MoE架构分析
1.什么是MoE
1.1 MoE简介
MoE是一种基于 Transformer 架构的模型,主要由两个关键部分组成:
- 稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”,专家通常是前馈网络 (FFN)。
- 门控网络 (Gating Network) 或称路由器(Router): 这个部分用于决定哪些令牌 (token) 被发送到哪个专家。
1.2MoE架构分析
MoE将Transformer的每个前馈网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。
在Laynormalize后,对于一个输入词元表示为x,首先通过门控函数计算每个词元分配给每个专家的概率:
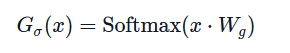
然后使用Top-k算法进行专家选择:Router会选择门控概率最高的前k个专家,将x输入给这k个专家计算加权输出。
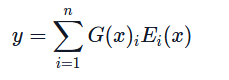
但是在训练过程中,如果词元都被分配给某几个专家,就会出现训练和微调过程中的稳定性问题。
2.Switch Transformers——提出Top-1专家;提出负载平衡损失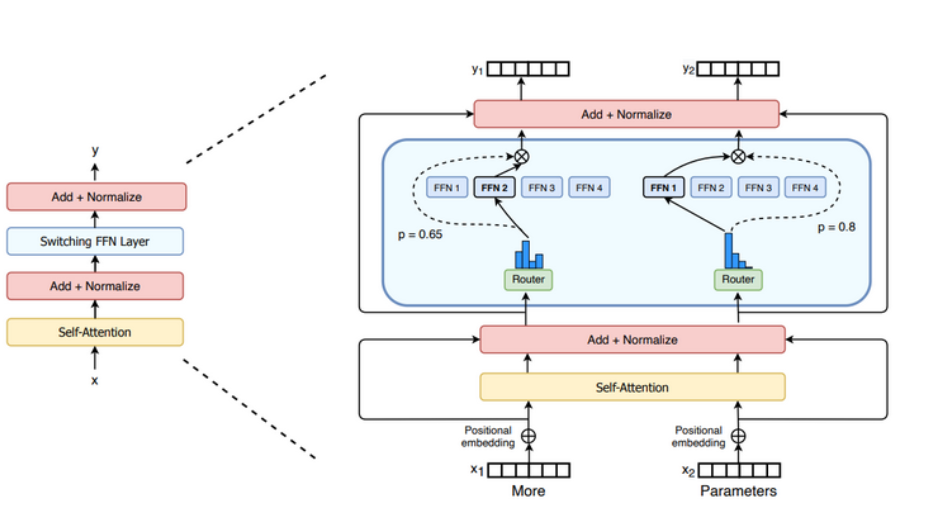
Top-1专家:只选择一个专家。
负载平衡损失(Load Balancing Loss):
为了避免某个专家被过度偏向,鼓励输入词元在训练过程中能够尽可能均匀地分配给所有的专家,文章设计了负载平衡损失。
①实际分配比例:实际被路由到专家 i 的词元数量占总词元数量的比例。
②期望分配概率:门控网络分配给专家 i 的概率在所有词元上的平均值。
③负载均衡损失:词元分配越平均,Loss越小。

3.ST-MoE——提出Router Z-loss
