多路径可靠传输协议(比如 MPTCP)为什么低效
可靠就不能多路径,多路径求可靠必然要多费劲。这不难理解,多路径必异步,这无疑增加了可靠性判断的难度。
前文 多路径传输(比如 MPTCP)对性能的意义 阐述了作为单连接的多子流 MPTCP 对传输性能的意义是无意义,本文接着阐述作为隧道承载协议的 MPTCP 如何继续没意义。看到很多 MiFi(Mobile Wi-Fi) 产品用 MPTCP 做隧道承载协议,就想泼盆凉水,提些警示。
单流 MPTCP 多路径聚合带宽是个无现实意义的考量指标,可能仅为 SpeedTest。常规吞吐都与 RTprop 正交而互为倾轧,吞吐聚合则更必然以 RTwait 做代价,前文说过,多条路径的异构 BDP 矩需要填充更大的发送端 buffer 才能撑满聚合带宽,具体度量取决于多路径对齐到达时间或对齐单位时延后的填充,即 BDP 之和性价比排序情况,而要消除此类时延,就要忽略 BDP 异构性和性价比,这是个矛盾。
简言之,你要在时间序列中精确排序路径性价比,时延,数据序列号,但 TCP 的可观测指标不足以支持这种精确排序,所以性能必有损失。
稍有意义的是 MPTCP 各 Subflow 统计意义上聚合带宽,这意味着它或许可能承载隧道流量。然而 MPTCP 仅抽象成单独的 socket,不具备直接承载隧道中多连接载荷的能力,就只能通过这单独的 MPTCP Meta socket 间接承载。但何必为了猎奇 MPTCP 而如此迂回,明明有更直接的方式。
如下图,使用 MPTCP 和多路标准 TCP 处理相同隧道载荷流量,以通过 tun/tap 转发 iperf 流量为例,你选哪一个:
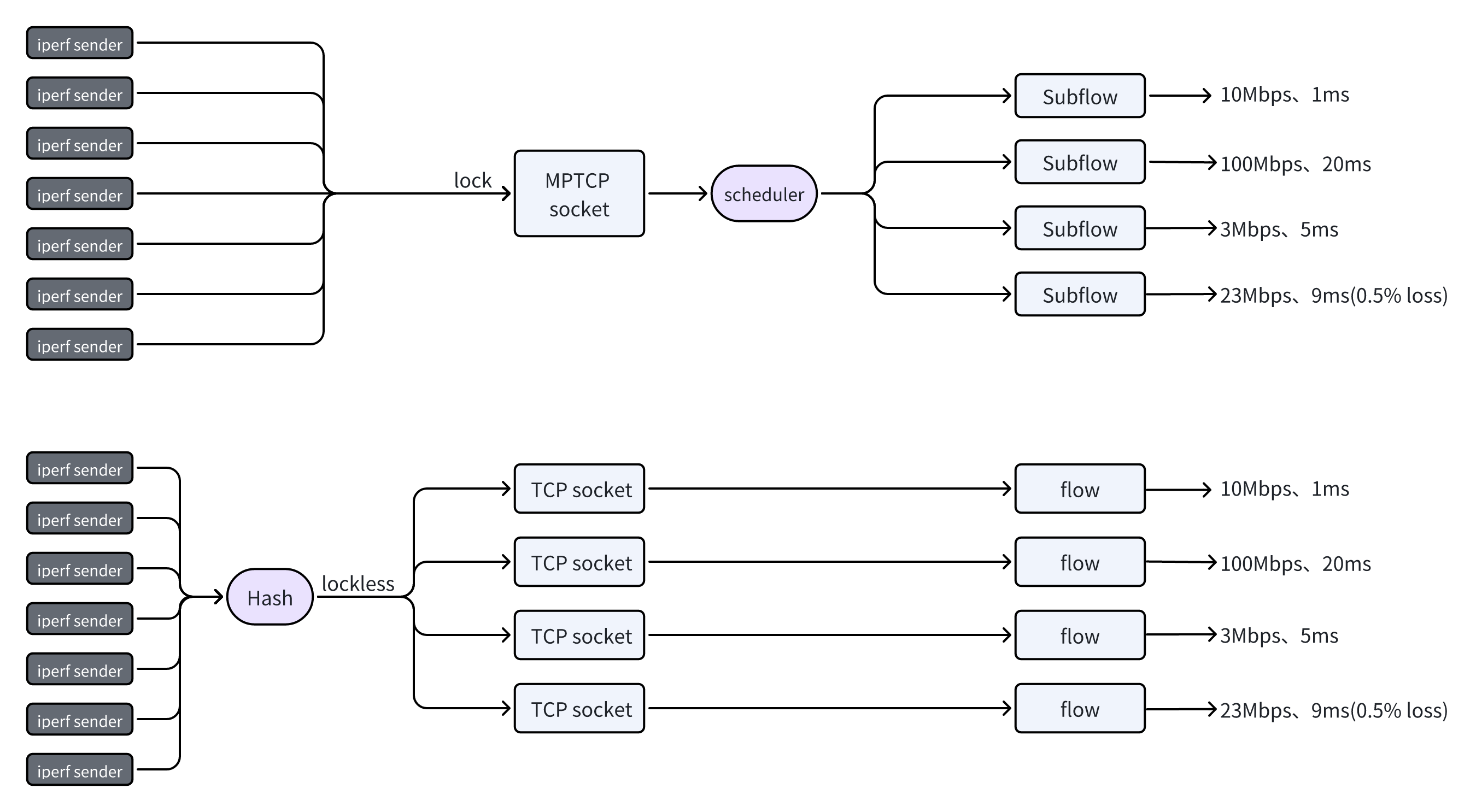
抛开具体协议不谈(比如可用 UDP 构建隧道,但同时要关注运营商对 UDP 的作用力,没完没了的),图示下半部是一个相当成熟的部署方案,比如 wireguard 等,以及各类加速器均采用这类方案,在多流统计意义上,它工作得很好:
- 每条路径都在满负荷带宽运行状态,带宽资源聚合叠加效果 100 分;
- 每条路径单独实施拥塞控制(比如 BBRv3),低时延体验 80 分(取决于具体 cc);
亲自比对一下上图的两类,MPTCP 输出总吞吐不超过 100Mbps,无论任何调度算法,且时延在 10ms 以上抖动,而多路标准 TCP 则稳定输出 130Mbps 以上,时延各自算各自,你说哪个好。
然而现实中总要有点花活儿,不然何谈创造。哪怕横竖一颠倒,扑朔迷离。横竖一颠倒,多个序变成一个强序,维持熵减需要的消耗更大,这个普遍真理一会儿稍微详述。
返回看 MPTCP 的主页:
初识 MPTCP,当初记得(有人告诉我)它可以最大限度兼容既有代码,不需要对程序进行太大的修改就可以适配 MPTCP,但终究还是不能不改,无法透明兼容。此外,MPTCP 路径管理作为控制平面逻辑,着实为应用程序覆盖太多的新增,这也就不是什么兼容强度问题了,而是一个新东西。
