SFP与Unsloth:大模型微调技术全解析
在当下流行的几种大模型微调方法中,大家经常会看到谈论SFP与Unsloth的文章,那我们应该如何了解它们?它们的技术特点又有哪些?各自应用在哪些模型微调的场景呢?本篇我们带着这些问题,一起来了解一下。
01
SFT微调技术介绍
监督微调(Supervised Fine-tuning, SFT)是一种迁移学习(Transfer Learning)技术,指的是在已经预训练好的模型(例如大语言模型中的 GPT、BERT 等)基础上,使用带有人工标注标签的监督数据,对模型进行进一步的训练,使其能更好地适应特定任务或领域。
1. 核心目的
-
任务适配:将模型的通用知识聚焦到特定目标(如生成符合人类指令的回答)。
-
性能提升:通过优化任务相关的损失函数(如交叉熵),提升模型在目标任务的准确率。
-
控制输出:约束模型生成格式(如JSON)、风格(如客服礼貌用语)或内容安全性。
2. SFT微调的关键要素:
预训练模型:指的是一个大规模、通用的基础模型,如 GPT、BERT、T5 等。
监督数据:包含输入和对应的目标输出(标签)的数据集,如问答对、分类标签、翻译对等。
损失函数:常见的有交叉熵损失(Cross-Entropy Loss),用于衡量预测输出与真实标签之间的差距。
优化器:如 Adam、AdamW,用于更新模型参数最小化损失函数。
微调策略:决定哪些层可以更新、学习率设置、训练轮数等。
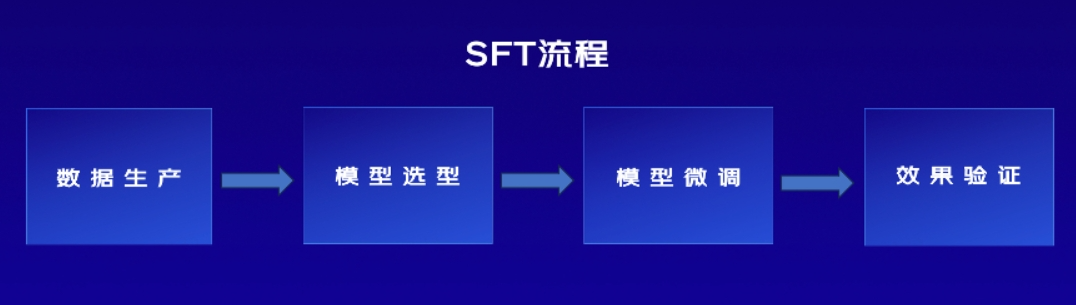
3. 典型流程
(1)加载预训练模型
加载一个已经训练好的基础模型(如 GPT-3、BERT、LLama 等)。
(2)准备监督数据集
数据格式通常为 `(input, output)` 对,例如:
{"input": "请将这段话翻译成英文:我喜欢人工智能。","output": "I like artificial intelligence."}
(3)定义任务和损失函数
如文本生成使用语言建模损失,文本分类使用交叉熵损失等。
(4)微调模型
使用监督数据对模型进行微调,使其在该任务上表现更好。
(5)验证与测试
使用验证集评估模型效果,调整参数,避免过拟合。
大模型微调是NLP 应用开发工程师必须掌握的核心技术之一,它是实现模型“落地应用”的关键步骤。
02
Unsloth微调模型
Unsloth 是一个专注于加速并优化大语言模型(LLM)微调和推理的开源项目。它的目标是让开发者能够更高效、更低成本地在本地或云端微调和部署如 LLaMA、Mistral 等主流开源大模型。
1. 特点
(1)极致加速的微调(Finetuning)
-
Unsloth 使用了一系列优化手段(如 FlashAttention、4bit 量化、LoRA)来让模型微调速度快上数倍。
-
对比 Hugging Face 的 Transformers 微调方式,Unsloth 能实现最高5倍以上训练加速。
-
支持 QLoRA(量化的LoRA),大幅减少所需显存。
(2) 低内存占用(Low Memory Usage)
通过整合 bitsandbytes、Flash Attention、Paged Optimizers 等技术,可以在8GB 或更少显存上训练 7B 甚至 13B 模型。
(3)一行代码加载优化模型
Unsloth 提供了类似 Huggingface 的接口,只需一行代码即可加载优化好的模型:
from unsloth import FastLanguageModelmodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/llama-3-8b-Instruct-bnb-4bit",max_seq_length = 2048,dtype = torch.float16,load_in_4bit = True,)
(4)支持主流开源模型
Unsloth 支持加载和微调多个热门开源 LLM,包括:
-
Meta 的 LLaMA 2 / LLaMA 3