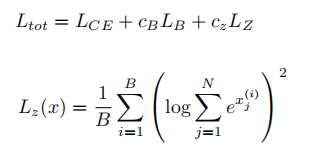
Lce:交叉熵损失,Transformer默认损失函数。
Lb:负载平衡损失,均衡分配专家。
Lz:路由器Z损失,惩罚过大的Logits量级(提高训练稳定性),防止Softmax饱和(避免梯度消失)。
4.DeepSeekV1——细粒度专家划分;共享专家分离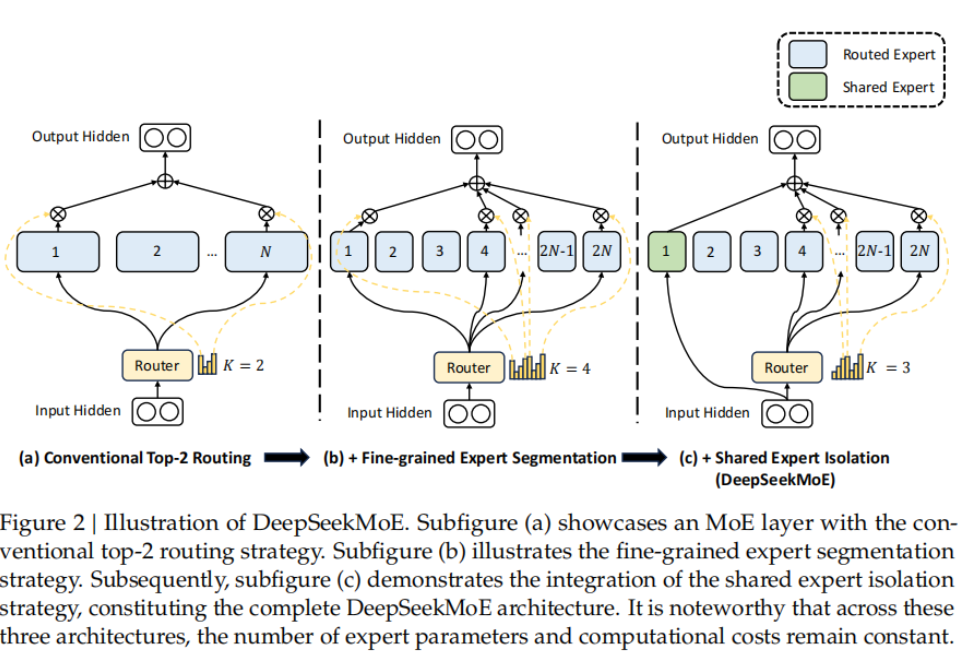
上图中(a)表示之前的MOE架构,专家分的粒度比较粗,并且没有共享专家,图(b)是将专家粒度划分的更细情况,图(c)在图(b)的基础上增加了共享专家。
细粒度专家划分:将大专家分割为m个小专家,假如原有N个专家,划分后就变为了mN个专家。
目标:MoE模型是为了在同计算量下训练更大的模型,随着模型变大,更多的细分专家有助于解决知识混合问题,提升专家特化程度。
共享专家分离:将部分专家进行隔离, 这些专家对于每一个输入token都会被激活。
目标:在传统的 MoE 中,不同的专家都会学习到一些非常基础和通用的知识。这种通用知识在多个专家中的重复学习就造成了参数冗余。共享专家被设计用来专门学习通用知识。进一步提升路由专家的特化程度。

DeepSeek提出的MoE层的输出由三部分构成:
- 共享专家输出
- Top-k路由专家输出
- 残差连接

与之前的Lb类似,主要修改点为:
- 基于共享专家对Switch Transformers的公式进行修改。
- fi(实际分配比例)增加了一个系数,消除不同激活专家数量对于损失函数的影响,使得最终的损失值在不同激活专家的情况下都能保持一个稳定的区间范围,不会浮动太大。
5.DeepSeekV2——多头潜在注意力
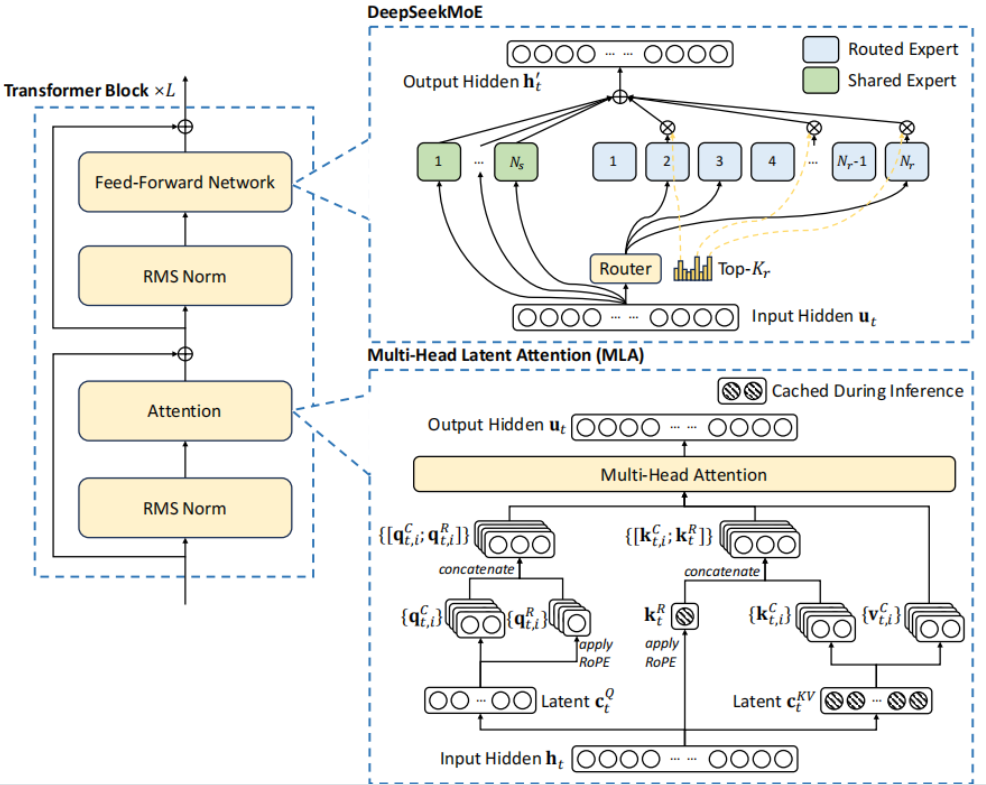
核心假设:KV矩阵是低秩的,存在大量冗余。低秩压缩能够不显著损失模型性能
核心目的是为了提高模型的推理效率。传统的注意力机制在处理大规模数据时,会产生非常大的KV缓存。MLA将这些KV缓存压缩成一个潜在向量,大大减少了计算量,从而提高了推理效率。
