深入理解SummaryWriter类与TensorBoard的基本使用
文章目录
- 引言
- 官方文档
- 一、TensorBoard概述和安装
- 二、SummaryWriter类详解
- 2.1 SummaryWriter类介绍和初始化
- 2.2 基本数据记录方法
- 2.2.1 记录标量数据
- 2.2.2 记录多个标量
- 2.2.3 记录直方图
- 2.2.4 记录图像
- 2.2.5 记录模型图
- 2.2.6 记录嵌入向量
- 2.2.7 记录超参数
- 2.2.8 记录P-R曲线
- 四、最佳实践
- 五、完整示例
引言
- 在深度学习和机器学习项目中,可视化是理解模型行为、调试问题和优化性能的关键环节。TensorBoard作为TensorFlow生态系统中的可视化工具,配合PyTorch中的SummaryWriter类,为研究人员和开发者提供了强大的实验跟踪和结果可视化能力。本文将详细介绍SummaryWriter类的使用方法以及如何通过它有效地利用TensorBoard进行实验监控。
官方文档
- PyTorch官方文档 - TensorBoard支持
- TensorBoard官方文档
- PyTorch TensorBoard教程
一、TensorBoard概述和安装
- TensorBoard安装与基本操作指南(PyTorch)
二、SummaryWriter类详解
2.1 SummaryWriter类介绍和初始化
- 在PyTorch中,
SummaryWriter类是连接PyTorch与TensorBoard的桥梁。要使用它,首先需要导入:
from torch.utils.tensorboard import SummaryWriter
- 然后创建一个
SummaryWriter实例:
writer = SummaryWriter(log_dir='runs/experiment_1')
参数说明:
log_dir:指定保存日志文件的目录。如果未指定,默认会生成一个runs/目录,并在其中创建以当前时间戳命名的子目录。comment:可以向默认的log_dir添加注释后缀purge_step:当TensorBoard因崩溃而重启时,可以跳过某些步骤max_queue:在磁盘写入前内存中存储的最大事件数flush_secs:将挂起的事件写入磁盘的频率(秒)filename_suffix:添加到所有事件文件名的后缀
- SummaryWriter的初始化方法:
- 提供一个路径,例如
./run/test,将使用该路径来保存日志
writer=SummaryWriter('./runs/test')
- 无参数,默认使用
