文献阅读——NeuroBayesSLAM
原文地址
1.核心理论:贝叶斯多感官整合框架
目标:结合视觉线索 c v i c_{vi} cvi和前庭线索 c v e c_{ve} cve来估计头部方向或位置 θ
贝叶斯公式
p ( θ ∣ c v i , c v e ) ∝ p ( c v i ∣ θ ) p ( c v e ∣ θ ) p ( θ ) p(\theta | c_{vi}, c_{ve}) \propto p(c_{vi} | \theta)p(c_{ve} | \theta)p(\theta) p(θ∣cvi,cve)∝p(cvi∣θ)p(cve∣θ)p(θ)
- p ( θ ∣ c v i , c v e ) p(\theta | c_{vi}, c_{ve}) p(θ∣cvi,cve):给定所有线索后, θ \theta θ 的后验概率分布。
- p ( c v i ∣ θ ) / p ( c v e ∣ θ ) p(c_{vi} | \theta) / p(c_{ve} | \theta) p(cvi∣θ)/p(cve∣θ):观察到线索 c v i / c v e c_{vi} / c_{ve} cvi/cve 的可能性,取决于真实状态 θ \theta θ。
- p ( θ ) p(\theta) p(θ): θ \theta θ 的先验概率(初始信念)。
简化假设:
- 没有先验时 p ( θ ) p(\theta) p(θ)均匀分布即为1。
- 视觉和前庭线索的噪声相互独立。
时间迭代:
p t ( θ ∣ c v i , c v e ) ∝ p t ( c v i ∣ θ ) p t ( c v e ∣ θ ) p t − 1 ( θ ∣ c v i , c v e ) p^t(\theta \mid c_{vi}, c_{ve}) \propto p^t(c_{vi} \mid \theta)p^t(c_{ve} \mid \theta)p^{t-1}(\theta \mid c_{vi}, c_{ve}) pt(θ∣cvi,cve)∝pt(cvi∣θ)pt(cve∣θ)pt−1(θ∣cvi,cve)
将当前时刻的线索与上一时刻的后验信念结合。
这个公式可以拆分为路径积分和地标校准:
路径积分 (Path Integration)
- 利用前庭/运动线索更新估计。
- 对应于贝叶斯框架中的前庭线索更新:
p t ( θ ∣ c v i , c v e ) ∝ p t ( c v e ∣ θ ) p t − 1 ( θ ∣ c v i , c v e ) p^t(\theta | c_{vi}, c_{ve}) \propto p^t(c_{ve} | \theta)p^{t-1}(\theta | c_{vi}, c_{ve}) pt(θ∣cvi,cve)∝pt(cve∣θ)pt−1(θ∣cvi,cve)
模拟动物根据自身运动(步数、速度)不断更新位置的过程。
地标校准 (Landmark Calibration)
- 利用视觉线索(熟悉地标)修正估计。
- 对应于贝叶斯框架中的视觉线索更新:
p t ( θ ∣ c v i , c v e ) ∝ p t ( c v i ∣ θ ) p t − 1 ( θ ∣ c v i , c v e ) p^t(\theta \mid c_{vi}, c_{ve}) \propto p^t(c_{vi} \mid \theta)p^{t-1}(\theta \mid c_{vi}, c_{ve}) pt(θ∣cvi,cve)∝pt(cvi∣θ)pt−1(θ∣cvi,cve)
当看到熟悉的景象时,调整内部地图以匹配外部世界。
2.模型架构
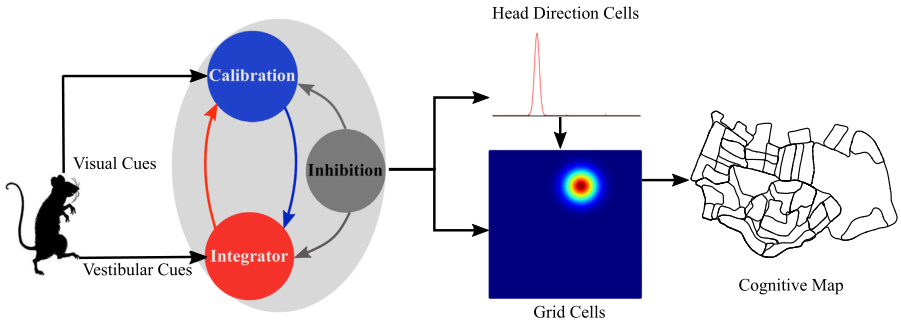 该图展示了模型的贝叶斯吸引子网络架构及其信息流动图表。
该图展示了模型的贝叶斯吸引子网络架构及其信息流动图表。
- 头部方向细胞(Head Direction Cells)编码方向。
- 网格细胞(Grid Cells)编码位置。
来自前庭线索和视觉线索的信息分别由整合细胞(Integrator Cells)和校准细胞(Calibration Cells)整合。
- 整合细胞接收前庭路径积分信息。
- 校准细胞接受视觉校准信息。
当线索冲突出现时,这两种细胞通过相互抑制和全局抑制来解决冲突,从而在网络中产生单峰活动。头部方向细胞网络中编码的方向被用于网格细胞网络中编码代理的位置。基于网格细胞网络提供的位置信息,构建了一个认知地图。
2.1 HD细胞网络
2.1.1表示:
- 每个细胞群体(整合细胞和校准细胞)维护一个一维高斯分布 p ( θ ) p(\theta) p(θ) 来表示对头部方向的信念。
