MYSQL之复合查询
复合查询
1. 多表查询
实际开发中往往数据来自不同的表, 所以需要多表查询.
继续使用之前的三张表 emp dept, salgrade 来演示如何进行多表查询:
例1: 显示雇员名、雇员工资以及所在部门的名字
因为部门名字 和 雇员信息不在一个表中, 因此需要多表查询:
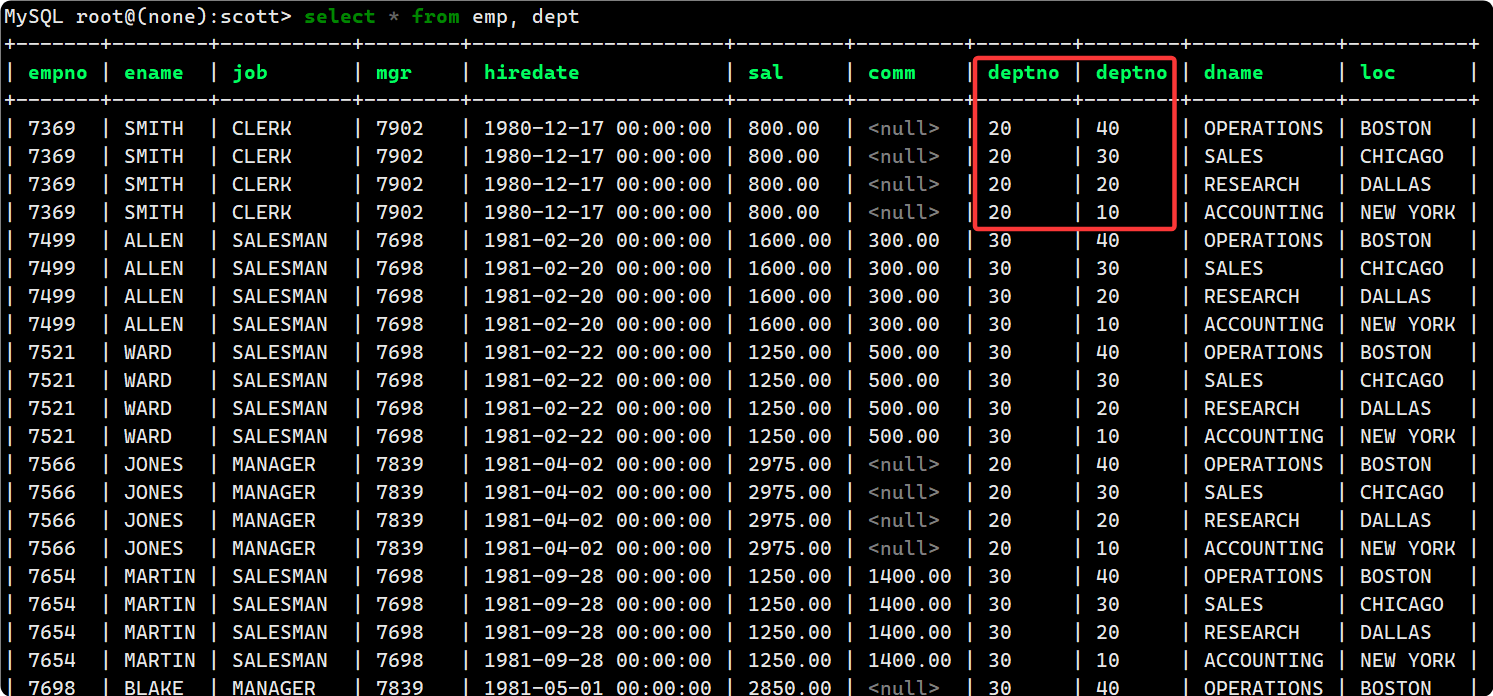
笛卡尔积:
我们从图中可以看到, 当我们把两张表联合查询时, 会生成一个新的大表, 这个大表是 这几张表的笛卡尔积, 如果 t1 有 m 列 a 行 数据, t2有 n 列 b 行 数据, 那么最终表 t1 × t2 就会生成 m+n 列数据, 共有 a*b 行数据.