./runs/日期时间路径来保存日志:
writer=SummaryWriter()
- 提供一个comment参数,将使用
./runs/日期时间-comment路径来保存日志:
writer=SummaryWriter(comment='test')
- 关闭SummaryWriter:使用完毕后,应该关闭
SummaryWriter以确保所有事件都被刷新到磁盘:
writer.close()
- 或者使用上下文管理器:
with SummaryWriter() as writer:writer.add_scalar('Loss/train', loss.item(), epoch)
2.2 基本数据记录方法
2.2.1 记录标量数据
- 最常用的功能是记录标量值,如损失和准确率:
writer.add_scalar('Loss/train', loss.item(), global_step=epoch)
writer.add_scalar('Accuracy/train', accuracy, global_step=epoch)
参数说明:
tag:数据的标识符,可以使用层级结构(如’Loss/train’)scalar_value:要记录的标量值global_step:记录的步数/迭代次数/epoch数
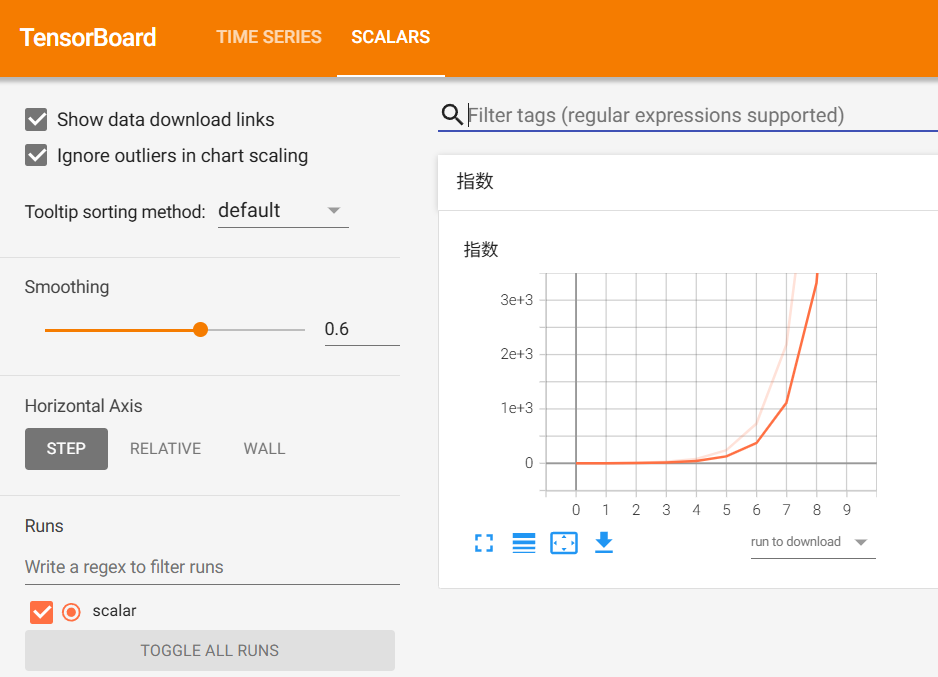
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(log_dir = './runs/test')
for i in range(10):writer.add_scalar('指数', 3**i, global_step=i)
writer.close()
2.2.2 记录多个标量
- 可以使用
add_scalars同时记录多个相关标量:
writer.add_scalars('Loss', {'train': train_loss, 'val': val_loss}, epoch)
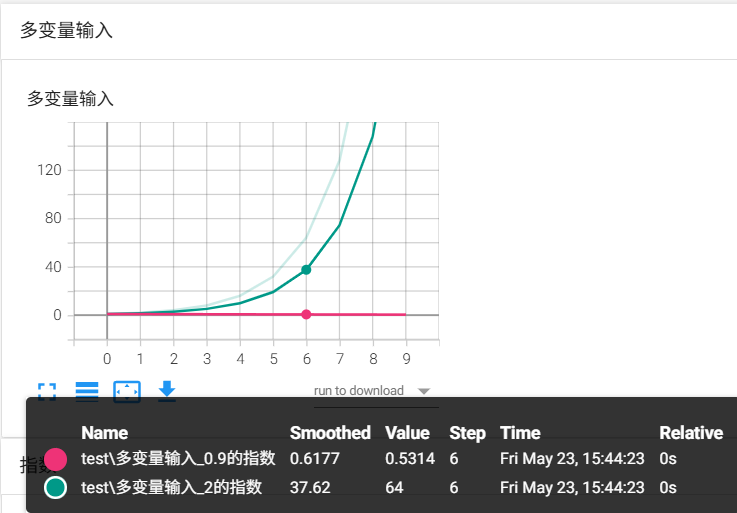
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(log_dir = './runs/test')
for i in range(10):writer.add_scalars('多变量输入', {'0.9的指数': 0.9**i, '2的指数': 2**i}, i)
writer.close()
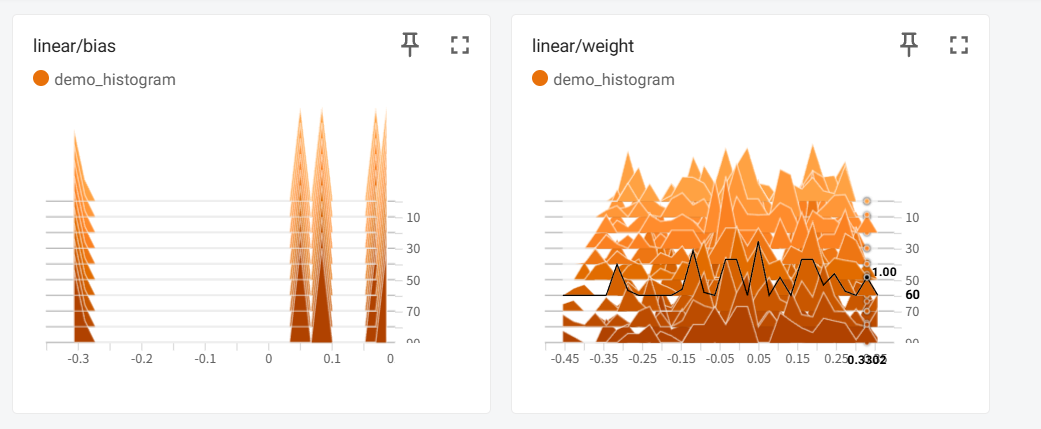
2.2.3 记录直方图
