大模型剪枝主流技术方案
1. 大模型剪枝概念
大模型剪枝是指对已经训练好的大型神经网络模型进行结构化或非结构化的简化操作,去除模型中对最终输出结果影响较小的部分(如神经元连接、权重等),从而减小模型的规模和计算复杂度,同时尽量保持模型原有的性能。
2. 大模型剪枝的原理
神经网络模型通常包含大量的参数和复杂的结构,但并非所有的参数和结构都对模型的预测结果起到关键作用。一些神经元之间的连接或者某些神经元的权重值非常小,在模型决策过程中贡献较低。剪枝的基本原理就是识别并去除这些不重要的部分,减少模型的冗余信息,降低计算资源的消耗。
3.大模型剪枝类型
3.1 非结构化剪枝
基于单个权重的重要性对模型中的权重进行剪枝,将绝对值较小的权重置为零,这些被置零的权重在后续的计算中可以被忽略,从而减少计算量。在一个全连接层中,如果某个权重值为 0.0001,而其他大部分权重的绝对值都在 0.1 以上,那么这个 0.0001 的权重可能对模型的输出影响较小,就可以将其剪掉。
非结构化剪枝的一些技术方案
3.1.1 Magnitude-based Pruning:
按权重绝对值排序剪枝(如SparseGPT剪枝60%参数仍保持低困惑度)。
论文名称:SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot
论文地址:
SparseGPT方法首次实现了对大规模GPT模型的高效无训练剪枝,能够在不显著损失精度的情况下实现高稀疏度。实验结果表明,SparseGPT在OPT-175B和BLOOM-176B等大规模模型上表现出色,能够实现50-60%的稀疏度,并且在零样本任务上表现接近原始模型。
SparseGPT通过将剪枝问题转化为一组超大规模的稀疏回归实例,并使用一种新的近似稀疏回归求解器来解决这些问题。该求解器能够在几小时内处理最大的开源GPT模型(如175B参数模型),并且准确度损失可以忽略不计。为了提高计算效率,SparseGPT采用了一种快速近似重构的方法。它通过迭代地应用OBS更新来逐步剪枝权重,而不是一次性计算所有权重的逆Hessian矩阵
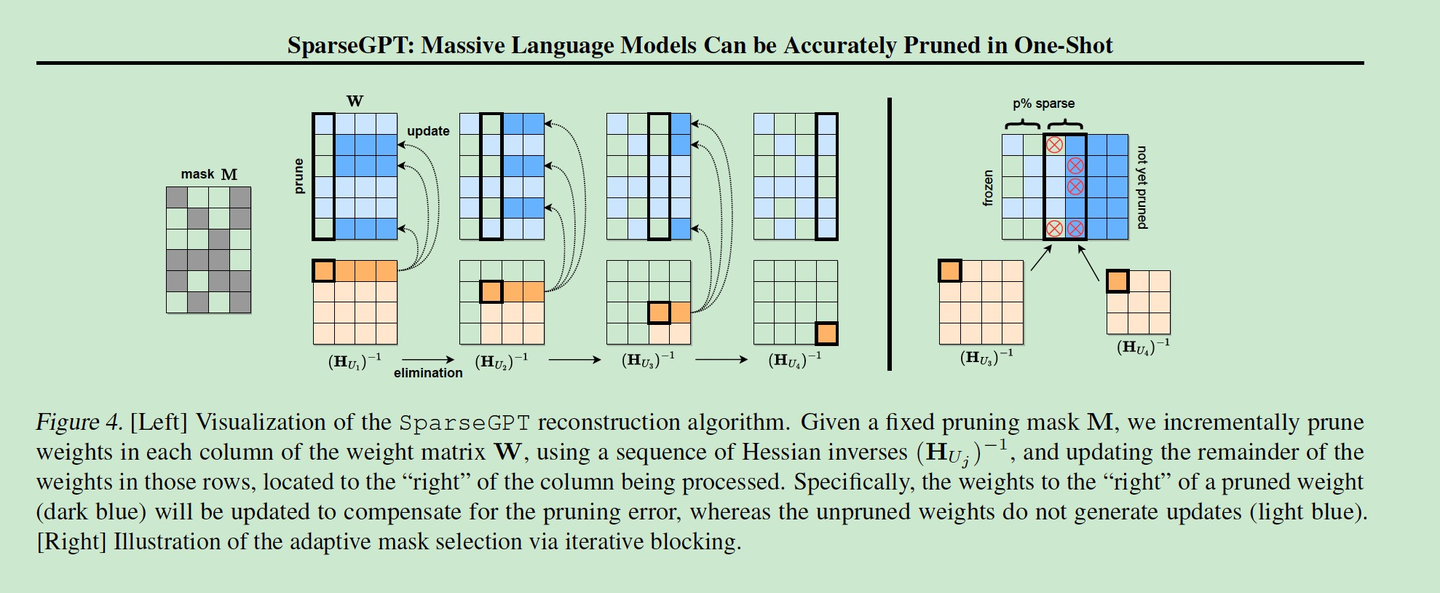
添加图片注释,不超过 140 字(可选)
3.1.2 LoRAPrune方法
’
LoRAPrune框架能够在高内存效率的情况下提供精确的结构化剪枝模型。LoRAPrune设计了一种基于LoRA的剪枝准则,利用LoRA的权重和梯度而不是预训练权重的梯度来估计重要性,并将其集成到迭代剪枝过程中,有效地移除冗余的通道和头。LoRAPrune提出了一种新的LoRA-guided剪枝准则,仅利用LoRA的权重和梯度来估计预训练权重的的重要性。
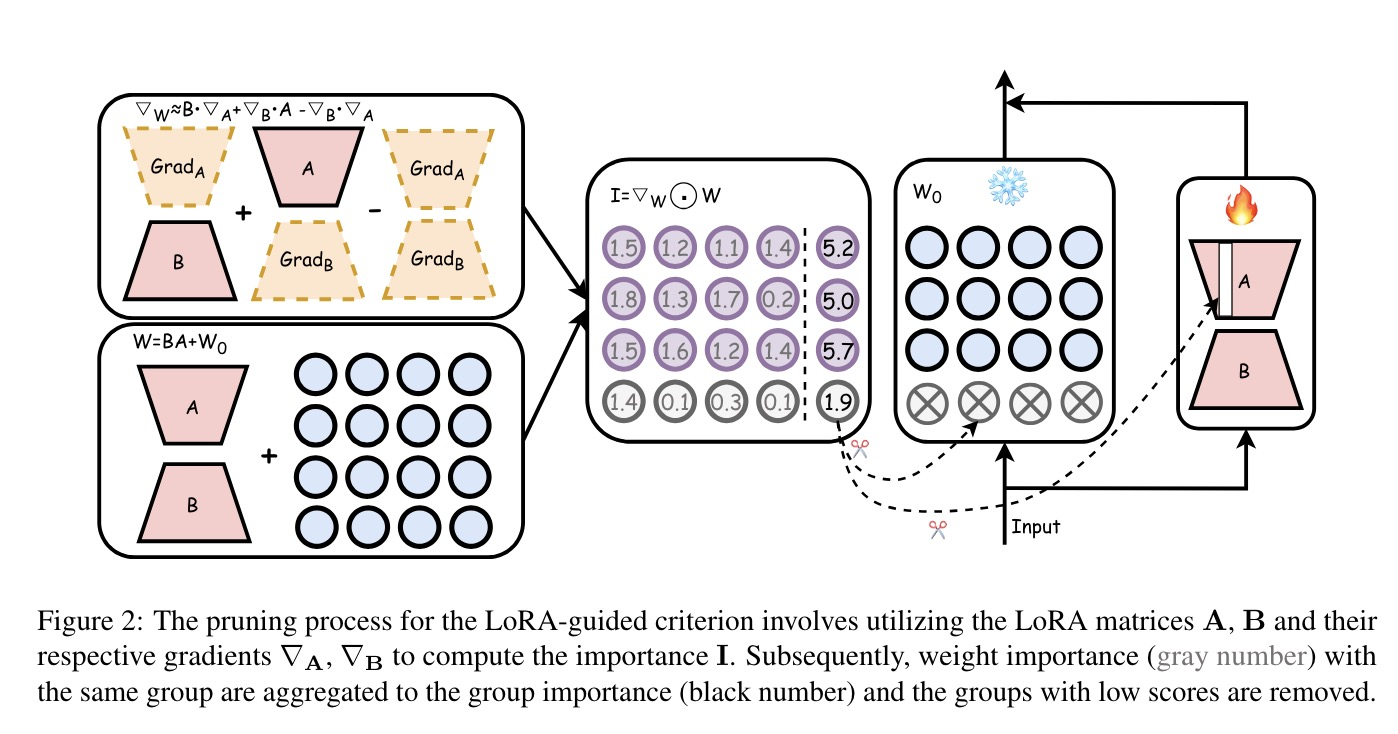
添加图片注释,不超过 140 字(可选)
论文名称: LoRAPrune: Structured Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
论文地址:
首先,设计了一种基于LoRA的剪枝标准,该标准利用LoRA的权重和梯度而不是预训练权重的梯度来进行重要性估计。公式如下

添加图片注释,不超过 140 字(可选)
其次,迭代剪枝过程:将上述剪枝标准集成到迭代剪枝过程中,逐步移除冗余通道和头。
-
初始化掩码和组重要性。
-
通过前向和后向传播计算损失,并使用AdamW优化器更新LoRA矩阵A和B。
-