MLA 的核心思想:
低秩键值联合压缩: 将原始的K和V向量联合压缩到一个维度远小于原始K、V向量总和的潜在向量c中。
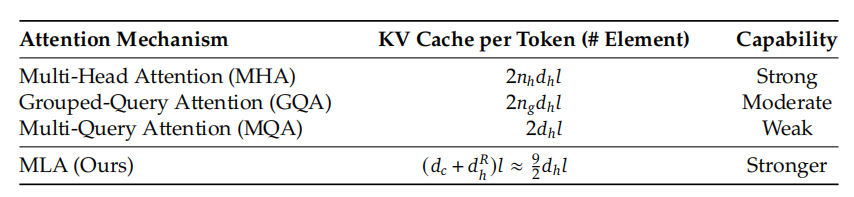
缓存潜在向量: 在推理时,只需要缓存这个低维的c,而不是完整的K和V,可以将 KV缓存减少约 93.3%。
从潜在向量重构 K 和 V: 在注意力计算时,再通过两个不同的上采样投影矩阵从缓存的c中重构出近似的K和V。
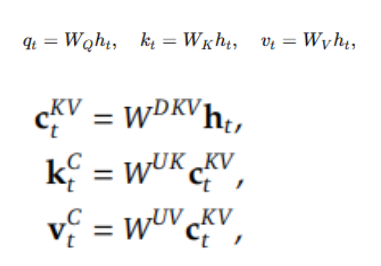
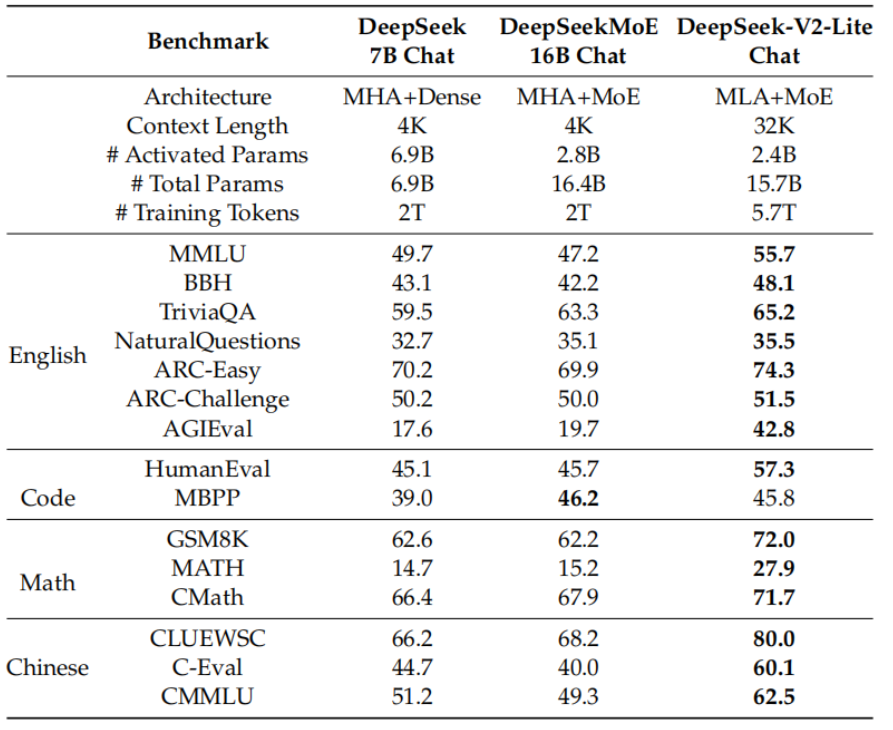
6.DeepSeekV3——无辅助损失的负载均衡策略;多词元预测训练目标
MoE层公式:
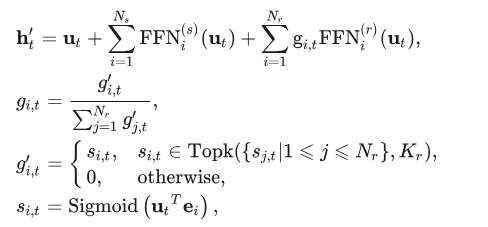
更新点:
- 使用Sigmoid替换Softmax,避免 Softmax 在专家数量很大时分数过度平滑的问题
- 在计算输出前对门控值进行归一化,确保所有被选专家的门控权重之和为 1,符合概率分布。
无辅助损失的负载均衡:
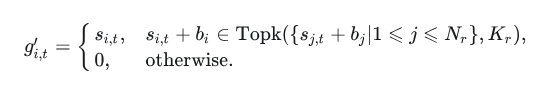
直接通过调整路由过程来实现负载均衡,而不需要额外的损失项。
在训练过程中动态调整偏置,使所有专家负载趋于均衡。
互补序列层面的辅助损失:
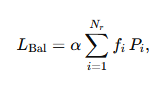
为防止单条序列极端失衡,仍加入一个极小系数的辅助损失。
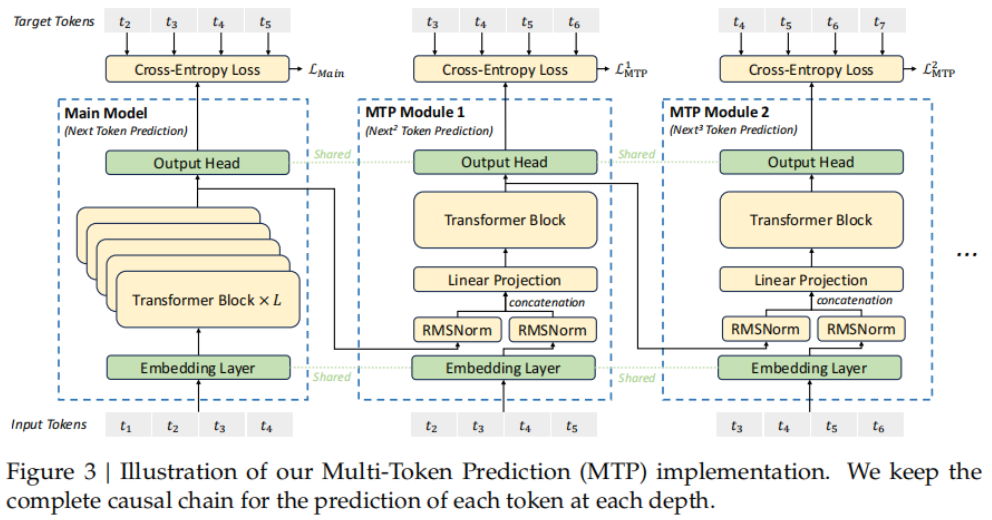
MTP层:预测后续的词元,通过共享Embedding层和输出头来影响主模型的性能。
训练时接收当前预测token的transformer输出,然后预测当前+1的输出,依次重复预测当前+2。
同样使用交叉熵损失进行训练。