- 记录张量的分布对于分析模型参数和激活非常有用:
writer.add_histogram(tag, values, global_step=epoch,bins='tensorflow',walltime=None,max_bins=None)
tag (string):数据名称。values(torch.Tensor, numpy.array,or string/blobname):用来构建直方图的数据。global_step (int, optional):训练的step。bins(string,optional):取值有’tensorflow’、‘auto’、‘fd’等,该参数决定了分桶的方式。walltime(float,optional):记录发生的时间,默认为time.time()。max_bins(int,optional):最大分桶数。
import torch
from torch.utils.tensorboard import SummaryWriter# 初始化
writer = SummaryWriter('runs/demo_histogram')
model = torch.nn.Linear(10, 2) # 简单线性层for step in range(100):# 模拟训练过程model.weight.data += 0.01 * torch.randn_like(model.weight)# 每10步记录一次权重分布if step % 10 == 0:writer.add_histogram('linear/weight', model.weight, step)writer.add_histogram('linear/bias', model.bias, step)writer.close()
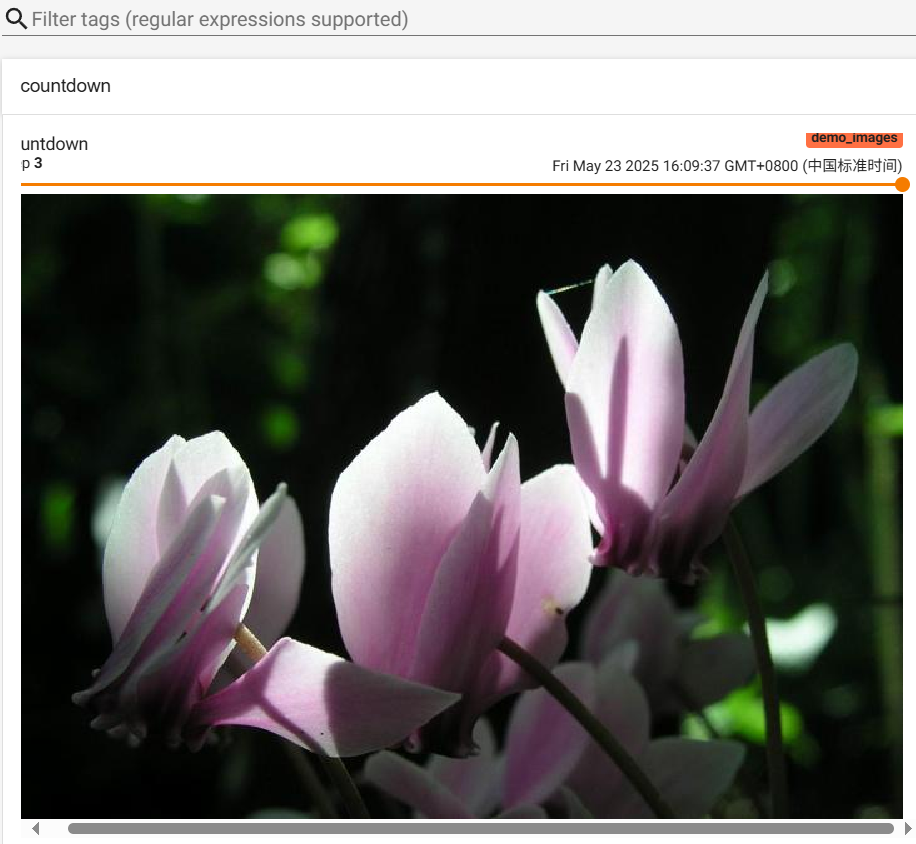
2.2.4 记录图像
- 可以记录图像数据用于可视化:
writer.add_image('input_images', img_tensor, global_step=epoch,walltime=None,dataformats='CHW')
- 对于多张图像,可以使用
add_images:
writer.add_images('batch_images', img_batch, global_step=epoch,walltime=None,dataformats='CHW')
- 参数说明:
tag(string):数据名称。img_tensor(torch.Tensor/numpy.array):图像数据。global_step(int,optional):训练的step。walltime(float,optional):记录发生的时间,默认为time.time()。dataformats(string,optional):图像数据的格式,默认为CHW,即Channel x Height x Width,还可以是'CHW'、'HWC'或'HW'等。
countdown为图像的名称,将图像从BGR格式转换为RGB格式后添加,global_step为全局步骤,dataformats指定图像的格式为HWC。
调用这个方法一定要保证数据的格式正确,像PyTorch Tensor的格式就是默认的'CHW'。可以拖动滑动条来查看不同global_step下的图片。
from torch.utils.tensorboard import SummaryWriter
import cv2 as cv# 初始化
writer = SummaryWriter('./runs/demo_images')for i in range(1,4):# 确保图像维度正确并使用正确的 dataformats 参数writer.add_image('countdown', cv.cvtColor(cv.imread('./image/{}.jpg'.format(i)), cv.COLOR_BGR2RGB),global_step=i, dataformats='HWC')writer.close()
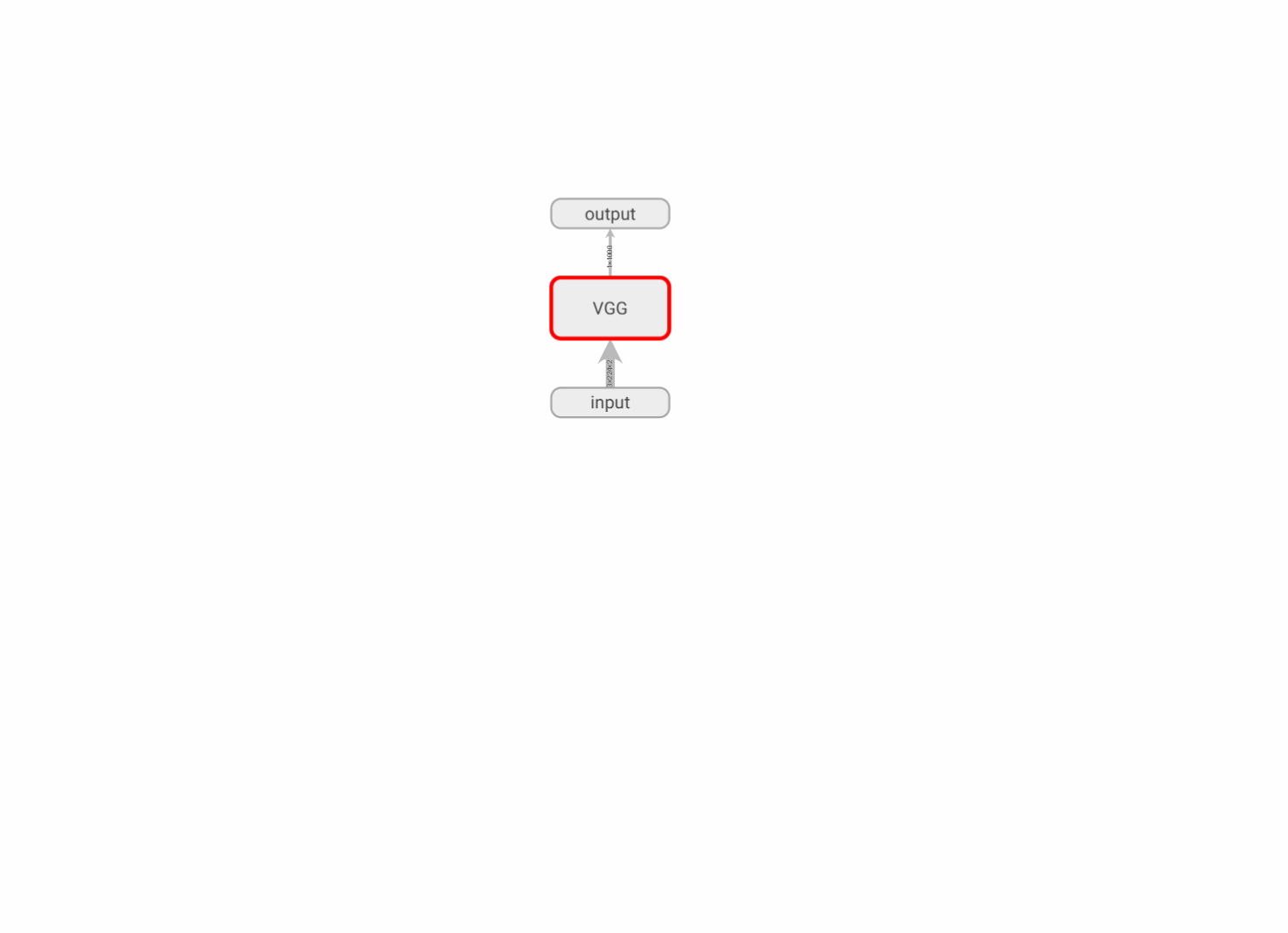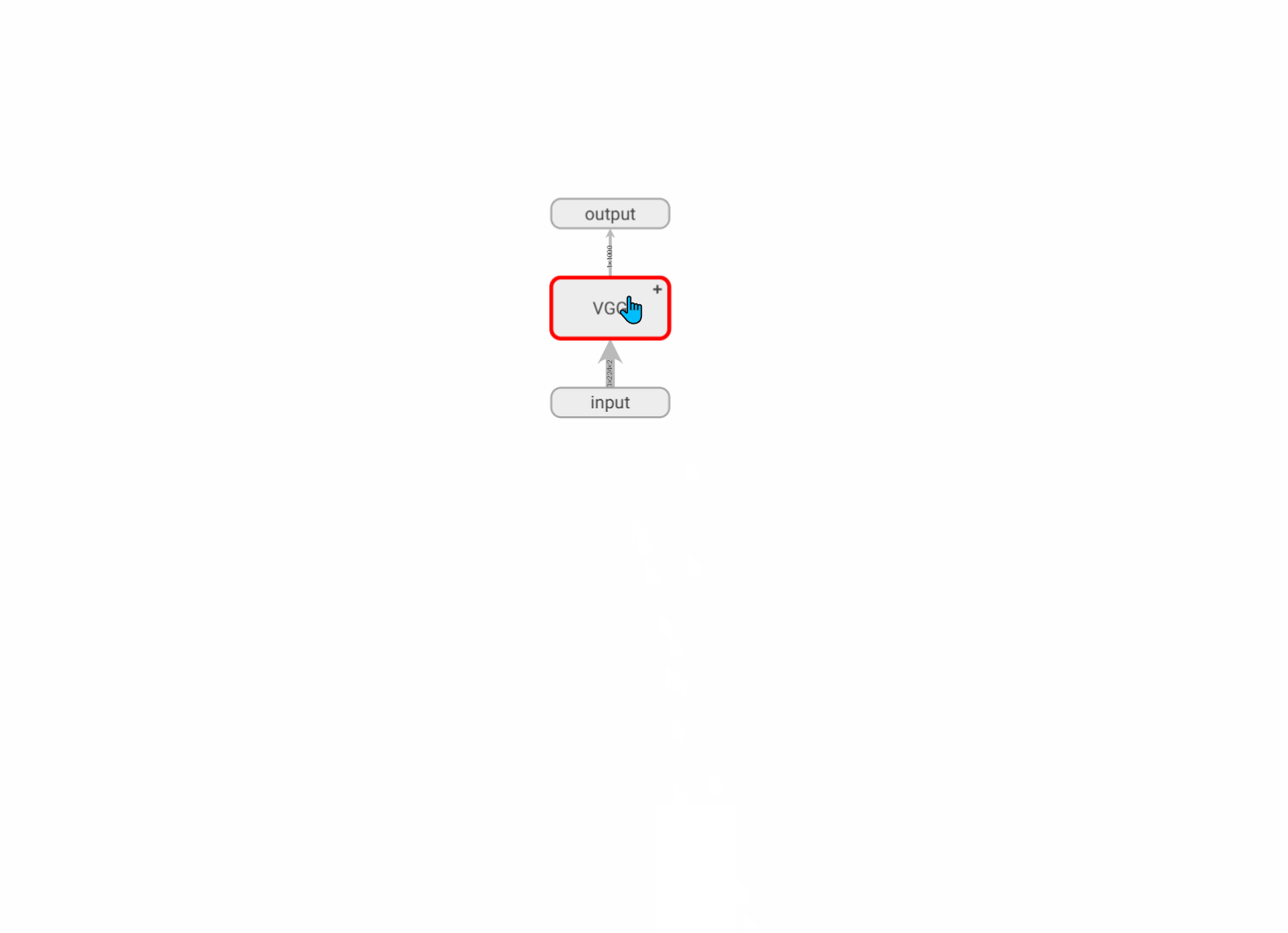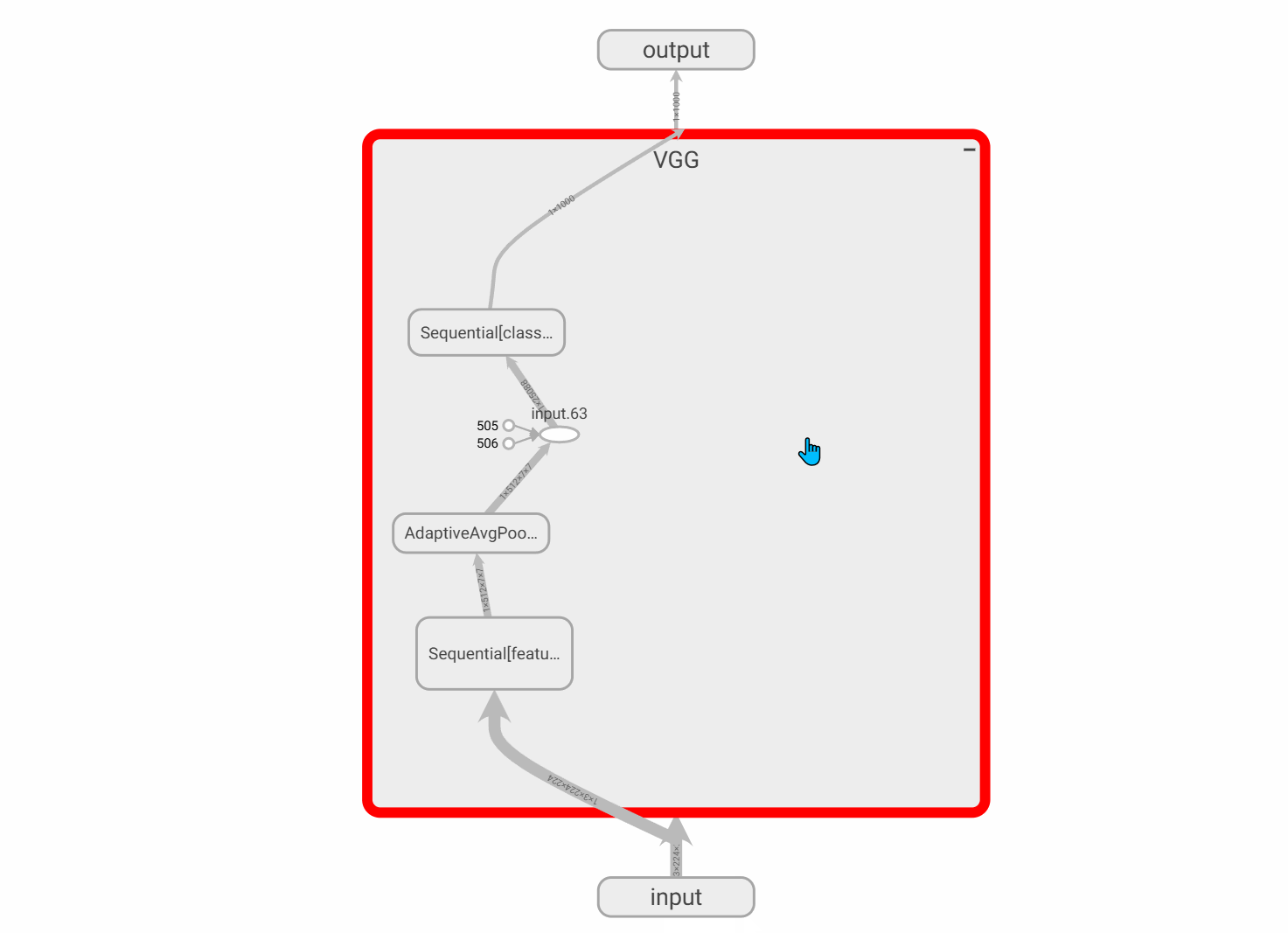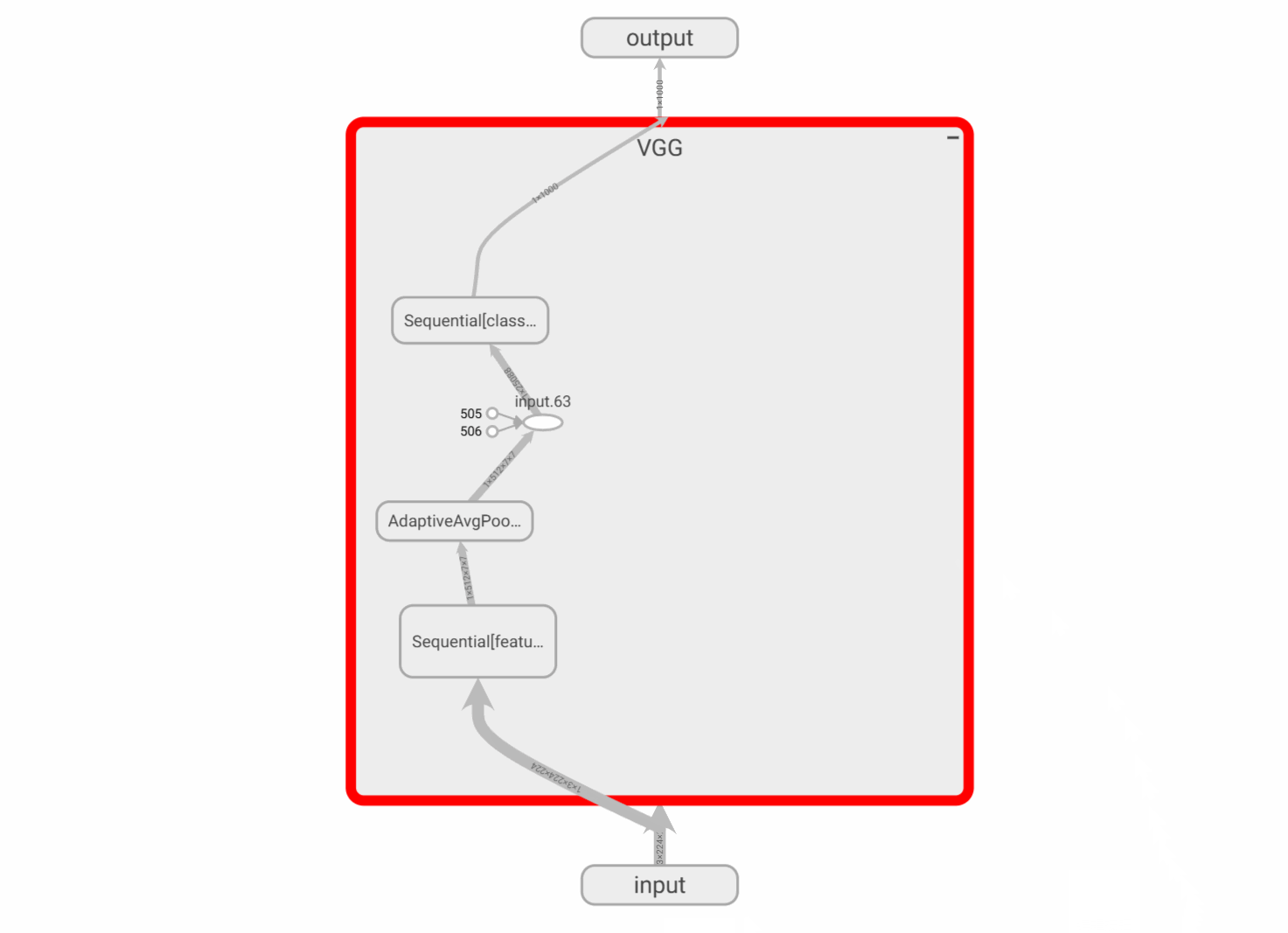
2.2.5 记录模型图
- 记录模型的计算图:
writer.add_graph(model, input_to_model=None,verbose=False,**kwargs)
model(torch.nn.Module):待可视化的网络模型。input_to_model(torch.Tensororlistoftorch.Tensor,optional):待输入神经网络的变量或一组变量。
import torch
import numpy as np