但是如图所示, 不是所有的数据都是有用的, 比如我们并不需要deptno不相等的行, 因此我们需要添加where子句去限制.
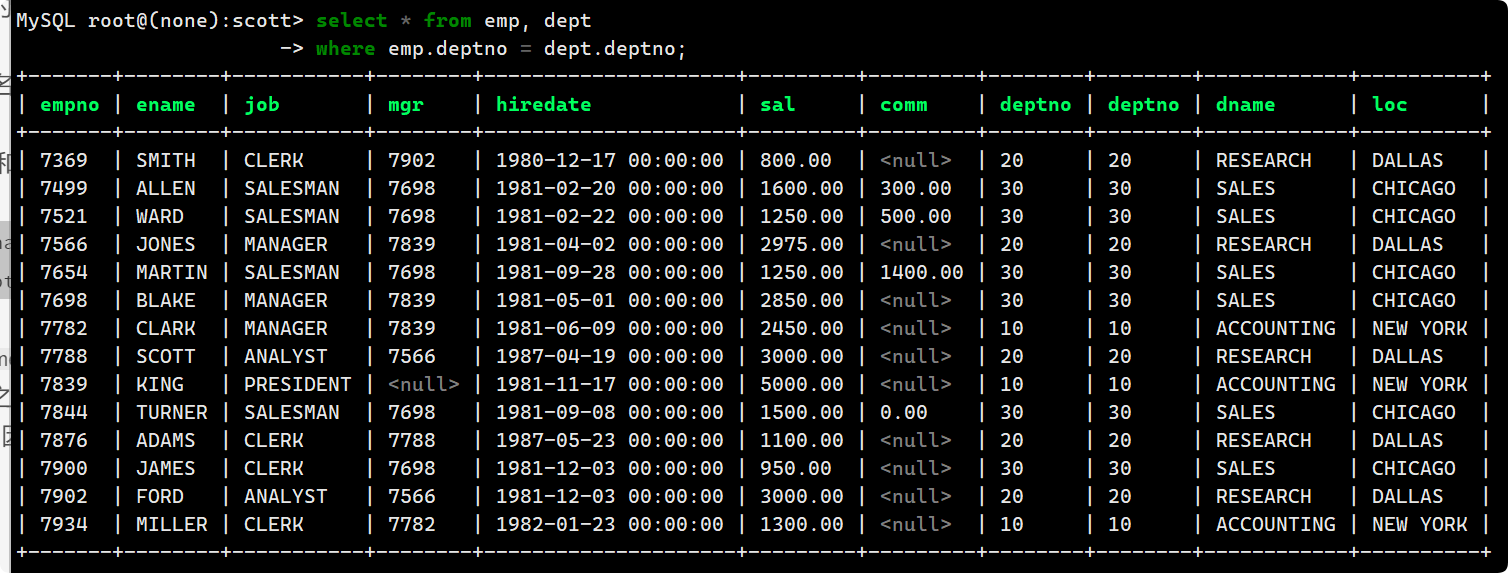
select emp.ename, emp.sal, dept.dname from emp, dept
where emp.deptno = dept.deptno;
注意,
emp.ename, emp.sal, dept.dname前面的table_name.都可以省略, 因为这些属性在两张表合并之后不会发生冲突, 而emp.deptno = dept.deptno就必须标明deptno是来自哪张表的.
