连接表、视图和存储过程

1. 视图
1.1. 视图的概念
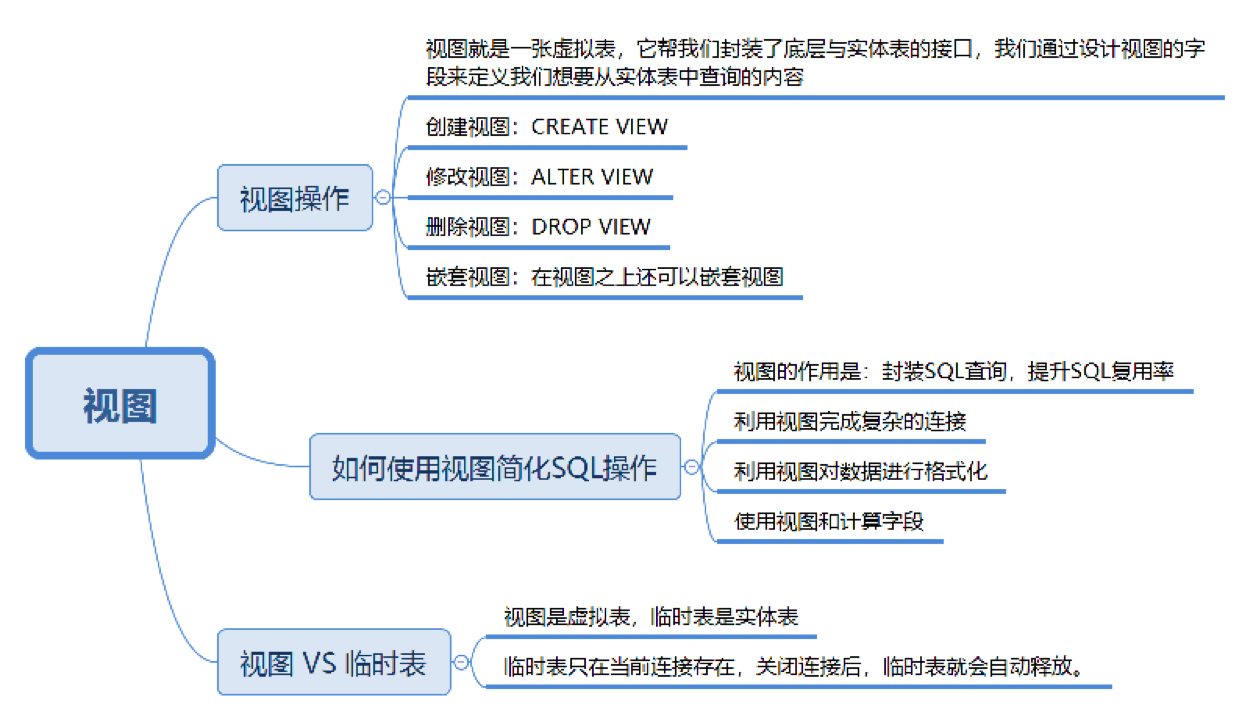
视图(View):虚拟表,本身不存储数据,而是封装了一个 SQL 查询的结果集。
用途:
- 只显示部分数据,提高数据访问的安全性。
- 简化复杂查询,提高复用性和可维护性。
- 可为不同用户提供不同的数据视图。
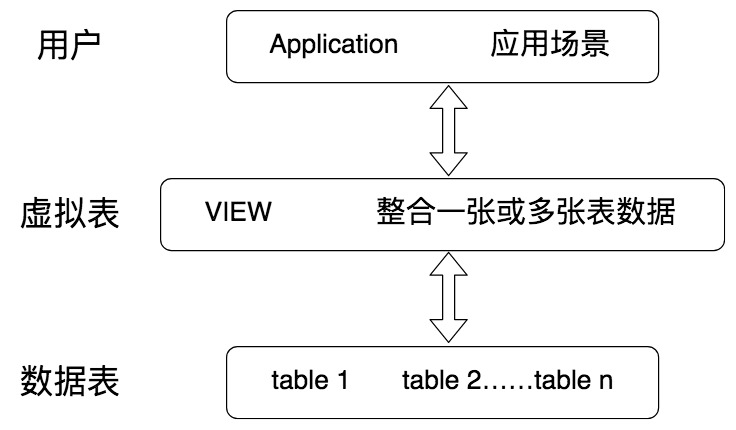
虚拟表的创建连接了一个或多个数据表,不同的查询应用都可以建立在虚拟表之上。
1.2. 创建、更新和删除视图
1. 创建视图:CREATE VIEW
CREATE VIEW view_name AS
SELECT column1, column2
FROM table
WHERE condition;嵌套视图:
当创建好一张视图之后,还可以在它的基础上继续创建视图。
2. 修改视图:ALTER VIEW
ALTER VIEW view_name AS
SELECT column1, column2
FROM table
WHERE condition3. 删除视图:DROP VIEW
DROP VIEW view_name1.3. 用视图简化SQL操作
1. 复杂连接视图封装
✅ 示例:封装球员与身高等级的连接
CREATE VIEW player_height_grades AS
SELECT p.player_name, p.height, h.height_level
FROM player AS p
JOIN height_grades AS h
ON p.height BETWEEN h.height_lowest AND h.height_highest;查询:
SELECT * FROM player_height_grades WHERE height BETWEEN 1.90 AND 2.08;2. 格式化输出视图