明明可以用现有组件堆出来的逻辑,非要出个新东西,自诩兼容却既麻烦又低效,这背后的隐藏动机恐怕是自私的。作为比较,看看 Netfilter 的主页,https://www.netfilter.org/,全是内容,没有纠结,因为没有 Netfilter,你无法用现有组件堆出来一个等价的。
回到最上面 MPTCP 和多 TCP 的对比,我就想起了当年修改 OpenVPN,修改 Wireguard 为多处理的幼稚动机,后来我检讨了自己。再次反思,如果这类修改真能提升 10 倍吞吐,社区不可能想不到。
OpenVPN,Wireguard 只提供搭建多处理系统的组件而不提供多处理逻辑本身,这非常合理。如此,工人们便可以通过各种方式组合并行多套组件来做多处理。创建多实例,流量在多个 tun 设备间 LB 才高尚,而反观我直接对进程做多线程改造,纯屎上雕花。
MPTCP 也是屎上雕花。
要说多路径标准 TCP 相比 MPTCP 的不足,最上面图示缺失了 scheduler 模块,仅仅显示了一个简单 hash 作为一个简单但足以说明问题的例子,这显然会带来公平性问题,比如连续两次 hash 到不同的 socket,那么更完整的结构应该如下:
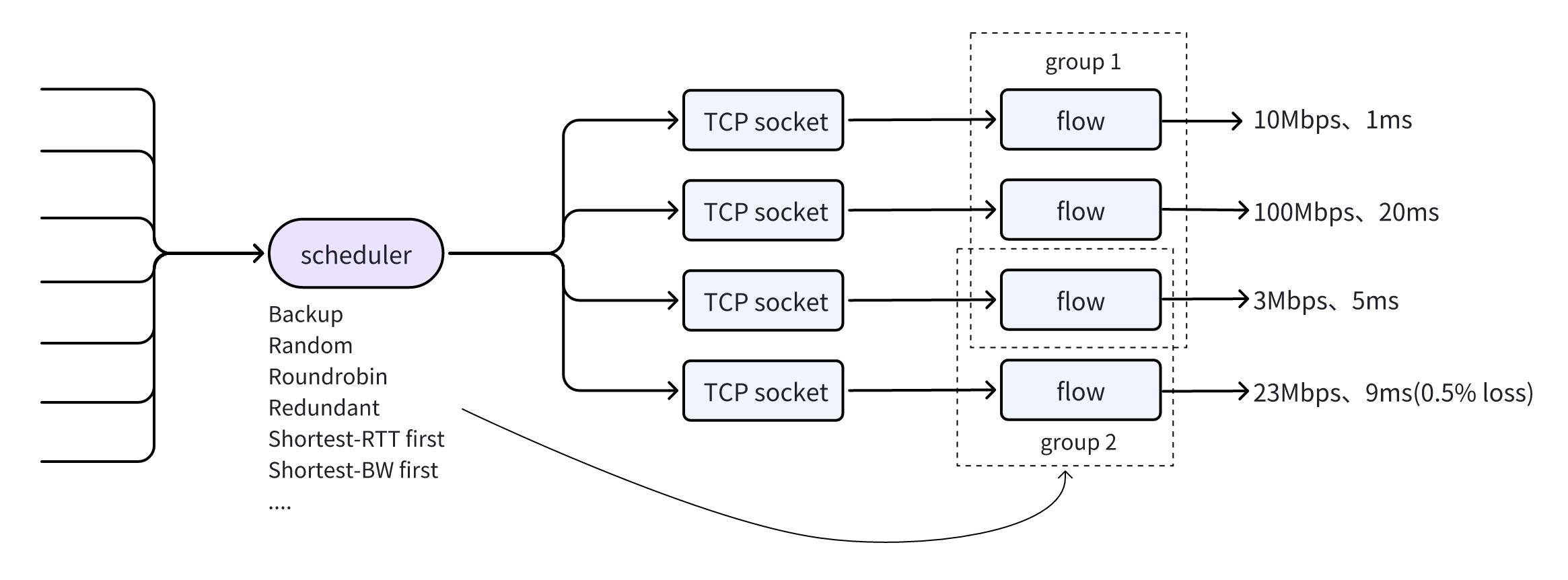
在实践和牢骚之外,前面点到,从熵和无序性的角度理解这个问题是高尚的。
稍微详细论述之前,需要明确的是,即使不使用 MPTCP 承载隧道流量,单单使用标准 TCP 做承载协议本身就不合适,这个我在早前做 overlay 城域网时就有关注,详见 Why TCP Over TCP Is A Bad Idea,Why TCP over TCP is a bad idea (2001),姑且解除 TCP over TCP 约束,扩展到 anything over TCP 的普遍情况,证明两个层面的事:
- anything over TCP 非常低效;
- anything over MPTCP 在 over TCP 低效的基础上更低效;
根据信息论中的 Landauer 定律,擦除 1 bit 信息至少需要消耗 k ⋅ T ln 2 k\cdot T\ln{2} k⋅Tln2 的能量(k 为玻尔兹曼常数,T 为温度)。Landauer 定律建立了信息和能量之间的关系,统一了信息论和热力学。
对于数据传输而言,维持可靠性和有序性需要降低熵,Landauer 定律意味着,降低熵需要持续消耗能量。
先看 anything over TCP 的情况,将 anything 松散到 UDP 是合适的。根据 Landauer 定律:
E ∝ Δ H ⋅ t = ( H i n i t i a l − H f i n a l ) ⋅ t E∝ΔH⋅t=(H_{initial}−H_{final})⋅t E∝ΔH⋅t=(Hinitial−Hfinal)⋅t