结果:
例2: 显示部门号为 10 的部门名, 员工名和工资:
只需要再之前的基础上添加一个 dept.deptno=10即可:
select dname, ename, sal from emp, dept
where emp.deptno = dept.deptno and dept.deptno=10;+------------+--------+---------+
| dname | ename | sal |
+------------+--------+---------+
| ACCOUNTING | CLARK | 2450.00 |
| ACCOUNTING | KING | 5000.00 |
| ACCOUNTING | MILLER | 1300.00 |
+------------+--------+---------+
例3 显示各个员工的姓名,工资,及工资级别
需要注意我们只需要那些 sal 在 [losal, hisal] 之间的行, 其它行都是无效的行:
select ename, sal, grade from emp, salgrade
where sal between losal and hisal order by grade;
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| WARD | 1250.00 | 2 |
| MARTIN | 1250.00 | 2 |
| MILLER | 1300.00 | 2 |
| ALLEN | 1600.00 | 3 |
| TURNER | 1500.00 | 3 |
| JONES | 2975.00 | 4 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| FORD | 3000.00 | 4 |
| KING | 5000.00 | 5 |
+--------+---------+-------+
2.自连接
自连接是指在同一张表连接查询.
- 一张表也可以和自己做笛卡尔积, 但是要给表重命名:
select * from dept as t1, dept as t2
+--------+------------+----------+--------+------------+----------+
| deptno | dname | loc | deptno | dname | loc |
+--------+------------+----------+--------+------------+----------+
| 40 | OPERATIONS | BOSTON | 10 | ACCOUNTING | NEW YORK |
| 30 | SALES | CHICAGO | 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS | 10 | ACCOUNTING | NEW YORK |
| 10 | ACCOUNTING | NEW YORK | 10 | ACCOUNTING | NEW YORK |
| 40 | OPERATIONS | BOSTON | 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO | 20 | RESEARCH | DALLAS |
| 20 | RESEARCH | DALLAS | 20 | RESEARCH | DALLAS |
| 10 | ACCOUNTING | NEW YORK | 20 | RESEARCH | DALLAS |
| 40 | OPERATIONS | BOSTON | 30 | SALES | CHICAGO |
| 30 | SALES | CHICAGO | 30 | SALES | CHICAGO |
| 20 | RESEARCH | DALLAS | 30 | SALES | CHICAGO |
| 10 | ACCOUNTING | NEW YORK | 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON | 40 | OPERATIONS | BOSTON |
| 30 | SALES | CHICAGO | 40 | OPERATIONS | BOSTON |
| 20 | RESEARCH | DALLAS | 40 | OPERATIONS | BOSTON |
| 10 | ACCOUNTING | NEW YORK | 40 | OPERATIONS | BOSTON |
+--------+------------+----------+--------+------------+----------+
案例: 显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号–empno)
这个案例用子查询和自连接都可以实现:
首先实际手动去解决这个问题时, 我们会分两步走: 首先会去 emp 查 FORD 的上级领导的编号(mgr)是什么, 然后再拿着这个编号去 emp 去查他的信息.
- 子查询, 查询出 FORD 的领导编号作为 where 的条件, 在 emp 查询即可
select empno, ename from emp
where empno=(select mgr from emp where ename="FORD")
+-------+-------+
| empno | ename |
+-------+-------+
| 7566 | JONES |
+-------+-------+
- 自连接, t2 表用于去筛选 FORD 的信息:
select * from emp t1, emp t2 where t2.ename="FORD"
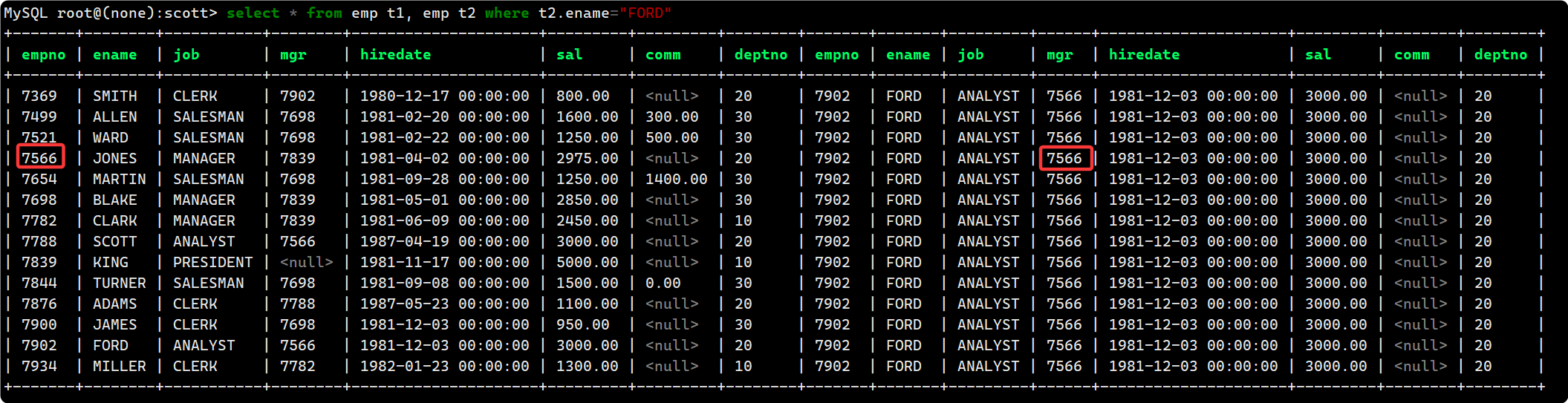
然后需要与 t1 表的empno对应:
select t1.empno,t1.ename from emp t1, emp t2
where t2.ename="FORD" and t1.empno=t2.mgr
+-------+-------+
| empno | ename |
+-------+-------+
| 7566 | JONES |
+-------+-------+
3. 子查询
单行子查询(单列)
单行子查询是返回一行记录的子查询, 之前已经使用过, 特点是充当 where 条件的子查询select语句中的列属性只有一个, 且查询结果也只有一行.
案例: 显示SMITH同一部门的员工
select * from emp where deptno=(select deptno from emp where ename='SMITH')