✅ 示例:拼接球员姓名和球队名称
CREATE VIEW player_team AS
SELECT CONCAT(player_name, '(', team.team_name, ')') AS player_team
FROM player JOIN team
ON player.team_id = team.team_id;3. 计算字段封装
✅ 示例:统计球员比赛得分组成
CREATE VIEW game_player_score AS
SELECT game_id, player_id,(shoot_hits - shoot_3_hits)*2 AS shoot_2_points,shoot_3_hits*3 AS shoot_3_points,shoot_p_hits AS shoot_p_points,score
FROM player_score;1.4. 视图的优点、与临时表的区别
视图的优点:
1. 安全性:
- 视图通常为只读,避免误改数据。
- 可基于权限控制字段访问。
2. 简洁性与复用性:
- 简化复杂 SQL。
- 可嵌套定义,便于模块化管理。
视图与临时表的区别:
| 特性 | 视图(View) | 临时表(Temporary Table) |
| 是否存储数据 | 否,虚拟表,实时查询结果 | 是,存储在临时空间 |
| 生命周期 | 持久存在(除非 DROP) | 仅当前会话存在,连接关闭即消失 |
| 用途 | 封装查询逻辑,数据隔离 | 存放临时数据,如中间计算结果 |
| 支持修改数据 | 限制较多(如包含聚合、连接) | 支持普通数据操作(增删改查) |
| 索引支持 | 大多不支持索引 | 通常支持索引 |
示例应用场景:
视图:给销售人员只显示价格、销量,不显示成本。
临时表:购物车临时保存每个用户选购的商品数据。
2. 存储过程 Stored Procedure
