【Agent的革命之路——LangGraph】工作流中的 map-reduce 模式
这节我们来探索一下工作流设计中常用的 Map-Reduce 模式,在介绍 Map-Reduce 模式之前,我们想来看下 LangGraph 中的Send 对象已经结构化输出。
Send对象
默认情况下,节点(Nodes)和边(Edges)会预先定义,并在同一共享状态(State)下运行。然而,某些情况下可能无法提前确定边的具体数量,或者需要同时存在不同版本的状态。一个典型例子是 Map-Reduce(映射-归约)设计模式:在此模式中,第一个节点可能生成一个对象列表,而后续需要对列表中的每个对象应用另一个节点。此时,对象的数量可能未知(意味着边的数量无法预先确定),且下游节点的输入状态应是独立的(每个生成的对象对应一个独立的状态)。
为支持此类设计模式,LangGraph 允许从**条件边(conditional edges)**返回 Send 对象。Send 接收两个参数:第一个是目标节点的名称,第二个是要传递给该节点的状态(State)。
下面是Send的伪代码:
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state['subjects']]
graph.add_conditional_edges("node_a", continue_to_jokes)
Structured outputs 结构化输出
对于许多应用程序(例如聊天机器人),模型需要直接用自然语言响应用户。但是,在某些情况下,我们需要模型以结构化格式输出。例如,我们可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。这需要激发结构化输出的概念,可以指示模型以特定的输出结构进行响应。
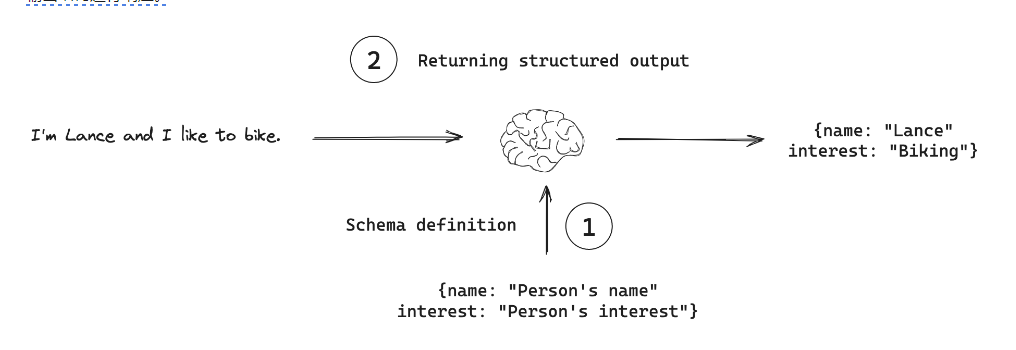
下面我们展示一下结构化输出的伪代码,该伪代码说明了使用结构化输出时推荐的工作流程。 Langchain提供了一种方法with_structured_output(),该方法可自动将模式与模型结合并解析输出的过程。该辅助功能可用于所有支持结构化输出的模型提供商。
# Define schema
schema = {"foo": "bar"}
# Bind schema to model
model_with_structure = model.with_structured_output(schema)
# Invoke the model to produce structured output that matches the schema
structured_output = model_with_structure.invoke(user_input)
我们稍微改动一下上面伪代码,使真实的代码更有可比性。
- 定义模式
通过Pydantic定义结构化输出,它提供了类型的提示和验证,
from pydantic import BaseModel, Field
class ResponseFormatter(BaseModel):
"""Always use this tool to structure your response to the user."""
answer: str = Field(description="The answer to the user's question")
followup_question: str = Field(description="A followup question the user could ask")
- 返回结构化输出
有几种结构化输出的方式,也是根据不同的模型提供商提供的输出方式,我一一举例。
工具调用模式:
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o", temperature=0)
# Bind responseformatter schema as a tool to the model
model_with_tools = model.bind_tools([ResponseFormatter])
# Invoke the model
ai_msg = model_with_tools.invoke("What is the powerhouse of the cell?")