实际在推理时没有被使用,主要用于提升主模型性能。
7.稠密模型和稀疏模型如何选择?
MoE 的优势:
-
相同激活参数的情况下有更大的总参数容量,意味着MoE具有相比有稠密模型更大的知识存储。
- MoE 的每个专家学习特化知识,门控网络(Router)在处理不同输入时,可以选择最合适的专家组合带来更优的知识组合。
简单的说:MoE架构能够实现相同计算成本下的更大规模的模型。
MoE的问题:
1.相同激活参数不代表占用显存相同,只是推理时激活的参数大小相同。
2.相同激活参数的情况下MoE模型大小显著高于稠密模型。
3.相同激活参数下,MoE推理速度不一定快于稠密模型。
MoE 架构与稠密模型在 VLA 部署上的对比分析 (激活相同数量参数时):
| 特性/需求 | MoE模型 | 对比结果 |
| 模型参数量 (总计) | 远大于稠密模型 | × |
| 显存占用 (静态参数) | 远大于稠密模型 | × |
| 计算量 (FLOPs) | 与稠密模型大致相当或略高。(门控网络的计算是额外开销) | × |
| 推理速度 | 可能略慢于或与稠密模型相当。额外的门控计算开销引入少量延迟。 | × |
| 推理结果质量 | 有潜力更高。 | √ |
| 硬件适应性 | 主流车载硬件可能没有针对性优化,可能不如稠密模型适应性好。 | × |
| 训练成本/复杂度 | 远高于稠密模型。因为需要训练远大于稠密模型的总参数,需要处理 MoE 泛化能力不足和不稳定性。 | × |
简单总结:极致的推理质量追求时可以选择使用MoE,需要付出总参数量庞大,训练难度高等代价。
总结:
- MoE模型发展迅速,即使是参数总量小的模型上,DeepSeekV2-VL(2025.1)和Kimi-VL(2025.4)也有巨大的性能提升,逐渐逼近同参数量的VLM。
- 目前多模态MoE模型并不多,且参数量很大,且同参数总量下效果不如稠密模型,不适合边缘部署。
- MoE模型更适合超大模型,但即使在小模型上也具有很大潜力。