2.1. 存储过程的定义
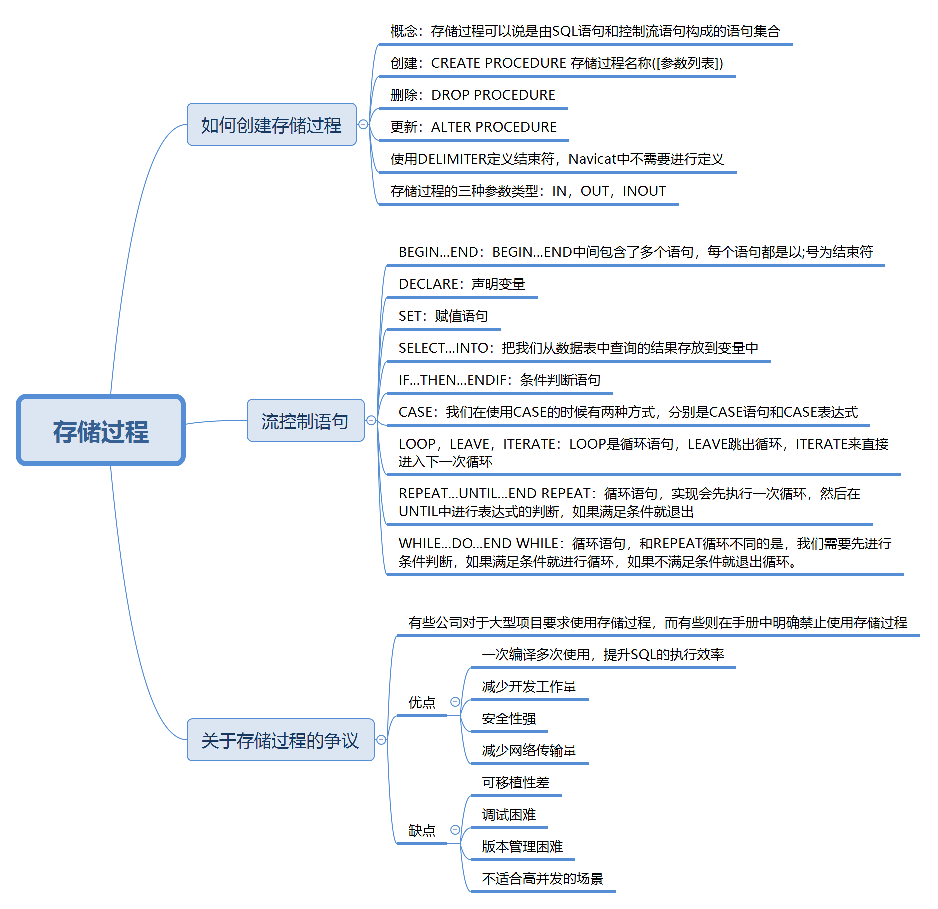
定义:SQL 中对一组语句的封装,可通过一次定义,多次调用,像函数一样执行。
结构组成:包含 SQL 语句、流控制语句(如循环、条件判断等)。
使用方式:
CREATE PROCEDURE proc_name ([参数])
BEGIN-- 语句块
END2.2. 存储过程的优缺点
优点:
| ✅ 1. 一次编译,多次执行 | 提前编译后存储在数据库中,后续调用无需重新解析,提高执行效率。 |
| ✅ 2. 封装逻辑,提升复用性 | 可将复杂逻辑封装成过程,结构清晰、易于维护与复用,有利于模块化开发。 |
| ✅ 3. 减少开发工作量 | 开发者只需调用过程,避免重复写 SQL,提高开发效率。 |
| ✅ 4. 增强数据安全性 | 可设置权限控制,用户只能访问授权存储过程,不直接操作底层表。 |
| ✅ 5. 降低网络通信成本 | 客户端只需一次调用,无需多次发送复杂 SQL,节省网络带宽与响应时间。 |
| ✅ 6. 适合执行复杂业务逻辑 | 封装控制流程(IF、LOOP、CASE)更容易组织复杂业务规则。 |
缺点:
| ⚠️ 1. 可移植性差 | 不同数据库的语法和支持程度不同(如 MySQL 与 Oracle 存储过程差异大),跨平台迁移困难。 |
| ⚠️ 2. 调试不方便 | 多数数据库缺少完善的调试工具,过程内错误排查困难,调试成本高。 |
| ⚠️ 3. 版本管理困难 | 存储过程通常不受代码版本控制系统(如 Git)管理,迭代不透明、易错难追踪。 |
| ⚠️ 4. 维护成本高 | 对团队协作和文档要求高,逻辑变更需谨慎更新过程,否则容易造成逻辑失效。 |
| ⚠️ 5. 不适合高并发环境 | 高并发场景更强调可扩展性与解耦,存储过程绑定数据库逻辑,难以灵活应对分库分表等架构。 |