# Get the tool call arguments
ai_msg.tool_calls[0]["args"]
# 输出结果
{'answer': "The powerhouse of the cell is the mitochondrion. Mitochondria are organelles that generate most of the cell's supply of adenosine triphosphate (ATP), which is used as a source of chemical energy.",
'followup_question': 'What is the function of ATP in the cell?'}
# Parse the dictionary into a pydantic object
pydantic_object = ResponseFormatter.model_validate(ai_msg.tool_calls[0]["args"])
当使用工具调用时,需要将工具调用参数从字典中解析为原始架构。并且,我们还需要指示模型在我们要执行结构化输出时始终使用该工具,这是提供商特定的设置。
json模式:
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o", model_kwargs={ "response_format": { "type": "json_object" } })
ai_msg = model.invoke("Return a JSON object with key 'random_ints' and a value of 10 random ints in [0-99]")
ai_msg.content
'\n{\n "random_ints": [23, 47, 89, 15, 34, 76, 58, 3, 62, 91]\n}'
使用JSON模式时,需要将输出解析为JSON对象。
当然Langchain提供了一个辅助功能(with_structured_output())来简化该过程。
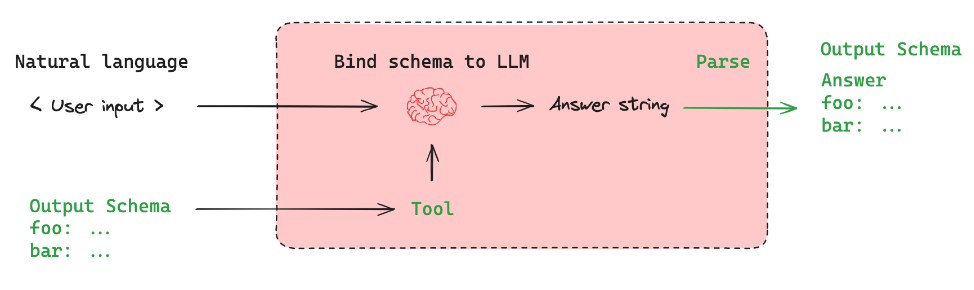
这两者都将模式绑定到模型作为工具,并将输出解析为指定的输出模式。
# Bind the schema to the model
model_with_structure = model.with_structured_output(ResponseFormatter)
# Invoke the model
structured_output = model_with_structure.invoke("What is the powerhouse of the cell?")
# 打印这个 pydantic object
structured_output
# 得到下面结果
ResponseFormatter(answer="The powerhouse of the cell is the mitochondrion. Mitochondria are organelles that generate most of the cell's supply of adenosine triphosphate (ATP), which is used as a source of chemical energy.", followup_question='What is the function of ATP in the cell?')
Map-reduce
我们经过上面介绍了Send对象还有结构化输出,对于我们接下来写 Map-reduce 模式提供了很好的铺垫。
下面我们来开始写个例子,由于Map-reduce模式操作对于高效任务分解和并行处理至关重要。此例子涉及将任务分解为较小的子任务,并行处理每个子任务,并汇总所有已完成子任务的结果。
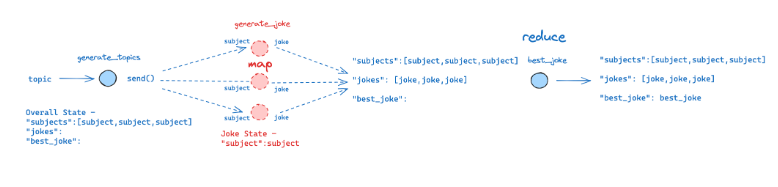
例子的场景:给定一个来自用户的一般主题,生成相关主题列表,为每个主题生成一个笑话,并从结果列表中选择最佳笑话。在这个设计模式中,第一个节点可能会生成一个对象列表(例如,相关主题),我们想要将其他节点(例如,生成一个笑话)应用于所有这些对象(例如,主题)。然而,出现了两个主要挑战。
(1)当我们布置图形时,对象(例如,主体)的数量可能提前未知(意味着可能不知道边的数量),
(2)下游节点的输入状态应该不同(每个生成的对象一个)。
LangGraph通过其SendAPI解决了这些挑战。通过利用条件边,Send可以将不同的状态(例如,主题)分配给节点的多个实例(例如,笑话生成)。重要的是,发送的状态可以与核心图的状态不同,从而实现灵活和动态的工作流管理。
下面是本例子的详细代码,我在每个组件上都加了关键注释:
import operator
from typing import Annotated
from typing_extensions import TypedDict
from langchain_anthropic import ChatAnthropic
from langgraph.types import Send
from langgraph.graph import END, StateGraph, START
from pydantic import BaseModel, Field
# 定义 model and prompts
subjects_prompt = """Generate a comma separated list of between 2 and 5 examples related to: {topic}."""
joke_prompt = """Generate a joke about {subject}"""
best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one.