由于 H T C P _ f i n a l < H U D P _ f i n a l H_{TCP\_{final}}<H_{UDP\_{final}} HTCP_final<HUDP_final,这意味着传输相同的数据,TCP 比 UDP 能耗更大(这是个显而易见的结论,但 Landauer 定律量化了它),那么相等能耗下,TCP 的效率更低。
顺着 Landauer 定律,证明 over MPTCP 更低效就不难了。
首先,MPTCP 维持 TCP 可靠,保序的语义,TCP 的特征 MPTCP 全部继承,其次只需要说明:
Δ H M P T C P = H M P T C P _ i n i t i a l − H f i n a l > Δ H T C P = H T C P _ i n i t i a l − H f i n a l \Delta H_{MPTCP}=H_{MPTCP\_initial}−H_{final}>\Delta H_{TCP}=H_{TCP\_initial}−H_{final} ΔHMPTCP=HMPTCP_initial−Hfinal>ΔHTCP=HTCP_initial−Hfinal
而这是显而易见的。
为理解这种显而易见,从衡量系统无序程度的信息熵定义出发,导出 MPTCP 的初始信息熵 H M P T C P _ i n i t i a l H_{MPTCP\_initial} HMPTCP_initial 高于标准 TCP 的 H T C P _ i n i t i a l H_{TCP\_initial} HTCP_initial,本质原因是多路径并行传输引入了更复杂的无序性来源。它们来自三个效应可叠加的维度。
首先,路径独立性导致的无序性叠加。
标准 TCP 通过单路径传输,其无序性(熵)上限由单路径路由,RTT 等波动范围决定,而 MPTCP 将数据流拆分到多条独立路径,每条路径的路由,RTT 等波动完全独立,因此 MPTCP 的无序性会随多路径扩散。多路径的独立随机过程导致数据包到达顺序的可能性空间增大,即信息熵 H = − ∑ p i log p i H = -\sum p_i \log p_i H=−∑pilogpi 中的概率分布 p i p_i pi 更分散(更多可能的乱序组合),因此 H M P T C P _ i n i t i a l H_{MPTCP\_initial} HMPTCP_initial 的该分量更高。
其次,跨路径序列号的 “全局无序性” 扩张。
标准 TCP 序列号仅在单路径内有效,接收端只需按单路径的序列号顺序重组数据,乱序范围限于未确认的窗口,无序性(熵)是局部范围的有限状态。MPTCP 为所有 Subflow 分配全局序列号,但 Subflow 报文异步注入接收端,接收端面对的是跨路径全局乱序,无序性范围扩展至所有 Subflow 窗口总和,假设标准 TCP 的乱序状态数为 N N N(N 为窗口),MPTCP 的乱序状态数为 ( k ⋅ N ) (k \cdot N) (k⋅N)(k 为路径数),这个式子轻松解释了下面的事实:
如果要聚合 Subflow 吞吐,就要付出更大的能耗,否则就接受聚合后的低效;