-
Mistral / Mixtral
-
OpenHermes、Zephyr、Code LLaMA 等
(5)兼容 Hugging Face
-
完全兼容 Hugging Face 的 Transformers 和 Datasets。
-
可将微调后的模型上传至 Hugging Face Hub。
(6)推理优化
推理部分也进行了优化,支持 FlashAttention 和量化模型的高效推理。
2. 性能对比示例
根据官方数据,Unsloth的微调效率能够大幅提升,并且适用于个人开发者进行低成本的模型开发。
| 框架 | 模型 | 显存占用 | 微调速度 | 加速比 |
| Huggingface | LLaMA 2 7B | 24GB | 40 tokens/s | 1x |
| Unsloth | LLaMA 2 7B (4bit) | 8GB | 180 tokens/s | 4.5x |
3. 小结
Unsloth 是一个面向开发者和研究人员的高效 LLM 微调工具,具有以下亮点:
-
快速、高效、资源占用低
-
支持主流开源模型
-
接口友好,易于上手
-
支持 4bit QLoRA + FlashAttention
如果你正在寻找一种方式在本地或低成本环境中微调开源大语言模型,Unsloth 是非常值得一试的工具。
03
SFT与Unsloth的联系
Unsloth 是一种工具 / 框架,SFT 是一种微调方法。它们并不矛盾,而是可以结合使用的。
1. 技术实现的差异
(1)传统SFT的瓶颈
-
计算冗余:PyTorch默认算子(如矩阵乘、LayerNorm)未针对微调任务优化,存在冗余内存拷贝。
-
显存浪费:中间激活值(如注意力矩阵)全精度存储,限制batch size和模型规模。
-
硬件利用率低:GPU计算单元空闲等待数据加载或内核启动。
(2)Unsloth的优化
A. 内核融合(Kernel Fusion)
-
将多个连续操作(如QKV投影 → RoPE位置编码 → 注意力计算)合并为单一GPU内核,减少内存I/O和内核启动开销。
-
例如:将PyTorch默认的20几个算子融合为5个定制Triton内核。
B . 4-bit量化训练
-
权重和梯度以4-bit存储(非对称量化),通过QLoRA机制反量化计算,显存占用降低至1/3。
-
量化误差通过微调过程动态补偿,几乎不影响最终精度。
C. 动态内存复用
-
预先分配显存池,避免频繁申请/释放显存(减少CUDA同步开销)。
-
中间变量复用(如梯度计算后立即释放激活值内存)。
2、 两者结合使用
我们可以使用Unsloth 框架来进行 SFT 微调,代码如下:
from unsloth import FastLanguageModelfrom trl import SFTTrainer # Hugging Face 的 SFT Trainermodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/llama-3-8b-Instruct-bnb-4bit",max_seq_length = 2048,dtype = torch.float16,load_in_4bit = True,)trainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=train_dataset,dataset_text_field="text",max_seq_length=2048,)trainer.train()
这段代码中就是使用了SFT 方式进行监督微调,而微调的加速和模型加载部分则是由Unsloth 提供支持。
04
总结
Unsloth微调是传统SFT在工程效率维度上的优化延伸,二者本质上是互补关系而非替代关系。通过底层计算优化,Unsloth让SFT在资源受限场景下变得可行,使开发者能够更专注于数据质量和模型设计,而非被硬件瓶颈束缚。选择时需权衡任务需求、硬件条件和对新技术的接受度。