+-------+-------+---------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+-------+-------+---------+------+---------------------+---------+--------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | <null> | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | <null> | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | <null> | 20 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | <null> | 20 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | <null> | 20 |
+-------+-------+---------+------+---------------------+---------+--------+--------+
多行子查询(单列)
多行子查询是返回多行记录的子查询, 特点是子查询语句选择了一个列, 但查询结果有多行.
- in关键字
案例: 查询和10号部门的工作岗位相同的雇员的名字, 岗位, 工资, 部门号, 但是不包含 10 自己.
10号部门的工作岗位可能有多个, 因此这是单列多行子查询:
select ename, job, sal, deptno from emp //查询雇员基本信息
where job in (select distinct job from emp where deptno=10) //子查询, 选出10号部门的岗位
and deptno!=10 //级别是和 job in 并列, 因为要求部门号不能包含自己(10)
order by deptno
+-------+---------+---------+--------+
| ename | job | sal | deptno |
+-------+---------+---------+--------+
| SMITH | CLERK | 800.00 | 20 |
| JONES | MANAGER | 2975.00 | 20 |
| ADAMS | CLERK | 1100.00 | 20 |
| BLAKE | MANAGER | 2850.00 | 30 |
| JAMES | CLERK | 950.00 | 30 |
+-------+---------+---------+--------+
在此基础上再追加一个要求, 我要显示出 deptno 的具体名称:
这里的重点是 from , 我们把刚才的查询结果又作为一个临时的表, 去和dept表做笛卡尔积, 这样又可以得到一个新表. 因此可以再次验证, “mysql中一切皆表”
select empno,ename,job,sal,dname
from (select empno, ename, job, sal, deptno from emp where job in (select distinct job from emp where deptno=10) and deptno!=10) as tmp, dept
where tmp.deptno=dept.deptno
+-------+-------+---------+---------+----------+
| empno | ename | job | sal | dname |
+-------+-------+---------+---------+----------+
| 7876 | ADAMS | CLERK | 1100.00 | RESEARCH |
| 7566 | JONES | MANAGER | 2975.00 | RESEARCH |
| 7369 | SMITH | CLERK | 800.00 | RESEARCH |
| 7900 | JAMES | CLERK | 950.00 | SALES |
| 7698 | BLAKE | MANAGER | 2850.00 | SALES |
+-------+-------+---------+---------+----------+
- all关键字
案例1: 显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
//max
select ename, sal, deptno from emp where sal > (select max(sal) from emp where deptno=30)
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| JONES | 2975.00 | 20 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+
//all
select ename, sal, deptno from emp where sal > all(select distinct sal from emp where deptno=30)
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| JONES | 2975.00 | 20 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+
- any关键字
案例2: 显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
//min
select ename, sal, deptno from emp where sal > (select min(sal) from emp where deptno=30)
//any
select ename, sal, deptno from emp where sal > any(select distinct sal
from emp where deptno=30)
+--------+---------+--------+
| ename | sal | deptno |
+--------+---------+--------+
| ALLEN | 1600.00 | 30 |
| WARD | 1250.00 | 30 |
| JONES | 2975.00 | 20 |
| MARTIN | 1250.00 | 30 |
| BLAKE | 2850.00 | 30 |
| CLARK | 2450.00 | 10 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| TURNER | 1500.00 | 30 |