p ( θ ) = 1 σ 2 π e − ∣ θ − μ ∣ 2 / 2 σ 2 p(\theta) = \frac{1}{\sigma\sqrt{2\pi}} e^{-|\theta - \mu|^2 / 2\sigma^2} p(θ)=σ2π1e−∣θ−μ∣2/2σ2
- μ \mu μ:方向的最大似然估计(均值),代表当前头部方向
- σ 2 \sigma^2 σ2:信念的不确定性(方差)
2.1.2 吸引子动力学
全局抑制:限制整体活动水平,防止过度兴奋。
1 ( σ inte t ) 2 = E W ( σ inte t − 1 ) 2 , 1 ( σ cali t ) 2 = E W ( σ cali t − 1 ) 2 \frac{1}{(\sigma_{\text{inte}}^{t})^{2}} = \frac{E}{W(\sigma_{\text{inte}}^{t-1})^{2}}, \quad \frac{1}{(\sigma_{\text{cali}}^{t})^{2}} = \frac{E}{W(\sigma_{\text{cali}}^{t-1})^{2}} (σintet)21=W(σintet−1)2E,(σcalit)21=W(σcalit−1)2E
- W W W 是总信息量
- E E E 是预设的总信息量上限
相互抑制:确保网络中只有一个稳定的“活动包”(单峰)占据主导地位。
1 ( σ inte t ) 2 = 1 ( σ inte t − 1 ) 2 − Δ inte 1 ( σ cali t − 1 ) 2 , 1 ( σ cali t ) 2 = 1 Δ cali 1 ( σ inte t − 1 ) 2 \frac{1}{(\sigma_{\text{inte}}^{t})^{2}} = \frac{1}{(\sigma_{\text{inte}}^{t-1})^{2}} - \Delta_{\text{inte}} \frac{1}{(\sigma_{\text{cali}}^{t-1})^{2}}, \quad \frac{1}{(\sigma_{\text{cali}}^{t})^{2}} = \frac{1}{\Delta_{\text{cali}}} \frac{1}{(\sigma_{\text{inte}}^{t-1})^{2}} (σintet)21=(σintet−1)21−Δinte(σcalit−1)21,(σcalit)21=Δcali1(σintet−1)21
- Δ inte \Delta_{\text{inte}} Δinte 和 Δ cali \Delta_{\text{cali}} Δcali 控制抑制强度
2.1.3路径积分更新
μ i n t e t = mod ( μ i n t e t − 1 + v t Δ t , 2 π ) \mu_{inte}^t = \text{mod}(\mu_{inte}^{t-1} + v^t \Delta t, 2\pi) μintet=mod(μintet−1+vtΔt,2π)
μ c a l l t = mod ( μ c a l l t − 1 + v t Δ t , 2 π ) \mu_{call}^t = \text{mod}(\mu_{call}^{t-1} + v^t \Delta t, 2\pi) μcallt=mod(μcallt−1+vtΔt,2π)
- v t v^t vt:来自前庭系统的速度信息。
- 由于方向具有周期性,故对 2 π 2\pi 2π取mod。
2.1.4视觉校准更新
当检测到熟悉视觉场景时,校准细胞接收注入能量 p inject ( θ ) p_{\text{inject}}(\theta) pinject(θ)。
1 ( σ cali t ) 2 = 1 ( σ cali t − 1 ) 2 + 1 ( σ inject t ) 2 \frac{1}{(\sigma^t_{\text{cali}})^2} = \frac{1}{(\sigma^{t-1}_{\text{cali}})^2} + \frac{1}{(\sigma^t_{\text{inject}})^2} (σcalit)21=(σcalit−1)21+(σinjectt)21
μ cali t = mod ( ( σ cali t ) 2 ( σ cali t − 1 ) 2 μ cali t − 1 + ( σ cali t ) 2 ( σ inject t ) 2 μ inject t , 2 π ) \mu^t_{\text{cali}} = \text{mod}\left( \frac{(\sigma^t_{\text{cali}})^2}{(\sigma^{t-1}_{\text{cali}})^2} \mu^{t-1}_{\text{cali}} + \frac{(\sigma^t_{\text{cali}})^2}{(\sigma^t_{\text{inject}})^2} \mu^t_{\text{inject}} \,,\, 2\pi \right) μcalit=mod((σcalit−1)2(σcalit)2μcalit−1+(σinjectt)2(σcalit)2μinjectt,2π)
- σ inject t \sigma^{t}_{\text{inject}} σinjectt:注入能量的标准差
- μ inject t \mu^{t}_{\text{inject}} μinjectt:注入能量的均值(预期校准方向)
最终信念是整合细胞和校准细胞信念的融合:
1 ( σ f t ) 2 = 1 ( σ inte t ) 2 + 1 ( σ cali t ) 2 \frac{1}{(\sigma_f^t)^2} = \frac{1}{(\sigma_{\text{inte}}^t)^2} + \frac{1}{(\sigma_{\text{cali}}^t)^2} (σft)21=(σintet)21+(σcalit)21
μ f t = mod ( ( σ f t ) 2 ( σ inte t ) 2 μ inte t + ( σ f t ) 2 ( σ cali t ) 2 μ cali t , 2 π ) \mu_f^t = \text{mod} \left( \frac{(\sigma_f^t)^2}{(\sigma_{\text{inte}}^t)^2} \mu_{\text{inte}}^t + \frac{(\sigma_f^t)^2}{(\sigma_{\text{cali}}^t)^2} \mu_{\text{cali}}^t \,,\, 2\pi \right) μft=mod((σintet)2(σft)2μintet+(σcalit)2(σft)2μcalit,2π)
- σ f t \sigma_f^t σft:综合不确定性的标准差
- μ f t \mu_f^t μft:综合方向估计(整合与校准的加权融合结果)
- 公式说明:
- 第一条公式体现整合(路径积分)和校准(地标修正)不确定性的加权调和平均
- 第二条公式通过方差倒数作为权重,融合整合细胞( μ inte t \mu_{\text{inte}}^t μintet)和校准细胞( μ cali t \mu_{\text{cali}}^t μcalit)的估计
2.2 网格细胞网络
2.2.1表示
- 类似于 HD 网络,但使用二维高斯分布 p ( x , y ) p(x, y) p(x,y) 来表示对位置的信念。
p ( x , y ) = 1 2 π σ x σ y e − ( ( x − μ x ) 2 2 σ x 2 + ( y − μ y ) 2 2 σ y 2 ) p(x, y) = \frac{1}{2\pi\sigma_x\sigma_y} e^{-\left( \frac{(x - \mu_x)^2}{2\sigma_x^2} + \frac{(y - \mu_y)^2}{2\sigma_y^2} \right)} p(x,y)=2πσxσy1e−(2σx2(x−μx)2+2σy2(y−μy)2)
- ( μ x , μ y ) (\mu_x, \mu_y) (μx,μy):位置的最大似然估计(均值),代表机器人在物理空间中的位置
- σ x 2 , σ y 2 \sigma_x^2, \sigma_y^2 σx2,σy2:信念在两个维度上的不确定性
2.2.2神经空间
- 采用具有周期性边界条件的二维神经空间(环面吸引子)。
- ( x , y ) ∈ [ 0 , 2 π ) (x, y) \in [0, 2\pi) (x,y)∈[0,2π)
- 均值 ( μ x , μ y ) (\mu_x, \mu_y) (μx,μy) 编码的实际位置需要通过解卷绕(unwrapping)操作来恢复
2.2.3更新机制
机制与HD网络类似,但作用于二维位置。
3 系统实现
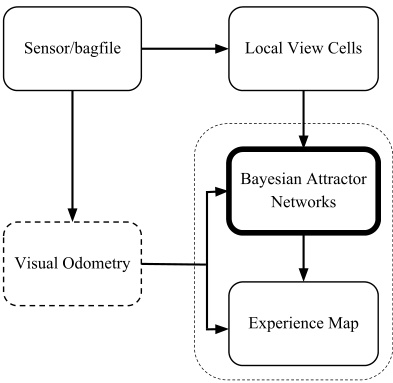
图片展示了NeuroBayesSLAM系统的软件架构。传感器/bagfile节点提供图像和里程计信息。视觉里程计为纯视觉数据集提供速度估计。局部视图单元节点确定当前视图是否熟悉。贝叶斯吸引子网络节点执行路径积分并做出环闭合决策。经验地图节点生成拓扑地图。整个系统通过这些组件协同工作,实现对环境的建模和导航。