因此 H M P T C P _ i n i t i a l H_{MPTCP\_initial} HMPTCP_initial 的该分量更高。
第三,路径动态性引入的熵增波动。
标准 TCP 的链路状态相对稳定,乱序模式具有时间相关性,如拥塞导致相对可预测时延,信息熵 H T C P _ i n i t i a l H_{TCP\_initial} HTCP_initial 接近平稳分布。MPTCP 支持路径动态切换或负载均衡,这会引发无序性脉冲式上升以及拍频效应,即周期性无序性增强,类似两个不同频率信号叠加产生的振幅波动。这些动态过程使 H M P T C P _ i n i t i a l H_{MPTCP\_initial} HMPTCP_initial 的该分量不仅绝对值更高,还包含随时间变化的熵增波动分量,进一步拉大与标准 TCP 的差距。
综上三者, H M P T C P _ i n i t i a l > H T C P _ i n i t i a l H_{MPTCP\_initial} > H_{TCP\_initial} HMPTCP_initial>HTCP_initial 由多路径的独立随机过程,全局跨路径无序性和路径动态性三个维度的所有可能的状态共同决定。
设标准 TCP 到达顺序用离散随机变量 X T C P X_{TCP} XTCP 表示,可能状态数为 M,则 MPTCP 的跨路径到达顺序为 X M P T C P X_{MPTCP} XMPTCP,状态数为 M k M^k Mk,即 k 条路径独立状态的笛卡尔积。
根据信息熵公式 H ( X ) = log 2 ∣ X ∣ H(X) = \log_2 |\mathcal{X}| H(X)=log2∣X∣, 则 H M P T C P _ i n i t i a l = log 2 M k = k ⋅ log 2 M = k ⋅ H T C P _ i n i t i a l H_{MPTCP\_initial} = \log_2 M^k = k \cdot \log_2 M = k \cdot H_{TCP\_initial} HMPTCP_initial=log2Mk=k⋅log2M=k⋅HTCP_initial 当 k ≥ 2 k \geq 2 k≥2 时,显然 H M P T C P _ i n i t i a l > H T C P _ i n i t i a l H_{MPTCP\_initial} > H_{TCP\_initial} HMPTCP_initial>HTCP_initial。
它的物理意义即,多路径使数据包到达顺序的 “可能性空间” 指数级扩展,信息熵随路径数线性增长,无序性本质上不可压缩。
然而现实中 MPTCP 至少能用,还不至于如上论证般拉跨,这实在是我一直将重点指向负面,现在补充仅剩下的正向熵减作用。
