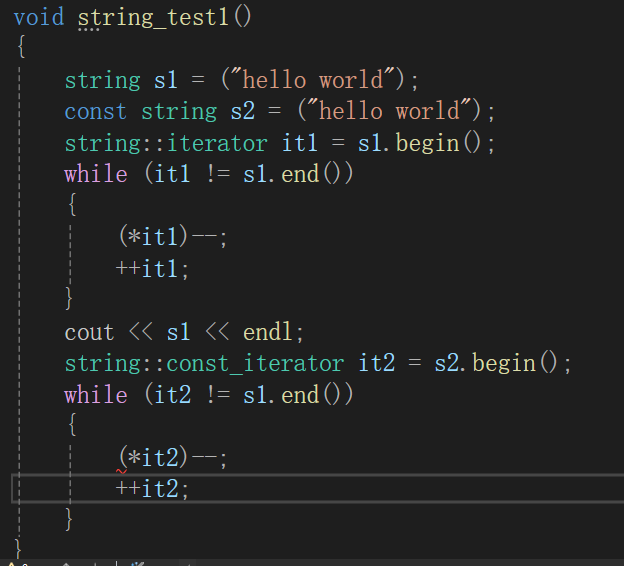
void string_test1()
{string s1 = ("hello world");const string s2 = ("hello world");string::iterator it1 = s1.begin();while (it1 != s1.end()){(*it1)--;++it1;}cout << s1 << endl;}
int main()
{string_test1();return 0;
}结果为:
![]()
但是这么写会报错,因为涉及到了权限的放大
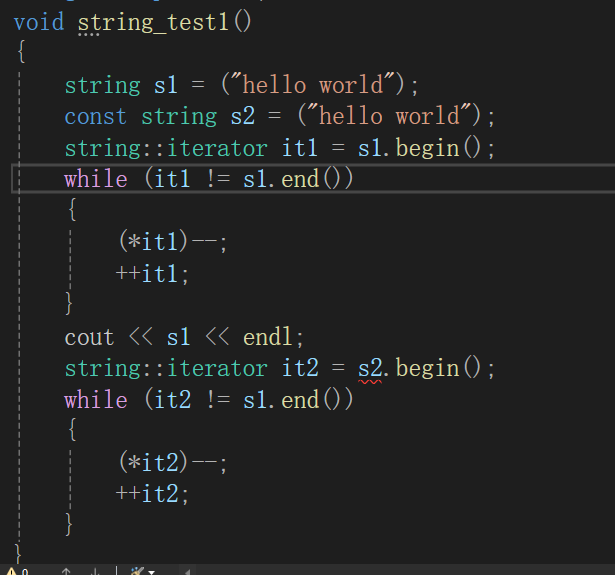
可以在迭代器上加const(不过指向的内容仍然不能修改)
反向迭代器
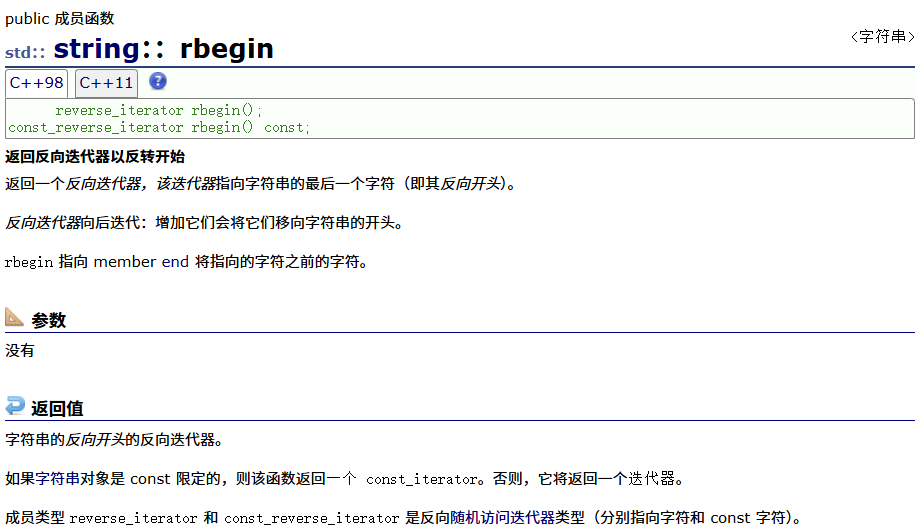
反向迭代器有两个:rbegin和rend
#include<iostream>
using namespace std;
void string_test1()
{string s1 = ("hello world");const string s2 = ("hello world");//倒着遍历string::reverse_iterator it3 = s1.rbegin();while (it3 != s1.rend()){cout << *it3 << " ";++it3;}cout<<endl;
}
int main()
{string_test1();return 0;
}结果如下:

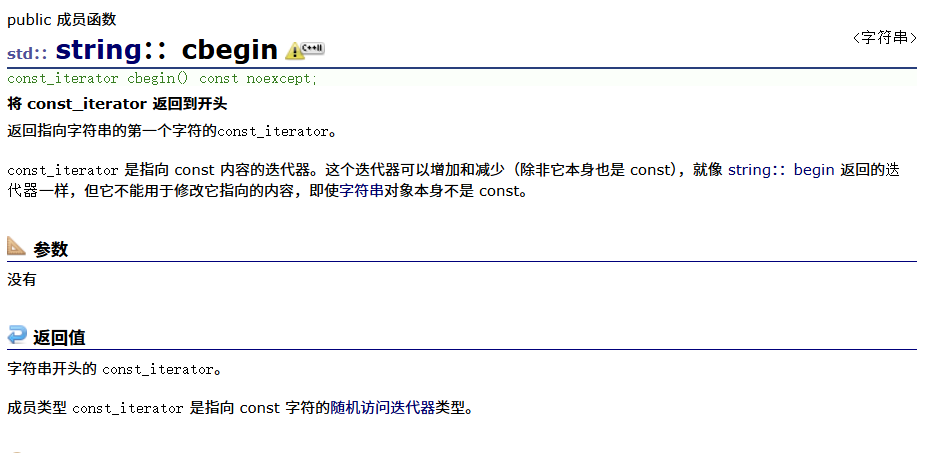
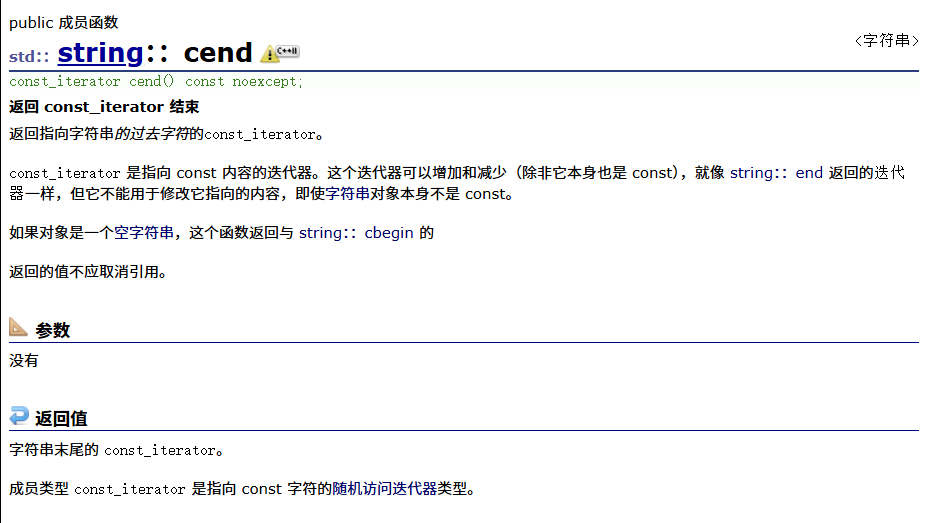
const迭代器