计算每批次数据的重要性,并使用移动平均更新重要性。
-
每几次迭代后,移除不重要组的权重,直到达到目标稀疏度。
3.1.3 Wanda方法
论文名称: A SIMPLE AND EFFECTIVE PRUNING APPROACH FOR LARGE LANGUAGE MODELS
论文地址:
github地址:
在wanda这个方法出现之前,剪枝方法一个是基于权重的剪枝方法如大小剪枝,简单地根据权重的大小来决定是否保留权重。另外一种是基于激活的剪枝方法则根据神经元的输出统计量来决定是否删除整个神经元。Wanda提出了一种新的剪枝度量,结合了权重和输入激活。这种方法解决了传统大小剪枝方法未能考虑输入激活的问题,使得权重的重要性评分更加全面和准确。
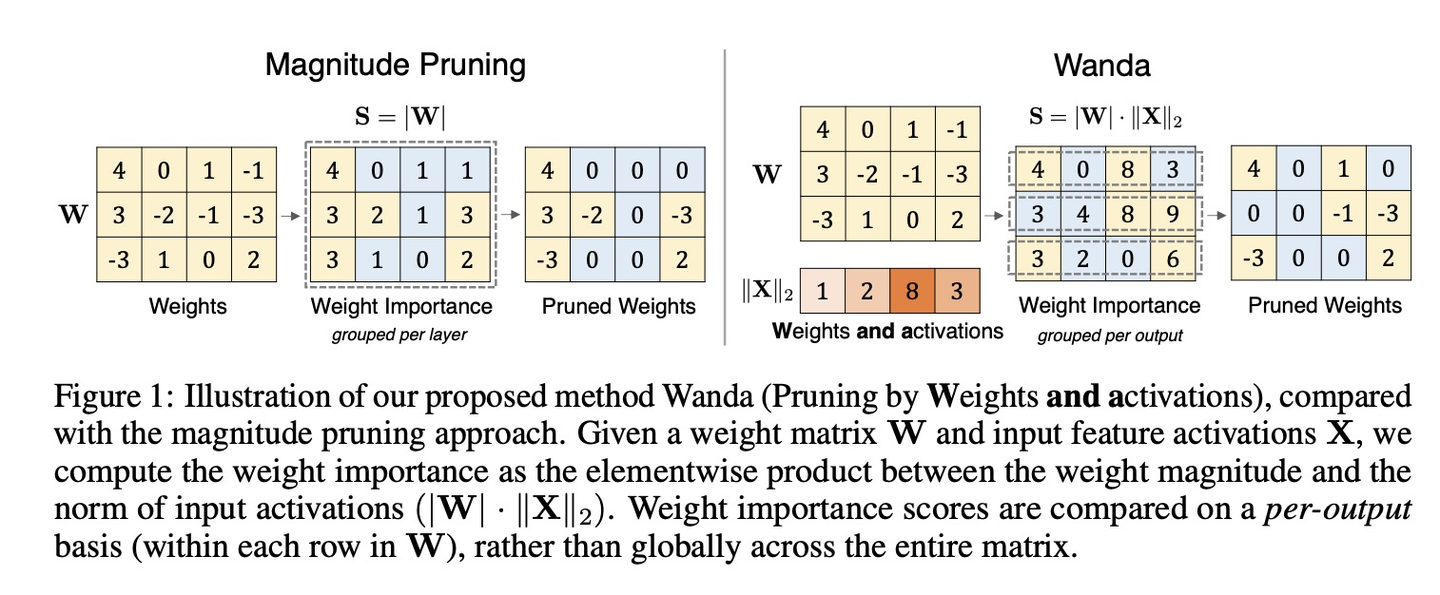
添加图片注释,不超过 140 字(可选)
总的来说wanda分为3步:
(1) 剪枝度量
每个权重的评分由其大小和对应输入激活的ℓ2范数乘积定义:其中,∣⋅∣表示绝对值运算符, 评估第j个特征的 范数, 解决了传统大小剪枝方法未能考虑输入激活的问题。
(2) 比较组:Wanda在每个输出上比较权重,而不是在整个层上进行比较。对于线性层中的每个权重 ,其比较组定义为连接到输出i的所有权重, 在这种比较组下,预定义的稀疏比S%的权重将被移除。
添加图片注释,不超过 140 字(可选)
(3) 前向传播实现:Wanda可以在单个前向传播过程中实现和集成。特征范数统计量 使用一组校准数据估计。
Wanda剪枝的具体方法在下面这个github链接里面:
wanda/lib/prune.py at main · locuslab/wanda · GitHub
为了方便我把核心的剪枝方法粘贴了出来,加了一点注释。
def prune_wanda(args, model, tokenizer, device=torch.device("cuda:0"), prune_n=0, prune_m=0):"""使用 Wanda 方法对 Transformer 模型进行剪枝参数:args: 包含配置参数的对象(如样本数量、稀疏度比例等)model: 要剪枝的 Transformer 模型tokenizer: 对应的分词器device: 运行设备(默认为 GPU)prune_n: 结构化剪枝参数 n(每 m 个权重保留 n 个)prune_m: 结构化剪枝参数 m(每 m 个权重中选择)"""# 保存原始缓存设置并禁用缓存(避免剪枝过程中受缓存影响)use_cache = model.config.use_cache model.config.use_cache = False print("loading calibration data")# 加载校准数据(假设 get_loaders 返回数据加载器和额外信息)dataloader, _ = get_loaders("c4", nsamples=args.nsamples, seed=args.seed, seqlen=model.seqlen, tokenizer=tokenizer)print("dataset loading complete")# 准备校准输入数据(输入张量、输出张量、注意力掩码、位置ID)with torch.no_grad():inps, outs, attention_mask, position_ids = prepare_calibration_input(model, dataloader, device)# 获取模型的所有层layers = model.model.layersfor i in range(len(layers)):layer = layers[i]# 找到当前层中需要剪枝的子模块(如线性层)subset = find_layers(layer)# 处理多 GPU 情况(如 LLaMA-30B 和 LLaMA-65B)if f"model.layers.