| ADAMS | 1100.00 | 20 |
| FORD | 3000.00 | 20 |
| MILLER | 1300.00 | 10 |
+--------+---------+--------+
多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言
的,而多列子查询则是指查询返回多个列数据的子查询语句
案例: 查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
首先我们查找出SMITH的 (部门, 岗位) 充当子查询条件, 由于这里只有一行数据, 因此使用=去比较即可, MYSQL 支持元组的比较.
select * from emp where (deptno, job) = (select deptno, job from emp where ename="SMITH") and ename != "SMITH";
+-------+-------+-------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+-------+-------+-------+------+---------------------+---------+--------+--------+
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | <null> | 20 |
+-------+-------+-------+------+---------------------+---------+--------+--------+
如果子查询的结果是多行数据, 把 = 替换为 in 即可.
补充: 任何时刻, 查询出来的临时结构, 本质在逻辑上也是表结构, 因此我们可以将任意 “已经存在的表” 和 “临时的表” 进行组合和查询.
在from子句中使用子查询
之前所有案例使用到的子查询, 都是在 where 子句中充当判断条件, 但这解决不了所有问题, 一些较复杂的场景where子查询就无法解决了.
子查询语句可以出现在 from 子句中充当一个表, 与主表进行笛卡尔积, 然后添加where 去筛选. 这里用到的数据查询的技巧是: 把一个子查询当做一个临时表使用.
案例1: 显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
这里把部门的(部门号, 平均工资)作为一个临时表, 与 emp 进行笛卡尔积, 然后在这个大表中再进行筛选:
select ename, emp.deptno, sal, avg_sal
from emp, (select avg(sal) as avg_sal, deptno from emp group by deptno) as tmp
where emp.deptno=tmp.deptno and sal > avg_sal
+-------+--------+---------+-------------+
| ename | deptno | sal | avg_sal |
+-------+--------+---------+-------------+
| FORD | 20 | 3000.00 | 2175.000000 |
| SCOTT | 20 | 3000.00 | 2175.000000 |
| JONES | 20 | 2975.00 | 2175.000000 |
| BLAKE | 30 | 2850.00 | 1566.666667 |
| ALLEN | 30 | 1600.00 | 1566.666667 |
| KING | 10 | 5000.00 | 2916.666667 |
+-------+--------+---------+-------------+
案例2: 查找每个部门工资最高的人的姓名、工资、部门、最高工资
select ename, sal, emp.deptno, max_sal
from (select deptno, max(sal) max_sal from emp group by deptno) as tmp, emp
where tmp.deptno=emp.deptno and emp.sal = max_sal
+-------+---------+--------+---------+
| ename | sal | deptno | max_sal |
+-------+---------+--------+---------+
| BLAKE | 2850.00 | 30 | 2850.00 |
| SCOTT | 3000.00 | 20 | 3000.00 |
| KING | 5000.00 | 10 | 5000.00 |
| FORD | 3000.00 | 20 | 3000.00 |
+-------+---------+--------+---------+
案例3: 显示每个部门的信息(部门名,编号,地址)和人员数量
方法一, 简单暴力进行多表查询, 可以分两步理解:
- 首先我们通过分组查询得到每个部门的人数:
select dept.deptno, count(*) from emp, dept where emp.deptno=dept.deptno group by dept.deptno
+--------+----------+
| deptno | count(*) |
+--------+----------+
| 20 | 5 |
| 30 | 6 |
| 10 | 3 |
+--------+----------+
- 但是我们要需要得到部门的其它信息, 但是为了适应分组查询的语法, 我们要需要把 dname 和 loc 当作 group by 的条件:
select dept.deptno, dept.dname, dept.loc, count(*) from emp, dept
where emp.deptno=dept.deptno
group by dept.deptno, dept.dname, dept.loc
+--------+------------+----------+----------+
| deptno | dname | loc | count(*) |
+--------+------------+----------+----------+
| 20 | RESEARCH | DALLAS | 5 |
| 30 | SALES | CHICAGO | 6 |
| 10 | ACCOUNTING | NEW YORK | 3 |
+--------+------------+----------+----------+
所以不太推荐这种写法.