const反向迭代器

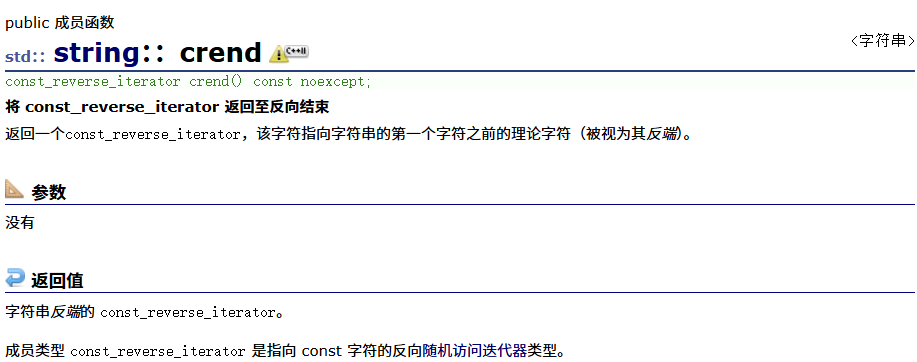
总源代码为:
#include<iostream>
using namespace std;
void string_test1()
{//正向迭代器string s1 = ("hello world");const string s2 = ("hello world");//遍历string::iterator it1 = s1.begin();while (it1 != s1.end()){(*it1)--;++it1;}cout << s1 << endl;//反向迭代器string::reverse_iterator it3 = s1.rbegin();while (it3 != s1.rend()){cout << *it3 << " ";++it3;}cout<<endl;//const迭代器string::const_iterator it2 = s2.begin();while (it2 != s1.end()){(*it2)--;++it2;}//const反向迭代器string::const_reverse_iterator it4 = s2.rbegin();while (it4 != s2.rend()){(*it4)--;++it4;}
}
int main()
{string_test1();return 0;
}迭代器失效问题
-
导致失效的操作:
-
修改字符串长度(如
append(),insert(),erase())。 -
重新分配内存(如
reserve()不足时扩容)。
-
-
安全实践:
-
在修改操作后,避免使用旧的迭代器。
-
使用索引或重新获取迭代器。
-
迭代器的作用
迭代器主要有两个作用:
1.遍历修改容器中数据
2.将将容器以迭代器传递给算法(函数模板)
范围for底层上依然是迭代器
迭代器的意义:
1.统一类似的方式遍历修改容器
2.算法脱离了具体的底层结构,与底层结构解耦(降低耦合,降低关联关系)
算法独立模板实现,针对多个容器处理
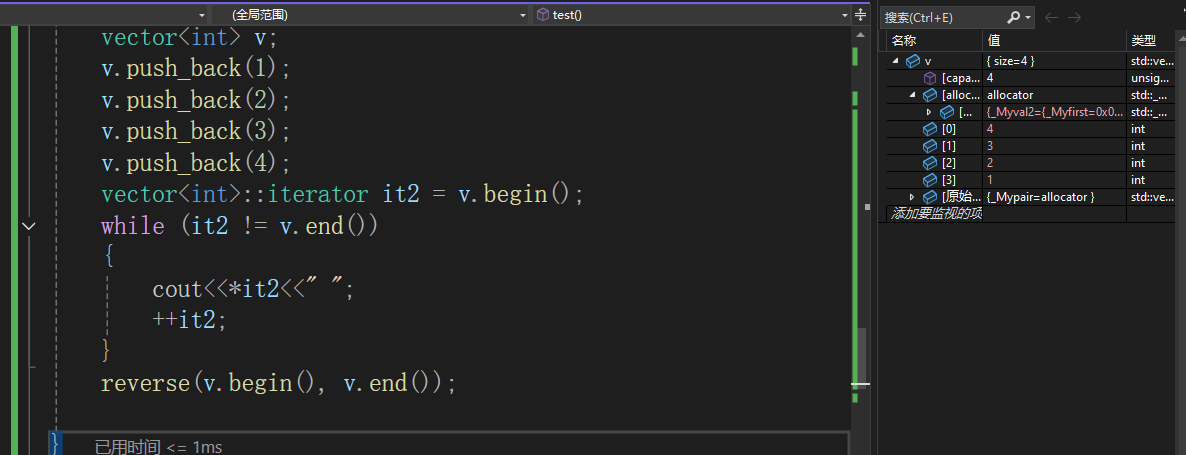
下图就是相关的代码示例:(使用前要包含头文件<algorithm>)
string的遍历
| 函数名称 | 功能说明 |
| operator[](重点) | 返回pos的位置,const string类对象调用 |
| begin+end | begin获取一个字符的迭代器+end获取最后一个字符下一个位置的迭代器 |
| rbegin+rend | begin获取一个字符的迭代器+end获取最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for新遍历方式 |
一、运算符重载介绍
operator[]
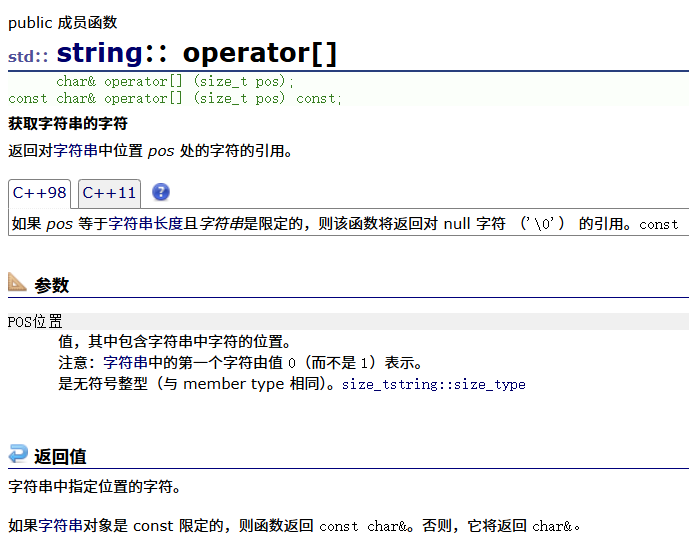
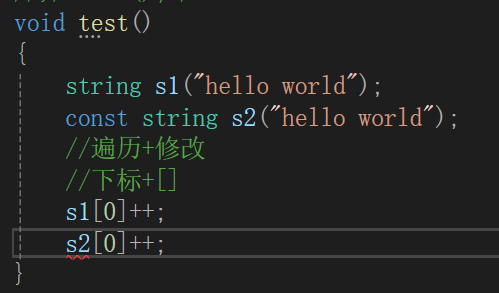
我们很明显地发现:s2是不能修改的
因为它们的调用关系是这样的
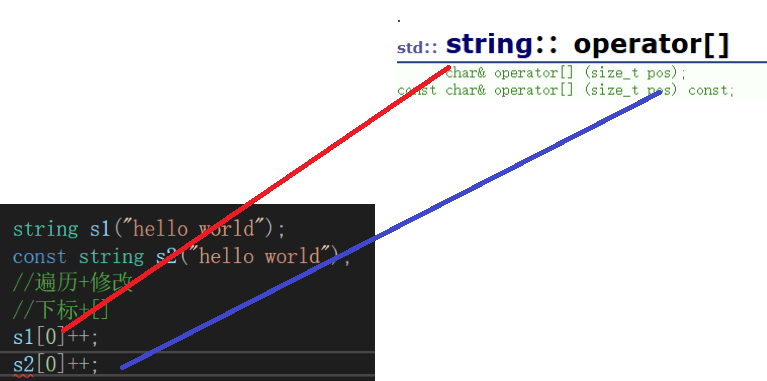
举例说明:
void test()
{string s1("hello world");const string s2("hello world");//遍历+修改//下标+[]s1[0]++;/*s2[0]++;*/cout<<s1<<endl;for (size_t i = 0;i < s1.size();i++){s1[i]++;}cout << s1 << endl;s1[8];//函数调用相当于s1.1operator[](8)//越界检查s1[20];
}
int main()
{test();return 0;
}结果为:
at
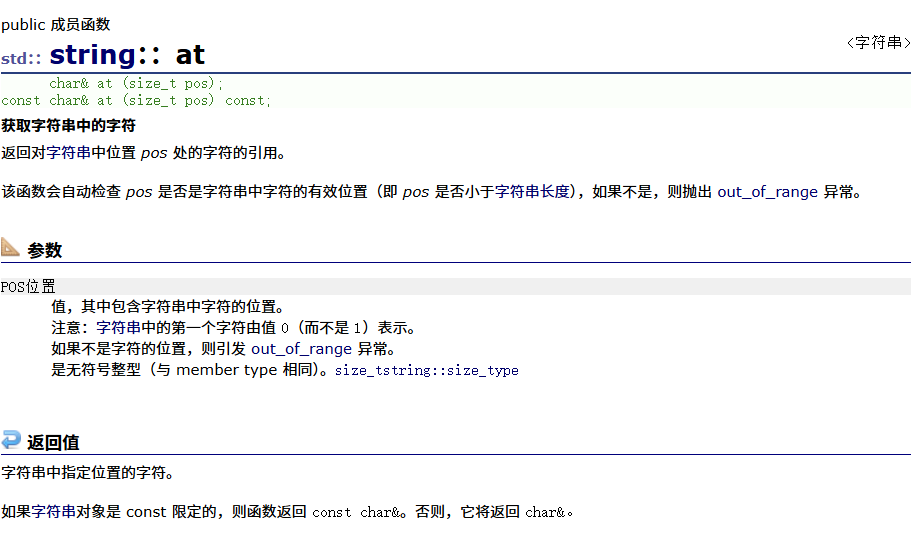
at与[]的区别是at失败后会抛出异常,[]则依赖于assert断言检查越界
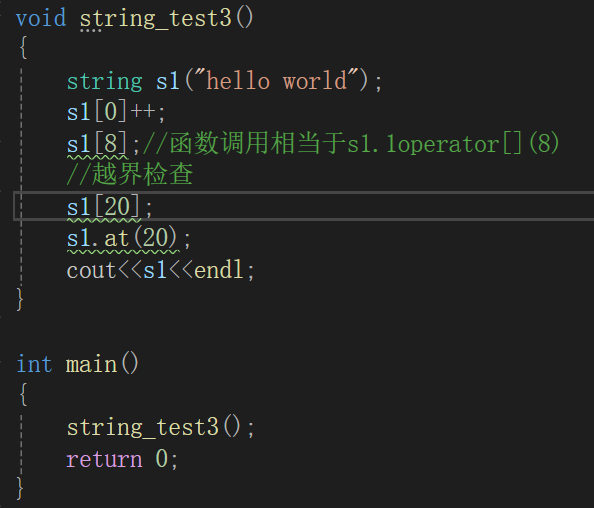
两处均已经报错
at的异常可以通过以下方式捕获(异常内容后续讲解)


back

front
二、迭代器
迭代器是像指针一样的类型对象
void test()
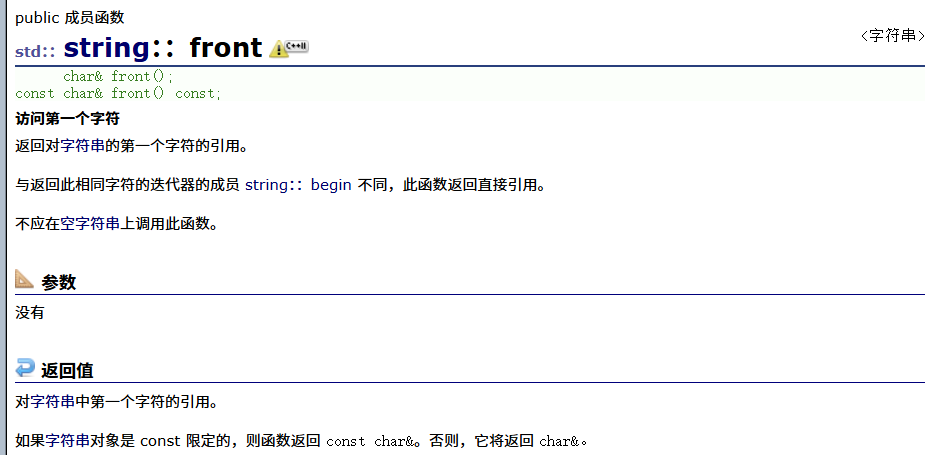
{string s1("hello world");const string s2("hello world");//遍历+修改//下标+[]s1[0]++;/*s2[0]++;*/cout<<s1<<endl;for (size_t i = 0;i < s1.size();i++){s1[i]++;}cout << s1 << endl;//begin() end()返回的是一段迭代器位置的区间,形式是这样的[ )//迭代器//s1--//iterator迭代器//迭代器使用起来像指针string::iterator it = s1.begin(); while (it!= s1.end()){(*it)--;++it;}cout << s1 << endl;}
int main()
{test();return 0;
}结果为:
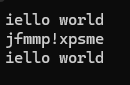
迭代器是所有容器的主流迭代方式,迭代器具有迁移性,掌握一个其他的也可以轻松上手
vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);vector<int>::iterator it2 = v.begin();while (it2 != v.end()){cout<<*it2<<" ";++it2;}![]()
三、范围for (C++11)
(这里需要结合前面的auto和范围for的拓展知识内容)
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main()
{int arr[] = {1,2,3,4,5};//C++11的遍历for (auto& e : arr)//从:开始自动,特点是://自动取范围中的数据赋值给e,//自动判断结束//自动迭代{e *= 2;}for (auto&e : arr){cout<<e<<" " << endl;}string str("hello world");for (auto ch : str){cout<<ch<<" ";}cout<<endl;return 0;
}范围for可以遍历vector,list等其他容器。
范围for本质上底层也会替换为新迭代器,即e=*迭代器
string类对象的修改操作
| 函数名称 | 功能介绍 |
| push_back | 在字符串中后尾插字符c |
| pop_back | 擦除字符串最后一个字符,并使得字符串有效长度-1 |
| operator+=(重点) | 在字符串后追加字符串str |
| append | 在字符串后追加一个字符串 |
| assign | 给字符串赋值,替换字符串内容 |
| erase | 取出字符串的一部分元素,减少其长度 |
| insert | 将其他字符穿插到字符串中位置pos之前 |
| replace | 将字符串中从pos开始的len长度的字符替换为新内容 |
| swap | 将容器中的字符与str的内容进行交换 |
push back
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <string>
using namespace std;
void string_test1()
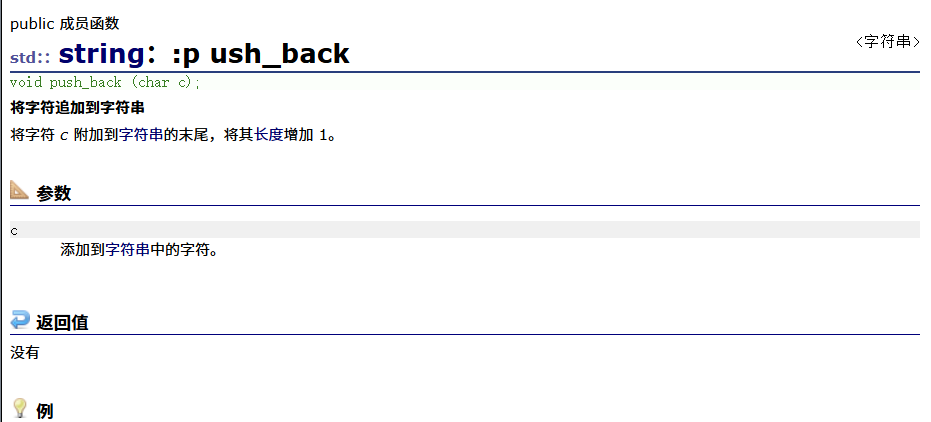
{string s1 = ("hello world");cout << s1 << endl;s1.push_back( '!');s1.push_back('!');cout << s1 << endl;
}
int main()
{string_test1();return 0;
}结果为:
pop back