{i}" in model.hf_device_map:dev = model.hf_device_map[f"model.layers.{i}"]# 将相关张量移动到对应的设备上inps, outs, attention_mask, position_ids = (inps.to(dev), outs.to(dev), attention_mask.to(dev), position_ids.to(dev))# 包装需要剪枝的层(用于记录前向传播时的激活值)wrapped_layers = {}for name in subset:wrapped_layers[name] = WrappedGPT(subset[name])# 定义前向钩子函数(用于捕获激活值)def add_batch(name):def tmp(_, inp, out):wrapped_layers[name].add_batch(inp[0].data, out.data)return tmp# 注册前向钩子handles = []for name in wrapped_layers:handles.append(subset[name].register_forward_hook(add_batch(name)))# 使用校准数据进行前向传播(收集激活值)for j in range(args.nsamples):with torch.no_grad():outs[j] = layer(inps[j].unsqueeze(0), attention_mask=attention_mask, position_ids=position_ids)[0]# 移除前向钩子for h in handles:h.remove()# 对当前层的每个子模块进行剪枝for name in subset:print(f"pruning layer {i} name {name}")# 计算权重的重要性指标 W_metric# 结合权重的绝对值和激活值的度量(scaler_row),这一段是核心W_metric = torch.abs(subset[name].weight.data) * \torch.sqrt(wrapped_layers[name].scaler_row.reshape((1,-1)))# 初始化剪枝掩码(全 False 表示不剪枝)W_mask = (torch.zeros_like(W_metric) == 1)# 结构化剪枝(n:m 稀疏度)if prune_n != 0:# 每 m 个权重中保留 n 个for ii in range(W_metric.shape[1]):if ii % prune_m == 0:# 获取当前 m 个权重中的最小 n 个tmp = W_metric[:,ii:(ii+prune_m)].float()# 设置剪枝掩码(True 表示剪枝)W_mask.scatter_(1, ii + torch.topk(tmp, prune_n, dim=1, largest=False)[1], True)else:# 