方法2:使用子查询, 把 (部门,人数) 先生成一个临时表, 然后与 dept 做笛卡尔积, 进行筛选:
select dept.deptno, dname, loc, total_num
from (select deptno, count(*) as total_num from emp group by deptno) as tmp, dept
where tmp.deptno=dept.deptno
+--------+------------+----------+-----------+
| deptno | dname | loc | total_num |
+--------+------------+----------+-----------+
| 10 | ACCOUNTING | NEW YORK | 3 |
| 20 | RESEARCH | DALLAS | 5 |
| 30 | SALES | CHICAGO | 6 |
+--------+------------+----------+-----------+
解决多表问题的本质: 想办法将
合并查询
在实际应用中, 为了合并多个 select 的执行结果, 可以使用集合操作符 union, union all.
它们都是取并集, 只是 union 会对行去重, union all 不会. 重复记录是指查询中各个字段完全重复的记录.
注意: union 语句中的多条 select 语句字段名称可以不同, 但字段属性必须一致, 字段数量必须相同.
union
该操作符用于取得两个结果集的并集, 当使用该操作符时, 会自动去掉结果集中的重复行
案例一: 将工资大于2500或职位是MANAGER的人找出来
select empno, ename, deptno from emp where sal > 2500 union select empno, ename, deptno from emp where job='MANAGER';
+-------+-------+--------+
| empno | ename | deptno |
+-------+-------+--------+
| 7566 | JONES | 20 |
| 7698 | BLAKE | 30 |
| 7788 | SCOTT | 20 |
| 7839 | KING | 10 |
| 7902 | FORD | 20 |
| 7782 | CLARK | 10 |
+-------+-------+--------+
其结果和在 where 子句中使用 or 的效果一样:
select empno, ename, deptno from emp where sal > 2500 or job='MANAGER'
+-------+-------+--------+
| empno | ename | deptno |
+-------+-------+--------+
| 7566 | JONES | 20 |
| 7698 | BLAKE | 30 |
| 7782 | CLARK | 10 |
| 7788 | SCOTT | 20 |
| 7839 | KING | 10 |
| 7902 | FORD | 20 |
+-------+-------+--------+
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行, 因此效率高于 union
案例二: 将工资大于25000或职位是MANAGER的人找出来
select empno, ename, deptno from emp where sal > 2500 union all select empno, ename, deptno from emp where job='MANAGER';
+-------+-------+--------+
| empno | ename | deptno |
+-------+-------+--------+
| 7566 | JONES | 20 |
| 7698 | BLAKE | 30 |
| 7788 | SCOTT | 20 |
| 7839 | KING | 10 |
| 7902 | FORD | 20 |
| 7566 | JONES | 20 |
| 7698 | BLAKE | 30 |
| 7782 | CLARK | 10 |
+-------+-------+--------+