#include <iostream>
#include <string>
using namespace std;
void string_test1()
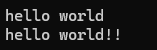
{string s1 = ("hello world");cout << s1 << endl;s1.push_back( '!');s1.push_back('!');cout << s1 << endl;s1.pop_back();s1.pop_back();cout << s1 << endl;
}
int main()
{string_test1();return 0;
}结果为:
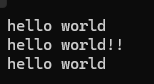
operator+=

operator+=的返回值是this指针
#include <iostream>
#include <string>
using namespace std;
void string_test1()
{string s1 = ("hello world");cout << s1 << endl;s1.push_back( '!');s1.push_back('!');cout << s1 << endl;s1.pop_back();s1.pop_back();cout << s1 << endl;s1.operator+=( " I love C++");cout << s1 << endl;s1.operator+=(" C");cout << s1 << endl;
}
int main()
{string_test1();return 0;
}结果为:
也可以这么写
#include <iostream>
#include <string>
using namespace std;
void string_test3()
{string s1 = ("The song of the end world");cout<<s1<<endl;s1 += " ";s1 += " singer ";cout<<s1<<endl;
}
int main()
{string_test3();return 0;
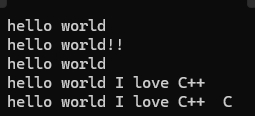
}append


 operator+=接口应用层面上比append更加广泛
operator+=接口应用层面上比append更加广泛
assign
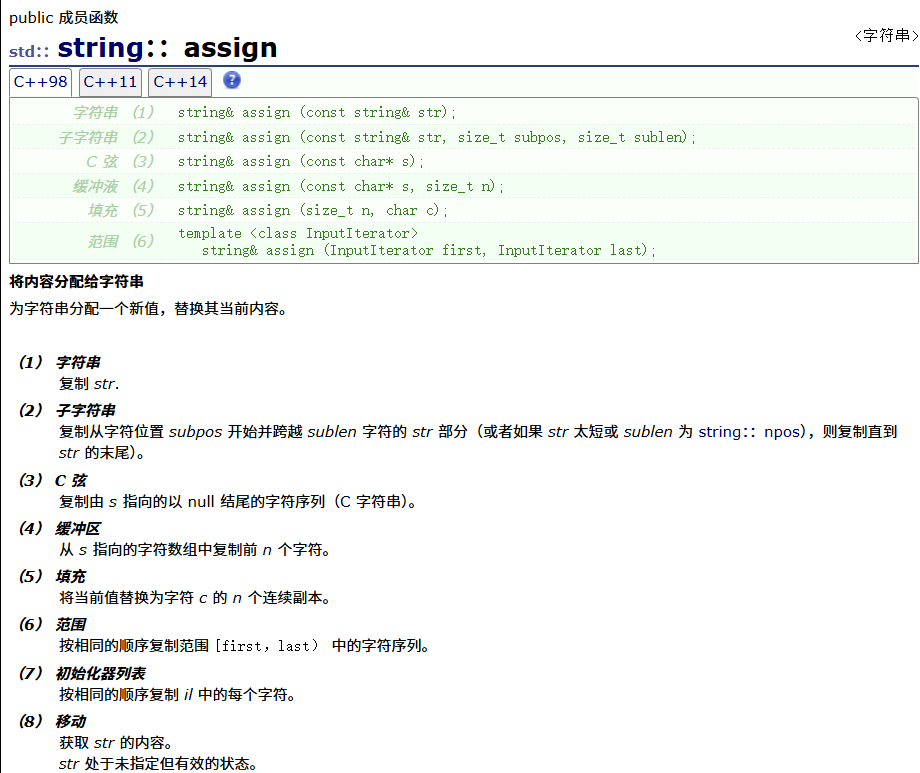
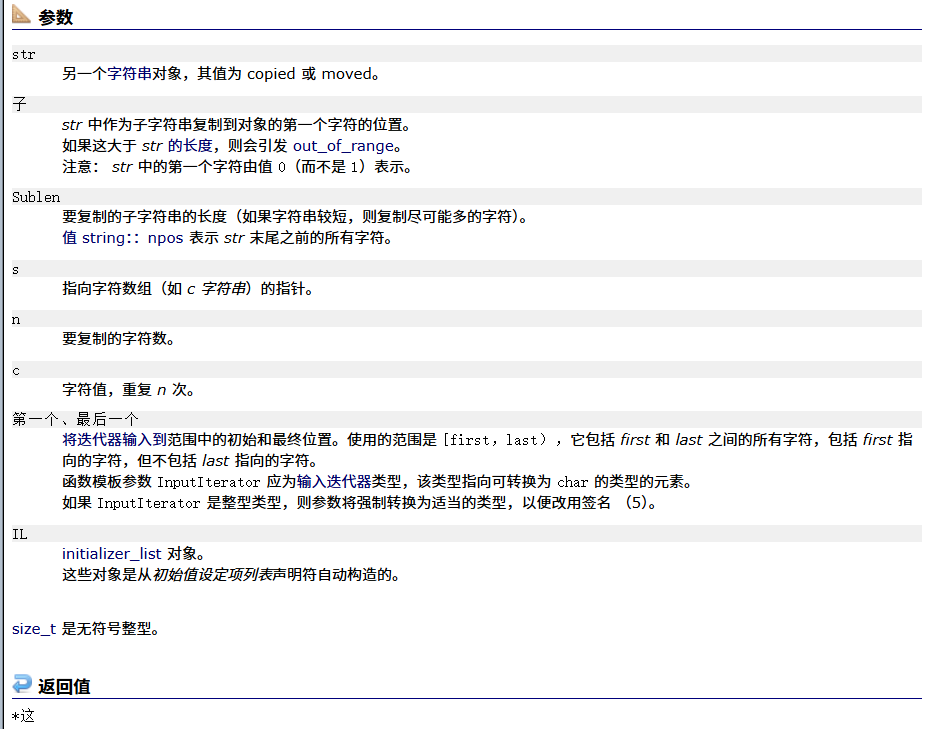
返回值是this指针
#include <iostream>
#include <string>
using namespace std;
void string_test4()
{string s1 = ("The song of the end world");cout<<s1<<endl;s1.assign(10,'~');cout<<s1<<endl;
}
int main()
{string_test4();return 0;
}结果为:
注意:
1. 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
2. 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
void test()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);vector<int>::iterator it2 = v.begin();while (it2 != v.end()){cout<<*it2<<" ";++it2;}reverse(v.begin(), v.end());
}insert
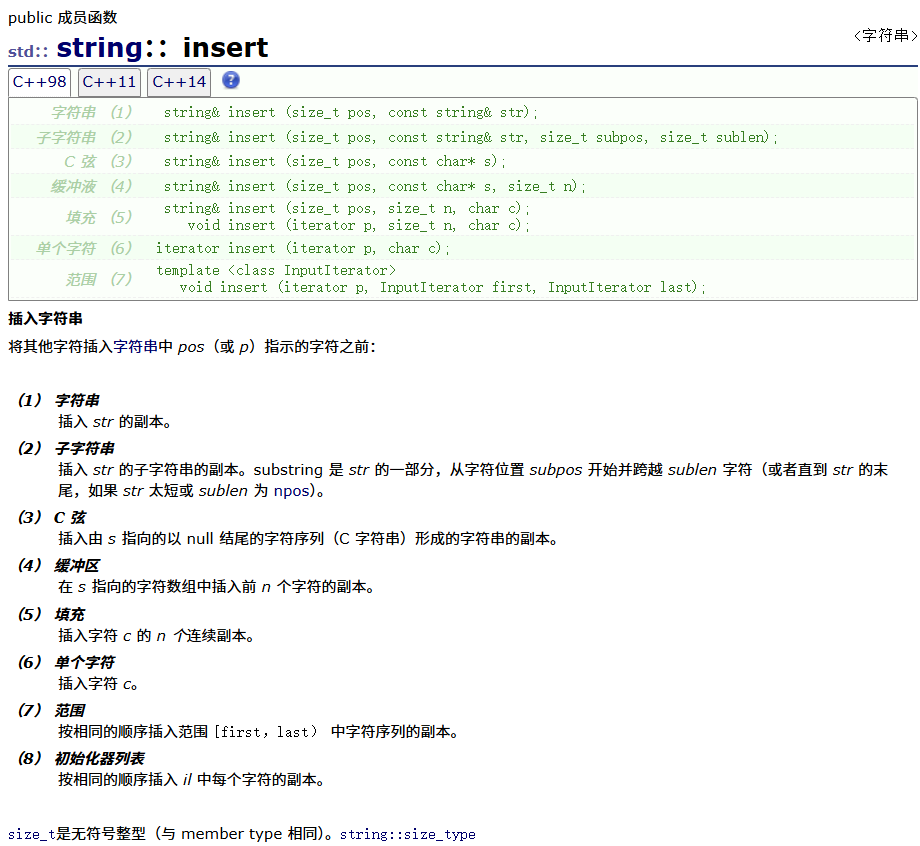