非结构化剪枝(按重要性排序后剪枝)sort_res = torch.sort(W_metric, dim=-1, stable=True)# 使用 Wanda 变体方法(调整稀疏度)if args.use_variant:# 计算累积和和总和tmp_metric = torch.cumsum(sort_res[0], dim=1)sum_before = W_metric.sum(dim=1)# 初始化 alpha 和历史范围alpha = 0.4alpha_hist = [0., 0.8]# 调用 return_given_alpha 函数生成初始剪枝掩码和稀疏度W_mask, cur_sparsity = return_given_alpha(alpha, sort_res, W_metric, tmp_metric, sum_before)# 二分搜索调整 alpha 以满足目标稀疏度while (torch.abs(cur_sparsity - args.sparsity_ratio) > 0.001) and \(alpha_hist[1] - alpha_hist[0] >= 0.001):if cur_sparsity > args.sparsity_ratio:alpha_new = (alpha + alpha_hist[0]) / 2.0alpha_hist[1] = alphaelse:alpha_new = (alpha + alpha_hist[1]) / 2.0alpha_hist[0] = alphaalpha = alpha_new W_mask, cur_sparsity = return_given_alpha(alpha, sort_res, W_metric, tmp_metric, sum_before)print(f"alpha found {alpha} sparsity {cur_sparsity:.6f}")else:# 未使用变体方法:直接按排序结果剪枝# 选择前 args.sparsity_ratio * 100% 的最小权重进行剪枝indices = sort_res[1][:, :int(W_metric.shape[1] * args.sparsity_ratio)]W_mask.scatter_(1, indices, True)# 应用剪枝掩码(将标记为 True 的权重置零)subset[name].weight.data[W_mask] = 0 # 剪枝后再次进行前向传播(验证剪枝效果,但未使用输出结果)for j in range(args.nsamples):with torch.no_grad():outs[j] = layer(inps[j].unsqueeze(0), attention_mask=attention_mask, position_ids=position_ids)[0]# 交换输入输出张量(目的不明确,可能需要结合上下文确认)inps, outs = outs, inps# 恢复原始缓存设置model.config.use_cache = use_cache # 清理 GPU 显存torch.cuda.empty_cache()##计算稀疏度
