Spark 中,创建 DataFrame 的方式(Scala语言)
在 Spark 中,创建 DataFrame 的方式多种多样,可根据数据来源、结构特性及性能需求灵活选择。
一、创建 DataFrame 的 12 种核心方式
1. 从 RDD 转换(需定义 Schema)
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._val spark = SparkSession.builder().master("local").getOrCreate()
val sc = spark.sparkContext// 创建RDD
val rdd = sc.parallelize(Seq((1, "Alice", 25),(2, "Bob", 30)
))// 方式1:通过StructType手动定义Schema
val schema = StructType(Seq(StructField("id", IntegerType, nullable = false),StructField("name", StringType, nullable = true),StructField("age", IntegerType, nullable = true)
))// 将RDD转换为Row RDD
val rowRDD = rdd.map(t => Row(t._1, t._2, t._3))// 应用Schema创建DataFrame
val df1 = spark.createDataFrame(rowRDD, schema)// 方式2:使用样例类(Case Class)自动推断Schema
case class Person(id: Int, name: String, age: Int)
val df2 = rdd.map(t => Person(t._1, t._2, t._3)).toDF()
2. 从 CSV 文件读取
// 基础读取
val csvDF = spark.read.csv("path/to/file.csv")// 高级选项
val csvDF = spark.read.option("header", "true") // 第一行为表头.option("inferSchema", "true") // 自动推断数据类型.option("delimiter", ",") // 指定分隔符.option("nullValue", "NULL") // 指定空值标识.option("dateFormat", "yyyy-MM-dd")// 指定日期格式.csv("path/to/file.csv")
3. 从 JSON 文件读取
// 基础读取
val jsonDF = spark.read.json("path/to/file.json")// 多Line JSON
val multiLineDF = spark.read.option("multiLine", "true").json("path/to/multi-line.json")// 从JSON字符串RDD创建
val jsonRDD = sc.parallelize(Seq("""{"name":"Alice","age":25}""","""{"name":"Bob","age":30}"""
))
val jsonDF = spark.read.json(jsonRDD)
4. 从 Parquet 文件读取(Spark 默认格式)
// 基础读取
val parquetDF = spark.read.parquet("path/to/file.parquet")// 读取多个路径
val multiPathDF = spark.read.parquet("path/to/file1.parquet", "path/to/file2.parquet"
)// 分区过滤(仅读取符合条件的分区)
val partitionedDF = spark.read.parquet("path/to/table/year=2023/month=05")
5. 从 Hive 表查询
// 创建支持Hive的SparkSession
val spark = SparkSession.builder().appName("HiveExample").config("hive.metastore.uris", "thrift://localhost:9083").enableHiveSupport().getOrCreate()// 查询Hive表