void string_test4()
{string s1 = ("The song of the end world");cout<<s1<<endl;s1.insert(11," I love you",0,7);cout<<s1<<endl;s1.insert(0," NAME: ");cout<<s1<<endl;s1.insert(0,"A");cout << s1 << endl;
}
int main()
{string_test4();return 0;
}结果为:
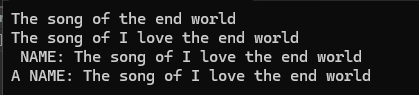
insert要谨慎使用:
底层涉及到了数据挪动,效率低下
erase
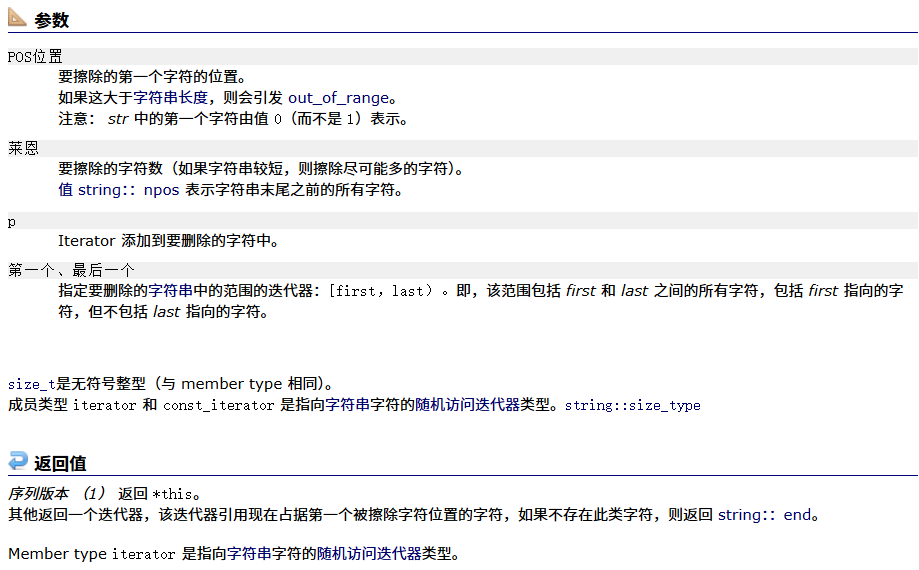 npos是整型的最大值
npos是整型的最大值
#include <iostream>
#include <string>
using namespace std;
void string_test5()
{string s1 = ("The song of the end world");cout<<s1<<endl;//小于的时候删除到指定位置s1.erase(1,7);cout<<s1<<endl;//大于字符长度的时候有多少删除多少s1.erase(1,30);cout<<s1<<endl;
}
int main()
{string_test5();return 0;
}erase也要谨慎使用:
因为底层原理也是涉及到数据移动,效率低下
replace
返回值是this指针
replace默认从0开始查找
replace也要谨慎使用
void string_test5()
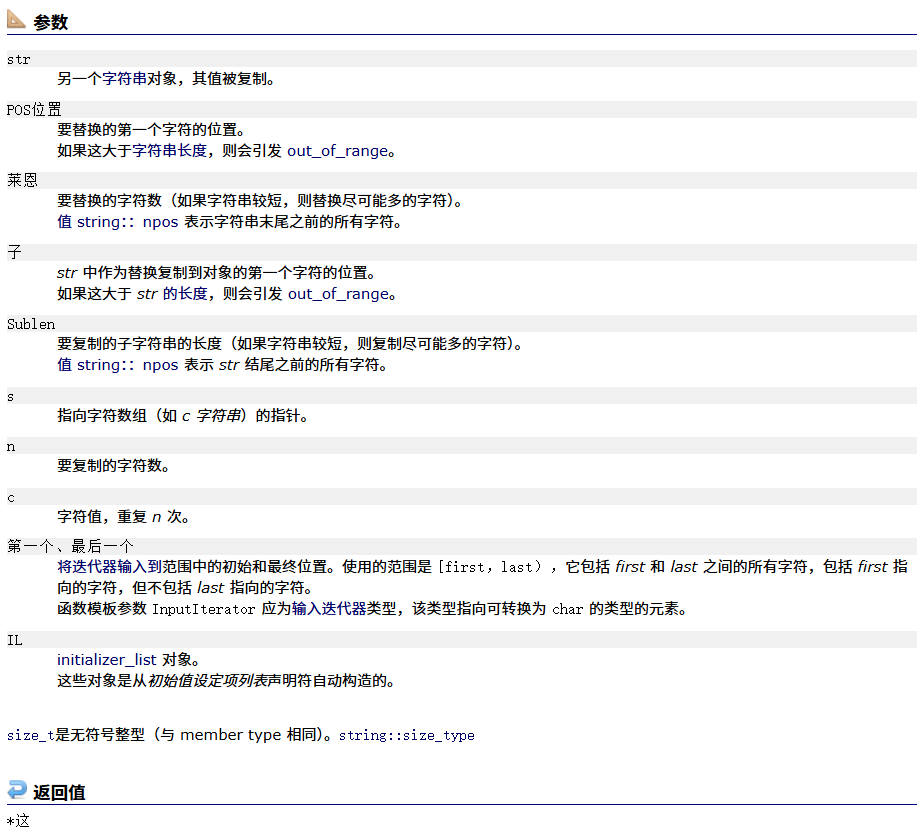
{string s1 = ("The song of the end world");cout<<s1<<endl;s1.replace(5,1," #");cout<<s1<<endl;s1.replace(5,5," #");cout<<s1<<endl;
}
int main()
{string_test5();return 0;
}结果为:
例题:将一串字符串中所有空格替换为百分号
题解1:
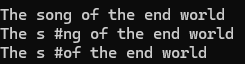
void replace_space1(string&s,char c)
{//将所有空格替换为指定字符csize_t pos=s.find(' ');while (pos != string::npos){s.replace(pos,1,1,c);pos = s.find(' ',pos+1);}cout<<s<<endl;
}
int main()
{string s1 = ("The song of the end world");cout<<s1<<endl;replace_space1(s1,'%'); return 0;
}结果为:
题解2:
#include <iostream>
#include <string>
using namespace std;
void replace_space2(string& s, char c)
{string s6;s6.reserve(s.size());//将所有空格替换为指定字符cfor (auto ch:s){if (ch == ' '){s6 += c;}else{s6 += ch;}}cout << s6 << endl;
}
int main()
{string s1 = ("The song of the end world");cout<<s1<<endl;replace_space2(s1,'%'); return 0;
}结果为;

swap
swap底层结构相对复杂,后续学习了底层会进行更深入的学习
string类的操作
| 字符串操作 | 字符串操作功能 |
| c_str(重点) | 获取等效的C字符串(在C++中调用C的接口) |
| data | 获取字符串数据 |
| get_allocator | 获取底层应用的内存池 |
| copy | 从字符串中复制字符序列 |
| substr | 生成一个子字符串 |
| find(重点) | 在字符串中从前向后查找内容 |
| rfind | 在字符串中从后向前查找内容 |
| find_first_of | 在字符串中搜索与其参数中指定的任何字符匹配的第一个字符。 |
| find_last_of | 在字符串中搜索与参数中指定的任何字符匹配的最后一个字符。 |
| find_first_not_of | 在字符串中搜索与参数中指定的任何字符都不匹配的第一个字符。 |
| find_last_not_of | 在字符串中搜索与参数中指定的任何字符都不匹配的最后一个字符。 |
| compare | 比较字符串 |
c_str
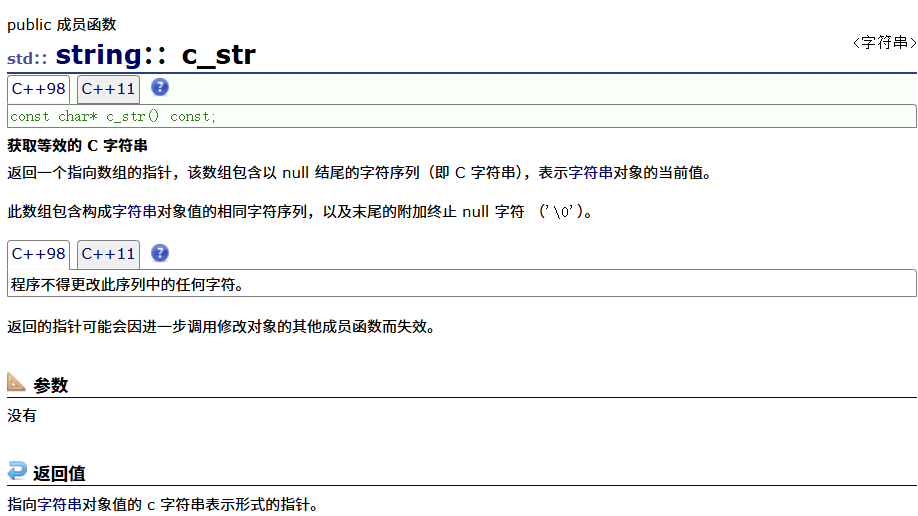
c_str主要的作用是在cpp文件中调用c的接口
比如打开该文件就是这样的结果
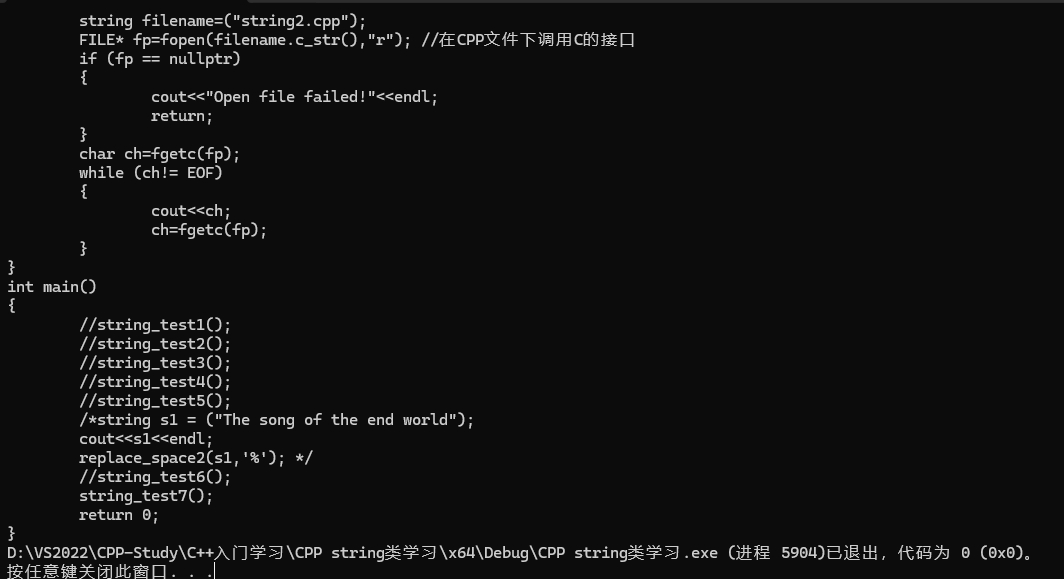
void string_test7()
{string filename=("string2.cpp");FILE* fp=fopen(filename.c_str(),"r"); //在CPP文件下调用C的接口if (fp == nullptr){cout<<"Open file failed!"<<endl;return;}char ch=fgetc(fp);while (ch!= EOF){cout<<ch; ch=fgetc(fp);}
}
int main()
{string_test7();return 0;
}结果为: (仅仅展示一部分)
data 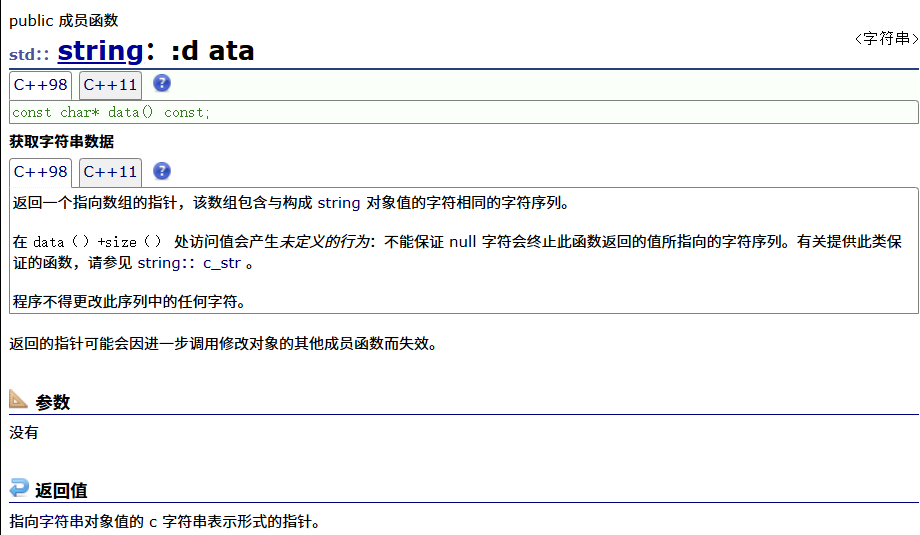
同c_str类似,也是未来与C语言适配而做出来的接口
get_allocator
allocator是系统库提供的内存池,这个的作用是获取底层应用的内存池
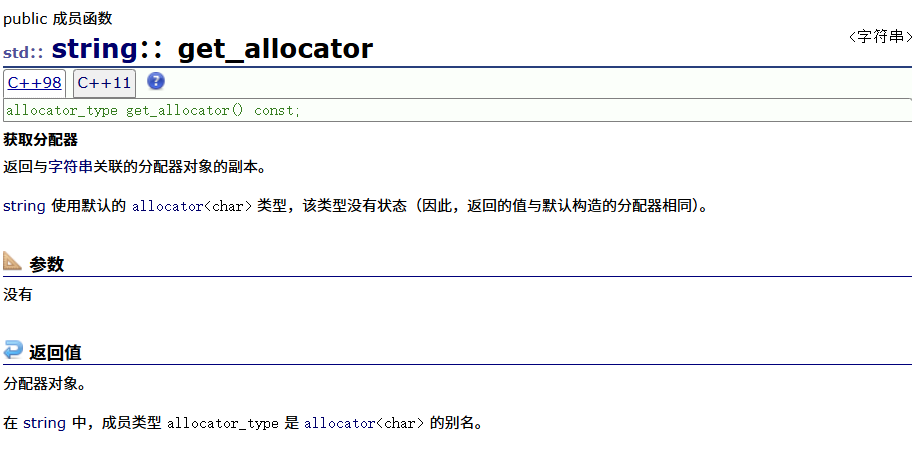
函数参数传递的是对象,模板参数传递的是类型