def check_sparsity(model):"""检查 Transformer 模型的稀疏度(sparsity)稀疏度定义为模型中权重为零的比例,用于衡量模型剪枝或稀疏化的效果。参数:model: 要检查稀疏度的 Transformer 模型(如 Hugging Face 的 transformers 模型)返回:float: 整个模型的全局稀疏度(所有参数中为零的比例)"""# 保存原始缓存设置并禁用缓存(避免剪枝过程中受缓存影响)use_cache = model.config.use_cache model.config.use_cache = False # 获取模型的所有层(假设模型是 Transformer 架构,model.model.layers 是各层的列表)layers = model.model.layers# 初始化全局计数器count = 0 # 全局零权重的总数total_params = 0 # 全局参数的总数# 遍历每一层for i in range(len(layers)):layer = layers[i]# 找到当前层中需要检查的子模块(如线性层、卷积层等)# 假设 find_layers 是一个自定义函数,返回当前层中可剪枝的子模块字典subset = find_layers(layer)# 初始化当前层的计数器sub_count = 0 # 当前层零权重的数量sub_params = 0 # 当前层参数的总数# 遍历当前层的每个子模块for name in subset:# 获取当前子模块的权重矩阵(假设子模块有 weight 属性)W = subset[name].weight.data# 累加全局零权重数和总参数数count += (W == 0).sum().item() # 计算当前权重矩阵中零值的数量,并累加到全局计数器total_params += W.numel() # 计算当前权重矩阵的总参数数量,并累加到全局计数器# 累加当前层的零权重数和总参数数sub_count += (W == 0).sum().item() # 计算当前权重矩阵中零值的数量,并累加到当前层计数器sub_params += W.numel() # 计算当前权重矩阵的总参数数量,并累加到当前层计数器# 打印当前层的稀疏度# 稀疏度 = 当前层零权重数 / 当前层总参数数print(f"layer {i} sparsity {float(sub_count)/sub_params:.6f}")# 恢复原始缓存设置model.config.use_cache = use_cache # 计算并返回整个模型的全局稀疏度# 全局稀疏度 = 全局零权重总数 / 全局总参数数return float(count) / total_params
在零样本任务中,Wanda在非结构性和结构化稀疏性上均显著优于大小剪枝方法,并且与最优方法SparseGPT竞争。例如,非结构化50%稀疏的LLaMA-65B和LLaMA-2-70B的零样本准确率分别达到了66.67%和67.03%,接近其密集对应模型的准确率。
3.2 结构化剪枝
以更大的粒度进行剪枝,如剪掉整个神经元、卷积核或者通道等。这种剪枝方式可以直接改变模型的结构,使得剪枝后的模型在硬件上更容易实现加速。
3.2.1 LLM-Pruner
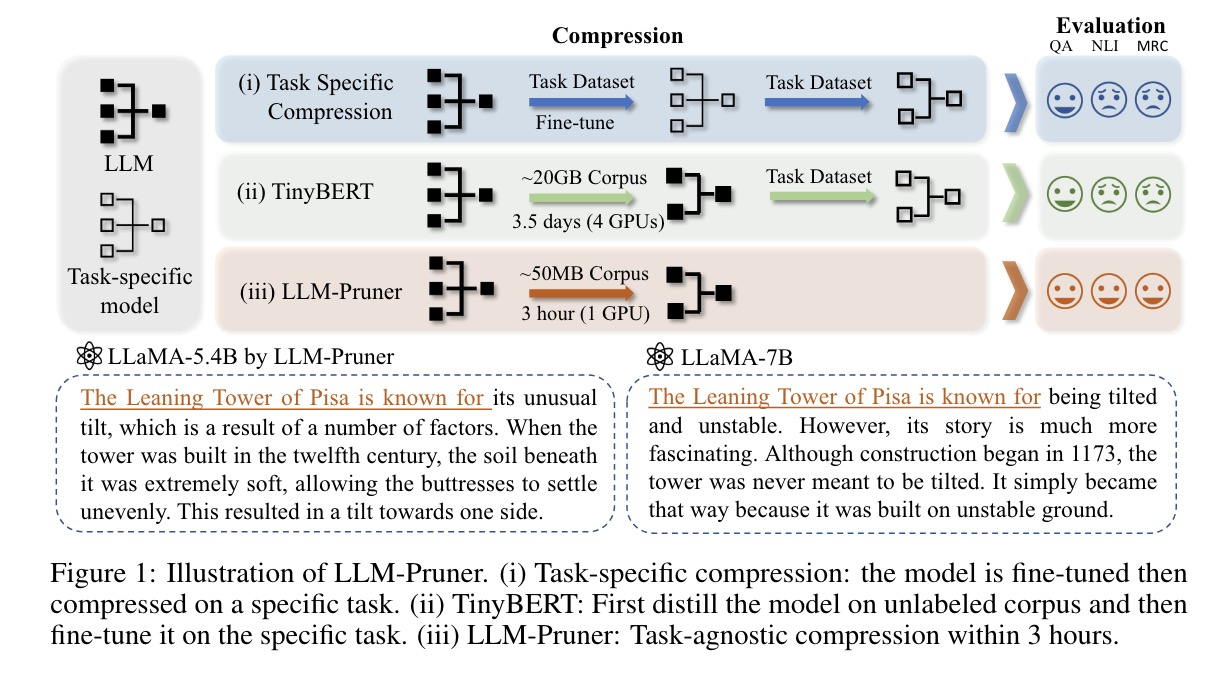
添加图片注释,不超过 140 字(可选)
论文名称:LLM-Pruner: On the Structural Pruning of Large Language Models
论文地址:
github地址:
这篇论文提出了LLM-Pruner,一种用于大规模语言模型任务无关压缩的新框架。LLM-Pruner通过构建依赖关系图、估计依赖组的重要性,并采用LoRA技术进行快速后训练,实现了模型的有效压缩。实验结果表明,LLM-Pruner在保留模型零样本能力的同时,显著减少了计算负担。然而,高剪枝率(如移除50%的参数)仍会导致显著的模型性能下降。未来的研究将继续探索更高剪枝率的压缩方法。
剪枝的核心思想分为3个阶段:
阶段1: 发现阶段,这一个阶段主要是构造依赖图。首先,构建LLMs中所有相互依赖结构的依赖关系图。假设Ni和Nj是模型中的两个神经元,In( )和Out( )分别表示指向或来自 的所有神经元。依赖关系定义为
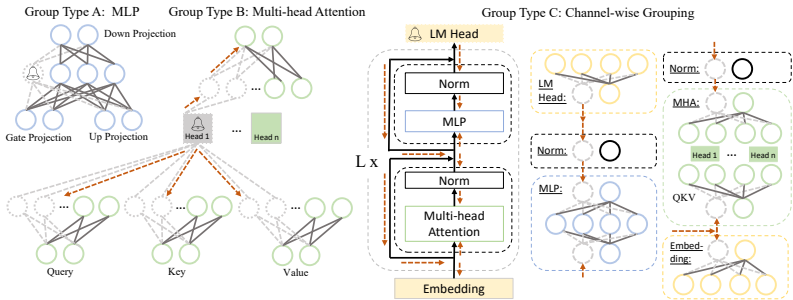
添加图片注释,不超过 140 字(可选)
阶段2 估计阶段: 在依赖关系图构建完成后,估计每个依赖组的整体重要性,并决定哪些组需要剪枝。由于训练数据受限,采用公共数据集或手动创建的样本作为替代资源。重要性估计公式为:

添加图片注释,不超过 140 字(可选)
其中,L表示下一个token预测损失,H是Hessian矩阵。由于D不是从原始训练数据中提取的,因此∂L⊤/∂Wi≈0,这使得通过梯度项确定Wi的重要性成为可能
阶段3 恢复阶段:为了加快模型恢复过程,采用低秩近似(LoRA)技术进行快速后训练。每个可学习权重矩阵W可以表示为W=PQ,其中P和Q是新的参数矩阵。其中,b是密集层的偏置。通过仅训练P和Q,减少了整体训练复杂度。前向计算可以表示为:
f(x)=(W+ΔW)X+b=(WX+b)+(PQ)X
效果分析
在LLaMA-7B上,剪枝20%的参数后,模型在七个分类数据集上的平均性能保留了94.97%。在Vicuna-7B上,剪枝20%的参数后,模型性能保留了92.03%。在ChatGLM-6B上,剪枝10%的参数后,模型性能仅下降了0.89%。
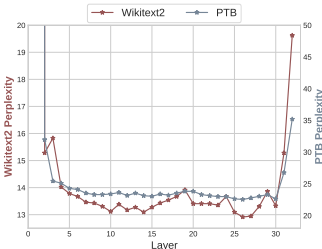
添加图片注释,不超过 140 字(可选)
3.2.2 裁剪大模型固定位置
通过裁剪大模型固定位置的方法。目标结构化剪枝,通过以端到端方式移除层、头部以及中间和隐藏维度,将较大模型剪枝为指定的目标形状;动态批量加载,根据跨不同领域的不同损失动态更新每个训练批次中采样数据的组成。
论文名称: SHEARED LLAMA: ACCELERATING LANGUAGE MODEL PRE-TRAINING VIA STRUCTURED PRUNING
论文地址:

添加图片注释,不超过 140 字(可选)
目标结构化剪枝:
该方法旨在将源模型剪枝为目标架构。目标架构是通过利用现有预训练模型的配置来确定的。具体步骤如下:
定义不同粒度的剪枝掩码变量,包括层、隐藏维度、注意力头和中间维度。
使用ℓ0正则化方法参数化剪枝掩码,以学习硬混凝土分布。这些分布在[0,1]上有支持,但在0或1处集中概率质量,从而实现离散剪枝或保留决策。
通过最小化最大目标 , (θ,z,λ,ϕ)来联合优化模型权重和剪枝掩码. 其中,L(θ,z)是使用掩码模型权重计算的语言建模损失。
θ:模型的参数。
z, φ, λ:剪枝过程中使用的掩码变量和拉格朗日乘子。
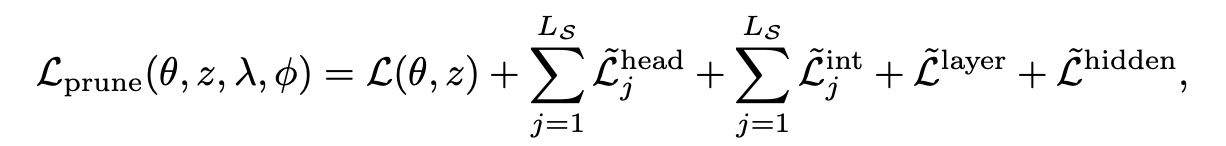
添加图片注释,不超过 140 字(可选)
动态批处理加载
为了有效利用数据并加速整体性能提升,提出了一种动态批处理加载算法。该算法根据每个域的损失率动态调整训练数据的比例.