from torchvision import models,transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWritervgg16 = models.vgg16() # 这里下载预训练好的模型transform_2 = transforms.Compose([transforms.Resize(224),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Lambda(lambda x: torch.index_select(x, 0, torch.LongTensor([2, 1, 0]))),transforms.Lambda(lambda x: x*255),transforms.Normalize(mean = [103.939, 116.779, 123.68],std = [ 1, 1, 1 ]),
])cat_img = Image.open('./image/1.jpg')
vgg16_input=transform_2(cat_img)[np.newaxis]# 因为pytorch的是分批次进行的,所以我们这里建立一个批次为1的数据集
print(vgg16_input.shape)#开始前向传播,打印输出值
raw_score = vgg16(vgg16_input)
raw_score_numpy = raw_score.data.numpy()
print(raw_score_numpy.shape, np.argmax(raw_score_numpy.ravel()))#将结构图在tensorboard进行展示
with SummaryWriter(log_dir='./runs/demo_graph', comment='vgg16') as writer:writer.add_graph(vgg16, (vgg16_input,))
writer.close()
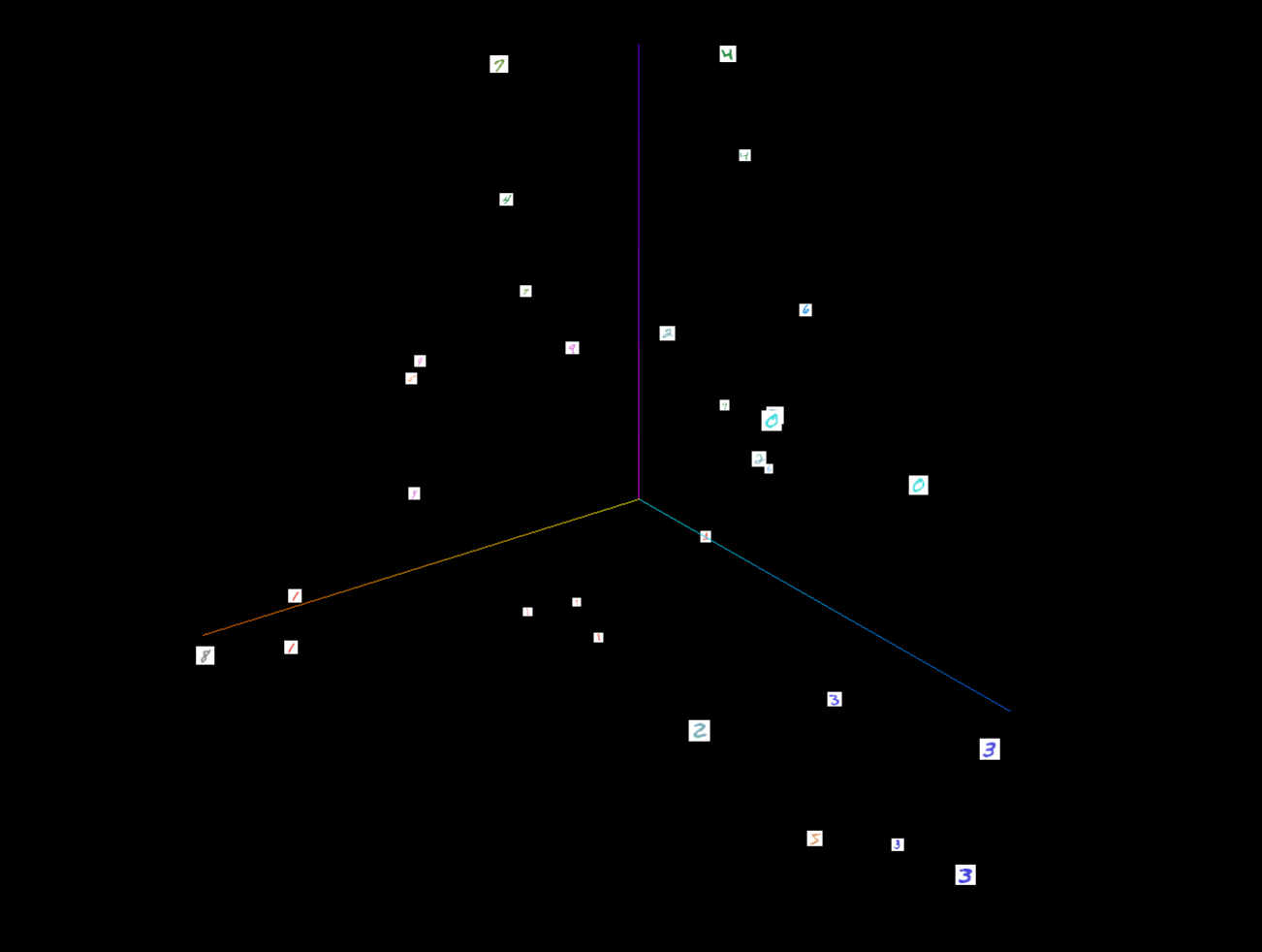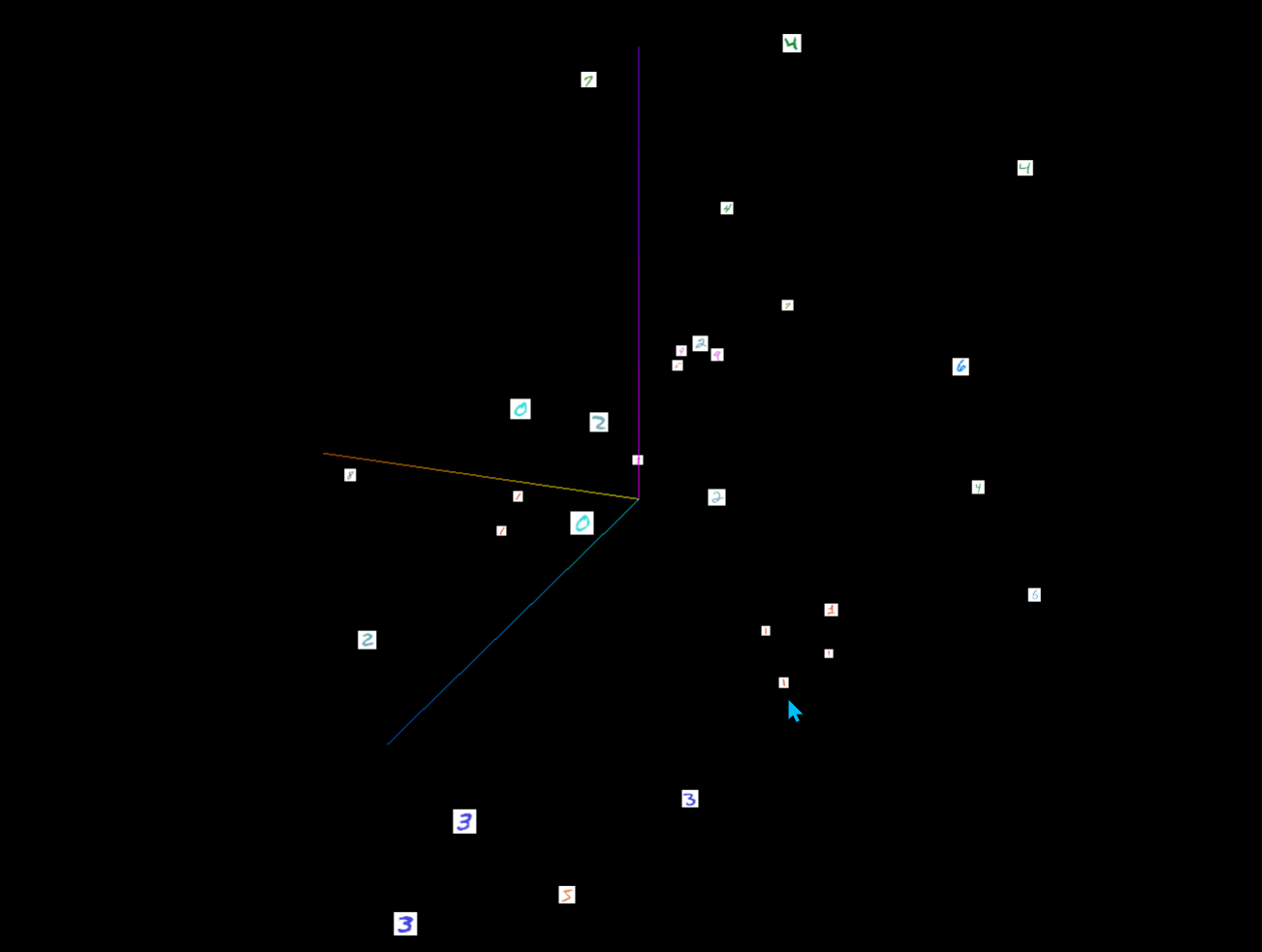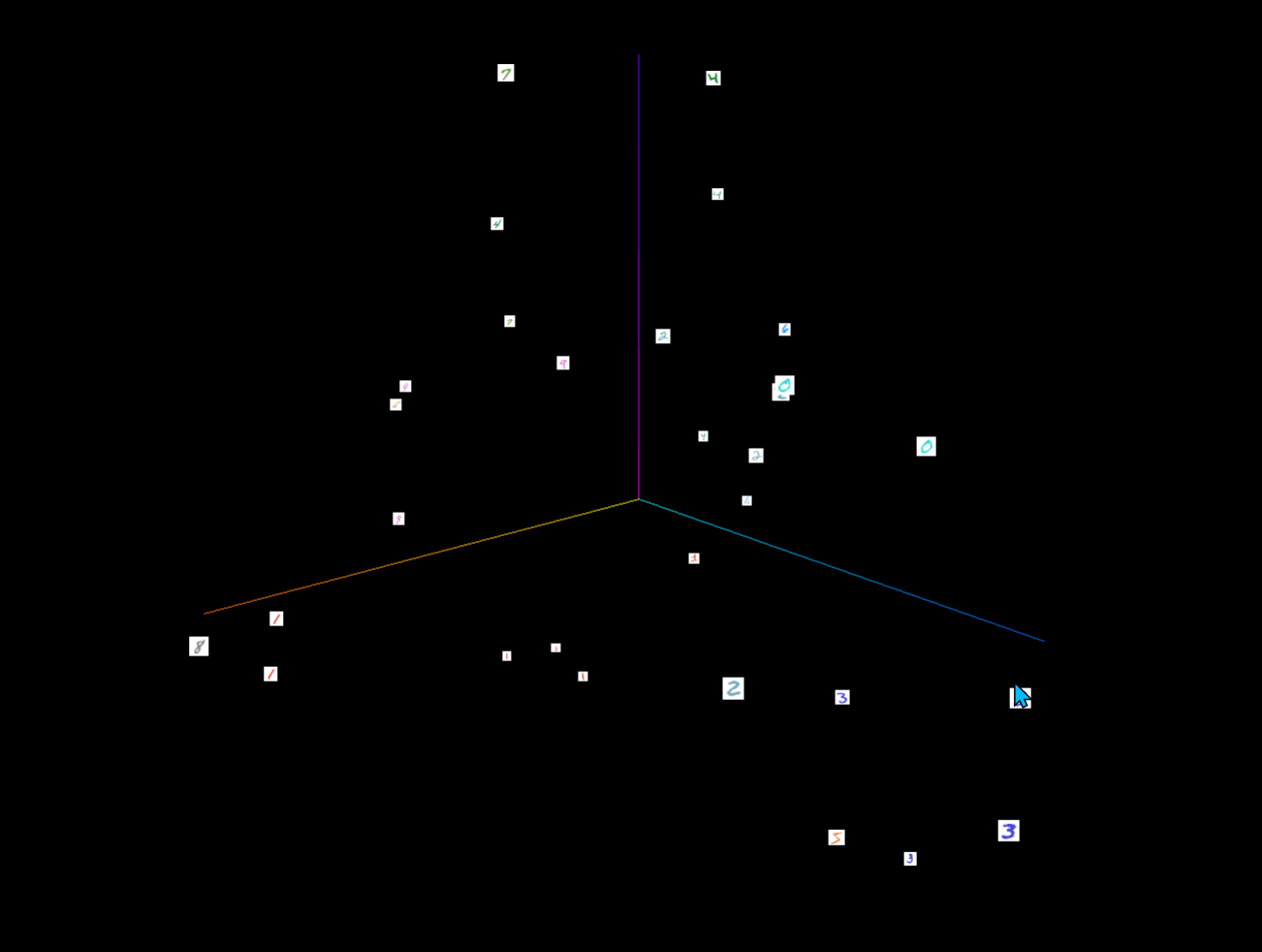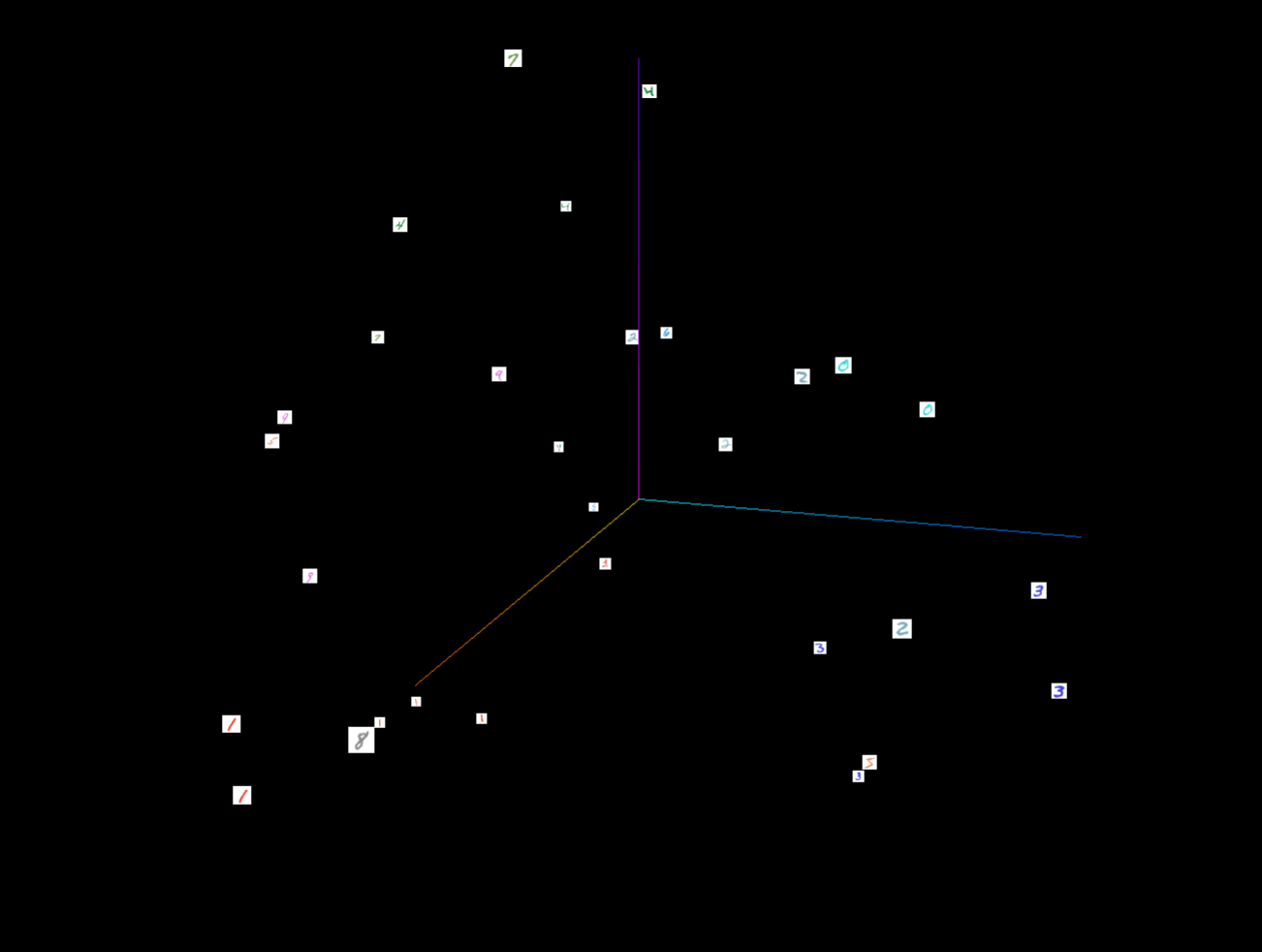
2.2.6 记录嵌入向量
- 可视化高维数据的低维表示:
writer.add_embedding(mat, metadata=None, label_img=None, global_step=None,tag='default',metadata_header=None)