copy

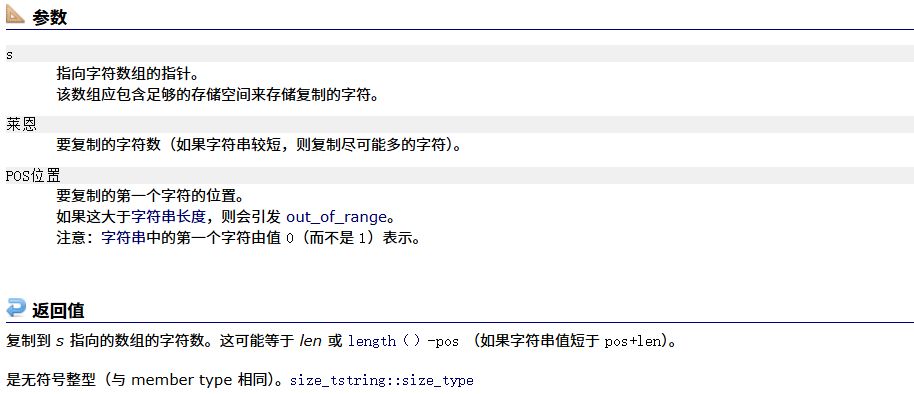
#include <iostream>
#include <string>
using namespace std;
void string_test8()
{char buffer[20];string str("The song of the end world");size_t length = str.copy(buffer, 4, 10);buffer[length] = '\0';std::cout << "buffer contains: " << buffer << '\n';
}
int main()
{string_test8();return 0;
}结果为:
![]()
但是copy的应用相对较少,应用相对较多的是如下的substr
substr
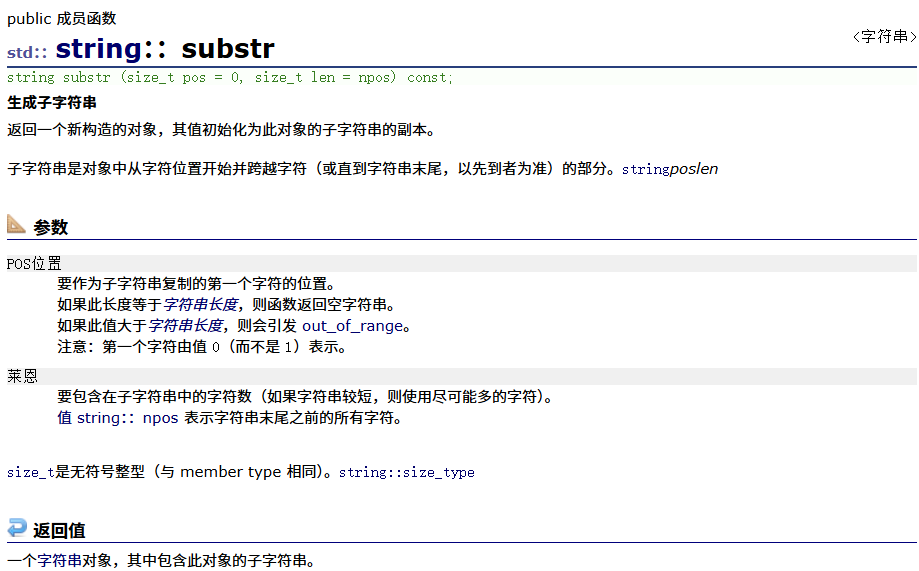
#include <iostream>
#include <string>
using namespace std;
void string_test9()
{string filename = "string2.cpp";//范围大小string str= filename.substr(4,filename.size()-4);cout<<str<<endl;
}
int main()
{string_test9();return 0;
}结果为:
![]()
#include <iostream>
#include <string>
using namespace std;
void string_test9()
{string filename = "string2.cpp";//范围大小string str= filename.substr(4,2);cout<<str<<endl; string str= filename.substr(4,filename.size()-4);cout<<str<<endl;
}
int main()
{string_test9();return 0;
}结果为:
pos不能越界,否则会抛出异常
find
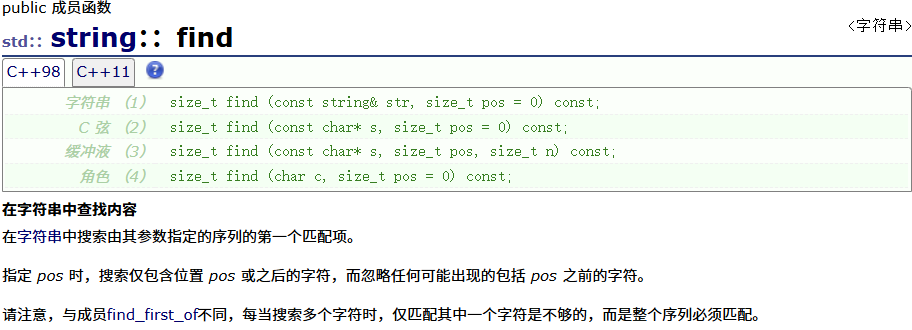
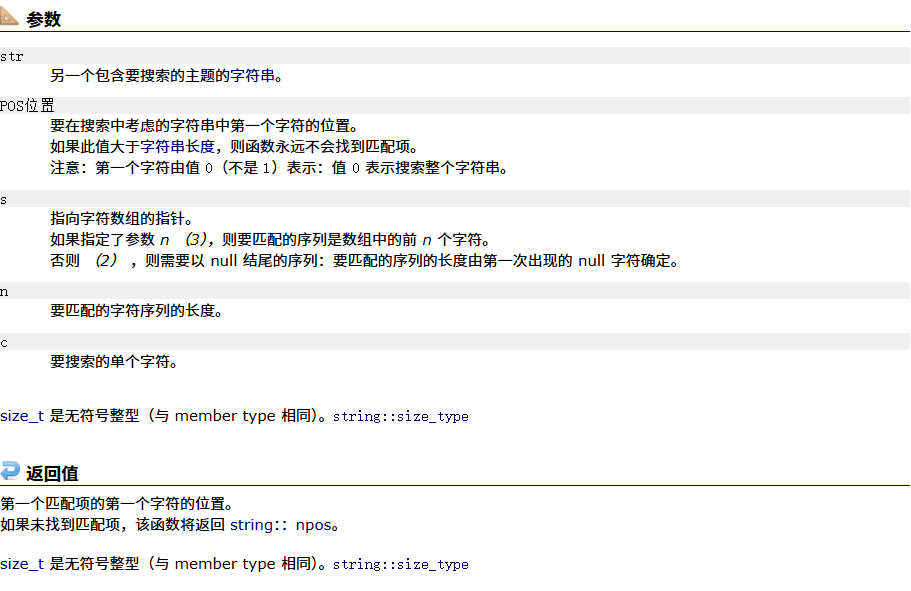
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <string>
using namespace std;
string string_find(const string&filename)
{size_t i=filename.find('.');if (i != string::npos){return filename.substr(i);}else{string empty;return empty;//方式二://return string();//方式三://return "";//本质上是隐式类型转换(const char*->string)}
}
void string_test10()
{string filename1 = "string2.cpp";string filename2 = "string2.c";string filename3 = "string2";cout<< string_find(filename1)<<endl;cout << string_find(filename2) << endl;cout << string_find(filename3) << endl;
}
int main()
{string_test10();return 0;
}结果为:
void spilt_url(const string&url)
{size_t pos1 = url.find(":");if (pos1 != string::npos){cout<< url.substr(0,pos1)<<endl;}size_t pos2 = pos1 + 3;size_t pos3 = url.find("/",pos2);if (pos3 != string::npos){cout<< url.substr(pos2,pos3-pos2)<<endl;cout<< url.substr(pos3+1)<<endl;}
}
void string_test11()
{string ur1 = "https://legacy.cplusplus.com/reference/string/string/compare/";//string ur2 = "https://en.cppreference.com/w/";spilt_url(ur1);//spilt_url(ur2);
}
int main()
{//string_test1();//string_test2();//string_test3();//string_test4();//string_test5();/*string s1 = ("The song of the end world");cout<<s1<<endl;replace_space2(s1,'%'); *///string_test6();//string_test7();//string_test8();//string_test9();//string_test10();string_test11();return 0;
}rfind
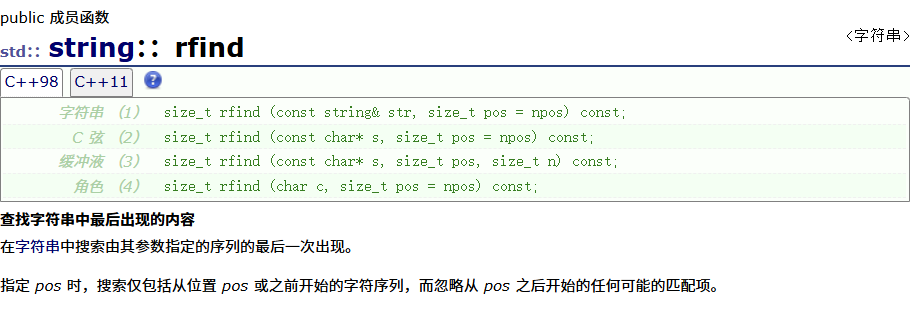
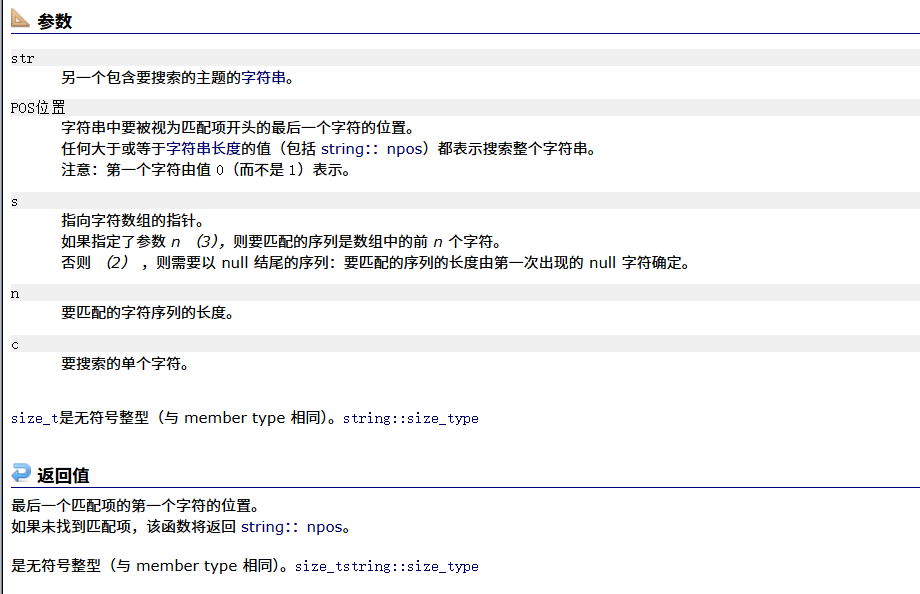
与find的区别是rfind是逆置寻找
find_first_of
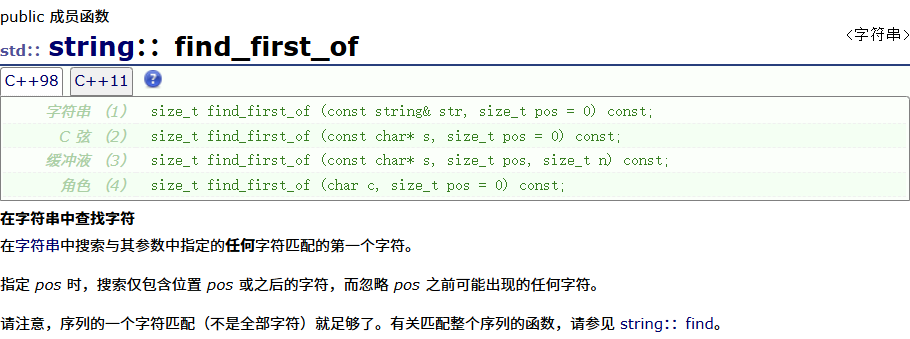
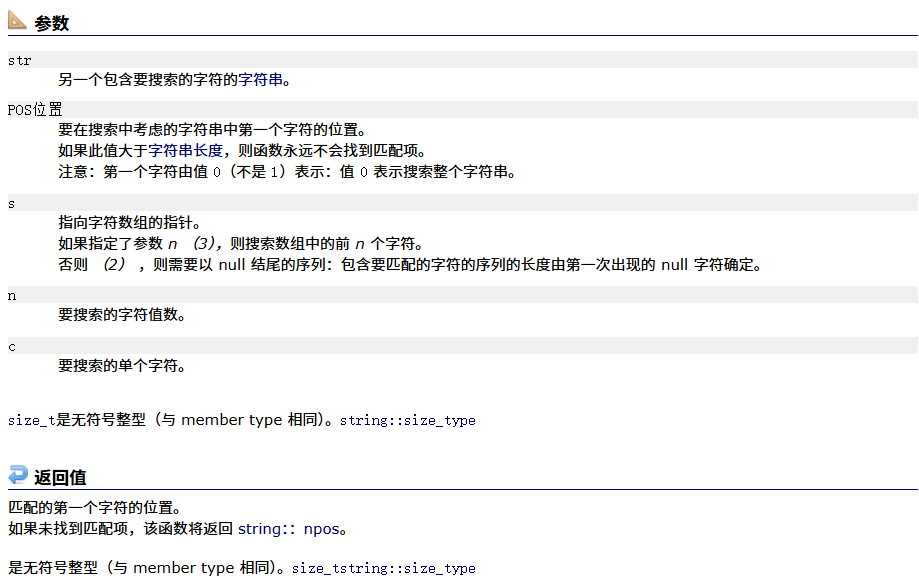
#include <iostream>
#include <string>
using namespace std;
void string_test12()
{string s1 = ("The song of the end world");size_t pos = s1.find_first_of("eo");while (pos != string::npos){s1[pos] = '*';pos = s1.find_first_of("eo",pos+1);}cout<<s1<<endl;
}
int main()
{string_test12();return 0;
}结果为:
![]()
find_last_of