动态批处理加载
1)在每个训练步骤中,评估模型在验证集上的损失,并根据损失差异更新数据加载比例。
2) 使用指数上升算法调整数据比例,以确保模型在各个域上的损失达到参考值。
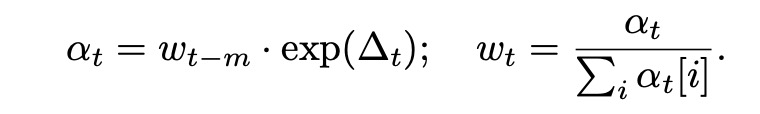
添加图片注释,不超过 140 字(可选)
用python表示一下
import numpy as npclass DynamicBatchLoader:def __init__(self, domain_weights, reference_losses, scaling_reference=True):"""初始化动态批处理加载器参数:domain_weights (dict): 初始各域的数据权重 {'domain1': w1, 'domain2': w2, ...}reference_losses (dict): 各域的参考损失 {'domain1': ref_loss1, 'domain2': ref_loss2, ...}scaling_reference (bool): 是否使用缩放参考损失(默认为True)"""self.domain_weights = domain_weightsself.reference_losses = reference_lossesself.scaling_reference = scaling_referenceself.current_weights = domain_weights.copy()def calculate_loss_difference(self, current_losses):"""计算当前损失与参考损失的差异参数:current_losses (dict): 当前各域的验证损失 {'domain1': loss1, 'domain2': loss2, ...}返回:dict: 损失差异 {'domain1': diff1, 'domain2': diff2, ...}"""loss_diff = {}for domain in current_losses:if self.scaling_reference:# 使用缩放参考损失ref_loss = self.reference_losses[domain]else:# 使用源模型参考损失(这里简化为初始权重对应的损失)# 实际应用中可能需要更复杂的计算ref_loss = self.reference_losses.get(domain, 1.0) # 默认值1.0loss_diff[domain] = max(current_losses[domain] - ref_loss, 0)return loss_diffdef update_weights(self, loss_diff):"""根据损失差异更新权重参数:loss_diff (dict): 损失差异 {'domain1': diff1, 'domain2': diff2, ...}"""# 计算调整因子adjusted_weights = {}total = 0for domain in self.current_weights:if domain in loss_diff:# 指数上升调整adjusted_weights[domain] = self.current_weights[domain] * np.exp(loss_diff[domain])else:adjusted_weights[domain] = self.current_weights[domain]total += adjusted_weights[domain]# 归一化权重self.current_weights = {d: w/total for d, w in adjusted_weights.items()}def get_batch_proportions(self):"""获取当前批次比例返回:dict: 当前各域的批次比例 {'domain1': p1, 'domain2': p2, ...}"""return self.current_weightsdef load_batch(self, all_domains_data, batch_size):"""根据当前权重从各域加载数据参数:all_domains_data (dict): 各域的数据 {'domain1': data1, 'domain2': data2, ...}batch_size (int): 批次大小返回:dict: 当前批次的样本 {'domain1': samples1, 'domain2': samples2, ...}"""proportions = self.get_batch_proportions()batch = {}for domain, proportion in proportions.items():if domain in all_domains_data:# 根据比例随机采样domain_data = all_domains_data[domain]sample_size = int(proportion * batch_size)if sample_size > 0:# 这里简化为随机采样,实际可能需要更复杂的采样策略batch_samples = np.random.choice(domain_data, size=sample_size, replace=False)batch[domain] = batch_samples# 确保总样本数等于batch_size(简单处理,可能需要更复杂的平衡)total_samples = sum(len(v) for v in batch.values())if total_samples < batch_size:# 如果样本不足,从所有域补充remaining = batch_size - total_samplesall_data = []for domain in all_domains_data:all_data.extend(all_domains_data[domain])if all_data:additional_samples = np.random.choice(all_data, size=remaining, replace=False)# 需要将additional_samples分配回各域(这里简化处理)# 实际应用中可能需要更复杂的分配策略for i, sample in enumerate(additional_samples):domain = list(all_domains_data.keys())[i % len(all_domains_data)]if domain not in batch:batch[domain] = []batch[domain].append(sample)return batch# 示例用法