val hiveDF = spark.sql("SELECT * FROM employees")// 创建临时视图
spark.sql("CREATE TEMP VIEW temp_table AS SELECT * FROM employees")
val viewDF = spark.table("temp_table")
6. 从 JDBC 连接读取
// 连接MySQL
val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/mydb").option("driver", "com.mysql.jdbc.Driver").option("dbtable", "employees").option("user", "root").option("password", "password").option("fetchsize", "1000") // 控制每次读取的行数.option("numPartitions", "4") // 并行读取的分区数.load()// 带条件查询
val conditionDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/mydb").option("query", "SELECT * FROM employees WHERE department = 'IT'").load()
7. 从内存集合手动构建
// 方式1:使用createDataFrame + 元组
val data = Seq((1, "Alice", 25),(2, "Bob", 30)
)
val df = spark.createDataFrame(data).toDF("id", "name", "age")// 方式2:使用createDataFrame + Row + Schema
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._val rows = Seq(Row(1, "Alice", 25),Row(2, "Bob", 30)
)val schema = StructType(Seq(StructField("id", IntegerType, nullable = false),StructField("name", StringType, nullable = true),StructField("age", IntegerType, nullable = true)
))val df = spark.createDataFrame(spark.sparkContext.parallelize(rows), schema)// 方式3:使用toDF(需导入隐式转换)
import spark.implicits._
val df = Seq((1, "Alice"),(2, "Bob")
).toDF("id", "name")
8. 从其他数据源(Avro、ORC 等)
// 从Avro文件读取(需添加Avro依赖)
val avroDF = spark.read.format("avro").load("path/to/file.avro")// 从ORC文件读取
val orcDF = spark.read.orc("path/to/file.orc")// 从HBase读取(需使用连接器)
val hbaseDF = spark.read.format("org.apache.spark.sql.execution.datasources.hbase").option("hbase.table", "mytable").load()
9. 从 Kafka 流创建(结构化流)
val kafkaDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092").option("subscribe", "topic1").option("startingOffsets", "earliest").load()// 解析JSON消息
import org.apache.spark.sql.functions._
val parsedDF = kafkaDF.select(from_json(col("value").cast("string"), schema).as("data")).select("data.*")