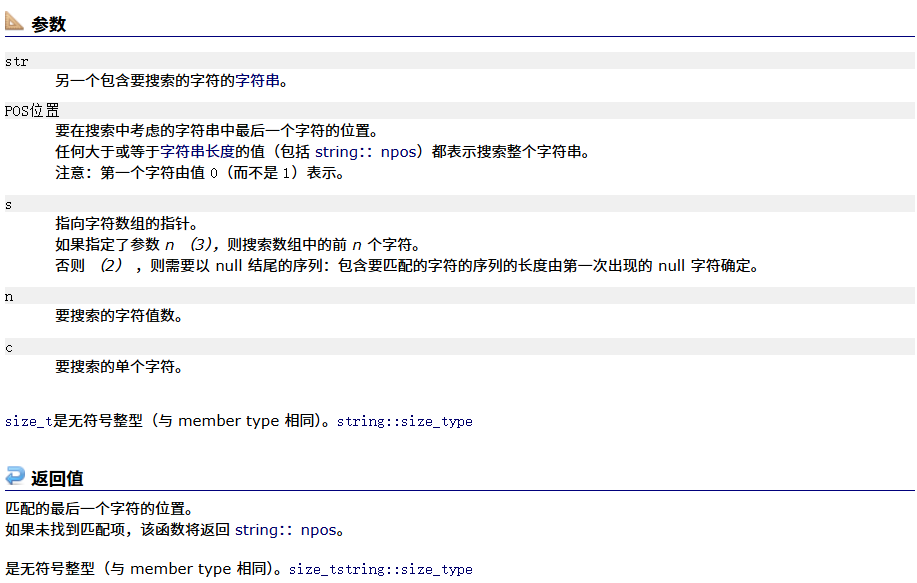
#include <iostream>
#include <string>
using namespace std;
void string_test12()
{string s1 = ("The song of the end world");size_t pos = s1.find_last_of("eo");while (pos != string::npos){s1[pos] = '*';pos = s1.find_first_of("eo",pos+1);}cout<<s1<<endl;
}
int main()
{string_test12();return 0;
}结果为:
![]()
find_first_not_of
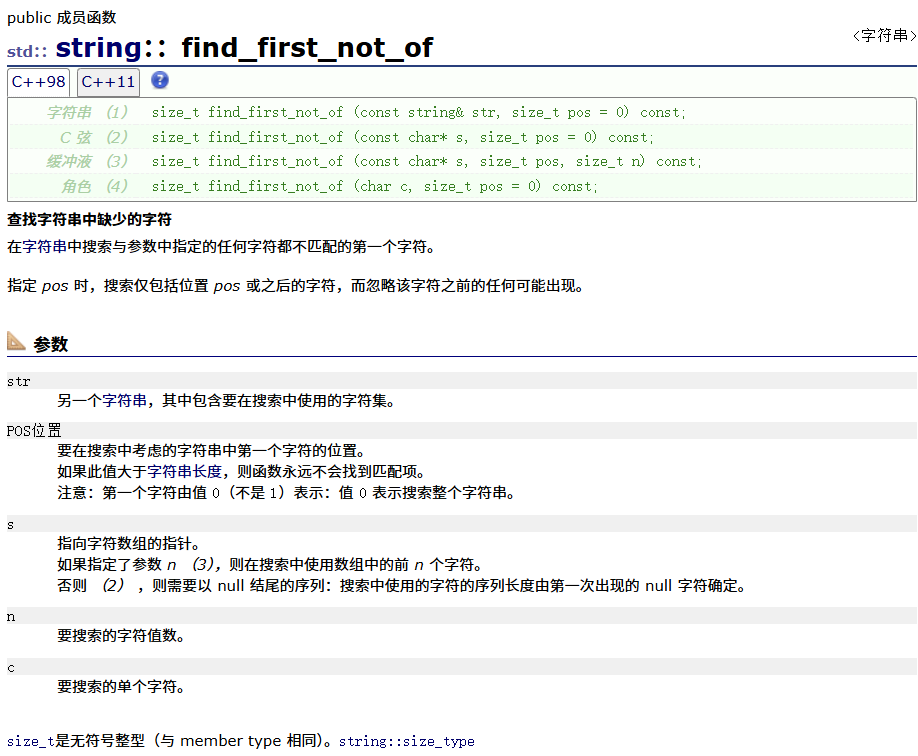

#include <iostream>
#include <string>
using namespace std;
void string_test12()
{string s1 = ("The song of the end world");size_t pos = s1.find_first_of("eo");while (pos != string::npos){s1[pos] = '*';pos = s1.find_first_not_of("eo",pos+1);}cout<<s1<<endl;
}
int main()
{string_test12();return 0;
}结果为:
![]()
find_last_not_of
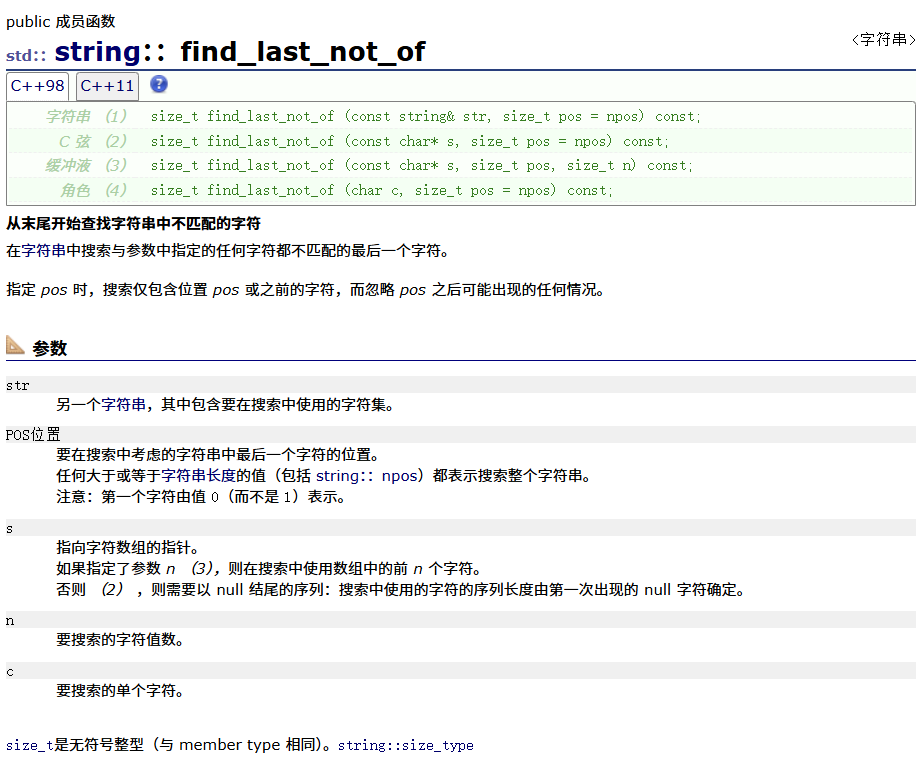
 compare
compare
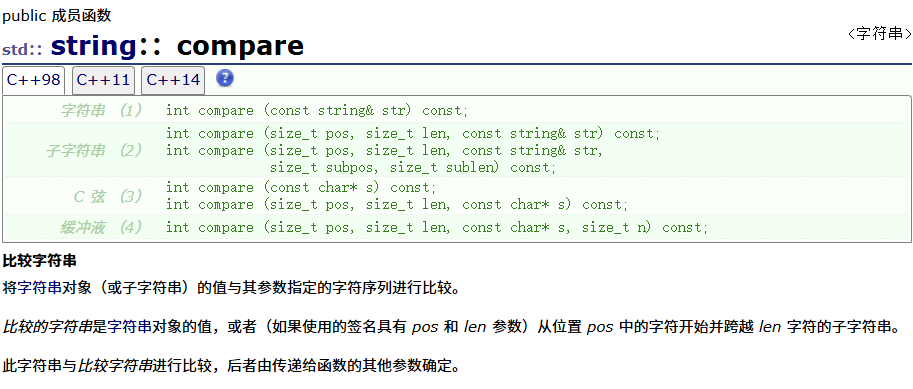
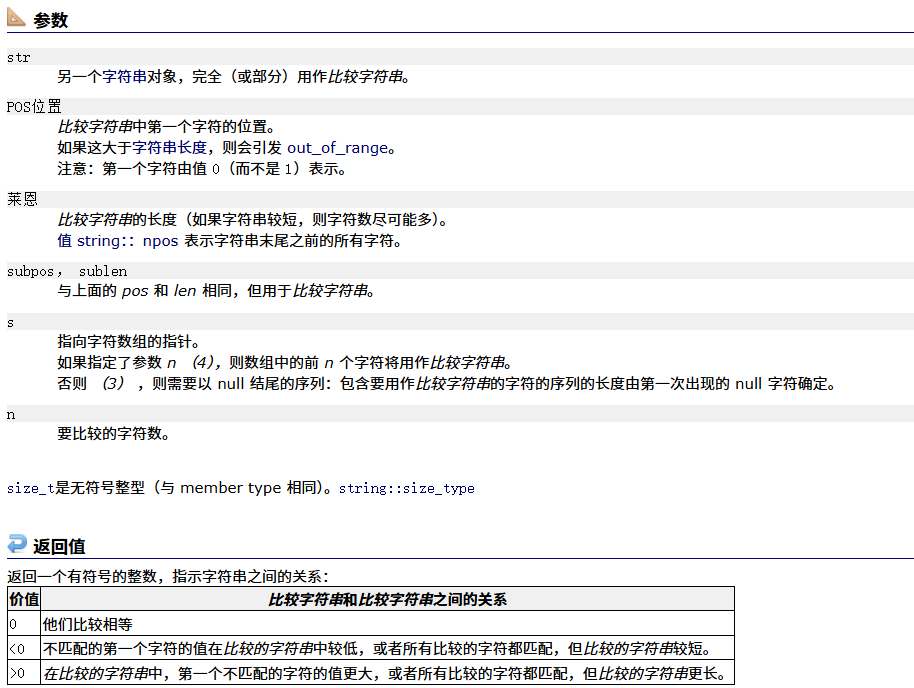 重载了比较大小
重载了比较大小
以非成员函数的形式重载函数,重载全局
与strcmp类似,按ASCII比
string的成员常量:npos