mat(torch.Tensor or numpy.array):一个矩阵,每行代表特征空间的一个数据点。metadata (list or torch.Tensor or numpy.array, optional):一个一维列表,矩阵中每行数据的标签,大小应和矩阵行数相同。label_img(torch.Tensor,optional):一个形如 N × C × H × W N \times C \times H \times W N×C×H×W的张量,对应矩阵每一行数据显示出的图像, N N N应和矩阵行数相同。global_step (int, optional):训练的步长。tag (string,optional):数据名称,不同名称的数据将分别展示。
- 将MNIST数据集的一部分图像转换为嵌入向量,并将这些嵌入向量以及相关的元数据和图像添加到SummaryWriter中。
import torchvision
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter('runs/vector')
mnist = torchvision.datasets.MNIST('./data', download=False)
writer.add_embedding(mnist.data.reshape((-1, 28 * 28))[:30,:],metadata=mnist.targets[:30],label_img = mnist.data[:30,:,:].reshape((-1, 1, 28, 28)).float() / 255,global_step=0
)
writer.close()
2.2.7 记录超参数
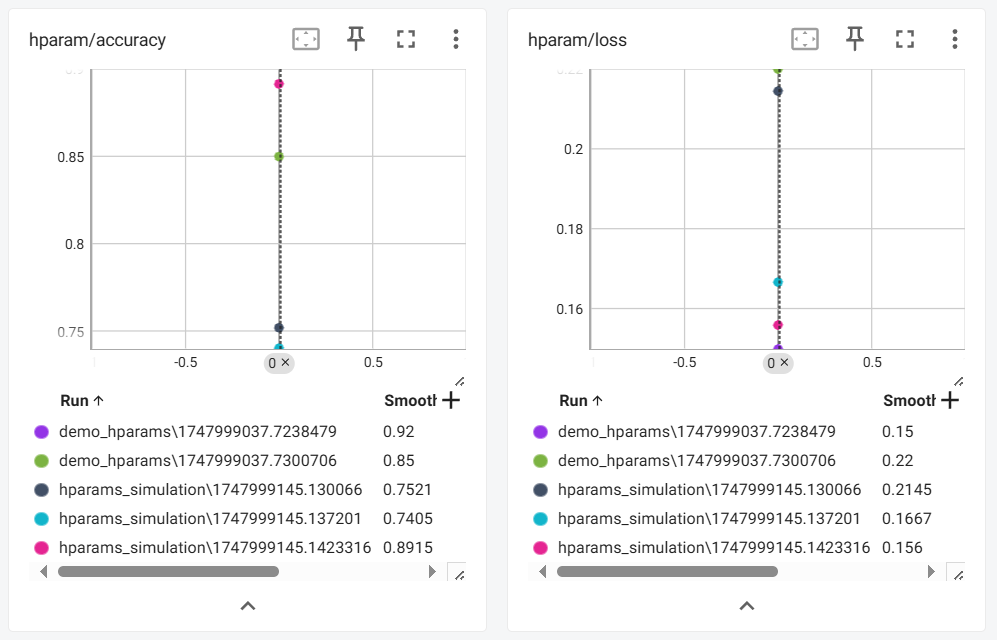
- 记录模型超参数和指标:
writer.add_hparams({'lr': 0.01, 'bsize': 32},{'hparam/accuracy': 0.9, 'hparam/loss': 0.1}
)
from torch.utils.tensorboard import SummaryWriter
import randomwriter = SummaryWriter('runs/hparams_simulation')# 模拟3组不同超参数的训练结果
for i in range(3):lr = 0.01 * (i+1) # 学习率递增batch_size = 32 * (i+1) # 批量大小递增# 模拟指标(随机值演示)accuracy = 0.8 + random.uniform(-0.1, 0.1)loss = 0.2 + random.uniform(-0.05, 0.05)# 记录当前超参数组合和指标writer.add_hparams({'lr': lr, 'batch_size': batch_size, 'exp_id': i},{'hparam/accuracy': accuracy, 'hparam/loss': loss})writer.close()

2.2.8 记录P-R曲线
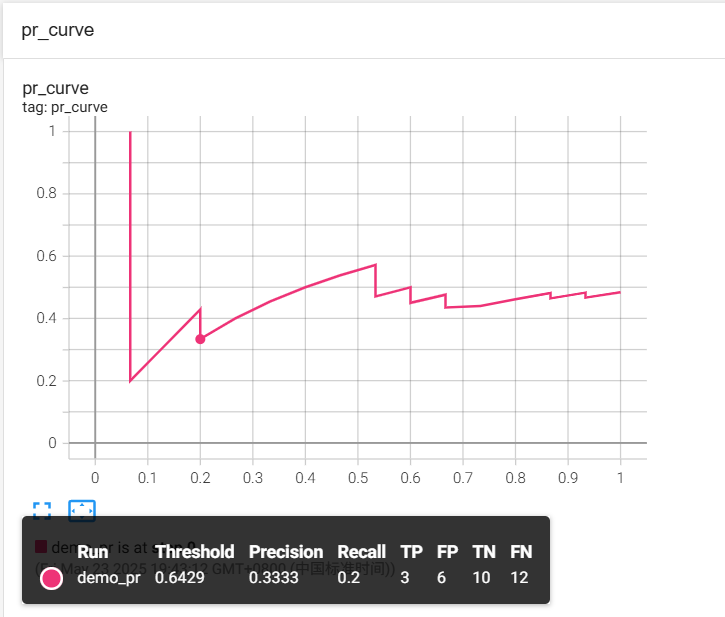
- P-R曲线就是精确率(Precision)和召回率(Recall)曲线,以召回率作为横坐标轴,精确率作为纵坐标轴。
P r e c i s i o n = T P T P + F P R e c a l l = T P T P + F N Precision=\frac{TP}{TP+FP}\\ Recall=\frac{TP}{TP+FN} Precision=TP+FPTPRecall=TP+FNTP - 使用算法对样本进行分类时,一般都有置信度,即表示该样本是正样本的概率。可以通过置信度对所有样本进行排序,再逐个选择阈值,将该样本之前的样本视为正例,该样本之后的例子视为负类。对于每个作为划分阈值的样本,都可以计算对应的精确度和召回率,从而绘制出曲线。
- 使用add_pr_curve方法来绘制P-R曲线:
add_pr_curve(classes[class_index],tensorboard_preds,tensorboard_probs,global_step=global_step)
tensorboard_preds(float):模型的预测值。tensorboard_probs(float):模型预测值的概率。global_step (int, optional):训练的step。
import numpy as np
from torch.utils.tensorboard import SummaryWriter
np.random.seed(20250523)
# 生成100个随机整数 范围为2到上限,并将其存储再labels变量中
labels=np.random.randint(2, size=100)
# 生成100个随机浮点数 范围为[0,1] ,并将其存储再predictions变量中
predictions=np.random.randn(100)
writer = SummaryWriter('runs/demo_pr')
# 添加PR曲线 用于评估二分类问题的性能
writer.add_pr_curve('pr_curve', labels, predictions, global_step=0)
writer.close()
四、最佳实践
- 命名规范:使用一致的命名约定(如
Loss/train、`Accuracy/va)、层级结构可以提高可读性 - 记录频率:训练循环中:每100-1000个batch记录一次、验证阶段:每个epoch记录一次