若要 MPTCP 可用,需实施更强的力量,如全局序列号管理,Subflow 调度,重排序等,以抵消熵增,相当于用这些算法实现的复杂性和能耗做代价有限提升吞吐。这一特性符合热力学第二定律,系统复杂度增加会导致无序基准线上升,维持有序性需付出更高成本,“更” 字说的是,每使一份劲,都要有能量耗散。
我在十年前曾排查过多起由于多核网关并发处理 TCP 流导致其吞吐下降一到两个数量级的案例,彼时各类转发技术刚刚开始还没完全开始卷,大多数人觉得并行处理可优化一切(现在依然这样认为),却忽略了流式传输的内在约束,这些案例正反面证明我上面的论述,换句话说,把 MPTCP 调度策略去掉,按 roundrobin or 时间戳 hash 的方式选择 Subflow,将会获得类似结局。
MPTCP 初版大概就在十年前给出:
本着对 MP 并行的执念,网关为什么不能并行处理 TCP,不就是加个调度算法吗?是也不是,要看规模缩放比例。
不是没人这么做,硬件如 Intel 某些处理器以及软件如 Wireguard 等都有并行流式加密逻辑,但这建立在加密操作本身时延相比仅转发时延高一个或几个数量级的基础上,这种差异下,多路径并行操作时上述三个叠加维度的波动本身占比就相当小,以至可忽略,最终还是规模缩放比例问题,这就跟广域网长传不值当优化单机性能但数据中心却必须关注传输 CPU 利用率一样。
相对立的另一面,基于 Landauer 定律的分析恰证明 MPTCP 在路径热备份模式下有收益。由于只有一条 Subflow 参与传输,当一条 Subflow 劣化到几乎不可用时,另一条 Subflow 接管行为正好削减了无序性而不是增加,比如 Subflow1 的 RTT 从 10ms 陡增到 2s 并持续,而另一条 Subflow2 以 40~100ms 波动 RTT 快速接管传输无论如何都是好事,但这两个 Subflow 同时传输,结局就很糟糕。
最后,我来综评为什么聚合带宽以获得聚合吞吐没有意义,因为绝大多数情况下,应用并不需要大吞吐,但却需要低时延,而聚合带宽的行为结果往往是付出了昂贵的时延却没得到不怎么需要的吞吐。
总之,聚合带宽本质上是个内卷添堵行为,网络拥塞的成因可以理解为对 buffer 的内卷,因为一条流的实际带宽取决于 buffer 占比而不是总量。既然内卷,普适真理是资源越匮乏,内卷越狠。带宽资源匮乏,无法满足所有用户在线行为,用户自然会将数据下载到本地离线使用,比如看片;带宽资源丰盈,可满足用户在线行为时,用户关注点就转移到低时延,相比突发下载,持续在线往往并不需要大带宽(对局游戏 100Kbps 量级)。
该现状下,传输吞吐优化领域的疲软跟当前网络传输模式改变有关,大文件下载越来越少,当今音视频流码率自适应带宽,高吞吐让位于低时延,大多数应用都 app limited,猛灌型的 “优化” 就没了市场,不管是技术还是人。
MPTCP 十多年了,几乎没有被部署更何谈广泛部署,大多数猎奇者都会在调研初期放弃,剩下的会继续拿它做 topic 写论文,所以说几乎看不到什么真东西。但作为一个玩具,玩转了确实能让人不明觉厉。
浙江温州皮鞋湿,下雨进水不会胖。