string类非成员函数
| 函数 | 功能说明 |
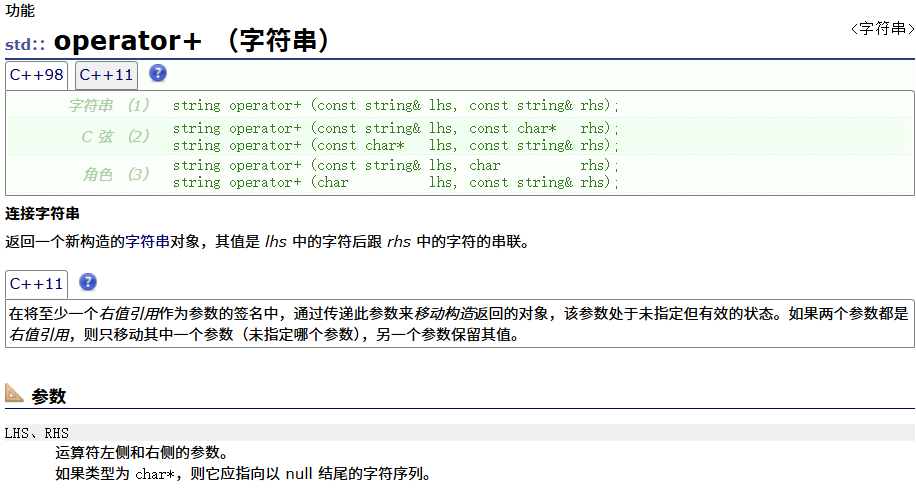
| operator+ | 尽量少用,因为传值返回,导致深拷贝效率降低 |
| operator>>(重点) | 输入运算符重载 |
| operator<<(重点) | 输出运算符重载 |
| getline(重点) | 获取一行字符串 |
| relation operators(重点) | 大小比较 |
| swap | 交换两个字符串的值 |
operator+
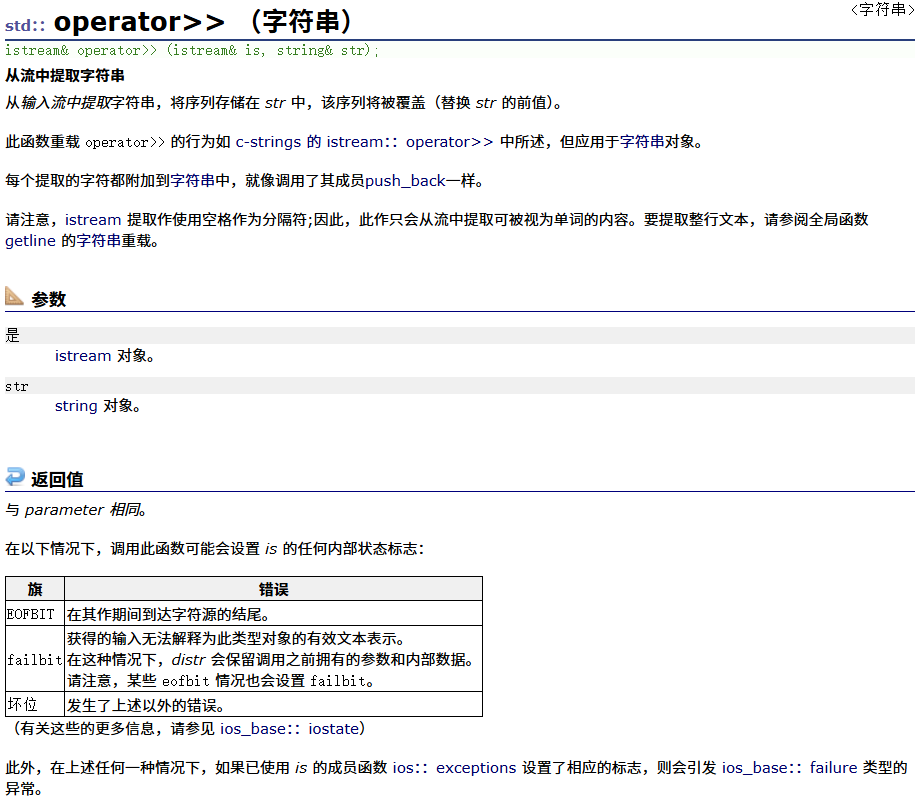
operator>>(重点)
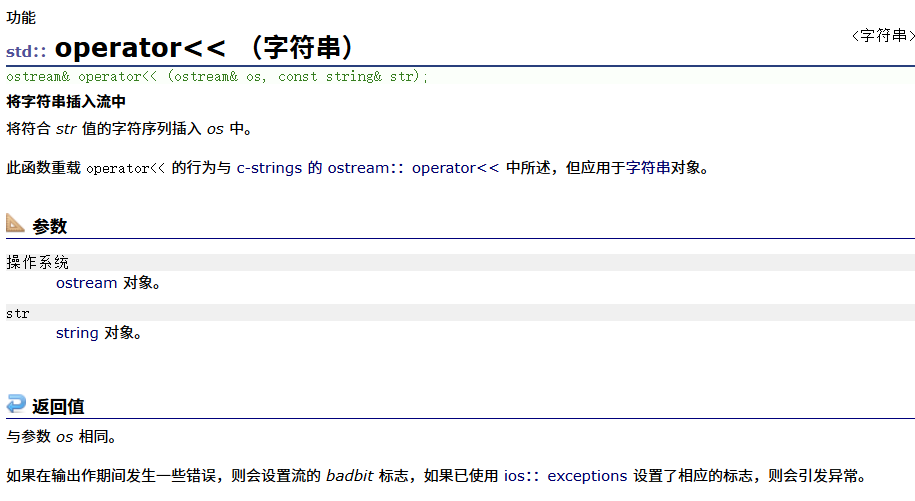
operator<<(重点)
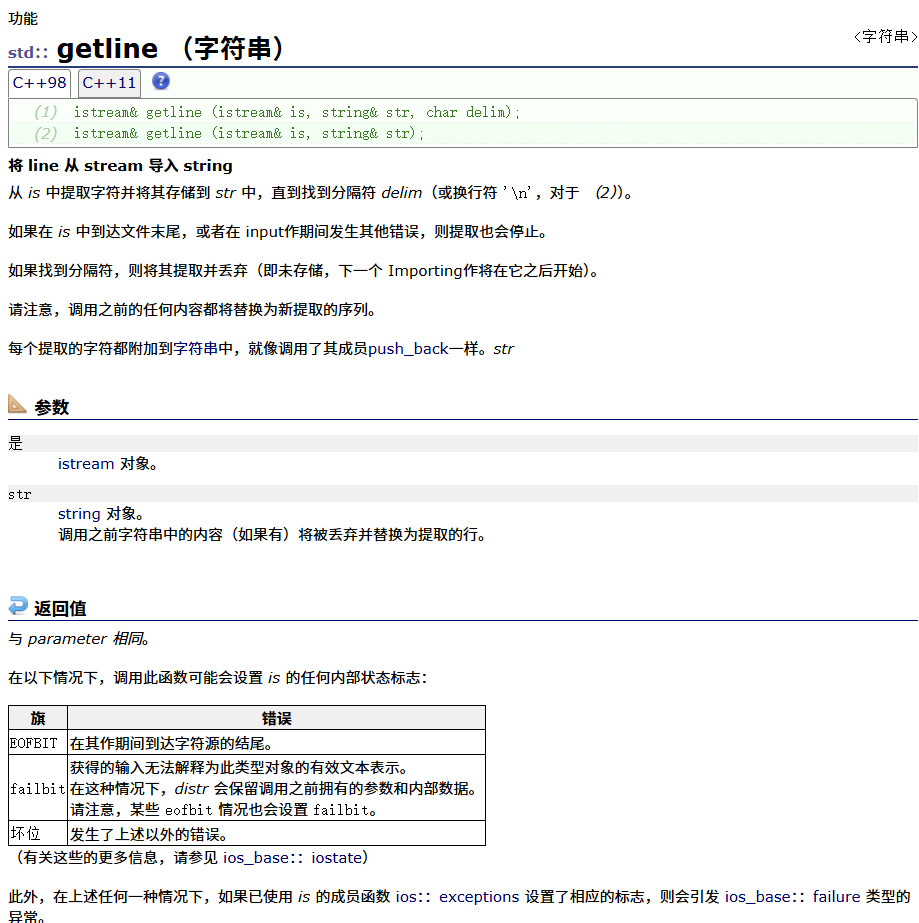
getline(重点)
getline只有遇到换行才会结束
delim是定界,即可以自己规定边界
举例说明:
#include <iostream>
#include <string>
using namespace std;int main()
{string s;getline(cin, s,'!');cout << s << endl;return 0;
}结果为:
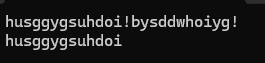
持续输入输出:
int main()
{string s;while (cin>>s){cout<<s<<endl;}return 0;
}relation operators(重点)
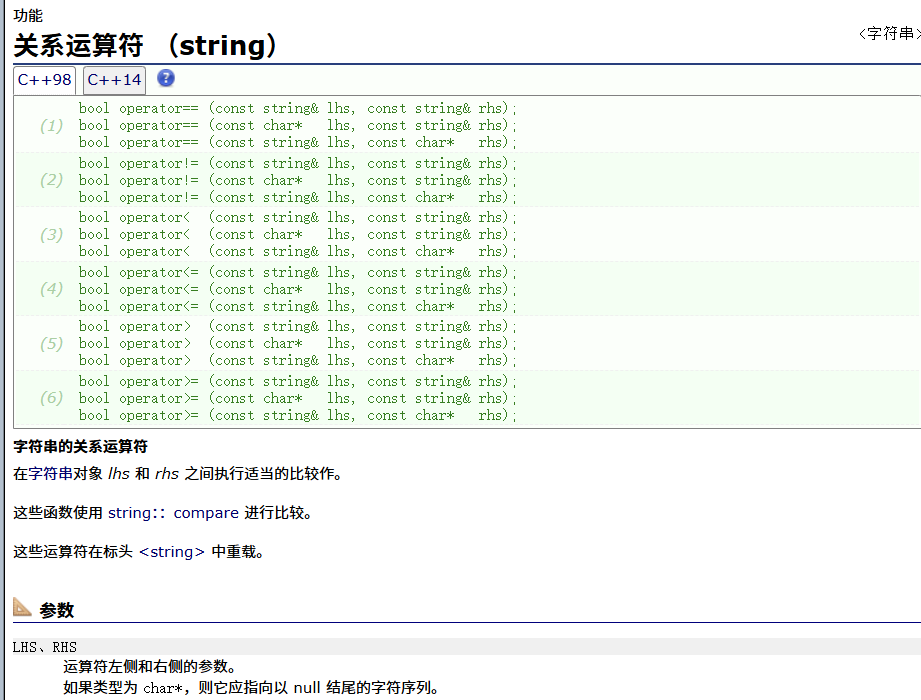
swap
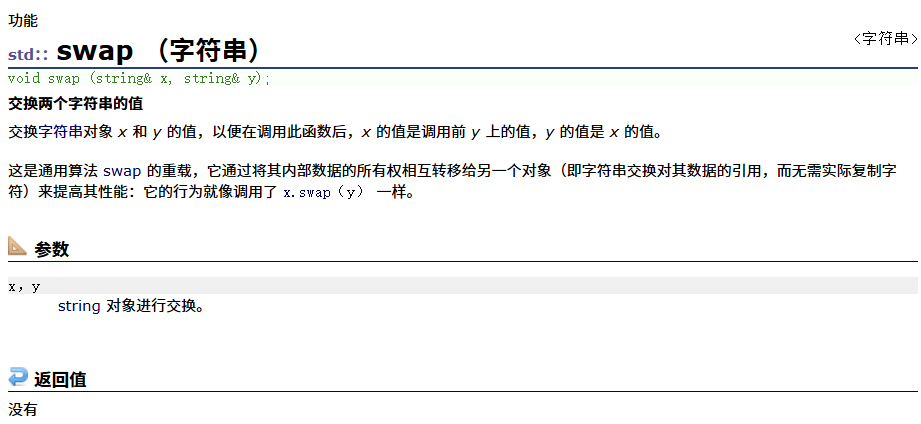
同之前的swap函数一样,后续学习底层后进行学习
一些string类的例题
1、字符串相加