- 组织实验:为每个实验创建单独的日志目录、在目录名中包含关键超参数或实验日期
- 资源管理:避免记录过多数据导致日志文件过大、定期清理不需要的旧实验
五、完整示例
- 以下是一个完整的PyTorch训练循环中使用SummaryWriter的示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter# 定义简单模型
class SimpleModel(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)# 初始化
model = SimpleModel()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
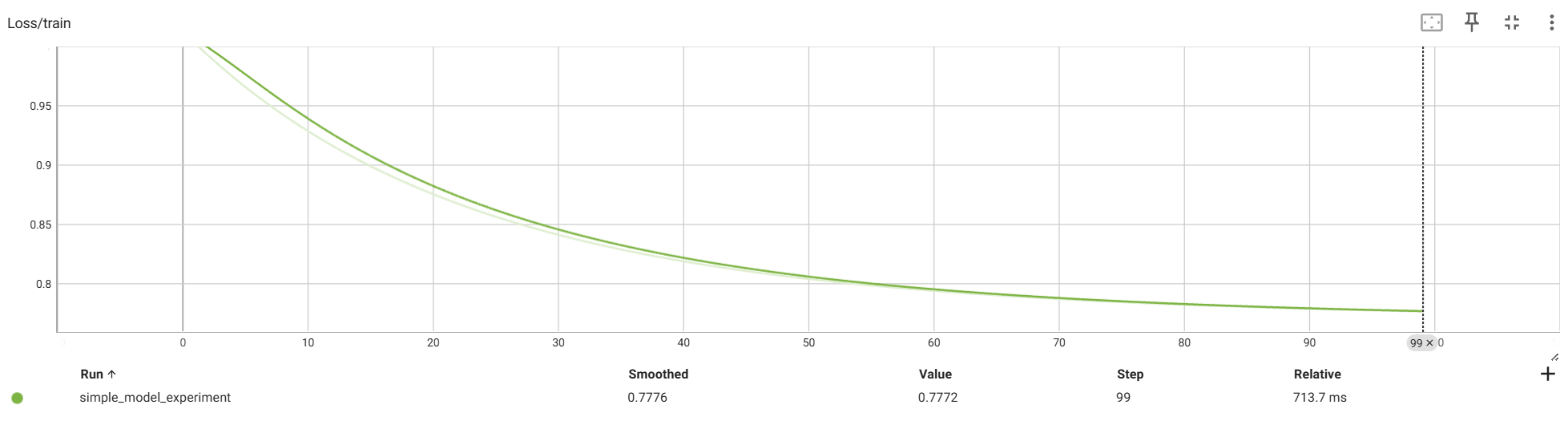
writer = SummaryWriter('runs/simple_model_experiment')# 模拟数据
inputs = torch.randn(100, 10)
targets = torch.randn(100, 1)# 训练循环
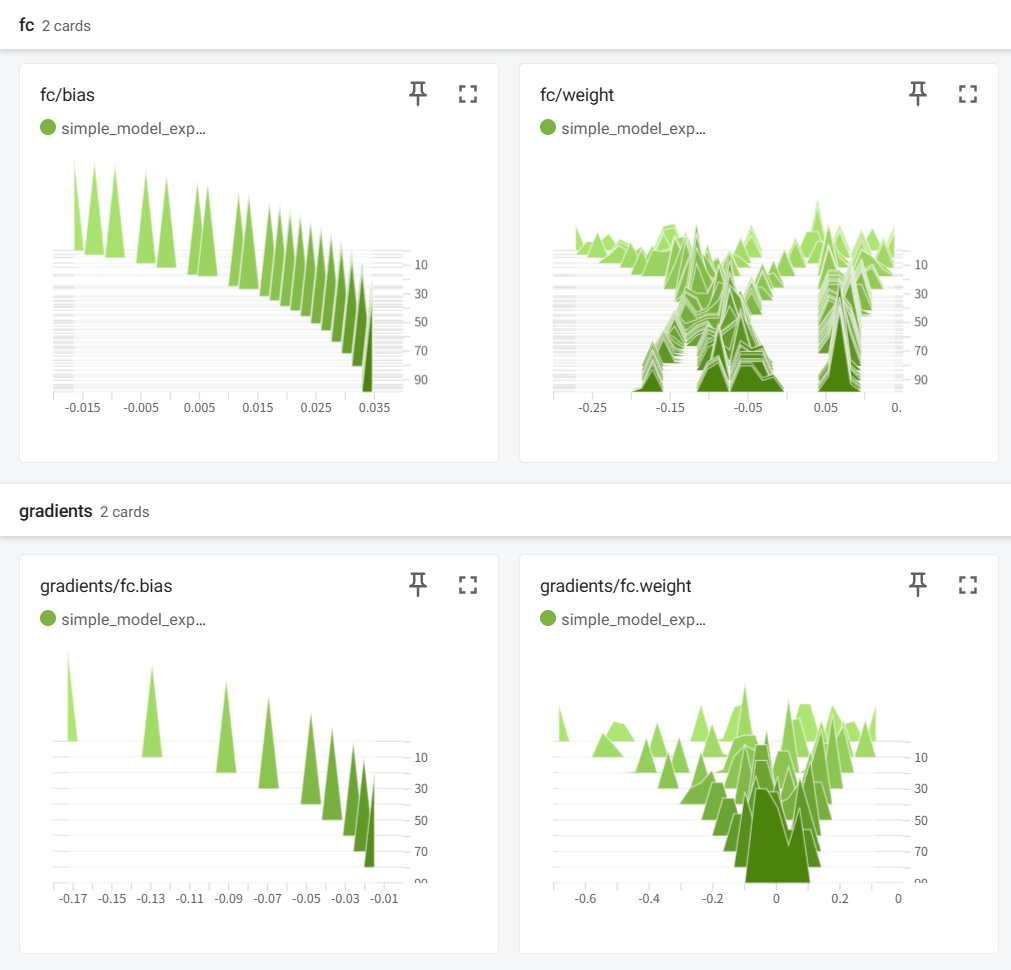
for epoch in range(100):optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()# 记录标量writer.add_scalar('Loss/train', loss.item(), epoch)# 记录直方图writer.add_histogram('fc/weight', model.fc.weight, epoch)writer.add_histogram('fc/bias', model.fc.bias, epoch)# 每10个epoch记录一次梯度if epoch % 10 == 0:for name, param in model.named_parameters():writer.add_histogram(f'gradients/{name}', param.grad, epoch)# 记录模型图
dummy_input = torch.randn(1, 10)
writer.add_graph(model, dummy_input)# 记录超参数和最终指标
writer.add_hparams({'lr': 0.01, 'batch_size': 100},{'hparam/loss': loss.item()}
)writer.close()