if __name__ == "__main__":# 初始化各域权重和参考损失domain_weights = {'CommonCrawl': 0.4,'GitHub': 0.05,'Books': 0.05,'StackExchange': 0.02,'Wiki': 0.05,'ArXiv': 0.025,'C4': 0.4}reference_losses = {'CommonCrawl': 1.0,'GitHub': 0.5,'Books': 0.8,'StackExchange': 0.7,'Wiki': 0.75,'ArXiv': 0.6,'C4': 0.9}# 创建动态批处理加载器loader = DynamicBatchLoader(domain_weights, reference_losses)# 模拟各域数据(实际应用中应该是真实数据)all_domains_data = {'CommonCrawl': list(range(1000)),'GitHub': list(range(100)),'Books': list(range(100)),'StackExchange': list(range(50)),'Wiki': list(range(100)),'ArXiv': list(range(50)),'C4': list(range(1000))}# 模拟当前损失(实际应用中应该是验证集上的损失)current_losses = {'CommonCrawl': 0.8,'GitHub': 0.4,'Books': 0.7,'StackExchange': 0.6,'Wiki': 0.65,'ArXiv': 0.5,'C4': 0.7}# 更新权重loss_diff = loader.calculate_loss_difference(current_losses)loader.update_weights(loss_diff)# 获取当前批次比例print("当前批次比例:", loader.get_batch_proportions())# 加载批次数据batch = loader.load_batch(all_domains_data, batch_size=128)print("各域样本数:", {k: len(v) for k, v in batch.items()})# 这段代码实现了动态批处理加载的核心逻辑:"""DynamicBatchLoader 类封装了动态批处理加载的功能
calculate_loss_difference 方法计算当前损失与参考损失的差异
update_weights 方法根据损失差异更新各域权重
get_batch_proportions 方法返回当前批次比例
load_batch 方法根据权重从各域加载数据
示例用法展示了如何初始化加载器、计算损失差异、更新权重并加载批次数据。实际应用中需要根据具体数据和需求进行调整,特别是数据采样部分可能需要更复杂的策略来确保批次内数据的平衡性。"""3.2.3 结构感知自适应剪枝(SAAP)
SAAP是比较新颖的LLM模型剪枝方法,即结构感知自适应剪枝(SAAP),以显著降低计算和内存成本,同时保持模型性能。SAAP遵循由三个阶段构成的结构化剪枝过程,即发现阶段、估计阶段和恢复阶段。发现阶段识别LLM中的所有组,而估计阶段和恢复阶段分别评估每个组的重要性并恢复模型性能。
论文名称:Adaptive Pruning for Large Language Models with Structural Importance Awareness
论文地址:
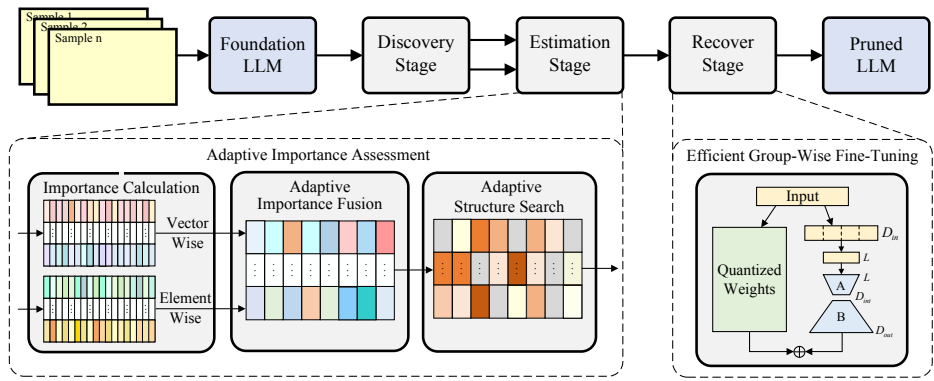
添加图片注释,不超过 140 字(可选)
自适应重要性评估
SAAP在估算阶段引入了一种自适应稳定性指标,以评估网络中不稳定和冗余的组成部分。通过结合粗粒度和细粒度信息,SAAP更好地捕捉不同耦合结构的重要性变化,并提高了重要性估计的准确性。其中, 表示粗粒度重要性得分, 表示细粒度重要性得分, 和 是噪声参数。该方法结合了粗粒度和细粒度的重要性信息,通过自适应融合来评估每个结构的重要性,从而提高了重要性评估的准确性。这种设计能够灵活适应不同网络结构和参数规模的大型语言模型,解决了现有方法中单一度量评估的不足。
核心公式就是下面这个:
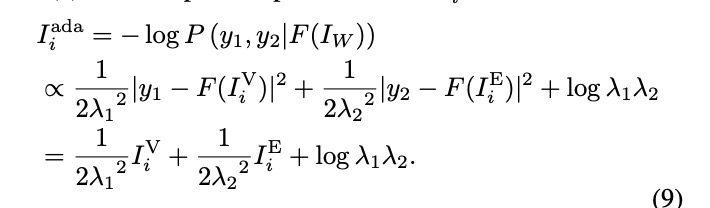
添加图片注释,不超过 140 字(可选)
自适应结构搜索策略
此外,SAAP在估算阶段通过提出一种自适应结构搜索策略扩展了其方法。该策略评估不同结构的重要性得分稳定性,从而实现统一评估,更有效地识别和剪除不稳定的耦合结构。自适应结构搜索通过计算每个耦合结构的重要性得分的稳定性来实现层间剪枝。具体来说,重要性波动指标 的计算公式如下
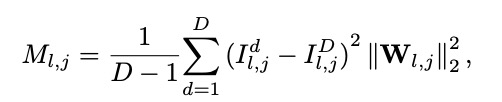
添加图片注释,不超过 140 字(可选)
为了进一步量化重要性波动的相对变化,论文引入了自适应稳定性指标 ,其公式如下:
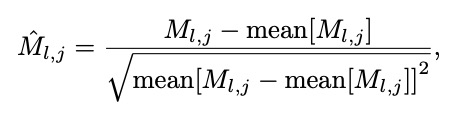
添加图片注释,不超过 140 字(可选)
表示第i层第j个通道的自适应稳定性指标。mean[ ] 表示所有通道的重要性波动指标的平均值。自适应稳定性指标通过标准化处理,使得不同层和模块之间的重要性波动具有可比性。该指标直接反映了重要性得分的相对波动性,波动性越高,说明该结构在不同输入或条件下的冗余性和不稳定性越大。
高效组间微调:
最后,提出了一种高效的组间微调策略,在剪枝阶段后维护LLMs的性能。通过对每组权重进行独立量化和调整,不仅提高了计算效率,还简化了部署过程。公式如下:
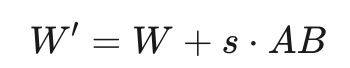
添加图片注释,不超过 140 字(可选)
其中,W是原始权重矩阵,s是调整参数,A和B是调整矩阵,W′是微调后的权重矩阵。
4. 剪枝的目的
减少存储需求:大型模型通常包含数以亿计甚至数十亿计的参数,需要大量的存储空间。通过剪枝可以显著减少模型的参数数量,从而降低存储成本,使得模型更易于部署在资源受限的设备上,如移动设备、嵌入式系统等。
提高推理速度:剪枝减少了模型中的计算量,使得模型在进行推理时的计算速度更快。这对于实时性要求较高的应用场景非常重要,如自动驾驶、视频监控等。
降低能耗:计算量的减少意味着硬件设备在执行模型推理时消耗的能量也会相应降低,这对于延长移动设备的电池续航时间以及降低数据中心的能耗具有重要意义。
5. 剪枝影响
积极影响:剪枝可以在不显著降低模型性能的前提下,有效减少模型的规模和计算复杂度,提高模型的效率和可用性。
消极影响:如果剪枝过度,可能会导致模型性能下降。因此,在进行剪枝操作时,需要仔细评估剪枝的比例和对模型性能的影响,通过合理的剪枝策略和微调过程来保证模型的性能基本不受影响。