本质上属于大数运算 的应用
答案:
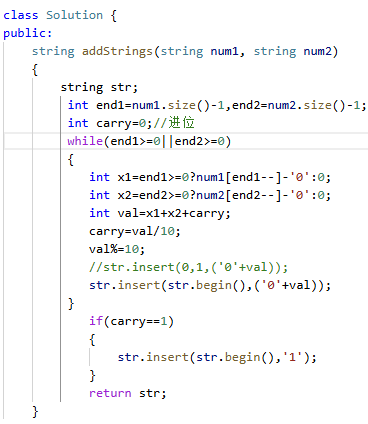
误区,这个解题方法的时间复杂度不是O(N)而是O(N^2)。为什么会这样呢?
为什么这道题中应用了insert。insert的底层是数据的移动,类似于顺序表,时间复杂度会更高
更好的方法:
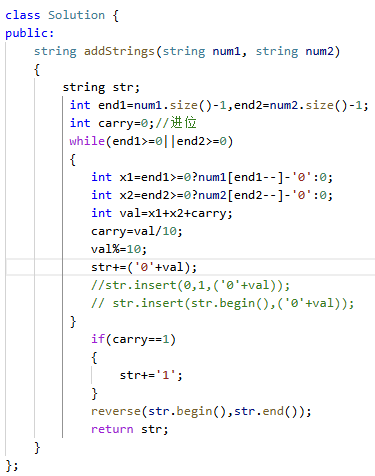
时间复杂度O(N)
2.仅仅反转字母
题目:

这道题本质上是类似于快速排序算法
这道题不适合用范围for,也不适合迭代器。用下标法求解这道题:
class Solution
{
public:string reverseOnlyLetters(string s) {if(s.empty())return s;size_t begin=0,end=s.size()-1;while(begin<end){while(begin<end&&!isalpha(s[begin])){++begin;}while(begin<end&&!isalpha(s[end])){--end;}swap(s[begin],s[end]);++begin;--end;}return s;}
};或者
class Solution
{
public:bool isletter(char ch){if(ch>='a'&&ch<='z'){return true;}else if(ch>='A'&&ch<='Z'){return true;}else {return false;}}string reverseOnlyLetters(string s) {if(s.empty())return s;size_t begin=0,end=s.size()-1;while(begin<end){while(begin<end&&!isletter(s[begin])){++begin;}while(begin<end&&!isletter(s[end])){--end;}swap(s[begin],s[end]);++begin;--end;}return s;}
};3.查找字符串中第一个唯一的字符
题目:

思路:哈希
哈希就是映射,即建立数字与位置的映射,就像下图这样
class Solution
{
public:int firstUniqChar(string s) {int count[26]={0};//每个字符出现的次数for(auto e:s){count[e-'a']++;}for(size_t i=0;i<s.size();++i){if(count[s[i]-'a']==1){return i;}}return -1;}
};4.字符串最后一个单词的长度
题目:
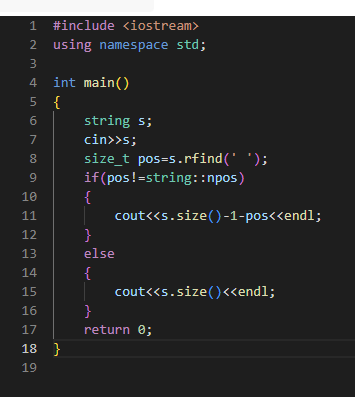
初始做法(不通过)
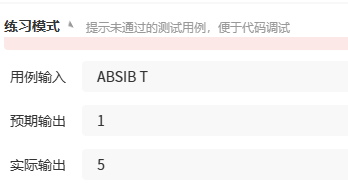
在VS上调试可以发现
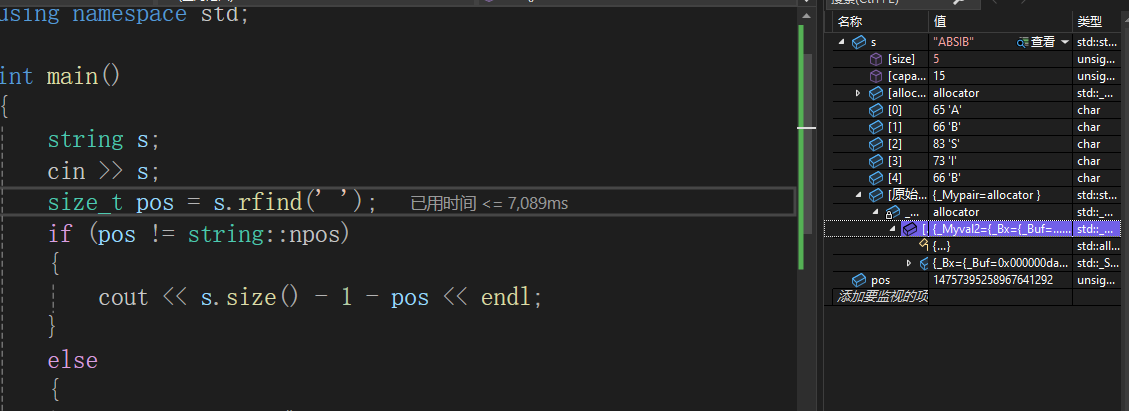
s并没有包括T
这是为什么呢?
因为scanf和cin输入多个值的时候,默认空格和换行是多个数值的分隔,无法读取空格之后的内容
当字符串有空格的时候需要用到getline
getline(cin,s);答案:
5.验证回文字符串
题目:

答案为:

VS和g++下string结构的说明
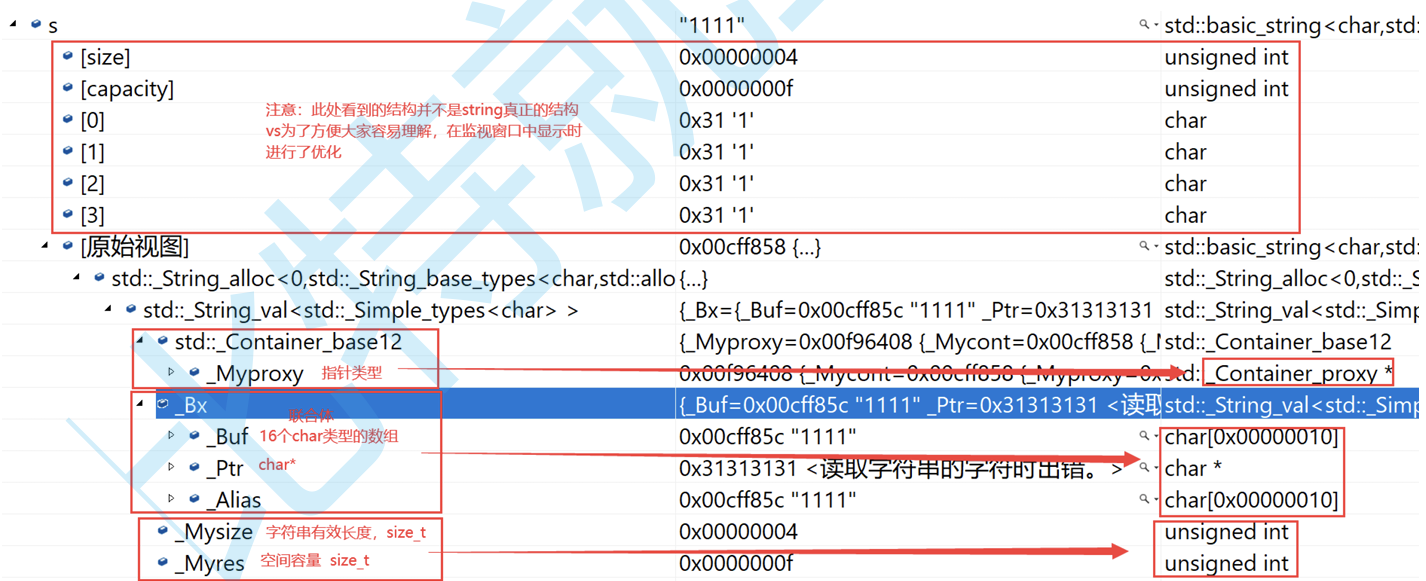
VS下string结构说明
string总共28个字节。内部结构相对复杂,先是一个联合体,联合体来定义string中字符串的存储空间:
当字符串长度小于16时,使用内部固定的字符数组来存放
当字符串长度大于16时,从堆上申请空间
union _Bxty
{//小的字符串长度value_type _Bxty[_BUF_SIZE];pointer _Ptr;char _Alias[_BUF_SIZE]
}_Bx;这种设计也是有道理的。大多数情况下字符串长度小于16,那么string对象创建好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高
其次还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间的总容量
最后还有一个指针做其他的事情
故总共16+4+4+4=28字节
string下string结构说明
g++下string是通过写时拷贝实现的。string对象总共占4个字节,内部只包含一个指针,该指针将用来指向一块堆空间,南北部包含了如下字段:
1、空间总大小
2、字符串长度
3、引用计数
4、指向堆空间的指针,用来存储字符串
struct _ReP_base
{size_type _M_length;size_type _M_capacity;_ATomic_word _M_refcount;
};
以上就是本次的博客内容,接下来我们将着手于string常用接口的模拟实现,敬请期待
在这里求一个点赞,谢谢
封面自取:
