# 大模型的本地部署与应用:从入门到实战
大模型的本地部署与应用:从入门到实战
在当今人工智能飞速发展的时代,大模型(尤其是大型语言模型,LLMs)已经成为自然语言处理(NLP)领域的核心力量。从文本生成、机器翻译到问答系统,大模型的应用无处不在。然而,对于许多开发者和研究人员来说,如何在本地环境中高效地部署和使用这些大模型仍然是一个挑战。本文将详细介绍大模型的本地安装、微调、提示词工程以及实战应用,帮助你快速入门并掌握大模型的部署与使用。
一、大模型的本地安装
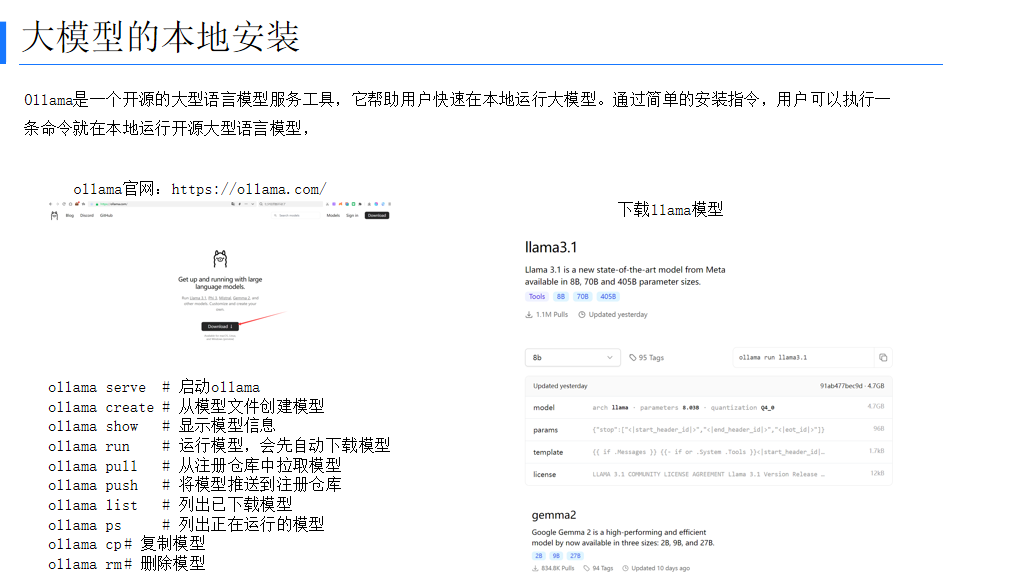
1.1 Ollama:本地运行大模型的利器
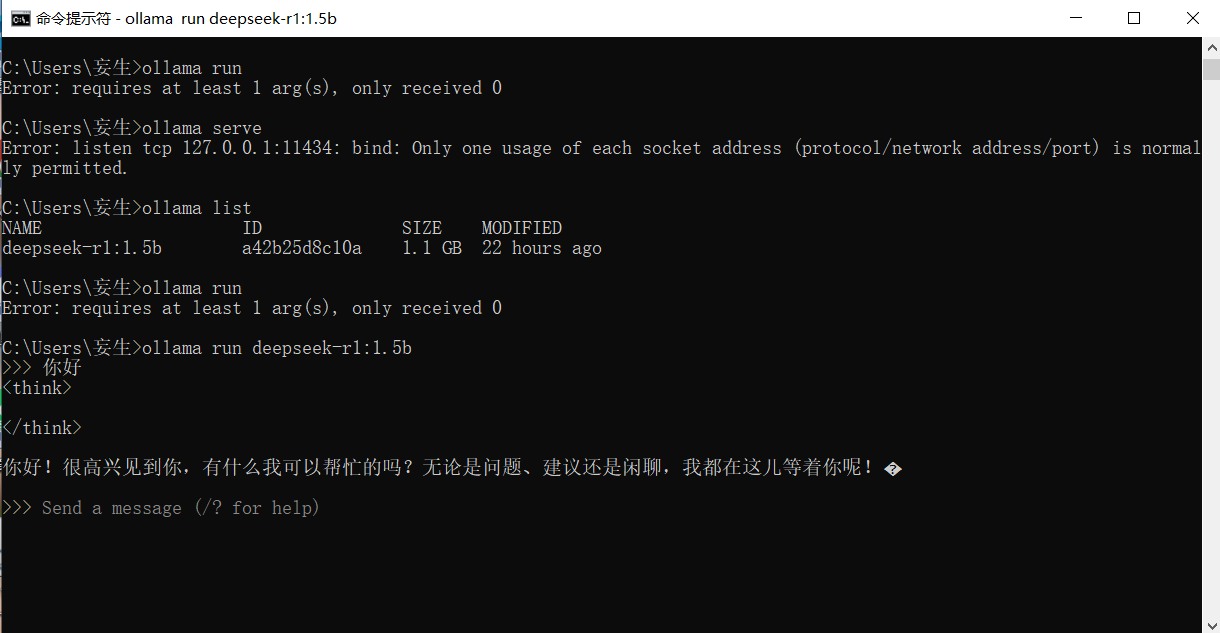
Ollama 是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型。以下是 Ollama 的一些常用命令:
ollama serve:启动 Ollama 服务。ollama create:从模型文件创建模型。ollama show:显示模型信息。ollama run:运行模型,会先自动下载模型。ollama pull:从注册仓库中拉取模型。ollama push:将模型推送到注册仓库。ollama list:列出已下载模型。ollama ps:列出正在运行的模型。ollama cp:复制模型。ollama rm:删除模型。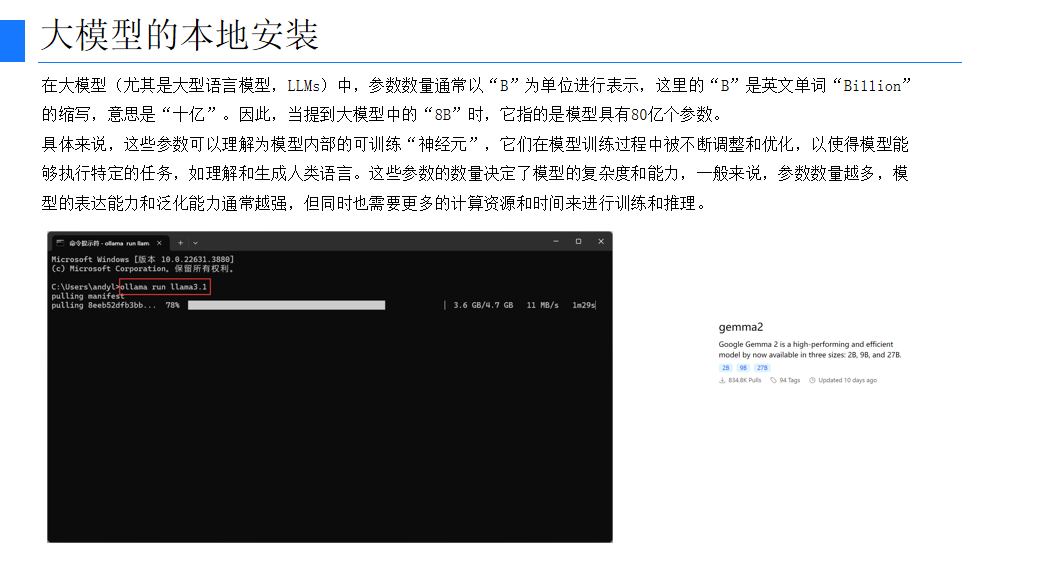
1.2 参数数量与模型复杂度
在大模型中,参数数量通常以“B”为单位表示,这里的“B”是“Billion”(十亿)的缩写。例如,“8B”指的是模型具有80亿个参数。这些参数可以理解为模型内部的可训练“神经元”,它们在模型训练过程中被不断调整和优化,以使得模型能够执行特定的任务,如理解和生成人类语言。参数数量越多,模型的表达能力和泛化能力通常越强,但同时也需要更多的计算资源和时间来进行训练和推理。
二、大模型的微调
2.1 Unsloth:加速模型训练
Unsloth 是一个开源的大模型训练加速项目,使用 OpenAI 的 Triton 对模型的计算过程进行重写,大幅提升模型的训练速度,降低训练中的显存占用。Unsloth 能够保证重写后的模型计算的一致性,实现中不存在近似计算,模型训练的精度损失为零。Unsloth 支持绝大多数主流的 GPU 设备,包括 V100, T4, Titan V, RTX 20, 30, 40x, A100, H100, L40 等,支持对 LoRA 和 QLoRA 的训练加速和高效显存管理,支持 Flash Attention。

2.2 微调资源需求
以 1B 的模型为例,全量微调需要 12GB 的显存,一般是模型的 6 倍。优化器(如 SGD、Adam)消耗资源较大,一般是模型的 4 倍,即 8GB。激活函数消耗资源较小,可以忽略不计。
2.3 高效微调(PEFT):QLoRA 和 LoRA
高效微调(PEFT)是一种通过减少训练参数数量来降低资源需求的方法。例如,QLoRA 和 LoRA 可以将模型的训练参数减少到 5%。具体来说,一个 1B 的模型在微调时,模型本身需要 2GB 的显存,梯度计算需要 0.1GB,优化器需要 0.4GB,总计消耗 2.6GB 的显存。

三、提示词工程
提示词(Prompt)是一种指令、问题或语句,用于引导或指示 AI 语言模型生成特定的文本输出。它是用户与语言模型交互的起始点,告诉模型用户的意图,并期望模型以有意义且相关的方式回应。提示词工程(Prompt Engineering)则是指对提示词进行精心设计和优化的过程,以达到更好的 AI 生成效果。这包括了解如何准确地表达需求,使 AI 能够理解并提供相关的回答。

四、大模型的扩展介绍
4.1 RAG:检索增强生成
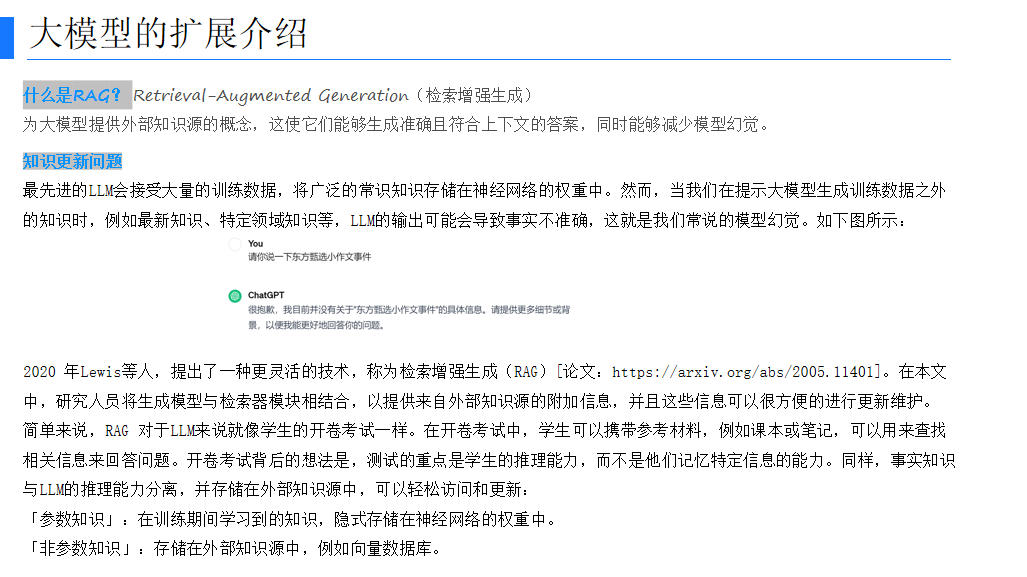
检索增强生成(Retrieval-Augmented Generation, RAG)是一种为大模型提供外部知识源的技术,使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。RAG 将生成模型与检索器模块相结合,提供来自外部知识源的附加信息,这些信息可以方便地进行更新和维护。RAG 对于 LLM 来说就像学生的开卷考试一样,测试的重点是模型的推理能力,而不是它记忆特定信息的能力。
五、大模型部署实战
5.1 Open WebUI:功能强大的自托管 WebUI
Open WebUI 是一个可扩展、功能丰富、用户友好的自托管 WebUI,专为大型语言模型(LLM)设计,旨在完全离线操作。它提供了直观且响应式的用户界面,使用户能够方便地加载、配置、运行和监控各种 AI 模型,而无需编写代码或使用命令行界面。以下是 Open WebUI 的主要功能:
- 支持多种 LLM:支持 Ollama 和 OpenAI 兼容的 API。
- 多模型对话:用户可以轻松地与多个模型同时互动。
- 协作聊天:支持多用户协作聊天。
- 再生历史访问记录:允许用户轻松回顾和探索整个再生历史记录。
- 导入/导出聊天历史:支持无缝地移入和移出聊天数据。
- 语音输入支持:提供语音输入功能。
- 高级参数微调:允许用户通过调整参数(如温度)并定义系统提示,以定制对话到特定偏好和需求。
- 图像生成集成:无缝集成图像生成功能,如 AUTOMATIC1111 API 和 DALL-E。
- OpenAI API 集成:无缝集成和定制各种兼容 OpenAI 的 API。
- 外部 Ollama 服务器连接:支持配置环境变量以连接到托管在不同地址的外部 Ollama 服务器。
- 多个 Ollama 实例负载均衡:支持将聊天请求分布在多个 Ollama 实例上,以提高性能和可靠性。
- 多用户管理:提供直观的管理面板以监督和管理用户。
- 基于角色的访问控制(RBAC):通过限制权限确保安全访问,只有授权的个人才能访问 Ollama,管理员保留专属的模型创建/拉取权限。
5.2 Open WebUI 的部署与安装
Open WebUI 支持多种部署方式,包括 Docker 和 Kubernetes 等容器化技术,以及 pip 直接手动安装。用户可以通过简单的配置和命令实现快速部署和高效管理。具体安装步骤可能因操作系统和用户需求而有所不同。更多详细信息可以参考 Open WebUI 的官方文档:Open WebUI Documentation
5.3 Open WebUI 的应用场景
- 本地模型调试与调用:Open WebUI 为本地大语言模型提供了图形化界面,方便用户进行模型调试和调用。
- 离线运行:由于 Open WebUI 旨在完全离线操作,因此它非常适合在没有网络连接或需要保护数据隐私的环境中使用。
- 个性化定制:用户可以根据自己的需求对 Open WebUI 进行个性化定制,如调整界面布局、添加自定义功能等。
六、Docker 的介绍与安装

6.1 Docker 的核心概念
- 容器:轻量级、可执行的独立软件包,包含应用运行所需的一切要素。
- 镜像:只读模板,包含运行某个软件所需的所有内容。
- 仓库:存储和分享镜像的地方,如 Docker Hub。
- Dockerfile:定义构建镜像的步骤和配置。
6.2 Docker 的优势
- 轻量级虚拟化:容器较传统虚拟机更轻量、高效。
- 运行环境一致性:确保应用在不同环境中的运行一致性。
- 可移植性:容器可以在任何支持 Docker 的环境中运行。
- 高效的资源利用:共享主机操作系统内核,节省资源。
- 快速部署和扩展:容器可以快速启动和部署,支持水平扩展。
- DevOps 支持:桥接开发和运维之间的差距,支持 DevOps 实践。
6.3 Docker 的安装与使用
用户可以从 Docker 官方网站 https://www.docker.com/ 下载适合其操作系统的 Docker 安装程序,并按照提示完成安装过程。安装完成后,用户可以通过 Docker 命令行工具或图形界面工具来管理容器和镜像。更多详细信息可以参考 Docker 的官方文档:Docker Documentation
七、Hugging Face:开源 AI 社区的重要力量

7.1 Hugging Face 的主要产品和服务
- Transformers 库:支持多种深度学习框架,提供大量预训练模型。
- Model Hub:庞大的预训练模型仓库,支持搜索、试用和分享模型。
- Datasets 库:易于使用的数据集库,加速实验流程。
- Tokenizers 库:高效工具用于构建和使用各种分词器。
7.2 Hugging Face 的社区与影响
Hugging Face 构建了一个活跃且开放的研究社区,鼓励知识共享和技术进步。它不仅是获取最新研究成果的地方,也是发布新模型和算法的首选平台之一。通过组织研讨会、发布教程和支持开源项目,Hugging Face 在全球范围内推动了 AI 教育的发展。
结语
大模型的本地部署与应用是一个复杂但充满机遇的领域。通过 Ollama、Unsloth、Open WebUI 和 Docker 等工具,开发者可以高效地在本地环境中部署和使用大模型,同时利用 Hugging Face 等开源社区的资源,加速开发和研究进程。希望本文能够帮助你快速入门并掌握大模型的部署与应用,开启你的 AI 之旅!