10. 从现有 DataFrame 转换
val originalDF = spark.read.csv("data.csv")// 重命名列
val renamedDF = originalDF.withColumnRenamed("oldName", "newName")// 添加计算列
val newDF = originalDF.withColumn("agePlus10", col("age") + 10)// 过滤数据
val filteredDF = originalDF.filter(col("age") > 25)// 连接两个DataFrame
val joinedDF = df1.join(df2, Seq("id"), "inner")
11. 从 SparkSession.range 创建数字序列
// 创建从0到9的整数DataFrame
val rangeDF = spark.range(10) // 生成单列"id"的DataFrame// 指定起始值和结束值
val customRangeDF = spark.range(5, 15) // 生成5到14的整数// 指定步长和分区数
val steppedDF = spark.range(0, 100, 5, 4) // 步长为5,4个分区
12. 从空 DataFrame 创建(指定 Schema)
import org.apache.spark.sql.types._// 定义Schema
val schema = StructType(Seq(StructField("id", IntegerType, nullable = false),StructField("name", StringType, nullable = true)
))// 创建空DataFrame
val emptyDF = spark.createDataFrame(spark.sparkContext.emptyRDD[Row], schema)// 检查是否为空
if (emptyDF.isEmpty) {println("DataFrame is empty!")
}
二、创建 DataFrame 的方式总结图
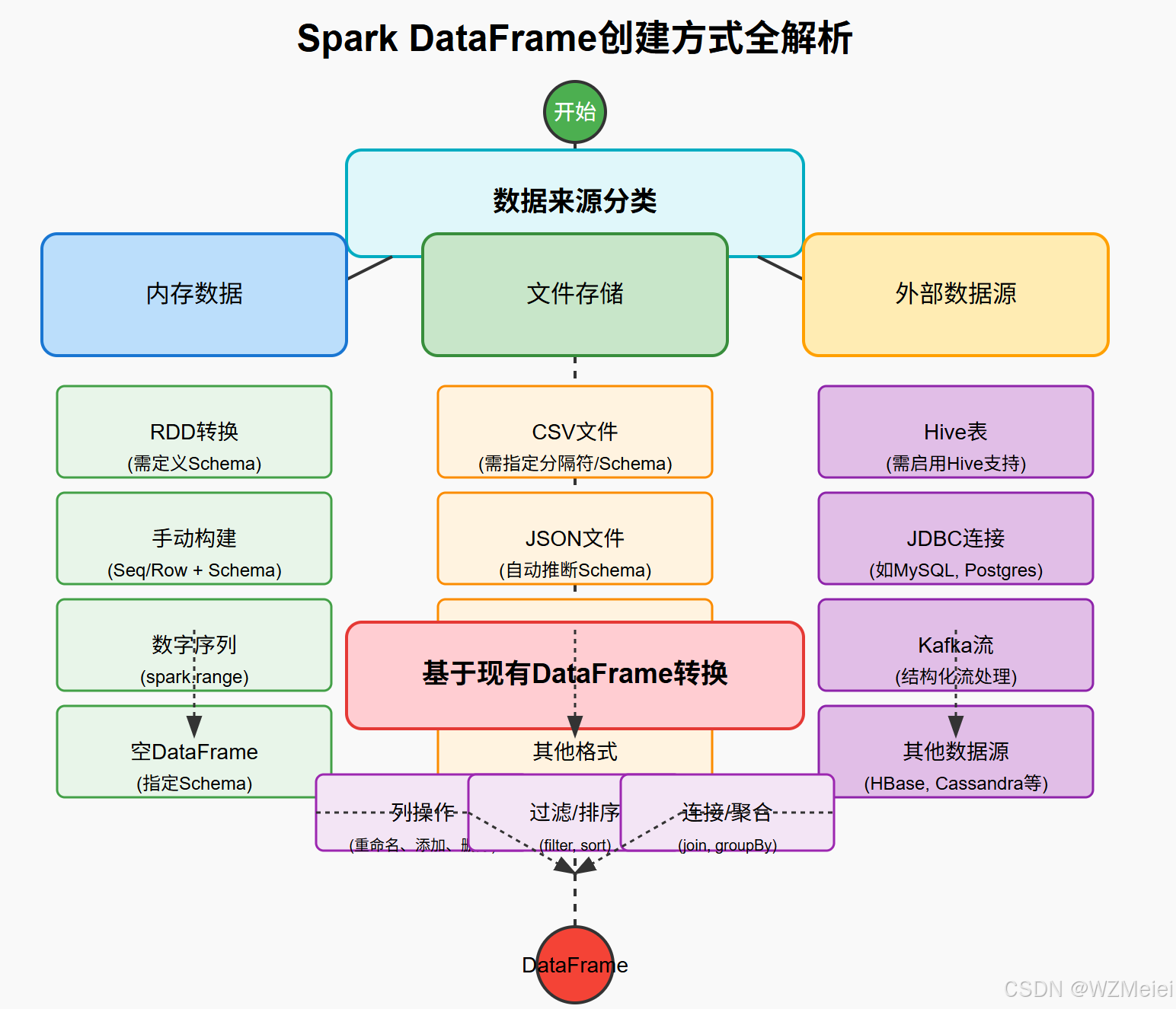
三、创建 DataFrame 的性能与场景对比
| 创建方式 | 适用场景 | 性能特点 | Schema 要求 |
|---|---|---|---|
| RDD 转换 | 已有 RDD,需结构化处理 | 需手动定义 Schema,性能取决于分区和数据量 | 必须手动定义(或通过样例类) |
| CSV/JSON 文件 | 从外部文件加载数据 | CSV 需解析,性能中等;JSON 需解析结构,大规模数据时较慢 | CSV 需手动指定,JSON 可自动推断 |
| Parquet 文件 | 大数据量存储与查询(Spark 默认格式) | 性能最优(列存储 + 压缩 + Schema) | 自带 Schema,无需额外定义 |
| Hive 表 / JDBC | 连接外部数据源 | 取决于数据源性能,需处理网络 IO | 从数据源获取 Schema |
| 手动构建(内存数据) | 测试或小规模数据 | 数据直接在内存,性能高,但数据量受驱动节点内存限制 | 需手动定义或通过样例类推断 |
| Kafka 流(结构化流) | 实时数据处理 | 流式处理,持续生成 DataFrame | 需定义消息格式(如 JSON Schema) |
| DataFrame 转换 | 基于现有 DataFrame 进行列操作、过滤、连接等变换 | 依赖于父 DataFrame 的性能,转换操作本身开销较小 | 继承或修改原有 Schema |
四、最佳实践建议
-
优先使用 Parquet:
- 对于中间数据存储和大规模查询,Parquet 格式性能最优。
-
避免频繁 Schema 推断:
- CSV/JSON 读取时,若数据量大且 Schema 固定,手动定义 Schema 可提升性能。
-
利用样例类简化开发:
- 从 RDD 或内存集合创建 DataFrame 时,使用样例类自动推断 Schema 可减少代码量。
-
合理配置 JDBC 参数:
- 通过
numPartitions和fetchsize控制并行度,避免数据倾斜。
- 通过
-
流式数据预解析:
- 从 Kafka 读取数据时,尽早解析 JSON/CSV 消息,避免后续重复解析。