{jokes}"""
class Subjects(BaseModel):
subjects: list[str]
class Joke(BaseModel):
joke: str
class BestJoke(BaseModel):
id: int = Field(description="Index of the best joke, starting with 0", ge=0)
model = ChatAnthropic(model="claude-3-5-sonnet-20240620")
# 定义组件
# 这将作为主图的全局状态。
# 它包含一个主题(我们期望用户提供),
# 然后会生成一个主题列表,并为每个主题生成一个笑话。
class OverallState(TypedDict):
topic: str
subjects: list
# 注意这里我们使用了 operator.add
# 这是因为我们希望将所有从单个节点生成的笑话合并到一个列表中 —— 这本质上是“归约”(reduce)部分。
jokes: Annotated[list, operator.add]
best_selected_joke: str
# 这将作为节点的状态,我们将所有主题“映射”到该节点以生成笑话。
class JokeState(TypedDict):
subject: str
# 这是我们将用于生成笑话主题的函数。
def generate_topics(state: OverallState):
prompt = subjects_prompt.format(topic=state["topic"])
response = model.with_structured_output(Subjects).invoke(prompt)
return {"subjects": response.subjects}
# 这里我们根据主题生成一个笑话。
def generate_joke(state: JokeState):
prompt = joke_prompt.format(subject=state["subject"])
response = model.with_structured_output(Joke).invoke(prompt)
return {"jokes": [response.joke]}
# 这里我们定义了遍历生成主题的逻辑,
# 并将其作为图中的一条边使用。
def continue_to_jokes(state: OverallState):
# 我们将返回一个 `Send` 对象列表。
# 每个 `Send` 对象包含图中一个节点的名称,
# 以及要发送给该节点的状态。
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]
# 这里我们将评判最佳笑话。
def best_joke(state: OverallState):
jokes = "\n\n".join(state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = model.with_structured_output(BestJoke).invoke(prompt)
return {"best_selected_joke": state["jokes"][response.id]}
# 构建图:在这里我们将所有内容整合在一起以构建我们的图。
graph = StateGraph(OverallState)
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_joke", generate_joke)
graph.add_node("best_joke", best_joke)
graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
graph.add_edge("generate_joke", "best_joke")
graph.add_edge("best_joke", END)
app = graph.compile()
这是我们的graph:
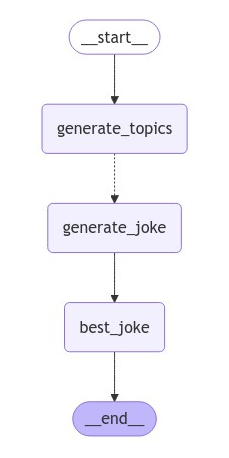
调用该graph:
# Call the graph: here we call it to generate a list of jokes
for s in app.stream({"topic": "animals"}):
print(s)
得到结果:
{'generate_topics': {'subjects': ['Lions', 'Elephants', 'Penguins', 'Dolphins']}}
{'generate_joke': {'jokes': ["Why don't elephants use computers? They're afraid of the mouse!"]}}
{'generate_joke': {'jokes': ["Why don't dolphins use smartphones? Because they're afraid of phishing!"]}}
{'generate_joke': {'jokes': ["Why don't you see penguins in Britain? Because they're afraid of Wales!"]}}
{'generate_joke': {'jokes': ["Why don't lions like fast food? Because they can't catch it!"]}}
{'best_joke': {'best_selected_joke': "Why don't dolphins use smartphones? Because they're afraid of phishing!"}}
通过上面的示例中,通过设计Map-Reduce 模式来处理生成笑话的任务。它被分为了 Map 阶段,和 Reduce 阶段,在Map阶段generate_topics 节点生成与主题相关的多个子主题(subjects)。然后,通过 continue_to_jokes 函数,将每个子主题映射到 generate_joke 节点,生成对应的笑话。每个子主题的处理是独立的,因此可以并行执行。而在Reduce 阶段,对任务进行了分解,生成笑话的任务可以分解为多个独立的子任务(每个子主题生成一个笑话),适合并行处理。首先 Map-Reduce 模式天然支持这种任务分解和并行化。其次主题的数量是动态的,无法预先确定。Map-Reduce 模式可以灵活处理动态数量的子任务。最终需要将所有生成的笑话合并为一个列表,并选择最佳笑话。Reduce 阶段提供了这种汇总功能。Map-Reduce 模式将任务分解为清晰的阶段(Map 和 Reduce),使代码结构更清晰,易于理解和维护。